diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
new file mode 100644
index 00000000..c35dbd76
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/bug_report.md
@@ -0,0 +1,58 @@
+---
+name: Bug report
+about: Create a bug report, if you don't follow this template, your report will be DELETED
+title: ''
+labels: 'triage'
+assignees: 'dgtlmoon'
+
+---
+
+**DO NOT USE THIS FORM TO REPORT THAT A PARTICULAR WEBSITE IS NOT SCRAPING/WATCHING AS EXPECTED**
+
+This form is only for direct bugs and feature requests todo directly with the software.
+
+Please report watched websites (full URL and _any_ settings) that do not work with changedetection.io as expected [**IN THE DISCUSSION FORUMS**](https://github.com/dgtlmoon/changedetection.io/discussions) or your report will be deleted
+
+CONSIDER TAKING OUT A SUBSCRIPTION FOR A SMALL PRICE PER MONTH, YOU GET THE BENEFIT OF USING OUR PAID PROXIES AND FURTHERING THE DEVELOPMENT OF CHANGEDETECTION.IO
+
+THANK YOU
+
+
+
+
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**Version**
+*Exact version* in the top right area: 0....
+
+**To Reproduce**
+
+Steps to reproduce the behavior:
+1. Go to '...'
+2. Click on '....'
+3. Scroll down to '....'
+4. See error
+
+! ALWAYS INCLUDE AN EXAMPLE URL WHERE IT IS POSSIBLE TO RE-CREATE THE ISSUE - USE THE 'SHARE WATCH' FEATURE AND PASTE IN THE SHARE-LINK!
+
+**Expected behavior**
+A clear and concise description of what you expected to happen.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
+
+**Desktop (please complete the following information):**
+ - OS: [e.g. iOS]
+ - Browser [e.g. chrome, safari]
+ - Version [e.g. 22]
+
+**Smartphone (please complete the following information):**
+ - Device: [e.g. iPhone6]
+ - OS: [e.g. iOS8.1]
+ - Browser [e.g. stock browser, safari]
+ - Version [e.g. 22]
+
+**Additional context**
+Add any other context about the problem here.
diff --git a/.github/ISSUE_TEMPLATE/feature_request.md b/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 00000000..6f50d85f
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,23 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: '[feature]'
+labels: 'enhancement'
+assignees: ''
+
+---
+**Version and OS**
+For example, 0.123 on linux/docker
+
+**Is your feature request related to a problem? Please describe.**
+A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
+
+**Describe the solution you'd like**
+A clear and concise description of what you want to happen.
+
+**Describe the use-case and give concrete real-world examples**
+Attach any HTML/JSON, give links to sites, screenshots etc, we are not mind readers
+
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
diff --git a/.github/test/Dockerfile-alpine b/.github/test/Dockerfile-alpine
new file mode 100644
index 00000000..b255195d
--- /dev/null
+++ b/.github/test/Dockerfile-alpine
@@ -0,0 +1,31 @@
+# Taken from https://github.com/linuxserver/docker-changedetection.io/blob/main/Dockerfile
+# Test that we can still build on Alpine (musl modified libc https://musl.libc.org/)
+# Some packages wont install via pypi because they dont have a wheel available under this architecture.
+
+FROM ghcr.io/linuxserver/baseimage-alpine:3.16
+ENV PYTHONUNBUFFERED=1
+
+COPY requirements.txt /requirements.txt
+
+RUN \
+ apk add --update --no-cache --virtual=build-dependencies \
+ cargo \
+ g++ \
+ gcc \
+ libc-dev \
+ libffi-dev \
+ libxslt-dev \
+ make \
+ openssl-dev \
+ py3-wheel \
+ python3-dev \
+ zlib-dev && \
+ apk add --update --no-cache \
+ libxslt \
+ python3 \
+ py3-pip && \
+ echo "**** pip3 install test of changedetection.io ****" && \
+ pip3 install -U pip wheel setuptools && \
+ pip3 install -U --no-cache-dir --find-links https://wheel-index.linuxserver.io/alpine-3.16/ -r /requirements.txt && \
+ apk del --purge \
+ build-dependencies
diff --git a/.github/workflows/containers.yml b/.github/workflows/containers.yml
index fe2b078b..d079a699 100644
--- a/.github/workflows/containers.yml
+++ b/.github/workflows/containers.yml
@@ -2,16 +2,20 @@ name: Build and push containers
on:
# Automatically triggered by a testing workflow passing, but this is only checked when it lands in the `master`/default branch
- workflow_run:
- workflows: ["ChangeDetection.io Test"]
- branches: [master]
- tags: ['0.*']
- types: [completed]
+# workflow_run:
+# workflows: ["ChangeDetection.io Test"]
+# branches: [master]
+# tags: ['0.*']
+# types: [completed]
# Or a new tagged release
release:
types: [published, edited]
+ push:
+ branches:
+ - master
+
jobs:
metadata:
runs-on: ubuntu-latest
@@ -81,8 +85,8 @@ jobs:
version: latest
driver-opts: image=moby/buildkit:master
- # master always builds :latest
- - name: Build and push :latest
+ # master branch -> :dev container tag
+ - name: Build and push :dev
id: docker_build
if: ${{ github.ref }} == "refs/heads/master"
uses: docker/build-push-action@v2
@@ -91,13 +95,12 @@ jobs:
file: ./Dockerfile
push: true
tags: |
- ${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest
- ghcr.io/${{ github.repository }}:latest
+ ${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:dev,ghcr.io/${{ github.repository }}:dev
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
cache-from: type=local,src=/tmp/.buildx-cache
cache-to: type=local,dest=/tmp/.buildx-cache
- # A new tagged release is required, which builds :tag
+ # A new tagged release is required, which builds :tag and :latest
- name: Build and push :tag
id: docker_build_tag_release
if: github.event_name == 'release' && startsWith(github.event.release.tag_name, '0.')
@@ -109,6 +112,8 @@ jobs:
tags: |
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:${{ github.event.release.tag_name }}
ghcr.io/dgtlmoon/changedetection.io:${{ github.event.release.tag_name }}
+ ${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest
+ ghcr.io/dgtlmoon/changedetection.io:latest
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
cache-from: type=local,src=/tmp/.buildx-cache
cache-to: type=local,dest=/tmp/.buildx-cache
@@ -123,5 +128,3 @@ jobs:
key: ${{ runner.os }}-buildx-${{ github.sha }}
restore-keys: |
${{ runner.os }}-buildx-
-
-
diff --git a/.github/workflows/test-container-build.yml b/.github/workflows/test-container-build.yml
new file mode 100644
index 00000000..735b7205
--- /dev/null
+++ b/.github/workflows/test-container-build.yml
@@ -0,0 +1,66 @@
+name: ChangeDetection.io Container Build Test
+
+# Triggers the workflow on push or pull request events
+
+# This line doesnt work, even tho it is the documented one
+#on: [push, pull_request]
+
+on:
+ push:
+ paths:
+ - requirements.txt
+ - Dockerfile
+
+ pull_request:
+ paths:
+ - requirements.txt
+ - Dockerfile
+
+ # Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
+ # @todo: some kind of path filter for requirements.txt and Dockerfile
+jobs:
+ test-container-build:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.9
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.9
+
+ # Just test that the build works, some libraries won't compile on ARM/rPi etc
+ - name: Set up QEMU
+ uses: docker/setup-qemu-action@v1
+ with:
+ image: tonistiigi/binfmt:latest
+ platforms: all
+
+ - name: Set up Docker Buildx
+ id: buildx
+ uses: docker/setup-buildx-action@v1
+ with:
+ install: true
+ version: latest
+ driver-opts: image=moby/buildkit:master
+
+ # https://github.com/dgtlmoon/changedetection.io/pull/1067
+ # Check we can still build under alpine/musl
+ - name: Test that the docker containers can build (musl via alpine check)
+ id: docker_build_musl
+ uses: docker/build-push-action@v2
+ with:
+ context: ./
+ file: ./.github/test/Dockerfile-alpine
+ platforms: linux/amd64,linux/arm64
+
+ - name: Test that the docker containers can build
+ id: docker_build
+ uses: docker/build-push-action@v2
+ # https://github.com/docker/build-push-action#customizing
+ with:
+ context: ./
+ file: ./Dockerfile
+ platforms: linux/arm/v7,linux/arm/v6,linux/amd64,linux/arm64,
+ cache-from: type=local,src=/tmp/.buildx-cache
+ cache-to: type=local,dest=/tmp/.buildx-cache
+
diff --git a/.github/workflows/test-only.yml b/.github/workflows/test-only.yml
index 7543e9d8..aac97335 100644
--- a/.github/workflows/test-only.yml
+++ b/.github/workflows/test-only.yml
@@ -1,13 +1,12 @@
-name: ChangeDetection.io Test
+name: ChangeDetection.io App Test
# Triggers the workflow on push or pull request events
on: [push, pull_request]
jobs:
- test-build:
+ test-application:
runs-on: ubuntu-latest
steps:
-
- uses: actions/checkout@v2
- name: Set up Python 3.9
uses: actions/setup-python@v2
@@ -20,6 +19,7 @@ jobs:
pip install flake8 pytest
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
+
- name: Lint with flake8
run: |
# stop the build if there are Python syntax errors or undefined names
@@ -27,13 +27,13 @@ jobs:
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
+ - name: Unit tests
+ run: |
+ python3 -m unittest changedetectionio.tests.unit.test_notification_diff
+
- name: Test with pytest
run: |
# Each test is totally isolated and performs its own cleanup/reset
cd changedetectionio; ./run_all_tests.sh
- # https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
- # https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
-
- # https://github.com/docker/buildx/issues/495#issuecomment-918925854
diff --git a/.gitignore b/.gitignore
index 07a2a887..39fc0dd0 100644
--- a/.gitignore
+++ b/.gitignore
@@ -7,4 +7,8 @@ __pycache__
.pytest_cache
build
dist
+venv
+test-datastore/*
+test-datastore
+*.egg-info*
.vscode/settings.json
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 00000000..8478a7ab
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,15 @@
+Contributing is always welcome!
+
+I am no professional flask developer, if you know a better way that something can be done, please let me know!
+
+Otherwise, it's always best to PR into the `dev` branch.
+
+Please be sure that all new functionality has a matching test!
+
+Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notification.py` for example
+
+```
+pip3 install -r requirements-dev
+```
+
+this is from https://github.com/dgtlmoon/changedetection.io/blob/master/requirements-dev.txt
diff --git a/Dockerfile b/Dockerfile
index 4605d475..6b067afe 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -5,13 +5,15 @@ FROM python:3.8-slim as builder
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
RUN apt-get update && apt-get install -y --no-install-recommends \
- libssl-dev \
- libffi-dev \
+ g++ \
gcc \
libc-dev \
+ libffi-dev \
+ libjpeg-dev \
+ libssl-dev \
libxslt-dev \
- zlib1g-dev \
- g++
+ make \
+ zlib1g-dev
RUN mkdir /install
WORKDIR /install
@@ -20,6 +22,12 @@ COPY requirements.txt /requirements.txt
RUN pip install --target=/dependencies -r /requirements.txt
+# Playwright is an alternative to Selenium
+# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
+# https://github.com/dgtlmoon/changedetection.io/pull/1067 also musl/alpine (not supported)
+RUN pip install --target=/dependencies playwright~=1.27.1 \
+ || echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
+
# Final image stage
FROM python:3.8-slim
@@ -29,19 +37,23 @@ ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
# Re #93, #73, excluding rustc (adds another 430Mb~)
RUN apt-get update && apt-get install -y --no-install-recommends \
- libssl-dev \
- libffi-dev \
+ g++ \
gcc \
libc-dev \
+ libffi-dev \
+ libjpeg-dev \
+ libssl-dev \
libxslt-dev \
- zlib1g-dev \
- g++
+ zlib1g-dev
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
ENV PYTHONUNBUFFERED=1
RUN [ ! -d "/datastore" ] && mkdir /datastore
+# Re #80, sets SECLEVEL=1 in openssl.conf to allow monitoring sites with weak/old cipher suites
+RUN sed -i 's/^CipherString = .*/CipherString = DEFAULT@SECLEVEL=1/' /etc/ssl/openssl.cnf
+
# Copy modules over to the final image and add their dir to PYTHONPATH
COPY --from=builder /dependencies /usr/local
ENV PYTHONPATH=/usr/local
@@ -50,6 +62,7 @@ EXPOSE 5000
# The actual flask app
COPY changedetectionio /app/changedetectionio
+
# The eventlet server wrapper
COPY changedetection.py /app/changedetection.py
diff --git a/MANIFEST.in b/MANIFEST.in
index 16459b79..f6e723b5 100644
--- a/MANIFEST.in
+++ b/MANIFEST.in
@@ -1,6 +1,13 @@
+recursive-include changedetectionio/api *
recursive-include changedetectionio/templates *
recursive-include changedetectionio/static *
+recursive-include changedetectionio/model *
+recursive-include changedetectionio/tests *
+recursive-include changedetectionio/res *
+prune changedetectionio/static/package-lock.json
+prune changedetectionio/static/styles/node_modules
+prune changedetectionio/static/styles/package-lock.json
include changedetection.py
global-exclude *.pyc
-global-exclude *node_modules*
-global-exclude venv
\ No newline at end of file
+global-exclude node_modules
+global-exclude venv
diff --git a/Procfile b/Procfile
new file mode 100644
index 00000000..116f3f1a
--- /dev/null
+++ b/Procfile
@@ -0,0 +1 @@
+web: python3 ./changedetection.py -C -d ./datastore -p $PORT
diff --git a/README-pip.md b/README-pip.md
index d770ad09..b6a00d32 100644
--- a/README-pip.md
+++ b/README-pip.md
@@ -1,38 +1,48 @@
-# changedetection.io
-
-
-
-
-
-
-
+## Web Site Change Detection, Monitoring and Notification.
-## Self-hosted open source change monitoring of web pages.
+Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
-_Know when web pages change! Stay ontop of new information!_
-
-Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
+[](https://lemonade.changedetection.io/start?src=pip)
-
+[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://lemonade.changedetection.io/start)
+
#### Example use cases
-Know when ...
-
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
+
+#### Key Features
+
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
-**Get monitoring now!**
```bash
-$ pip3 install changedetection.io
+$ pip3 install changedetection.io
```
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
@@ -44,28 +54,5 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
-### Features
-- Website monitoring
-- Change detection of content and analyses
-- Filters on change (Select by CSS or JSON)
-- Triggers (Wait for text, wait for regex)
-- Notification support
-- JSON API Monitoring
-- Parse JSON embedded in HTML
-- (Reverse) Proxy support
-- Javascript support via WebDriver
-- RaspberriPi (arm v6/v7/64 support)
-
See https://github.com/dgtlmoon/changedetection.io for more information.
-
-
-### Support us
-
-Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-
-Please support us, even small amounts help a LOT.
-
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
-
-
diff --git a/README.md b/README.md
index 6939f4f1..03d734df 100644
--- a/README.md
+++ b/README.md
@@ -1,57 +1,105 @@
-# changedetection.io
+## Web Site Change Detection, Monitoring and Notification.
+
+_Live your data-life pro-actively, Detect website changes and perform meaningful actions, trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._
+
+
+[](https://lemonade.changedetection.io/start?src=github)
+
+[![Release Version][release-shield]][release-link] [![Docker Pulls][docker-pulls]][docker-link] [![License][license-shield]](LICENSE.md)
+

-
-
-
-
-
-
-## Self-hosted open source change monitoring of web pages.
+[**Don't have time? Let us host it for you! try our $6.99/month subscription - use our proxies and support!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
-_Know when web pages change! Stay ontop of new information!_
-
-Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
-
-Open source web page monitoring, notification and change detection.
+- Chrome browser included.
+- Super fast, no registration needed setup.
+- Get started watching and receiving website change notifications straight away.
-
+### Target specific parts of the webpage using the Visual Selector tool.
-#### Example use cases
+Available when connected to a playwright content fetcher (included as part of our subscription service)
-Know when ...
+[](https://lemonade.changedetection.io/start?src=github)
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+### Easily see what changed, examine by word, line, or individual character.
+
+[](https://lemonade.changedetection.io/start?src=github)
+
+
+### Perform interactive browser steps
+
+Fill in text boxes, click buttons and more, setup your changedetection scenario.
+
+Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
+
+[](https://lemonade.changedetection.io/start?src=github)
+
+After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
+Requires Playwright to be enabled.
+
+
+### Example use cases
+
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+- Get notified when certain keywords appear in Twitter search results
+- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
-_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver!_
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
-**Get monitoring now! super simple, one command!**
+#### Key Features
-Run the python code on your own machine by cloning this repository, or with docker and/or docker-compose
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
+- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
+- Send a screenshot with the notification when a change is detected in the web page
+
+We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
+
+Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
## Installation
### Docker
-_Note:_ We also use GitHub's container repository, because DockerHub has limited pull/downloads.
-
With Docker composer, just clone this repository and..
+
```bash
$ docker-compose up -d
```
+
Docker standalone
```bash
-$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
+`:latest` tag is our latest stable release, `:dev` tag is our bleeding edge `master` branch.
+
+### Windows
+
+See the install instructions at the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Microsoft-Windows
+
### Python Pip
Check out our pypi page https://pypi.org/project/changedetection.io/
@@ -69,10 +117,10 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
### Docker
```
-docker pull ghcr.io/dgtlmoon/changedetection.io
-docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+docker pull dgtlmoon/changedetection.io
+docker kill $(docker ps -a -f name=changedetection.io -q)
+docker rm $(docker ps -a -f name=changedetection.io -q)
+docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
### docker-compose
@@ -81,15 +129,15 @@ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/dat
docker-compose pull && docker-compose up -d
```
-## Screenshots
+See the wiki for more information https://github.com/dgtlmoon/changedetection.io/wiki
-Examining differences in content.
-
+## Filters
-Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
+XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
+(We support LXML `re:test`, `re:math` and `re:replace`.)
-### Notifications
+## Notifications
ChangeDetection.io supports a massive amount of notifications (including email, office365, custom APIs, etc) when a web-page has a change detected thanks to the apprise library.
Simply set one or more notification URL's in the _[edit]_ tab of that watch.
@@ -107,25 +155,33 @@ Just some examples
json://someserver.com/custom-api
syslog://
-And everything else in this list!
+And everything else in this list!
-
+
Now you can also customise your notification content and use Jinja2 templating for their title and body!
-### JSON API Monitoring
+## JSON API Monitoring
-Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
+Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
-
+
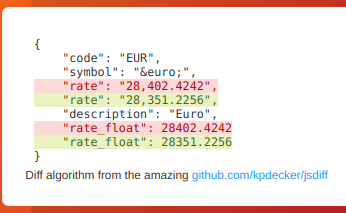
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
-
+
-#### Parse JSON embedded in HTML!
+### JSONPath or jq?
-When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
+For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specifc information on jq.
+
+One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
+
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
+
+### Parse JSON embedded in HTML!
+
+When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
```
@@ -135,42 +191,39 @@ When you enable a `json:` filter, you can even automatically extract and parse e
```
-`json:$.price` would give `23.50`, or you can extract the whole structure
+`json:$.price` or `jq:.price` would give `23.50`, or you can extract the whole structure
-### Proxy
+## Proxy Configuration
-A proxy for ChangeDetection.io can be configured by setting environment the
-`HTTP_PROXY`, `HTTPS_PROXY` variables, examples are also in the `docker-compose.yml`
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [BrightData proxy services where possible]( https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support)
-`NO_PROXY` exclude list can be specified by following `"localhost,192.168.0.0/24"`
+## Raspberry Pi support?
-as `docker run` with `-e`
-
-```
-docker run -d --restart always -e HTTPS_PROXY="socks5h://10.10.1.10:1080" -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
-```
-
-With `docker-compose`, see the `Proxy support example` in docker-compose.yml.
-
-For more information see https://docs.python-requests.org/en/master/user/advanced/#proxies
-
-This proxy support also extends to the notifications https://github.com/caronc/apprise/issues/387#issuecomment-841718867
+Raspberry Pi and linux/arm/v6 linux/arm/v7 arm64 devices are supported! See the wiki for [details](https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver)
-### RaspberriPi support?
-
-RaspberriPi and linux/arm/v6 linux/arm/v7 arm64 devices are supported!
-
-### Windows native support?
-
-Sorry not yet :( https://github.com/dgtlmoon/changedetection.io/labels/windows
-
-### Support us
+## Support us
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-Please support us, even small amounts help a LOT.
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
+Firstly, consider taking out a [change detection monthly subscription - unlimited checks and watches](https://lemonade.changedetection.io/start) , even if you don't use it, you still get the warm fuzzy feeling of helping out the project. (And who knows, you might just use it!)
-
+Or directly donate an amount PayPal [](https://www.paypal.com/donate/?hosted_button_id=7CP6HR9ZCNDYJ)
+
+Or BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
+
+
+
+## Commercial Support
+
+I offer commercial support, this software is depended on by network security, aerospace , data-science and data-journalist professionals just to name a few, please reach out at dgtlmoon@gmail.com for any enquiries, I am more than glad to work with your organisation to further the possibilities of what can be done with changedetection.io
+
+
+[release-shield]: https://img.shields.io:/github/v/release/dgtlmoon/changedetection.io?style=for-the-badge
+[docker-pulls]: https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io?style=for-the-badge
+[test-shield]: https://github.com/dgtlmoon/changedetection.io/actions/workflows/test-only.yml/badge.svg?branch=master
+
+[license-shield]: https://img.shields.io/github/license/dgtlmoon/changedetection.io.svg?style=for-the-badge
+[release-link]: https://github.com/dgtlmoon.com/changedetection.io/releases
+[docker-link]: https://hub.docker.com/r/dgtlmoon/changedetection.io
diff --git a/app.json b/app.json
new file mode 100644
index 00000000..a9249e88
--- /dev/null
+++ b/app.json
@@ -0,0 +1,21 @@
+{
+ "name": "ChangeDetection.io",
+ "description": "The best and simplest self-hosted open source website change detection monitoring and notification service.",
+ "keywords": [
+ "changedetection",
+ "website monitoring"
+ ],
+ "repository": "https://github.com/dgtlmoon/changedetection.io",
+ "success_url": "/",
+ "scripts": {
+ },
+ "env": {
+ },
+ "formation": {
+ "web": {
+ "quantity": 1,
+ "size": "free"
+ }
+ },
+ "image": "heroku/python"
+}
diff --git a/changedetection.py b/changedetection.py
index 5814f8fe..8455315a 100755
--- a/changedetection.py
+++ b/changedetection.py
@@ -1,97 +1,41 @@
#!/usr/bin/python3
-# Launch as a eventlet.wsgi server instance.
+# Entry-point for running from the CLI when not installed via Pip, Pip will handle the console_scripts entry_points's from setup.py
+# It's recommended to use `pip3 install changedetection.io` and start with `changedetection.py` instead, it will be linkd to your global path.
+# or Docker.
+# Read more https://github.com/dgtlmoon/changedetection.io/wiki
-import getopt
+from changedetectionio import changedetection
+import multiprocessing
+import signal
import os
-import sys
-import eventlet
-import eventlet.wsgi
-import changedetectionio
+def sigchld_handler(_signo, _stack_frame):
+ import sys
+ print('Shutdown: Got SIGCHLD')
+ # https://stackoverflow.com/questions/40453496/python-multiprocessing-capturing-signals-to-restart-child-processes-or-shut-do
+ pid, status = os.waitpid(-1, os.WNOHANG | os.WUNTRACED | os.WCONTINUED)
-from changedetectionio import store
-
-def main():
- ssl_mode = False
- port = os.environ.get('PORT') or 5000
- do_cleanup = False
-
- # Must be absolute so that send_from_directory doesnt try to make it relative to backend/
- datastore_path = os.path.join(os.getcwd(), "datastore")
-
- try:
- opts, args = getopt.getopt(sys.argv[1:], "csd:p:", "port")
- except getopt.GetoptError:
- print('backend.py -s SSL enable -p [port] -d [datastore path]')
- sys.exit(2)
-
- for opt, arg in opts:
- # if opt == '--purge':
- # Remove history, the actual files you need to delete manually.
- # for uuid, watch in datastore.data['watching'].items():
- # watch.update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': None})
-
- if opt == '-s':
- ssl_mode = True
-
- if opt == '-p':
- port = int(arg)
-
- if opt == '-d':
- datastore_path = arg
-
- # Cleanup (remove text files that arent in the index)
- if opt == '-c':
- do_cleanup = True
-
- # isnt there some @thingy to attach to each route to tell it, that this route needs a datastore
- app_config = {'datastore_path': datastore_path}
-
- if not os.path.isdir(app_config['datastore_path']):
- print ("ERROR: Directory path for the datastore '{}' does not exist, cannot start, please make sure the directory exists.\n"
- "Alternatively, use the -d parameter.".format(app_config['datastore_path']),file=sys.stderr)
- sys.exit(2)
-
- datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=changedetectionio.__version__)
- app = changedetectionio.changedetection_app(app_config, datastore)
-
- # Go into cleanup mode
- if do_cleanup:
- datastore.remove_unused_snapshots()
-
- app.config['datastore_path'] = datastore_path
-
-
- @app.context_processor
- def inject_version():
- return dict(right_sticky="v{}".format(datastore.data['version_tag']),
- new_version_available=app.config['NEW_VERSION_AVAILABLE'],
- has_password=datastore.data['settings']['application']['password'] != False
- )
-
- # Proxy sub-directory support
- # Set environment var USE_X_SETTINGS=1 on this script
- # And then in your proxy_pass settings
- #
- # proxy_set_header Host "localhost";
- # proxy_set_header X-Forwarded-Prefix /app;
-
- if os.getenv('USE_X_SETTINGS'):
- print ("USE_X_SETTINGS is ENABLED\n")
- from werkzeug.middleware.proxy_fix import ProxyFix
- app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
-
- if ssl_mode:
- # @todo finalise SSL config, but this should get you in the right direction if you need it.
- eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen(('', port)),
- certfile='cert.pem',
- keyfile='privkey.pem',
- server_side=True), app)
-
- else:
- eventlet.wsgi.server(eventlet.listen(('', int(port))), app)
+ print('Sub-process: pid %d status %d' % (pid, status))
+ if status != 0:
+ sys.exit(1)
+ raise SystemExit
if __name__ == '__main__':
- main()
+
+ #signal.signal(signal.SIGCHLD, sigchld_handler)
+
+ # The only way I could find to get Flask to shutdown, is to wrap it and then rely on the subsystem issuing SIGTERM/SIGKILL
+ parse_process = multiprocessing.Process(target=changedetection.main)
+ parse_process.daemon = True
+ parse_process.start()
+ import time
+
+ try:
+ while True:
+ time.sleep(1)
+
+ except KeyboardInterrupt:
+ #parse_process.terminate() not needed, because this process will issue it to the sub-process anyway
+ print ("Exited - CTRL+C")
diff --git a/changedetectionio/.gitignore b/changedetectionio/.gitignore
new file mode 100644
index 00000000..0d3c1d4e
--- /dev/null
+++ b/changedetectionio/.gitignore
@@ -0,0 +1,2 @@
+test-datastore
+package-lock.json
diff --git a/changedetectionio/__init__.py b/changedetectionio/__init__.py
index 1704ae1e..5d22a280 100644
--- a/changedetectionio/__init__.py
+++ b/changedetectionio/__init__.py
@@ -1,36 +1,41 @@
#!/usr/bin/python3
-
-# @todo logging
-# @todo extra options for url like , verify=False etc.
-# @todo enable https://urllib3.readthedocs.io/en/latest/user-guide.html#ssl as option?
-# @todo option for interval day/6 hour/etc
-# @todo on change detected, config for calling some API
-# @todo fetch title into json
-# https://distill.io/features
-# proxy per check
-# - flask_cors, itsdangerous,MarkupSafe
-
-import time
-import os
-import timeago
+import datetime
import flask_login
-from flask_login import login_required
-
+import logging
+import os
+import pytz
+import queue
import threading
+import time
+import timeago
+
+from copy import deepcopy
+from distutils.util import strtobool
+from feedgen.feed import FeedGenerator
from threading import Event
-import queue
+from flask import (
+ Flask,
+ abort,
+ flash,
+ make_response,
+ redirect,
+ render_template,
+ request,
+ send_from_directory,
+ session,
+ url_for,
+)
+from flask_compress import Compress as FlaskCompress
+from flask_login import login_required
+from flask_restful import abort, Api
+from flask_wtf import CSRFProtect
-from flask import Flask, render_template, request, send_from_directory, abort, redirect, url_for, flash
+from changedetectionio import html_tools
+from changedetectionio.api import api_v1
-from feedgen.feed import FeedGenerator
-from flask import make_response
-import datetime
-import pytz
-from copy import deepcopy
-
-__version__ = '0.39.3'
+__version__ = '0.39.22.1'
datastore = None
@@ -40,15 +45,17 @@ ticker_thread = None
extra_stylesheets = []
-update_q = queue.Queue()
-
+update_q = queue.PriorityQueue()
notification_q = queue.Queue()
-# Needs to be set this way because we also build and publish via pip
-base_path = os.path.dirname(os.path.realpath(__file__))
app = Flask(__name__,
- static_url_path="{}/static".format(base_path),
- template_folder="{}/templates".format(base_path))
+ static_url_path="",
+ static_folder="static",
+ template_folder="templates")
+from flask_compress import Compress
+
+# Super handy for compressing large BrowserSteps responses and others
+FlaskCompress(app)
# Stop browser caching of assets
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 0
@@ -63,7 +70,13 @@ app.config['LOGIN_DISABLED'] = False
# Disables caching of the templates
app.config['TEMPLATES_AUTO_RELOAD'] = True
+app.jinja_env.add_extension('jinja2.ext.loopcontrols')
+csrf = CSRFProtect()
+csrf.init_app(app)
+notification_debug_log=[]
+
+watch_api = Api(app, decorators=[csrf.exempt])
def init_app_secret(datastore_path):
secret = ""
@@ -82,16 +95,6 @@ def init_app_secret(datastore_path):
return secret
-# Remember python is by reference
-# populate_form in wtfors didnt work for me. (try using a setattr() obj type on datastore.watch?)
-def populate_form_from_watch(form, watch):
- for i in form.__dict__.keys():
- if i[0] != '_':
- p = getattr(form, i)
- if hasattr(p, 'data') and i in watch:
- setattr(p, "data", watch[i])
-
-
# We use the whole watch object from the store/JSON so we can see if there's some related status in terms of a thread
# running or something similar.
@app.template_filter('format_last_checked_time')
@@ -99,27 +102,28 @@ def _jinja2_filter_datetime(watch_obj, format="%Y-%m-%d %H:%M:%S"):
# Worker thread tells us which UUID it is currently processing.
for t in running_update_threads:
if t.current_uuid == watch_obj['uuid']:
- return "Checking now.."
+ return ' Checking now'
if watch_obj['last_checked'] == 0:
return 'Not yet'
return timeago.format(int(watch_obj['last_checked']), time.time())
-
-# @app.context_processor
-# def timeago():
-# def _timeago(lower_time, now):
-# return timeago.format(lower_time, now)
-# return dict(timeago=_timeago)
-
@app.template_filter('format_timestamp_timeago')
def _jinja2_filter_datetimestamp(timestamp, format="%Y-%m-%d %H:%M:%S"):
+ if timestamp == False:
+ return 'Not yet'
+
return timeago.format(timestamp, time.time())
- # return timeago.format(timestamp, time.time())
- # return datetime.datetime.utcfromtimestamp(timestamp).strftime(format)
+@app.template_filter('format_seconds_ago')
+def _jinja2_filter_seconds_precise(timestamp):
+ if timestamp == False:
+ return 'Not yet'
+ return format(int(time.time()-timestamp), ',d')
+
+# When nobody is logged in Flask-Login's current_user is set to an AnonymousUser object.
class User(flask_login.UserMixin):
id=None
@@ -128,7 +132,6 @@ class User(flask_login.UserMixin):
def get_user(self, email="defaultuser@changedetection.io"):
return self
def is_authenticated(self):
-
return True
def is_active(self):
return True
@@ -137,13 +140,21 @@ class User(flask_login.UserMixin):
def get_id(self):
return str(self.id)
+ # Compare given password against JSON store or Env var
def check_password(self, password):
- import hashlib
import base64
+ import hashlib
+
+ # Can be stored in env (for deployments) or in the general configs
+ raw_salt_pass = os.getenv("SALTED_PASS", False)
+
+ if not raw_salt_pass:
+ raw_salt_pass = datastore.data['settings']['application']['password']
+
+ raw_salt_pass = base64.b64decode(raw_salt_pass)
+
- # Getting the values back out
- raw_salt_pass = base64.b64decode(datastore.data['settings']['application']['password'])
salt_from_storage = raw_salt_pass[:32] # 32 is the length of the salt
# Use the exact same setup you used to generate the key, but this time put in the password to check
@@ -163,12 +174,36 @@ def changedetection_app(config=None, datastore_o=None):
global datastore
datastore = datastore_o
+ # so far just for read-only via tests, but this will be moved eventually to be the main source
+ # (instead of the global var)
+ app.config['DATASTORE']=datastore_o
+
#app.config.update(config or {})
login_manager = flask_login.LoginManager(app)
login_manager.login_view = 'login'
app.secret_key = init_app_secret(config['datastore_path'])
+
+ watch_api.add_resource(api_v1.WatchSingleHistory,
+ '/api/v1/watch//history/',
+ resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
+
+ watch_api.add_resource(api_v1.WatchHistory,
+ '/api/v1/watch//history',
+ resource_class_kwargs={'datastore': datastore})
+
+ watch_api.add_resource(api_v1.CreateWatch, '/api/v1/watch',
+ resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
+
+ watch_api.add_resource(api_v1.Watch, '/api/v1/watch/',
+ resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
+
+ watch_api.add_resource(api_v1.SystemInfo, '/api/v1/systeminfo',
+ resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
+
+
+
# Setup cors headers to allow all domains
# https://flask-cors.readthedocs.io/en/latest/
# CORS(app)
@@ -194,11 +229,15 @@ def changedetection_app(config=None, datastore_o=None):
@app.route('/login', methods=['GET', 'POST'])
def login():
- if not datastore.data['settings']['application']['password']:
+ if not datastore.data['settings']['application']['password'] and not os.getenv("SALTED_PASS", False):
flash("Login not required, no password enabled.", "notice")
return redirect(url_for('index'))
if request.method == 'GET':
+ if flask_login.current_user.is_authenticated:
+ flash("Already logged in")
+ return redirect(url_for("index"))
+
output = render_template("login.html")
return output
@@ -209,10 +248,18 @@ def changedetection_app(config=None, datastore_o=None):
if (user.check_password(password)):
flask_login.login_user(user, remember=True)
- next = request.args.get('next')
+
+ # For now there's nothing else interesting here other than the index/list page
+ # It's more reliable and safe to ignore the 'next' redirect
+ # When we used...
+ # next = request.args.get('next')
+ # return redirect(next or url_for('index'))
+ # We would sometimes get login loop errors on sites hosted in sub-paths
+
+ # note for the future:
# if not is_safe_url(next):
# return flask.abort(400)
- return redirect(next or url_for('index'))
+ return redirect(url_for('index'))
else:
flash('Incorrect password', 'error')
@@ -221,27 +268,33 @@ def changedetection_app(config=None, datastore_o=None):
@app.before_request
def do_something_whenever_a_request_comes_in():
- # Disable password loginif there is not one set
- app.config['LOGIN_DISABLED'] = datastore.data['settings']['application']['password'] == False
- @app.route("/", methods=['GET'])
+ # Disable password login if there is not one set
+ # (No password in settings or env var)
+ app.config['LOGIN_DISABLED'] = datastore.data['settings']['application']['password'] == False and os.getenv("SALTED_PASS", False) == False
+
+ # Set the auth cookie path if we're running as X-settings/X-Forwarded-Prefix
+ if os.getenv('USE_X_SETTINGS') and 'X-Forwarded-Prefix' in request.headers:
+ app.config['REMEMBER_COOKIE_PATH'] = request.headers['X-Forwarded-Prefix']
+ app.config['SESSION_COOKIE_PATH'] = request.headers['X-Forwarded-Prefix']
+
+ # For the RSS path, allow access via a token
+ if request.path == '/rss' and request.args.get('token'):
+ app_rss_token = datastore.data['settings']['application']['rss_access_token']
+ rss_url_token = request.args.get('token')
+ if app_rss_token == rss_url_token:
+ app.config['LOGIN_DISABLED'] = True
+
+ @app.route("/rss", methods=['GET'])
@login_required
- def index():
+ def rss():
+ from . import diff
limit_tag = request.args.get('tag')
- pause_uuid = request.args.get('pause')
-
- if pause_uuid:
- try:
- datastore.data['watching'][pause_uuid]['paused'] ^= True
- datastore.needs_write = True
-
- return redirect(url_for('index', tag = limit_tag))
- except KeyError:
- pass
-
# Sort by last_changed and add the uuid which is usually the key..
sorted_watches = []
+
+ # @todo needs a .itemsWithTag() or something - then we can use that in Jinaj2 and throw this away
for uuid, watch in datastore.data['watching'].items():
if limit_tag != None:
@@ -256,94 +309,183 @@ def changedetection_app(config=None, datastore_o=None):
watch['uuid'] = uuid
sorted_watches.append(watch)
- sorted_watches.sort(key=lambda x: x['last_changed'], reverse=True)
+ sorted_watches.sort(key=lambda x: x.last_changed, reverse=False)
+
+ fg = FeedGenerator()
+ fg.title('changedetection.io')
+ fg.description('Feed description')
+ fg.link(href='https://changedetection.io')
+
+ for watch in sorted_watches:
+
+ dates = list(watch.history.keys())
+ # Re #521 - Don't bother processing this one if theres less than 2 snapshots, means we never had a change detected.
+ if len(dates) < 2:
+ continue
+
+ prev_fname = watch.history[dates[-2]]
+
+ if not watch.viewed:
+ # Re #239 - GUID needs to be individual for each event
+ # @todo In the future make this a configurable link back (see work on BASE_URL https://github.com/dgtlmoon/changedetection.io/pull/228)
+ guid = "{}/{}".format(watch['uuid'], watch.last_changed)
+ fe = fg.add_entry()
+
+ # Include a link to the diff page, they will have to login here to see if password protection is enabled.
+ # Description is the page you watch, link takes you to the diff JS UI page
+ base_url = datastore.data['settings']['application']['base_url']
+ if base_url == '':
+ base_url = ""
+
+ diff_link = {'href': "{}{}".format(base_url, url_for('diff_history_page', uuid=watch['uuid']))}
+
+ fe.link(link=diff_link)
+
+ # @todo watch should be a getter - watch.get('title') (internally if URL else..)
+
+ watch_title = watch.get('title') if watch.get('title') else watch.get('url')
+ fe.title(title=watch_title)
+ latest_fname = watch.history[dates[-1]]
+
+ html_diff = diff.render_diff(prev_fname, latest_fname, include_equal=False, line_feed_sep="")
+ fe.content(content="
{}
{}".format(watch_title, html_diff),
+ type='CDATA')
+
+ fe.guid(guid, permalink=False)
+ dt = datetime.datetime.fromtimestamp(int(watch.newest_history_key))
+ dt = dt.replace(tzinfo=pytz.UTC)
+ fe.pubDate(dt)
+
+ response = make_response(fg.rss_str())
+ response.headers.set('Content-Type', 'application/rss+xml;charset=utf-8')
+ return response
+
+ @app.route("/", methods=['GET'])
+ @login_required
+ def index():
+ from changedetectionio import forms
+
+ limit_tag = request.args.get('tag')
+ # Redirect for the old rss path which used the /?rss=true
+ if request.args.get('rss'):
+ return redirect(url_for('rss', tag=limit_tag))
+
+ op = request.args.get('op')
+ if op:
+ uuid = request.args.get('uuid')
+ if op == 'pause':
+ datastore.data['watching'][uuid]['paused'] ^= True
+ elif op == 'mute':
+ datastore.data['watching'][uuid]['notification_muted'] ^= True
+
+ datastore.needs_write = True
+ return redirect(url_for('index', tag = limit_tag))
+
+ # Sort by last_changed and add the uuid which is usually the key..
+ sorted_watches = []
+ for uuid, watch in datastore.data['watching'].items():
+
+ if limit_tag != None:
+ # Support for comma separated list of tags.
+ if watch['tag'] is None:
+ continue
+ for tag_in_watch in watch['tag'].split(','):
+ tag_in_watch = tag_in_watch.strip()
+ if tag_in_watch == limit_tag:
+ watch['uuid'] = uuid
+ sorted_watches.append(watch)
+
+ else:
+ watch['uuid'] = uuid
+ sorted_watches.append(watch)
existing_tags = datastore.get_all_tags()
- rss = request.args.get('rss')
- if rss:
- fg = FeedGenerator()
- fg.title('changedetection.io')
- fg.description('Feed description')
- fg.link(href='https://changedetection.io')
+ form = forms.quickWatchForm(request.form)
+ output = render_template("watch-overview.html",
+ form=form,
+ watches=sorted_watches,
+ tags=existing_tags,
+ active_tag=limit_tag,
+ app_rss_token=datastore.data['settings']['application']['rss_access_token'],
+ has_unviewed=datastore.has_unviewed,
+ # Don't link to hosting when we're on the hosting environment
+ hosted_sticky=os.getenv("SALTED_PASS", False) == False,
+ guid=datastore.data['app_guid'],
+ queued_uuids=[uuid for p,uuid in update_q.queue])
- for watch in sorted_watches:
- if not watch['viewed']:
- # Re #239 - GUID needs to be individual for each event
- # @todo In the future make this a configurable link back (see work on BASE_URL https://github.com/dgtlmoon/changedetection.io/pull/228)
- guid = "{}/{}".format(watch['uuid'], watch['last_changed'])
- fe = fg.add_entry()
- fe.title(watch['url'])
- fe.link(href=watch['url'])
- fe.description(watch['url'])
- fe.guid(guid, permalink=False)
- dt = datetime.datetime.fromtimestamp(int(watch['newest_history_key']))
- dt = dt.replace(tzinfo=pytz.UTC)
- fe.pubDate(dt)
-
- response = make_response(fg.rss_str())
- response.headers.set('Content-Type', 'application/rss+xml')
- return response
-
- else:
- from changedetectionio import forms
- form = forms.quickWatchForm(request.form)
-
- output = render_template("watch-overview.html",
- form=form,
- watches=sorted_watches,
- tags=existing_tags,
- active_tag=limit_tag,
- has_unviewed=datastore.data['has_unviewed'])
+ if session.get('share-link'):
+ del(session['share-link'])
return output
- @app.route("/scrub", methods=['GET', 'POST'])
- @login_required
- def scrub_page():
- import re
+ # AJAX endpoint for sending a test
+ @app.route("/notification/send-test", methods=['POST'])
+ @login_required
+ def ajax_callback_send_notification_test():
+
+ import apprise
+ from .apprise_asset import asset
+ apobj = apprise.Apprise(asset=asset)
+
+
+ # validate URLS
+ if not len(request.form['notification_urls'].strip()):
+ return make_response({'error': 'No Notification URLs set'}, 400)
+
+ for server_url in request.form['notification_urls'].splitlines():
+ if len(server_url.strip()):
+ if not apobj.add(server_url):
+ message = '{} is not a valid AppRise URL.'.format(server_url)
+ return make_response({'error': message}, 400)
+
+ try:
+ n_object = {'watch_url': request.form['window_url'],
+ 'notification_urls': request.form['notification_urls'].splitlines(),
+ 'notification_title': request.form['notification_title'].strip(),
+ 'notification_body': request.form['notification_body'].strip(),
+ 'notification_format': request.form['notification_format'].strip()
+ }
+ notification_q.put(n_object)
+ except Exception as e:
+ return make_response({'error': str(e)}, 400)
+
+ return 'OK'
+
+
+ @app.route("/clear_history/", methods=['GET'])
+ @login_required
+ def clear_watch_history(uuid):
+ try:
+ datastore.clear_watch_history(uuid)
+ except KeyError:
+ flash('Watch not found', 'error')
+ else:
+ flash("Cleared snapshot history for watch {}".format(uuid))
+
+ return redirect(url_for('index'))
+
+ @app.route("/clear_history", methods=['GET', 'POST'])
+ @login_required
+ def clear_all_history():
if request.method == 'POST':
confirmtext = request.form.get('confirmtext')
- limit_date = request.form.get('limit_date')
- limit_timestamp = 0
- # Re #149 - allow empty/0 timestamp limit
- if len(limit_date):
- try:
- limit_date = limit_date.replace('T', ' ')
- # I noticed chrome will show '/' but actually submit '-'
- limit_date = limit_date.replace('-', '/')
- # In the case that :ss seconds are supplied
- limit_date = re.sub('(\d\d:\d\d)(:\d\d)', '\\1', limit_date)
-
- str_to_dt = datetime.datetime.strptime(limit_date, '%Y/%m/%d %H:%M')
- limit_timestamp = int(str_to_dt.timestamp())
-
- if limit_timestamp > time.time():
- flash("Timestamp is in the future, cannot continue.", 'error')
- return redirect(url_for('scrub_page'))
-
- except ValueError:
- flash('Incorrect date format, cannot continue.', 'error')
- return redirect(url_for('scrub_page'))
-
- if confirmtext == 'scrub':
+ if confirmtext == 'clear':
changes_removed = 0
- for uuid, watch in datastore.data['watching'].items():
- if limit_timestamp:
- changes_removed += datastore.scrub_watch(uuid, limit_timestamp=limit_timestamp)
- else:
- changes_removed += datastore.scrub_watch(uuid)
+ for uuid in datastore.data['watching'].keys():
+ datastore.clear_watch_history(uuid)
+ #TODO: KeyError not checked, as it is above
- flash("Cleared snapshot history ({} snapshots removed)".format(changes_removed))
+ flash("Cleared snapshot history for all watches")
else:
flash('Incorrect confirmation text.', 'error')
return redirect(url_for('index'))
- output = render_template("scrub.html")
+ output = render_template("clear_all_history.html")
return output
@@ -352,25 +494,30 @@ def changedetection_app(config=None, datastore_o=None):
def get_current_checksum_include_ignore_text(uuid):
import hashlib
+
from changedetectionio import fetch_site_status
# Get the most recent one
- newest_history_key = datastore.get_val(uuid, 'newest_history_key')
+ newest_history_key = datastore.data['watching'][uuid].get('newest_history_key')
- # 0 means that theres only one, so that there should be no 'unviewed' history availabe
+ # 0 means that theres only one, so that there should be no 'unviewed' history available
if newest_history_key == 0:
- newest_history_key = list(datastore.data['watching'][uuid]['history'].keys())[0]
+ newest_history_key = list(datastore.data['watching'][uuid].history.keys())[0]
if newest_history_key:
- with open(datastore.data['watching'][uuid]['history'][newest_history_key],
+ with open(datastore.data['watching'][uuid].history[newest_history_key],
encoding='utf-8') as file:
raw_content = file.read()
handler = fetch_site_status.perform_site_check(datastore=datastore)
- stripped_content = handler.strip_ignore_text(raw_content,
+ stripped_content = html_tools.strip_ignore_text(raw_content,
datastore.data['watching'][uuid]['ignore_text'])
- checksum = hashlib.md5(stripped_content).hexdigest()
+ if datastore.data['settings']['application'].get('ignore_whitespace', False):
+ checksum = hashlib.md5(stripped_content.translate(None, b'\r\n\t ')).hexdigest()
+ else:
+ checksum = hashlib.md5(stripped_content).hexdigest()
+
return checksum
return datastore.data['watching'][uuid]['previous_md5']
@@ -378,105 +525,153 @@ def changedetection_app(config=None, datastore_o=None):
@app.route("/edit/", methods=['GET', 'POST'])
@login_required
+ # https://stackoverflow.com/questions/42984453/wtforms-populate-form-with-data-if-data-exists
+ # https://wtforms.readthedocs.io/en/3.0.x/forms/#wtforms.form.Form.populate_obj ?
+
def edit_page(uuid):
from changedetectionio import forms
- form = forms.watchForm(request.form)
+ from changedetectionio.blueprint.browser_steps.browser_steps import browser_step_ui_config
+ using_default_check_time = True
# More for testing, possible to return the first/only
+ if not datastore.data['watching'].keys():
+ flash("No watches to edit", "error")
+ return redirect(url_for('index'))
+
if uuid == 'first':
uuid = list(datastore.data['watching'].keys()).pop()
+ if not uuid in datastore.data['watching']:
+ flash("No watch with the UUID %s found." % (uuid), "error")
+ return redirect(url_for('index'))
- if request.method == 'GET':
- if not uuid in datastore.data['watching']:
- flash("No watch with the UUID %s found." % (uuid), "error")
- return redirect(url_for('index'))
+ # be sure we update with a copy instead of accidently editing the live object by reference
+ default = deepcopy(datastore.data['watching'][uuid])
- populate_form_from_watch(form, datastore.data['watching'][uuid])
+ # Show system wide default if nothing configured
+ if all(value == 0 or value == None for value in datastore.data['watching'][uuid]['time_between_check'].values()):
+ default['time_between_check'] = deepcopy(datastore.data['settings']['requests']['time_between_check'])
+
+ # Defaults for proxy choice
+ if datastore.proxy_list is not None: # When enabled
+ # @todo
+ # Radio needs '' not None, or incase that the chosen one no longer exists
+ if default['proxy'] is None or not any(default['proxy'] in tup for tup in datastore.proxy_list):
+ default['proxy'] = ''
+
+ # proxy_override set to the json/text list of the items
+ form = forms.watchForm(formdata=request.form if request.method == 'POST' else None,
+ data=default,
+ )
+
+ # form.browser_steps[0] can be assumed that we 'goto url' first
+
+ if datastore.proxy_list is None:
+ # @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
+ del form.proxy
+ else:
+ form.proxy.choices = [('', 'Default')]
+ for p in datastore.proxy_list:
+ form.proxy.choices.append(tuple((p, datastore.proxy_list[p]['label'])))
- if datastore.data['watching'][uuid]['fetch_backend'] is None:
- form.fetch_backend.data = datastore.data['settings']['application']['fetch_backend']
if request.method == 'POST' and form.validate():
+ extra_update_obj = {}
+
+ if request.args.get('unpause_on_save'):
+ extra_update_obj['paused'] = False
# Re #110, if they submit the same as the default value, set it to None, so we continue to follow the default
- if form.minutes_between_check.data == datastore.data['settings']['requests']['minutes_between_check']:
- form.minutes_between_check.data = None
+ # Assume we use the default value, unless something relevant is different, then use the form value
+ # values could be None, 0 etc.
