mirror of
https://github.com/dgtlmoon/changedetection.io.git
synced 2025-11-08 18:47:32 +00:00
Compare commits
1 Commits
0.39.20.1
...
proxies-js
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
4b50ebb5c9 |
46
.github/workflows/test-container-build.yml
vendored
46
.github/workflows/test-container-build.yml
vendored
@@ -1,46 +0,0 @@
|
|||||||
name: ChangeDetection.io Container Build Test
|
|
||||||
|
|
||||||
# Triggers the workflow on push or pull request events
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
paths:
|
|
||||||
- requirements.txt
|
|
||||||
- Dockerfile
|
|
||||||
|
|
||||||
# Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
|
|
||||||
# @todo: some kind of path filter for requirements.txt and Dockerfile
|
|
||||||
jobs:
|
|
||||||
test-container-build:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2
|
|
||||||
- name: Set up Python 3.9
|
|
||||||
uses: actions/setup-python@v2
|
|
||||||
with:
|
|
||||||
python-version: 3.9
|
|
||||||
|
|
||||||
# Just test that the build works, some libraries won't compile on ARM/rPi etc
|
|
||||||
- name: Set up QEMU
|
|
||||||
uses: docker/setup-qemu-action@v1
|
|
||||||
with:
|
|
||||||
image: tonistiigi/binfmt:latest
|
|
||||||
platforms: all
|
|
||||||
|
|
||||||
- name: Set up Docker Buildx
|
|
||||||
id: buildx
|
|
||||||
uses: docker/setup-buildx-action@v1
|
|
||||||
with:
|
|
||||||
install: true
|
|
||||||
version: latest
|
|
||||||
driver-opts: image=moby/buildkit:master
|
|
||||||
|
|
||||||
- name: Test that the docker containers can build
|
|
||||||
id: docker_build
|
|
||||||
uses: docker/build-push-action@v2
|
|
||||||
# https://github.com/docker/build-push-action#customizing
|
|
||||||
with:
|
|
||||||
context: ./
|
|
||||||
file: ./Dockerfile
|
|
||||||
platforms: linux/arm/v7,linux/arm/v6,linux/amd64,linux/arm64,
|
|
||||||
cache-from: type=local,src=/tmp/.buildx-cache
|
|
||||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
|
||||||
12
.github/workflows/test-only.yml
vendored
12
.github/workflows/test-only.yml
vendored
@@ -1,25 +1,28 @@
|
|||||||
name: ChangeDetection.io App Test
|
name: ChangeDetection.io Test
|
||||||
|
|
||||||
# Triggers the workflow on push or pull request events
|
# Triggers the workflow on push or pull request events
|
||||||
on: [push, pull_request]
|
on: [push, pull_request]
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
test-application:
|
test-build:
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
|
|
||||||
- uses: actions/checkout@v2
|
- uses: actions/checkout@v2
|
||||||
- name: Set up Python 3.9
|
- name: Set up Python 3.9
|
||||||
uses: actions/setup-python@v2
|
uses: actions/setup-python@v2
|
||||||
with:
|
with:
|
||||||
python-version: 3.9
|
python-version: 3.9
|
||||||
|
|
||||||
|
- name: Show env vars
|
||||||
|
run: set
|
||||||
|
|
||||||
- name: Install dependencies
|
- name: Install dependencies
|
||||||
run: |
|
run: |
|
||||||
python -m pip install --upgrade pip
|
python -m pip install --upgrade pip
|
||||||
pip install flake8 pytest
|
pip install flake8 pytest
|
||||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||||
|
|
||||||
- name: Lint with flake8
|
- name: Lint with flake8
|
||||||
run: |
|
run: |
|
||||||
# stop the build if there are Python syntax errors or undefined names
|
# stop the build if there are Python syntax errors or undefined names
|
||||||
@@ -36,4 +39,7 @@ jobs:
|
|||||||
# Each test is totally isolated and performs its own cleanup/reset
|
# Each test is totally isolated and performs its own cleanup/reset
|
||||||
cd changedetectionio; ./run_all_tests.sh
|
cd changedetectionio; ./run_all_tests.sh
|
||||||
|
|
||||||
|
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||||
|
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||||
|
|
||||||
|
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||||
|
|||||||
11
Dockerfile
11
Dockerfile
@@ -5,14 +5,13 @@ FROM python:3.8-slim as builder
|
|||||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||||
|
|
||||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||||
g++ \
|
libssl-dev \
|
||||||
|
libffi-dev \
|
||||||
gcc \
|
gcc \
|
||||||
libc-dev \
|
libc-dev \
|
||||||
libffi-dev \
|
|
||||||
libssl-dev \
|
|
||||||
libxslt-dev \
|
libxslt-dev \
|
||||||
make \
|
zlib1g-dev \
|
||||||
zlib1g-dev
|
g++
|
||||||
|
|
||||||
RUN mkdir /install
|
RUN mkdir /install
|
||||||
WORKDIR /install
|
WORKDIR /install
|
||||||
@@ -23,7 +22,7 @@ RUN pip install --target=/dependencies -r /requirements.txt
|
|||||||
|
|
||||||
# Playwright is an alternative to Selenium
|
# Playwright is an alternative to Selenium
|
||||||
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
||||||
RUN pip install --target=/dependencies playwright~=1.26 \
|
RUN pip install --target=/dependencies playwright~=1.24 \
|
||||||
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
||||||
|
|
||||||
# Final image stage
|
# Final image stage
|
||||||
|
|||||||
@@ -33,7 +33,7 @@ _Need an actual Chrome runner with Javascript support? We support fetching via W
|
|||||||
#### Key Features
|
#### Key Features
|
||||||
|
|
||||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JsonPath rules
|
||||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||||
- Easily specify how often a site should be checked
|
- Easily specify how often a site should be checked
|
||||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||||
|
|||||||
70
README.md
70
README.md
@@ -12,14 +12,11 @@ Know when important content changes, we support notifications via Discord, Teleg
|
|||||||
|
|
||||||
[**Don't have time? Let us host it for you! try our $6.99/month subscription - use our proxies and support!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
[**Don't have time? Let us host it for you! try our $6.99/month subscription - use our proxies and support!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
||||||
|
|
||||||
- Chrome browser included.
|
|
||||||
- Super fast, no registration needed setup.
|
|
||||||
- Start watching and receiving change notifications instantly.
|
|
||||||
|
|
||||||
|
|
||||||
Easily see what changed, examine by word, line, or individual character.
|
- Automatic Updates, Automatic Backups, No Heroku "paused application", don't miss a change!
|
||||||
|
- Javascript browser included
|
||||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
- Unlimited checks and watches!
|
||||||
|
|
||||||
|
|
||||||
#### Example use cases
|
#### Example use cases
|
||||||
@@ -47,18 +44,22 @@ _Need an actual Chrome runner with Javascript support? We support fetching via W
|
|||||||
#### Key Features
|
#### Key Features
|
||||||
|
|
||||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JsonPath rules
|
||||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||||
- Easily specify how often a site should be checked
|
- Easily specify how often a site should be checked
|
||||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||||
- Use the "Visual Selector" to help target specific elements
|
- Use the "Visual Selector" to help target specific elements
|
||||||
- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
|
|
||||||
|
|
||||||
We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
|
|
||||||
|
|
||||||
## Screenshots
|
## Screenshots
|
||||||
|
|
||||||
|
### Examine differences in content.
|
||||||
|
|
||||||
|
Easily see what changed, examine by word, line, or individual character.
