Compare commits
420 Commits
0.39.14
...
puppeteer-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fc4bee57b3 | ||
|
|
de0f35701d | ||
|
|
5242649a62 | ||
|
|
06fbea0a8e | ||
|
|
edd2f5b087 | ||
|
|
eb61dda30a | ||
|
|
e4b40fa65d | ||
|
|
5325918f29 | ||
|
|
b04adcb45a | ||
|
|
5447e9b1f8 | ||
|
|
6e824964c2 | ||
|
|
00fe439351 | ||
|
|
8eee913438 | ||
|
|
06921d973e | ||
|
|
316f28a0f2 | ||
|
|
3801d339f5 | ||
|
|
d814535dc6 | ||
|
|
cf3f3e4497 | ||
|
|
ba76c2a280 | ||
|
|
94f38f052e | ||
|
|
1710885fc4 | ||
|
|
2018e73240 | ||
|
|
fae8c89a4e | ||
|
|
40988c55c6 | ||
|
|
5aa713b7ea | ||
|
|
e1f5dfb703 | ||
|
|
966600d28e | ||
|
|
e7ac356d99 | ||
|
|
e874df4ffc | ||
|
|
d1f44d0345 | ||
|
|
8536af0845 | ||
|
|
9076ba6bd3 | ||
|
|
43af18e2bc | ||
|
|
ad75e8cdd0 | ||
|
|
f604643356 | ||
|
|
d5fd22f693 | ||
|
|
1d9d11b3f5 | ||
|
|
f49464f451 | ||
|
|
bc6bde4062 | ||
|
|
2863167f45 | ||
|
|
ce3966c104 | ||
|
|
d5f574ca17 | ||
|
|
c96ece170a | ||
|
|
1fb90bbddc | ||
|
|
55b6ae86e8 | ||
|
|
66b892f770 | ||
|
|
3b80bb2f0e | ||
|
|
e6d2d87b31 | ||
|
|
6e71088cde | ||
|
|
2bc988dffc | ||
|
|
a578de36c5 | ||
|
|
4c74d39df0 | ||
|
|
c454cbb808 | ||
|
|
6f1eec0d5a | ||
|
|
0d05ee1586 | ||
|
|
23476f0e70 | ||
|
|
cf363971c1 | ||
|
|
35409f79bf | ||
|
|
fc88306805 | ||
|
|
8253074d56 | ||
|
|
5f9c8db3e1 | ||
|
|
abf234298c | ||
|
|
0e1032a36a | ||
|
|
3b96e40464 | ||
|
|
c747cf7ba8 | ||
|
|
3e98c8ae4b | ||
|
|
aaad71fc19 | ||
|
|
78f93113d8 | ||
|
|
e9e586205a | ||
|
|
89f1ba58b6 | ||
|
|
6f4fd011e3 | ||
|
|
900dc5ee78 | ||
|
|
7b8b50138b | ||
|
|
01af21f856 | ||
|
|
f7f4ab314b | ||
|
|
ce0355c0ad | ||
|
|
0f43213d9d | ||
|
|
93c57d9fad | ||
|
|
3cdd075baf | ||
|
|
5c617e8530 | ||
|
|
1a48965ba1 | ||
|
|
41856c4ed8 | ||
|
|
0ed897c50f | ||
|
|
f8e587c415 | ||
|
|
d47a25eb6d | ||
|
|
9a0792d185 | ||
|
|
948ef7ade4 | ||
|
|
0ba139f8f9 | ||
|
|
a9431191fc | ||
|
|
774451f256 | ||
|
|
04577cbf32 | ||
|
|
f2864af8f1 | ||
|
|
9a36d081c4 | ||
|
|
7048a0acbd | ||
|
|
fba719ab8d | ||
|
|
7c5e2d00af | ||
|
|
02b8fc0c18 | ||
|
|
de15dfd80d | ||
|
|
024c8d8fd5 | ||
|
|
fab7d325f7 | ||
|
|
58c7cbeac7 | ||
|
|
ab9efdfd14 | ||
|
|
65d5a5d34c | ||
|
|
93c157ee7f | ||
|
|
de85db887c | ||
|
|
50805ca38a | ||
|
|
fc6424c39e | ||
|
|
f0966eb23a | ||
|
|
e4fb5ab4da | ||
|
|
e99f07a51d | ||
|
|
08ee223b5f | ||
|
|
572f9b8a31 | ||
|
|
fcfd1b5e10 | ||
|
|
0790dd555e | ||
|
|
0b20dc7712 | ||
|
|
13c4121f52 | ||
|
|
e8e176f3bd | ||
|
|
7a1d2d924e | ||
|
|
c3731cf055 | ||
|
|
a287e5a86c | ||
|
|
235535c327 | ||
|
|
44dc62da2d | ||
|
|
0c380c170f | ||
|
|
b7a2501d64 | ||
|
|
e970fef991 | ||
|
|
b76148a0f4 | ||
|
|
93cc30437f | ||
|
|
6562d6e0d4 | ||
|
|
6c217cc3b6 | ||
|
|
f30cdf0674 | ||
|
|
14da0646a7 | ||
|
|
b413cdecc7 | ||
|
|
7bf52d9275 | ||
|
|
09e6624afd | ||
|
|
b58fd995b5 | ||
|
|
f7bb8a0afa | ||
|
|
3e333496c1 | ||
|
|
ee776a9627 | ||
|
|
65db4d68e3 | ||
|
|
74d93d10c3 | ||
|
|
37aef0530a | ||
|
|
f86763dc7a | ||
|
|
13c25f9b92 | ||
|
|
265f622e75 | ||
|
|
c12db2b725 | ||
|
|
a048e4a02d | ||
|
|
69662ff91c | ||
|
|
fc94c57d7f | ||
|
|
7b94ba6f23 | ||
|
|
2345b6b558 | ||
|
|
b8d5a12ad0 | ||
|
|
9e67a572c5 | ||
|
|
378d7b7362 | ||
|
|
d1d4045c49 | ||
|
|
77409eeb3a | ||
|
|
87726e0bb2 | ||
|
|
72222158e9 | ||
|
|
1814924c19 | ||
|
|
8aae4197d7 | ||
|
|
3a8a41a3ff | ||
|
|
64caeea491 | ||
|
|
3838bff397 | ||
|
|
55ea983bda | ||
|
|
b4d79839bf | ||
|
|
0b8c3add34 | ||
|
|
51d57f0963 | ||
|
|
6d932149e3 | ||
|
|
2c764e8f84 | ||
|
|
07765b0d38 | ||
|
|
7c3faa8e38 | ||
|
|
4624974b91 | ||
|
|
991841f1f9 | ||
|
|
e3db324698 | ||
|
|
0988bef2cd | ||
|
|
5b281f2c34 | ||
|
|
a224f64cd6 | ||
|
|
7ee97ae37f | ||
|
|
69756f20f2 | ||
|
|
326b7aacbb | ||
|
|
fde7b3fd97 | ||
|
|
9d04cb014a | ||
|
|
5b530ff61c | ||
|
|
c98536ace4 | ||
|
|
463747d3b7 | ||
|
|
791bdb42aa | ||
|
|
ce6c2737a8 | ||
|
|
ade9e1138b | ||
|
|
68d5178367 | ||
|
|
41dc57aee3 | ||
|
|
943704cd04 | ||
|
|
883561f979 | ||
|
|
35d44c8277 | ||
|
|
d07d7a1b18 | ||
|
|
f066a1c38f | ||
|
|
d0d191a7d1 | ||
|
|
d7482c8d6a | ||
|
|
bcf7417f63 | ||
|
|
df6e835035 | ||
|
|
ab28f20eba | ||
|
|
1174b95ab4 | ||
|
|
a564475325 | ||
|
|
85d8d57997 | ||
|
|
359dcb63e3 | ||
|
|
b043d477dc | ||
|
|
06bcfb28e5 | ||
|
|
ca3b351bae | ||
|
|
b7e0f0a5e4 | ||
|
|
61f0ac2937 | ||
|
|
fca66eb558 | ||
|
|
359fc48fb4 | ||
|
|
d0efeb9770 | ||
|
|
3416532cd6 | ||
|
|
defc7a340e | ||
|
|
c197c062e1 | ||
|
|
77b59809ca | ||
|
|
f90b170e68 | ||
|
|
c93ca1841c | ||
|
|
57f604dff1 | ||
|
|
8499468749 | ||
|
|
7f6a13ea6c | ||
|
|
9874f0cbc7 | ||
|
|
72834a42fd | ||
|
|
724cb17224 | ||
|
|
4eb4b401a1 | ||
|
|
5d40e16c73 | ||
|
|
492bbce6b6 | ||
|
|
0394a56be5 | ||
|
|
7839551d6b | ||
|
|
9c5588c791 | ||
|
|
5a43a350de | ||
|
|
3c31f023ce | ||
|
|
4cbcc59461 | ||
|
|
4be0260381 | ||
|
|
957a3c1c16 | ||
|
|
85897e0bf9 | ||
|
|
63095f70ea | ||
|
|
8d5b0b5576 | ||
|
|
1b077abd93 | ||
|
|
32ea1a8721 | ||
|
|
fff32cef0d | ||
|
|
8fb146f3e4 | ||
|
|
770b0faa45 | ||
|
|
f6faa90340 | ||
|
|
669fd3ae0b | ||
|
|
17d37fb626 | ||
|
|
dfa7fc3a81 | ||
|
|
cd467df97a | ||
|
|
71bc2fed82 | ||
|
|
738fcfe01c | ||
|
|
3ebb2ab9ba | ||
|
|
ac98bc9144 | ||
|
|
3705ce6681 | ||
|
|
f7ea99412f | ||
|
|
d4715e2bc8 | ||
|
|
8567a83c47 | ||
|
|
77fdf59ae3 | ||
|
|
0e194aa4b4 | ||
|
|
2ba55bb477 | ||
|
|
4c759490da | ||
|
|
58a52c1f60 | ||
|
|
22638399c1 | ||
|
|
e3381776f2 | ||
|
|
26e2f21a80 | ||
|
|
b6009ae9ff | ||
|
|
b046d6ef32 | ||
|
|
e154a3cb7a | ||
|
|
1262700263 | ||
|
|
434c5813b9 | ||
|
|
0a3dc7d77b | ||
|
|
a7e296de65 | ||
|
|
bd0fbaaf27 | ||
|
|
0c111bd9ae | ||
|
|
ed9ac0b7fb | ||
|
|
743a3069bb | ||
|
|
fefc39427b | ||
|
|
2c6faa7c4e | ||
|
|
6168cd2899 | ||
|
|
f3c7c969d8 | ||
|
|
1355c2a245 | ||
|
|
96cf1a06df | ||
|
|
019a4a0375 | ||
|
|
db2f7b80ea | ||
|
|
bfabd7b094 | ||
|
|
d92dbfe765 | ||
|
|
67d2441334 | ||
|
|
3c30bc02d5 | ||
|
|
dcb54117d5 | ||
|
|
b1e32275dc | ||
|
|
e2a6865932 | ||
|
|
f04adb7202 | ||
|
|
1193a7f22c | ||
|
|
0b976827bb | ||
|
|
280e916033 | ||
|
|
5494e61a05 | ||
|
|
e461c0b819 | ||
|
|
d67c654f37 | ||
|
|
06ab34b6af | ||
|
|
ba8676c4ba | ||
|
|
4899c1a4f9 | ||
|
|
9bff1582f7 | ||
|
|
269e3bb7c5 | ||
|
|
9976f3f969 | ||
|
|
1f250aa868 | ||
|
|
1c08d9f150 | ||
|
|
9942107016 | ||
|
|
1eb5726cbf | ||
|
|
b3271ff7bb | ||
|
|
f82d3b648a | ||
|
|
034b1330d4 | ||
|
|
a7d005109f | ||
|
|
048c355e04 | ||
|
|
4026575b0b | ||
|
|
8c466b4826 | ||
|
|
6f072b42e8 | ||
|
|
e318253f31 | ||
|
|
f0f2fe94ce | ||
|
|
26f5c56ba4 | ||
|
|
a1c3107cd6 | ||
|
|
8fef3ff4ab | ||
|
|
baa25c9f9e | ||
|
|
488699b7d4 | ||
|
|
cf3a1ee3e3 | ||
|
|
daae43e9f9 | ||
|
|
cdeedaa65c | ||
|
|
3c9d2ded38 | ||
|
|
9f4364a130 | ||
|
|
5bd9eaf99d | ||
|
|
b1c51c0a65 | ||
|
|
232bd92389 | ||
|
|
e6173357a9 | ||
|
|
f2b8888aff | ||
|
|
9c46f175f9 | ||
|
|
1f27865fdf | ||
|
|
faa42d75e0 | ||
|
|
3b6e6d85bb | ||
|
|
30d6a272ce | ||
|
|
291700554e | ||
|
|
a82fad7059 | ||
|
|
c2fe5ae0d1 | ||
|
|
5beefdb7cc | ||
|
|
872bbba71c | ||
|
|
d578de1a35 | ||
|
|
cdc104be10 | ||
|
|
dd0eeca056 | ||
|
|
a95468be08 | ||
|
|
ace44d0e00 | ||
|
|
ebb8b88621 | ||
|
|
12fc2200de | ||
|
|
52d3d375ba | ||
|
|
08117089e6 | ||
|
|
2ba3a6d53f | ||
|
|
2f636553a9 | ||
|
|
0bde48b282 | ||
|
|
fae1164c0b | ||
|
|
169c293143 | ||
|
|
46cb5cff66 | ||
|
|
05584ea886 | ||
|
|
176a591357 | ||
|
|
15569f9592 | ||
|
|
5f9e475fe0 | ||
|
|
34b8784f50 | ||
|
|
2b054ced8c | ||
|
|
6553980cd5 | ||
|
|
7c12c47204 | ||
|
|
dbd9b470d7 | ||
|
|
83555a9991 | ||
|
|
5bfdb28bd2 | ||
|
|
31a6a6717b | ||
|
|
7da32f9ac3 | ||
|
|
bb732d3d2e | ||
|
|
485e55f9ed | ||
|
|
601a20ea49 | ||
|
|
76996b9eb8 | ||
|
|
fba2b1a39d | ||
|
|
4a91505af5 | ||
|
|
4841c79b4c | ||
|
|
2ba00d2e1d | ||
|
|
19c96f4bdd | ||
|
|
82b900fbf4 | ||
|
|
358a365303 | ||
|
|
a07ca4b136 | ||
|
|
ba8cf2c8cf | ||
|
|
3106b6688e | ||
|
|
2c83845dac | ||
|
|
111266d6fa | ||
|
|
ead610151f | ||
|
|
7e1e763989 | ||
|
|
327cc4af34 | ||
|
|
6008ff516e | ||
|
|
cdcf4b353f | ||
|
|
1ab70f8e86 | ||
|
|
8227c012a7 | ||
|
|
c113d5fb24 | ||
|
|
8c8d4066d7 | ||
|
|
277dc9e1c1 | ||
|
|
fc0fd1ce9d | ||
|
|
bd6127728a | ||
|
|
4101ae00c6 | ||
|
|
62f14df3cb | ||
|
|
560d465c59 | ||
|
|
7929aeddfc | ||
|
|
8294519f43 | ||
|
|
8ba8a220b6 | ||
|
|
aa3c8a9370 | ||
|
|
dbb5468cdc | ||
|
|
329c7620fb | ||
|
|
1f974bfbb0 | ||
|
|
437c8525af | ||
|
|
a2a1d5ae90 | ||
|
|
2566de2aae | ||
|
|
dfec8dbb39 | ||
|
|
5cefb16e52 | ||
|
|
341ae24b73 | ||
|
|
f47c2fb7f6 | ||
|
|
9d742446ab | ||
|
|
e3e022b0f4 | ||
|
|
6de4027c27 | ||
|
|
cda3837355 | ||
|
|
7983675325 | ||
|
|
eef56e52c6 |
25
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -1,25 +1,42 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Create a report to help us improve
|
||||
about: Create a bug report, if you don't follow this template, your report will be DELETED
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
labels: 'triage'
|
||||
assignees: 'dgtlmoon'
|
||||
|
||||
---
|
||||
|
||||
**DO NOT USE THIS FORM TO REPORT THAT A PARTICULAR WEBSITE IS NOT SCRAPING/WATCHING AS EXPECTED**
|
||||
|
||||
This form is only for direct bugs and feature requests todo directly with the software.
|
||||
|
||||
Please report watched websites (full URL and _any_ settings) that do not work with changedetection.io as expected [**IN THE DISCUSSION FORUMS**](https://github.com/dgtlmoon/changedetection.io/discussions) or your report will be deleted
|
||||
|
||||
CONSIDER TAKING OUT A SUBSCRIPTION FOR A SMALL PRICE PER MONTH, YOU GET THE BENEFIT OF USING OUR PAID PROXIES AND FURTHERING THE DEVELOPMENT OF CHANGEDETECTION.IO
|
||||
|
||||
THANK YOU
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**Describe the bug**
|
||||
A clear and concise description of what the bug is.
|
||||
|
||||
**Version**
|
||||
In the top right area: 0....
|
||||
*Exact version* in the top right area: 0....
|
||||
|
||||
**To Reproduce**
|
||||
|
||||
Steps to reproduce the behavior:
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
4. See error
|
||||
|
||||
! ALWAYS INCLUDE AN EXAMPLE URL WHERE IT IS POSSIBLE TO RE-CREATE THE ISSUE - USE THE 'SHARE WATCH' FEATURE AND PASTE IN THE SHARE-LINK!
|
||||
|
||||
**Expected behavior**
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
|
||||
4
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -1,8 +1,8 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
title: '[feature]'
|
||||
labels: 'enhancement'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
31
.github/test/Dockerfile-alpine
vendored
Normal file
@@ -0,0 +1,31 @@
|
||||
# Taken from https://github.com/linuxserver/docker-changedetection.io/blob/main/Dockerfile
|
||||
# Test that we can still build on Alpine (musl modified libc https://musl.libc.org/)
|
||||
# Some packages wont install via pypi because they dont have a wheel available under this architecture.
|
||||
|
||||
FROM ghcr.io/linuxserver/baseimage-alpine:3.16
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
|
||||
COPY requirements.txt /requirements.txt
|
||||
|
||||
RUN \
|
||||
apk add --update --no-cache --virtual=build-dependencies \
|
||||
cargo \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libxslt-dev \
|
||||
make \
|
||||
openssl-dev \
|
||||
py3-wheel \
|
||||
python3-dev \
|
||||
zlib-dev && \
|
||||
apk add --update --no-cache \
|
||||
libxslt \
|
||||
python3 \
|
||||
py3-pip && \
|
||||
echo "**** pip3 install test of changedetection.io ****" && \
|
||||
pip3 install -U pip wheel setuptools && \
|
||||
pip3 install -U --no-cache-dir --find-links https://wheel-index.linuxserver.io/alpine-3.16/ -r /requirements.txt && \
|
||||
apk del --purge \
|
||||
build-dependencies
|
||||
20
.github/workflows/containers.yml
vendored
@@ -50,7 +50,6 @@ jobs:
|
||||
python -m pip install --upgrade pip
|
||||
pip install flake8 pytest
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
|
||||
- name: Create release metadata
|
||||
run: |
|
||||
@@ -85,8 +84,8 @@ jobs:
|
||||
version: latest
|
||||
driver-opts: image=moby/buildkit:master
|
||||
|
||||
# master always builds :latest
|
||||
- name: Build and push :latest
|
||||
# master branch -> :dev container tag
|
||||
- name: Build and push :dev
|
||||
id: docker_build
|
||||
if: ${{ github.ref }} == "refs/heads/master"
|
||||
uses: docker/build-push-action@v2
|
||||
@@ -95,12 +94,14 @@ jobs:
|
||||
file: ./Dockerfile
|
||||
push: true
|
||||
tags: |
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest,ghcr.io/${{ github.repository }}:latest
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:dev,ghcr.io/${{ github.repository }}:dev
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
# Looks like this was disabled
|
||||
# provenance: false
|
||||
|
||||
# A new tagged release is required, which builds :tag
|
||||
# A new tagged release is required, which builds :tag and :latest
|
||||
- name: Build and push :tag
|
||||
id: docker_build_tag_release
|
||||
if: github.event_name == 'release' && startsWith(github.event.release.tag_name, '0.')