+ # Set to None unless the next for: says that something is different
+ extra_update_obj['time_between_check'] = dict.fromkeys(form.time_between_check.data)
+ for k, v in form.time_between_check.data.items():
+ if v and v != datastore.data['settings']['requests']['time_between_check'][k]:
+ extra_update_obj['time_between_check'] = form.time_between_check.data
+ using_default_check_time = False
+ break
+ # Use the default if its the same as system wide
if form.fetch_backend.data == datastore.data['settings']['application']['fetch_backend']:
- form.fetch_backend.data = None
+ extra_update_obj['fetch_backend'] = None
- update_obj = {'url': form.url.data.strip(),
- 'minutes_between_check': form.minutes_between_check.data,
- 'tag': form.tag.data.strip(),
- 'title': form.title.data.strip(),
- 'headers': form.headers.data,
- 'fetch_backend': form.fetch_backend.data,
- 'trigger_text': form.trigger_text.data,
- 'notification_title': form.notification_title.data,
- 'notification_body': form.notification_body.data,
- 'extract_title_as_title': form.extract_title_as_title.data
- }
-
- # Notification URLs
- datastore.data['watching'][uuid]['notification_urls'] = form.notification_urls.data
-
- # Ignore text
+ # Ignore text
form_ignore_text = form.ignore_text.data
datastore.data['watching'][uuid]['ignore_text'] = form_ignore_text
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
if form_ignore_text:
- if len(datastore.data['watching'][uuid]['history']):
- update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
-
-
- datastore.data['watching'][uuid]['css_filter'] = form.css_filter.data.strip()
+ if len(datastore.data['watching'][uuid].history):
+ extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
- if form.css_filter.data.strip() != datastore.data['watching'][uuid]['css_filter']:
- if len(datastore.data['watching'][uuid]['history']):
- update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
+ if form.include_filters.data != datastore.data['watching'][uuid].get('include_filters', []):
+ if len(datastore.data['watching'][uuid].history):
+ extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
- datastore.data['watching'][uuid].update(update_obj)
+ # Be sure proxy value is None
+ if datastore.proxy_list is not None and form.data['proxy'] == '':
+ extra_update_obj['proxy'] = None
- flash("Updated watch.")
+ datastore.data['watching'][uuid].update(form.data)
+ datastore.data['watching'][uuid].update(extra_update_obj)
- # Queue the watch for immediate recheck
- update_q.put(uuid)
+ if request.args.get('unpause_on_save'):
+ flash("Updated watch - unpaused!.")
+ else:
+ flash("Updated watch.")
- if form.trigger_check.data:
- n_object = {'watch_url': form.url.data.strip(),
- 'notification_urls': form.notification_urls.data,
- 'notification_title': form.notification_title.data,
- 'notification_body' : form.notification_body.data
- }
- notification_q.put(n_object)
+ # Re #286 - We wait for syncing new data to disk in another thread every 60 seconds
+ # But in the case something is added we should save straight away
+ datastore.needs_write_urgent = True
- flash('Notifications queued.')
+ # Queue the watch for immediate recheck, with a higher priority
+ update_q.put((1, uuid))
# Diff page [edit] link should go back to diff page
if request.args.get("next") and request.args.get("next") == 'diff':
return redirect(url_for('diff_history_page', uuid=uuid))
- else:
- return redirect(url_for('index'))
+
+ return redirect(url_for('index'))
else:
if request.method == 'POST' and not form.validate():
flash("An error occurred, please see below.", "error")
- # Re #110 offer the default minutes
- using_default_minutes = False
- if form.minutes_between_check.data == None:
- form.minutes_between_check.data = datastore.data['settings']['requests']['minutes_between_check']
- using_default_minutes = True
+ visualselector_data_is_ready = datastore.visualselector_data_is_ready(uuid)
+
+ # Only works reliably with Playwright
+ visualselector_enabled = os.getenv('PLAYWRIGHT_DRIVER_URL', False) and default['fetch_backend'] == 'html_webdriver'
+
+ # JQ is difficult to install on windows and must be manually added (outside requirements.txt)
+ jq_support = True
+ try:
+ import jq
+ except ModuleNotFoundError:
+ jq_support = False
+
+ watch = datastore.data['watching'].get(uuid)
+ system_uses_webdriver = datastore.data['settings']['application']['fetch_backend'] == 'html_webdriver'
+ is_html_webdriver = True if watch.get('fetch_backend') == 'html_webdriver' or (
+ watch.get('fetch_backend', None) is None and system_uses_webdriver) else False
output = render_template("edit.html",
- uuid=uuid,
- watch=datastore.data['watching'][uuid],
+ browser_steps_config=browser_step_ui_config,
+ current_base_url=datastore.data['settings']['application']['base_url'],
+ emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False),
form=form,
- using_default_minutes=using_default_minutes
+ has_default_notification_urls=True if len(datastore.data['settings']['application']['notification_urls']) else False,
+ has_empty_checktime=using_default_check_time,
+ is_html_webdriver=is_html_webdriver,
+ jq_support=jq_support,
+ playwright_enabled=os.getenv('PLAYWRIGHT_DRIVER_URL', False),
+ settings_application=datastore.data['settings']['application'],
+ using_global_webdriver_wait=default['webdriver_delay'] is None,
+ uuid=uuid,
+ visualselector_enabled=visualselector_enabled,
+ watch=watch
)
return output
@@ -484,108 +679,129 @@ def changedetection_app(config=None, datastore_o=None):
@app.route("/settings", methods=['GET', "POST"])
@login_required
def settings_page():
+ from changedetectionio import content_fetcher, forms
- from changedetectionio import forms
- from changedetectionio import content_fetcher
+ default = deepcopy(datastore.data['settings'])
+ if datastore.proxy_list is not None:
+ available_proxies = list(datastore.proxy_list.keys())
+ # When enabled
+ system_proxy = datastore.data['settings']['requests']['proxy']
+ # In the case it doesnt exist anymore
+ if not system_proxy in available_proxies:
+ system_proxy = None
- form = forms.globalSettingsForm(request.form)
+ default['requests']['proxy'] = system_proxy if system_proxy is not None else available_proxies[0]
+ # Used by the form handler to keep or remove the proxy settings
+ default['proxy_list'] = available_proxies[0]
- if request.method == 'GET':
- form.minutes_between_check.data = int(datastore.data['settings']['requests']['minutes_between_check'])
- form.notification_urls.data = datastore.data['settings']['application']['notification_urls']
- form.extract_title_as_title.data = datastore.data['settings']['application']['extract_title_as_title']
- form.fetch_backend.data = datastore.data['settings']['application']['fetch_backend']
- form.notification_title.data = datastore.data['settings']['application']['notification_title']
- form.notification_body.data = datastore.data['settings']['application']['notification_body']
- form.base_url.data = datastore.data['settings']['application']['base_url']
- # Password unset is a GET
- if request.values.get('removepassword') == 'yes':
- from pathlib import Path
- datastore.data['settings']['application']['password'] = False
- flash("Password protection removed.", 'notice')
- flask_login.logout_user()
- return redirect(url_for('settings_page'))
+ # Don't use form.data on POST so that it doesnt overrid the checkbox status from the POST status
+ form = forms.globalSettingsForm(formdata=request.form if request.method == 'POST' else None,
+ data=default
+ )
- if request.method == 'POST' and form.validate():
+ # Remove the last option 'System default'
+ form.application.form.notification_format.choices.pop()
- datastore.data['settings']['application']['notification_urls'] = form.notification_urls.data
- datastore.data['settings']['requests']['minutes_between_check'] = form.minutes_between_check.data
- datastore.data['settings']['application']['extract_title_as_title'] = form.extract_title_as_title.data
- datastore.data['settings']['application']['fetch_backend'] = form.fetch_backend.data
- datastore.data['settings']['application']['notification_title'] = form.notification_title.data
- datastore.data['settings']['application']['notification_body'] = form.notification_body.data
- datastore.data['settings']['application']['notification_urls'] = form.notification_urls.data
- datastore.data['settings']['application']['base_url'] = form.base_url.data
+ if datastore.proxy_list is None:
+ # @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
+ del form.requests.form.proxy
+ else:
+ form.requests.form.proxy.choices = []
+ for p in datastore.proxy_list:
+ form.requests.form.proxy.choices.append(tuple((p, datastore.proxy_list[p]['label'])))
- if form.trigger_check.data and len(form.notification_urls.data):
- n_object = {'watch_url': "Test from changedetection.io!",
- 'notification_urls': form.notification_urls.data,
- 'notification_title': form.notification_title.data,
- 'notification_body': form.notification_body.data
- }
- notification_q.put(n_object)
- flash('Notifications queued.')
- if form.password.encrypted_password:
- datastore.data['settings']['application']['password'] = form.password.encrypted_password
- flash("Password protection enabled.", 'notice')
- flask_login.logout_user()
- return redirect(url_for('index'))
+ if request.method == 'POST':
+ # Password unset is a GET, but we can lock the session to a salted env password to always need the password
+ if form.application.form.data.get('removepassword_button', False):
+ # SALTED_PASS means the password is "locked" to what we set in the Env var
+ if not os.getenv("SALTED_PASS", False):
+ datastore.remove_password()
+ flash("Password protection removed.", 'notice')
+ flask_login.logout_user()
+ return redirect(url_for('settings_page'))
- datastore.needs_write = True
- flash("Settings updated.")
+ if form.validate():
+ # Don't set password to False when a password is set - should be only removed with the `removepassword` button
+ app_update = dict(deepcopy(form.data['application']))
- if request.method == 'POST' and not form.validate():
- flash("An error occurred, please see below.", "error")
+ # Never update password with '' or False (Added by wtforms when not in submission)
+ if 'password' in app_update and not app_update['password']:
+ del (app_update['password'])
- output = render_template("settings.html", form=form)
+ datastore.data['settings']['application'].update(app_update)
+ datastore.data['settings']['requests'].update(form.data['requests'])
+
+ if not os.getenv("SALTED_PASS", False) and len(form.application.form.password.encrypted_password):
+ datastore.data['settings']['application']['password'] = form.application.form.password.encrypted_password
+ datastore.needs_write_urgent = True
+ flash("Password protection enabled.", 'notice')
+ flask_login.logout_user()
+ return redirect(url_for('index'))
+
+ datastore.needs_write_urgent = True
+ flash("Settings updated.")
+
+ else:
+ flash("An error occurred, please see below.", "error")
+
+ output = render_template("settings.html",
+ form=form,
+ current_base_url = datastore.data['settings']['application']['base_url'],
+ hide_remove_pass=os.getenv("SALTED_PASS", False),
+ api_key=datastore.data['settings']['application'].get('api_access_token'),
+ emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False),
+ settings_application=datastore.data['settings']['application'])
return output
@app.route("/import", methods=['GET', "POST"])
@login_required
def import_page():
- import validators
remaining_urls = []
-
- good = 0
-
if request.method == 'POST':
- urls = request.values.get('urls').split("\n")
- for url in urls:
- url = url.strip()
- if len(url) and validators.url(url):
- new_uuid = datastore.add_watch(url=url.strip(), tag="")
- # Straight into the queue.
- update_q.put(new_uuid)
- good += 1
+ from .importer import import_url_list, import_distill_io_json
+
+ # URL List import
+ if request.values.get('urls') and len(request.values.get('urls').strip()):
+ # Import and push into the queue for immediate update check
+ importer = import_url_list()
+ importer.run(data=request.values.get('urls'), flash=flash, datastore=datastore)
+ for uuid in importer.new_uuids:
+ update_q.put((1, uuid))
+
+ if len(importer.remaining_data) == 0:
+ return redirect(url_for('index'))
else:
- if len(url):
- remaining_urls.append(url)
+ remaining_urls = importer.remaining_data
+
+ # Distill.io import
+ if request.values.get('distill-io') and len(request.values.get('distill-io').strip()):
+ # Import and push into the queue for immediate update check
+ d_importer = import_distill_io_json()
+ d_importer.run(data=request.values.get('distill-io'), flash=flash, datastore=datastore)
+ for uuid in d_importer.new_uuids:
+ update_q.put((1, uuid))
- flash("{} Imported, {} Skipped.".format(good, len(remaining_urls)))
- if len(remaining_urls) == 0:
- # Looking good, redirect to index.
- return redirect(url_for('index'))
# Could be some remaining, or we could be on GET
output = render_template("import.html",
- remaining="\n".join(remaining_urls)
+ import_url_list_remaining="\n".join(remaining_urls),
+ original_distill_json=''
)
return output
# Clear all statuses, so we do not see the 'unviewed' class
- @app.route("/api/mark-all-viewed", methods=['GET'])
+ @app.route("/form/mark-all-viewed", methods=['GET'])
@login_required
def mark_all_viewed():
# Save the current newest history as the most recently viewed
for watch_uuid, watch in datastore.data['watching'].items():
- datastore.set_last_viewed(watch_uuid, watch['newest_history_key'])
+ datastore.set_last_viewed(watch_uuid, int(time.time()))
- flash("Cleared all statuses.")
return redirect(url_for('index'))
@app.route("/diff/", methods=['GET'])
@@ -603,79 +819,170 @@ def changedetection_app(config=None, datastore_o=None):
flash("No history found for the specified link, bad link?", "error")
return redirect(url_for('index'))
- dates = list(watch['history'].keys())
- # Convert to int, sort and back to str again
- dates = [int(i) for i in dates]
- dates.sort(reverse=True)
- dates = [str(i) for i in dates]
+ history = watch.history
+ dates = list(history.keys())
if len(dates) < 2:
flash("Not enough saved change detection snapshots to produce a report.", "error")
return redirect(url_for('index'))
# Save the current newest history as the most recently viewed
- datastore.set_last_viewed(uuid, dates[0])
+ datastore.set_last_viewed(uuid, time.time())
- newest_file = watch['history'][dates[0]]
- with open(newest_file, 'r') as f:
- newest_version_file_contents = f.read()
+ newest_file = history[dates[-1]]
+
+ # Read as binary and force decode as UTF-8
+ # Windows may fail decode in python if we just use 'r' mode (chardet decode exception)
+ try:
+ with open(newest_file, 'r', encoding='utf-8', errors='ignore') as f:
+ newest_version_file_contents = f.read()
+ except Exception as e:
+ newest_version_file_contents = "Unable to read {}.\n".format(newest_file)
previous_version = request.args.get('previous_version')
-
try:
- previous_file = watch['history'][previous_version]
+ previous_file = history[previous_version]
except KeyError:
# Not present, use a default value, the second one in the sorted list.
- previous_file = watch['history'][dates[1]]
+ previous_file = history[dates[-2]]
- with open(previous_file, 'r') as f:
- previous_version_file_contents = f.read()
+ try:
+ with open(previous_file, 'r', encoding='utf-8', errors='ignore') as f:
+ previous_version_file_contents = f.read()
+ except Exception as e:
+ previous_version_file_contents = "Unable to read {}.\n".format(previous_file)
- output = render_template("diff.html", watch_a=watch,
+
+ screenshot_url = watch.get_screenshot()
+
+ system_uses_webdriver = datastore.data['settings']['application']['fetch_backend'] == 'html_webdriver'
+
+ is_html_webdriver = True if watch.get('fetch_backend') == 'html_webdriver' or (
+ watch.get('fetch_backend', None) is None and system_uses_webdriver) else False
+
+ output = render_template("diff.html",
+ watch_a=watch,
newest=newest_version_file_contents,
previous=previous_version_file_contents,
extra_stylesheets=extra_stylesheets,
- versions=dates[1:],
+ versions=dates[:-1], # All except current/last
uuid=uuid,
- newest_version_timestamp=dates[0],
+ newest_version_timestamp=dates[-1],
current_previous_version=str(previous_version),
current_diff_url=watch['url'],
extra_title=" - Diff - {}".format(watch['title'] if watch['title'] else watch['url']),
- left_sticky= True )
+ left_sticky=True,
+ screenshot=screenshot_url,
+ is_html_webdriver=is_html_webdriver,
+ last_error=watch['last_error'],
+ last_error_text=watch.get_error_text(),
+ last_error_screenshot=watch.get_error_snapshot()
+ )
return output
@app.route("/preview/", methods=['GET'])
@login_required
def preview_page(uuid):
+ content = []
+ ignored_line_numbers = []
+ trigger_line_numbers = []
# More for testing, possible to return the first/only
if uuid == 'first':
uuid = list(datastore.data['watching'].keys()).pop()
- extra_stylesheets = [url_for('static_content', group='styles', filename='diff.css')]
-
try:
watch = datastore.data['watching'][uuid]
except KeyError:
flash("No history found for the specified link, bad link?", "error")
return redirect(url_for('index'))
- newest = list(watch['history'].keys())[-1]
- with open(watch['history'][newest], 'r') as f:
- content = f.readlines()
+ system_uses_webdriver = datastore.data['settings']['application']['fetch_backend'] == 'html_webdriver'
+ extra_stylesheets = [url_for('static_content', group='styles', filename='diff.css')]
+
+
+ is_html_webdriver = True if watch.get('fetch_backend') == 'html_webdriver' or (
+ watch.get('fetch_backend', None) is None and system_uses_webdriver) else False
+
+ # Never requested successfully, but we detected a fetch error
+ if datastore.data['watching'][uuid].history_n == 0 and (watch.get_error_text() or watch.get_error_snapshot()):
+ flash("Preview unavailable - No fetch/check completed or triggers not reached", "error")
+ output = render_template("preview.html",
+ content=content,
+ history_n=watch.history_n,
+ extra_stylesheets=extra_stylesheets,
+# current_diff_url=watch['url'],
+ watch=watch,
+ uuid=uuid,
+ is_html_webdriver=is_html_webdriver,
+ last_error=watch['last_error'],
+ last_error_text=watch.get_error_text(),
+ last_error_screenshot=watch.get_error_snapshot())
+ return output
+
+ timestamp = list(watch.history.keys())[-1]
+ filename = watch.history[timestamp]
+ try:
+ with open(filename, 'r', encoding='utf-8', errors='ignore') as f:
+ tmp = f.readlines()
+
+ # Get what needs to be highlighted
+ ignore_rules = watch.get('ignore_text', []) + datastore.data['settings']['application']['global_ignore_text']
+
+ # .readlines will keep the \n, but we will parse it here again, in the future tidy this up
+ ignored_line_numbers = html_tools.strip_ignore_text(content="".join(tmp),
+ wordlist=ignore_rules,
+ mode='line numbers'
+ )
+
+ trigger_line_numbers = html_tools.strip_ignore_text(content="".join(tmp),
+ wordlist=watch['trigger_text'],
+ mode='line numbers'
+ )
+ # Prepare the classes and lines used in the template
+ i=0
+ for l in tmp:
+ classes=[]
+ i+=1
+ if i in ignored_line_numbers:
+ classes.append('ignored')
+ if i in trigger_line_numbers:
+ classes.append('triggered')
+ content.append({'line': l, 'classes': ' '.join(classes)})
+
+ except Exception as e:
+ content.append({'line': "File doesnt exist or unable to read file {}".format(filename), 'classes': ''})
output = render_template("preview.html",
content=content,
+ history_n=watch.history_n,
extra_stylesheets=extra_stylesheets,
+ ignored_line_numbers=ignored_line_numbers,
+ triggered_line_numbers=trigger_line_numbers,
current_diff_url=watch['url'],
- uuid=uuid)
+ screenshot=watch.get_screenshot(),
+ watch=watch,
+ uuid=uuid,
+ is_html_webdriver=is_html_webdriver,
+ last_error=watch['last_error'],
+ last_error_text=watch.get_error_text(),
+ last_error_screenshot=watch.get_error_snapshot())
+
return output
+ @app.route("/settings/notification-logs", methods=['GET'])
+ @login_required
+ def notification_logs():
+ global notification_debug_log
+ output = render_template("notification-log.html",
+ logs=notification_debug_log if len(notification_debug_log) else ["Notification logs are empty - no notifications sent yet."])
+
+ return output
@app.route("/favicon.ico", methods=['GET'])
def favicon():
- return send_from_directory("/app/static/images", filename="favicon.ico")
+ return send_from_directory("static/images", path="favicon.ico")
# We're good but backups are even better!
@app.route("/backup", methods=['GET'])
@@ -686,15 +993,13 @@ def changedetection_app(config=None, datastore_o=None):
from pathlib import Path
# Remove any existing backup file, for now we just keep one file
- for previous_backup_filename in Path(app.config['datastore_path']).rglob('changedetection-backup-*.zip'):
+
+ for previous_backup_filename in Path(datastore_o.datastore_path).rglob('changedetection-backup-*.zip'):
os.unlink(previous_backup_filename)
# create a ZipFile object
backupname = "changedetection-backup-{}.zip".format(int(time.time()))
-
- # We only care about UUIDS from the current index file
- uuids = list(datastore.data['watching'].keys())
- backup_filepath = os.path.join(app.config['datastore_path'], backupname)
+ backup_filepath = os.path.join(datastore_o.datastore_path, backupname)
with zipfile.ZipFile(backup_filepath, "w",
compression=zipfile.ZIP_DEFLATED,
@@ -704,72 +1009,146 @@ def changedetection_app(config=None, datastore_o=None):
datastore.sync_to_json()
# Add the index
- zipObj.write(os.path.join(app.config['datastore_path'], "url-watches.json"), arcname="url-watches.json")
+ zipObj.write(os.path.join(datastore_o.datastore_path, "url-watches.json"), arcname="url-watches.json")
# Add the flask app secret
- zipObj.write(os.path.join(app.config['datastore_path'], "secret.txt"), arcname="secret.txt")
+ zipObj.write(os.path.join(datastore_o.datastore_path, "secret.txt"), arcname="secret.txt")
- # Add any snapshot data we find, use the full path to access the file, but make the file 'relative' in the Zip.
- for txt_file_path in Path(app.config['datastore_path']).rglob('*.txt'):
- parent_p = txt_file_path.parent
- if parent_p.name in uuids:
- zipObj.write(txt_file_path,
- arcname=str(txt_file_path).replace(app.config['datastore_path'], ''),
+ # Add any data in the watch data directory.
+ for uuid, w in datastore.data['watching'].items():
+ for f in Path(w.watch_data_dir).glob('*'):
+ zipObj.write(f,
+ # Use the full path to access the file, but make the file 'relative' in the Zip.
+ arcname=os.path.join(f.parts[-2], f.parts[-1]),
compress_type=zipfile.ZIP_DEFLATED,
compresslevel=8)
# Create a list file with just the URLs, so it's easier to port somewhere else in the future
- list_file = os.path.join(app.config['datastore_path'], "url-list.txt")
- with open(list_file, "w") as f:
- for uuid in datastore.data['watching']:
- url = datastore.data['watching'][uuid]['url']
+ list_file = "url-list.txt"
+ with open(os.path.join(datastore_o.datastore_path, list_file), "w") as f:
+ for uuid in datastore.data["watching"]:
+ url = datastore.data["watching"][uuid]["url"]
f.write("{}\r\n".format(url))
+ list_with_tags_file = "url-list-with-tags.txt"
+ with open(
+ os.path.join(datastore_o.datastore_path, list_with_tags_file), "w"
+ ) as f:
+ for uuid in datastore.data["watching"]:
+ url = datastore.data["watching"][uuid]["url"]
+ tag = datastore.data["watching"][uuid]["tag"]
+ f.write("{} {}\r\n".format(url, tag))
# Add it to the Zip
- zipObj.write(list_file,
- arcname="url-list.txt",
- compress_type=zipfile.ZIP_DEFLATED,
- compresslevel=8)
+ zipObj.write(
+ os.path.join(datastore_o.datastore_path, list_file),
+ arcname=list_file,
+ compress_type=zipfile.ZIP_DEFLATED,
+ compresslevel=8,
+ )
+ zipObj.write(
+ os.path.join(datastore_o.datastore_path, list_with_tags_file),
+ arcname=list_with_tags_file,
+ compress_type=zipfile.ZIP_DEFLATED,
+ compresslevel=8,
+ )
- return send_from_directory(app.config['datastore_path'], backupname, as_attachment=True)
+ # Send_from_directory needs to be the full absolute path
+ return send_from_directory(os.path.abspath(datastore_o.datastore_path), backupname, as_attachment=True)
@app.route("/static//", methods=['GET'])
def static_content(group, filename):
+ from flask import make_response
+
+ if group == 'screenshot':
+ # Could be sensitive, follow password requirements
+ if datastore.data['settings']['application']['password'] and not flask_login.current_user.is_authenticated:
+ abort(403)
+
+ screenshot_filename = "last-screenshot.png" if not request.args.get('error_screenshot') else "last-error-screenshot.png"
+
+ # These files should be in our subdirectory
+ try:
+ # set nocache, set content-type
+ response = make_response(send_from_directory(os.path.join(datastore_o.datastore_path, filename), screenshot_filename))
+ response.headers['Content-type'] = 'image/png'
+ response.headers['Cache-Control'] = 'no-cache, no-store, must-revalidate'
+ response.headers['Pragma'] = 'no-cache'
+ response.headers['Expires'] = 0
+ return response
+
+ except FileNotFoundError:
+ abort(404)
+
+
+ if group == 'visual_selector_data':
+ # Could be sensitive, follow password requirements
+ if datastore.data['settings']['application']['password'] and not flask_login.current_user.is_authenticated:
+ abort(403)
+
+ # These files should be in our subdirectory
+ try:
+ # set nocache, set content-type
+ watch_dir = datastore_o.datastore_path + "/" + filename
+ response = make_response(send_from_directory(filename="elements.json", directory=watch_dir, path=watch_dir + "/elements.json"))
+ response.headers['Content-type'] = 'application/json'
+ response.headers['Cache-Control'] = 'no-cache, no-store, must-revalidate'
+ response.headers['Pragma'] = 'no-cache'
+ response.headers['Expires'] = 0
+ return response
+
+ except FileNotFoundError:
+ abort(404)
+
# These files should be in our subdirectory
try:
- return send_from_directory("static/{}".format(group), filename=filename)
+ return send_from_directory("static/{}".format(group), path=filename)
except FileNotFoundError:
abort(404)
- @app.route("/api/add", methods=['POST'])
+ @app.route("/form/add/quickwatch", methods=['POST'])
@login_required
- def api_watch_add():
+ def form_quick_watch_add():
from changedetectionio import forms
form = forms.quickWatchForm(request.form)
- if form.validate():
-
- url = request.form.get('url').strip()
- if datastore.url_exists(url):
- flash('The URL {} already exists'.format(url), "error")
- return redirect(url_for('index'))
-
- # @todo add_watch should throw a custom Exception for validation etc
- new_uuid = datastore.add_watch(url=url, tag=request.form.get('tag').strip())
- # Straight into the queue.