|
||||||
|
|
||||||
|
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||||
|
|
||||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||||
|
|
||||||
### Filter by elements using the Visual Selector tool.
|
### Filter by elements using the Visual Selector tool.
|
||||||
@@ -121,7 +122,7 @@ See the wiki for more information https://github.com/dgtlmoon/changedetection.io
|
|||||||
|
|
||||||
|
|
||||||
## Filters
|
## Filters
|
||||||
XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
XPath, JSONPath and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||||
|
|
||||||
(We support LXML `re:test`, `re:math` and `re:replace`.)
|
(We support LXML `re:test`, `re:math` and `re:replace`.)
|
||||||
|
|
||||||
@@ -151,7 +152,7 @@ Now you can also customise your notification content!
|
|||||||
|
|
||||||
## JSON API Monitoring
|
## JSON API Monitoring
|
||||||
|
|
||||||
Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
|
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@@ -159,52 +160,9 @@ This will re-parse the JSON and apply formatting to the text, making it super ea
|
|||||||
|
|
||||||
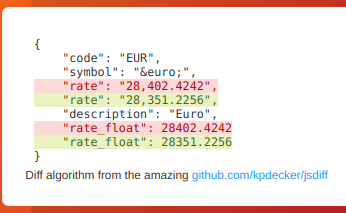
|

|
||||||
|
|
||||||
### JSONPath or jq?
|
|
||||||
|
|
||||||
For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more information on jq.
|
|
||||||
|
|
||||||
The example below adds the price in dollars to each item in the JSON data, and then filters to only show items that are greater than 10.
|
|
||||||
|
|
||||||
#### Sample input data from API
|
|
||||||
```
|
|
||||||
{
|
|
||||||
"items": [
|
|
||||||
{
|
|
||||||
"name": "Product A",
|
|
||||||
"priceInCents": 2500
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"name": "Product B",
|
|
||||||
"priceInCents": 500
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"name": "Product C",
|
|
||||||
"priceInCents": 2000
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### Sample jq
|
|
||||||
`jq:.items[] | . + { "priceInDollars": (.priceInCents / 100) } | select(.priceInDollars > 10)`
|
|
||||||
|
|
||||||
#### Sample output data
|
|
||||||
```
|
|
||||||
{
|
|
||||||
"name": "Product A",
|
|
||||||
"priceInCents": 2500,
|
|
||||||
"priceInDollars": 25
|
|
||||||
}
|
|
||||||
{
|
|
||||||
"name": "Product C",
|
|
||||||
"priceInCents": 2000,
|
|
||||||
"priceInDollars": 20
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Parse JSON embedded in HTML!
|
### Parse JSON embedded in HTML!
|
||||||
|
|
||||||
When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||||
|
|
||||||
```
|
```
|
||||||
<html>
|
<html>
|
||||||
@@ -214,7 +172,7 @@ When you enable a `json:` or `jq:` filter, you can even automatically extract an
|
|||||||
</script>
|
</script>
|
||||||
```
|
```
|
||||||
|
|
||||||
`json:$.price` or `jq:.price` would give `23.50`, or you can extract the whole structure
|
`json:$.price` would give `23.50`, or you can extract the whole structure
|
||||||
|
|
||||||
## Proxy configuration
|
## Proxy configuration
|
||||||
|
|
||||||
|
|||||||
@@ -33,7 +33,7 @@ from flask_wtf import CSRFProtect
|
|||||||
from changedetectionio import html_tools
|
from changedetectionio import html_tools
|
||||||
from changedetectionio.api import api_v1
|
from changedetectionio.api import api_v1
|
||||||
|
|
||||||
__version__ = '0.39.20.1'
|
__version__ = '0.39.19.1'
|
||||||
|
|
||||||
datastore = None
|
datastore = None
|
||||||
|
|
||||||
@@ -661,16 +661,15 @@ def changedetection_app(config=None, datastore_o=None):
|
|||||||
|
|
||||||
default = deepcopy(datastore.data['settings'])
|
default = deepcopy(datastore.data['settings'])
|
||||||
if datastore.proxy_list is not None:
|
if datastore.proxy_list is not None:
|
||||||
available_proxies = list(datastore.proxy_list.keys())
|
|
||||||
# When enabled
|
# When enabled
|
||||||
system_proxy = datastore.data['settings']['requests']['proxy']
|
system_proxy = datastore.data['settings']['requests']['proxy']
|
||||||
# In the case it doesnt exist anymore
|
# In the case it doesnt exist anymore
|
||||||
if not system_proxy in available_proxies:
|
if not any([system_proxy in tup for tup in datastore.proxy_list]):
|
||||||
system_proxy = None
|
system_proxy = None
|
||||||
|
|
||||||
default['requests']['proxy'] = system_proxy if system_proxy is not None else available_proxies[0]
|
default['requests']['proxy'] = system_proxy if system_proxy is not None else datastore.proxy_list[0][0]
|
||||||
# Used by the form handler to keep or remove the proxy settings
|
# Used by the form handler to keep or remove the proxy settings
|
||||||
default['proxy_list'] = available_proxies[0]
|
default['proxy_list'] = datastore.proxy_list
|
||||||
|
|
||||||
|
|
||||||
# Don't use form.data on POST so that it doesnt overrid the checkbox status from the POST status
|
# Don't use form.data on POST so that it doesnt overrid the checkbox status from the POST status
|
||||||
@@ -685,10 +684,7 @@ def changedetection_app(config=None, datastore_o=None):
|
|||||||
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
||||||
del form.requests.form.proxy
|
del form.requests.form.proxy
|
||||||
else:
|
else:
|
||||||
form.requests.form.proxy.choices = []
|
form.requests.form.proxy.choices = datastore.proxy_list
|
||||||
for p in datastore.proxy_list:
|
|
||||||
form.requests.form.proxy.choices.append(tuple((p, datastore.proxy_list[p]['label'])))
|
|
||||||
|
|
||||||
|
|
||||||
if request.method == 'POST':
|
if request.method == 'POST':
|
||||||
# Password unset is a GET, but we can lock the session to a salted env password to always need the password
|
# Password unset is a GET, but we can lock the session to a salted env password to always need the password
|
||||||
@@ -1444,19 +1440,16 @@ def ticker_thread_check_time_launch_checks():
|
|||||||
if not uuid in running_uuids and uuid not in [q_uuid for p,q_uuid in update_q.queue]:
|
if not uuid in running_uuids and uuid not in [q_uuid for p,q_uuid in update_q.queue]:
|
||||||
|
|
||||||
# Proxies can be set to have a limit on seconds between which they can be called
|
# Proxies can be set to have a limit on seconds between which they can be called
|
||||||
watch_proxy = datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
watch_proxy = watch.get('proxy')
|
||||||
if watch_proxy and watch_proxy in list(datastore.proxy_list.keys()):
|
if watch_proxy and any([watch_proxy in p for p in datastore.proxy_list]):
|
||||||
# Proxy may also have some threshold minimum
|
# Proxy may also have some threshold minimum
|
||||||
proxy_list_reuse_time_minimum = int(datastore.proxy_list.get(watch_proxy, {}).get('reuse_time_minimum', 0))
|
proxy_list_reuse_time_minimum = int(datastore.proxy_list.get(watch_proxy, {}).get('reuse_time_minimum', 0))
|
||||||
if proxy_list_reuse_time_minimum:
|
if proxy_list_reuse_time_minimum:
|
||||||
proxy_last_used_time = proxy_last_called_time.get(watch_proxy, 0)
|
proxy_last_used_time = proxy_last_called_time.get(watch_proxy, 0)
|
||||||