|
||||
@@ -110,10 +111,15 @@ jobs:
|
||||
file: ./Dockerfile
|
||||
push: true
|
||||
tags: |
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:${{ github.event.release.tag_name }},ghcr.io/dgtlmoon/changedetection.io:${{ github.event.release.tag_name }}
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:${{ github.event.release.tag_name }}
|
||||
ghcr.io/dgtlmoon/changedetection.io:${{ github.event.release.tag_name }}
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest
|
||||
ghcr.io/dgtlmoon/changedetection.io:latest
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
# Looks like this was disabled
|
||||
# provenance: false
|
||||
|
||||
- name: Image digest
|
||||
run: echo step SHA ${{ steps.vars.outputs.sha_short }} tag ${{steps.vars.outputs.tag}} branch ${{steps.vars.outputs.branch}} digest ${{ steps.docker_build.outputs.digest }}
|
||||
@@ -125,5 +131,3 @@ jobs:
|
||||
key: ${{ runner.os }}-buildx-${{ github.sha }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-buildx-
|
||||
|
||||
|
||||
|
||||
44
.github/workflows/pypi.yml
vendored
@@ -1,44 +0,0 @@
|
||||
name: PyPi Test and Push tagged release
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
on:
|
||||
workflow_run:
|
||||
workflows: ["ChangeDetection.io Test"]
|
||||
tags: '*.*'
|
||||
types: [completed]
|
||||
|
||||
|
||||
jobs:
|
||||
test-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# python -m pip install --upgrade pip
|
||||
# pip install flake8 pytest
|
||||
# if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
# if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
|
||||
- name: Test that pip builds without error
|
||||
run: |
|
||||
pip3 --version
|
||||
python3 -m pip install wheel
|
||||
python3 setup.py bdist_wheel
|
||||
python3 -m pip install dist/changedetection.io-*-none-any.whl --force
|
||||
changedetection.io -d /tmp -p 10000 &
|
||||
sleep 3
|
||||
curl http://127.0.0.1:10000/static/styles/pure-min.css >/dev/null
|
||||
killall -9 changedetection.io
|
||||
|
||||
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||
|
||||
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||
#if: ${{ github.event_name == 'release'}}
|
||||
68
.github/workflows/test-container-build.yml
vendored
Normal file
@@ -0,0 +1,68 @@
|
||||
name: ChangeDetection.io Container Build Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
|
||||
# This line doesnt work, even tho it is the documented one
|
||||
#on: [push, pull_request]
|
||||
|
||||
on:
|
||||
push:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
- .github/workflows/*
|
||||
|
||||
pull_request:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
- .github/workflows/*
|
||||
|
||||
# Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
|
||||
# @todo: some kind of path filter for requirements.txt and Dockerfile
|
||||
jobs:
|
||||
test-container-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
# Just test that the build works, some libraries won't compile on ARM/rPi etc
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v1
|
||||
with:
|
||||
image: tonistiigi/binfmt:latest
|
||||
platforms: all
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
id: buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
with:
|
||||
install: true
|
||||
version: latest
|
||||
driver-opts: image=moby/buildkit:master
|
||||
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067
|
||||
# Check we can still build under alpine/musl
|
||||
- name: Test that the docker containers can build (musl via alpine check)
|
||||
id: docker_build_musl
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: ./
|
||||
file: ./.github/test/Dockerfile-alpine
|
||||
platforms: linux/amd64,linux/arm64
|
||||
|
||||
- name: Test that the docker containers can build
|
||||
id: docker_build
|
||||
uses: docker/build-push-action@v2
|
||||
# https://github.com/docker/build-push-action#customizing
|
||||
with:
|
||||
context: ./
|
||||
file: ./Dockerfile
|
||||
platforms: linux/arm/v7,linux/arm/v6,linux/amd64,linux/arm64,
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
84
.github/workflows/test-only.yml
vendored
@@ -1,45 +1,85 @@
|
||||
name: ChangeDetection.io Test
|
||||
name: ChangeDetection.io App Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
on: [push, pull_request]
|
||||
|
||||
jobs:
|
||||
test-build:
|
||||
test-application:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
|
||||
# Mainly just for link/flake8
|
||||
- name: Set up Python 3.10
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Show env vars
|
||||
run: set
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install flake8 pytest
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
- name: Lint with flake8
|
||||
run: |
|
||||
pip3 install flake8
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
|
||||
|
||||
- name: Unit tests
|
||||
- name: Spin up ancillary testable services
|
||||
run: |
|
||||
python3 -m unittest changedetectionio.tests.unit.test_notification_diff
|
||||
|
||||
docker network create changedet-network
|
||||
|
||||
- name: Test with pytest
|
||||
# Selenium+browserless
|
||||
docker run --network changedet-network -d --hostname selenium -p 4444:4444 --rm --shm-size="2g" selenium/standalone-chrome-debug:3.141.59
|
||||
docker run --network changedet-network -d --hostname browserless -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]" -e "DEFAULT_LAUNCH_ARGS=[\"--window-size=1920,1080\"]" --rm -p 3000:3000 --shm-size="2g" browserless/chrome:1.53-chrome-stable
|
||||
|
||||
- name: Build changedetection.io container for testing
|
||||
run: |
|
||||
# Build a changedetection.io container and start testing inside
|
||||
docker build . -t test-changedetectionio
|
||||
|
||||
- name: Test built container with pytest
|
||||
run: |
|
||||
# Each test is totally isolated and performs its own cleanup/reset
|
||||
cd changedetectionio; ./run_all_tests.sh
|
||||
|
||||
# Unit tests
|
||||
docker run test-changedetectionio bash -c 'python3 -m unittest changedetectionio.tests.unit.test_notification_diff'
|
||||
|
||||
# All tests
|
||||
docker run --network changedet-network test-changedetectionio bash -c 'cd changedetectionio && ./run_basic_tests.sh'
|
||||
|
||||
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||
- name: Test built container selenium+browserless/playwright
|
||||
run: |
|
||||
|
||||
# Selenium fetch
|
||||
docker run --rm -e "WEBDRIVER_URL=http://selenium:4444/wd/hub" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py'
|
||||
|
||||
# Playwright/Browserless fetch
|
||||
docker run --rm -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py && pytest tests/visualselector/test_fetch_data.py'
|
||||
|
||||
# restock detection via playwright - added name=changedet here so that playwright/browserless can connect to it
|
||||
docker run --rm --name "changedet" -e "FLASK_SERVER_NAME=changedet" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest --live-server-port=5004 --live-server-host=0.0.0.0 tests/restock/test_restock.py'
|
||||
|
||||
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||
- name: Test with puppeteer fetcher and disk cache
|
||||
run: |
|
||||
docker run --rm -e "PUPPETEER_DISK_CACHE=/tmp/data/" -e "USE_EXPERIMENTAL_PUPPETEER_FETCH=yes" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py && pytest tests/visualselector/test_fetch_data.py'
|
||||
# Browserless would have had -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]" added above
|
||||
|
||||
- name: Test proxy interaction
|
||||
run: |
|
||||
cd changedetectionio
|
||||
./run_proxy_tests.sh
|
||||
cd ..
|
||||
|
||||
- name: Test changedetection.io container starts+runs basically without error
|
||||
run: |
|
||||
docker run -p 5556:5000 -d test-changedetectionio
|
||||
sleep 3
|
||||
# Should return 0 (no error) when grep finds it
|
||||
curl -s http://localhost:5556 |grep -q checkbox-uuid
|
||||
|
||||
# and IPv6
|
||||
curl -s -g -6 "http://[::1]:5556"|grep -q checkbox-uuid
|
||||
|
||||
|
||||
#export WEBDRIVER_URL=http://localhost:4444/wd/hub
|
||||
#pytest tests/fetchers/test_content.py
|
||||
#pytest tests/test_errorhandling.py
|
||||
36
.github/workflows/test-pip-build.yml
vendored
Normal file
@@ -0,0 +1,36 @@
|
||||
name: ChangeDetection.io PIP package test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
|
||||
# This line doesnt work, even tho it is the documented one
|
||||
on: [push, pull_request]
|
||||
|
||||
# Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
|
||||
# @todo: some kind of path filter for requirements.txt and Dockerfile
|
||||
jobs:
|
||||
test-pip-build-basics:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
|
||||
- name: Test that the basic pip built package runs without error
|
||||
run: |
|
||||
set -e
|
||||
mkdir dist
|
||||
pip3 install wheel
|
||||
python3 setup.py bdist_wheel
|
||||
pip3 install -r requirements.txt
|
||||
rm ./changedetection.py
|
||||
rm -rf changedetectio
|
||||
|
||||
pip3 install dist/changedetection.io*.whl
|
||||
changedetection.io -d /tmp -p 10000 &
|
||||
sleep 3
|
||||
curl http://127.0.0.1:10000/static/styles/pure-min.css >/dev/null
|
||||
killall -9 changedetection.io
|
||||
2
.gitignore
vendored
@@ -8,5 +8,7 @@ __pycache__
|
||||
build
|
||||
dist
|
||||
venv
|
||||
test-datastore/*
|
||||
test-datastore
|
||||
*.egg-info*
|
||||
.vscode/settings.json
|
||||
|
||||
@@ -6,10 +6,4 @@ Otherwise, it's always best to PR into the `dev` branch.
|
||||
|
||||
Please be sure that all new functionality has a matching test!
|
||||
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notifications.py` for example
|
||||
|
||||
```
|
||||
pip3 install -r requirements-dev
|
||||
```
|
||||
|
||||
this is from https://github.com/dgtlmoon/changedetection.io/blob/master/requirements-dev.txt
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notification.py` for example
|
||||
|
||||
39
Dockerfile
@@ -1,17 +1,19 @@
|
||||
# pip dependencies install stage
|
||||
FROM python:3.8-slim as builder
|
||||
FROM python:3.10-slim as builder
|
||||
|
||||
# rustc compiler would be needed on ARM type devices but theres an issue with some deps not building..
|
||||
# See `cryptography` pin comment in requirements.txt
|
||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libjpeg-dev \
|
||||
libssl-dev \
|
||||
libxslt-dev \
|
||||
zlib1g-dev \
|
||||
g++
|
||||
make \
|
||||
zlib1g-dev
|
||||
|
||||
RUN mkdir /install
|
||||
WORKDIR /install
|
||||
@@ -22,25 +24,21 @@ RUN pip install --target=/dependencies -r /requirements.txt
|
||||
|
||||
# Playwright is an alternative to Selenium
|
||||
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
||||
RUN pip install --target=/dependencies playwright~=1.20 \
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067 also musl/alpine (not supported)
|
||||
RUN pip install --target=/dependencies playwright~=1.27.1 \
|
||||
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
||||
|
||||
# Final image stage
|
||||
FROM python:3.8-slim
|
||||
FROM python:3.10-slim
|
||||
|
||||
# Actual packages needed at runtime, usually due to the notification (apprise) backend
|
||||
# rustc compiler would be needed on ARM type devices but theres an issue with some deps not building..
|
||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
# Re #93, #73, excluding rustc (adds another 430Mb~)
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libxslt-dev \
|
||||
zlib1g-dev \
|
||||
g++
|
||||
libssl1.1 \
|
||||
libxslt1.1 \
|
||||
# For pdftohtml
|
||||
poppler-utils \
|
||||
zlib1g \
|
||||
&& apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
|
||||
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
@@ -58,6 +56,7 @@ EXPOSE 5000
|
||||
|
||||
# The actual flask app
|
||||
COPY changedetectionio /app/changedetectionio
|
||||
|
||||
# The eventlet server wrapper
|
||||
COPY changedetection.py /app/changedetection.py
|
||||
|
||||
|
||||
14
MANIFEST.in
@@ -1,7 +1,15 @@
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/api *
|
||||
recursive-include changedetectionio/blueprint *
|
||||
recursive-include changedetectionio/model *
|
||||
recursive-include changedetectionio/processors *
|
||||
recursive-include changedetectionio/res *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/tests *
|
||||
prune changedetectionio/static/package-lock.json
|
||||
prune changedetectionio/static/styles/node_modules
|
||||
prune changedetectionio/static/styles/package-lock.json
|
||||
include changedetection.py
|
||||
global-exclude *.pyc
|
||||
global-exclude node_modules
|
||||
global-exclude venv
|
||||
global-exclude venv
|
||||
|
||||
@@ -1,45 +1,48 @@
|
||||
# changedetection.io
|
||||

|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io" alt="Docker Pulls"/>
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/github/v/release/dgtlmoon/changedetection.io" alt="Change detection latest tag version"/>
|
||||
</a>
|
||||
## Web Site Change Detection, Monitoring and Notification.
|
||||
|
||||
## Self-hosted open source change monitoring of web pages.
|
||||
Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
|
||||
|
||||
_Know when web pages change! Stay ontop of new information!_
|
||||
|
||||
Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start?src=pip)
|
||||
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
|
||||
[**Try our $6.99/month subscription - unlimited checks, watches and notifications!**](https://lemonade.changedetection.io/start), choose from different geographical locations, let us handle everything for you.
|
||||
|
||||
[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
#### Example use cases
|
||||
|
||||
Know when ...
|
||||
|
||||
- Government department updates (changes are often only on their websites)
|
||||
- Local government news (changes are often only on their websites)
|
||||
- Products and services have a change in pricing
|
||||
- _Out of stock notification_ and _Back In stock notification_
|
||||
- Governmental department updates (changes are often only on their websites)
|
||||
- New software releases, security advisories when you're not on their mailing list.
|
||||
- Festivals with changes
|
||||
- Realestate listing changes
|
||||
- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
|
||||
- COVID related news from government websites
|
||||
- University/organisation news from their website
|
||||
- Detect and monitor changes in JSON API responses
|
||||
- API monitoring and alerting
|
||||
- JSON API monitoring and alerting
|
||||
- Changes in legal and other documents
|
||||
- Trigger API calls via notifications when text appears on a website
|
||||
- Glue together APIs using the JSON filter and JSON notifications
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
|
||||
#### Key Features
|
||||
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
|
||||
**Get monitoring now!**
|
||||
|
||||
```bash
|
||||
$ pip3 install changedetection.io
|
||||
$ pip3 install changedetection.io
|
||||
```
|
||||
|
||||
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
|
||||
@@ -51,17 +54,5 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
|
||||
|
||||
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
|
||||
|
||||
### Features
|
||||
- Website monitoring
|
||||
- Change detection of content and analyses
|
||||
- Filters on change (Select by CSS or JSON)
|
||||
- Triggers (Wait for text, wait for regex)
|
||||
- Notification support
|
||||
- JSON API Monitoring
|
||||
- Parse JSON embedded in HTML
|
||||
- (Reverse) Proxy support
|
||||
- Javascript support via WebDriver
|
||||
- RaspberriPi (arm v6/v7/64 support)
|
||||
|
||||
See https://github.com/dgtlmoon/changedetection.io for more information.
|
||||
|
||||
|
||||
142
README.md
@@ -1,38 +1,57 @@
|
||||
# changedetection.io
|
||||
## Web Site Change Detection, Restock monitoring and notifications.
|
||||
|
||||
**_Detect website content changes and perform meaningful actions - trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._**
|
||||
|
||||
_Live your data-life pro-actively._
|
||||
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start?src=github)
|
||||
|
||||
[![Release Version][release-shield]][release-link] [![Docker Pulls][docker-pulls]][docker-link] [![License][license-shield]](LICENSE.md)
|
||||
|
||||

|
||||
|
||||
## Self-Hosted, Open Source, Change Monitoring of Web Pages
|
||||
[**Don't have time? Let us host it for you! try our $8.99/month subscription - use our proxies and support!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
||||
|
||||
_Know when web pages change! Stay ontop of new information!_
|
||||
|
||||
Live your data-life *pro-actively* instead of *re-actively*.
|
||||
|
||||
Free, Open-source web page monitoring, notification and change detection. Don't have time? [**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start)
|
||||
- Chrome browser included.
|
||||
- Super fast, no registration needed setup.
|
||||
- Get started watching and receiving website change notifications straight away.
|
||||
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
### Target specific parts of the webpage using the Visual Selector tool.
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (included as part of our subscription service)
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />](https://lemonade.changedetection.io/start?src=github)
|
||||
|
||||
### Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />](https://lemonade.changedetection.io/start?src=github)
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
### Perform interactive browser steps
|
||||
|
||||
[**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
||||
Fill in text boxes, click buttons and more, setup your changedetection scenario.
|
||||
|
||||
Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
|
||||
|
||||
[<img src="docs/browsersteps-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Website change detection with interactive browser steps, login, cookies etc" />](https://lemonade.changedetection.io/start?src=github)
|
||||
|
||||
After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
|
||||
Requires Playwright to be enabled.
|
||||
|
||||
|
||||
|
||||
- Automatic Updates, Automatic Backups, No Heroku "paused application", don't miss a change!
|
||||
- Javascript browser included
|
||||
- Unlimited checks and watches!
|
||||
|
||||
|
||||
#### Example use cases
|
||||
### Example use cases
|
||||
|
||||
- Products and services have a change in pricing
|
||||
- _Out of stock notification_ and _Back In stock notification_
|
||||
- Monitor and track PDF file changes, know when a PDF file has text changes.
|
||||
- Governmental department updates (changes are often only on their websites)
|
||||
- New software releases, security advisories when you're not on their mailing list.
|
||||
- Festivals with changes
|
||||
- Discogs restock alerts and monitoring
|
||||
- Realestate listing changes
|
||||
- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
|
||||
- COVID related news from government websites
|
||||
- University/organisation news from their website
|
||||
- Detect and monitor changes in JSON API responses
|
||||
@@ -43,31 +62,49 @@ Free, Open-source web page monitoring, notification and change detection. Don't
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
- Get notified when certain keywords appear in Twitter search results
|
||||
- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
|
||||
- Get alerts when new job positions are open on Bamboo HR and other job platforms
|
||||
- Website defacement monitoring
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver!</a>_
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
|
||||
## Screenshots
|
||||
#### Key Features
|
||||
|
||||
Examining differences in content.
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Track changes in PDF files (Monitor text changed in the PDF, Also monitor PDF filesize and checksums)
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
|
||||
- Send a screenshot with the notification when a change is detected in the web page
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
### Docker
|
||||
|
||||
With Docker composer, just clone this repository and..
|
||||
|
||||
```bash
|
||||
$ docker-compose up -d
|
||||
```
|
||||
|
||||
Docker standalone
|
||||
```bash
|
||||
$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
|
||||
```
|
||||
|
||||
`:latest` tag is our latest stable release, `:dev` tag is our bleeding edge `master` branch.
|
||||
|
||||
Alternative docker repository over at ghcr - [ghcr.io/dgtlmoon/changedetection.io](https://ghcr.io/dgtlmoon/changedetection.io)
|
||||
|
||||
### Windows
|
||||
|
||||
See the install instructions at the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Microsoft-Windows
|
||||
@@ -90,8 +127,8 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
|
||||
### Docker
|
||||
```
|
||||
docker pull dgtlmoon/changedetection.io
|
||||
docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker kill $(docker ps -a -f name=changedetection.io -q)
|
||||
docker rm $(docker ps -a -f name=changedetection.io -q)
|
||||
docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
|
||||
```
|
||||
|
||||
@@ -105,9 +142,9 @@ See the wiki for more information https://github.com/dgtlmoon/changedetection.io
|
||||
|
||||
|
||||
## Filters
|
||||
XPath, JSONPath and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
|
||||
(We support LXML re:test, re:math and re:replace.)
|
||||
XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
(We support LXML `re:test`, `re:math` and `re:replace`.)
|
||||
|
||||
## Notifications
|
||||
|
||||
@@ -129,42 +166,71 @@ Just some examples
|
||||
|
||||
<a href="https://github.com/caronc/apprise#popular-notification-services">And everything else in this list!</a>
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
|
||||
Now you can also customise your notification content!
|
||||
Now you can also customise your notification content and use <a target="_new" href="https://jinja.palletsprojects.com/en/3.0.x/templates/">Jinja2 templating</a> for their title and body!
|
||||
|
||||
## JSON API Monitoring
|
||||
|
||||
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||
Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
|
||||
|
||||

|
||||

|
||||
|
||||
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
|
||||
|
||||

|
||||
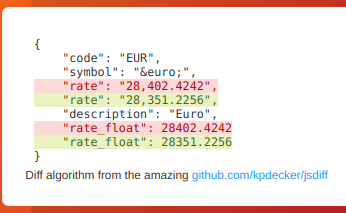
|
||||
|
||||
### JSONPath or jq?
|
||||
|
||||
For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specifc information on jq.
|
||||
|
||||
One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
|
||||
|
||||
### Parse JSON embedded in HTML!
|
||||
|
||||
When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
|
||||
```
|
||||
<html>
|
||||
...
|
||||
<script type="application/ld+json">
|
||||
{"@context":"http://schema.org","@type":"Product","name":"Nan Optipro Stage 1 Baby Formula 800g","price": 23.50 }
|
||||
|
||||
{
|
||||
"@context":"http://schema.org/",
|
||||
"@type":"Product",
|
||||
"offers":{
|
||||
"@type":"Offer",
|
||||
"availability":"http://schema.org/InStock",
|
||||
"price":"3949.99",
|
||||
"priceCurrency":"USD",
|
||||
"url":"https://www.newegg.com/p/3D5-000D-001T1"
|
||||
},
|
||||
"description":"Cobratype King Cobra Hero Desktop Gaming PC",
|
||||
"name":"Cobratype King Cobra Hero Desktop Gaming PC",
|
||||
"sku":"3D5-000D-001T1",
|
||||
"itemCondition":"NewCondition"
|
||||
}
|
||||
</script>
|
||||
```
|
||||
|
||||
`json:$.price` would give `23.50`, or you can extract the whole structure
|
||||
`json:$..price` or `jq:..price` would give `3949.99`, or you can extract the whole structure (use a JSONpath test website to validate with)
|
||||
|
||||
## Proxy configuration
|
||||
The application also supports notifying you that it can follow this information automatically
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration
|
||||
|
||||
## Proxy Configuration
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [BrightData proxy services where possible]( https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support)
|
||||
|
||||
## Raspberry Pi support?
|
||||
|
||||
Raspberry Pi and linux/arm/v6 linux/arm/v7 arm64 devices are supported! See the wiki for [details](https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver)
|
||||
|
||||
## API Support
|
||||
|
||||
Supports managing the website watch list [via our API](https://changedetection.io/docs/api_v1/index.html)
|
||||
|
||||
## Support us
|
||||
|
||||
@@ -177,7 +243,7 @@ Or directly donate an amount PayPal [:
|
||||
import sys
|
||||
print('Shutdown: Got SIGCHLD')
|
||||
# https://stackoverflow.com/questions/40453496/python-multiprocessing-capturing-signals-to-restart-child-processes-or-shut-do
|
||||
pid, status = os.waitpid(-1, os.WNOHANG | os.WUNTRACED | os.WCONTINUED)
|
||||
|
||||
print('Sub-process: pid %d status %d' % (pid, status))
|
||||
if status != 0:
|
||||
sys.exit(1)
|
||||
|
||||
raise SystemExit
|
||||
|
||||
if __name__ == '__main__':
|
||||
changedetection.main()
|
||||
|
||||
#signal.signal(signal.SIGCHLD, sigchld_handler)
|
||||
|
||||
# The only way I could find to get Flask to shutdown, is to wrap it and then rely on the subsystem issuing SIGTERM/SIGKILL
|
||||
parse_process = multiprocessing.Process(target=changedetection.main)
|
||||
parse_process.daemon = True
|
||||
parse_process.start()
|
||||
import time
|
||||
|
||||
try:
|
||||
while True:
|
||||
time.sleep(1)
|
||||
if not parse_process.is_alive():
|
||||
# Process died/crashed for some reason, exit with error set
|
||||
sys.exit(1)
|
||||
|
||||
except KeyboardInterrupt:
|
||||
#parse_process.terminate() not needed, because this process will issue it to the sub-process anyway
|
||||
print ("Exited - CTRL+C")
|
||||
|
||||
1
changedetectionio/.gitignore
vendored
@@ -1 +1,2 @@
|
||||
test-datastore
|
||||
package-lock.json
|
||||
|
||||
117
changedetectionio/api/api_schema.py
Normal file
@@ -0,0 +1,117 @@
|
||||
# Responsible for building the storage dict into a set of rules ("JSON Schema") acceptable via the API
|
||||
# Probably other ways to solve this when the backend switches to some ORM
|
||||
|
||||
def build_time_between_check_json_schema():
|
||||
# Setup time between check schema
|
||||
schema_properties_time_between_check = {
|
||||
"type": "object",
|
||||
"additionalProperties": False,
|
||||
"properties": {}
|
||||
}
|
||||
for p in ['weeks', 'days', 'hours', 'minutes', 'seconds']:
|
||||
schema_properties_time_between_check['properties'][p] = {
|
||||
"anyOf": [
|
||||
{
|
||||
"type": "integer"
|
||||
},
|
||||
{
|
||||
"type": "null"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
return schema_properties_time_between_check
|
||||
|
||||
def build_watch_json_schema(d):
|
||||
# Base JSON schema
|
||||
schema = {
|
||||
'type': 'object',
|
||||
'properties': {},
|
||||
}
|
||||
|
||||
for k, v in d.items():
|
||||
# @todo 'integer' is not covered here because its almost always for internal usage
|
||||
|
||||
if isinstance(v, type(None)):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "null"},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, list):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "array",
|
||||
# Always is an array of strings, like text or regex or something
|
||||
"items": {
|
||||
"type": "string",
|
||||
"maxLength": 5000
|
||||
}
|
||||
},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, bool):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "boolean"},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, str):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "string",
|
||||
"maxLength": 5000},
|
||||
]
|
||||
}
|
||||
|
||||
# Can also be a string (or None by default above)
|
||||
for v in ['body',
|
||||
'notification_body',
|
||||
'notification_format',
|
||||
'notification_title',
|
||||
'proxy',
|
||||
'tag',
|
||||
'title',
|
||||
'webdriver_js_execute_code'
|
||||
]:
|
||||
schema['properties'][v]['anyOf'].append({'type': 'string', "maxLength": 5000})
|
||||
|
||||
# None or Boolean
|
||||
schema['properties']['track_ldjson_price_data']['anyOf'].append({'type': 'boolean'})
|
||||
|
||||
schema['properties']['method'] = {"type": "string",
|
||||
"enum": ["GET", "POST", "DELETE", "PUT"]
|
||||
}
|
||||
|
||||
schema['properties']['fetch_backend']['anyOf'].append({"type": "string",
|
||||
"enum": ["html_requests", "html_webdriver"]
|
||||
})
|
||||
|
||||
|
||||
|
||||
# All headers must be key/value type dict
|
||||
schema['properties']['headers'] = {
|
||||
"type": "object",
|
||||
"patternProperties": {
|
||||
# Should always be a string:string type value
|
||||
".*": {"type": "string"},
|
||||
}
|
||||
}
|
||||
|
||||
from changedetectionio.notification import valid_notification_formats
|
||||
|
||||
schema['properties']['notification_format'] = {'type': 'string',
|
||||
'enum': list(valid_notification_formats.keys())
|
||||
}
|
||||
|
||||
# Stuff that shouldn't be available but is just state-storage
|
||||
for v in ['previous_md5', 'last_error', 'has_ldjson_price_data', 'previous_md5_before_filters', 'uuid']:
|
||||
del schema['properties'][v]
|
||||
|
||||
schema['properties']['webdriver_delay']['anyOf'].append({'type': 'integer'})
|
||||
|
||||
schema['properties']['time_between_check'] = build_time_between_check_json_schema()