- update_q.put(new_uuid)
-
- flash("Watch added.")
- return redirect(url_for('index'))
- else:
+ if not form.validate():
flash("Error")
return redirect(url_for('index'))
+ url = request.form.get('url').strip()
+ if datastore.url_exists(url):
+ flash('The URL {} already exists'.format(url), "error")
+ return redirect(url_for('index'))
+
+ add_paused = request.form.get('edit_and_watch_submit_button') != None
+ new_uuid = datastore.add_watch(url=url, tag=request.form.get('tag').strip(), extras={'paused': add_paused})
+
+
+ if not add_paused and new_uuid:
+ # Straight into the queue.
+ update_q.put((1, new_uuid))
+ flash("Watch added.")
+
+ if add_paused:
+ flash('Watch added in Paused state, saving will unpause.')
+ return redirect(url_for('edit_page', uuid=new_uuid, unpause_on_save=1))
+
+ return redirect(url_for('index'))
+
+
+
@app.route("/api/delete", methods=['GET'])
@login_required
- def api_delete():
-
+ def form_delete():
uuid = request.args.get('uuid')
+
+ if uuid != 'all' and not uuid in datastore.data['watching'].keys():
+ flash('The watch by UUID {} does not exist.'.format(uuid), 'error')
+ return redirect(url_for('index'))
+
+ # More for testing, possible to return the first/only
+ if uuid == 'first':
+ uuid = list(datastore.data['watching'].keys()).pop()
datastore.delete(uuid)
flash('Deleted.')
@@ -777,17 +1156,21 @@ def changedetection_app(config=None, datastore_o=None):
@app.route("/api/clone", methods=['GET'])
@login_required
- def api_clone():
+ def form_clone():
uuid = request.args.get('uuid')
+ # More for testing, possible to return the first/only
+ if uuid == 'first':
+ uuid = list(datastore.data['watching'].keys()).pop()
+
new_uuid = datastore.clone(uuid)
- update_q.put(new_uuid)
+ update_q.put((5, new_uuid))
flash('Cloned.')
return redirect(url_for('index'))
@app.route("/api/checknow", methods=['GET'])
@login_required
- def api_watch_checknow():
+ def form_watch_checknow():
tag = request.args.get('tag')
uuid = request.args.get('uuid')
@@ -801,7 +1184,7 @@ def changedetection_app(config=None, datastore_o=None):
if uuid:
if uuid not in running_uuids:
- update_q.put(uuid)
+ update_q.put((1, uuid))
i = 1
elif tag != None:
@@ -809,33 +1192,146 @@ def changedetection_app(config=None, datastore_o=None):
for watch_uuid, watch in datastore.data['watching'].items():
if (tag != None and tag in watch['tag']):
if watch_uuid not in running_uuids and not datastore.data['watching'][watch_uuid]['paused']:
- update_q.put(watch_uuid)
+ update_q.put((1, watch_uuid))
i += 1
else:
# No tag, no uuid, add everything.
for watch_uuid, watch in datastore.data['watching'].items():
-
if watch_uuid not in running_uuids and not datastore.data['watching'][watch_uuid]['paused']:
- update_q.put(watch_uuid)
+ update_q.put((1, watch_uuid))
i += 1
- flash("{} watches are rechecking.".format(i))
+ flash("{} watches are queued for rechecking.".format(i))
return redirect(url_for('index', tag=tag))
+ @app.route("/form/checkbox-operations", methods=['POST'])
+ @login_required
+ def form_watch_list_checkbox_operations():
+ op = request.form['op']
+ uuids = request.form.getlist('uuids')
+
+ if (op == 'delete'):
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.delete(uuid.strip())
+ flash("{} watches deleted".format(len(uuids)))
+
+ elif (op == 'pause'):
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.data['watching'][uuid.strip()]['paused'] = True
+
+ flash("{} watches paused".format(len(uuids)))
+
+ elif (op == 'unpause'):
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.data['watching'][uuid.strip()]['paused'] = False
+ flash("{} watches unpaused".format(len(uuids)))
+
+ elif (op == 'mute'):
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.data['watching'][uuid.strip()]['notification_muted'] = True
+ flash("{} watches muted".format(len(uuids)))
+
+ elif (op == 'unmute'):
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.data['watching'][uuid.strip()]['notification_muted'] = False
+ flash("{} watches un-muted".format(len(uuids)))
+
+ elif (op == 'notification-default'):
+ from changedetectionio.notification import (
+ default_notification_format_for_watch
+ )
+ for uuid in uuids:
+ uuid = uuid.strip()
+ if datastore.data['watching'].get(uuid):
+ datastore.data['watching'][uuid.strip()]['notification_title'] = None
+ datastore.data['watching'][uuid.strip()]['notification_body'] = None
+ datastore.data['watching'][uuid.strip()]['notification_urls'] = []
+ datastore.data['watching'][uuid.strip()]['notification_format'] = default_notification_format_for_watch
+ flash("{} watches set to use default notification settings".format(len(uuids)))
+
+ return redirect(url_for('index'))
+
+ @app.route("/api/share-url", methods=['GET'])
+ @login_required
+ def form_share_put_watch():
+ """Given a watch UUID, upload the info and return a share-link
+ the share-link can be imported/added"""
+ import requests
+ import json
+ tag = request.args.get('tag')
+ uuid = request.args.get('uuid')
+
+ # more for testing
+ if uuid == 'first':
+ uuid = list(datastore.data['watching'].keys()).pop()
+
+ # copy it to memory as trim off what we dont need (history)
+ watch = deepcopy(datastore.data['watching'][uuid])
+ # For older versions that are not a @property
+ if (watch.get('history')):
+ del (watch['history'])
+
+ # for safety/privacy
+ for k in list(watch.keys()):
+ if k.startswith('notification_'):
+ del watch[k]
+
+ for r in['uuid', 'last_checked', 'last_changed']:
+ if watch.get(r):
+ del (watch[r])
+
+ # Add the global stuff which may have an impact
+ watch['ignore_text'] += datastore.data['settings']['application']['global_ignore_text']
+ watch['subtractive_selectors'] += datastore.data['settings']['application']['global_subtractive_selectors']
+
+ watch_json = json.dumps(watch)
+
+ try:
+ r = requests.request(method="POST",
+ data={'watch': watch_json},
+ url="https://changedetection.io/share/share",
+ headers={'App-Guid': datastore.data['app_guid']})
+ res = r.json()
+
+ session['share-link'] = "https://changedetection.io/share/{}".format(res['share_key'])
+
+
+ except Exception as e:
+ logging.error("Error sharing -{}".format(str(e)))
+ flash("Could not share, something went wrong while communicating with the share server - {}".format(str(e)), 'error')
+
+ # https://changedetection.io/share/VrMv05wpXyQa
+ # in the browser - should give you a nice info page - wtf
+ # paste in etc
+ return redirect(url_for('index'))
+
+ import changedetectionio.blueprint.browser_steps as browser_steps
+ app.register_blueprint(browser_steps.construct_blueprint(datastore), url_prefix='/browser-steps')
+
# @todo handle ctrl break
ticker_thread = threading.Thread(target=ticker_thread_check_time_launch_checks).start()
-
threading.Thread(target=notification_runner).start()
- # Check for new release version
- threading.Thread(target=check_for_new_version).start()
+ # Check for new release version, but not when running in test/build or pytest
+ if not os.getenv("GITHUB_REF", False) and not config.get('disable_checkver') == True:
+ threading.Thread(target=check_for_new_version).start()
+
return app
# Check for new version and anonymous stats
def check_for_new_version():
import requests
-
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
@@ -861,6 +1357,9 @@ def check_for_new_version():
app.config.exit.wait(86400)
def notification_runner():
+ global notification_debug_log
+ from datetime import datetime
+ import json
while not app.config.exit.is_set():
try:
# At the moment only one thread runs (single runner)
@@ -869,22 +1368,45 @@ def notification_runner():
time.sleep(1)
else:
- # Process notifications
+
+ now = datetime.now()
+ sent_obj = None
+
try:
from changedetectionio import notification
- notification.process_notification(n_object, datastore)
+
+ sent_obj = notification.process_notification(n_object, datastore)
except Exception as e:
- print("Watch URL: {} Error {}".format(n_object['watch_url'], e))
+ logging.error("Watch URL: {} Error {}".format(n_object['watch_url'], str(e)))
+ # UUID wont be present when we submit a 'test' from the global settings
+ if 'uuid' in n_object:
+ datastore.update_watch(uuid=n_object['uuid'],
+ update_obj={'last_notification_error': "Notification error detected, goto notification log."})
+ log_lines = str(e).splitlines()
+ notification_debug_log += log_lines
+
+ # Process notifications
+ notification_debug_log+= ["{} - SENDING - {}".format(now.strftime("%Y/%m/%d %H:%M:%S,000"), json.dumps(sent_obj))]
+ # Trim the log length
+ notification_debug_log = notification_debug_log[-100:]
# Thread runner to check every minute, look for new watches to feed into the Queue.
def ticker_thread_check_time_launch_checks():
+ import random
from changedetectionio import update_worker
- # Spin up Workers.
- for _ in range(datastore.data['settings']['requests']['workers']):
+ proxy_last_called_time = {}
+
+ recheck_time_minimum_seconds = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 20))
+ print("System env MINIMUM_SECONDS_RECHECK_TIME", recheck_time_minimum_seconds)
+
+ # Spin up Workers that do the fetching
+ # Can be overriden by ENV or use the default settings
+ n_workers = int(os.getenv("FETCH_WORKERS", datastore.data['settings']['requests']['workers']))
+ for _ in range(n_workers):
new_worker = update_worker.update_worker(update_q, notification_q, app, datastore)
running_update_threads.append(new_worker)
new_worker.start()
@@ -898,27 +1420,88 @@ def ticker_thread_check_time_launch_checks():
running_uuids.append(t.current_uuid)
# Re #232 - Deepcopy the data incase it changes while we're iterating through it all
- copied_datastore = deepcopy(datastore)
+ watch_uuid_list = []
+ while True:
+ try:
+ watch_uuid_list = datastore.data['watching'].keys()
+ except RuntimeError as e:
+ # RuntimeError: dictionary changed size during iteration
+ time.sleep(0.1)
+ else:
+ break
+
+ # Re #438 - Don't place more watches in the queue to be checked if the queue is already large
+ while update_q.qsize() >= 2000:
+ time.sleep(1)
+
+
+ recheck_time_system_seconds = int(datastore.threshold_seconds)
# Check for watches outside of the time threshold to put in the thread queue.
- for uuid, watch in copied_datastore.data['watching'].items():
+ for uuid in watch_uuid_list:
+ now = time.time()
+ watch = datastore.data['watching'].get(uuid)
+ if not watch:
+ logging.error("Watch: {} no longer present.".format(uuid))
+ continue
+
+ # No need todo further processing if it's paused
+ if watch['paused']:
+ continue
+
# If they supplied an individual entry minutes to threshold.
- if 'minutes_between_check' in watch and watch['minutes_between_check'] is not None:
- # Cast to int just incase
- max_time = int(watch['minutes_between_check']) * 60
- else:
- # Default system wide.
- max_time = int(copied_datastore.data['settings']['requests']['minutes_between_check']) * 60
- threshold = time.time() - max_time
+ watch_threshold_seconds = watch.threshold_seconds()
+ threshold = watch_threshold_seconds if watch_threshold_seconds > 0 else recheck_time_system_seconds
- # Yeah, put it in the queue, it's more than time.
- if not watch['paused'] and watch['last_checked'] <= threshold:
- if not uuid in running_uuids and uuid not in update_q.queue:
- update_q.put(uuid)
+ # #580 - Jitter plus/minus amount of time to make the check seem more random to the server
+ jitter = datastore.data['settings']['requests'].get('jitter_seconds', 0)
+ if jitter > 0:
+ if watch.jitter_seconds == 0:
+ watch.jitter_seconds = random.uniform(-abs(jitter), jitter)
- # Wait a few seconds before checking the list again
- time.sleep(3)
+ seconds_since_last_recheck = now - watch['last_checked']
+
+ if seconds_since_last_recheck >= (threshold + watch.jitter_seconds) and seconds_since_last_recheck >= recheck_time_minimum_seconds:
+ if not uuid in running_uuids and uuid not in [q_uuid for p,q_uuid in update_q.queue]:
+
+ # Proxies can be set to have a limit on seconds between which they can be called
+ watch_proxy = datastore.get_preferred_proxy_for_watch(uuid=uuid)
+ if watch_proxy and watch_proxy in list(datastore.proxy_list.keys()):
+ # Proxy may also have some threshold minimum
+ proxy_list_reuse_time_minimum = int(datastore.proxy_list.get(watch_proxy, {}).get('reuse_time_minimum', 0))
+ if proxy_list_reuse_time_minimum:
+ proxy_last_used_time = proxy_last_called_time.get(watch_proxy, 0)
+ time_since_proxy_used = int(time.time() - proxy_last_used_time)
+ if time_since_proxy_used < proxy_list_reuse_time_minimum:
+ # Not enough time difference reached, skip this watch
+ print("> Skipped UUID {} using proxy '{}', not enough time between proxy requests {}s/{}s".format(uuid,
+ watch_proxy,
+ time_since_proxy_used,
+ proxy_list_reuse_time_minimum))
+ continue
+ else:
+ # Record the last used time
+ proxy_last_called_time[watch_proxy] = int(time.time())
+
+ # Use Epoch time as priority, so we get a "sorted" PriorityQueue, but we can still push a priority 1 into it.
+ priority = int(time.time())
+ print(
+ "> Queued watch UUID {} last checked at {} queued at {:0.2f} priority {} jitter {:0.2f}s, {:0.2f}s since last checked".format(
+ uuid,
+ watch['last_checked'],
+ now,
+ priority,
+ watch.jitter_seconds,
+ now - watch['last_checked']))
+ # Into the queue with you
+ update_q.put((priority, uuid))
+
+ # Reset for next time
+ watch.jitter_seconds = 0
+
+ # Wait before checking the list again - saves CPU
+ time.sleep(1)
# Should be low so we can break this out in testing
app.config.exit.wait(1)
diff --git a/changedetectionio/api/__init__.py b/changedetectionio/api/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/changedetectionio/api/api_v1.py b/changedetectionio/api/api_v1.py
new file mode 100644
index 00000000..40131ca5
--- /dev/null
+++ b/changedetectionio/api/api_v1.py
@@ -0,0 +1,158 @@
+from flask_restful import abort, Resource
+from flask import request, make_response
+import validators
+from . import auth
+
+
+
+# https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
+
+class Watch(Resource):
+ def __init__(self, **kwargs):
+ # datastore is a black box dependency
+ self.datastore = kwargs['datastore']
+ self.update_q = kwargs['update_q']
+
+ # Get information about a single watch, excluding the history list (can be large)
+ # curl http://localhost:4000/api/v1/watch/
+ # ?recheck=true
+ @auth.check_token
+ def get(self, uuid):
+ from copy import deepcopy
+ watch = deepcopy(self.datastore.data['watching'].get(uuid))
+ if not watch:
+ abort(404, message='No watch exists with the UUID of {}'.format(uuid))
+
+ if request.args.get('recheck'):
+ self.update_q.put((1, uuid))
+ return "OK", 200
+
+ # Return without history, get that via another API call
+ watch['history_n'] = watch.history_n
+ return watch
+
+ @auth.check_token
+ def delete(self, uuid):
+ if not self.datastore.data['watching'].get(uuid):
+ abort(400, message='No watch exists with the UUID of {}'.format(uuid))
+
+ self.datastore.delete(uuid)
+ return 'OK', 204
+
+
+class WatchHistory(Resource):
+ def __init__(self, **kwargs):
+ # datastore is a black box dependency
+ self.datastore = kwargs['datastore']
+
+ # Get a list of available history for a watch by UUID
+ # curl http://localhost:4000/api/v1/watch//history
+ def get(self, uuid):
+ watch = self.datastore.data['watching'].get(uuid)
+ if not watch:
+ abort(404, message='No watch exists with the UUID of {}'.format(uuid))
+ return watch.history, 200
+
+
+class WatchSingleHistory(Resource):
+ def __init__(self, **kwargs):
+ # datastore is a black box dependency
+ self.datastore = kwargs['datastore']
+
+ # Read a given history snapshot and return its content
+ # or "latest"
+ # curl http://localhost:4000/api/v1/watch//history/
+ @auth.check_token
+ def get(self, uuid, timestamp):
+ watch = self.datastore.data['watching'].get(uuid)
+ if not watch:
+ abort(404, message='No watch exists with the UUID of {}'.format(uuid))
+
+ if not len(watch.history):
+ abort(404, message='Watch found but no history exists for the UUID {}'.format(uuid))
+
+ if timestamp == 'latest':
+ timestamp = list(watch.history.keys())[-1]
+
+ with open(watch.history[timestamp], 'r') as f:
+ content = f.read()
+
+ response = make_response(content, 200)
+ response.mimetype = "text/plain"
+ return response
+
+
+class CreateWatch(Resource):
+ def __init__(self, **kwargs):
+ # datastore is a black box dependency
+ self.datastore = kwargs['datastore']
+ self.update_q = kwargs['update_q']
+
+ @auth.check_token
+ def post(self):
+ # curl http://localhost:4000/api/v1/watch -H "Content-Type: application/json" -d '{"url": "https://my-nice.com", "tag": "one, two" }'
+ json_data = request.get_json()
+ tag = json_data['tag'].strip() if json_data.get('tag') else ''
+
+ if not validators.url(json_data['url'].strip()):
+ return "Invalid or unsupported URL", 400
+
+ extras = {'title': json_data['title'].strip()} if json_data.get('title') else {}
+
+ new_uuid = self.datastore.add_watch(url=json_data['url'].strip(), tag=tag, extras=extras)
+ self.update_q.put((1, new_uuid))
+ return {'uuid': new_uuid}, 201
+
+ # Return concise list of available watches and some very basic info
+ # curl http://localhost:4000/api/v1/watch|python -mjson.tool
+ # ?recheck_all=1 to recheck all
+ @auth.check_token
+ def get(self):
+ list = {}
+ for k, v in self.datastore.data['watching'].items():
+ list[k] = {'url': v['url'],
+ 'title': v['title'],
+ 'last_checked': v['last_checked'],
+ 'last_changed': v.last_changed,
+ 'last_error': v['last_error']}
+
+ if request.args.get('recheck_all'):
+ for uuid in self.datastore.data['watching'].keys():
+ self.update_q.put((1, uuid))
+ return {'status': "OK"}, 200
+
+ return list, 200
+
+class SystemInfo(Resource):
+ def __init__(self, **kwargs):
+ # datastore is a black box dependency
+ self.datastore = kwargs['datastore']
+ self.update_q = kwargs['update_q']
+
+ @auth.check_token
+ def get(self):
+ import time
+ overdue_watches = []
+
+ # Check all watches and report which have not been checked but should have been
+
+ for uuid, watch in self.datastore.data.get('watching', {}).items():
+ # see if now - last_checked is greater than the time that should have been
+ # this is not super accurate (maybe they just edited it) but better than nothing
+ t = watch.threshold_seconds()
+ if not t:
+ # Use the system wide default
+ t = self.datastore.threshold_seconds
+
+ time_since_check = time.time() - watch.get('last_checked')
+
+ # Allow 5 minutes of grace time before we decide it's overdue
+ if time_since_check - (5 * 60) > t:
+ overdue_watches.append(uuid)
+
+ return {
+ 'queue_size': self.update_q.qsize(),
+ 'overdue_watches': overdue_watches,
+ 'uptime': round(time.time() - self.datastore.start_time, 2),
+ 'watch_count': len(self.datastore.data.get('watching', {}))
+ }, 200
diff --git a/changedetectionio/api/auth.py b/changedetectionio/api/auth.py
new file mode 100644
index 00000000..806a8ccd
--- /dev/null
+++ b/changedetectionio/api/auth.py
@@ -0,0 +1,33 @@
+from flask import request, make_response, jsonify
+from functools import wraps
+
+
+# Simple API auth key comparison
+# @todo - Maybe short lived token in the future?
+
+def check_token(f):
+ @wraps(f)
+ def decorated(*args, **kwargs):
+ datastore = args[0].datastore
+
+ config_api_token_enabled = datastore.data['settings']['application'].get('api_access_token_enabled')
+ if not config_api_token_enabled:
+ return
+
+ try:
+ api_key_header = request.headers['x-api-key']
+ except KeyError:
+ return make_response(
+ jsonify("No authorization x-api-key header."), 403
+ )
+
+ config_api_token = datastore.data['settings']['application'].get('api_access_token')
+
+ if api_key_header != config_api_token:
+ return make_response(
+ jsonify("Invalid access - API key invalid."), 403
+ )
+
+ return f(*args, **kwargs)
+
+ return decorated
diff --git a/changedetectionio/apprise_asset.py b/changedetectionio/apprise_asset.py
new file mode 100644
index 00000000..6661cf16
--- /dev/null
+++ b/changedetectionio/apprise_asset.py
@@ -0,0 +1,11 @@
+import apprise
+
+# Create our AppriseAsset and populate it with some of our new values:
+# https://github.com/caronc/apprise/wiki/Development_API#the-apprise-asset-object
+asset = apprise.AppriseAsset(
+ image_url_logo='https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
+)
+
+asset.app_id = "changedetection.io"
+asset.app_desc = "ChangeDetection.io best and simplest website monitoring and change detection"
+asset.app_url = "https://changedetection.io"
diff --git a/changedetectionio/blueprint/__init__.py b/changedetectionio/blueprint/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/changedetectionio/blueprint/browser_steps/__init__.py b/changedetectionio/blueprint/browser_steps/__init__.py
new file mode 100644
index 00000000..9087acac
--- /dev/null
+++ b/changedetectionio/blueprint/browser_steps/__init__.py
@@ -0,0 +1,231 @@
+
+# HORRIBLE HACK BUT WORKS :-) PR anyone?
+#
+# Why?
+# `browsersteps_playwright_browser_interface.chromium.connect_over_cdp()` will only run once without async()
+# - this flask app is not async()
+# - browserless has a single timeout/keepalive which applies to the session made at .connect_over_cdp()
+#
+# So it means that we must unfortunately for now just keep a single timer since .connect_over_cdp() was run
+# and know when that reaches timeout/keepalive :( when that time is up, restart the connection and tell the user
+# that their time is up, insert another coin. (reload)
+#
+# Bigger picture
+# - It's horrible that we have this click+wait deal, some nice socket.io solution using something similar
+# to what the browserless debug UI already gives us would be smarter..