time_since_proxy_used = int(time.time() - proxy_last_used_time)
|
time_since_proxy_used = time.time() - proxy_last_used_time
|
||||||
if time_since_proxy_used < proxy_list_reuse_time_minimum:
|
if time_since_proxy_used < proxy_list_reuse_time_minimum:
|
||||||
# Not enough time difference reached, skip this watch
|
# Not enough time difference reached, skip this watch
|
||||||
print("> Skipped UUID {} using proxy '{}', not enough time between proxy requests {}s/{}s".format(uuid,
|
print("Skipped UUID {} on proxy {}, not enough time between proxy requests".format(uuid, watch_proxy))
|
||||||
watch_proxy,
|
|
||||||
time_since_proxy_used,
|
|
||||||
proxy_list_reuse_time_minimum))
|
|
||||||
continue
|
continue
|
||||||
else:
|
else:
|
||||||
# Record the last used time
|
# Record the last used time
|
||||||
|
|||||||
@@ -316,7 +316,6 @@ class base_html_playwright(Fetcher):
|
|||||||
import playwright._impl._api_types
|
import playwright._impl._api_types
|
||||||
from playwright._impl._api_types import Error, TimeoutError
|
from playwright._impl._api_types import Error, TimeoutError
|
||||||
response = None
|
response = None
|
||||||
|
|
||||||
with sync_playwright() as p:
|
with sync_playwright() as p:
|
||||||
browser_type = getattr(p, self.browser_type)
|
browser_type = getattr(p, self.browser_type)
|
||||||
|
|
||||||
@@ -374,11 +373,8 @@ class base_html_playwright(Fetcher):
|
|||||||
print("response object was none")
|
print("response object was none")
|
||||||
raise EmptyReply(url=url, status_code=None)
|
raise EmptyReply(url=url, status_code=None)
|
||||||
|
|
||||||
|
# Bug 2(?) Set the viewport size AFTER loading the page
|
||||||
# Removed browser-set-size, seemed to be needed to make screenshots work reliably in older playwright versions
|
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||||
# Was causing exceptions like 'waiting for page but content is changing' etc
|
|
||||||
# https://www.browserstack.com/docs/automate/playwright/change-browser-window-size 1280x720 should be the default
|
|
||||||
|
|
||||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||||
time.sleep(extra_wait)
|
time.sleep(extra_wait)
|
||||||
|
|
||||||
@@ -402,13 +398,6 @@ class base_html_playwright(Fetcher):
|
|||||||
|
|
||||||
raise JSActionExceptions(status_code=response.status, screenshot=error_screenshot, message=str(e), url=url)
|
raise JSActionExceptions(status_code=response.status, screenshot=error_screenshot, message=str(e), url=url)
|
||||||
|
|
||||||
else:
|
|
||||||
# JS eval was run, now we also wait some time if possible to let the page settle
|
|
||||||
if self.render_extract_delay:
|
|
||||||
page.wait_for_timeout(self.render_extract_delay * 1000)
|
|
||||||
|
|
||||||
page.wait_for_timeout(500)
|
|
||||||
|
|
||||||
self.content = page.content()
|
self.content = page.content()
|
||||||
self.status_code = response.status
|
self.status_code = response.status
|
||||||
self.headers = response.all_headers()
|
self.headers = response.all_headers()
|
||||||
@@ -525,6 +514,8 @@ class base_html_webdriver(Fetcher):
|
|||||||
# Selenium doesn't automatically wait for actions as good as Playwright, so wait again
|
# Selenium doesn't automatically wait for actions as good as Playwright, so wait again
|
||||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||||
|
|
||||||
|
self.screenshot = self.driver.get_screenshot_as_png()
|
||||||
|
|
||||||
# @todo - how to check this? is it possible?
|
# @todo - how to check this? is it possible?
|
||||||
self.status_code = 200
|
self.status_code = 200
|
||||||
# @todo somehow we should try to get this working for WebDriver
|
# @todo somehow we should try to get this working for WebDriver
|
||||||
@@ -535,8 +526,6 @@ class base_html_webdriver(Fetcher):
|
|||||||
self.content = self.driver.page_source
|
self.content = self.driver.page_source
|
||||||
self.headers = {}
|
self.headers = {}
|
||||||
|
|
||||||
self.screenshot = self.driver.get_screenshot_as_png()
|
|
||||||
|
|
||||||
# Does the connection to the webdriver work? run a test connection.
|
# Does the connection to the webdriver work? run a test connection.
|
||||||
def is_ready(self):
|
def is_ready(self):
|
||||||
from selenium import webdriver
|
from selenium import webdriver
|
||||||
@@ -575,11 +564,6 @@ class html_requests(Fetcher):
|
|||||||
ignore_status_codes=False,
|
ignore_status_codes=False,
|
||||||
current_css_filter=None):
|
current_css_filter=None):
|
||||||
|
|
||||||
# Make requests use a more modern looking user-agent
|
|
||||||
if not 'User-Agent' in request_headers:
|
|
||||||
request_headers['User-Agent'] = os.getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT",
|
|
||||||
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36')
|
|
||||||
|
|
||||||
proxies = {}
|
proxies = {}
|
||||||
|
|
||||||
# Allows override the proxy on a per-request basis
|
# Allows override the proxy on a per-request basis
|
||||||
|
|||||||
@@ -20,6 +20,36 @@ class perform_site_check():
|
|||||||
super().__init__(*args, **kwargs)
|
super().__init__(*args, **kwargs)
|
||||||
self.datastore = datastore
|
self.datastore = datastore
|
||||||
|
|
||||||
|
# If there was a proxy list enabled, figure out what proxy_args/which proxy to use
|
||||||
|
# Returns the proxy as a URL
|
||||||
|
# if watch.proxy use that
|
||||||
|
# fetcher.proxy_override = watch.proxy or main config proxy
|
||||||
|
# Allows override the proxy on a per-request basis
|
||||||
|
# ALWAYS use the first one is nothing selected
|
||||||
|
|
||||||
|
def set_proxy_from_list(self, watch):
|
||||||
|
proxy_args = None
|
||||||
|
if self.datastore.proxy_list is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# If its a valid one
|
||||||
|
if any([watch['proxy'] in p for p in self.datastore.proxy_list]):
|
||||||
|
proxy_args = self.datastore.proxy_list.get(watch['proxy']).get('url')
|
||||||
|
|
||||||
|
# not valid (including None), try the system one
|
||||||
|
else:
|
||||||
|
system_proxy = self.datastore.data['settings']['requests']['proxy']
|
||||||
|
# Is not None and exists
|
||||||
|
if self.datastore.proxy_list.get():
|
||||||
|
proxy_args = self.datastore.proxy_list.get(system_proxy).get('url')
|
||||||
|
|
||||||
|
# Fallback - Did not resolve anything, use the first available
|
||||||
|
if proxy_args is None:
|
||||||
|
first_default = list(self.datastore.proxy_list)[0]
|
||||||
|
proxy_args = self.datastore.proxy_list.get(first_default).get('url')
|
||||||
|
|
||||||
|
return proxy_args
|
||||||
|
|
||||||
# Doesn't look like python supports forward slash auto enclosure in re.findall
|
# Doesn't look like python supports forward slash auto enclosure in re.findall
|
||||||
# So convert it to inline flag "foobar(?i)" type configuration
|
# So convert it to inline flag "foobar(?i)" type configuration
|
||||||
def forward_slash_enclosed_regex_to_options(self, regex):
|
def forward_slash_enclosed_regex_to_options(self, regex):
|
||||||