|
||||
|
||||
# headers ?
|
||||
return schema
|
||||
|
||||
@@ -1,11 +1,24 @@
|
||||
from flask_expects_json import expects_json
|
||||
from changedetectionio import queuedWatchMetaData
|
||||
from flask_restful import abort, Resource
|
||||
from flask import request, make_response
|
||||
import validators
|
||||
from . import auth
|
||||
import copy
|
||||
|
||||
# See docs/README.md for rebuilding the docs/apidoc information
|
||||
|
||||
from . import api_schema
|
||||
|
||||
# https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
# Build a JSON Schema atleast partially based on our Watch model
|
||||
from changedetectionio.model.Watch import base_config as watch_base_config
|
||||
schema = api_schema.build_watch_json_schema(watch_base_config)
|
||||
|
||||
schema_create_watch = copy.deepcopy(schema)
|
||||
schema_create_watch['required'] = ['url']
|
||||
|
||||
schema_update_watch = copy.deepcopy(schema)
|
||||
schema_update_watch['additionalProperties'] = False
|
||||
|
||||
class Watch(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
@@ -15,31 +28,100 @@ class Watch(Resource):
|
||||
|
||||
# Get information about a single watch, excluding the history list (can be large)
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>
|
||||
# @todo - version2 - ?muted and ?paused should be able to be called together, return the watch struct not "OK"
|
||||
# ?recheck=true
|
||||
@auth.check_token
|
||||
def get(self, uuid):
|
||||
"""
|
||||
@api {get} /api/v1/watch/:uuid Get a single watch data
|
||||
@apiDescription Retrieve watch information and set muted/paused status
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
curl "http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091?muted=unmuted" -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
curl "http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091?paused=unpaused" -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
@apiName Watch
|
||||
@apiGroup Watch
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiQuery {Boolean} [recheck] Recheck this watch `recheck=1`
|
||||
@apiQuery {String} [paused] =`paused` or =`unpaused` , Sets the PAUSED state
|
||||
@apiQuery {String} [muted] =`muted` or =`unmuted` , Sets the MUTE NOTIFICATIONS state
|
||||
@apiSuccess (200) {String} OK When paused/muted/recheck operation OR full JSON object of the watch
|
||||
@apiSuccess (200) {JSON} WatchJSON JSON Full JSON object of the watch
|
||||
"""
|
||||
from copy import deepcopy
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if request.args.get('recheck'):
|
||||
self.update_q.put(uuid)
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': True}))
|
||||
return "OK", 200
|
||||
if request.args.get('paused', '') == 'paused':
|
||||
self.datastore.data['watching'].get(uuid).pause()
|
||||
return "OK", 200
|
||||
elif request.args.get('paused', '') == 'unpaused':
|
||||
self.datastore.data['watching'].get(uuid).unpause()
|
||||
return "OK", 200
|
||||
if request.args.get('muted', '') == 'muted':
|
||||
self.datastore.data['watching'].get(uuid).mute()
|
||||
return "OK", 200
|
||||
elif request.args.get('muted', '') == 'unmuted':
|
||||
self.datastore.data['watching'].get(uuid).unmute()
|
||||
return "OK", 200
|
||||
|
||||
# Return without history, get that via another API call
|
||||
watch['history_n'] = len(watch['history'])
|
||||
del (watch['history'])
|
||||
# Properties are not returned as a JSON, so add the required props manually
|
||||
watch['history_n'] = watch.history_n
|
||||
watch['last_changed'] = watch.last_changed
|
||||
|
||||
return watch
|
||||
|
||||
@auth.check_token
|
||||
def delete(self, uuid):
|
||||
"""
|
||||
@api {delete} /api/v1/watch/:uuid Delete a watch and related history
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -X DELETE -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiName Delete
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was deleted
|
||||
"""
|
||||
if not self.datastore.data['watching'].get(uuid):
|
||||
abort(400, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
self.datastore.delete(uuid)
|
||||
return 'OK', 204
|
||||
|
||||
@auth.check_token
|
||||
@expects_json(schema_update_watch)
|
||||
def put(self, uuid):
|
||||
"""
|
||||
@api {put} /api/v1/watch/:uuid Update watch information
|
||||
@apiExample {curl} Example usage:
|
||||
Update (PUT)
|
||||
curl http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -X PUT -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json" -d '{"url": "https://my-nice.com" , "tag": "new list"}'
|
||||
|
||||
@apiDescription Updates an existing watch using JSON, accepts the same structure as returned in <a href="#api-Watch-Watch">get single watch information</a>
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiName Update a watch
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was updated
|
||||
@apiSuccess (500) {String} ERR Some other error
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if request.json.get('proxy'):
|
||||
plist = self.datastore.proxy_list
|
||||
if not request.json.get('proxy') in plist:
|
||||
return "Invalid proxy choice, currently supported proxies are '{}'".format(', '.join(plist)), 400
|
||||
|
||||
watch.update(request.json)
|
||||
|
||||
return "OK", 200
|
||||
|
||||
|
||||
class WatchHistory(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
@@ -49,10 +131,25 @@ class WatchHistory(Resource):
|
||||
# Get a list of available history for a watch by UUID
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>/history
|
||||
def get(self, uuid):
|
||||
"""
|
||||
@api {get} /api/v1/watch/<string:uuid>/history Get a list of all historical snapshots available for a watch
|
||||
@apiDescription Requires `uuid`, returns list
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091/history -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json"
|
||||
{
|
||||
"1676649279": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/cb7e9be8258368262246910e6a2a4c30.txt",
|
||||
"1677092785": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/e20db368d6fc633e34f559ff67bb4044.txt",
|
||||
"1677103794": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/02efdd37dacdae96554a8cc85dc9c945.txt"
|
||||
}
|
||||
@apiName Get list of available stored snapshots for watch
|
||||
@apiGroup Watch History
|
||||
@apiSuccess (200) {String} OK
|
||||
@apiSuccess (404) {String} ERR Not found
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
return watch['history'], 200
|
||||
return watch.history, 200
|
||||
|
||||
|
||||
class WatchSingleHistory(Resource):
|
||||
@@ -60,23 +157,29 @@ class WatchSingleHistory(Resource):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
# Read a given history snapshot and return its content
|
||||
# <string:timestamp> or "latest"
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>/history/<int:timestamp>
|
||||
@auth.check_token
|
||||
def get(self, uuid, timestamp):
|
||||
"""
|
||||
@api {get} /api/v1/watch/<string:uuid>/history/<int:timestamp> Get single snapshot from watch
|
||||
@apiDescription Requires watch `uuid` and `timestamp`. `timestamp` of "`latest`" for latest available snapshot, or <a href="#api-Watch_History-Get_list_of_available_stored_snapshots_for_watch">use the list returned here</a>
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091/history/1677092977 -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json"
|
||||
@apiName Get single snapshot content
|
||||
@apiGroup Watch History
|
||||
@apiSuccess (200) {String} OK
|
||||
@apiSuccess (404) {String} ERR Not found
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if not len(watch['history']):
|
||||
if not len(watch.history):
|
||||
abort(404, message='Watch found but no history exists for the UUID {}'.format(uuid))
|
||||
|
||||
if timestamp == 'latest':
|
||||
timestamp = list(watch['history'].keys())[-1]
|
||||
timestamp = list(watch.history.keys())[-1]
|
||||
|
||||
with open(watch['history'][timestamp], 'r') as f:
|
||||
content = f.read()
|
||||
content = watch.get_history_snapshot(timestamp)
|
||||
|
||||
response = make_response(content, 200)
|
||||
response.mimetype = "text/plain"
|
||||
@@ -90,36 +193,138 @@ class CreateWatch(Resource):
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
@expects_json(schema_create_watch)
|
||||
def post(self):
|
||||
# curl http://localhost:4000/api/v1/watch -H "Content-Type: application/json" -d '{"url": "https://my-nice.com", "tag": "one, two" }'
|
||||
"""
|
||||
@api {post} /api/v1/watch Create a single watch
|
||||
@apiDescription Requires atleast `url` set, can accept the same structure as <a href="#api-Watch-Watch">get single watch information</a> to create.
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json" -d '{"url": "https://my-nice.com" , "tag": "nice list"}'
|
||||
@apiName Create
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was created
|
||||
@apiSuccess (500) {String} ERR Some other error
|
||||
"""
|
||||
|
||||
json_data = request.get_json()
|
||||
tag = json_data['tag'].strip() if json_data.get('tag') else ''
|
||||
url = json_data['url'].strip()
|
||||
|
||||
if not validators.url(json_data['url'].strip()):
|
||||
return "Invalid or unsupported URL", 400
|
||||
|
||||
extras = {'title': json_data['title'].strip()} if json_data.get('title') else {}
|
||||
if json_data.get('proxy'):
|
||||
plist = self.datastore.proxy_list
|
||||
if not json_data.get('proxy') in plist:
|
||||
return "Invalid proxy choice, currently supported proxies are '{}'".format(', '.join(plist)), 400
|
||||
|
||||
new_uuid = self.datastore.add_watch(url=json_data['url'].strip(), tag=tag, extras=extras)
|
||||
self.update_q.put(new_uuid)
|
||||
return {'uuid': new_uuid}, 201
|
||||
extras = copy.deepcopy(json_data)
|
||||
del extras['url']
|
||||
|
||||
new_uuid = self.datastore.add_watch(url=url, extras=extras)
|
||||
if new_uuid:
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': new_uuid, 'skip_when_checksum_same': True}))
|
||||
return {'uuid': new_uuid}, 201
|
||||
else:
|
||||
return "Invalid or unsupported URL", 400
|
||||
|
||||
# Return concise list of available watches and some very basic info
|
||||
# curl http://localhost:4000/api/v1/watch|python -mjson.tool
|
||||
# ?recheck_all=1 to recheck all
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
"""
|
||||
@api {get} /api/v1/watch List watches
|
||||
@apiDescription Return concise list of available watches and some very basic info
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/watch -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
{
|
||||
"6a4b7d5c-fee4-4616-9f43-4ac97046b595": {
|
||||
"last_changed": 1677103794,
|
||||
"last_checked": 1677103794,
|
||||
"last_error": false,
|
||||
"title": "",
|
||||
"url": "http://www.quotationspage.com/random.php"
|
||||
},
|
||||
"e6f5fd5c-dbfe-468b-b8f3-f9d6ff5ad69b": {
|
||||
"last_changed": 0,
|
||||
"last_checked": 1676662819,
|
||||
"last_error": false,
|
||||
"title": "QuickLook",
|
||||
"url": "https://github.com/QL-Win/QuickLook/tags"
|
||||
}
|
||||
}
|
||||
|
||||
@apiParam {String} [recheck_all] Optional Set to =1 to force recheck of all watches
|
||||
@apiParam {String} [tag] Optional name of tag to limit results
|
||||
@apiName ListWatches
|
||||
@apiGroup Watch Management
|
||||
@apiSuccess (200) {String} OK JSON dict
|
||||
"""
|
||||
list = {}
|
||||
for k, v in self.datastore.data['watching'].items():
|
||||
list[k] = {'url': v['url'],
|
||||
'title': v['title'],
|
||||
'last_checked': v['last_checked'],
|
||||
'last_changed': v['last_changed'],
|
||||
'last_error': v['last_error']}
|
||||
|
||||
tag_limit = request.args.get('tag', None)
|
||||
for k, watch in self.datastore.data['watching'].items():
|
||||
if tag_limit:
|
||||
if not tag_limit.lower() in watch.all_tags:
|
||||
continue
|
||||
|
||||
list[k] = {'url': watch['url'],
|
||||
'title': watch['title'],
|
||||
'last_checked': watch['last_checked'],
|
||||
'last_changed': watch.last_changed,
|
||||
'last_error': watch['last_error']}
|
||||
|
||||
if request.args.get('recheck_all'):
|
||||
for uuid in self.datastore.data['watching'].keys():
|
||||
self.update_q.put(uuid)
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': True}))
|
||||
return {'status': "OK"}, 200
|
||||
|
||||
return list, 200
|
||||
|
||||
class SystemInfo(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
"""
|
||||
@api {get} /api/v1/systeminfo Return system info
|
||||
@apiDescription Return some info about the current system state
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:4000/api/v1/systeminfo -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
HTTP/1.0 200
|
||||
{
|
||||
'queue_size': 10 ,
|
||||
'overdue_watches': ["watch-uuid-list"],
|
||||
'uptime': 38344.55,
|
||||
'watch_count': 800,
|
||||
'version': "0.40.1"
|
||||
}
|
||||
@apiName Get Info
|
||||
@apiGroup System Information
|
||||
"""
|
||||
import time
|
||||
overdue_watches = []
|
||||
|
||||
# Check all watches and report which have not been checked but should have been
|
||||
|
||||
for uuid, watch in self.datastore.data.get('watching', {}).items():
|
||||
# see if now - last_checked is greater than the time that should have been
|
||||
# this is not super accurate (maybe they just edited it) but better than nothing
|
||||
t = watch.threshold_seconds()
|
||||
if not t:
|
||||
# Use the system wide default
|
||||
t = self.datastore.threshold_seconds
|
||||
|
||||
time_since_check = time.time() - watch.get('last_checked')
|
||||
|
||||
# Allow 5 minutes of grace time before we decide it's overdue
|
||||
if time_since_check - (5 * 60) > t:
|
||||
overdue_watches.append(uuid)
|
||||
from changedetectionio import __version__ as main_version
|
||||
return {
|
||||
'queue_size': self.update_q.qsize(),
|
||||
'overdue_watches': overdue_watches,
|
||||
'uptime': round(time.time() - self.datastore.start_time, 2),
|
||||
'watch_count': len(self.datastore.data.get('watching', {})),
|
||||
'version': main_version
|
||||
}, 200
|
||||
|
||||
11
changedetectionio/apprise_asset.py
Normal file
@@ -0,0 +1,11 @@
|
||||
import apprise
|
||||
|
||||
# Create our AppriseAsset and populate it with some of our new values:
|
||||
# https://github.com/caronc/apprise/wiki/Development_API#the-apprise-asset-object
|
||||
asset = apprise.AppriseAsset(
|
||||
image_url_logo='https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
|
||||
)
|
||||
|
||||
asset.app_id = "changedetection.io"
|
||||
asset.app_desc = "ChangeDetection.io best and simplest website monitoring and change detection"
|
||||
asset.app_url = "https://changedetection.io"
|
||||
0
changedetectionio/blueprint/__init__.py
Normal file
239
changedetectionio/blueprint/browser_steps/__init__.py
Normal file
@@ -0,0 +1,239 @@
|
||||
|
||||
# HORRIBLE HACK BUT WORKS :-) PR anyone?
|
||||
#
|
||||
# Why?
|
||||
# `browsersteps_playwright_browser_interface.chromium.connect_over_cdp()` will only run once without async()
|
||||
# - this flask app is not async()
|
||||
# - browserless has a single timeout/keepalive which applies to the session made at .connect_over_cdp()
|
||||
#
|
||||
# So it means that we must unfortunately for now just keep a single timer since .connect_over_cdp() was run
|
||||
# and know when that reaches timeout/keepalive :( when that time is up, restart the connection and tell the user
|
||||
# that their time is up, insert another coin. (reload)
|
||||
#
|
||||
# Bigger picture
|
||||
# - It's horrible that we have this click+wait deal, some nice socket.io solution using something similar
|
||||
# to what the browserless debug UI already gives us would be smarter..
|
||||
#
|
||||
# OR
|
||||
# - Some API call that should be hacked into browserless or playwright that we can "/api/bump-keepalive/{session_id}/60"
|
||||
# So we can tell it that we need more time (run this on each action)
|
||||
#
|
||||
# OR
|
||||
# - use multiprocessing to bump this over to its own process and add some transport layer (queue/pipes)
|
||||
|
||||
from distutils.util import strtobool
|
||||
from flask import Blueprint, request, make_response
|
||||
import os
|
||||
import logging
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
from changedetectionio import login_optionally_required
|
||||
browsersteps_live_ui_o = {}
|
||||
browsersteps_playwright_browser_interface = None
|
||||
browsersteps_playwright_browser_interface_browser = None
|
||||
browsersteps_playwright_browser_interface_context = None
|
||||
browsersteps_playwright_browser_interface_end_time = None
|
||||
browsersteps_playwright_browser_interface_start_time = None
|
||||
|
||||
def cleanup_playwright_session():
|
||||
|
||||
global browsersteps_live_ui_o
|
||||
global browsersteps_playwright_browser_interface
|
||||
global browsersteps_playwright_browser_interface_browser
|
||||
global browsersteps_playwright_browser_interface_context
|
||||
global browsersteps_playwright_browser_interface_end_time
|
||||
global browsersteps_playwright_browser_interface_start_time
|
||||
|
||||
browsersteps_live_ui_o = {}
|
||||
browsersteps_playwright_browser_interface = None
|
||||
browsersteps_playwright_browser_interface_browser = None
|
||||
browsersteps_playwright_browser_interface_end_time = None
|
||||
browsersteps_playwright_browser_interface_start_time = None
|
||||
|
||||
print("Cleaning up old playwright session because time was up, calling .goodbye()")
|
||||
try:
|
||||
browsersteps_playwright_browser_interface_context.goodbye()
|
||||
except Exception as e:
|
||||
print ("Got exception in shutdown, probably OK")
|
||||
print (str(e))
|
||||
|
||||
browsersteps_playwright_browser_interface_context = None
|
||||
|
||||
print ("Cleaning up old playwright session because time was up - done")
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore):
|
||||
|
||||
browser_steps_blueprint = Blueprint('browser_steps', __name__, template_folder="templates")
|
||||
|
||||
@login_optionally_required
|
||||
@browser_steps_blueprint.route("/browsersteps_update", methods=['GET', 'POST'])
|
||||
def browsersteps_ui_update():
|
||||
import base64
|
||||
import playwright._impl._api_types
|
||||
import time
|
||||
|
||||
from changedetectionio.blueprint.browser_steps import browser_steps
|
||||
|
||||
global browsersteps_live_ui_o, browsersteps_playwright_browser_interface_end_time
|
||||
global browsersteps_playwright_browser_interface_browser
|
||||
global browsersteps_playwright_browser_interface
|
||||
global browsersteps_playwright_browser_interface_start_time
|
||||
|
||||
step_n = None
|
||||
remaining =0
|
||||
uuid = request.args.get('uuid')
|
||||
|
||||
browsersteps_session_id = request.args.get('browsersteps_session_id')
|
||||
|
||||
if not browsersteps_session_id:
|
||||
return make_response('No browsersteps_session_id specified', 500)
|
||||
|
||||
# Because we don't "really" run in a context manager ( we make the playwright interface global/long-living )
|
||||
# We need to manage the shutdown when the time is up
|
||||
if browsersteps_playwright_browser_interface_end_time:
|
||||
remaining = browsersteps_playwright_browser_interface_end_time-time.time()
|
||||
if browsersteps_playwright_browser_interface_end_time and remaining <= 0:
|
||||
cleanup_playwright_session()
|
||||
return make_response('Browser session expired, please reload the Browser Steps interface', 401)
|
||||
|
||||
# Actions - step/apply/etc, do the thing and return state
|
||||
if request.method == 'POST':
|
||||
# @todo - should always be an existing session
|
||||
step_operation = request.form.get('operation')
|
||||
step_selector = request.form.get('selector')
|
||||
step_optional_value = request.form.get('optional_value')
|
||||
step_n = int(request.form.get('step_n'))
|
||||
is_last_step = strtobool(request.form.get('is_last_step'))
|
||||
|
||||
if step_operation == 'Goto site':
|
||||
step_operation = 'goto_url'
|
||||
step_optional_value = datastore.data['watching'][uuid].get('url')
|
||||
step_selector = None
|
||||
|
||||
# @todo try.. accept.. nice errors not popups..
|
||||
try:
|
||||
|
||||
this_session = browsersteps_live_ui_o.get(browsersteps_session_id)
|
||||
if not this_session:
|
||||
print("Browser exited")
|
||||
return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
this_session.call_action(action_name=step_operation,
|
||||
selector=step_selector,
|
||||
optional_value=step_optional_value)
|
||||
|
||||
except Exception as e:
|
||||
print("Exception when calling step operation", step_operation, str(e))
|
||||
# Try to find something of value to give back to the user
|
||||
return make_response(str(e).splitlines()[0], 401)