+#
+# OR
+# - Some API call that should be hacked into browserless or playwright that we can "/api/bump-keepalive/{session_id}/60"
+# So we can tell it that we need more time (run this on each action)
+#
+# OR
+# - use multiprocessing to bump this over to its own process and add some transport layer (queue/pipes)
+
+from distutils.util import strtobool
+from flask import Blueprint, request, make_response
+from flask_login import login_required
+import os
+import logging
+from changedetectionio.store import ChangeDetectionStore
+
+browsersteps_live_ui_o = {}
+browsersteps_playwright_browser_interface = None
+browsersteps_playwright_browser_interface_browser = None
+browsersteps_playwright_browser_interface_context = None
+browsersteps_playwright_browser_interface_end_time = None
+browsersteps_playwright_browser_interface_start_time = None
+
+def cleanup_playwright_session():
+
+ global browsersteps_live_ui_o
+ global browsersteps_playwright_browser_interface
+ global browsersteps_playwright_browser_interface_browser
+ global browsersteps_playwright_browser_interface_context
+ global browsersteps_playwright_browser_interface_end_time
+ global browsersteps_playwright_browser_interface_start_time
+
+ browsersteps_live_ui_o = {}
+ browsersteps_playwright_browser_interface = None
+ browsersteps_playwright_browser_interface_browser = None
+ browsersteps_playwright_browser_interface_end_time = None
+ browsersteps_playwright_browser_interface_start_time = None
+
+ print("Cleaning up old playwright session because time was up, calling .goodbye()")
+ try:
+ browsersteps_playwright_browser_interface_context.goodbye()
+ except Exception as e:
+ print ("Got exception in shutdown, probably OK")
+ print (str(e))
+
+ browsersteps_playwright_browser_interface_context = None
+
+ print ("Cleaning up old playwright session because time was up - done")
+
+def construct_blueprint(datastore: ChangeDetectionStore):
+
+ browser_steps_blueprint = Blueprint('browser_steps', __name__, template_folder="templates")
+
+ @login_required
+ @browser_steps_blueprint.route("/browsersteps_update", methods=['GET', 'POST'])
+ def browsersteps_ui_update():
+ import base64
+ import playwright._impl._api_types
+ import time
+
+ from changedetectionio.blueprint.browser_steps import browser_steps
+
+ global browsersteps_live_ui_o, browsersteps_playwright_browser_interface_end_time
+ global browsersteps_playwright_browser_interface_browser
+ global browsersteps_playwright_browser_interface
+ global browsersteps_playwright_browser_interface_start_time
+
+ step_n = None
+ remaining =0
+ uuid = request.args.get('uuid')
+
+ browsersteps_session_id = request.args.get('browsersteps_session_id')
+
+ if not browsersteps_session_id:
+ return make_response('No browsersteps_session_id specified', 500)
+
+ # Because we don't "really" run in a context manager ( we make the playwright interface global/long-living )
+ # We need to manage the shutdown when the time is up
+ if browsersteps_playwright_browser_interface_end_time:
+ remaining = browsersteps_playwright_browser_interface_end_time-time.time()
+ if browsersteps_playwright_browser_interface_end_time and remaining <= 0:
+ cleanup_playwright_session()
+ return make_response('Browser session expired, please reload the Browser Steps interface', 401)
+
+ # Actions - step/apply/etc, do the thing and return state
+ if request.method == 'POST':
+ # @todo - should always be an existing session
+ step_operation = request.form.get('operation')
+ step_selector = request.form.get('selector')
+ step_optional_value = request.form.get('optional_value')
+ step_n = int(request.form.get('step_n'))
+ is_last_step = strtobool(request.form.get('is_last_step'))
+
+ if step_operation == 'Goto site':
+ step_operation = 'goto_url'
+ step_optional_value = None
+ step_selector = datastore.data['watching'][uuid].get('url')
+
+ # @todo try.. accept.. nice errors not popups..
+ try:
+
+ this_session = browsersteps_live_ui_o.get(browsersteps_session_id)
+ if not this_session:
+ print("Browser exited")
+ return make_response('Browser session ran out of time :( Please reload this page.', 401)
+
+ this_session.call_action(action_name=step_operation,
+ selector=step_selector,
+ optional_value=step_optional_value)
+
+ except Exception as e:
+ print("Exception when calling step operation", step_operation, str(e))
+ # Try to find something of value to give back to the user
+ return make_response(str(e).splitlines()[0], 401)
+
+ # Get visual selector ready/update its data (also use the current filter info from the page?)
+ # When the last 'apply' button was pressed
+ # @todo this adds overhead because the xpath selection is happening twice
+ u = this_session.page.url
+ if is_last_step and u:
+ (screenshot, xpath_data) = this_session.request_visualselector_data()
+ datastore.save_screenshot(watch_uuid=uuid, screenshot=screenshot)
+ datastore.save_xpath_data(watch_uuid=uuid, data=xpath_data)
+
+ # Setup interface
+ if request.method == 'GET':
+
+ if not browsersteps_playwright_browser_interface:
+ print("Starting connection with playwright")
+ logging.debug("browser_steps.py connecting")
+
+ global browsersteps_playwright_browser_interface_context
+ from . import nonContext
+ browsersteps_playwright_browser_interface_context = nonContext.c_sync_playwright()
+ browsersteps_playwright_browser_interface = browsersteps_playwright_browser_interface_context.start()
+
+ time.sleep(1)
+ # At 20 minutes, some other variable is closing it
+ # @todo find out what it is and set it
+ seconds_keepalive = int(os.getenv('BROWSERSTEPS_MINUTES_KEEPALIVE', 10)) * 60
+
+ # keep it alive for 10 seconds more than we advertise, sometimes it helps to keep it shutting down cleanly
+ keepalive = "&timeout={}".format(((seconds_keepalive+3) * 1000))
+ try:
+ browsersteps_playwright_browser_interface_browser = browsersteps_playwright_browser_interface.chromium.connect_over_cdp(
+ os.getenv('PLAYWRIGHT_DRIVER_URL', '') + keepalive)
+ except Exception as e:
+ if 'ECONNREFUSED' in str(e):
+ return make_response('Unable to start the Playwright session properly, is it running?', 401)
+
+ browsersteps_playwright_browser_interface_end_time = time.time() + (seconds_keepalive-3)
+ print("Starting connection with playwright - done")
+
+ if not browsersteps_live_ui_o.get(browsersteps_session_id):
+ # Boot up a new session
+ proxy_id = datastore.get_preferred_proxy_for_watch(uuid=uuid)
+ proxy = None
+ if proxy_id:
+ proxy_url = datastore.proxy_list.get(proxy_id).get('url')
+ if proxy_url:
+ proxy = {'server': proxy_url}
+ print("Browser Steps: UUID {} Using proxy {}".format(uuid, proxy_url))
+
+ # Begin the new "Playwright Context" that re-uses the playwright interface
+ # Each session is a "Playwright Context" as a list, that uses the playwright interface
+ browsersteps_live_ui_o[browsersteps_session_id] = browser_steps.browsersteps_live_ui(
+ playwright_browser=browsersteps_playwright_browser_interface_browser,
+ proxy=proxy)
+ this_session = browsersteps_live_ui_o[browsersteps_session_id]
+
+ if not this_session.page:
+ cleanup_playwright_session()
+ return make_response('Browser session ran out of time :( Please reload this page.', 401)
+
+ response = None
+
+ if request.method == 'POST':
+ # Screenshots and other info only needed on requesting a step (POST)
+ try:
+ state = this_session.get_current_state()
+ except playwright._impl._api_types.Error as e:
+ return make_response("Browser session ran out of time :( Please reload this page."+str(e), 401)
+
+ # Use send_file() which is way faster than read/write loop on bytes
+ import json
+ from tempfile import mkstemp
+ from flask import send_file
+ tmp_fd, tmp_file = mkstemp(text=True, suffix=".json", prefix="changedetectionio-")
+
+ output = json.dumps({'screenshot': "data:image/jpeg;base64,{}".format(
+ base64.b64encode(state[0]).decode('ascii')),
+ 'xpath_data': state[1],
+ 'session_age_start': this_session.age_start,
+ 'browser_time_remaining': round(remaining)
+ })
+
+ with os.fdopen(tmp_fd, 'w') as f:
+ f.write(output)
+
+ response = make_response(send_file(path_or_file=tmp_file,
+ mimetype='application/json; charset=UTF-8',
+ etag=True))
+ # No longer needed
+ os.unlink(tmp_file)
+
+ elif request.method == 'GET':
+ # Just enough to get the session rolling, it will call for goto-site via POST next
+ response = make_response({
+ 'session_age_start': this_session.age_start,
+ 'browser_time_remaining': round(remaining)
+ })
+
+ return response
+
+ return browser_steps_blueprint
+
+
diff --git a/changedetectionio/blueprint/browser_steps/browser_steps.py b/changedetectionio/blueprint/browser_steps/browser_steps.py
new file mode 100644
index 00000000..7fc7ca3b
--- /dev/null
+++ b/changedetectionio/blueprint/browser_steps/browser_steps.py
@@ -0,0 +1,270 @@
+#!/usr/bin/python3
+
+import os
+import time
+import re
+from random import randint
+
+# Two flags, tell the JS which of the "Selector" or "Value" field should be enabled in the front end
+# 0- off, 1- on
+browser_step_ui_config = {'Choose one': '0 0',
+ # 'Check checkbox': '1 0',
+ # 'Click button containing text': '0 1',
+ # 'Scroll to bottom': '0 0',
+ # 'Scroll to element': '1 0',
+ # 'Scroll to top': '0 0',
+ # 'Switch to iFrame by index number': '0 1'
+ # 'Uncheck checkbox': '1 0',
+ # @todo
+ 'Check checkbox': '1 0',
+ 'Click X,Y': '0 1',
+ 'Click element if exists': '1 0',
+ 'Click element': '1 0',
+ 'Click element containing text': '0 1',
+ 'Enter text in field': '1 1',
+ 'Execute JS': '0 1',
+# 'Extract text and use as filter': '1 0',
+ 'Goto site': '0 0',
+ 'Press Enter': '0 0',
+ 'Select by label': '1 1',
+ 'Scroll down': '0 0',
+ 'Uncheck checkbox': '1 0',
+ 'Wait for seconds': '0 1',
+ 'Wait for text': '0 1',
+ # 'Press Page Down': '0 0',
+ # 'Press Page Up': '0 0',
+ # weird bug, come back to it later
+ }
+
+
+# Good reference - https://playwright.dev/python/docs/input
+# https://pythonmana.com/2021/12/202112162236307035.html
+#
+# ONLY Works in Playwright because we need the fullscreen screenshot
+class steppable_browser_interface():
+ page = None
+
+ # Convert and perform "Click Button" for example
+ def call_action(self, action_name, selector=None, optional_value=None):
+ now = time.time()
+ call_action_name = re.sub('[^0-9a-zA-Z]+', '_', action_name.lower())
+ if call_action_name == 'choose_one':
+ return
+
+ print("> action calling", call_action_name)
+ # https://playwright.dev/python/docs/selectors#xpath-selectors
+ if selector.startswith('/') and not selector.startswith('//'):
+ selector = "xpath=" + selector
+
+ action_handler = getattr(self, "action_" + call_action_name)
+
+ # Support for Jinja2 variables in the value and selector
+ from jinja2 import Environment
+ jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
+
+ if selector and ('{%' in selector or '{{' in selector):
+ selector = str(jinja2_env.from_string(selector).render())
+
+ if optional_value and ('{%' in optional_value or '{{' in optional_value):
+ optional_value = str(jinja2_env.from_string(optional_value).render())
+
+ action_handler(selector, optional_value)
+ self.page.wait_for_timeout(3 * 1000)
+ print("Call action done in", time.time() - now)
+
+ def action_goto_url(self, url, optional_value):
+ # self.page.set_viewport_size({"width": 1280, "height": 5000})
+ now = time.time()
+ response = self.page.goto(url, timeout=0, wait_until='domcontentloaded')
+ print("Time to goto URL", time.time() - now)
+
+ # Wait_until = commit
+ # - `'commit'` - consider operation to be finished when network response is received and the document started loading.
+ # Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
+ # This seemed to solve nearly all 'TimeoutErrors'
+ extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5))
+ self.page.wait_for_timeout(extra_wait * 1000)
+
+ def action_click_element_containing_text(self, selector=None, value=''):
+ if not len(value.strip()):
+ return
+ elem = self.page.get_by_text(value)
+ if elem.count():
+ elem.first.click(delay=randint(200, 500), timeout=3000)
+
+ def action_enter_text_in_field(self, selector, value):
+ if not len(selector.strip()):
+ return
+
+ self.page.fill(selector, value, timeout=10 * 1000)
+
+ def action_execute_js(self, selector, value):
+ self.page.evaluate(value)
+
+ def action_click_element(self, selector, value):
+ print("Clicking element")
+ if not len(selector.strip()):
+ return
+ self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
+
+ def action_click_element_if_exists(self, selector, value):
+ import playwright._impl._api_types as _api_types
+ print("Clicking element if exists")
+ if not len(selector.strip()):
+ return
+ try:
+ self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
+ except _api_types.TimeoutError as e:
+ return
+ except _api_types.Error as e:
+ # Element was there, but page redrew and now its long long gone
+ return
+
+ def action_click_x_y(self, selector, value):
+ x, y = value.strip().split(',')
+ x = int(float(x.strip()))
+ y = int(float(y.strip()))
+ self.page.mouse.click(x=x, y=y, delay=randint(200, 500))
+
+ def action_scroll_down(self, selector, value):
+ # Some sites this doesnt work on for some reason
+ self.page.mouse.wheel(0, 600)
+ self.page.wait_for_timeout(1000)
+
+ def action_wait_for_seconds(self, selector, value):
+ self.page.wait_for_timeout(int(value) * 1000)
+
+ # @todo - in the future make some popout interface to capture what needs to be set
+ # https://playwright.dev/python/docs/api/class-keyboard
+ def action_press_enter(self, selector, value):
+ self.page.keyboard.press("Enter", delay=randint(200, 500))
+
+ def action_press_page_up(self, selector, value):
+ self.page.keyboard.press("PageUp", delay=randint(200, 500))
+
+ def action_press_page_down(self, selector, value):
+ self.page.keyboard.press("PageDown", delay=randint(200, 500))
+
+ def action_check_checkbox(self, selector, value):
+ self.page.locator(selector).check(timeout=1000)
+
+ def action_uncheck_checkbox(self, selector, value):
+ self.page.locator(selector, timeout=1000).uncheck(timeout=1000)
+
+
+# Responsible for maintaining a live 'context' with browserless
+# @todo - how long do contexts live for anyway?
+class browsersteps_live_ui(steppable_browser_interface):
+ context = None
+ page = None
+ render_extra_delay = 1
+ stale = False
+ # bump and kill this if idle after X sec
+ age_start = 0
+
+ # use a special driver, maybe locally etc
+ command_executor = os.getenv(
+ "PLAYWRIGHT_BROWSERSTEPS_DRIVER_URL"
+ )
+ # if not..
+ if not command_executor:
+ command_executor = os.getenv(
+ "PLAYWRIGHT_DRIVER_URL",
+ 'ws://playwright-chrome:3000'
+ ).strip('"')
+
+ browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
+
+ def __init__(self, playwright_browser, proxy=None):
+ self.age_start = time.time()
+ self.playwright_browser = playwright_browser
+ if self.context is None:
+ self.connect(proxy=proxy)
+
+ # Connect and setup a new context
+ def connect(self, proxy=None):
+ # Should only get called once - test that
+ keep_open = 1000 * 60 * 5
+ now = time.time()
+
+ # @todo handle multiple contexts, bind a unique id from the browser on each req?
+ self.context = self.playwright_browser.new_context(
+ # @todo
+ # user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
+ # proxy=self.proxy,
+ # This is needed to enable JavaScript execution on GitHub and others
+ bypass_csp=True,
+ # Should never be needed
+ accept_downloads=False,
+ proxy=proxy
+ )
+
+ self.page = self.context.new_page()
+
+ # self.page.set_default_navigation_timeout(keep_open)
+ self.page.set_default_timeout(keep_open)
+ # @todo probably this doesnt work
+ self.page.on(
+ "close",
+ self.mark_as_closed,
+ )
+ # Listen for all console events and handle errors
+ self.page.on("console", lambda msg: print(f"Browser steps console - {msg.type}: {msg.text} {msg.args}"))
+
+ print("Time to browser setup", time.time() - now)
+ self.page.wait_for_timeout(1 * 1000)
+
+ def mark_as_closed(self):
+ print("Page closed, cleaning up..")
+
+ @property
+ def has_expired(self):
+ if not self.page:
+ return True
+
+
+ def get_current_state(self):
+ """Return the screenshot and interactive elements mapping, generally always called after action_()"""
+ from pkg_resources import resource_string
+ xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
+ now = time.time()
+ self.page.wait_for_timeout(1 * 1000)
+
+ # The actual screenshot
+ screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=40)
+
+ self.page.evaluate("var include_filters=''")
+ # Go find the interactive elements
+ # @todo in the future, something smarter that can scan for elements with .click/focus etc event handlers?
+ elements = 'a,button,input,select,textarea,i,th,td,p,li,h1,h2,h3,h4,div,span'
+ xpath_element_js = xpath_element_js.replace('%ELEMENTS%', elements)
+ xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
+ # So the JS will find the smallest one first
+ xpath_data['size_pos'] = sorted(xpath_data['size_pos'], key=lambda k: k['width'] * k['height'], reverse=True)
+ print("Time to complete get_current_state of browser", time.time() - now)
+ # except
+ # playwright._impl._api_types.Error: Browser closed.
+ # @todo show some countdown timer?
+ return (screenshot, xpath_data)
+
+ def request_visualselector_data(self):
+ """
+ Does the same that the playwright operation in content_fetcher does
+ This is used to just bump the VisualSelector data so it' ready to go if they click on the tab
+ @todo refactor and remove duplicate code, add include_filters
+ :param xpath_data:
+ :param screenshot:
+ :param current_include_filters:
+ :return:
+ """
+
+ self.page.evaluate("var include_filters=''")
+ from pkg_resources import resource_string
+ # The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
+ xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
+ from changedetectionio.content_fetcher import visualselector_xpath_selectors
+ xpath_element_js = xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
+ xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
+ screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
+
+ return (screenshot, xpath_data)
diff --git a/changedetectionio/blueprint/browser_steps/nonContext.py b/changedetectionio/blueprint/browser_steps/nonContext.py
new file mode 100644
index 00000000..5345f306
--- /dev/null
+++ b/changedetectionio/blueprint/browser_steps/nonContext.py
@@ -0,0 +1,18 @@
+from playwright.sync_api import PlaywrightContextManager
+import asyncio
+
+# So playwright wants to run as a context manager, but we do something horrible and hacky
+# we are holding the session open for as long as possible, then shutting it down, and opening a new one
+# So it means we don't get to use PlaywrightContextManager' __enter__ __exit__
+# To work around this, make goodbye() act the same as the __exit__()
+#
+# But actually I think this is because the context is opened correctly with __enter__() but we timeout the connection
+# then theres some lock condition where we cant destroy it without it hanging
+
+class c_PlaywrightContextManager(PlaywrightContextManager):
+
+ def goodbye(self) -> None:
+ self.__exit__()
+
+def c_sync_playwright() -> PlaywrightContextManager:
+ return c_PlaywrightContextManager()
diff --git a/changedetectionio/changedetection.py b/changedetectionio/changedetection.py
new file mode 100755
index 00000000..9d508a4a
--- /dev/null
+++ b/changedetectionio/changedetection.py
@@ -0,0 +1,136 @@
+#!/usr/bin/python3
+
+# Launch as a eventlet.wsgi server instance.
+
+from distutils.util import strtobool
+import eventlet
+import eventlet.wsgi
+import getopt
+import os
+import signal
+import sys
+
+from . import store, changedetection_app, content_fetcher
+from . import __version__
+
+# Only global so we can access it in the signal handler
+app = None
+datastore = None
+
+def sigterm_handler(_signo, _stack_frame):
+ global app
+ global datastore
+# app.config.exit.set()
+ print('Shutdown: Got SIGTERM, DB saved to disk')
+ datastore.sync_to_json()
+# raise SystemExit
+
+def main():
+ global datastore
+ global app
+ ssl_mode = False
+ host = ''
+ port = os.environ.get('PORT') or 5000
+ do_cleanup = False
+ datastore_path = None
+
+ # On Windows, create and use a default path.
+ if os.name == 'nt':
+ datastore_path = os.path.expandvars(r'%APPDATA%\changedetection.io')
+ os.makedirs(datastore_path, exist_ok=True)
+ else:
+ # Must be absolute so that send_from_directory doesnt try to make it relative to backend/
+ datastore_path = os.path.join(os.getcwd(), "../datastore")
+
+ try:
+ opts, args = getopt.getopt(sys.argv[1:], "Ccsd:h:p:", "port")
+ except getopt.GetoptError:
+ print('backend.py -s SSL enable -h [host] -p [port] -d [datastore path]')
+ sys.exit(2)
+
+ create_datastore_dir = False
+
+ for opt, arg in opts:
+ if opt == '-s':
+ ssl_mode = True
+
+ if opt == '-h':
+ host = arg
+
+ if opt == '-p':
+ port = int(arg)
+
+ if opt == '-d':
+ datastore_path = arg
+
+ # Cleanup (remove text files that arent in the index)
+ if opt == '-c':
+ do_cleanup = True
+
+ # Create the datadir if it doesnt exist
+ if opt == '-C':
+ create_datastore_dir = True
+
+ # isnt there some @thingy to attach to each route to tell it, that this route needs a datastore
+ app_config = {'datastore_path': datastore_path}
+
+ if not os.path.isdir(app_config['datastore_path']):
+ if create_datastore_dir:
+ os.mkdir(app_config['datastore_path'])
+ else:
+ print(
+ "ERROR: Directory path for the datastore '{}' does not exist, cannot start, please make sure the directory exists or specify a directory with the -d option.\n"
+ "Or use the -C parameter to create the directory.".format(app_config['datastore_path']), file=sys.stderr)
+ sys.exit(2)
+
+
+ datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=__version__)
+ app = changedetection_app(app_config, datastore)
+
+ signal.signal(signal.SIGTERM, sigterm_handler)
+
+ # Go into cleanup mode
+ if do_cleanup:
+ datastore.remove_unused_snapshots()
+
+ app.config['datastore_path'] = datastore_path
+
+
+ @app.context_processor
+ def inject_version():
+ return dict(right_sticky="v{}".format(datastore.data['version_tag']),
+ new_version_available=app.config['NEW_VERSION_AVAILABLE'],
+ has_password=datastore.data['settings']['application']['password'] != False
+ )
+
+ # Monitored websites will not receive a Referer header when a user clicks on an outgoing link.
+ # @Note: Incompatible with password login (and maybe other features) for now, submit a PR!
+ @app.after_request
+ def hide_referrer(response):
+ if strtobool(os.getenv("HIDE_REFERER", 'false')):
+ response.headers["Referrer-Policy"] = "no-referrer"
+
+ return response
+
+ # Proxy sub-directory support
+ # Set environment var USE_X_SETTINGS=1 on this script
+ # And then in your proxy_pass settings
+ #
+ # proxy_set_header Host "localhost";
+ # proxy_set_header X-Forwarded-Prefix /app;
+
+ if os.getenv('USE_X_SETTINGS'):
+ print ("USE_X_SETTINGS is ENABLED\n")
+ from werkzeug.middleware.proxy_fix import ProxyFix
+ app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
+
+ if ssl_mode:
+ # @todo finalise SSL config, but this should get you in the right direction if you need it.
+ eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen((host, port)),
+ certfile='cert.pem',
+ keyfile='privkey.pem',
+ server_side=True), app)
+
+ else:
+ eventlet.wsgi.server(eventlet.listen((host, int(port))), app)
+
diff --git a/changedetectionio/content_fetcher.py b/changedetectionio/content_fetcher.py
index 1f6ef14a..1f86cdd0 100644
--- a/changedetectionio/content_fetcher.py
+++ b/changedetectionio/content_fetcher.py
@@ -1,63 +1,397 @@
+from abc import abstractmethod
+import chardet
+import json
+import logging
import os
+import requests
+import sys
import time
-from abc import ABC, abstractmethod
-from selenium import webdriver
-from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
-from selenium.common.exceptions import WebDriverException
-import urllib3.exceptions
+visualselector_xpath_selectors = 'div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary'
+
+class Non200ErrorCodeReceived(Exception):
+ def __init__(self, status_code, url, screenshot=None, xpath_data=None, page_html=None):
+ # Set this so we can use it in other parts of the app
+ self.status_code = status_code
+ self.url = url
+ self.screenshot = screenshot
+ self.xpath_data = xpath_data
+ self.page_text = None
+
+ if page_html:
+ from changedetectionio import html_tools
+ self.page_text = html_tools.html_to_text(page_html)
+ return
+
+
+class JSActionExceptions(Exception):
+ def __init__(self, status_code, url, screenshot, message=''):
+ self.status_code = status_code
+ self.url = url
+ self.screenshot = screenshot
+ self.message = message
+ return
+
+class BrowserStepsStepTimout(Exception):
+ def __init__(self, step_n):
+ self.step_n = step_n
+ return
+
+
+class PageUnloadable(Exception):
+ def __init__(self, status_code, url, screenshot=False, message=False):
+ # Set this so we can use it in other parts of the app
+ self.status_code = status_code
+ self.url = url
+ self.screenshot = screenshot
+ self.message = message
+ return
class EmptyReply(Exception):
- pass
+ def __init__(self, status_code, url, screenshot=None):
+ # Set this so we can use it in other parts of the app
+ self.status_code = status_code
+ self.url = url
+ self.screenshot = screenshot
+ return
+
+class ScreenshotUnavailable(Exception):
+ def __init__(self, status_code, url, page_html=None):
+ # Set this so we can use it in other parts of the app
+ self.status_code = status_code
+ self.url = url
+ if page_html:
+ from html_tools import html_to_text
+ self.page_text = html_to_text(page_html)
+ return
+
+class ReplyWithContentButNoText(Exception):
+ def __init__(self, status_code, url, screenshot=None):
+ # Set this so we can use it in other parts of the app
+ self.status_code = status_code
+ self.url = url
+ self.screenshot = screenshot
+ return
class Fetcher():
error = None
status_code = None
- content = None # Should be bytes?