@@ -84,12 +114,9 @@ class perform_site_check():
|
|||||||
# If the klass doesnt exist, just use a default
|
# If the klass doesnt exist, just use a default
|
||||||
klass = getattr(content_fetcher, "html_requests")
|
klass = getattr(content_fetcher, "html_requests")
|
||||||
|
|
||||||
proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
proxy_url = self.set_proxy_from_list(watch)
|
||||||
proxy_url = None
|
if proxy_url:
|
||||||
if proxy_id:
|
|
||||||
proxy_url = self.datastore.proxy_list.get(proxy_id).get('url')
|
|
||||||
print ("UUID {} Using proxy {}".format(uuid, proxy_url))
|
print ("UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||||
|
|
||||||
fetcher = klass(proxy_override=proxy_url)
|
fetcher = klass(proxy_override=proxy_url)
|
||||||
|
|
||||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||||
@@ -141,9 +168,8 @@ class perform_site_check():
|
|||||||
has_filter_rule = True
|
has_filter_rule = True
|
||||||
|
|
||||||
if has_filter_rule:
|
if has_filter_rule:
|
||||||
json_filter_prefixes = ['json:', 'jq:']
|
if 'json:' in css_filter_rule:
|
||||||
if any(prefix in css_filter_rule for prefix in json_filter_prefixes):
|
stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, jsonpath_filter=css_filter_rule)
|
||||||
stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, json_filter=css_filter_rule)
|
|
||||||
is_html = False
|
is_html = False
|
||||||
|
|
||||||
if is_html or is_source:
|
if is_html or is_source:
|
||||||
|
|||||||
@@ -304,21 +304,6 @@ class ValidateCSSJSONXPATHInput(object):
|
|||||||
# Re #265 - maybe in the future fetch the page and offer a
|
# Re #265 - maybe in the future fetch the page and offer a
|
||||||
# warning/notice that its possible the rule doesnt yet match anything?
|
# warning/notice that its possible the rule doesnt yet match anything?
|
||||||
|
|
||||||
if 'jq:' in line:
|
|
||||||
if not self.allow_json:
|
|
||||||
raise ValidationError("jq not permitted in this field!")
|
|
||||||
|
|
||||||
import jq
|
|
||||||
input = line.replace('jq:', '')
|
|
||||||
|
|
||||||
try:
|
|
||||||
jq.compile(input)
|
|
||||||
except (ValueError) as e:
|
|
||||||
message = field.gettext('\'%s\' is not a valid jq expression. (%s)')
|
|
||||||
raise ValidationError(message % (input, str(e)))
|
|
||||||
except:
|
|
||||||
raise ValidationError("A system-error occurred when validating your jq expression")
|
|
||||||
|
|
||||||
|
|
||||||
class quickWatchForm(Form):
|
class quickWatchForm(Form):
|
||||||
url = fields.URLField('URL', validators=[validateURL()])
|
url = fields.URLField('URL', validators=[validateURL()])
|
||||||
|
|||||||
@@ -3,7 +3,6 @@ from typing import List
|
|||||||
|
|
||||||
from bs4 import BeautifulSoup
|
from bs4 import BeautifulSoup
|
||||||
from jsonpath_ng.ext import parse
|
from jsonpath_ng.ext import parse
|
||||||
import jq
|
|
||||||
import re
|
import re
|
||||||
from inscriptis import get_text
|
from inscriptis import get_text
|
||||||
from inscriptis.model.config import ParserConfig
|
from inscriptis.model.config import ParserConfig
|
||||||
@@ -80,26 +79,19 @@ def extract_element(find='title', html_content=''):
|
|||||||
return element_text
|
return element_text
|
||||||
|
|
||||||
#
|
#
|
||||||
def _parse_json(json_data, json_filter):
|
def _parse_json(json_data, jsonpath_filter):
|
||||||
if 'json:' in json_filter:
|
s=[]
|
||||||
jsonpath_expression = parse(json_filter.replace('json:', ''))
|
jsonpath_expression = parse(jsonpath_filter.replace('json:', ''))
|
||||||
match = jsonpath_expression.find(json_data)
|
match = jsonpath_expression.find(json_data)
|
||||||
return _get_stripped_text_from_json_match(match)
|
|
||||||
if 'jq:' in json_filter:
|
|
||||||
jq_expression = jq.compile(json_filter.replace('jq:', ''))
|
|
||||||
match = jq_expression.input(json_data).all()
|
|
||||||
return _get_stripped_text_from_json_match(match)
|
|
||||||
|
|
||||||
def _get_stripped_text_from_json_match(match):
|
|
||||||
s = []
|
|
||||||
# More than one result, we will return it as a JSON list.
|
# More than one result, we will return it as a JSON list.
|
||||||
if len(match) > 1:
|
if len(match) > 1:
|
||||||
for i in match:
|
for i in match:
|
||||||
s.append(i.value if hasattr(i, 'value') else i)
|
s.append(i.value)
|
||||||
|
|
||||||
# Single value, use just the value, as it could be later used in a token in notifications.
|
# Single value, use just the value, as it could be later used in a token in notifications.
|
||||||
if len(match) == 1:
|
if len(match) == 1:
|
||||||
s = match[0].value if hasattr(match[0], 'value') else match[0]
|
s = match[0].value
|
||||||
|
|
||||||
# Re #257 - Better handling where it does not exist, in the case the original 's' value was False..
|
# Re #257 - Better handling where it does not exist, in the case the original 's' value was False..
|
||||||
if not match:
|
if not match:
|
||||||
@@ -111,16 +103,16 @@ def _get_stripped_text_from_json_match(match):
|
|||||||
|
|
||||||
return stripped_text_from_html
|
return stripped_text_from_html
|
||||||
|
|
||||||
def extract_json_as_string(content, json_filter):
|
def extract_json_as_string(content, jsonpath_filter):
|
||||||
|
|
||||||
stripped_text_from_html = False
|
stripped_text_from_html = False
|
||||||
|
|
||||||
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded <script type=ldjson>
|
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded <script type=ldjson>
|
||||||
try:
|
try:
|
||||||
stripped_text_from_html = _parse_json(json.loads(content), json_filter)
|
stripped_text_from_html = _parse_json(json.loads(content), jsonpath_filter)
|
||||||
except json.JSONDecodeError:
|
except json.JSONDecodeError:
|
||||||
|
|
||||||
# Foreach <script json></script> blob.. just return the first that matches json_filter
|
# Foreach <script json></script> blob.. just return the first that matches jsonpath_filter
|
||||||
s = []
|
s = []
|
||||||
soup = BeautifulSoup(content, 'html.parser')
|
soup = BeautifulSoup(content, 'html.parser')
|
||||||
bs_result = soup.findAll('script')
|
bs_result = soup.findAll('script')
|
||||||
@@ -139,7 +131,7 @@ def extract_json_as_string(content, json_filter):
|
|||||||
# Just skip it
|
# Just skip it
|
||||||
continue
|
continue
|
||||||
else:
|
else:
|
||||||
stripped_text_from_html = _parse_json(json_data, json_filter)
|
stripped_text_from_html = _parse_json(json_data, jsonpath_filter)
|
||||||
if stripped_text_from_html:
|
if stripped_text_from_html:
|
||||||
break
|
break
|
||||||
|
|
||||||
|
|||||||
@@ -13,6 +13,10 @@ class model(dict):
|
|||||||
'watching': {},
|
'watching': {},
|
||||||
'settings': {
|
'settings': {
|
||||||
'headers': {
|
'headers': {
|
||||||
|
'User-Agent': getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT", 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'),
|
||||||
|
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
|
||||||
|
'Accept-Encoding': 'gzip, deflate', # No support for brolti in python requests yet.