|
||||
|
||||
# Get visual selector ready/update its data (also use the current filter info from the page?)
|
||||
# When the last 'apply' button was pressed
|
||||
# @todo this adds overhead because the xpath selection is happening twice
|
||||
u = this_session.page.url
|
||||
if is_last_step and u:
|
||||
(screenshot, xpath_data) = this_session.request_visualselector_data()
|
||||
datastore.save_screenshot(watch_uuid=uuid, screenshot=screenshot)
|
||||
datastore.save_xpath_data(watch_uuid=uuid, data=xpath_data)
|
||||
|
||||
# Setup interface
|
||||
if request.method == 'GET':
|
||||
|
||||
if not browsersteps_playwright_browser_interface:
|
||||
print("Starting connection with playwright")
|
||||
logging.debug("browser_steps.py connecting")
|
||||
|
||||
global browsersteps_playwright_browser_interface_context
|
||||
from . import nonContext
|
||||
browsersteps_playwright_browser_interface_context = nonContext.c_sync_playwright()
|
||||
browsersteps_playwright_browser_interface = browsersteps_playwright_browser_interface_context.start()
|
||||
# At 20 minutes, some other variable is closing it
|
||||
# @todo find out what it is and set it
|
||||
seconds_keepalive = int(os.getenv('BROWSERSTEPS_MINUTES_KEEPALIVE', 10)) * 60
|
||||
|
||||
# keep it alive for 10 seconds more than we advertise, sometimes it helps to keep it shutting down cleanly
|
||||
keepalive = "&timeout={}".format(((seconds_keepalive+3) * 1000))
|
||||
try:
|
||||
browsersteps_playwright_browser_interface_browser = browsersteps_playwright_browser_interface.chromium.connect_over_cdp(
|
||||
os.getenv('PLAYWRIGHT_DRIVER_URL', '') + keepalive)
|
||||
except Exception as e:
|
||||
if 'ECONNREFUSED' in str(e):
|
||||
return make_response('Unable to start the Playwright session properly, is it running?', 401)
|
||||
|
||||
browsersteps_playwright_browser_interface_end_time = time.time() + (seconds_keepalive-3)
|
||||
print("Starting connection with playwright - done")
|
||||
|
||||
if not browsersteps_live_ui_o.get(browsersteps_session_id):
|
||||
# Boot up a new session
|
||||
proxy_id = datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
proxy = None
|
||||
if proxy_id:
|
||||
proxy_url = datastore.proxy_list.get(proxy_id).get('url')
|
||||
if proxy_url:
|
||||
|
||||
# Playwright needs separate username and password values
|
||||
from urllib.parse import urlparse
|
||||
parsed = urlparse(proxy_url)
|
||||
proxy = {'server': proxy_url}
|
||||
|
||||
if parsed.username:
|
||||
proxy['username'] = parsed.username
|
||||
|
||||
if parsed.password:
|
||||
proxy['password'] = parsed.password
|
||||
|
||||
print("Browser Steps: UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||
|
||||
# Begin the new "Playwright Context" that re-uses the playwright interface
|
||||
# Each session is a "Playwright Context" as a list, that uses the playwright interface
|
||||
browsersteps_live_ui_o[browsersteps_session_id] = browser_steps.browsersteps_live_ui(
|
||||
playwright_browser=browsersteps_playwright_browser_interface_browser,
|
||||
proxy=proxy)
|
||||
this_session = browsersteps_live_ui_o[browsersteps_session_id]
|
||||
|
||||
if not this_session.page:
|
||||
cleanup_playwright_session()
|
||||
return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
response = None
|
||||
|
||||
if request.method == 'POST':
|
||||
# Screenshots and other info only needed on requesting a step (POST)
|
||||
try:
|
||||
state = this_session.get_current_state()
|
||||
except playwright._impl._api_types.Error as e:
|
||||
return make_response("Browser session ran out of time :( Please reload this page."+str(e), 401)
|
||||
|
||||
# Use send_file() which is way faster than read/write loop on bytes
|
||||
import json
|
||||
from tempfile import mkstemp
|
||||
from flask import send_file
|
||||
tmp_fd, tmp_file = mkstemp(text=True, suffix=".json", prefix="changedetectionio-")
|
||||
|
||||
output = json.dumps({'screenshot': "data:image/jpeg;base64,{}".format(
|
||||
base64.b64encode(state[0]).decode('ascii')),
|
||||
'xpath_data': state[1],
|
||||
'session_age_start': this_session.age_start,
|
||||
'browser_time_remaining': round(remaining)
|
||||
})
|
||||
|
||||
with os.fdopen(tmp_fd, 'w') as f:
|
||||
f.write(output)
|
||||
|
||||
response = make_response(send_file(path_or_file=tmp_file,
|
||||
mimetype='application/json; charset=UTF-8',
|
||||
etag=True))
|
||||
# No longer needed
|
||||
os.unlink(tmp_file)
|
||||
|
||||
elif request.method == 'GET':
|
||||
# Just enough to get the session rolling, it will call for goto-site via POST next
|
||||
response = make_response({
|
||||
'session_age_start': this_session.age_start,
|
||||
'browser_time_remaining': round(remaining)
|
||||
})
|
||||
|
||||
return response
|
||||
|
||||
return browser_steps_blueprint
|
||||
|
||||
|
||||
281
changedetectionio/blueprint/browser_steps/browser_steps.py
Normal file
@@ -0,0 +1,281 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
from random import randint
|
||||
|
||||
# Two flags, tell the JS which of the "Selector" or "Value" field should be enabled in the front end
|
||||
# 0- off, 1- on
|
||||
browser_step_ui_config = {'Choose one': '0 0',
|
||||
# 'Check checkbox': '1 0',
|
||||
# 'Click button containing text': '0 1',
|
||||
# 'Scroll to bottom': '0 0',
|
||||
# 'Scroll to element': '1 0',
|
||||
# 'Scroll to top': '0 0',
|
||||
# 'Switch to iFrame by index number': '0 1'
|
||||
# 'Uncheck checkbox': '1 0',
|
||||
# @todo
|
||||
'Check checkbox': '1 0',
|
||||
'Click X,Y': '0 1',
|
||||
'Click element if exists': '1 0',
|
||||
'Click element': '1 0',
|
||||
'Click element containing text': '0 1',
|
||||
'Enter text in field': '1 1',
|
||||
'Execute JS': '0 1',
|
||||
# 'Extract text and use as filter': '1 0',
|
||||
'Goto site': '0 0',
|
||||
'Goto URL': '0 1',
|
||||
'Press Enter': '0 0',
|
||||
'Select by label': '1 1',
|
||||
'Scroll down': '0 0',
|
||||
'Uncheck checkbox': '1 0',
|
||||
'Wait for seconds': '0 1',
|
||||
'Wait for text': '0 1',
|
||||
'Wait for text in element': '1 1',
|
||||
# 'Press Page Down': '0 0',
|
||||
# 'Press Page Up': '0 0',
|
||||
# weird bug, come back to it later
|
||||
}
|
||||
|
||||
|
||||
# Good reference - https://playwright.dev/python/docs/input
|
||||
# https://pythonmana.com/2021/12/202112162236307035.html
|
||||
#
|
||||
# ONLY Works in Playwright because we need the fullscreen screenshot
|
||||
class steppable_browser_interface():
|
||||
page = None
|
||||
|
||||
# Convert and perform "Click Button" for example
|
||||
def call_action(self, action_name, selector=None, optional_value=None):
|
||||
now = time.time()
|
||||
call_action_name = re.sub('[^0-9a-zA-Z]+', '_', action_name.lower())
|
||||
if call_action_name == 'choose_one':
|
||||
return
|
||||
|
||||
print("> action calling", call_action_name)
|
||||
# https://playwright.dev/python/docs/selectors#xpath-selectors
|
||||
if selector and selector.startswith('/') and not selector.startswith('//'):
|
||||
selector = "xpath=" + selector
|
||||
|
||||
action_handler = getattr(self, "action_" + call_action_name)
|
||||
|
||||
# Support for Jinja2 variables in the value and selector
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
if selector and ('{%' in selector or '{{' in selector):
|
||||
selector = str(jinja2_env.from_string(selector).render())
|
||||
|
||||
if optional_value and ('{%' in optional_value or '{{' in optional_value):
|
||||
optional_value = str(jinja2_env.from_string(optional_value).render())
|
||||
|
||||
action_handler(selector, optional_value)
|
||||
self.page.wait_for_timeout(3 * 1000)
|
||||
print("Call action done in", time.time() - now)
|
||||
|
||||
def action_goto_url(self, selector, value):
|
||||
# self.page.set_viewport_size({"width": 1280, "height": 5000})
|
||||
now = time.time()
|
||||
response = self.page.goto(value, timeout=0, wait_until='commit')
|
||||
|
||||
# Wait_until = commit
|
||||
# - `'commit'` - consider operation to be finished when network response is received and the document started loading.
|
||||
# Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
|
||||
# This seemed to solve nearly all 'TimeoutErrors'
|
||||
print("Time to goto URL ", time.time() - now)
|
||||
|
||||
def action_click_element_containing_text(self, selector=None, value=''):
|
||||
if not len(value.strip()):
|
||||
return
|
||||
elem = self.page.get_by_text(value)
|
||||
if elem.count():
|
||||
elem.first.click(delay=randint(200, 500), timeout=3000)
|
||||
|
||||
def action_enter_text_in_field(self, selector, value):
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
|
||||
self.page.fill(selector, value, timeout=10 * 1000)
|
||||
|
||||
def action_execute_js(self, selector, value):
|
||||
self.page.evaluate(value)
|
||||
|
||||
def action_click_element(self, selector, value):
|
||||
print("Clicking element")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
|
||||
|
||||
def action_click_element_if_exists(self, selector, value):
|
||||
import playwright._impl._api_types as _api_types
|
||||
print("Clicking element if exists")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
try:
|
||||
self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
|
||||
except _api_types.TimeoutError as e:
|
||||
return
|
||||
except _api_types.Error as e:
|
||||
# Element was there, but page redrew and now its long long gone
|
||||
return
|
||||
|
||||
def action_click_x_y(self, selector, value):
|
||||
x, y = value.strip().split(',')
|
||||
x = int(float(x.strip()))
|
||||
y = int(float(y.strip()))
|
||||
self.page.mouse.click(x=x, y=y, delay=randint(200, 500))
|
||||
|
||||
def action_scroll_down(self, selector, value):
|
||||
# Some sites this doesnt work on for some reason
|
||||
self.page.mouse.wheel(0, 600)
|
||||
self.page.wait_for_timeout(1000)
|
||||
|
||||
def action_wait_for_seconds(self, selector, value):
|
||||
self.page.wait_for_timeout(int(value) * 1000)
|
||||
|
||||
def action_wait_for_text(self, selector, value):
|
||||
import json
|
||||
v = json.dumps(value)
|
||||
self.page.wait_for_function(f'document.querySelector("body").innerText.includes({v});', timeout=30000)
|
||||
|
||||
def action_wait_for_text_in_element(self, selector, value):
|
||||
import json
|
||||
s = json.dumps(selector)
|
||||
v = json.dumps(value)
|
||||
self.page.wait_for_function(f'document.querySelector({s}).innerText.includes({v});', timeout=30000)
|
||||
|
||||
# @todo - in the future make some popout interface to capture what needs to be set
|
||||
# https://playwright.dev/python/docs/api/class-keyboard
|
||||
def action_press_enter(self, selector, value):
|
||||
self.page.keyboard.press("Enter", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_up(self, selector, value):
|
||||
self.page.keyboard.press("PageUp", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_down(self, selector, value):
|
||||
self.page.keyboard.press("PageDown", delay=randint(200, 500))
|
||||
|
||||
def action_check_checkbox(self, selector, value):
|
||||
self.page.locator(selector).check(timeout=1000)
|
||||
|
||||
def action_uncheck_checkbox(self, selector, value):
|
||||
self.page.locator(selector, timeout=1000).uncheck(timeout=1000)
|
||||
|
||||
|
||||
# Responsible for maintaining a live 'context' with browserless
|
||||
# @todo - how long do contexts live for anyway?
|
||||
class browsersteps_live_ui(steppable_browser_interface):
|
||||
context = None
|
||||
page = None
|
||||
render_extra_delay = 1
|
||||
stale = False
|
||||
# bump and kill this if idle after X sec
|
||||
age_start = 0
|
||||
|
||||
# use a special driver, maybe locally etc
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_BROWSERSTEPS_DRIVER_URL"
|
||||
)
|
||||
# if not..
|
||||
if not command_executor:
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_DRIVER_URL",
|
||||
'ws://playwright-chrome:3000'
|
||||
).strip('"')
|
||||
|
||||
browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
|
||||
def __init__(self, playwright_browser, proxy=None):
|
||||
self.age_start = time.time()
|
||||
self.playwright_browser = playwright_browser
|
||||
if self.context is None:
|
||||
self.connect(proxy=proxy)
|
||||
|
||||
# Connect and setup a new context
|
||||
def connect(self, proxy=None):
|
||||
# Should only get called once - test that
|
||||
keep_open = 1000 * 60 * 5
|
||||
now = time.time()
|
||||
|
||||
# @todo handle multiple contexts, bind a unique id from the browser on each req?
|
||||
self.context = self.playwright_browser.new_context(
|
||||
# @todo
|
||||
# user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
# proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should never be needed
|
||||
accept_downloads=False,
|
||||
proxy=proxy
|
||||
)
|
||||
|
||||
self.page = self.context.new_page()
|
||||
|
||||
# self.page.set_default_navigation_timeout(keep_open)
|
||||
self.page.set_default_timeout(keep_open)
|
||||
# @todo probably this doesnt work
|
||||
self.page.on(
|
||||
"close",
|
||||
self.mark_as_closed,
|
||||
)
|
||||
# Listen for all console events and handle errors
|
||||
self.page.on("console", lambda msg: print(f"Browser steps console - {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
print("Time to browser setup", time.time() - now)
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
def mark_as_closed(self):
|
||||
print("Page closed, cleaning up..")
|
||||
|
||||
@property
|
||||
def has_expired(self):
|
||||
if not self.page:
|
||||
return True
|
||||
|
||||
|
||||
def get_current_state(self):
|
||||
"""Return the screenshot and interactive elements mapping, generally always called after action_()"""
|
||||
from pkg_resources import resource_string
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
now = time.time()
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
# The actual screenshot
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=40)
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
# Go find the interactive elements
|
||||
# @todo in the future, something smarter that can scan for elements with .click/focus etc event handlers?
|
||||
elements = 'a,button,input,select,textarea,i,th,td,p,li,h1,h2,h3,h4,div,span'
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', elements)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
# So the JS will find the smallest one first
|
||||
xpath_data['size_pos'] = sorted(xpath_data['size_pos'], key=lambda k: k['width'] * k['height'], reverse=True)
|
||||
print("Time to complete get_current_state of browser", time.time() - now)
|
||||
# except
|
||||
# playwright._impl._api_types.Error: Browser closed.
|
||||
# @todo show some countdown timer?
|
||||
return (screenshot, xpath_data)
|
||||
|
||||
def request_visualselector_data(self):
|
||||
"""
|
||||
Does the same that the playwright operation in content_fetcher does
|
||||
This is used to just bump the VisualSelector data so it' ready to go if they click on the tab
|
||||
@todo refactor and remove duplicate code, add include_filters
|
||||
:param xpath_data:
|
||||
:param screenshot:
|
||||
:param current_include_filters:
|
||||
:return:
|
||||
"""
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
from changedetectionio.content_fetcher import visualselector_xpath_selectors
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
|
||||
return (screenshot, xpath_data)
|
||||
18
changedetectionio/blueprint/browser_steps/nonContext.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from playwright.sync_api import PlaywrightContextManager
|
||||
import asyncio
|
||||
|
||||
# So playwright wants to run as a context manager, but we do something horrible and hacky
|
||||
# we are holding the session open for as long as possible, then shutting it down, and opening a new one
|
||||
# So it means we don't get to use PlaywrightContextManager' __enter__ __exit__
|
||||
# To work around this, make goodbye() act the same as the __exit__()
|
||||
#
|
||||
# But actually I think this is because the context is opened correctly with __enter__() but we timeout the connection
|
||||
# then theres some lock condition where we cant destroy it without it hanging
|
||||
|
||||
class c_PlaywrightContextManager(PlaywrightContextManager):
|
||||
|
||||
def goodbye(self) -> None:
|
||||
self.__exit__()
|
||||
|
||||
def c_sync_playwright() -> PlaywrightContextManager:
|
||||
return c_PlaywrightContextManager()
|
||||
33
changedetectionio/blueprint/price_data_follower/__init__.py
Normal file
@@ -0,0 +1,33 @@
|
||||
|
||||
from distutils.util import strtobool
|
||||
from flask import Blueprint, flash, redirect, url_for
|
||||
from flask_login import login_required
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
from changedetectionio import queuedWatchMetaData
|
||||
from queue import PriorityQueue
|
||||
|
||||
PRICE_DATA_TRACK_ACCEPT = 'accepted'
|
||||
PRICE_DATA_TRACK_REJECT = 'rejected'
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore, update_q: PriorityQueue):
|
||||
|
||||
price_data_follower_blueprint = Blueprint('price_data_follower', __name__)
|
||||
|
||||
@login_required
|
||||
@price_data_follower_blueprint.route("/<string:uuid>/accept", methods=['GET'])
|
||||
def accept(uuid):
|
||||
datastore.data['watching'][uuid]['track_ldjson_price_data'] = PRICE_DATA_TRACK_ACCEPT
|
||||
update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': False}))
|
||||
return redirect(url_for("form_watch_checknow", uuid=uuid))
|
||||
|
||||
|
||||
@login_required
|
||||
@price_data_follower_blueprint.route("/<string:uuid>/reject", methods=['GET'])
|
||||
def reject(uuid):
|
||||
datastore.data['watching'][uuid]['track_ldjson_price_data'] = PRICE_DATA_TRACK_REJECT
|
||||
return redirect(url_for("index"))
|
||||
|
||||
|
||||
return price_data_follower_blueprint
|
||||
|
||||
|
||||
@@ -2,21 +2,42 @@
|
||||
|
||||
# Launch as a eventlet.wsgi server instance.
|
||||
|
||||
import getopt
|
||||
import os
|
||||
import sys
|
||||
from distutils.util import strtobool
|
||||
from json.decoder import JSONDecodeError
|
||||
|
||||
import eventlet
|
||||
import eventlet.wsgi
|
||||
import getopt
|
||||
import os
|
||||
import signal
|
||||
import socket
|
||||
import sys
|
||||
|
||||
from . import store, changedetection_app, content_fetcher
|
||||
from . import __version__
|
||||
|
||||
# Only global so we can access it in the signal handler
|
||||
app = None
|
||||
datastore = None
|
||||
|
||||
def sigterm_handler(_signo, _stack_frame):
|
||||
global app
|
||||
global datastore
|
||||
# app.config.exit.set()
|
||||
print('Shutdown: Got SIGTERM, DB saved to disk')
|
||||
datastore.sync_to_json()
|
||||
# raise SystemExit
|
||||
|
||||
def main():
|
||||
ssl_mode = False
|
||||
host = ''
|
||||
port = os.environ.get('PORT') or 5000
|
||||
do_cleanup = False
|
||||
global datastore
|
||||
global app
|
||||
|
||||
datastore_path = None
|
||||
do_cleanup = False
|
||||
host = ''
|
||||
ipv6_enabled = False
|
||||
port = os.environ.get('PORT') or 5000
|
||||
ssl_mode = False
|
||||
|
||||
# On Windows, create and use a default path.
|
||||
if os.name == 'nt':
|
||||
@@ -27,7 +48,7 @@ def main():
|
||||
datastore_path = os.path.join(os.getcwd(), "../datastore")
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "Ccsd:h:p:", "port")
|
||||
opts, args = getopt.getopt(sys.argv[1:], "6Ccsd:h:p:", "port")
|
||||
except getopt.GetoptError:
|
||||
print('backend.py -s SSL enable -h [host] -p [port] -d [datastore path]')
|
||||
sys.exit(2)
|
||||
@@ -35,11 +56,6 @@ def main():
|
||||
create_datastore_dir = False
|
||||
|
||||
for opt, arg in opts:
|
||||
# if opt == '--purge':
|
||||
# Remove history, the actual files you need to delete manually.
|
||||
# for uuid, watch in datastore.data['watching'].items():
|
||||
# watch.update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': None})
|
||||
|
||||
if opt == '-s':
|
||||
ssl_mode = True
|
||||
|
||||
@@ -52,6 +68,10 @@ def main():
|
||||
if opt == '-d':
|
||||
datastore_path = arg
|
||||
|
||||
if opt == '-6':
|
||||
print ("Enabling IPv6 listen support")
|
||||
ipv6_enabled = True
|
||||
|
||||
# Cleanup (remove text files that arent in the index)
|
||||
if opt == '-c':
|
||||
do_cleanup = True
|
||||
@@ -72,9 +92,18 @@ def main():
|
||||
"Or use the -C parameter to create the directory.".format(app_config['datastore_path']), file=sys.stderr)
|
||||
sys.exit(2)
|
||||
|
||||
datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=__version__)
|
||||
try:
|
||||
datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=__version__)
|
||||
except JSONDecodeError as e:
|
||||
# Dont' start if the JSON DB looks corrupt
|
||||
print ("ERROR: JSON DB or Proxy List JSON at '{}' appears to be corrupt, aborting".format(app_config['datastore_path']))
|
||||
print(str(e))
|
||||
return
|
||||
|
||||
app = changedetection_app(app_config, datastore)
|
||||
|
||||
signal.signal(signal.SIGTERM, sigterm_handler)
|
||||
|
||||
# Go into cleanup mode
|
||||
if do_cleanup:
|
||||
datastore.remove_unused_snapshots()
|
||||
@@ -89,6 +118,15 @@ def main():
|
||||
has_password=datastore.data['settings']['application']['password'] != False
|
||||
)
|
||||
|
||||
# Monitored websites will not receive a Referer header when a user clicks on an outgoing link.
|
||||
# @Note: Incompatible with password login (and maybe other features) for now, submit a PR!
|
||||
@app.after_request
|
||||
def hide_referrer(response):
|
||||
if strtobool(os.getenv("HIDE_REFERER", 'false')):
|
||||
response.headers["Referrer-Policy"] = "no-referrer"
|
||||
|
||||
return response
|
||||
|
||||
# Proxy sub-directory support
|
||||
# Set environment var USE_X_SETTINGS=1 on this script
|
||||
# And then in your proxy_pass settings
|
||||
@@ -101,14 +139,15 @@ def main():
|
||||
from werkzeug.middleware.proxy_fix import ProxyFix
|
||||
app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
|
||||
|
||||
s_type = socket.AF_INET6 if ipv6_enabled else socket.AF_INET
|
||||
|
||||
if ssl_mode:
|
||||
# @todo finalise SSL config, but this should get you in the right direction if you need it.
|
||||
eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen((host, port)),
|
||||
eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen((host, port), s_type),
|
||||
certfile='cert.pem',
|
||||
keyfile='privkey.pem',
|
||||
server_side=True), app)
|
||||
|
||||
else:
|
||||
eventlet.wsgi.server(eventlet.listen((host, int(port))), app)
|
||||
|
||||
eventlet.wsgi.server(eventlet.listen((host, int(port)), s_type), app)
|
||||
|
||||
|
||||
@@ -1,40 +1,117 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import hashlib
|
||||
from abc import abstractmethod
|
||||
import chardet
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import requests
|
||||
import time
|
||||
import sys
|
||||
import time
|
||||
|
||||
visualselector_xpath_selectors = 'div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary'
|
||||
|
||||
|
||||
class Non200ErrorCodeReceived(Exception):
|
||||
def __init__(self, status_code, url, screenshot=None, xpath_data=None, page_html=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.xpath_data = xpath_data
|
||||
self.page_text = None
|
||||
|
||||
if page_html:
|
||||
from changedetectionio import html_tools
|
||||
self.page_text = html_tools.html_to_text(page_html)
|
||||
return
|
||||
|
||||
|
||||
class checksumFromPreviousCheckWasTheSame(Exception):
|
||||
def __init__(self):
|
||||
return
|
||||
|
||||
|
||||
class JSActionExceptions(Exception):
|
||||
def __init__(self, status_code, url, screenshot, message=''):
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.message = message
|
||||
return
|
||||
|
||||
|
||||
class BrowserStepsStepTimout(Exception):
|
||||
def __init__(self, step_n):
|
||||
self.step_n = step_n
|
||||
return
|
||||
|
||||
|
||||
class PageUnloadable(Exception):
|
||||
def __init__(self, status_code, url, message, screenshot=False):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.message = message
|
||||
return
|
||||
|
||||
|
||||
class EmptyReply(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
def __init__(self, status_code, url, screenshot=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
return
|
||||
pass
|
||||
|
||||
|
||||
class ScreenshotUnavailable(Exception):
|
||||
def __init__(self, status_code, url, page_html=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
if page_html:
|
||||
from html_tools import html_to_text
|
||||
self.page_text = html_to_text(page_html)
|
||||
return
|
||||
|
||||
|
||||
class ReplyWithContentButNoText(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
def __init__(self, status_code, url, screenshot=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
return
|
||||
pass
|
||||
|
||||
|
||||
class Fetcher():
|
||||
error = None
|
||||
status_code = None
|
||||
browser_steps = None
|
||||
browser_steps_screenshot_path = None
|
||||
content = None
|
||||
headers = None
|
||||
error = None
|
||||
fetcher_description = "No description"
|
||||
headers = {}
|
||||
status_code = None
|
||||
webdriver_js_execute_code = None
|
||||
xpath_data = None
|
||||
xpath_element_js = ""
|
||||
instock_data = None
|
||||
instock_data_js = ""
|
||||
|
||||
# Will be needed in the future by the VisualSelector, always get this where possible.
|
||||
screenshot = False
|
||||
fetcher_description = "No description"
|
||||
system_http_proxy = os.getenv('HTTP_PROXY')
|
||||
system_https_proxy = os.getenv('HTTPS_PROXY')
|
||||
|
||||
# Time ONTOP of the system defined env minimum time
|
||||
render_extract_delay=0
|
||||
render_extract_delay = 0
|
||||
|
||||
def __init__(self):
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
self.xpath_element_js = resource_string(__name__, "res/xpath_element_scraper.js").decode('utf-8')
|
||||
self.instock_data_js = resource_string(__name__, "res/stock-not-in-stock.js").decode('utf-8')
|
||||
|
||||
@abstractmethod
|
||||
def get_error(self):
|
||||
@@ -47,7 +124,9 @@ class Fetcher():
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
# Should set self.error, self.status_code and self.content
|
||||
pass
|
||||
|
||||
@@ -59,11 +138,63 @@ class Fetcher():
|
||||
def get_last_status_code(self):
|
||||
return self.status_code
|
||||
|
||||
@abstractmethod
|
||||
def screenshot_step(self, step_n):
|
||||
return None
|
||||
|
||||
@abstractmethod
|
||||
# Return true/false if this checker is ready to run, in the case it needs todo some special config check etc
|
||||
def is_ready(self):
|
||||
return True
|
||||
|
||||
def iterate_browser_steps(self):
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import steppable_browser_interface
|
||||
from playwright._impl._api_types import TimeoutError
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
step_n = 0
|
||||
|
||||
if self.browser_steps is not None and len(self.browser_steps):
|
||||
interface = steppable_browser_interface()
|
||||
interface.page = self.page
|
||||
|
||||
valid_steps = filter(
|
||||
lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'),
|
||||
self.browser_steps)
|
||||
|
||||
for step in valid_steps:
|
||||
step_n += 1
|
||||
print(">> Iterating check - browser Step n {} - {}...".format(step_n, step['operation']))
|
||||
self.screenshot_step("before-" + str(step_n))
|
||||
self.save_step_html("before-" + str(step_n))
|
||||
try:
|
||||
optional_value = step['optional_value']
|
||||
selector = step['selector']
|
||||
# Support for jinja2 template in step values, with date module added
|
||||
if '{%' in step['optional_value'] or '{{' in step['optional_value']:
|
||||
optional_value = str(jinja2_env.from_string(step['optional_value']).render())
|
||||
if '{%' in step['selector'] or '{{' in step['selector']:
|
||||
selector = str(jinja2_env.from_string(step['selector']).render())
|
||||
|
||||
getattr(interface, "call_action")(action_name=step['operation'],
|
||||
selector=selector,
|
||||
optional_value=optional_value)
|
||||
self.screenshot_step(step_n)
|
||||
self.save_step_html(step_n)
|
||||
except TimeoutError:
|
||||
# Stop processing here
|
||||
raise BrowserStepsStepTimout(step_n=step_n)
|
||||
|
||||
# It's always good to reset these
|
||||
def delete_browser_steps_screenshots(self):
|
||||
import glob
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
dest = os.path.join(self.browser_steps_screenshot_path, 'step_*.jpeg')
|
||||
files = glob.glob(dest)
|
||||
for f in files:
|
||||
os.unlink(f)
|
||||
|
||||
|
||||
# Maybe for the future, each fetcher provides its own diff output, could be used for text, image
|
||||
# the current one would return javascript output (as we use JS to generate the diff)
|
||||
@@ -100,7 +231,7 @@ class base_html_playwright(Fetcher):
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
|
||||
super().__init__()
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
self.browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
self.command_executor = os.getenv(
|
||||
@@ -122,58 +253,294 @@ class base_html_playwright(Fetcher):
|
||||
if proxy_override:
|
||||
self.proxy = {'server': proxy_override}
|
||||
|
||||
if self.proxy:
|
||||
# Playwright needs separate username and password values
|
||||
from urllib.parse import urlparse
|
||||
parsed = urlparse(self.proxy.get('server'))
|
||||
if parsed.username:
|
||||
self.proxy['username'] = parsed.username
|
||||
self.proxy['password'] = parsed.password
|
||||
|
||||
def screenshot_step(self, step_n=''):
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=85)
|
||||
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.jpeg'.format(step_n))
|
||||
logging.debug("Saving step screenshot to {}".format(destination))
|
||||
with open(destination, 'wb') as f:
|
||||
f.write(screenshot)
|
||||
|
||||
def save_step_html(self, step_n):
|
||||
content = self.page.content()
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.html'.format(step_n))
|
||||
logging.debug("Saving step HTML to {}".format(destination))
|
||||
with open(destination, 'w') as f:
|
||||
f.write(content)
|
||||
|
||||
def run_fetch_browserless_puppeteer(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
from pkg_resources import resource_string
|
||||
|
||||
extra_wait_ms = (int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay) * 1000
|
||||
|
||||
self.xpath_element_js = self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
|
||||
code = resource_string(__name__, "res/puppeteer_fetch.js").decode('utf-8')
|
||||
# In the future inject this is a proper JS package
|
||||
code = code.replace('%xpath_scrape_code%', self.xpath_element_js)
|
||||
code = code.replace('%instock_scrape_code%', self.instock_data_js)
|
||||
|
||||
from requests.exceptions import ConnectTimeout, ReadTimeout
|
||||
wait_browserless_seconds = 240
|
||||
|
||||
browserless_function_url = os.getenv('BROWSERLESS_FUNCTION_URL')
|
||||
from urllib.parse import urlparse
|
||||
if not browserless_function_url:
|
||||
# Convert/try to guess from PLAYWRIGHT_DRIVER_URL
|
||||
o = urlparse(os.getenv('PLAYWRIGHT_DRIVER_URL'))
|
||||
browserless_function_url = o._replace(scheme="http")._replace(path="function").geturl()
|
||||
|
||||
|
||||
# Append proxy connect string
|
||||
if self.proxy:
|
||||
import urllib.parse
|
||||
# Remove username/password if it exists in the URL or you will receive "ERR_NO_SUPPORTED_PROXIES" error
|
||||
# Actual authentication handled by Puppeteer/node
|
||||
o = urlparse(self.proxy.get('server'))
|
||||
proxy_url = urllib.parse.quote(o._replace(netloc="{}:{}".format(o.hostname, o.port)).geturl())
|
||||
browserless_function_url = f"{browserless_function_url}&--proxy-server={proxy_url}&dumpio=true"
|
||||
|
||||
|
||||
try:
|
||||
amp = '&' if '?' in browserless_function_url else '?'
|
||||
response = requests.request(
|
||||
method="POST",
|
||||
json={
|
||||
"code": code,
|
||||
"context": {
|
||||
# Very primitive disk cache - USE WITH EXTREME CAUTION
|
||||
# Run browserless container with -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]"
|
||||
'disk_cache_dir': os.getenv("PUPPETEER_DISK_CACHE", False), # or path to disk cache ending in /, ie /tmp/cache/
|
||||
'execute_js': self.webdriver_js_execute_code,
|
||||
'extra_wait_ms': extra_wait_ms,
|
||||
'include_filters': current_include_filters,
|
||||
'req_headers': request_headers,
|
||||
'screenshot_quality': int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)),
|
||||
'url': url,
|
||||
'user_agent': request_headers.get('User-Agent', 'Mozilla/5.0'),
|
||||
'proxy_username': self.proxy.get('username','') if self.proxy else False,
|
||||
'proxy_password': self.proxy.get('password', '') if self.proxy else False,
|
||||
'no_cache_list': [
|
||||
'twitter',
|
||||
'.pdf'
|
||||
],
|
||||
# Could use https://github.com/easylist/easylist here, or install a plugin
|
||||
'block_url_list': [
|
||||
'adnxs.com',
|
||||
'analytics.twitter.com',
|
||||
'doubleclick.net',
|
||||
'google-analytics.com',
|
||||
'googletagmanager',
|
||||
'trustpilot.com'
|
||||
]
|
||||
}
|
||||
},
|
||||
# @todo /function needs adding ws:// to http:// rebuild this
|
||||
url=browserless_function_url+f"{amp}--disable-features=AudioServiceOutOfProcess&dumpio=true&--disable-remote-fonts",
|
||||
timeout=wait_browserless_seconds)
|
||||
|
||||
except ReadTimeout:
|
||||
raise PageUnloadable(url=url, status_code=None, message=f"No response from browserless in {wait_browserless_seconds}s")
|
||||
except ConnectTimeout:
|
||||
raise PageUnloadable(url=url, status_code=None, message=f"Timed out connecting to browserless, retrying..")
|
||||
else:
|
||||
# 200 Here means that the communication to browserless worked only, not the page state
|
||||
if response.status_code == 200:
|
||||
import base64
|
||||
|
||||
x = response.json()
|
||||
if not x.get('screenshot'):
|
||||
# https://github.com/puppeteer/puppeteer/blob/v1.0.0/docs/troubleshooting.md#tips
|
||||
# https://github.com/puppeteer/puppeteer/issues/1834
|
||||
# https://github.com/puppeteer/puppeteer/issues/1834#issuecomment-381047051
|
||||
# Check your memory is shared and big enough
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
if not x.get('content', '').strip():
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
if x.get('status_code', 200) != 200 and not ignore_status_codes:
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=x.get('status_code', 200), page_html=x['content'])
|
||||
|
||||
self.content = x.get('content')
|
||||
self.headers = x.get('headers')
|
||||
self.instock_data = x.get('instock_data')
|
||||
self.screenshot = base64.b64decode(x.get('screenshot'))
|
||||
self.xpath_data = x.get('xpath_data')
|
||||
|
||||
else:
|
||||
# Some other error from browserless
|
||||
raise PageUnloadable(url=url, status_code=None, message=response.content.decode('utf-8'))
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
# For now, USE_EXPERIMENTAL_PUPPETEER_FETCH is not supported by watches with BrowserSteps (for now!)
|
||||
has_browser_steps = self.browser_steps and list(filter(
|
||||
lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'),
|
||||
self.browser_steps))
|
||||
|
||||
if not has_browser_steps:
|
||||
if os.getenv('USE_EXPERIMENTAL_PUPPETEER_FETCH'):
|
||||
# Temporary backup solution until we rewrite the playwright code
|
||||
return self.run_fetch_browserless_puppeteer(
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes,
|
||||
current_include_filters,
|
||||
is_binary)
|
||||
|
||||
from playwright.sync_api import sync_playwright
|
||||
import playwright._impl._api_types
|
||||
from playwright._impl._api_types import Error, TimeoutError
|
||||
|
||||
self.delete_browser_steps_screenshots()
|
||||
response = None
|
||||
with sync_playwright() as p:
|
||||
browser_type = getattr(p, self.browser_type)
|
||||
|
||||
# Seemed to cause a connection Exception even tho I can see it connect
|
||||
# self.browser = browser_type.connect(self.command_executor, timeout=timeout*1000)
|
||||
browser = browser_type.connect_over_cdp(self.command_executor, timeout=timeout * 1000)
|
||||
# 60,000 connection timeout only
|
||||
browser = browser_type.connect_over_cdp(self.command_executor, timeout=60000)
|
||||
|
||||
# Set user agent to prevent Cloudflare from blocking the browser
|
||||
# Use the default one configured in the App.py model that's passed from fetch_site_status.py
|
||||
context = browser.new_context(
|
||||
user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
proxy=self.proxy
|
||||
user_agent=request_headers.get('User-Agent', 'Mozilla/5.0'),
|
||||
proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should be `allow` or `block` - sites like YouTube can transmit large amounts of data via Service Workers
|
||||
service_workers=os.getenv('PLAYWRIGHT_SERVICE_WORKERS', 'allow'),
|
||||
# Should never be needed
|
||||
accept_downloads=False
|
||||
)
|
||||
page = context.new_page()
|
||||
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
|
||||
self.page = context.new_page()
|
||||
if len(request_headers):
|
||||
context.set_extra_http_headers(request_headers)
|
||||
|
||||
self.page.set_default_navigation_timeout(90000)
|
||||
self.page.set_default_timeout(90000)
|
||||
|
||||
# Listen for all console events and handle errors
|
||||
self.page.on("console", lambda msg: print(f"Playwright console: Watch URL: {url} {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
# Goto page
|
||||
try:
|
||||
response = page.goto(url, timeout=timeout * 1000, wait_until='commit')
|
||||
# Wait_until = commit
|
||||
# - `'commit'` - consider operation to be finished when network response is received and the document started loading.
|
||||
# Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
|
||||
# This seemed to solve nearly all 'TimeoutErrors'
|
||||
response = self.page.goto(url, wait_until='commit')
|
||||
except playwright._impl._api_types.Error as e:
|
||||
# Retry once - https://github.com/browserless/chrome/issues/2485
|
||||
# Sometimes errors related to invalid cert's and other can be random
|
||||
print("Content Fetcher > retrying request got error - ", str(e))
|
||||
time.sleep(1)
|
||||
response = self.page.goto(url, wait_until='commit')
|
||||
|
||||
except Exception as e:
|
||||
print("Content Fetcher > Other exception when page.goto", str(e))
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None, message=str(e))
|
||||
|
||||
# Execute any browser steps
|
||||
try:
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
page.wait_for_timeout(extra_wait * 1000)
|
||||
self.page.wait_for_timeout(extra_wait * 1000)
|
||||
|
||||
if self.webdriver_js_execute_code is not None and len(self.webdriver_js_execute_code):
|
||||
self.page.evaluate(self.webdriver_js_execute_code)
|
||||
|
||||
except playwright._impl._api_types.TimeoutError as e:
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
context.close()
|
||||
browser.close()
|
||||
# This can be ok, we will try to grab what we could retrieve
|
||||
pass
|
||||
except Exception as e:
|
||||
print("Content Fetcher > Other exception when executing custom JS code", str(e))
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None, message=str(e))
|
||||
|
||||
if response is None:
|
||||
context.close()
|
||||
browser.close()
|
||||
print("Content Fetcher > Response object was none")
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
if len(page.content().strip()) == 0:
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
# Run Browser Steps here
|
||||
self.iterate_browser_steps()
|
||||
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
time.sleep(extra_wait)
|
||||
|
||||
self.content = self.page.content()
|
||||
self.status_code = response.status
|
||||
if len(self.page.content().strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
print("Content Fetcher > Content was empty")
|
||||
raise EmptyReply(url=url, status_code=response.status)
|
||||
|
||||
self.status_code = response.status
|
||||
self.content = page.content()
|
||||
self.headers = response.all_headers()
|
||||
|
||||
# So we can find an element on the page where its selector was entered manually (maybe not xPath etc)
|
||||
if current_include_filters is not None:
|
||||
self.page.evaluate("var include_filters={}".format(json.dumps(current_include_filters)))
|
||||
else:
|
||||
self.page.evaluate("var include_filters=''")
|
||||
|
||||
self.xpath_data = self.page.evaluate(
|
||||
"async () => {" + self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors) + "}")
|
||||
self.instock_data = self.page.evaluate("async () => {" + self.instock_data_js + "}")
|
||||
|
||||
# Bug 3 in Playwright screenshot handling
|
||||
# Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
|
||||
# JPEG is better here because the screenshots can be very very large
|
||||
page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
|
||||
self.screenshot = page.screenshot(type='jpeg', full_page=True, quality=90)
|
||||
|
||||
# Screenshots also travel via the ws:// (websocket) meaning that the binary data is base64 encoded
|
||||
# which will significantly increase the IO size between the server and client, it's recommended to use the lowest
|
||||
# acceptable screenshot quality here
|
||||
try:
|
||||
# The actual screenshot
|
||||
self.screenshot = self.page.screenshot(type='jpeg', full_page=True,
|
||||
quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
context.close()
|
||||
browser.close()
|
||||
|
||||
@@ -194,6 +561,7 @@ class base_html_webdriver(Fetcher):
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
super().__init__()
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
@@ -225,7 +593,9 @@ class base_html_webdriver(Fetcher):
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
@@ -245,6 +615,14 @@ class base_html_webdriver(Fetcher):
|
||||
self.quit()
|
||||
raise
|
||||
|
||||
self.driver.set_window_size(1280, 1024)
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
|
||||
if self.webdriver_js_execute_code is not None:
|
||||
self.driver.execute_script(self.webdriver_js_execute_code)
|
||||
# Selenium doesn't automatically wait for actions as good as Playwright, so wait again
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
|
||||
# @todo - how to check this? is it possible?
|
||||
self.status_code = 200
|
||||
# @todo somehow we should try to get this working for WebDriver
|
||||
@@ -254,14 +632,13 @@ class base_html_webdriver(Fetcher):
|
||||
time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay)
|
||||
self.content = self.driver.page_source
|
||||
self.headers = {}
|
||||
|
||||
self.screenshot = self.driver.get_screenshot_as_png()
|
||||
self.quit()
|
||||
|
||||
# Does the connection to the webdriver work? run a test connection.
|
||||
def is_ready(self):
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
|
||||
self.driver = webdriver.Remote(
|
||||
command_executor=self.command_executor,
|
||||
@@ -276,7 +653,7 @@ class base_html_webdriver(Fetcher):
|
||||
try:
|
||||
self.driver.quit()
|
||||
except Exception as e:
|
||||
print("Exception in chrome shutdown/quit" + str(e))
|
||||
print("Content Fetcher > Exception in chrome shutdown/quit" + str(e))
|
||||
|
||||
|
||||
# "html_requests" is listed as the default fetcher in store.py!
|
||||
@@ -292,9 +669,16 @@ class html_requests(Fetcher):
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
proxies={}
|
||||
# Make requests use a more modern looking user-agent
|
||||
if not 'User-Agent' in request_headers:
|
||||
request_headers['User-Agent'] = os.getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT",
|
||||
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36')
|
||||
|
||||
proxies = {}
|
||||
|
||||
# Allows override the proxy on a per-request basis
|
||||
if self.proxy_override:
|
||||
@@ -317,19 +701,31 @@ class html_requests(Fetcher):
|
||||
# For example - some sites don't tell us it's utf-8, but return utf-8 content
|
||||
# This seems to not occur when using webdriver/selenium, it seems to detect the text encoding more reliably.
|
||||
# https://github.com/psf/requests/issues/1604 good info about requests encoding detection
|
||||
if not r.headers.get('content-type') or not 'charset=' in r.headers.get('content-type'):
|
||||
encoding = chardet.detect(r.content)['encoding']
|
||||
if encoding:
|
||||
r.encoding = encoding
|
||||
if not is_binary:
|
||||
# Don't run this for PDF (and requests identified as binary) takes a _long_ time
|
||||
if not r.headers.get('content-type') or not 'charset=' in r.headers.get('content-type'):
|
||||
encoding = chardet.detect(r.content)['encoding']
|
||||
if encoding:
|
||||
r.encoding = encoding
|
||||
|
||||
if not r.content or not len(r.content):
|
||||
raise EmptyReply(url=url, status_code=r.status_code)
|
||||
|
||||
# @todo test this
|
||||
# @todo maybe you really want to test zero-byte return pages?
|
||||
if (not ignore_status_codes and not r) or not r.content or not len(r.content):
|
||||
raise EmptyReply(url=url, status_code=r.status_code)
|
||||
if r.status_code != 200 and not ignore_status_codes:
|
||||
# maybe check with content works?
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=r.status_code, page_html=r.text)
|
||||
|
||||
self.status_code = r.status_code
|
||||
self.content = r.text
|
||||
if is_binary:
|
||||
# Binary files just return their checksum until we add something smarter
|
||||
self.content = hashlib.md5(r.content).hexdigest()
|
||||
else:
|
||||
self.content = r.text
|
||||
|
||||
self.headers = r.headers
|
||||
self.raw_content = r.content
|
||||
|
||||
|
||||
# Decide which is the 'real' HTML webdriver, this is more a system wide config
|
||||
|
||||
@@ -1,14 +0,0 @@
|
||||
FROM python:3.8-slim
|
||||
|
||||
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
RUN [ ! -d "/datastore" ] && mkdir /datastore
|
||||
|
||||
COPY sleep.py /
|
||||
CMD [ "python", "/sleep.py" ]
|
||||
|
||||
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
import time
|
||||
|
||||
print ("Sleep loop, you should run your script from the console")
|
||||
|
||||
while True:
|
||||
# Wait for 5 seconds
|
||||
time.sleep(2)
|
||||
@@ -10,7 +10,7 @@ def same_slicer(l, a, b):
|
||||
return l[a:b]
|
||||
|
||||
# like .compare but a little different output
|
||||
def customSequenceMatcher(before, after, include_equal=False):
|
||||
def customSequenceMatcher(before, after, include_equal=False, include_removed=True, include_added=True, include_replaced=True, include_change_type_prefix=True):
|
||||
cruncher = difflib.SequenceMatcher(isjunk=lambda x: x in " \\t", a=before, b=after)
|
||||
|
||||
# @todo Line-by-line mode instead of buncghed, including `after` that is not in `before` (maybe unset?)
|
||||
@@ -18,34 +18,39 @@ def customSequenceMatcher(before, after, include_equal=False):
|
||||
if include_equal and tag == 'equal':
|
||||
g = before[alo:ahi]
|
||||
yield g
|
||||
elif tag == 'delete':
|
||||
g = ["(removed) " + i for i in same_slicer(before, alo, ahi)]
|
||||
elif include_removed and tag == 'delete':
|
||||
row_prefix = "(removed) " if include_change_type_prefix else ''
|
||||
g = [ row_prefix + i for i in same_slicer(before, alo, ahi)]
|
||||
yield g
|
||||
elif tag == 'replace':
|
||||
g = ["(changed) " + i for i in same_slicer(before, alo, ahi)]
|
||||
g += ["(into ) " + i for i in same_slicer(after, blo, bhi)]
|
||||
elif include_replaced and tag == 'replace':
|
||||
row_prefix = "(changed) " if include_change_type_prefix else ''
|
||||
g = [row_prefix + i for i in same_slicer(before, alo, ahi)]
|
||||
row_prefix = "(into) " if include_change_type_prefix else ''
|
||||
g += [row_prefix + i for i in same_slicer(after, blo, bhi)]
|
||||
yield g
|
||||
elif tag == 'insert':
|
||||
g = ["(added ) " + i for i in same_slicer(after, blo, bhi)]
|
||||
elif include_added and tag == 'insert':
|
||||
row_prefix = "(added) " if include_change_type_prefix else ''
|
||||
g = [row_prefix + i for i in same_slicer(after, blo, bhi)]
|
||||
yield g
|
||||
|
||||
# only_differences - only return info about the differences, no context
|
||||
# line_feed_sep could be "<br/>" or "<li>" or "\n" etc
|
||||
def render_diff(previous_file, newest_file, include_equal=False, line_feed_sep="\n"):
|
||||
with open(newest_file, 'r') as f:
|
||||
newest_version_file_contents = f.read()
|
||||
newest_version_file_contents = [line.rstrip() for line in newest_version_file_contents.splitlines()]
|
||||
# line_feed_sep could be "<br>" or "<li>" or "\n" etc
|
||||
def render_diff(previous_version_file_contents, newest_version_file_contents, include_equal=False, include_removed=True, include_added=True, include_replaced=True, line_feed_sep="\n", include_change_type_prefix=True):
|
||||
|
||||
if previous_file:
|
||||
with open(previous_file, 'r') as f:
|
||||
previous_version_file_contents = f.read()
|
||||
newest_version_file_contents = [line.rstrip() for line in newest_version_file_contents.splitlines()]
|
||||
|
||||
if previous_version_file_contents:
|
||||
previous_version_file_contents = [line.rstrip() for line in previous_version_file_contents.splitlines()]
|
||||
else:
|
||||
previous_version_file_contents = ""
|
||||
|
||||
rendered_diff = customSequenceMatcher(previous_version_file_contents,
|
||||
newest_version_file_contents,
|
||||
include_equal)
|
||||
rendered_diff = customSequenceMatcher(before=previous_version_file_contents,
|
||||
after=newest_version_file_contents,
|
||||
include_equal=include_equal,
|
||||
include_removed=include_removed,
|
||||
include_added=include_added,
|
||||
include_replaced=include_replaced,
|
||||
include_change_type_prefix=include_change_type_prefix)
|
||||
|
||||
# Recursively join lists
|
||||
f = lambda L: line_feed_sep.join([f(x) if type(x) is list else x for x in L])
|
||||
|
||||
@@ -1,239 +0,0 @@
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import urllib3
|
||||
|
||||
from changedetectionio import content_fetcher, html_tools
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
|
||||
# Some common stuff here that can be moved to a base class
|
||||
class perform_site_check():
|
||||
|
||||
def __init__(self, *args, datastore, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
# If there was a proxy list enabled, figure out what proxy_args/which proxy to use
|
||||
# if watch.proxy use that
|
||||
# fetcher.proxy_override = watch.proxy or main config proxy
|
||||
# Allows override the proxy on a per-request basis
|
||||
# ALWAYS use the first one is nothing selected
|
||||
|
||||
def set_proxy_from_list(self, watch):
|
||||
proxy_args = None
|
||||
if self.datastore.proxy_list is None:
|
||||
return None
|
||||
|
||||
# If its a valid one
|
||||
if any([watch['proxy'] in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = watch['proxy']
|
||||
|
||||
# not valid (including None), try the system one
|
||||
else:
|
||||
system_proxy = self.datastore.data['settings']['requests']['proxy']
|
||||
# Is not None and exists
|
||||
if any([system_proxy in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = system_proxy
|
||||
|
||||
# Fallback - Did not resolve anything, use the first available
|
||||
if proxy_args is None:
|
||||
proxy_args = self.datastore.proxy_list[0][0]
|
||||
|
||||
return proxy_args
|
||||
|
||||
def run(self, uuid):
|
||||
timestamp = int(time.time()) # used for storage etc too
|
||||
|
||||
changed_detected = False
|
||||
screenshot = False # as bytes
|
||||
stripped_text_from_html = ""
|
||||
|
||||
watch = self.datastore.data['watching'][uuid]
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file', watch['url'], re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
extra_headers = self.datastore.get_val(uuid, 'headers')
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = self.datastore.data['settings']['headers'].copy()
|
||||
request_headers.update(extra_headers)
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
# Requests doesnt yet support brotli encoding, so don't put 'br' here, be totally sure that the user cannot
|
||||
# do this by accident.
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests']['timeout']
|
||||
url = self.datastore.get_val(uuid, 'url')
|
||||
request_body = self.datastore.get_val(uuid, 'body')
|
||||
request_method = self.datastore.get_val(uuid, 'method')
|
||||
ignore_status_code = self.datastore.get_val(uuid, 'ignore_status_codes')
|
||||
|
||||
# source: support
|
||||
is_source = False
|
||||
if url.startswith('source:'):
|
||||
url = url.replace('source:', '')
|
||||
is_source = True
|
||||
|
||||
# Pluggable content fetcher
|
||||
prefer_backend = watch['fetch_backend']
|
||||
if hasattr(content_fetcher, prefer_backend):
|
||||
klass = getattr(content_fetcher, prefer_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
proxy_args = self.set_proxy_from_list(watch)
|
||||
fetcher = klass(proxy_override=proxy_args)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if watch['webdriver_delay'] is not None:
|
||||
fetcher.render_extract_delay = watch['webdriver_delay']
|
||||
elif system_webdriver_delay is not None:
|
||||
fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_code)
|
||||
|
||||
# Fetching complete, now filters
|
||||
# @todo move to class / maybe inside of fetcher abstract base?
|
||||
|
||||
# @note: I feel like the following should be in a more obvious chain system
|
||||
# - Check filter text
|
||||
# - Is the checksum different?
|
||||
# - Do we convert to JSON?
|
||||
# https://stackoverflow.com/questions/41817578/basic-method-chaining ?
|
||||
# return content().textfilter().jsonextract().checksumcompare() ?
|
||||
|
||||
is_json = 'application/json' in fetcher.headers.get('Content-Type', '')
|
||||
is_html = not is_json
|
||||
|
||||
# source: support, basically treat it as plaintext
|
||||
if is_source:
|
||||
is_html = False
|
||||
is_json = False
|
||||
|
||||
css_filter_rule = watch['css_filter']
|
||||
subtractive_selectors = watch.get(
|
||||
"subtractive_selectors", []
|
||||
) + self.datastore.data["settings"]["application"].get(
|
||||
"global_subtractive_selectors", []
|
||||
)
|
||||
|
||||
has_filter_rule = css_filter_rule and len(css_filter_rule.strip())
|
||||
has_subtractive_selectors = subtractive_selectors and len(subtractive_selectors[0].strip())
|
||||
|
||||
if is_json and not has_filter_rule:
|
||||
css_filter_rule = "json:$"
|
||||
has_filter_rule = True
|
||||
|
||||
if has_filter_rule:
|
||||
if 'json:' in css_filter_rule:
|
||||
stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, jsonpath_filter=css_filter_rule)
|
||||
is_html = False
|
||||
|
||||
if is_html or is_source:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = fetcher.content
|
||||
|
||||
# If not JSON, and if it's not text/plain..
|
||||
if 'text/plain' in fetcher.headers.get('Content-Type', '').lower():
|
||||
# Don't run get_text or xpath/css filters on plaintext
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if css_filter_rule[0] == '/' or css_filter_rule.startswith('xpath:'):
|
||||
html_content = html_tools.xpath_filter(xpath_filter=css_filter_rule.replace('xpath:', ''),
|
||||
html_content=fetcher.content)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
|
||||
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
if not is_source:
|
||||
# extract text
|
||||
stripped_text_from_html = \
|
||||
html_tools.html_to_text(
|
||||
html_content,
|
||||
render_anchor_tag_content=self.datastore.data["settings"][
|
||||
"application"].get(
|
||||
"render_anchor_tag_content", False)
|
||||
)
|
||||
|
||||
elif is_source:
|
||||
stripped_text_from_html = html_content
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# Treat pages with no renderable text content as a change? No by default
|
||||
empty_pages_are_a_change = self.datastore.data['settings']['application'].get('empty_pages_are_a_change', False)
|
||||
if not is_json and not empty_pages_are_a_change and len(stripped_text_from_html.strip()) == 0:
|
||||
raise content_fetcher.ReplyWithContentButNoText(url=url, status_code=200)
|
||||
|
||||
# We rely on the actual text in the html output.. many sites have random script vars etc,
|
||||
# in the future we'll implement other mechanisms.
|
||||
|
||||
update_obj["last_check_status"] = fetcher.get_last_status_code()
|
||||
|
||||
# If there's text to skip
|
||||
# @todo we could abstract out the get_text() to handle this cleaner
|
||||
text_to_ignore = watch.get('ignore_text', []) + self.datastore.data['settings']['application'].get('global_ignore_text', [])
|
||||
if len(text_to_ignore):
|
||||
stripped_text_from_html = html_tools.strip_ignore_text(stripped_text_from_html, text_to_ignore)
|
||||
else:
|
||||
stripped_text_from_html = stripped_text_from_html.encode('utf8')
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
else:
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html).hexdigest()
|
||||
|
||||
# On the first run of a site, watch['previous_md5'] will be None, set it the current one.
|
||||
if not watch.get('previous_md5'):
|
||||
watch['previous_md5'] = fetched_md5
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
if len(watch['trigger_text']):
|
||||
# Yeah, lets block first until something matches
|
||||
blocked_by_not_found_trigger_text = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['trigger_text'],
|
||||
mode="line numbers")
|
||||
if result:
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
if not blocked_by_not_found_trigger_text and watch['previous_md5'] != fetched_md5:
|
||||
changed_detected = True
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
update_obj["last_changed"] = timestamp
|
||||
|
||||
# Extract title as title
|
||||
if is_html:
|
||||
if self.datastore.data['settings']['application']['extract_title_as_title'] or watch['extract_title_as_title']:
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
|
||||
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter, fetcher.screenshot
|
||||
@@ -1,11 +1,10 @@
|
||||
import os
|
||||
import re
|
||||
|
||||
from wtforms import (
|
||||
BooleanField,
|
||||
Field,
|
||||
Form,
|
||||
IntegerField,
|
||||
PasswordField,
|
||||
RadioField,
|
||||
SelectField,
|
||||
StringField,
|
||||
@@ -13,15 +12,17 @@ from wtforms import (
|
||||
TextAreaField,
|
||||
fields,
|
||||
validators,
|
||||
widgets,
|
||||
widgets
|
||||
)
|
||||
from wtforms.fields import FieldList
|
||||
from wtforms.validators import ValidationError
|
||||
|
||||
# default
|
||||
# each select <option data-enabled="enabled-0-0"
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import browser_step_ui_config
|
||||
|
||||
from changedetectionio import content_fetcher
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
valid_notification_formats,
|
||||
)
|
||||
|
||||
@@ -137,7 +138,7 @@ class ValidateContentFetcherIsReady(object):
|
||||
from changedetectionio import content_fetcher
|
||||
|
||||
# Better would be a radiohandler that keeps a reference to each class
|
||||
if field.data is not None:
|
||||
if field.data is not None and field.data != 'system':
|
||||
klass = getattr(content_fetcher, field.data)
|
||||
some_object = klass()
|
||||
try:
|
||||
@@ -146,12 +147,12 @@ class ValidateContentFetcherIsReady(object):
|
||||
except urllib3.exceptions.MaxRetryError as e:
|
||||
driver_url = some_object.command_executor
|
||||
message = field.gettext('Content fetcher \'%s\' did not respond.' % (field.data))
|
||||
message += '<br/>' + field.gettext(
|
||||
message += '<br>' + field.gettext(
|
||||
'Be sure that the selenium/webdriver runner is running and accessible via network from this container/host.')
|
||||
message += '<br/>' + field.gettext('Did you follow the instructions in the wiki?')
|
||||
message += '<br/><br/>' + field.gettext('WebDriver Host: %s' % (driver_url))
|
||||
message += '<br/><a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">Go here for more information</a>'
|
||||
message += '<br/>'+field.gettext('Content fetcher did not respond properly, unable to use it.\n %s' % (str(e)))
|
||||
message += '<br>' + field.gettext('Did you follow the instructions in the wiki?')
|
||||
message += '<br><br>' + field.gettext('WebDriver Host: %s' % (driver_url))
|
||||
message += '<br><a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">Go here for more information</a>'
|
||||
message += '<br>'+field.gettext('Content fetcher did not respond properly, unable to use it.\n %s' % (str(e)))
|
||||
|
||||
raise ValidationError(message)
|
||||
|
||||
@@ -192,7 +193,7 @@ class ValidateAppRiseServers(object):
|
||||
message = field.gettext('\'%s\' is not a valid AppRise URL.' % (server_url))
|
||||
raise ValidationError(message)
|
||||
|
||||
class ValidateTokensList(object):
|
||||
class ValidateJinja2Template(object):
|
||||
"""
|
||||
Validates that a {token} is from a valid set
|
||||
"""
|
||||
@@ -201,14 +202,27 @@ class ValidateTokensList(object):
|
||||
|
||||
def __call__(self, form, field):
|
||||
from changedetectionio import notification
|
||||
regex = re.compile('{.*?}')
|
||||
for p in re.findall(regex, field.data):
|
||||
if not p.strip('{}') in notification.valid_tokens:
|
||||
message = field.gettext('Token \'%s\' is not a valid token.')
|
||||
raise ValidationError(message % (p))
|
||||
|
||||
|
||||
from jinja2 import Environment, BaseLoader, TemplateSyntaxError
|
||||
from jinja2.meta import find_undeclared_variables
|
||||
|
||||
|
||||
try:
|
||||
jinja2_env = Environment(loader=BaseLoader)
|
||||
jinja2_env.globals.update(notification.valid_tokens)
|
||||
rendered = jinja2_env.from_string(field.data).render()
|
||||
except TemplateSyntaxError as e:
|
||||
raise ValidationError(f"This is not a valid Jinja2 template: {e}") from e
|
||||
|
||||
ast = jinja2_env.parse(field.data)
|
||||
undefined = ", ".join(find_undeclared_variables(ast))
|
||||
if undefined:
|
||||
raise ValidationError(
|
||||
f"The following tokens used in the notification are not valid: {undefined}"
|
||||
)
|
||||
|
||||
class validateURL(object):
|
||||
|
||||
|
||||
"""
|
||||
Flask wtform validators wont work with basic auth
|
||||
"""
|
||||
@@ -218,12 +232,18 @@ class validateURL(object):
|
||||
|
||||
def __call__(self, form, field):
|
||||
import validators
|
||||
|
||||
try:
|
||||
validators.url(field.data.strip())
|
||||
except validators.ValidationFailure:
|
||||
message = field.gettext('\'%s\' is not a valid URL.' % (field.data.strip()))
|
||||
raise ValidationError(message)
|
||||
|
||||
|
||||
from .model.Watch import is_safe_url
|
||||
if not is_safe_url(field.data):
|
||||
raise ValidationError('Watch protocol is not permitted by SAFE_PROTOCOL_REGEX')
|
||||
|
||||
|
||||
class ValidateListRegex(object):
|
||||
"""
|
||||
Validates that anything that looks like a regex passes as a regex
|
||||
@@ -303,33 +323,75 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
|
||||
# Re #265 - maybe in the future fetch the page and offer a
|
||||
# warning/notice that its possible the rule doesnt yet match anything?
|
||||
if not self.allow_json:
|
||||
raise ValidationError("jq not permitted in this field!")
|
||||
|
||||
if 'jq:' in line:
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise ValidationError("jq not support not found")
|
||||
|
||||
input = line.replace('jq:', '')
|
||||
|
||||
try:
|
||||
jq.compile(input)
|
||||
except (ValueError) as e:
|
||||
message = field.gettext('\'%s\' is not a valid jq expression. (%s)')
|
||||
raise ValidationError(message % (input, str(e)))
|
||||
except:
|
||||
raise ValidationError("A system-error occurred when validating your jq expression")
|
||||
|
||||
class quickWatchForm(Form):
|
||||
from . import processors
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)])
|
||||
tag = StringField('Group tag', [validators.Optional()])
|
||||
watch_submit_button = SubmitField('Watch', render_kw={"class": "pure-button pure-button-primary"})
|
||||
processor = RadioField(u'Processor', choices=processors.available_processors(), default="text_json_diff")
|
||||
edit_and_watch_submit_button = SubmitField('Edit > Watch', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
|
||||
# Common to a single watch and the global settings
|
||||
class commonSettingsForm(Form):
|
||||
|
||||
notification_urls = StringListField('Notification URL list', validators=[validators.Optional(), ValidateNotificationBodyAndTitleWhenURLisSet(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification title', default=default_notification_title, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_body = TextAreaField('Notification body', default=default_notification_body, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys(), default=default_notification_format)
|
||||
fetch_backend = RadioField(u'Fetch method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
notification_urls = StringListField('Notification URL List', validators=[validators.Optional(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification Title', default='ChangeDetection.io Notification - {{ watch_url }}', validators=[validators.Optional(), ValidateJinja2Template()])
|
||||
notification_body = TextAreaField('Notification Body', default='{{ watch_url }} had a change.', validators=[validators.Optional(), ValidateJinja2Template()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys())
|
||||
fetch_backend = RadioField(u'Fetch Method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
extract_title_as_title = BooleanField('Extract <title> from document and use as watch title', default=False)
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1, message="Should contain one or more seconds")] )
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1,
|
||||
message="Should contain one or more seconds")])
|
||||
class importForm(Form):
|
||||
from . import processors
|
||||
processor = RadioField(u'Processor', choices=processors.available_processors(), default="text_json_diff")
|
||||
urls = TextAreaField('URLs')
|
||||
|
||||
class SingleBrowserStep(Form):
|
||||
|
||||
operation = SelectField('Operation', [validators.Optional()], choices=browser_step_ui_config.keys())
|
||||
|
||||
# maybe better to set some <script>var..
|
||||
selector = StringField('Selector', [validators.Optional()], render_kw={"placeholder": "CSS or xPath selector"})
|
||||
optional_value = StringField('value', [validators.Optional()], render_kw={"placeholder": "Value"})
|
||||
# @todo move to JS? ajax fetch new field?
|
||||
# remove_button = SubmitField('-', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Remove'})
|
||||
# add_button = SubmitField('+', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Add new step after'})
|
||||
|
||||
class watchForm(commonSettingsForm):
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)], default='')
|
||||
tag = StringField('Group tag', [validators.Optional()], default='')
|
||||
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
|
||||
css_filter = StringField('CSS/JSON/XPATH Filter', [ValidateCSSJSONXPATHInput()], default='')
|
||||
include_filters = StringListField('CSS/JSONPath/JQ/XPath Filters', [ValidateCSSJSONXPATHInput()], default='')
|
||||
|
||||
subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
|
||||
extract_text = StringListField('Extract text', [ValidateListRegex()])
|
||||
|
||||
title = StringField('Title', default='')
|
||||
|
||||
ignore_text = StringListField('Ignore text', [ValidateListRegex()])
|
||||
@@ -337,10 +399,29 @@ class watchForm(commonSettingsForm):
|
||||
body = TextAreaField('Request body', [validators.Optional()])
|
||||
method = SelectField('Request method', choices=valid_method, default=default_method)
|
||||
ignore_status_codes = BooleanField('Ignore status codes (process non-2xx status codes as normal)', default=False)
|
||||
check_unique_lines = BooleanField('Only trigger when unique lines appear', default=False)
|
||||
|
||||
filter_text_added = BooleanField('Added lines', default=True)
|
||||
filter_text_replaced = BooleanField('Replaced/changed lines', default=True)
|
||||
filter_text_removed = BooleanField('Removed lines', default=True)
|
||||
|
||||
# @todo this class could be moved to its own text_json_diff_watchForm and this goes to restock_diff_Watchform perhaps
|
||||
in_stock_only = BooleanField('Only trigger when product goes BACK to in-stock', default=True)
|
||||
|
||||
trigger_text = StringListField('Trigger/wait for text', [validators.Optional(), ValidateListRegex()])
|
||||
if os.getenv("PLAYWRIGHT_DRIVER_URL"):
|
||||
browser_steps = FieldList(FormField(SingleBrowserStep), min_entries=10)
|
||||
text_should_not_be_present = StringListField('Block change-detection while text matches', [validators.Optional(), ValidateListRegex()])
|
||||
webdriver_js_execute_code = TextAreaField('Execute JavaScript before change detection', render_kw={"rows": "5"}, validators=[validators.Optional()])
|
||||
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
save_and_preview_button = SubmitField('Save & Preview', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
proxy = RadioField('Proxy')
|
||||
filter_failure_notification_send = BooleanField(
|
||||
'Send a notification when the filter can no longer be found on the page', default=False)
|
||||
|
||||
notification_muted = BooleanField('Notifications Muted / Off', default=False)
|
||||
notification_screenshot = BooleanField('Attach screenshot to notification (where possible)', default=False)
|
||||
|
||||
def validate(self, **kwargs):
|
||||
if not super().validate():
|
||||
@@ -353,29 +434,60 @@ class watchForm(commonSettingsForm):
|
||||
self.body.errors.append('Body must be empty when Request Method is set to GET')
|
||||
result = False
|
||||
|
||||
# Attempt to validate jinja2 templates in the URL
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(self.url.data).render())
|
||||
except Exception as e:
|
||||
self.url.errors.append('Invalid template syntax')
|
||||
result = False
|
||||
return result
|
||||
|
||||
|
||||
class SingleExtraProxy(Form):
|
||||
|
||||
# maybe better to set some <script>var..
|
||||
proxy_name = StringField('Name', [validators.Optional()], render_kw={"placeholder": "Name"})
|
||||
proxy_url = StringField('Proxy URL', [validators.Optional()], render_kw={"placeholder": "http://user:pass@...:3128", "size":50})
|
||||
# @todo do the validation here instead
|
||||
|
||||
# datastore.data['settings']['requests']..
|
||||
class globalSettingsRequestForm(Form):
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
proxy = RadioField('Proxy')
|
||||
jitter_seconds = IntegerField('Random jitter seconds ± check',
|
||||
render_kw={"style": "width: 5em;"},
|
||||
validators=[validators.NumberRange(min=0, message="Should contain zero or more seconds")])
|
||||
extra_proxies = FieldList(FormField(SingleExtraProxy), min_entries=5)
|
||||
|
||||
def validate_extra_proxies(self, extra_validators=None):
|
||||
for e in self.data['extra_proxies']:
|
||||
if e.get('proxy_name') or e.get('proxy_url'):
|
||||
if not e.get('proxy_name','').strip() or not e.get('proxy_url','').strip():
|
||||
self.extra_proxies.errors.append('Both a name, and a Proxy URL is required.')