+ content = None
+ headers = None
+ browser_steps = None
+ browser_steps_screenshot_path = None
+
+ fetcher_description = "No description"
+ webdriver_js_execute_code = None
+ xpath_element_js = ""
+
+ xpath_data = None
+
+ # Will be needed in the future by the VisualSelector, always get this where possible.
+ screenshot = False
+ system_http_proxy = os.getenv('HTTP_PROXY')
+ system_https_proxy = os.getenv('HTTPS_PROXY')
+
+ # Time ONTOP of the system defined env minimum time
+ render_extract_delay = 0
+
+ def __init__(self):
+ from pkg_resources import resource_string
+ # The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
+ self.xpath_element_js = resource_string(__name__, "res/xpath_element_scraper.js").decode('utf-8')
- fetcher_description ="No description"
@abstractmethod
def get_error(self):
return self.error
@abstractmethod
- def run(self, url, timeout, request_headers):
+ def run(self,
+ url,
+ timeout,
+ request_headers,
+ request_body,
+ request_method,
+ ignore_status_codes=False,
+ current_include_filters=None):
# Should set self.error, self.status_code and self.content
pass
+ @abstractmethod
+ def quit(self):
+ return
+
@abstractmethod
def get_last_status_code(self):
return self.status_code
+ @abstractmethod
+ def screenshot_step(self, step_n):
+ return None
+
@abstractmethod
# Return true/false if this checker is ready to run, in the case it needs todo some special config check etc
def is_ready(self):
return True
+ def iterate_browser_steps(self):
+ from changedetectionio.blueprint.browser_steps.browser_steps import steppable_browser_interface
+ from playwright._impl._api_types import TimeoutError
+ from jinja2 import Environment
+ jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
+
+ step_n = 0
+
+ if self.browser_steps is not None and len(self.browser_steps):
+ interface = steppable_browser_interface()
+ interface.page = self.page
+
+ valid_steps = filter(lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'), self.browser_steps)
+
+ for step in valid_steps:
+ step_n += 1
+ print(">> Iterating check - browser Step n {} - {}...".format(step_n, step['operation']))
+ self.screenshot_step("before-"+str(step_n))
+ self.save_step_html("before-"+str(step_n))
+ try:
+ optional_value = step['optional_value']
+ selector = step['selector']
+ # Support for jinja2 template in step values, with date module added
+ if '{%' in step['optional_value'] or '{{' in step['optional_value']:
+ optional_value = str(jinja2_env.from_string(step['optional_value']).render())
+ if '{%' in step['selector'] or '{{' in step['selector']:
+ selector = str(jinja2_env.from_string(step['selector']).render())
+
+ getattr(interface, "call_action")(action_name=step['operation'],
+ selector=selector,
+ optional_value=optional_value)
+ self.screenshot_step(step_n)
+ self.save_step_html(step_n)
+ except TimeoutError:
+ # Stop processing here
+ raise BrowserStepsStepTimout(step_n=step_n)
+
+
+
+ # It's always good to reset these
+ def delete_browser_steps_screenshots(self):
+ import glob
+ if self.browser_steps_screenshot_path is not None:
+ dest = os.path.join(self.browser_steps_screenshot_path, 'step_*.jpeg')
+ files = glob.glob(dest)
+ for f in files:
+ os.unlink(f)
+
# Maybe for the future, each fetcher provides its own diff output, could be used for text, image
# the current one would return javascript output (as we use JS to generate the diff)
#
-# Returns tuple(mime_type, stream)
-# @abstractmethod
-# def return_diff(self, stream_a, stream_b):
-# return
-
def available_fetchers():
- import inspect
- from changedetectionio import content_fetcher
- p=[]
- for name, obj in inspect.getmembers(content_fetcher):
- if inspect.isclass(obj):
- # @todo html_ is maybe better as fetcher_ or something
- # In this case, make sure to edit the default one in store.py and fetch_site_status.py
- if "html_" in name:
- t=tuple([name,obj.fetcher_description])
- p.append(t)
+ # See the if statement at the bottom of this file for how we switch between playwright and webdriver
+ import inspect
+ p = []
+ for name, obj in inspect.getmembers(sys.modules[__name__], inspect.isclass):
+ if inspect.isclass(obj):
+ # @todo html_ is maybe better as fetcher_ or something
+ # In this case, make sure to edit the default one in store.py and fetch_site_status.py
+ if name.startswith('html_'):
+ t = tuple([name, obj.fetcher_description])
+ p.append(t)
- return p
+ return p
-class html_webdriver(Fetcher):
+class base_html_playwright(Fetcher):
+ fetcher_description = "Playwright {}/Javascript".format(
+ os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').capitalize()
+ )
+ if os.getenv("PLAYWRIGHT_DRIVER_URL"):
+ fetcher_description += " via '{}'".format(os.getenv("PLAYWRIGHT_DRIVER_URL"))
+
+ browser_type = ''
+ command_executor = ''
+
+ # Configs for Proxy setup
+ # In the ENV vars, is prefixed with "playwright_proxy_", so it is for example "playwright_proxy_server"
+ playwright_proxy_settings_mappings = ['bypass', 'server', 'username', 'password']
+
+ proxy = None
+
+ def __init__(self, proxy_override=None):
+ super().__init__()
+ # .strip('"') is going to save someone a lot of time when they accidently wrap the env value
+ self.browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
+ self.command_executor = os.getenv(
+ "PLAYWRIGHT_DRIVER_URL",
+ 'ws://playwright-chrome:3000'
+ ).strip('"')
+
+ # If any proxy settings are enabled, then we should setup the proxy object
+ proxy_args = {}
+ for k in self.playwright_proxy_settings_mappings:
+ v = os.getenv('playwright_proxy_' + k, False)
+ if v:
+ proxy_args[k] = v.strip('"')
+
+ if proxy_args:
+ self.proxy = proxy_args
+
+ # allow per-watch proxy selection override
+ if proxy_override:
+ self.proxy = {'server': proxy_override}
+
+ def screenshot_step(self, step_n=''):
+
+ # There's a bug where we need to do it twice or it doesnt take the whole page, dont know why.
+ self.page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
+ screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=85)
+
+ if self.browser_steps_screenshot_path is not None:
+ destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.jpeg'.format(step_n))
+ logging.debug("Saving step screenshot to {}".format(destination))
+ with open(destination, 'wb') as f:
+ f.write(screenshot)
+
+ def save_step_html(self, step_n):
+ content = self.page.content()
+ destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.html'.format(step_n))
+ logging.debug("Saving step HTML to {}".format(destination))
+ with open(destination, 'w') as f:
+ f.write(content)
+
+ def run(self,
+ url,
+ timeout,
+ request_headers,
+ request_body,
+ request_method,
+ ignore_status_codes=False,
+ current_include_filters=None):
+
+ from playwright.sync_api import sync_playwright
+ import playwright._impl._api_types
+
+ self.delete_browser_steps_screenshots()
+ response = None
+ with sync_playwright() as p:
+ browser_type = getattr(p, self.browser_type)
+
+ # Seemed to cause a connection Exception even tho I can see it connect
+ # self.browser = browser_type.connect(self.command_executor, timeout=timeout*1000)
+ # 60,000 connection timeout only
+ browser = browser_type.connect_over_cdp(self.command_executor, timeout=60000)
+
+ # Set user agent to prevent Cloudflare from blocking the browser
+ # Use the default one configured in the App.py model that's passed from fetch_site_status.py
+ context = browser.new_context(
+ user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
+ proxy=self.proxy,
+ # This is needed to enable JavaScript execution on GitHub and others
+ bypass_csp=True,
+ # Should never be needed
+ accept_downloads=False
+ )
+
+ self.page = context.new_page()
+ if len(request_headers):
+ context.set_extra_http_headers(request_headers)
+
+ try:
+ self.page.set_default_navigation_timeout(90000)
+ self.page.set_default_timeout(90000)
+
+ # Listen for all console events and handle errors
+ self.page.on("console", lambda msg: print(f"Playwright console: Watch URL: {url} {msg.type}: {msg.text} {msg.args}"))
+
+ # Bug - never set viewport size BEFORE page.goto
+
+
+ # Waits for the next navigation. Using Python context manager
+ # prevents a race condition between clicking and waiting for a navigation.
+ with self.page.expect_navigation():
+ response = self.page.goto(url, wait_until='load')
+ # Wait_until = commit
+ # - `'commit'` - consider operation to be finished when network response is received and the document started loading.
+ # Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
+ # This seemed to solve nearly all 'TimeoutErrors'
+ extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
+ self.page.wait_for_timeout(extra_wait * 1000)
+
+ if self.webdriver_js_execute_code is not None and len(self.webdriver_js_execute_code):
+ self.page.evaluate(self.webdriver_js_execute_code)
+
+ except playwright._impl._api_types.TimeoutError as e:
+ context.close()
+ browser.close()
+ # This can be ok, we will try to grab what we could retrieve
+ pass
+ except Exception as e:
+ print ("other exception when page.goto")
+ print (str(e))
+ context.close()
+ browser.close()
+ raise PageUnloadable(url=url, status_code=None)
+
+
+ if response is None:
+ context.close()
+ browser.close()
+ print ("response object was none")
+ raise EmptyReply(url=url, status_code=None)
+
+ # Bug 2(?) Set the viewport size AFTER loading the page
+ self.page.set_viewport_size({"width": 1280, "height": 1024})
+
+ # Run Browser Steps here
+ self.iterate_browser_steps()
+
+ extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
+ time.sleep(extra_wait)
+
+
+ self.content = self.page.content()
+ self.status_code = response.status
+
+ if len(self.page.content().strip()) == 0:
+ context.close()
+ browser.close()
+ print ("Content was empty")
+ raise EmptyReply(url=url, status_code=None)
+
+ # Bug 2(?) Set the viewport size AFTER loading the page
+ self.page.set_viewport_size({"width": 1280, "height": 1024})
+
+ self.status_code = response.status
+ self.content = self.page.content()
+ self.headers = response.all_headers()
+
+ # So we can find an element on the page where its selector was entered manually (maybe not xPath etc)
+ if current_include_filters is not None:
+ self.page.evaluate("var include_filters={}".format(json.dumps(current_include_filters)))
+ else:
+ self.page.evaluate("var include_filters=''")
+
+ self.xpath_data = self.page.evaluate("async () => {" + self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors) + "}")
+
+ # Bug 3 in Playwright screenshot handling
+ # Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
+ # JPEG is better here because the screenshots can be very very large
+
+ # Screenshots also travel via the ws:// (websocket) meaning that the binary data is base64 encoded
+ # which will significantly increase the IO size between the server and client, it's recommended to use the lowest
+ # acceptable screenshot quality here
+ try:
+ # Quality set to 1 because it's not used, just used as a work-around for a bug, no need to change this.
+ self.page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024}, quality=1)
+ # The actual screenshot
+ self.screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
+ except Exception as e:
+ context.close()
+ browser.close()
+ raise ScreenshotUnavailable(url=url, status_code=None)
+
+ context.close()
+ browser.close()
+
+class base_html_webdriver(Fetcher):
if os.getenv("WEBDRIVER_URL"):
fetcher_description = "WebDriver Chrome/Javascript via '{}'".format(os.getenv("WEBDRIVER_URL"))
else:
@@ -65,67 +399,175 @@ class html_webdriver(Fetcher):
command_executor = ''
- def __init__(self):
- self.command_executor = os.getenv("WEBDRIVER_URL", 'http://browser-chrome:4444/wd/hub')
+ # Configs for Proxy setup
+ # In the ENV vars, is prefixed with "webdriver_", so it is for example "webdriver_sslProxy"
+ selenium_proxy_settings_mappings = ['proxyType', 'ftpProxy', 'httpProxy', 'noProxy',
+ 'proxyAutoconfigUrl', 'sslProxy', 'autodetect',
+ 'socksProxy', 'socksVersion', 'socksUsername', 'socksPassword']
+ proxy = None
- def run(self, url, timeout, request_headers):
+ def __init__(self, proxy_override=None):
+ super().__init__()
+ from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
- # check env for WEBDRIVER_URL
- driver = webdriver.Remote(
- command_executor=self.command_executor,
- desired_capabilities=DesiredCapabilities.CHROME)
+ # .strip('"') is going to save someone a lot of time when they accidently wrap the env value
+ self.command_executor = os.getenv("WEBDRIVER_URL", 'http://browser-chrome:4444/wd/hub').strip('"')
- try:
- driver.get(url)
- except WebDriverException as e:
- # Be sure we close the session window
- driver.quit()
- raise
+ # If any proxy settings are enabled, then we should setup the proxy object
+ proxy_args = {}
+ for k in self.selenium_proxy_settings_mappings:
+ v = os.getenv('webdriver_' + k, False)
+ if v:
+ proxy_args[k] = v.strip('"')
- # @todo - how to check this? is it possible?
- self.status_code = 200
+ # Map back standard HTTP_ and HTTPS_PROXY to webDriver httpProxy/sslProxy
+ if not proxy_args.get('webdriver_httpProxy') and self.system_http_proxy:
+ proxy_args['httpProxy'] = self.system_http_proxy
+ if not proxy_args.get('webdriver_sslProxy') and self.system_https_proxy:
+ proxy_args['httpsProxy'] = self.system_https_proxy
- # @todo - dom wait loaded?
- time.sleep(5)
- self.content = driver.page_source
+ # Allows override the proxy on a per-request basis
+ if proxy_override is not None:
+ proxy_args['httpProxy'] = proxy_override
- driver.quit()
+ if proxy_args:
+ self.proxy = SeleniumProxy(raw=proxy_args)
+ def run(self,
+ url,
+ timeout,
+ request_headers,
+ request_body,
+ request_method,
+ ignore_status_codes=False,
+ current_include_filters=None):
- def is_ready(self):
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.common.exceptions import WebDriverException
+ # request_body, request_method unused for now, until some magic in the future happens.
- driver = webdriver.Remote(
+ # check env for WEBDRIVER_URL
+ self.driver = webdriver.Remote(
+ command_executor=self.command_executor,
+ desired_capabilities=DesiredCapabilities.CHROME,
+ proxy=self.proxy)
+
+ try:
+ self.driver.get(url)
+ except WebDriverException as e:
+ # Be sure we close the session window
+ self.quit()
+ raise
+
+ self.driver.set_window_size(1280, 1024)
+ self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
+
+ if self.webdriver_js_execute_code is not None:
+ self.driver.execute_script(self.webdriver_js_execute_code)
+ # Selenium doesn't automatically wait for actions as good as Playwright, so wait again
+ self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
+
+ # @todo - how to check this? is it possible?
+ self.status_code = 200
+ # @todo somehow we should try to get this working for WebDriver
+ # raise EmptyReply(url=url, status_code=r.status_code)
+
+ # @todo - dom wait loaded?
+ time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay)
+ self.content = self.driver.page_source
+ self.headers = {}
+
+ self.screenshot = self.driver.get_screenshot_as_png()
+
+ # Does the connection to the webdriver work? run a test connection.
+ def is_ready(self):
+ from selenium import webdriver
+ from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
+
+ self.driver = webdriver.Remote(
command_executor=self.command_executor,
desired_capabilities=DesiredCapabilities.CHROME)
# driver.quit() seems to cause better exceptions
- driver.quit()
-
-
+ self.quit()
return True
+ def quit(self):
+ if self.driver:
+ try:
+ self.driver.quit()
+ except Exception as e:
+ print("Exception in chrome shutdown/quit" + str(e))
+
+
# "html_requests" is listed as the default fetcher in store.py!
class html_requests(Fetcher):
fetcher_description = "Basic fast Plaintext/HTTP Client"
- def run(self, url, timeout, request_headers):
- import requests
+ def __init__(self, proxy_override=None):
+ self.proxy_override = proxy_override
- r = requests.get(url,
- headers=request_headers,
- timeout=timeout,
- verify=False)
+ def run(self,
+ url,
+ timeout,
+ request_headers,
+ request_body,
+ request_method,
+ ignore_status_codes=False,
+ current_include_filters=None):
- html = r.text
+ # Make requests use a more modern looking user-agent
+ if not 'User-Agent' in request_headers:
+ request_headers['User-Agent'] = os.getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT",
+ 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36')
+ proxies = {}
+
+ # Allows override the proxy on a per-request basis
+ if self.proxy_override:
+ proxies = {'http': self.proxy_override, 'https': self.proxy_override, 'ftp': self.proxy_override}
+ else:
+ if self.system_http_proxy:
+ proxies['http'] = self.system_http_proxy
+ if self.system_https_proxy:
+ proxies['https'] = self.system_https_proxy
+
+ r = requests.request(method=request_method,
+ data=request_body,
+ url=url,
+ headers=request_headers,
+ timeout=timeout,
+ proxies=proxies,
+ verify=False)
+
+ # If the response did not tell us what encoding format to expect, Then use chardet to override what `requests` thinks.
+ # For example - some sites don't tell us it's utf-8, but return utf-8 content
+ # This seems to not occur when using webdriver/selenium, it seems to detect the text encoding more reliably.
+ # https://github.com/psf/requests/issues/1604 good info about requests encoding detection
+ if not r.headers.get('content-type') or not 'charset=' in r.headers.get('content-type'):
+ encoding = chardet.detect(r.content)['encoding']
+ if encoding:
+ r.encoding = encoding
+
+ if not r.content or not len(r.content):
+ raise EmptyReply(url=url, status_code=r.status_code)
# @todo test this
- if not r or not html or not len(html):
- raise EmptyReply(url)
+ # @todo maybe you really want to test zero-byte return pages?
+ if r.status_code != 200 and not ignore_status_codes:
+ # maybe check with content works?
+ raise Non200ErrorCodeReceived(url=url, status_code=r.status_code, page_html=r.text)
self.status_code = r.status_code
- self.content = html
+ self.content = r.text
+ self.headers = r.headers
+
+# Decide which is the 'real' HTML webdriver, this is more a system wide config
+# rather than site-specific.
+use_playwright_as_chrome_fetcher = os.getenv('PLAYWRIGHT_DRIVER_URL', False)
+if use_playwright_as_chrome_fetcher:
+ html_webdriver = base_html_playwright
+else:
+ html_webdriver = base_html_webdriver
diff --git a/changedetectionio/diff.py b/changedetectionio/diff.py
new file mode 100644
index 00000000..61ab5c5b
--- /dev/null
+++ b/changedetectionio/diff.py
@@ -0,0 +1,52 @@
+# used for the notifications, the front-end is using a JS library
+
+import difflib
+
+
+def same_slicer(l, a, b):
+ if a == b:
+ return [l[a]]
+ else:
+ return l[a:b]
+
+# like .compare but a little different output
+def customSequenceMatcher(before, after, include_equal=False):
+ cruncher = difflib.SequenceMatcher(isjunk=lambda x: x in " \\t", a=before, b=after)
+
+ # @todo Line-by-line mode instead of buncghed, including `after` that is not in `before` (maybe unset?)
+ for tag, alo, ahi, blo, bhi in cruncher.get_opcodes():
+ if include_equal and tag == 'equal':
+ g = before[alo:ahi]
+ yield g
+ elif tag == 'delete':
+ g = ["(removed) " + i for i in same_slicer(before, alo, ahi)]
+ yield g
+ elif tag == 'replace':
+ g = ["(changed) " + i for i in same_slicer(before, alo, ahi)]
+ g += ["(into ) " + i for i in same_slicer(after, blo, bhi)]
+ yield g
+ elif tag == 'insert':
+ g = ["(added ) " + i for i in same_slicer(after, blo, bhi)]
+ yield g
+
+# only_differences - only return info about the differences, no context
+# line_feed_sep could be " " or "
" or "\n" etc
+def render_diff(previous_file, newest_file, include_equal=False, line_feed_sep="\n"):
+ with open(newest_file, 'r') as f:
+ newest_version_file_contents = f.read()
+ newest_version_file_contents = [line.rstrip() for line in newest_version_file_contents.splitlines()]
+
+ if previous_file:
+ with open(previous_file, 'r') as f:
+ previous_version_file_contents = f.read()
+ previous_version_file_contents = [line.rstrip() for line in previous_version_file_contents.splitlines()]
+ else:
+ previous_version_file_contents = ""
+
+ rendered_diff = customSequenceMatcher(previous_version_file_contents,
+ newest_version_file_contents,
+ include_equal)
+
+ # Recursively join lists
+ f = lambda L: line_feed_sep.join([f(x) if type(x) is list else x for x in L])
+ return f(rendered_diff)
diff --git a/changedetectionio/fetch_site_status.py b/changedetectionio/fetch_site_status.py
index fc8c1e6e..68762f45 100644
--- a/changedetectionio/fetch_site_status.py
+++ b/changedetectionio/fetch_site_status.py
@@ -1,72 +1,68 @@
-import time
-from changedetectionio import content_fetcher
import hashlib
-from inscriptis import get_text
-import urllib3
-from . import html_tools
+import logging
+import os
import re
+import time
+import urllib3
+
+from changedetectionio import content_fetcher, html_tools
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
+class FilterNotFoundInResponse(ValueError):
+ def __init__(self, msg):
+ ValueError.__init__(self, msg)
+
+
# Some common stuff here that can be moved to a base class
+# (set_proxy_from_list)
class perform_site_check():
+ screenshot = None
+ xpath_data = None
def __init__(self, *args, datastore, **kwargs):
super().__init__(*args, **kwargs)
self.datastore = datastore
- def strip_ignore_text(self, content, list_ignore_text):
- import re
- ignore = []
- ignore_regex = []
- for k in list_ignore_text:
-
- # Is it a regex?
- if k[0] == '/':
- ignore_regex.append(k.strip(" /"))
- else:
- ignore.append(k)
-
- output = []
- for line in content.splitlines():
-
- # Always ignore blank lines in this mode. (when this function gets called)
- if len(line.strip()):
- regex_matches = False
-
- # if any of these match, skip
- for regex in ignore_regex:
- try:
- if re.search(regex, line, re.IGNORECASE):
- regex_matches = True
- except Exception as e:
- continue
-
- if not regex_matches and not any(skip_text in line for skip_text in ignore):
- output.append(line.encode('utf8'))
-
- return "\n".encode('utf8').join(output)
+ # Doesn't look like python supports forward slash auto enclosure in re.findall
+ # So convert it to inline flag "foobar(?i)" type configuration
+ def forward_slash_enclosed_regex_to_options(self, regex):
+ res = re.search(r'^/(.*?)/(\w+)$', regex, re.IGNORECASE)
+ if res:
+ regex = res.group(1)
+ regex += '(?{})'.format(res.group(2))
+ else:
+ regex += '(?{})'.format('i')
+ return regex
def run(self, uuid):
- timestamp = int(time.time()) # used for storage etc too
-
+ from copy import deepcopy
changed_detected = False
+ screenshot = False # as bytes
stripped_text_from_html = ""
- watch = self.datastore.data['watching'][uuid]
+ # DeepCopy so we can be sure we don't accidently change anything by reference
+ watch = deepcopy(self.datastore.data['watching'].get(uuid))
- update_obj = {'previous_md5': self.datastore.data['watching'][uuid]['previous_md5'],
- 'history': {},
- "last_checked": timestamp
- }
+ if not watch:
+ return
- extra_headers = self.datastore.get_val(uuid, 'headers')
+ # Protect against file:// access
+ if re.search(r'^file', watch.get('url', ''), re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
+ raise Exception(
+ "file:// type access is denied for security reasons."
+ )
+
+ # Unset any existing notification error
+ update_obj = {'last_notification_error': False, 'last_error': False}
+
+ extra_headers = watch.get('headers', [])
# Tweak the base config with the per-watch ones
- request_headers = self.datastore.data['settings']['headers'].copy()
+ request_headers = deepcopy(self.datastore.data['settings']['headers'])
request_headers.update(extra_headers)
# https://github.com/psf/requests/issues/4525
@@ -75,105 +71,246 @@ class perform_site_check():
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
- # @todo check the failures are really handled how we expect
+ timeout = self.datastore.data['settings']['requests'].get('timeout')
+ url = watch.link
+
+ request_body = self.datastore.data['watching'][uuid].get('body')
+ request_method = self.datastore.data['watching'][uuid].get('method')
+ ignore_status_codes = self.datastore.data['watching'][uuid].get('ignore_status_codes', False)
+
+ # source: support
+ is_source = False
+ if url.startswith('source:'):
+ url = url.replace('source:', '')
+ is_source = True
+
+ # Pluggable content fetcher
+ prefer_backend = watch.get('fetch_backend')
+ if hasattr(content_fetcher, prefer_backend):
+ klass = getattr(content_fetcher, prefer_backend)
else:
- timeout = self.datastore.data['settings']['requests']['timeout']
- url = self.datastore.get_val(uuid, 'url')
+ # If the klass doesnt exist, just use a default
+ klass = getattr(content_fetcher, "html_requests")
- # Pluggable content fetcher
- prefer_backend = watch['fetch_backend']
- if hasattr(content_fetcher, prefer_backend):
- klass = getattr(content_fetcher, prefer_backend)
- else:
- # If the klass doesnt exist, just use a default
- klass = getattr(content_fetcher, "html_requests")
+ proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=uuid)
+ proxy_url = None
+ if proxy_id:
+ proxy_url = self.datastore.proxy_list.get(proxy_id).get('url')
+ print("UUID {} Using proxy {}".format(uuid, proxy_url))
+ fetcher = klass(proxy_override=proxy_url)
- fetcher = klass()
- fetcher.run(url, timeout, request_headers)
- # Fetching complete, now filters
- # @todo move to class / maybe inside of fetcher abstract base?