|
||||||
|
'Accept-Language': 'en-GB,en-US;q=0.9,en;'
|
||||||
},
|
},
|
||||||
'requests': {
|
'requests': {
|
||||||
'timeout': int(getenv("DEFAULT_SETTINGS_REQUESTS_TIMEOUT", "45")), # Default 45 seconds
|
'timeout': int(getenv("DEFAULT_SETTINGS_REQUESTS_TIMEOUT", "45")), # Default 45 seconds
|
||||||
|
|||||||
@@ -48,48 +48,4 @@ pytest tests/test_errorhandling.py
|
|||||||
pytest tests/visualselector/test_fetch_data.py
|
pytest tests/visualselector/test_fetch_data.py
|
||||||
|
|
||||||
unset PLAYWRIGHT_DRIVER_URL
|
unset PLAYWRIGHT_DRIVER_URL
|
||||||
docker kill $$-test_browserless
|
docker kill $$-test_browserless
|
||||||
|
|
||||||
# Test proxy list handling, starting two squids on different ports
|
|
||||||
# Each squid adds a different header to the response, which is the main thing we test for.
|
|
||||||
docker run -d --name $$-squid-one --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf -p 3128:3128 ubuntu/squid:4.13-21.10_edge
|
|
||||||
docker run -d --name $$-squid-two --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf -p 3129:3128 ubuntu/squid:4.13-21.10_edge
|
|
||||||
|
|
||||||
|
|
||||||
# So, basic HTTP as env var test
|
|
||||||
export HTTP_PROXY=http://localhost:3128
|
|
||||||
export HTTPS_PROXY=http://localhost:3128
|
|
||||||
pytest tests/proxy_list/test_proxy.py
|
|
||||||
docker logs $$-squid-one 2>/dev/null|grep one.changedetection.io
|
|
||||||
if [ $? -ne 0 ]
|
|
||||||
then
|
|
||||||
echo "Did not see a request to one.changedetection.io in the squid logs (while checking env vars HTTP_PROXY/HTTPS_PROXY)"
|
|
||||||
fi
|
|
||||||
unset HTTP_PROXY
|
|
||||||
unset HTTPS_PROXY
|
|
||||||
|
|
||||||
|
|
||||||
# 2nd test actually choose the preferred proxy from proxies.json
|
|
||||||
cp tests/proxy_list/proxies.json-example ./test-datastore/proxies.json
|
|
||||||
# Makes a watch use a preferred proxy
|
|
||||||
pytest tests/proxy_list/test_multiple_proxy.py
|
|
||||||
|
|
||||||
# Should be a request in the default "first" squid
|
|
||||||
docker logs $$-squid-one 2>/dev/null|grep chosen.changedetection.io
|
|
||||||
if [ $? -ne 0 ]
|
|
||||||
then
|
|
||||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy)"
|
|
||||||
fi
|
|
||||||
|
|
||||||
# And one in the 'second' squid (user selects this as preferred)
|
|
||||||
docker logs $$-squid-two 2>/dev/null|grep chosen.changedetection.io
|
|
||||||
if [ $? -ne 0 ]
|
|
||||||
then
|
|
||||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy)"
|
|
||||||
fi
|
|
||||||
|
|
||||||
# @todo - test system override proxy selection and watch defaults, setup a 3rd squid?
|
|
||||||
docker kill $$-squid-one
|
|
||||||
docker kill $$-squid-two
|
|
||||||
|
|
||||||
|
|
||||||
@@ -81,6 +81,8 @@ class ChangeDetectionStore:
|
|||||||
except (FileNotFoundError, json.decoder.JSONDecodeError):
|
except (FileNotFoundError, json.decoder.JSONDecodeError):
|
||||||
if include_default_watches:
|
if include_default_watches:
|
||||||
print("Creating JSON store at", self.datastore_path)
|
print("Creating JSON store at", self.datastore_path)
|
||||||
|
|
||||||
|
self.add_watch(url='http://www.quotationspage.com/random.php', tag='test')
|
||||||
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
||||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt', tag='changedetection.io')
|
self.add_watch(url='https://changedetection.io/CHANGELOG.txt', tag='changedetection.io')
|
||||||
|
|
||||||
@@ -438,36 +440,6 @@ class ChangeDetectionStore:
|
|||||||
print ("Registered proxy list", list(self.proxy_list.keys()))
|
print ("Registered proxy list", list(self.proxy_list.keys()))
|
||||||
|
|
||||||
|
|
||||||
def get_preferred_proxy_for_watch(self, uuid):
|
|
||||||
"""
|
|
||||||
Returns the preferred proxy by ID key
|
|
||||||
:param uuid: UUID
|
|
||||||
:return: proxy "key" id
|
|
||||||
"""
|
|
||||||
|
|
||||||
proxy_id = None
|
|
||||||
if self.proxy_list is None:
|
|
||||||
return None
|
|
||||||
|
|
||||||
# If its a valid one
|
|
||||||
watch = self.data['watching'].get(uuid)
|
|
||||||
|
|
||||||
if watch.get('proxy') and watch.get('proxy') in list(self.proxy_list.keys()):
|
|
||||||
return watch.get('proxy')
|
|
||||||
|
|
||||||
# not valid (including None), try the system one
|
|
||||||
else:
|
|
||||||
system_proxy_id = self.data['settings']['requests'].get('proxy')
|
|
||||||
# Is not None and exists
|
|
||||||
if self.proxy_list.get(system_proxy_id):
|
|
||||||
return system_proxy_id
|
|
||||||
|
|
||||||
# Fallback - Did not resolve anything, use the first available
|
|
||||||
if system_proxy_id is None:
|
|
||||||
first_default = list(self.proxy_list)[0]
|
|
||||||
return first_default
|
|
||||||
|
|
||||||
return None
|
|
||||||
|
|
||||||
# Run all updates
|
# Run all updates
|
||||||
# IMPORTANT - Each update could be run even when they have a new install and the schema is correct
|
# IMPORTANT - Each update could be run even when they have a new install and the schema is correct
|
||||||
@@ -575,11 +547,3 @@ class ChangeDetectionStore:
|
|||||||
continue
|
continue
|
||||||
return
|
return
|
||||||
|
|
||||||
|
|
||||||
# We incorrectly used common header overrides that should only apply to Requests
|
|
||||||
# These are now handled in content_fetcher::html_requests and shouldnt be passed to Playwright/Selenium
|
|
||||||
def update_7(self):
|
|
||||||
# These were hard-coded in early versions
|
|
||||||
for v in ['User-Agent', 'Accept', 'Accept-Encoding', 'Accept-Language']:
|
|
||||||
if self.data['settings']['headers'].get(v):
|
|
||||||
del self.data['settings']['headers'][v]
|
|
||||||
|
|||||||
@@ -77,7 +77,6 @@
|
|||||||
<span class="pure-form-message-inline">
|
<span class="pure-form-message-inline">
|
||||||
<p>Use the <strong>Basic</strong> method (default) where your watched site doesn't need Javascript to render.</p>
|
<p>Use the <strong>Basic</strong> method (default) where your watched site doesn't need Javascript to render.</p>
|
||||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||||
Tip: <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support">Connect using BrightData Proxies, find out more here.</a>
|
|
||||||
</span>
|
</span>
|
||||||
</div>
|
</div>
|
||||||
{% if form.proxy %}
|
{% if form.proxy %}
|
||||||
@@ -184,12 +183,8 @@ User-Agent: wonderbra 1.0") }}
|
|||||||
<span class="pure-form-message-inline">
|
<span class="pure-form-message-inline">
|
||||||
<ul>
|
<ul>
|
||||||
<li>CSS - Limit text to this CSS rule, only text matching this CSS rule is included.</li>
|
<li>CSS - Limit text to this CSS rule, only text matching this CSS rule is included.</li>
|
||||||
<li>JSON - Limit text to this JSON rule, using either <a href="https://pypi.org/project/jsonpath-ng/" target="new">JSONPath</a> or <a href="https://stedolan.github.io/jq/" target="new">jq</a>.