|
||||
return False
|
||||
|
||||
|
||||
# datastore.data['settings']['application']..
|
||||
class globalSettingsApplicationForm(commonSettingsForm):
|
||||
|
||||
base_url = StringField('Base URL', validators=[validators.Optional()])
|
||||
global_subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
global_ignore_text = StringListField('Ignore Text', [ValidateListRegex()])
|
||||
ignore_whitespace = BooleanField('Ignore whitespace')
|
||||
real_browser_save_screenshot = BooleanField('Save last screenshot when using Chrome?')
|
||||
removepassword_button = SubmitField('Remove password', render_kw={"class": "pure-button pure-button-primary"})
|
||||
empty_pages_are_a_change = BooleanField('Treat empty pages as a change?', default=False)
|
||||
render_anchor_tag_content = BooleanField('Render anchor tag content', default=False)
|
||||
fetch_backend = RadioField('Fetch Method', default="html_requests", choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
api_access_token_enabled = BooleanField('API access token security check enabled', default=True, validators=[validators.Optional()])
|
||||
base_url = StringField('Base URL', validators=[validators.Optional()])
|
||||
empty_pages_are_a_change = BooleanField('Treat empty pages as a change?', default=False)
|
||||
fetch_backend = RadioField('Fetch Method', default="html_requests", choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
global_ignore_text = StringListField('Ignore Text', [ValidateListRegex()])
|
||||
global_subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
ignore_whitespace = BooleanField('Ignore whitespace')
|
||||
password = SaltyPasswordField()
|
||||
removepassword_button = SubmitField('Remove password', render_kw={"class": "pure-button pure-button-primary"})
|
||||
render_anchor_tag_content = BooleanField('Render anchor tag content', default=False)
|
||||
shared_diff_access = BooleanField('Allow access to view diff page when password is enabled', default=False, validators=[validators.Optional()])
|
||||
filter_failure_notification_threshold_attempts = IntegerField('Number of times the filter can be missing before sending a notification',
|
||||
render_kw={"style": "width: 5em;"},
|
||||
validators=[validators.NumberRange(min=0,
|
||||
message="Should contain zero or more attempts")])
|
||||
|
||||
|
||||
class globalSettingsForm(Form):
|
||||
@@ -386,3 +498,8 @@ class globalSettingsForm(Form):
|
||||
requests = FormField(globalSettingsRequestForm)
|
||||
application = FormField(globalSettingsApplicationForm)
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
|
||||
class extractDataForm(Form):
|
||||
extract_regex = StringField('RegEx to extract', validators=[validators.Length(min=1, message="Needs a RegEx")])
|
||||
extract_submit_button = SubmitField('Extract as CSV', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
@@ -1,26 +1,40 @@
|
||||
import json
|
||||
import re
|
||||
from typing import List
|
||||
|
||||
from bs4 import BeautifulSoup
|
||||
from jsonpath_ng.ext import parse
|
||||
import re
|
||||
from inscriptis import get_text
|
||||
from inscriptis.model.config import ParserConfig
|
||||
from jsonpath_ng.ext import parse
|
||||
from typing import List
|
||||
import json
|
||||
import re
|
||||
|
||||
# HTML added to be sure each result matching a filter (.example) gets converted to a new line by Inscriptis
|
||||
TEXT_FILTER_LIST_LINE_SUFFIX = "<br>"
|
||||
|
||||
# 'price' , 'lowPrice', 'highPrice' are usually under here
|
||||
# all of those may or may not appear on different websites
|
||||
LD_JSON_PRODUCT_OFFER_SELECTOR = "json:$..offers"
|
||||
|
||||
class JSONNotFound(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
# Given a CSS Rule, and a blob of HTML, return the blob of HTML that matches
|
||||
def css_filter(css_filter, html_content):
|
||||
def include_filters(include_filters, html_content, append_pretty_line_formatting=False):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
html_block = ""
|
||||
for item in soup.select(css_filter, separator=""):
|
||||
html_block += str(item)
|
||||
r = soup.select(include_filters, separator="")
|
||||
|
||||
return html_block + "\n"
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and not element.name in (['br', 'hr', 'div', 'p']):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
html_block += str(element)
|
||||
|
||||
return html_block
|
||||
|
||||
def subtractive_css_selector(css_selector, html_content):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
@@ -36,14 +50,29 @@ def element_removal(selectors: List[str], html_content):
|
||||
|
||||
|
||||
# Return str Utf-8 of matched rules
|
||||
def xpath_filter(xpath_filter, html_content):
|
||||
def xpath_filter(xpath_filter, html_content, append_pretty_line_formatting=False):
|
||||
from lxml import etree, html
|
||||
|
||||
tree = html.fromstring(bytes(html_content, encoding='utf-8'))
|
||||
html_block = ""
|
||||
|
||||
for item in tree.xpath(xpath_filter.strip(), namespaces={'re':'http://exslt.org/regular-expressions'}):
|
||||
html_block+= etree.tostring(item, pretty_print=True).decode('utf-8')+"<br/>"
|
||||
r = tree.xpath(xpath_filter.strip(), namespaces={'re': 'http://exslt.org/regular-expressions'})
|
||||
#@note: //title/text() wont work where <title>CDATA..
|
||||
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and (not hasattr( element, 'tag' ) or not element.tag in (['br', 'hr', 'div', 'p'])):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
if type(element) == etree._ElementStringResult:
|
||||
html_block += str(element)
|
||||
elif type(element) == etree._ElementUnicodeResult:
|
||||
html_block += str(element)
|
||||
else:
|
||||
html_block += etree.tostring(element, pretty_print=True).decode('utf-8')
|
||||
|
||||
return html_block
|
||||
|
||||
@@ -62,19 +91,35 @@ def extract_element(find='title', html_content=''):
|
||||
return element_text
|
||||
|
||||
#
|
||||
def _parse_json(json_data, jsonpath_filter):
|
||||
s=[]
|
||||
jsonpath_expression = parse(jsonpath_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
def _parse_json(json_data, json_filter):
|
||||
if 'json:' in json_filter:
|
||||
jsonpath_expression = parse(json_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
|
||||
if 'jq:' in json_filter:
|
||||
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise Exception("jq not support not found")
|
||||
|
||||
jq_expression = jq.compile(json_filter.replace('jq:', ''))
|
||||
match = jq_expression.input(json_data).all()
|
||||
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
|
||||
def _get_stripped_text_from_json_match(match):
|
||||
s = []
|
||||
# More than one result, we will return it as a JSON list.
|
||||
if len(match) > 1:
|
||||
for i in match:
|
||||
s.append(i.value)
|
||||
s.append(i.value if hasattr(i, 'value') else i)
|
||||
|
||||
# Single value, use just the value, as it could be later used in a token in notifications.
|
||||
if len(match) == 1:
|
||||
s = match[0].value
|
||||
s = match[0].value if hasattr(match[0], 'value') else match[0]
|
||||
|
||||
# Re #257 - Better handling where it does not exist, in the case the original 's' value was False..
|
||||
if not match:
|
||||
@@ -86,19 +131,26 @@ def _parse_json(json_data, jsonpath_filter):
|
||||
|
||||
return stripped_text_from_html
|
||||
|
||||
def extract_json_as_string(content, jsonpath_filter):
|
||||
|
||||
# content - json
|
||||
# json_filter - ie json:$..price
|
||||
# ensure_is_ldjson_info_type - str "product", optional, "@type == product" (I dont know how to do that as a json selector)
|
||||
def extract_json_as_string(content, json_filter, ensure_is_ldjson_info_type=None):
|
||||
stripped_text_from_html = False
|
||||
|
||||
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded <script type=ldjson>
|
||||
try:
|
||||
stripped_text_from_html = _parse_json(json.loads(content), jsonpath_filter)
|
||||
stripped_text_from_html = _parse_json(json.loads(content), json_filter)
|
||||
except json.JSONDecodeError:
|
||||
|
||||
# Foreach <script json></script> blob.. just return the first that matches jsonpath_filter
|
||||
# Foreach <script json></script> blob.. just return the first that matches json_filter
|
||||
s = []
|
||||
soup = BeautifulSoup(content, 'html.parser')
|
||||
bs_result = soup.findAll('script')
|
||||
|
||||
if ensure_is_ldjson_info_type:
|
||||
bs_result = soup.findAll('script', {"type": "application/ld+json"})
|
||||
else:
|
||||
bs_result = soup.findAll('script')
|
||||
|
||||
|
||||
if not bs_result:
|
||||
raise JSONNotFound("No parsable JSON found in this document")
|
||||
@@ -114,8 +166,15 @@ def extract_json_as_string(content, jsonpath_filter):
|
||||
# Just skip it
|
||||
continue
|
||||
else:
|
||||
stripped_text_from_html = _parse_json(json_data, jsonpath_filter)
|
||||
if stripped_text_from_html:
|
||||
stripped_text_from_html = _parse_json(json_data, json_filter)
|
||||
if ensure_is_ldjson_info_type:
|
||||
# Could sometimes be list, string or something else random
|
||||
if isinstance(json_data, dict):
|
||||
# If it has LD JSON 'key' @type, and @type is 'product', and something was found for the search
|
||||
# (Some sites have multiple of the same ld+json @type='product', but some have the review part, some have the 'price' part)
|
||||
if json_data.get('@type', False) and json_data.get('@type','').lower() == ensure_is_ldjson_info_type.lower() and stripped_text_from_html:
|
||||
break
|
||||
elif stripped_text_from_html:
|
||||
break
|
||||
|
||||
if not stripped_text_from_html:
|
||||
@@ -202,3 +261,44 @@ def html_to_text(html_content: str, render_anchor_tag_content=False) -> str:
|
||||
|
||||
return text_content
|
||||
|
||||
|
||||
# Does LD+JSON exist with a @type=='product' and a .price set anywhere?
|
||||
def has_ldjson_product_info(content):
|
||||
try:
|
||||
pricing_data = extract_json_as_string(content=content, json_filter=LD_JSON_PRODUCT_OFFER_SELECTOR, ensure_is_ldjson_info_type="product")
|
||||
except JSONNotFound as e:
|
||||
# Totally fine
|
||||
return False
|
||||
x=bool(pricing_data)
|
||||
return x
|
||||
|
||||
|
||||
def workarounds_for_obfuscations(content):
|
||||
"""
|
||||
Some sites are using sneaky tactics to make prices and other information un-renderable by Inscriptis
|
||||
This could go into its own Pip package in the future, for faster updates
|
||||
"""
|
||||
|
||||
# HomeDepot.com style <span>$<!-- -->90<!-- -->.<!-- -->74</span>
|
||||
# https://github.com/weblyzard/inscriptis/issues/45
|
||||
if not content:
|
||||
return content
|
||||
|
||||
content = re.sub('<!--\s+-->', '', content)
|
||||
|
||||
return content
|
||||
|
||||
|
||||
def get_triggered_text(content, trigger_text):
|
||||
triggered_text = []
|
||||
result = strip_ignore_text(content=content,
|
||||
wordlist=trigger_text,
|
||||
mode="line numbers")
|
||||
|
||||
i = 1
|
||||
for p in content.splitlines():
|
||||
if i in result:
|
||||
triggered_text.append(p)
|
||||
i += 1
|
||||
|
||||
return triggered_text
|
||||
|
||||
@@ -29,6 +29,7 @@ class import_url_list(Importer):
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
processor=None
|
||||
):
|
||||
|
||||
urls = data.split("\n")
|
||||
@@ -52,7 +53,11 @@ class import_url_list(Importer):
|
||||
# Flask wtform validators wont work with basic auth, use validators package
|
||||
# Up to 5000 per batch so we dont flood the server
|
||||
if len(url) and validators.url(url.replace('source:', '')) and good < 5000:
|
||||
new_uuid = datastore.add_watch(url=url.strip(), tag=tags, write_to_disk_now=False)
|
||||
extras = None
|
||||
if processor:
|
||||
extras = {'processor': processor}
|
||||
new_uuid = datastore.add_watch(url=url.strip(), tag=tags, write_to_disk_now=False, extras=extras)
|
||||
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
@@ -92,7 +97,7 @@ class import_distill_io_json(Importer):
|
||||
|
||||
for d in data.get('data'):
|
||||
d_config = json.loads(d['config'])
|
||||
extras = {'title': d['name']}
|
||||
extras = {'title': d.get('name', None)}
|
||||
|
||||
if len(d['uri']) and good < 5000:
|
||||
try:
|
||||
@@ -103,23 +108,20 @@ class import_distill_io_json(Importer):
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
extras['include_filters'] = []
|
||||
try:
|
||||
extras['css_filter'] = d_config['selections'][0]['frames'][0]['includes'][0]['expr']
|
||||
if d_config['selections'][0]['frames'][0]['includes'][0]['type'] == 'xpath':
|
||||
extras['css_filter'] = 'xpath:' + extras['css_filter']
|
||||
|
||||
extras['include_filters'].append('xpath:' + d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
else:
|
||||
extras['include_filters'].append(d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
try:
|
||||
|
||||
if d.get('tags', False):
|
||||
extras['tag'] = ", ".join(d['tags'])
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
new_uuid = datastore.add_watch(url=d['uri'].strip(),
|
||||
extras=extras,
|
||||
|
||||
@@ -1,30 +1,26 @@
|
||||
import collections
|
||||
import os
|
||||
|
||||
import uuid as uuid_builder
|
||||
|
||||
from os import getenv
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
)
|
||||
|
||||
_FILTER_FAILURE_THRESHOLD_ATTEMPTS_DEFAULT = 6
|
||||
|
||||
class model(dict):
|
||||
base_config = {
|
||||
'note': "Hello! If you change this file manually, please be sure to restart your changedetection.io instance!",
|
||||
'watching': {},
|
||||
'settings': {
|
||||
'headers': {
|
||||
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
|
||||
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
|
||||
'Accept-Encoding': 'gzip, deflate', # No support for brolti in python requests yet.
|
||||
'Accept-Language': 'en-GB,en-US;q=0.9,en;'
|
||||
},
|
||||
'requests': {
|
||||
'timeout': 15, # Default 15 seconds
|
||||
'extra_proxies': [], # Configurable extra proxies via the UI
|
||||
'jitter_seconds': 0,
|
||||
'proxy': None, # Preferred proxy connection
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': 3, 'minutes': None, 'seconds': None},
|
||||
'workers': 10, # Number of threads, lower is better for slow connections
|
||||
'proxy': None # Preferred proxy connection
|
||||
'timeout': int(getenv("DEFAULT_SETTINGS_REQUESTS_TIMEOUT", "45")), # Default 45 seconds
|
||||
'workers': int(getenv("DEFAULT_SETTINGS_REQUESTS_WORKERS", "10")), # Number of threads, lower is better for slow connections
|
||||
},
|
||||
'application': {
|
||||
'api_access_token_enabled': True,
|
||||
@@ -32,18 +28,19 @@ class model(dict):
|
||||
'base_url' : None,
|
||||
'extract_title_as_title': False,
|
||||
'empty_pages_are_a_change': False,
|
||||
'fetch_backend': os.getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'fetch_backend': getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'filter_failure_notification_threshold_attempts': _FILTER_FAILURE_THRESHOLD_ATTEMPTS_DEFAULT,
|
||||
'global_ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'global_subtractive_selectors': [],
|
||||
'ignore_whitespace': False,
|
||||
'ignore_whitespace': True,
|
||||
'render_anchor_tag_content': False,
|
||||
'notification_urls': [], # Apprise URL list
|
||||
# Custom notification content
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'real_browser_save_screenshot': True,
|
||||
'schema_version' : 0,
|
||||
'shared_diff_access': False,
|
||||
'webdriver_delay': None # Extra delay in seconds before extracting text
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,57 +1,312 @@
|
||||
from distutils.util import strtobool
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import uuid
|
||||
|
||||
import uuid as uuid_builder
|
||||
# Allowable protocols, protects against javascript: etc
|
||||
# file:// is further checked by ALLOW_FILE_URI
|
||||
SAFE_PROTOCOL_REGEX='^(http|https|ftp|file):'
|
||||
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
default_notification_format_for_watch
|
||||
)
|
||||
|
||||
base_config = {
|
||||
'body': None,
|
||||
'check_unique_lines': False, # On change-detected, compare against all history if its something new
|
||||
'check_count': 0,
|
||||
'date_created': None,
|
||||
'consecutive_filter_failures': 0, # Every time the CSS/xPath filter cannot be located, reset when all is fine.
|
||||
'extract_text': [], # Extract text by regex after filters
|
||||
'extract_title_as_title': False,
|
||||
'fetch_backend': 'system', # plaintext, playwright etc
|
||||
'processor': 'text_json_diff', # could be restock_diff or others from .processors
|
||||
'filter_failure_notification_send': strtobool(os.getenv('FILTER_FAILURE_NOTIFICATION_SEND_DEFAULT', 'True')),
|
||||
'filter_text_added': True,
|
||||
'filter_text_replaced': True,
|
||||
'filter_text_removed': True,
|
||||
'has_ldjson_price_data': None,
|
||||
'track_ldjson_price_data': None,
|
||||
'headers': {}, # Extra headers to send
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'in_stock_only' : True, # Only trigger change on going to instock from out-of-stock
|
||||
'include_filters': [],
|
||||
'last_checked': 0,
|
||||
'last_error': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'method': 'GET',
|
||||
# Custom notification content
|
||||
'notification_body': None,
|
||||
'notification_format': default_notification_format_for_watch,
|
||||
'notification_muted': False,
|
||||
'notification_title': None,
|
||||
'notification_screenshot': False, # Include the latest screenshot if available and supported by the apprise URL
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'paused': False,
|
||||
'previous_md5': False,
|
||||
'previous_md5_before_filters': False, # Used for skipping changedetection entirely
|
||||
'proxy': None, # Preferred proxy connection
|
||||
'subtractive_selectors': [],
|
||||
'tag': None,
|
||||
'text_should_not_be_present': [], # Text that should not present
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None},
|
||||
'title': None,
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'url': '',
|
||||
'uuid': str(uuid.uuid4()),
|
||||
'webdriver_delay': None,
|
||||
'webdriver_js_execute_code': None, # Run before change-detection
|
||||
}
|
||||
|
||||
|
||||
def is_safe_url(test_url):
|
||||
# See https://github.com/dgtlmoon/changedetection.io/issues/1358
|
||||
|
||||
# Remove 'source:' prefix so we dont get 'source:javascript:' etc
|
||||
# 'source:' is a valid way to tell us to return the source
|
||||
|
||||
r = re.compile(re.escape('source:'), re.IGNORECASE)
|
||||
test_url = r.sub('', test_url)
|
||||
|
||||
pattern = re.compile(os.getenv('SAFE_PROTOCOL_REGEX', SAFE_PROTOCOL_REGEX), re.IGNORECASE)
|
||||
if not pattern.match(test_url.strip()):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
class model(dict):
|
||||
base_config = {
|
||||
'url': None,
|
||||
'tag': None,
|
||||
'last_checked': 0,
|
||||
'last_changed': 0,
|
||||
'paused': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'newest_history_key': 0,
|
||||
'title': None,
|
||||
'previous_md5': False,
|
||||
# UUID not needed, should be generated only as a key
|
||||
# 'uuid':
|
||||
'headers': {}, # Extra headers to send
|
||||
'body': None,
|
||||
'method': 'GET',
|
||||
'history': {}, # Dict of timestamp and output stripped filename
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
# Custom notification content
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'css_filter': "",
|
||||
'subtractive_selectors': [],
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'fetch_backend': None,
|
||||
'extract_title_as_title': False,
|
||||
'proxy': None, # Preferred proxy connection
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None},
|
||||
'webdriver_delay': None
|
||||
}
|
||||
__newest_history_key = None
|
||||
__history_n = 0
|
||||
jitter_seconds = 0
|
||||
|
||||
def __init__(self, *arg, **kw):
|
||||
self.update(self.base_config)
|
||||
# goes at the end so we update the default object with the initialiser
|
||||
|
||||
self.update(base_config)
|
||||
self.__datastore_path = kw['datastore_path']
|
||||
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
del kw['datastore_path']
|
||||
|
||||
if kw.get('default'):
|
||||
self.update(kw['default'])
|
||||
del kw['default']
|
||||
|
||||
# Be sure the cached timestamp is ready
|
||||
bump = self.history
|
||||
|
||||
# Goes at the end so we update the default object with the initialiser
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
|
||||
@property
|
||||
def viewed(self):
|
||||
if int(self['last_viewed']) >= int(self.newest_history_key) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def ensure_data_dir_exists(self):
|
||||
if not os.path.isdir(self.watch_data_dir):
|
||||
print ("> Creating data dir {}".format(self.watch_data_dir))
|
||||
os.mkdir(self.watch_data_dir)
|
||||
|
||||
@property
|
||||
def link(self):
|
||||
|
||||
url = self.get('url', '')
|
||||
if not is_safe_url(url):
|
||||
return 'DISABLED'
|
||||
|
||||
ready_url = url
|
||||
if '{%' in url or '{{' in url:
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(url).render())
|
||||
except Exception as e:
|
||||
from flask import (
|
||||
flash, Markup, url_for
|
||||
)
|
||||
message = Markup('<a href="{}#general">The URL {} is invalid and cannot be used, click to edit</a>'.format(
|
||||
url_for('edit_page', uuid=self.get('uuid')), self.get('url', '')))
|
||||
flash(message, 'error')
|
||||
return ''
|
||||
|
||||
return ready_url
|
||||
|
||||
@property
|
||||
def get_fetch_backend(self):
|
||||
"""
|
||||
Like just using the `fetch_backend` key but there could be some logic
|
||||
:return:
|
||||
"""
|
||||
# Maybe also if is_image etc?
|
||||
# This is because chrome/playwright wont render the PDF in the browser and we will just fetch it and use pdf2html to see the text.