+ # Configurable per-watch or global extra delay before extracting text (for webDriver types)
+ system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
+ if watch['webdriver_delay'] is not None:
+ fetcher.render_extract_delay = watch.get('webdriver_delay')
+ elif system_webdriver_delay is not None:
+ fetcher.render_extract_delay = system_webdriver_delay
- # @note: I feel like the following should be in a more obvious chain system
- # - Check filter text
- # - Is the checksum different?
- # - Do we convert to JSON?
- # https://stackoverflow.com/questions/41817578/basic-method-chaining ?
- # return content().textfilter().jsonextract().checksumcompare() ?
+ # Possible conflict
+ if prefer_backend == 'html_webdriver':
+ fetcher.browser_steps = watch.get('browser_steps', None)
+ fetcher.browser_steps_screenshot_path = os.path.join(self.datastore.datastore_path, uuid)
- is_html = True
- css_filter_rule = watch['css_filter']
- if css_filter_rule and len(css_filter_rule.strip()):
- if 'json:' in css_filter_rule:
- stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, jsonpath_filter=css_filter_rule)
+ if watch.get('webdriver_js_execute_code') is not None and watch.get('webdriver_js_execute_code').strip():
+ fetcher.webdriver_js_execute_code = watch.get('webdriver_js_execute_code')
+
+ fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, watch.get('include_filters'))
+ fetcher.quit()
+
+ self.screenshot = fetcher.screenshot
+ self.xpath_data = fetcher.xpath_data
+
+ # Fetching complete, now filters
+ # @todo move to class / maybe inside of fetcher abstract base?
+
+ # @note: I feel like the following should be in a more obvious chain system
+ # - Check filter text
+ # - Is the checksum different?
+ # - Do we convert to JSON?
+ # https://stackoverflow.com/questions/41817578/basic-method-chaining ?
+ # return content().textfilter().jsonextract().checksumcompare() ?
+
+ is_json = 'application/json' in fetcher.headers.get('Content-Type', '')
+ is_html = not is_json
+
+ # source: support, basically treat it as plaintext
+ if is_source:
+ is_html = False
+ is_json = False
+
+ include_filters_rule = watch.get('include_filters', [])
+ # include_filters_rule = watch['include_filters']
+ subtractive_selectors = watch.get(
+ "subtractive_selectors", []
+ ) + self.datastore.data["settings"]["application"].get(
+ "global_subtractive_selectors", []
+ )
+
+ has_filter_rule = include_filters_rule and len("".join(include_filters_rule).strip())
+ has_subtractive_selectors = subtractive_selectors and len(subtractive_selectors[0].strip())
+
+ if is_json and not has_filter_rule:
+ include_filters_rule.append("json:$")
+ has_filter_rule = True
+
+ if has_filter_rule:
+ json_filter_prefixes = ['json:', 'jq:']
+ for filter in include_filters_rule:
+ if any(prefix in filter for prefix in json_filter_prefixes):
+ stripped_text_from_html += html_tools.extract_json_as_string(content=fetcher.content, json_filter=filter)
is_html = False
- else:
- # CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
- stripped_text_from_html = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
- if is_html:
- # CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
- html_content = fetcher.content
- if css_filter_rule and len(css_filter_rule.strip()):
- html_content = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
+ if is_html or is_source:
- # get_text() via inscriptis
- stripped_text_from_html = get_text(html_content)
+ # CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
+ fetcher.content = html_tools.workarounds_for_obfuscations(fetcher.content)
+ html_content = fetcher.content
- # We rely on the actual text in the html output.. many sites have random script vars etc,
- # in the future we'll implement other mechanisms.
-
- update_obj["last_check_status"] = fetcher.get_last_status_code()
- update_obj["last_error"] = False
-
-
- # If there's text to skip
- # @todo we could abstract out the get_text() to handle this cleaner
- if len(watch['ignore_text']):
- stripped_text_from_html = self.strip_ignore_text(stripped_text_from_html, watch['ignore_text'])
+ # If not JSON, and if it's not text/plain..
+ if 'text/plain' in fetcher.headers.get('Content-Type', '').lower():
+ # Don't run get_text or xpath/css filters on plaintext
+ stripped_text_from_html = html_content
else:
- stripped_text_from_html = stripped_text_from_html.encode('utf8')
+ # Then we assume HTML
+ if has_filter_rule:
+ html_content = ""
+ for filter_rule in include_filters_rule:
+ # For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
+ if filter_rule[0] == '/' or filter_rule.startswith('xpath:'):
+ html_content += html_tools.xpath_filter(xpath_filter=filter_rule.replace('xpath:', ''),
+ html_content=fetcher.content,
+ append_pretty_line_formatting=not is_source)
+ else:
+ # CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
+ html_content += html_tools.include_filters(include_filters=filter_rule,
+ html_content=fetcher.content,
+ append_pretty_line_formatting=not is_source)
+ if not html_content.strip():
+ raise FilterNotFoundInResponse(include_filters_rule)
+ if has_subtractive_selectors:
+ html_content = html_tools.element_removal(subtractive_selectors, html_content)
+
+ if is_source:
+ stripped_text_from_html = html_content
+ else:
+ # extract text
+ do_anchor = self.datastore.data["settings"]["application"].get("render_anchor_tag_content", False)
+ stripped_text_from_html = \
+ html_tools.html_to_text(
+ html_content,
+ render_anchor_tag_content=do_anchor
+ )
+
+ # Re #340 - return the content before the 'ignore text' was applied
+ text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
+
+ # Treat pages with no renderable text content as a change? No by default
+ empty_pages_are_a_change = self.datastore.data['settings']['application'].get('empty_pages_are_a_change', False)
+ if not is_json and not empty_pages_are_a_change and len(stripped_text_from_html.strip()) == 0:
+ raise content_fetcher.ReplyWithContentButNoText(url=url, status_code=fetcher.get_last_status_code(), screenshot=screenshot)
+
+ # We rely on the actual text in the html output.. many sites have random script vars etc,
+ # in the future we'll implement other mechanisms.
+
+ update_obj["last_check_status"] = fetcher.get_last_status_code()
+
+ # If there's text to skip
+ # @todo we could abstract out the get_text() to handle this cleaner
+ text_to_ignore = watch.get('ignore_text', []) + self.datastore.data['settings']['application'].get('global_ignore_text', [])
+ if len(text_to_ignore):
+ stripped_text_from_html = html_tools.strip_ignore_text(stripped_text_from_html, text_to_ignore)
+ else:
+ stripped_text_from_html = stripped_text_from_html.encode('utf8')
+
+ # 615 Extract text by regex
+ extract_text = watch.get('extract_text', [])
+ if len(extract_text) > 0:
+ regex_matched_output = []
+ for s_re in extract_text:
+ # incase they specified something in '/.../x'
+ regex = self.forward_slash_enclosed_regex_to_options(s_re)
+ result = re.findall(regex.encode('utf-8'), stripped_text_from_html)
+
+ for l in result:
+ if type(l) is tuple:
+ # @todo - some formatter option default (between groups)
+ regex_matched_output += list(l) + [b'\n']
+ else:
+ # @todo - some formatter option default (between each ungrouped result)
+ regex_matched_output += [l] + [b'\n']
+
+ # Now we will only show what the regex matched
+ stripped_text_from_html = b''
+ text_content_before_ignored_filter = b''
+ if regex_matched_output:
+ # @todo some formatter for presentation?
+ stripped_text_from_html = b''.join(regex_matched_output)
+ text_content_before_ignored_filter = stripped_text_from_html
+
+ # Re #133 - if we should strip whitespaces from triggering the change detected comparison
+ if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
+ fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
+ else:
fetched_md5 = hashlib.md5(stripped_text_from_html).hexdigest()
- blocked_by_not_found_trigger_text = False
+ ############ Blocking rules, after checksum #################
+ blocked = False
- if len(watch['trigger_text']):
- blocked_by_not_found_trigger_text = True
- for line in watch['trigger_text']:
- # Because JSON wont serialize a re.compile object
- if line[0] == '/' and line[-1] == '/':
- regex = re.compile(line.strip('/'), re.IGNORECASE)
- # Found it? so we don't wait for it anymore
- r = re.search(regex, str(stripped_text_from_html))
- if r:
- blocked_by_not_found_trigger_text = False
- break
+ trigger_text = watch.get('trigger_text', [])
+ if len(trigger_text):
+ # Assume blocked
+ blocked = True
+ # Filter and trigger works the same, so reuse it
+ # It should return the line numbers that match
+ result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
+ wordlist=trigger_text,
+ mode="line numbers")
+ # Unblock if the trigger was found
+ if result:
+ blocked = False
- elif line.lower() in str(stripped_text_from_html).lower():
- # We found it don't wait for it.
- blocked_by_not_found_trigger_text = False
- break
+ text_should_not_be_present = watch.get('text_should_not_be_present', [])
+ if len(text_should_not_be_present):
+ # If anything matched, then we should block a change from happening
+ result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
+ wordlist=text_should_not_be_present,
+ mode="line numbers")
+ if result:
+ blocked = True
+ # The main thing that all this at the moment comes down to :)
+ if watch.get('previous_md5') != fetched_md5:
+ changed_detected = True
- # could be None or False depending on JSON type
- # On the first run of a site, watch['previous_md5'] will be an empty string
- if not blocked_by_not_found_trigger_text and watch['previous_md5'] != fetched_md5:
- changed_detected = True
+ # Looks like something changed, but did it match all the rules?
+ if blocked:
+ changed_detected = False
- # Don't confuse people by updating as last-changed, when it actually just changed from None..
- if self.datastore.get_val(uuid, 'previous_md5'):
- update_obj["last_changed"] = timestamp
+ # Extract title as title
+ if is_html:
+ if self.datastore.data['settings']['application'].get('extract_title_as_title') or watch['extract_title_as_title']:
+ if not watch['title'] or not len(watch['title']):
+ update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
- update_obj["previous_md5"] = fetched_md5
+ if changed_detected:
+ if watch.get('check_unique_lines', False):
+ has_unique_lines = watch.lines_contain_something_unique_compared_to_history(lines=stripped_text_from_html.splitlines())
+ # One or more lines? unsure?
+ if not has_unique_lines:
+ logging.debug("check_unique_lines: UUID {} didnt have anything new setting change_detected=False".format(uuid))
+ changed_detected = False
+ else:
+ logging.debug("check_unique_lines: UUID {} had unique content".format(uuid))
- # Extract title as title
- if is_html:
- if self.datastore.data['settings']['application']['extract_title_as_title'] or watch['extract_title_as_title']:
- if not watch['title'] or not len(watch['title']):
- update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
+ # Always record the new checksum
+ update_obj["previous_md5"] = fetched_md5
+ # On the first run of a site, watch['previous_md5'] will be None, set it the current one.
+ if not watch.get('previous_md5'):
+ watch['previous_md5'] = fetched_md5
- return changed_detected, update_obj, stripped_text_from_html
+ return changed_detected, update_obj, text_content_before_ignored_filter
diff --git a/changedetectionio/forms.py b/changedetectionio/forms.py
index 46b6977c..c6c58828 100644
--- a/changedetectionio/forms.py
+++ b/changedetectionio/forms.py
@@ -1,39 +1,75 @@
-from wtforms import Form, SelectField, RadioField, BooleanField, StringField, PasswordField, validators, IntegerField, fields, TextAreaField, \
- Field
-from wtforms import widgets
-from wtforms.validators import ValidationError
-from wtforms.fields import html5
-from changedetectionio import content_fetcher
+import os
import re
+from wtforms import (
+ BooleanField,
+ Form,
+ IntegerField,
+ RadioField,
+ SelectField,
+ StringField,
+ SubmitField,
+ TextAreaField,
+ fields,
+ validators,
+ widgets
+)
+from wtforms.fields import FieldList
+from wtforms.validators import ValidationError
+
+# default
+# each select
 -
- -
+## Web Site Change Detection, Monitoring and Notification.
-## Self-hosted open source change monitoring of web pages.
+Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
-_Know when web pages change! Stay ontop of new information!_
-
-Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
+[
-
+## Web Site Change Detection, Monitoring and Notification.
-## Self-hosted open source change monitoring of web pages.
+Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
-_Know when web pages change! Stay ontop of new information!_
-
-Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
+[ ](https://lemonade.changedetection.io/start?src=pip)
-
](https://lemonade.changedetection.io/start?src=pip)
- +[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://lemonade.changedetection.io/start)
+
#### Example use cases
-Know when ...
-
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
+
+#### Key Features
+
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
-**Get monitoring now!**
```bash
-$ pip3 install changedetection.io
+$ pip3 install changedetection.io
```
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
@@ -44,28 +54,5 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
-### Features
-- Website monitoring
-- Change detection of content and analyses
-- Filters on change (Select by CSS or JSON)
-- Triggers (Wait for text, wait for regex)
-- Notification support
-- JSON API Monitoring
-- Parse JSON embedded in HTML
-- (Reverse) Proxy support
-- Javascript support via WebDriver
-- RaspberriPi (arm v6/v7/64 support)
-
See https://github.com/dgtlmoon/changedetection.io for more information.
-
-
-### Support us
-
-Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-
-Please support us, even small amounts help a LOT.
-
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
-
-
+[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://lemonade.changedetection.io/start)
+
#### Example use cases
-Know when ...
-
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
+
+#### Key Features
+
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
-**Get monitoring now!**
```bash
-$ pip3 install changedetection.io
+$ pip3 install changedetection.io
```
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
@@ -44,28 +54,5 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
-### Features
-- Website monitoring
-- Change detection of content and analyses
-- Filters on change (Select by CSS or JSON)
-- Triggers (Wait for text, wait for regex)
-- Notification support
-- JSON API Monitoring
-- Parse JSON embedded in HTML
-- (Reverse) Proxy support
-- Javascript support via WebDriver
-- RaspberriPi (arm v6/v7/64 support)
-
See https://github.com/dgtlmoon/changedetection.io for more information.
-
-
-### Support us
-
-Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-
-Please support us, even small amounts help a LOT.
-
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
-
- diff --git a/README.md b/README.md
index 6939f4f1..03d734df 100644
--- a/README.md
+++ b/README.md
@@ -1,57 +1,105 @@
-# changedetection.io
+## Web Site Change Detection, Monitoring and Notification.
+
+_Live your data-life pro-actively, Detect website changes and perform meaningful actions, trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._
+
+
+[
diff --git a/README.md b/README.md
index 6939f4f1..03d734df 100644
--- a/README.md
+++ b/README.md
@@ -1,57 +1,105 @@
-# changedetection.io
+## Web Site Change Detection, Monitoring and Notification.
+
+_Live your data-life pro-actively, Detect website changes and perform meaningful actions, trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._
+
+
+[ ](https://lemonade.changedetection.io/start?src=github)
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+### Easily see what changed, examine by word, line, or individual character.
+
+[
](https://lemonade.changedetection.io/start?src=github)
-- Government department updates (changes are often only on their websites)
-- Local government news (changes are often only on their websites)
+### Easily see what changed, examine by word, line, or individual character.
+
+[ ](https://lemonade.changedetection.io/start?src=github)
+
+
+### Perform interactive browser steps
+
+Fill in text boxes, click buttons and more, setup your changedetection scenario.
+
+Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
+
+[
](https://lemonade.changedetection.io/start?src=github)
+
+
+### Perform interactive browser steps
+
+Fill in text boxes, click buttons and more, setup your changedetection scenario.
+
+Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
+
+[ ](https://lemonade.changedetection.io/start?src=github)
+
+After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
+Requires Playwright to be enabled.
+
+
+### Example use cases
+
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+- Get notified when certain keywords appear in Twitter search results
+- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
-_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver!_
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
-**Get monitoring now! super simple, one command!**
+#### Key Features
-Run the python code on your own machine by cloning this repository, or with docker and/or docker-compose
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
+- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
+- Send a screenshot with the notification when a change is detected in the web page
+
+We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
+
+Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
## Installation
### Docker
-_Note:_ We also use GitHub's container repository, because DockerHub has limited pull/downloads.
-
With Docker composer, just clone this repository and..
+
```bash
$ docker-compose up -d
```
+
Docker standalone
```bash
-$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
+`:latest` tag is our latest stable release, `:dev` tag is our bleeding edge `master` branch.
+
+### Windows
+
+See the install instructions at the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Microsoft-Windows
+
### Python Pip
Check out our pypi page https://pypi.org/project/changedetection.io/
@@ -69,10 +117,10 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
### Docker
```
-docker pull ghcr.io/dgtlmoon/changedetection.io
-docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+docker pull dgtlmoon/changedetection.io
+docker kill $(docker ps -a -f name=changedetection.io -q)
+docker rm $(docker ps -a -f name=changedetection.io -q)
+docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
### docker-compose
@@ -81,15 +129,15 @@ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/dat
docker-compose pull && docker-compose up -d
```
-## Screenshots
+See the wiki for more information https://github.com/dgtlmoon/changedetection.io/wiki
-Examining differences in content.
-
](https://lemonade.changedetection.io/start?src=github)
+
+After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
+Requires Playwright to be enabled.
+
+
+### Example use cases
+
+- Products and services have a change in pricing
+- _Out of stock notification_ and _Back In stock notification_
+- Governmental department updates (changes are often only on their websites)
- New software releases, security advisories when you're not on their mailing list.
- Festivals with changes
- Realestate listing changes
+- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
- COVID related news from government websites
+- University/organisation news from their website
- Detect and monitor changes in JSON API responses
-- API monitoring and alerting
+- JSON API monitoring and alerting
+- Changes in legal and other documents
+- Trigger API calls via notifications when text appears on a website
+- Glue together APIs using the JSON filter and JSON notifications
+- Create RSS feeds based on changes in web content
+- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
+- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
+- Get notified when certain keywords appear in Twitter search results
+- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
-_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver!_
+_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!_
-**Get monitoring now! super simple, one command!**
+#### Key Features
-Run the python code on your own machine by cloning this repository, or with docker and/or docker-compose
+- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
+- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
+- Switch between fast non-JS and Chrome JS based "fetchers"
+- Easily specify how often a site should be checked
+- Execute JS before extracting text (Good for logging in, see examples in the UI!)
+- Override Request Headers, Specify `POST` or `GET` and other methods
+- Use the "Visual Selector" to help target specific elements
+- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
+- Send a screenshot with the notification when a change is detected in the web page
+
+We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
+
+Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
## Installation
### Docker
-_Note:_ We also use GitHub's container repository, because DockerHub has limited pull/downloads.
-
With Docker composer, just clone this repository and..
+
```bash
$ docker-compose up -d
```
+
Docker standalone
```bash
-$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
+`:latest` tag is our latest stable release, `:dev` tag is our bleeding edge `master` branch.
+
+### Windows
+
+See the install instructions at the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Microsoft-Windows
+
### Python Pip
Check out our pypi page https://pypi.org/project/changedetection.io/
@@ -69,10 +117,10 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
### Docker
```
-docker pull ghcr.io/dgtlmoon/changedetection.io
-docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
-docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io ghcr.io/dgtlmoon/changedetection.io
+docker pull dgtlmoon/changedetection.io
+docker kill $(docker ps -a -f name=changedetection.io -q)
+docker rm $(docker ps -a -f name=changedetection.io -q)
+docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
```
### docker-compose
@@ -81,15 +129,15 @@ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/dat
docker-compose pull && docker-compose up -d
```
-## Screenshots
+See the wiki for more information https://github.com/dgtlmoon/changedetection.io/wiki
-Examining differences in content.
- +## Filters
-Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
+XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
+(We support LXML `re:test`, `re:math` and `re:replace`.)
-### Notifications
+## Notifications
ChangeDetection.io supports a massive amount of notifications (including email, office365, custom APIs, etc) when a web-page has a change detected thanks to the apprise library.
Simply set one or more notification URL's in the _[edit]_ tab of that watch.
@@ -107,25 +155,33 @@ Just some examples
json://someserver.com/custom-api
syslog://
-And everything else in this list!
+And everything else in this list!
-
+## Filters
-Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
+XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
+(We support LXML `re:test`, `re:math` and `re:replace`.)
-### Notifications
+## Notifications
ChangeDetection.io supports a massive amount of notifications (including email, office365, custom APIs, etc) when a web-page has a change detected thanks to the apprise library.
Simply set one or more notification URL's in the _[edit]_ tab of that watch.
@@ -107,25 +155,33 @@ Just some examples
json://someserver.com/custom-api
syslog://
-And everything else in this list!
+And everything else in this list!
- +
+ Now you can also customise your notification content and use Jinja2 templating for their title and body!
-### JSON API Monitoring
+## JSON API Monitoring
-Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
+Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
-
+
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
-
+
-#### Parse JSON embedded in HTML!
+### JSONPath or jq?
-When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
+For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specifc information on jq.
+
+One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
+
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
+
+### Parse JSON embedded in HTML!
+
+When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
```
@@ -135,42 +191,39 @@ When you enable a `json:` filter, you can even automatically extract and parse e
```
-`json:$.price` would give `23.50`, or you can extract the whole structure
+`json:$.price` or `jq:.price` would give `23.50`, or you can extract the whole structure
-### Proxy
+## Proxy Configuration
-A proxy for ChangeDetection.io can be configured by setting environment the
-`HTTP_PROXY`, `HTTPS_PROXY` variables, examples are also in the `docker-compose.yml`
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [BrightData proxy services where possible]( https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support)
-`NO_PROXY` exclude list can be specified by following `"localhost,192.168.0.0/24"`
+## Raspberry Pi support?
-as `docker run` with `-e`
-
-```
-docker run -d --restart always -e HTTPS_PROXY="socks5h://10.10.1.10:1080" -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
-```
-
-With `docker-compose`, see the `Proxy support example` in docker-compose.yml.
-
-For more information see https://docs.python-requests.org/en/master/user/advanced/#proxies
-
-This proxy support also extends to the notifications https://github.com/caronc/apprise/issues/387#issuecomment-841718867
+Raspberry Pi and linux/arm/v6 linux/arm/v7 arm64 devices are supported! See the wiki for [details](https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver)
-### RaspberriPi support?
-
-RaspberriPi and linux/arm/v6 linux/arm/v7 arm64 devices are supported!
-
-### Windows native support?
-
-Sorry not yet :( https://github.com/dgtlmoon/changedetection.io/labels/windows
-
-### Support us
+## Support us
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-Please support us, even small amounts help a LOT.
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
+Firstly, consider taking out a [change detection monthly subscription - unlimited checks and watches](https://lemonade.changedetection.io/start) , even if you don't use it, you still get the warm fuzzy feeling of helping out the project. (And who knows, you might just use it!)
-
Now you can also customise your notification content and use Jinja2 templating for their title and body!
-### JSON API Monitoring
+## JSON API Monitoring
-Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
+Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
-
+
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
-
+
-#### Parse JSON embedded in HTML!
+### JSONPath or jq?
-When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
+For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specifc information on jq.
+
+One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
+
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
+
+### Parse JSON embedded in HTML!
+
+When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
```
@@ -135,42 +191,39 @@ When you enable a `json:` filter, you can even automatically extract and parse e
```
-`json:$.price` would give `23.50`, or you can extract the whole structure
+`json:$.price` or `jq:.price` would give `23.50`, or you can extract the whole structure
-### Proxy
+## Proxy Configuration
-A proxy for ChangeDetection.io can be configured by setting environment the
-`HTTP_PROXY`, `HTTPS_PROXY` variables, examples are also in the `docker-compose.yml`
+See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [BrightData proxy services where possible]( https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support)
-`NO_PROXY` exclude list can be specified by following `"localhost,192.168.0.0/24"`
+## Raspberry Pi support?
-as `docker run` with `-e`
-
-```
-docker run -d --restart always -e HTTPS_PROXY="socks5h://10.10.1.10:1080" -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
-```
-
-With `docker-compose`, see the `Proxy support example` in docker-compose.yml.
-
-For more information see https://docs.python-requests.org/en/master/user/advanced/#proxies
-
-This proxy support also extends to the notifications https://github.com/caronc/apprise/issues/387#issuecomment-841718867
+Raspberry Pi and linux/arm/v6 linux/arm/v7 arm64 devices are supported! See the wiki for [details](https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver)
-### RaspberriPi support?
-
-RaspberriPi and linux/arm/v6 linux/arm/v7 arm64 devices are supported!
-
-### Windows native support?
-
-Sorry not yet :( https://github.com/dgtlmoon/changedetection.io/labels/windows
-
-### Support us
+## Support us
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
-Please support us, even small amounts help a LOT.
-BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
+Firstly, consider taking out a [change detection monthly subscription - unlimited checks and watches](https://lemonade.changedetection.io/start) , even if you don't use it, you still get the warm fuzzy feeling of helping out the project. (And who knows, you might just use it!)