|
<li>JSON - Limit text to this JSON rule, using <a href="https://pypi.org/project/jsonpath-ng/">JSONPath</a>, prefix with <code>"json:"</code>, use <code>json:$</code> to force re-formatting if required, <a
|
||||||
<ul>
|
href="https://jsonpath.com/" target="new">test your JSONPath here</a></li>
|
||||||
<li>JSONPath: Prefix with <code>json:</code>, use <code>json:$</code> to force re-formatting if required, <a href="https://jsonpath.com/" target="new">test your JSONPath here</a>.</li>
|
|
||||||
<li>jq: Prefix with <code>jq:</code> and <a href="https://jqplay.org/" target="new">test your jq here</a>. Using <a href="https://stedolan.github.io/jq/" target="new">jq</a> allows for complex filtering and processing of JSON data with built-in functions, regex, filtering, and more. See examples and documentation <a href="https://stedolan.github.io/jq/manual/" target="new">here</a>.</li>
|
|
||||||
</ul>
|
|
||||||
</li>
|
|
||||||
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash,
|
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash,
|
||||||
<ul>
|
<ul>
|
||||||
<li>Example: <code>//*[contains(@class, 'sametext')]</code> or <code>xpath://*[contains(@class, 'sametext')]</code>, <a
|
<li>Example: <code>//*[contains(@class, 'sametext')]</code> or <code>xpath://*[contains(@class, 'sametext')]</code>, <a
|
||||||
@@ -198,7 +193,7 @@ User-Agent: wonderbra 1.0") }}
|
|||||||
</ul>
|
</ul>
|
||||||
</li>
|
</li>
|
||||||
</ul>
|
</ul>
|
||||||
Please be sure that you thoroughly understand how to write CSS, JSONPath, XPath, or jq selector rules before filing an issue on GitHub! <a
|
Please be sure that you thoroughly understand how to write CSS or JSONPath, XPath selector rules before filing an issue on GitHub! <a
|
||||||
href="https://github.com/dgtlmoon/changedetection.io/wiki/CSS-Selector-help">here for more CSS selector help</a>.<br/>
|
href="https://github.com/dgtlmoon/changedetection.io/wiki/CSS-Selector-help">here for more CSS selector help</a>.<br/>
|
||||||
</span>
|
</span>
|
||||||
</div>
|
</div>
|
||||||
|
|||||||
@@ -99,8 +99,6 @@
|
|||||||
<p>Use the <strong>Basic</strong> method (default) where your watched sites don't need Javascript to render.</p>
|
<p>Use the <strong>Basic</strong> method (default) where your watched sites don't need Javascript to render.</p>
|
||||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||||
</span>
|
</span>
|
||||||
<br/>
|
|
||||||
Tip: <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support">Connect using BrightData Proxies, find out more here.</a>
|
|
||||||
</div>
|
</div>
|
||||||
<fieldset class="pure-group" id="webdriver-override-options">
|
<fieldset class="pure-group" id="webdriver-override-options">
|
||||||
<div class="pure-form-message-inline">
|
<div class="pure-form-message-inline">
|
||||||
|
|||||||
@@ -1,2 +0,0 @@
|
|||||||
"""Tests for the app."""
|
|
||||||
|
|
||||||
@@ -1,14 +0,0 @@
|
|||||||
#!/usr/bin/python3
|
|
||||||
|
|
||||||
from .. import conftest
|
|
||||||
|
|
||||||
#def pytest_addoption(parser):
|
|
||||||
# parser.addoption("--url_suffix", action="store", default="identifier for request")
|
|
||||||
|
|
||||||
|
|
||||||
#def pytest_generate_tests(metafunc):
|
|
||||||
# # This is called for every test. Only get/set command line arguments
|
|
||||||
# # if the argument is specified in the list of test "fixturenames".
|
|
||||||
# option_value = metafunc.config.option.url_suffix
|
|
||||||
# if 'url_suffix' in metafunc.fixturenames and option_value is not None:
|
|
||||||
# metafunc.parametrize("url_suffix", [option_value])
|
|
||||||
@@ -1,10 +0,0 @@
|
|||||||
{
|
|
||||||
"proxy-one": {
|
|
||||||
"label": "One",
|
|
||||||
"url": "http://127.0.0.1:3128"
|
|
||||||
},
|
|
||||||
"proxy-two": {
|
|
||||||
"label": "two",
|
|
||||||
"url": "http://127.0.0.1:3129"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,41 +0,0 @@
|
|||||||
acl localnet src 0.0.0.1-0.255.255.255 # RFC 1122 "this" network (LAN)
|
|
||||||
acl localnet src 10.0.0.0/8 # RFC 1918 local private network (LAN)
|
|
||||||
acl localnet src 100.64.0.0/10 # RFC 6598 shared address space (CGN)
|
|
||||||
acl localnet src 169.254.0.0/16 # RFC 3927 link-local (directly plugged) machines
|
|
||||||
acl localnet src 172.16.0.0/12 # RFC 1918 local private network (LAN)
|
|
||||||
acl localnet src 192.168.0.0/16 # RFC 1918 local private network (LAN)
|
|
||||||
acl localnet src fc00::/7 # RFC 4193 local private network range
|
|
||||||
acl localnet src fe80::/10 # RFC 4291 link-local (directly plugged) machines
|
|
||||||
acl localnet src 159.65.224.174
|
|
||||||
acl SSL_ports port 443
|
|
||||||
acl Safe_ports port 80 # http
|
|
||||||
acl Safe_ports port 21 # ftp
|
|
||||||
acl Safe_ports port 443 # https
|
|
||||||
acl Safe_ports port 70 # gopher
|
|
||||||
acl Safe_ports port 210 # wais
|
|
||||||
acl Safe_ports port 1025-65535 # unregistered ports
|
|
||||||
acl Safe_ports port 280 # http-mgmt
|
|
||||||
acl Safe_ports port 488 # gss-http
|
|
||||||
acl Safe_ports port 591 # filemaker
|
|
||||||
acl Safe_ports port 777 # multiling http
|
|
||||||
acl CONNECT method CONNECT
|
|
||||||
|
|
||||||
http_access deny !Safe_ports
|
|
||||||
http_access deny CONNECT !SSL_ports
|
|
||||||
http_access allow localhost manager
|
|
||||||
http_access deny manager
|
|
||||||
http_access allow localhost
|
|
||||||
http_access allow localnet
|
|
||||||
http_access deny all
|
|
||||||
http_port 3128
|
|
||||||
coredump_dir /var/spool/squid
|
|
||||||
refresh_pattern ^ftp: 1440 20% 10080
|
|
||||||
refresh_pattern ^gopher: 1440 0% 1440
|
|
||||||
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
|
|
||||||
refresh_pattern \/(Packages|Sources)(|\.bz2|\.gz|\.xz)$ 0 0% 0 refresh-ims
|
|
||||||
refresh_pattern \/Release(|\.gpg)$ 0 0% 0 refresh-ims
|
|
||||||
refresh_pattern \/InRelease$ 0 0% 0 refresh-ims
|
|
||||||
refresh_pattern \/(Translation-.*)(|\.bz2|\.gz|\.xz)$ 0 0% 0 refresh-ims
|
|
||||||
refresh_pattern . 0 20% 4320
|
|
||||||
logfile_rotate 0
|
|
||||||
|
|
||||||
@@ -1,38 +0,0 @@
|
|||||||
#!/usr/bin/python3
|
|
||||||
|
|
||||||
import time
|
|
||||||
from flask import url_for
|
|
||||||
from ..util import live_server_setup
|
|
||||||
|
|
||||||
def test_preferred_proxy(client, live_server):
|
|
||||||
time.sleep(1)
|
|
||||||
live_server_setup(live_server)
|
|
||||||
time.sleep(1)
|
|
||||||
url = "http://chosen.changedetection.io"
|
|
||||||
|
|
||||||
res = client.post(
|
|
||||||
url_for("import_page"),
|
|
||||||
# Because a URL wont show in squid/proxy logs due it being SSLed
|
|
||||||
# Use plain HTTP or a specific domain-name here
|
|
||||||
data={"urls": url},
|
|
||||||
follow_redirects=True
|
|
||||||
)
|
|
||||||
|
|
||||||
assert b"1 Imported" in res.data
|
|
||||||
|
|
||||||
time.sleep(2)
|
|
||||||
res = client.post(
|
|
||||||
url_for("edit_page", uuid="first"),
|
|
||||||
data={
|
|
||||||
"css_filter": "",
|
|
||||||
"fetch_backend": "html_requests",
|
|
||||||
"headers": "",
|
|
||||||
"proxy": "proxy-two",
|
|
||||||
"tag": "",
|
|
||||||
"url": url,
|
|
||||||
},
|
|
||||||
follow_redirects=True
|
|
||||||
)
|
|
||||||
assert b"Updated watch." in res.data
|
|
||||||
time.sleep(2)
|
|
||||||
# Now the request should appear in the second-squid logs
|
|
||||||
@@ -1,19 +0,0 @@
|
|||||||
#!/usr/bin/python3
|
|
||||||
|
|
||||||
import time
|
|
||||||
from flask import url_for
|
|
||||||
from ..util import live_server_setup, wait_for_all_checks, extract_UUID_from_client
|
|
||||||
|
|
||||||
# just make a request, we will grep in the docker logs to see it actually got called
|
|
||||||
def test_check_basic_change_detection_functionality(client, live_server):
|
|
||||||
live_server_setup(live_server)
|
|
||||||
res = client.post(
|
|
||||||
url_for("import_page"),
|
|
||||||
# Because a URL wont show in squid/proxy logs due it being SSLed
|
|
||||||
# Use plain HTTP or a specific domain-name here
|
|
||||||
data={"urls": "http://one.changedetection.io"},
|
|
||||||
follow_redirects=True
|
|
||||||
)
|
|
||||||
|
|
||||||
assert b"1 Imported" in res.data
|
|
||||||
time.sleep(3)
|
|
||||||
@@ -2,7 +2,7 @@
|
|||||||
# coding=utf-8
|
# coding=utf-8
|
||||||
|
|
||||||
import time
|
import time
|
||||||
from flask import url_for, escape
|
from flask import url_for
|
||||||
from . util import live_server_setup
|
from . util import live_server_setup
|
||||||
import pytest
|
import pytest
|
||||||
|
|
||||||
@@ -36,26 +36,16 @@ and it can also be repeated
|
|||||||
from .. import html_tools
|
from .. import html_tools
|
||||||
|
|
||||||
# See that we can find the second <script> one, which is not broken, and matches our filter
|
# See that we can find the second <script> one, which is not broken, and matches our filter
|
||||||
text = html_tools.extract_json_as_string(content, "json:$.offers.price")
|
text = html_tools.extract_json_as_string(content, "$.offers.price")
|
||||||
assert text == "23.5"
|
assert text == "23.5"
|
||||||
|
|
||||||
# also check for jq
|
text = html_tools.extract_json_as_string('{"id":5}', "$.id")
|
||||||
text = html_tools.extract_json_as_string(content, "jq:.offers.price")
|
|
||||||
assert text == "23.5"
|
|
||||||
|
|
||||||
text = html_tools.extract_json_as_string('{"id":5}', "json:$.id")
|
|
||||||
assert text == "5"
|
|
||||||
|
|
||||||
text = html_tools.extract_json_as_string('{"id":5}', "jq:.id")
|
|
||||||
assert text == "5"
|
assert text == "5"
|
||||||
|
|
||||||
# When nothing at all is found, it should throw JSONNOTFound
|
# When nothing at all is found, it should throw JSONNOTFound
|
||||||
# Which is caught and shown to the user in the watch-overview table
|
# Which is caught and shown to the user in the watch-overview table
|
||||||
with pytest.raises(html_tools.JSONNotFound) as e_info:
|
with pytest.raises(html_tools.JSONNotFound) as e_info:
|
||||||
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "json:$.id")
|
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "$.id")
|
||||||
|
|
||||||
with pytest.raises(html_tools.JSONNotFound) as e_info:
|
|
||||||
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "jq:.id")
|
|
||||||
|
|
||||||
def set_original_ext_response():
|
def set_original_ext_response():
|
||||||
data = """
|
data = """
|
||||||
@@ -76,7 +66,6 @@ def set_original_ext_response():
|
|||||||
|
|
||||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||||
f.write(data)
|
f.write(data)
|
||||||
return None
|
|
||||||
|
|
||||||