- +
+## Commercial Support
+
+I offer commercial support, this software is depended on by network security, aerospace , data-science and data-journalist professionals just to name a few, please reach out at dgtlmoon@gmail.com for any enquiries, I am more than glad to work with your organisation to further the possibilities of what can be done with changedetection.io
+
+
+[release-shield]: https://img.shields.io:/github/v/release/dgtlmoon/changedetection.io?style=for-the-badge
+[docker-pulls]: https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io?style=for-the-badge
+[test-shield]: https://github.com/dgtlmoon/changedetection.io/actions/workflows/test-only.yml/badge.svg?branch=master
+
+[license-shield]: https://img.shields.io/github/license/dgtlmoon/changedetection.io.svg?style=for-the-badge
+[release-link]: https://github.com/dgtlmoon.com/changedetection.io/releases
+[docker-link]: https://hub.docker.com/r/dgtlmoon/changedetection.io
diff --git a/app.json b/app.json
new file mode 100644
index 00000000..a9249e88
--- /dev/null
+++ b/app.json
@@ -0,0 +1,21 @@
+{
+ "name": "ChangeDetection.io",
+ "description": "The best and simplest self-hosted open source website change detection monitoring and notification service.",
+ "keywords": [
+ "changedetection",
+ "website monitoring"
+ ],
+ "repository": "https://github.com/dgtlmoon/changedetection.io",
+ "success_url": "/",
+ "scripts": {
+ },
+ "env": {
+ },
+ "formation": {
+ "web": {
+ "quantity": 1,
+ "size": "free"
+ }
+ },
+ "image": "heroku/python"
+}
diff --git a/changedetection.py b/changedetection.py
index 5814f8fe..8455315a 100755
--- a/changedetection.py
+++ b/changedetection.py
@@ -1,97 +1,41 @@
#!/usr/bin/python3
-# Launch as a eventlet.wsgi server instance.
+# Entry-point for running from the CLI when not installed via Pip, Pip will handle the console_scripts entry_points's from setup.py
+# It's recommended to use `pip3 install changedetection.io` and start with `changedetection.py` instead, it will be linkd to your global path.
+# or Docker.
+# Read more https://github.com/dgtlmoon/changedetection.io/wiki
-import getopt
+from changedetectionio import changedetection
+import multiprocessing
+import signal
import os
-import sys
-import eventlet
-import eventlet.wsgi
-import changedetectionio
+def sigchld_handler(_signo, _stack_frame):
+ import sys
+ print('Shutdown: Got SIGCHLD')
+ # https://stackoverflow.com/questions/40453496/python-multiprocessing-capturing-signals-to-restart-child-processes-or-shut-do
+ pid, status = os.waitpid(-1, os.WNOHANG | os.WUNTRACED | os.WCONTINUED)
-from changedetectionio import store
-
-def main():
- ssl_mode = False
- port = os.environ.get('PORT') or 5000
- do_cleanup = False
-
- # Must be absolute so that send_from_directory doesnt try to make it relative to backend/
- datastore_path = os.path.join(os.getcwd(), "datastore")
-
- try:
- opts, args = getopt.getopt(sys.argv[1:], "csd:p:", "port")
- except getopt.GetoptError:
- print('backend.py -s SSL enable -p [port] -d [datastore path]')
- sys.exit(2)
-
- for opt, arg in opts:
- # if opt == '--purge':
- # Remove history, the actual files you need to delete manually.
- # for uuid, watch in datastore.data['watching'].items():
- # watch.update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': None})
-
- if opt == '-s':
- ssl_mode = True
-
- if opt == '-p':
- port = int(arg)
-
- if opt == '-d':
- datastore_path = arg
-
- # Cleanup (remove text files that arent in the index)
- if opt == '-c':
- do_cleanup = True
-
- # isnt there some @thingy to attach to each route to tell it, that this route needs a datastore
- app_config = {'datastore_path': datastore_path}
-
- if not os.path.isdir(app_config['datastore_path']):
- print ("ERROR: Directory path for the datastore '{}' does not exist, cannot start, please make sure the directory exists.\n"
- "Alternatively, use the -d parameter.".format(app_config['datastore_path']),file=sys.stderr)
- sys.exit(2)
-
- datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=changedetectionio.__version__)
- app = changedetectionio.changedetection_app(app_config, datastore)
-
- # Go into cleanup mode
- if do_cleanup:
- datastore.remove_unused_snapshots()
-
- app.config['datastore_path'] = datastore_path
-
-
- @app.context_processor
- def inject_version():
- return dict(right_sticky="v{}".format(datastore.data['version_tag']),
- new_version_available=app.config['NEW_VERSION_AVAILABLE'],
- has_password=datastore.data['settings']['application']['password'] != False
- )
-
- # Proxy sub-directory support
- # Set environment var USE_X_SETTINGS=1 on this script
- # And then in your proxy_pass settings
- #
- # proxy_set_header Host "localhost";
- # proxy_set_header X-Forwarded-Prefix /app;
-
- if os.getenv('USE_X_SETTINGS'):
- print ("USE_X_SETTINGS is ENABLED\n")
- from werkzeug.middleware.proxy_fix import ProxyFix
- app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
-
- if ssl_mode:
- # @todo finalise SSL config, but this should get you in the right direction if you need it.
- eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen(('', port)),
- certfile='cert.pem',
- keyfile='privkey.pem',
- server_side=True), app)
-
- else:
- eventlet.wsgi.server(eventlet.listen(('', int(port))), app)
+ print('Sub-process: pid %d status %d' % (pid, status))
+ if status != 0:
+ sys.exit(1)
+ raise SystemExit
if __name__ == '__main__':
- main()
+
+ #signal.signal(signal.SIGCHLD, sigchld_handler)
+
+ # The only way I could find to get Flask to shutdown, is to wrap it and then rely on the subsystem issuing SIGTERM/SIGKILL
+ parse_process = multiprocessing.Process(target=changedetection.main)
+ parse_process.daemon = True
+ parse_process.start()
+ import time
+
+ try:
+ while True:
+ time.sleep(1)
+
+ except KeyboardInterrupt:
+ #parse_process.terminate() not needed, because this process will issue it to the sub-process anyway
+ print ("Exited - CTRL+C")
diff --git a/changedetectionio/.gitignore b/changedetectionio/.gitignore
new file mode 100644
index 00000000..0d3c1d4e
--- /dev/null
+++ b/changedetectionio/.gitignore
@@ -0,0 +1,2 @@
+test-datastore
+package-lock.json
diff --git a/changedetectionio/__init__.py b/changedetectionio/__init__.py
index 1704ae1e..5d22a280 100644
--- a/changedetectionio/__init__.py
+++ b/changedetectionio/__init__.py
@@ -1,36 +1,41 @@
#!/usr/bin/python3
-
-# @todo logging
-# @todo extra options for url like , verify=False etc.
-# @todo enable https://urllib3.readthedocs.io/en/latest/user-guide.html#ssl as option?
-# @todo option for interval day/6 hour/etc
-# @todo on change detected, config for calling some API
-# @todo fetch title into json
-# https://distill.io/features
-# proxy per check
-# - flask_cors, itsdangerous,MarkupSafe
-
-import time
-import os
-import timeago
+import datetime
import flask_login
-from flask_login import login_required
-
+import logging
+import os
+import pytz
+import queue
import threading
+import time
+import timeago
+
+from copy import deepcopy
+from distutils.util import strtobool
+from feedgen.feed import FeedGenerator
from threading import Event
-import queue
+from flask import (
+ Flask,
+ abort,
+ flash,
+ make_response,
+ redirect,
+ render_template,
+ request,
+ send_from_directory,
+ session,
+ url_for,
+)
+from flask_compress import Compress as FlaskCompress
+from flask_login import login_required
+from flask_restful import abort, Api
+from flask_wtf import CSRFProtect
-from flask import Flask, render_template, request, send_from_directory, abort, redirect, url_for, flash
+from changedetectionio import html_tools
+from changedetectionio.api import api_v1
-from feedgen.feed import FeedGenerator
-from flask import make_response
-import datetime
-import pytz
-from copy import deepcopy
-
-__version__ = '0.39.3'
+__version__ = '0.39.22.1'
datastore = None
@@ -40,15 +45,17 @@ ticker_thread = None
extra_stylesheets = []
-update_q = queue.Queue()
-
+update_q = queue.PriorityQueue()
notification_q = queue.Queue()
-# Needs to be set this way because we also build and publish via pip
-base_path = os.path.dirname(os.path.realpath(__file__))
app = Flask(__name__,
- static_url_path="{}/static".format(base_path),
- template_folder="{}/templates".format(base_path))
+ static_url_path="",
+ static_folder="static",
+ template_folder="templates")
+from flask_compress import Compress
+
+# Super handy for compressing large BrowserSteps responses and others
+FlaskCompress(app)
# Stop browser caching of assets
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 0
@@ -63,7 +70,13 @@ app.config['LOGIN_DISABLED'] = False
# Disables caching of the templates
app.config['TEMPLATES_AUTO_RELOAD'] = True
+app.jinja_env.add_extension('jinja2.ext.loopcontrols')
+csrf = CSRFProtect()
+csrf.init_app(app)
+notification_debug_log=[]
+
+watch_api = Api(app, decorators=[csrf.exempt])
def init_app_secret(datastore_path):
secret = ""
@@ -82,16 +95,6 @@ def init_app_secret(datastore_path):
return secret
-# Remember python is by reference
-# populate_form in wtfors didnt work for me. (try using a setattr() obj type on datastore.watch?)
-def populate_form_from_watch(form, watch):
- for i in form.__dict__.keys():
- if i[0] != '_':
- p = getattr(form, i)
- if hasattr(p, 'data') and i in watch:
- setattr(p, "data", watch[i])
-
-
# We use the whole watch object from the store/JSON so we can see if there's some related status in terms of a thread
# running or something similar.
@app.template_filter('format_last_checked_time')
@@ -99,27 +102,28 @@ def _jinja2_filter_datetime(watch_obj, format="%Y-%m-%d %H:%M:%S"):
# Worker thread tells us which UUID it is currently processing.
for t in running_update_threads:
if t.current_uuid == watch_obj['uuid']:
- return "Checking now.."
+ return ' Checking now'
if watch_obj['last_checked'] == 0:
return 'Not yet'
return timeago.format(int(watch_obj['last_checked']), time.time())
-
-# @app.context_processor
-# def timeago():
-# def _timeago(lower_time, now):
-# return timeago.format(lower_time, now)
-# return dict(timeago=_timeago)
-
@app.template_filter('format_timestamp_timeago')
def _jinja2_filter_datetimestamp(timestamp, format="%Y-%m-%d %H:%M:%S"):
+ if timestamp == False:
+ return 'Not yet'
+
return timeago.format(timestamp, time.time())
- # return timeago.format(timestamp, time.time())
- # return datetime.datetime.utcfromtimestamp(timestamp).strftime(format)
+@app.template_filter('format_seconds_ago')
+def _jinja2_filter_seconds_precise(timestamp):
+ if timestamp == False:
+ return 'Not yet'
+ return format(int(time.time()-timestamp), ',d')
+
+# When nobody is logged in Flask-Login's current_user is set to an AnonymousUser object.
class User(flask_login.UserMixin):
id=None
@@ -128,7 +132,6 @@ class User(flask_login.UserMixin):
def get_user(self, email="defaultuser@changedetection.io"):
return self
def is_authenticated(self):
-
return True
def is_active(self):
return True
@@ -137,13 +140,21 @@ class User(flask_login.UserMixin):
def get_id(self):
return str(self.id)
+ # Compare given password against JSON store or Env var
def check_password(self, password):
- import hashlib
import base64
+ import hashlib
+
+ # Can be stored in env (for deployments) or in the general configs
+ raw_salt_pass = os.getenv("SALTED_PASS", False)
+
+ if not raw_salt_pass:
+ raw_salt_pass = datastore.data['settings']['application']['password']
+
+ raw_salt_pass = base64.b64decode(raw_salt_pass)
+
- # Getting the values back out
- raw_salt_pass = base64.b64decode(datastore.data['settings']['application']['password'])
salt_from_storage = raw_salt_pass[:32] # 32 is the length of the salt
# Use the exact same setup you used to generate the key, but this time put in the password to check
@@ -163,12 +174,36 @@ def changedetection_app(config=None, datastore_o=None):
global datastore
datastore = datastore_o
+ # so far just for read-only via tests, but this will be moved eventually to be the main source
+ # (instead of the global var)
+ app.config['DATASTORE']=datastore_o
+
#app.config.update(config or {})
login_manager = flask_login.LoginManager(app)
login_manager.login_view = 'login'
app.secret_key = init_app_secret(config['datastore_path'])
+
+ watch_api.add_resource(api_v1.WatchSingleHistory,
+ '/api/v1/watch/
+
+## Commercial Support
+
+I offer commercial support, this software is depended on by network security, aerospace , data-science and data-journalist professionals just to name a few, please reach out at dgtlmoon@gmail.com for any enquiries, I am more than glad to work with your organisation to further the possibilities of what can be done with changedetection.io
+
+
+[release-shield]: https://img.shields.io:/github/v/release/dgtlmoon/changedetection.io?style=for-the-badge
+[docker-pulls]: https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io?style=for-the-badge
+[test-shield]: https://github.com/dgtlmoon/changedetection.io/actions/workflows/test-only.yml/badge.svg?branch=master
+
+[license-shield]: https://img.shields.io/github/license/dgtlmoon/changedetection.io.svg?style=for-the-badge
+[release-link]: https://github.com/dgtlmoon.com/changedetection.io/releases
+[docker-link]: https://hub.docker.com/r/dgtlmoon/changedetection.io
diff --git a/app.json b/app.json
new file mode 100644
index 00000000..a9249e88
--- /dev/null
+++ b/app.json
@@ -0,0 +1,21 @@
+{
+ "name": "ChangeDetection.io",
+ "description": "The best and simplest self-hosted open source website change detection monitoring and notification service.",
+ "keywords": [
+ "changedetection",
+ "website monitoring"
+ ],
+ "repository": "https://github.com/dgtlmoon/changedetection.io",
+ "success_url": "/",
+ "scripts": {
+ },
+ "env": {
+ },
+ "formation": {
+ "web": {
+ "quantity": 1,
+ "size": "free"
+ }
+ },
+ "image": "heroku/python"
+}
diff --git a/changedetection.py b/changedetection.py
index 5814f8fe..8455315a 100755
--- a/changedetection.py
+++ b/changedetection.py
@@ -1,97 +1,41 @@
#!/usr/bin/python3
-# Launch as a eventlet.wsgi server instance.
+# Entry-point for running from the CLI when not installed via Pip, Pip will handle the console_scripts entry_points's from setup.py
+# It's recommended to use `pip3 install changedetection.io` and start with `changedetection.py` instead, it will be linkd to your global path.
+# or Docker.
+# Read more https://github.com/dgtlmoon/changedetection.io/wiki
-import getopt
+from changedetectionio import changedetection
+import multiprocessing
+import signal
import os
-import sys
-import eventlet
-import eventlet.wsgi
-import changedetectionio
+def sigchld_handler(_signo, _stack_frame):
+ import sys
+ print('Shutdown: Got SIGCHLD')
+ # https://stackoverflow.com/questions/40453496/python-multiprocessing-capturing-signals-to-restart-child-processes-or-shut-do
+ pid, status = os.waitpid(-1, os.WNOHANG | os.WUNTRACED | os.WCONTINUED)
-from changedetectionio import store
-
-def main():
- ssl_mode = False
- port = os.environ.get('PORT') or 5000
- do_cleanup = False
-
- # Must be absolute so that send_from_directory doesnt try to make it relative to backend/
- datastore_path = os.path.join(os.getcwd(), "datastore")
-
- try:
- opts, args = getopt.getopt(sys.argv[1:], "csd:p:", "port")
- except getopt.GetoptError:
- print('backend.py -s SSL enable -p [port] -d [datastore path]')
- sys.exit(2)
-
- for opt, arg in opts:
- # if opt == '--purge':
- # Remove history, the actual files you need to delete manually.
- # for uuid, watch in datastore.data['watching'].items():
- # watch.update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': None})
-
- if opt == '-s':
- ssl_mode = True
-
- if opt == '-p':
- port = int(arg)
-
- if opt == '-d':
- datastore_path = arg
-
- # Cleanup (remove text files that arent in the index)
- if opt == '-c':
- do_cleanup = True
-
- # isnt there some @thingy to attach to each route to tell it, that this route needs a datastore
- app_config = {'datastore_path': datastore_path}
-
- if not os.path.isdir(app_config['datastore_path']):
- print ("ERROR: Directory path for the datastore '{}' does not exist, cannot start, please make sure the directory exists.\n"
- "Alternatively, use the -d parameter.".format(app_config['datastore_path']),file=sys.stderr)
- sys.exit(2)
-
- datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=changedetectionio.__version__)
- app = changedetectionio.changedetection_app(app_config, datastore)
-
- # Go into cleanup mode
- if do_cleanup:
- datastore.remove_unused_snapshots()
-
- app.config['datastore_path'] = datastore_path
-
-
- @app.context_processor
- def inject_version():
- return dict(right_sticky="v{}".format(datastore.data['version_tag']),
- new_version_available=app.config['NEW_VERSION_AVAILABLE'],
- has_password=datastore.data['settings']['application']['password'] != False
- )
-
- # Proxy sub-directory support
- # Set environment var USE_X_SETTINGS=1 on this script
- # And then in your proxy_pass settings
- #
- # proxy_set_header Host "localhost";
- # proxy_set_header X-Forwarded-Prefix /app;
-
- if os.getenv('USE_X_SETTINGS'):
- print ("USE_X_SETTINGS is ENABLED\n")
- from werkzeug.middleware.proxy_fix import ProxyFix
- app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
-
- if ssl_mode:
- # @todo finalise SSL config, but this should get you in the right direction if you need it.
- eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen(('', port)),
- certfile='cert.pem',
- keyfile='privkey.pem',
- server_side=True), app)
-
- else:
- eventlet.wsgi.server(eventlet.listen(('', int(port))), app)
+ print('Sub-process: pid %d status %d' % (pid, status))
+ if status != 0:
+ sys.exit(1)
+ raise SystemExit
if __name__ == '__main__':
- main()
+
+ #signal.signal(signal.SIGCHLD, sigchld_handler)
+
+ # The only way I could find to get Flask to shutdown, is to wrap it and then rely on the subsystem issuing SIGTERM/SIGKILL
+ parse_process = multiprocessing.Process(target=changedetection.main)
+ parse_process.daemon = True
+ parse_process.start()
+ import time
+
+ try:
+ while True:
+ time.sleep(1)
+
+ except KeyboardInterrupt:
+ #parse_process.terminate() not needed, because this process will issue it to the sub-process anyway
+ print ("Exited - CTRL+C")
diff --git a/changedetectionio/.gitignore b/changedetectionio/.gitignore
new file mode 100644
index 00000000..0d3c1d4e
--- /dev/null
+++ b/changedetectionio/.gitignore
@@ -0,0 +1,2 @@
+test-datastore
+package-lock.json
diff --git a/changedetectionio/__init__.py b/changedetectionio/__init__.py
index 1704ae1e..5d22a280 100644
--- a/changedetectionio/__init__.py
+++ b/changedetectionio/__init__.py
@@ -1,36 +1,41 @@
#!/usr/bin/python3
-
-# @todo logging
-# @todo extra options for url like , verify=False etc.
-# @todo enable https://urllib3.readthedocs.io/en/latest/user-guide.html#ssl as option?
-# @todo option for interval day/6 hour/etc
-# @todo on change detected, config for calling some API
-# @todo fetch title into json
-# https://distill.io/features
-# proxy per check
-# - flask_cors, itsdangerous,MarkupSafe
-
-import time
-import os
-import timeago
+import datetime
import flask_login
-from flask_login import login_required
-
+import logging
+import os
+import pytz
+import queue
import threading
+import time
+import timeago
+
+from copy import deepcopy
+from distutils.util import strtobool
+from feedgen.feed import FeedGenerator
from threading import Event
-import queue
+from flask import (
+ Flask,
+ abort,
+ flash,
+ make_response,
+ redirect,
+ render_template,
+ request,
+ send_from_directory,
+ session,
+ url_for,
+)
+from flask_compress import Compress as FlaskCompress
+from flask_login import login_required
+from flask_restful import abort, Api
+from flask_wtf import CSRFProtect
-from flask import Flask, render_template, request, send_from_directory, abort, redirect, url_for, flash
+from changedetectionio import html_tools
+from changedetectionio.api import api_v1
-from feedgen.feed import FeedGenerator
-from flask import make_response
-import datetime
-import pytz
-from copy import deepcopy
-
-__version__ = '0.39.3'
+__version__ = '0.39.22.1'
datastore = None
@@ -40,15 +45,17 @@ ticker_thread = None
extra_stylesheets = []
-update_q = queue.Queue()
-
+update_q = queue.PriorityQueue()
notification_q = queue.Queue()
-# Needs to be set this way because we also build and publish via pip
-base_path = os.path.dirname(os.path.realpath(__file__))
app = Flask(__name__,
- static_url_path="{}/static".format(base_path),
- template_folder="{}/templates".format(base_path))
+ static_url_path="",
+ static_folder="static",
+ template_folder="templates")
+from flask_compress import Compress
+
+# Super handy for compressing large BrowserSteps responses and others
+FlaskCompress(app)
# Stop browser caching of assets
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 0
@@ -63,7 +70,13 @@ app.config['LOGIN_DISABLED'] = False
# Disables caching of the templates
app.config['TEMPLATES_AUTO_RELOAD'] = True
+app.jinja_env.add_extension('jinja2.ext.loopcontrols')
+csrf = CSRFProtect()
+csrf.init_app(app)
+notification_debug_log=[]
+
+watch_api = Api(app, decorators=[csrf.exempt])
def init_app_secret(datastore_path):
secret = ""
@@ -82,16 +95,6 @@ def init_app_secret(datastore_path):
return secret
-# Remember python is by reference
-# populate_form in wtfors didnt work for me. (try using a setattr() obj type on datastore.watch?)
-def populate_form_from_watch(form, watch):
- for i in form.__dict__.keys():
- if i[0] != '_':
- p = getattr(form, i)
- if hasattr(p, 'data') and i in watch:
- setattr(p, "data", watch[i])
-
-
# We use the whole watch object from the store/JSON so we can see if there's some related status in terms of a thread
# running or something similar.
@app.template_filter('format_last_checked_time')
@@ -99,27 +102,28 @@ def _jinja2_filter_datetime(watch_obj, format="%Y-%m-%d %H:%M:%S"):
# Worker thread tells us which UUID it is currently processing.
for t in running_update_threads:
if t.current_uuid == watch_obj['uuid']:
- return "Checking now.."
+ return ' Checking now'
if watch_obj['last_checked'] == 0:
return 'Not yet'
return timeago.format(int(watch_obj['last_checked']), time.time())
-
-# @app.context_processor
-# def timeago():
-# def _timeago(lower_time, now):
-# return timeago.format(lower_time, now)
-# return dict(timeago=_timeago)
-
@app.template_filter('format_timestamp_timeago')
def _jinja2_filter_datetimestamp(timestamp, format="%Y-%m-%d %H:%M:%S"):
+ if timestamp == False:
+ return 'Not yet'
+
return timeago.format(timestamp, time.time())
- # return timeago.format(timestamp, time.time())
- # return datetime.datetime.utcfromtimestamp(timestamp).strftime(format)
+@app.template_filter('format_seconds_ago')
+def _jinja2_filter_seconds_precise(timestamp):
+ if timestamp == False:
+ return 'Not yet'
+ return format(int(time.time()-timestamp), ',d')
+
+# When nobody is logged in Flask-Login's current_user is set to an AnonymousUser object.
class User(flask_login.UserMixin):
id=None
@@ -128,7 +132,6 @@ class User(flask_login.UserMixin):
def get_user(self, email="defaultuser@changedetection.io"):
return self
def is_authenticated(self):
-
return True
def is_active(self):
return True
@@ -137,13 +140,21 @@ class User(flask_login.UserMixin):
def get_id(self):
return str(self.id)
+ # Compare given password against JSON store or Env var
def check_password(self, password):
- import hashlib
import base64
+ import hashlib
+
+ # Can be stored in env (for deployments) or in the general configs
+ raw_salt_pass = os.getenv("SALTED_PASS", False)
+
+ if not raw_salt_pass:
+ raw_salt_pass = datastore.data['settings']['application']['password']
+
+ raw_salt_pass = base64.b64decode(raw_salt_pass)
+
- # Getting the values back out
- raw_salt_pass = base64.b64decode(datastore.data['settings']['application']['password'])
salt_from_storage = raw_salt_pass[:32] # 32 is the length of the salt
# Use the exact same setup you used to generate the key, but this time put in the password to check
@@ -163,12 +174,36 @@ def changedetection_app(config=None, datastore_o=None):
global datastore
datastore = datastore_o
+ # so far just for read-only via tests, but this will be moved eventually to be the main source
+ # (instead of the global var)
+ app.config['DATASTORE']=datastore_o
+
#app.config.update(config or {})
login_manager = flask_login.LoginManager(app)
login_manager.login_view = 'login'
app.secret_key = init_app_secret(config['datastore_path'])
+
+ watch_api.add_resource(api_v1.WatchSingleHistory,
+ '/api/v1/watch/