def set_modified_ext_response():
|
def set_modified_ext_response():
|
||||||
data = """
|
data = """
|
||||||
@@ -97,7 +86,6 @@ def set_modified_ext_response():
|
|||||||
|
|
||||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||||
f.write(data)
|
f.write(data)
|
||||||
return None
|
|
||||||
|
|
||||||
def set_original_response():
|
def set_original_response():
|
||||||
test_return_data = """
|
test_return_data = """
|
||||||
@@ -196,10 +184,10 @@ def test_check_json_without_filter(client, live_server):
|
|||||||
assert b'"<b>' in res.data
|
assert b'"<b>' in res.data
|
||||||
assert res.data.count(b'{\n') >= 2
|
assert res.data.count(b'{\n') >= 2
|
||||||
|
|
||||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
|
||||||
assert b'Deleted' in res.data
|
|
||||||
|
|
||||||
def check_json_filter(json_filter, client, live_server):
|
def test_check_json_filter(client, live_server):
|
||||||
|
json_filter = 'json:boss.name'
|
||||||
|
|
||||||
set_original_response()
|
set_original_response()
|
||||||
|
|
||||||
# Give the endpoint time to spin up
|
# Give the endpoint time to spin up
|
||||||
@@ -238,7 +226,7 @@ def check_json_filter(json_filter, client, live_server):
|
|||||||
res = client.get(
|
res = client.get(
|
||||||
url_for("edit_page", uuid="first"),
|
url_for("edit_page", uuid="first"),
|
||||||
)
|
)
|
||||||
assert bytes(escape(json_filter).encode('utf-8')) in res.data
|
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||||
|
|
||||||
# Trigger a check
|
# Trigger a check
|
||||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||||
@@ -264,16 +252,10 @@ def check_json_filter(json_filter, client, live_server):
|
|||||||
# And #462 - check we see the proper utf-8 string there
|
# And #462 - check we see the proper utf-8 string there
|
||||||
assert "Örnsköldsvik".encode('utf-8') in res.data
|
assert "Örnsköldsvik".encode('utf-8') in res.data
|
||||||
|
|
||||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
|
||||||
assert b'Deleted' in res.data
|
|
||||||
|
|
||||||
def test_check_jsonpath_filter(client, live_server):
|
def test_check_json_filter_bool_val(client, live_server):
|
||||||
check_json_filter('json:boss.name', client, live_server)
|
json_filter = "json:$['available']"
|
||||||
|
|
||||||
def test_check_jq_filter(client, live_server):
|
|
||||||
check_json_filter('jq:.boss.name', client, live_server)
|
|
||||||
|
|
||||||
def check_json_filter_bool_val(json_filter, client, live_server):
|
|
||||||
set_original_response()
|
set_original_response()
|
||||||
|
|
||||||
# Give the endpoint time to spin up
|
# Give the endpoint time to spin up
|
||||||
@@ -322,21 +304,14 @@ def check_json_filter_bool_val(json_filter, client, live_server):
|
|||||||
# But the change should be there, tho its hard to test the change was detected because it will show old and new versions
|
# But the change should be there, tho its hard to test the change was detected because it will show old and new versions
|
||||||
assert b'false' in res.data
|
assert b'false' in res.data
|
||||||
|
|
||||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
|
||||||
assert b'Deleted' in res.data
|
|
||||||
|
|
||||||
def test_check_jsonpath_filter_bool_val(client, live_server):
|
|
||||||
check_json_filter_bool_val("json:$['available']", client, live_server)
|
|
||||||
|
|
||||||
def test_check_jq_filter_bool_val(client, live_server):
|
|
||||||
check_json_filter_bool_val("jq:.available", client, live_server)
|
|
||||||
|
|
||||||
# Re #265 - Extended JSON selector test
|
# Re #265 - Extended JSON selector test
|
||||||
# Stuff to consider here
|
# Stuff to consider here
|
||||||
# - Selector should be allowed to return empty when it doesnt match (people might wait for some condition)
|
# - Selector should be allowed to return empty when it doesnt match (people might wait for some condition)
|
||||||
# - The 'diff' tab could show the old and new content
|
# - The 'diff' tab could show the old and new content
|
||||||
# - Form should let us enter a selector that doesnt (yet) match anything
|
# - Form should let us enter a selector that doesnt (yet) match anything
|
||||||
def check_json_ext_filter(json_filter, client, live_server):
|
def test_check_json_ext_filter(client, live_server):
|
||||||
|
json_filter = 'json:$[?(@.status==Sold)]'
|
||||||
|
|
||||||
set_original_ext_response()
|
set_original_ext_response()
|
||||||
|
|
||||||
# Give the endpoint time to spin up
|
# Give the endpoint time to spin up
|
||||||
@@ -375,7 +350,7 @@ def check_json_ext_filter(json_filter, client, live_server):
|
|||||||
res = client.get(
|
res = client.get(
|
||||||
url_for("edit_page", uuid="first"),
|
url_for("edit_page", uuid="first"),
|
||||||
)
|
)
|
||||||
assert bytes(escape(json_filter).encode('utf-8')) in res.data
|
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||||
|
|
||||||
# Trigger a check
|
# Trigger a check
|
||||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||||
@@ -401,11 +376,3 @@ def check_json_ext_filter(json_filter, client, live_server):
|
|||||||
assert b'ForSale' not in res.data
|
assert b'ForSale' not in res.data
|
||||||
assert b'Sold' in res.data
|
assert b'Sold' in res.data
|
||||||
|
|
||||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
|
||||||
assert b'Deleted' in res.data
|
|
||||||
|
|
||||||
def test_check_jsonpath_ext_filter(client, live_server):
|
|
||||||
check_json_ext_filter('json:$[?(@.status==Sold)]', client, live_server)
|
|
||||||
|
|
||||||
def test_check_jq_ext_filter(client, live_server):
|
|
||||||
check_json_ext_filter('jq:.[] | select(.status | contains("Sold"))', client, live_server)
|
|
||||||
@@ -6,8 +6,6 @@ services:
|
|||||||
hostname: changedetection
|
hostname: changedetection
|
||||||
volumes:
|
volumes:
|
||||||
- changedetection-data:/datastore
|
- changedetection-data:/datastore
|
||||||
# Configurable proxy list support, see https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#proxy-list-support
|
|
||||||
# - ./proxies.json:/datastore/proxies.json
|
|
||||||
|
|
||||||
# environment:
|
# environment:
|
||||||
# Default listening port, can also be changed with the -p option
|
# Default listening port, can also be changed with the -p option
|
||||||
|
|||||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 46 KiB |
@@ -10,19 +10,15 @@ flask_restful
|
|||||||
pytz
|
pytz
|
||||||
|
|
||||||
# Set these versions together to avoid a RequestsDependencyWarning
|
# Set these versions together to avoid a RequestsDependencyWarning
|
||||||
# >= 2.26 also adds Brotli support if brotli is installed
|
requests[socks] ~= 2.26
|
||||||
brotli ~= 1.0
|
|
||||||
requests[socks] ~= 2.28
|
|
||||||
|
|
||||||
urllib3 > 1.26
|
urllib3 > 1.26
|
||||||
chardet > 2.3.0
|
chardet > 2.3.0
|
||||||
|
|
||||||
wtforms ~= 3.0
|
wtforms ~= 3.0
|
||||||
jsonpath-ng ~= 1.5.3
|
jsonpath-ng ~= 1.5.3
|
||||||
jq ~= 1.3.0
|
|
||||||
|
|
||||||
# Notification library
|
# Notification library
|
||||||
apprise ~= 1.1.0
|
apprise ~= 1.0.0
|
||||||
|
|
||||||
# apprise mqtt https://github.com/dgtlmoon/changedetection.io/issues/315
|
# apprise mqtt https://github.com/dgtlmoon/changedetection.io/issues/315
|
||||||
paho-mqtt
|
paho-mqtt
|
||||||
|
|||||||
Reference in New Issue
Block a user