|
||||
if self.is_pdf:
|
||||
return 'html_requests'
|
||||
|
||||
return self.get('fetch_backend')
|
||||
|
||||
@property
|
||||
def is_pdf(self):
|
||||
# content_type field is set in the future
|
||||
# https://github.com/dgtlmoon/changedetection.io/issues/1392
|
||||
# Not sure the best logic here
|
||||
return self.get('url', '').lower().endswith('.pdf') or 'pdf' in self.get('content_type', '').lower()
|
||||
|
||||
@property
|
||||
def label(self):
|
||||
# Used for sorting
|
||||
if self['title']:
|
||||
return self['title']
|
||||
return self['url']
|
||||
|
||||
@property
|
||||
def last_changed(self):
|
||||
# last_changed will be the newest snapshot, but when we have just one snapshot, it should be 0
|
||||
if self.__history_n <= 1:
|
||||
return 0
|
||||
if self.__newest_history_key:
|
||||
return int(self.__newest_history_key)
|
||||
return 0
|
||||
|
||||
@property
|
||||
def history_n(self):
|
||||
return self.__history_n
|
||||
|
||||
@property
|
||||
def history(self):
|
||||
"""History index is just a text file as a list
|
||||
{watch-uuid}/history.txt
|
||||
|
||||
contains a list like
|
||||
|
||||
{epoch-time},{filename}\n
|
||||
|
||||
We read in this list as the history information
|
||||
|
||||
"""
|
||||
tmp_history = {}
|
||||
|
||||
# Read the history file as a dict
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
if os.path.isfile(fname):
|
||||
logging.debug("Reading history index " + str(time.time()))
|
||||
with open(fname, "r") as f:
|
||||
for i in f.readlines():
|
||||
if ',' in i:
|
||||
k, v = i.strip().split(',', 2)
|
||||
|
||||
# The index history could contain a relative path, so we need to make the fullpath
|
||||
# so that python can read it
|
||||
if not '/' in v and not '\'' in v:
|
||||
v = os.path.join(self.watch_data_dir, v)
|
||||
else:
|
||||
# It's possible that they moved the datadir on older versions
|
||||
# So the snapshot exists but is in a different path
|
||||
snapshot_fname = v.split('/')[-1]
|
||||
proposed_new_path = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(v) and os.path.exists(proposed_new_path):
|
||||
v = proposed_new_path
|
||||
|
||||
tmp_history[k] = v
|
||||
|
||||
if len(tmp_history):
|
||||
self.__newest_history_key = list(tmp_history.keys())[-1]
|
||||
|
||||
self.__history_n = len(tmp_history)
|
||||
|
||||
return tmp_history
|
||||
|
||||
@property
|
||||
def has_history(self):
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
return os.path.isfile(fname)
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
@property
|
||||
def newest_history_key(self):
|
||||
if self.__newest_history_key is not None:
|
||||
return self.__newest_history_key
|
||||
|
||||
if len(self.history) <= 1:
|
||||
return 0
|
||||
|
||||
|
||||
bump = self.history
|
||||
return self.__newest_history_key
|
||||
|
||||
def get_history_snapshot(self, timestamp):
|
||||
import brotli
|
||||
filepath = self.history[timestamp]
|
||||
|
||||
# See if a brotli versions exists and switch to that
|
||||
if not filepath.endswith('.br') and os.path.isfile(f"{filepath}.br"):
|
||||
filepath = f"{filepath}.br"
|
||||
|
||||
# OR in the backup case that the .br does not exist, but the plain one does
|
||||
if filepath.endswith('.br') and not os.path.isfile(filepath):
|
||||
if os.path.isfile(filepath.replace('.br', '')):
|
||||
filepath = filepath.replace('.br', '')
|
||||
|
||||
if filepath.endswith('.br'):
|
||||
# Brotli doesnt have a fileheader to detect it, so we rely on filename
|
||||
# https://www.rfc-editor.org/rfc/rfc7932
|
||||
with open(filepath, 'rb') as f:
|
||||
return(brotli.decompress(f.read()).decode('utf-8'))
|
||||
|
||||
with open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
|
||||
return f.read()
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, contents, timestamp, snapshot_id):
|
||||
import brotli
|
||||
|
||||
self.ensure_data_dir_exists()
|
||||
|
||||
# Small hack so that we sleep just enough to allow 1 second between history snapshots
|
||||
# this is because history.txt indexes/keys snapshots by epoch seconds and we dont want dupe keys
|
||||
if self.__newest_history_key and int(timestamp) == int(self.__newest_history_key):
|
||||
time.sleep(timestamp - self.__newest_history_key)
|
||||
|
||||
threshold = int(os.getenv('SNAPSHOT_BROTLI_COMPRESSION_THRESHOLD', 1024))
|
||||
skip_brotli = strtobool(os.getenv('DISABLE_BROTLI_TEXT_SNAPSHOT', 'False'))
|
||||
|
||||
if not skip_brotli and len(contents) > threshold:
|
||||
snapshot_fname = f"{snapshot_id}.txt.br"
|
||||
dest = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(dest):
|
||||
with open(dest, 'wb') as f:
|
||||
f.write(brotli.compress(contents, mode=brotli.MODE_TEXT))
|
||||
else:
|
||||
snapshot_fname = f"{snapshot_id}.txt"
|
||||
dest = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(dest):
|
||||
with open(dest, 'wb') as f:
|
||||
f.write(contents)
|
||||
|
||||
# Append to index
|
||||
# @todo check last char was \n
|
||||
index_fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
with open(index_fname, 'a') as f:
|
||||
f.write("{},{}\n".format(timestamp, snapshot_fname))
|
||||
f.close()
|
||||
|
||||
self.__newest_history_key = timestamp
|
||||
self.__history_n += 1
|
||||
|
||||
# @todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
return snapshot_fname
|
||||
|
||||
@property
|
||||
def has_empty_checktime(self):
|
||||
@@ -62,9 +317,180 @@ class model(dict):
|
||||
|
||||
def threshold_seconds(self):
|
||||
seconds = 0
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
for m, n in mtable.items():
|
||||
x = self.get('time_between_check', {}).get(m, None)
|
||||
if x:
|
||||
seconds += x * n
|
||||
return seconds
|
||||
|
||||
# Iterate over all history texts and see if something new exists
|
||||
def lines_contain_something_unique_compared_to_history(self, lines: list):
|
||||
local_lines = set([l.decode('utf-8').strip().lower() for l in lines])
|
||||
|
||||
# Compare each lines (set) against each history text file (set) looking for something new..
|
||||
existing_history = set({})
|
||||
for k, v in self.history.items():
|
||||
content = self.get_history_snapshot(k)
|
||||
alist = set([line.strip().lower() for line in content.splitlines()])
|
||||
existing_history = existing_history.union(alist)
|
||||
|
||||
# Check that everything in local_lines(new stuff) already exists in existing_history - it should
|
||||
# if not, something new happened
|
||||
return not local_lines.issubset(existing_history)
|
||||
|
||||
def get_screenshot(self):
|
||||
fname = os.path.join(self.watch_data_dir, "last-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
|
||||
# False is not an option for AppRise, must be type None
|
||||
return None
|
||||
|
||||
def __get_file_ctime(self, filename):
|
||||
fname = os.path.join(self.watch_data_dir, filename)
|
||||
if os.path.isfile(fname):
|
||||
return int(os.path.getmtime(fname))
|
||||
return False
|
||||
|
||||
@property
|
||||
def error_text_ctime(self):
|
||||
return self.__get_file_ctime('last-error.txt')
|
||||
|
||||
@property
|
||||
def snapshot_text_ctime(self):
|
||||
if self.history_n==0:
|
||||
return False
|
||||
|
||||
timestamp = list(self.history.keys())[-1]
|
||||
return int(timestamp)
|
||||
|
||||
@property
|
||||
def snapshot_screenshot_ctime(self):
|
||||
return self.__get_file_ctime('last-screenshot.png')
|
||||
|
||||
@property
|
||||
def snapshot_error_screenshot_ctime(self):
|
||||
return self.__get_file_ctime('last-error-screenshot.png')
|
||||
|
||||
@property
|
||||
def watch_data_dir(self):
|
||||
# The base dir of the watch data
|
||||
return os.path.join(self.__datastore_path, self['uuid'])
|
||||
|
||||
def get_error_text(self):
|
||||
"""Return the text saved from a previous request that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.watch_data_dir, "last-error.txt")
|
||||
if os.path.isfile(fname):
|
||||
with open(fname, 'r') as f:
|
||||
return f.read()
|
||||
return False
|
||||
|
||||
def get_error_snapshot(self):
|
||||
"""Return path to the screenshot that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.watch_data_dir, "last-error-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
return False
|
||||
|
||||
|
||||
def pause(self):
|
||||
self['paused'] = True
|
||||
|
||||
def unpause(self):
|
||||
self['paused'] = False
|
||||
|
||||
def toggle_pause(self):
|
||||
self['paused'] ^= True
|
||||
|
||||
def mute(self):
|
||||
self['notification_muted'] = True
|
||||
|
||||
def unmute(self):
|
||||
self['notification_muted'] = False
|
||||
|
||||
def toggle_mute(self):
|
||||
self['notification_muted'] ^= True
|
||||
|
||||
def extract_regex_from_all_history(self, regex):
|
||||
import csv
|
||||
import re
|
||||
import datetime
|
||||
csv_output_filename = False
|
||||
csv_writer = False
|
||||
f = None
|
||||
|
||||
# self.history will be keyed with the full path
|
||||
for k, fname in self.history.items():
|
||||
if os.path.isfile(fname):
|
||||
if True:
|
||||
contents = self.get_history_snapshot(k)
|
||||
res = re.findall(regex, contents, re.MULTILINE)
|
||||
if res:
|
||||
if not csv_writer:
|
||||
# A file on the disk can be transferred much faster via flask than a string reply
|
||||
csv_output_filename = 'report.csv'
|
||||
f = open(os.path.join(self.watch_data_dir, csv_output_filename), 'w')
|
||||
# @todo some headers in the future
|
||||
#fieldnames = ['Epoch seconds', 'Date']
|
||||
csv_writer = csv.writer(f,
|
||||
delimiter=',',
|
||||
quotechar='"',
|
||||
quoting=csv.QUOTE_MINIMAL,
|
||||
#fieldnames=fieldnames
|
||||
)
|
||||
csv_writer.writerow(['Epoch seconds', 'Date'])
|
||||
# csv_writer.writeheader()
|
||||
|
||||
date_str = datetime.datetime.fromtimestamp(int(k)).strftime('%Y-%m-%d %H:%M:%S')
|
||||
for r in res:
|
||||
row = [k, date_str]
|
||||
if isinstance(r, str):
|
||||
row.append(r)
|
||||
else:
|
||||
row+=r
|
||||
csv_writer.writerow(row)
|
||||
|
||||
if f:
|
||||
f.close()
|
||||
|
||||
return csv_output_filename
|
||||
|
||||
@property
|
||||
# Return list of tags, stripped and lowercase, used for searching
|
||||
def all_tags(self):
|
||||
return [s.strip().lower() for s in self.get('tag','').split(',')]
|
||||
|
||||
def has_special_diff_filter_options_set(self):
|
||||
|
||||
# All False - nothing would be done, so act like it's not processable
|
||||
if not self.get('filter_text_added', True) and not self.get('filter_text_replaced', True) and not self.get('filter_text_removed', True):
|
||||
return False
|
||||
|
||||
# Or one is set
|
||||
if not self.get('filter_text_added', True) or not self.get('filter_text_replaced', True) or not self.get('filter_text_removed', True):
|
||||
return True
|
||||
|
||||
# None is set
|
||||
return False
|
||||
|
||||
|
||||
def get_last_fetched_before_filters(self):
|
||||
import brotli
|
||||
filepath = os.path.join(self.watch_data_dir, 'last-fetched.br')
|
||||
|
||||
if not os.path.isfile(filepath):
|
||||
# If a previous attempt doesnt yet exist, just snarf the previous snapshot instead
|
||||
dates = list(self.history.keys())
|
||||
if len(dates):
|
||||
return self.get_history_snapshot(dates[-1])
|
||||
else:
|
||||
return ''
|
||||
|
||||
with open(filepath, 'rb') as f:
|
||||
return(brotli.decompress(f.read()).decode('utf-8'))
|
||||
|
||||
def save_last_fetched_before_filters(self, contents):
|
||||
import brotli
|
||||
filepath = os.path.join(self.watch_data_dir, 'last-fetched.br')
|
||||
with open(filepath, 'wb') as f:
|
||||
f.write(brotli.compress(contents, mode=brotli.MODE_TEXT))
|
||||
|
||||
@@ -1,56 +1,107 @@
|
||||
import apprise
|
||||
from jinja2 import Environment, BaseLoader
|
||||
from apprise import NotifyFormat
|
||||
import json
|
||||
|
||||
valid_tokens = {
|
||||
'base_url': '',
|
||||
'watch_url': '',
|
||||
'watch_uuid': '',
|
||||
'watch_title': '',
|
||||
'watch_tag': '',
|
||||
'current_snapshot': '',
|
||||
'diff': '',
|
||||
'diff_added': '',
|
||||
'diff_full': '',
|
||||
'diff_removed': '',
|
||||
'diff_url': '',
|
||||
'preview_url': '',
|
||||
'current_snapshot': ''
|
||||
'triggered_text': '',
|
||||
'watch_tag': '',
|
||||
'watch_title': '',
|
||||
'watch_url': '',
|
||||
'watch_uuid': '',
|
||||
}
|
||||
|
||||
default_notification_format_for_watch = 'System default'
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{{watch_url}} had a change.\n---\n{{diff}}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {{watch_url}}'
|
||||
|
||||
valid_notification_formats = {
|
||||
'Text': NotifyFormat.TEXT,
|
||||
'Markdown': NotifyFormat.MARKDOWN,
|
||||
'HTML': NotifyFormat.HTML,
|
||||
# Used only for editing a watch (not for global)
|
||||
default_notification_format_for_watch: default_notification_format_for_watch
|
||||
}
|
||||
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{watch_url} had a change.\n---\n{diff}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {watch_url}'
|
||||
# include the decorator
|
||||
from apprise.decorators import notify
|
||||
|
||||
@notify(on="delete")
|
||||
@notify(on="deletes")
|
||||
@notify(on="get")
|
||||
@notify(on="gets")
|
||||
@notify(on="post")
|
||||
@notify(on="posts")
|
||||
@notify(on="put")
|
||||
@notify(on="puts")
|
||||
def apprise_custom_api_call_wrapper(body, title, notify_type, *args, **kwargs):
|
||||
import requests
|
||||
url = kwargs['meta'].get('url')
|
||||
|
||||
if url.startswith('post'):
|
||||
r = requests.post
|
||||
elif url.startswith('get'):
|
||||
r = requests.get
|
||||
elif url.startswith('put'):
|
||||
r = requests.put
|
||||
elif url.startswith('delete'):
|
||||
r = requests.delete
|
||||
|
||||
url = url.replace('post://', 'http://')
|
||||
url = url.replace('posts://', 'https://')
|
||||
url = url.replace('put://', 'http://')
|
||||
url = url.replace('puts://', 'https://')
|
||||
url = url.replace('get://', 'http://')
|
||||
url = url.replace('gets://', 'https://')
|
||||
url = url.replace('put://', 'http://')
|
||||
url = url.replace('puts://', 'https://')
|
||||
url = url.replace('delete://', 'http://')
|
||||
url = url.replace('deletes://', 'https://')
|
||||
|
||||
# Try to auto-guess if it's JSON
|
||||
headers = {}
|
||||
try:
|
||||
json.loads(body)
|
||||
headers = {'Content-Type': 'application/json; charset=utf-8'}
|
||||
except ValueError as e:
|
||||
pass
|
||||
|
||||
|
||||
r(url, headers=headers, data=body)
|
||||
|
||||
|
||||
def process_notification(n_object, datastore):
|
||||
|
||||
# Get the notification body from datastore
|
||||
n_body = n_object.get('notification_body', default_notification_body)
|
||||
n_title = n_object.get('notification_title', default_notification_title)
|
||||
n_format = valid_notification_formats.get(
|
||||
n_object['notification_format'],
|
||||
valid_notification_formats[default_notification_format],
|
||||
)
|
||||
|
||||
|
||||
# Insert variables into the notification content
|
||||
notification_parameters = create_notification_parameters(n_object, datastore)
|
||||
|
||||
for n_k in notification_parameters:
|
||||
token = '{' + n_k + '}'
|
||||
val = notification_parameters[n_k]
|
||||
n_title = n_title.replace(token, val)
|
||||
n_body = n_body.replace(token, val)
|
||||
|
||||
# Get the notification body from datastore
|
||||
jinja2_env = Environment(loader=BaseLoader)
|
||||
n_body = jinja2_env.from_string(n_object.get('notification_body', default_notification_body)).render(**notification_parameters)
|
||||
n_title = jinja2_env.from_string(n_object.get('notification_title', default_notification_title)).render(**notification_parameters)
|
||||
n_format = valid_notification_formats.get(
|
||||
n_object.get('notification_format', default_notification_format),
|
||||
valid_notification_formats[default_notification_format],
|
||||
)
|
||||
|
||||
# https://github.com/caronc/apprise/wiki/Development_LogCapture
|
||||
# Anything higher than or equal to WARNING (which covers things like Connection errors)
|
||||
# raise it as an exception
|
||||
apobjs=[]
|
||||
sent_objs=[]
|
||||
from .apprise_asset import asset
|
||||
for url in n_object['notification_urls']:
|
||||
|
||||
apobj = apprise.Apprise(debug=True)
|
||||
url = jinja2_env.from_string(url).render(**notification_parameters)
|
||||
apobj = apprise.Apprise(debug=True, asset=asset)
|
||||
url = url.strip()
|
||||
if len(url):
|
||||
print(">> Process Notification: AppRise notifying {}".format(url))
|
||||
@@ -63,29 +114,50 @@ def process_notification(n_object, datastore):
|
||||
|
||||
# So if no avatar_url is specified, add one so it can be correctly calculated into the total payload
|
||||
k = '?' if not '?' in url else '&'
|
||||
if not 'avatar_url' in url:
|
||||
if not 'avatar_url' in url \
|
||||
and not url.startswith('mail') \
|
||||
and not url.startswith('post') \
|
||||
and not url.startswith('get') \
|
||||
and not url.startswith('delete') \
|
||||
and not url.startswith('put'):
|
||||
url += k + 'avatar_url=https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
|
||||
|
||||
if url.startswith('tgram://'):
|
||||
# Telegram only supports a limit subset of HTML, remove the '<br>' we place in.
|
||||
# re https://github.com/dgtlmoon/changedetection.io/issues/555
|
||||
# @todo re-use an existing library we have already imported to strip all non-allowed tags
|
||||
n_body = n_body.replace('<br>', '\n')
|
||||
n_body = n_body.replace('</br>', '\n')
|
||||
# real limit is 4096, but minus some for extra metadata
|
||||
payload_max_size = 3600
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
|
||||
elif url.startswith('discord://'):
|
||||
elif url.startswith('discord://') or url.startswith('https://discordapp.com/api/webhooks') or url.startswith('https://discord.com/api'):
|
||||
# real limit is 2000, but minus some for extra metadata
|
||||
payload_max_size = 1700
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
|
||||
elif url.startswith('mailto'):
|
||||
# Apprise will default to HTML, so we need to override it
|
||||
# So that whats' generated in n_body is in line with what is going to be sent.
|
||||
# https://github.com/caronc/apprise/issues/633#issuecomment-1191449321
|
||||
if not 'format=' in url and (n_format == 'text' or n_format == 'markdown'):
|
||||
prefix = '?' if not '?' in url else '&'
|
||||
url = "{}{}format={}".format(url, prefix, n_format)
|
||||
|
||||
apobj.add(url)
|
||||
|
||||
apobj.notify(
|
||||
title=n_title,
|
||||
body=n_body,
|
||||
body_format=n_format)
|
||||
body_format=n_format,
|
||||
# False is not an option for AppRise, must be type None
|
||||
attach=n_object.get('screenshot', None)
|
||||
)
|
||||
|
||||
apobj.clear()
|
||||
|
||||
@@ -96,6 +168,15 @@ def process_notification(n_object, datastore):
|
||||
log_value = logs.getvalue()
|
||||
if log_value and 'WARNING' in log_value or 'ERROR' in log_value:
|
||||
raise Exception(log_value)
|
||||
|
||||
sent_objs.append({'title': n_title,
|
||||
'body': n_body,
|
||||
'url' : url,
|
||||
'body_format': n_format})
|
||||
|
||||
# Return what was sent for better logging - after the for loop
|
||||
return sent_objs
|
||||
|
||||
|
||||
# Notification title + body content parameters get created here.
|
||||
def create_notification_parameters(n_object, datastore):
|
||||
@@ -116,7 +197,7 @@ def create_notification_parameters(n_object, datastore):
|
||||
|
||||
watch_url = n_object['watch_url']
|
||||
|
||||
# Re #148 - Some people have just {base_url} in the body or title, but this may break some notification services
|
||||
# Re #148 - Some people have just {{ base_url }} in the body or title, but this may break some notification services
|
||||
# like 'Join', so it's always best to atleast set something obvious so that they are not broken.
|
||||
if base_url == '':
|
||||
base_url = "<base-url-env-var-not-set>"
|
||||
@@ -131,15 +212,18 @@ def create_notification_parameters(n_object, datastore):
|
||||
tokens.update(
|
||||
{
|
||||
'base_url': base_url if base_url is not None else '',
|
||||
'current_snapshot': n_object['current_snapshot'] if 'current_snapshot' in n_object else '',
|
||||
'diff': n_object.get('diff', ''), # Null default in the case we use a test
|
||||
'diff_added': n_object.get('diff_added', ''), # Null default in the case we use a test
|
||||
'diff_full': n_object.get('diff_full', ''), # Null default in the case we use a test
|
||||
'diff_removed': n_object.get('diff_removed', ''), # Null default in the case we use a test
|
||||
'diff_url': diff_url,
|
||||
'preview_url': preview_url,
|
||||
'triggered_text': n_object.get('triggered_text', ''),
|
||||
'watch_tag': watch_tag if watch_tag is not None else '',
|
||||
'watch_title': watch_title if watch_title is not None else '',
|
||||
'watch_url': watch_url,
|
||||
'watch_uuid': uuid,
|
||||
'watch_title': watch_title if watch_title is not None else '',
|
||||
'watch_tag': watch_tag if watch_tag is not None else '',
|
||||
'diff_url': diff_url,
|
||||
'diff': n_object.get('diff', ''), # Null default in the case we use a test
|
||||
'diff_full': n_object.get('diff_full', ''), # Null default in the case we use a test
|
||||
'preview_url': preview_url,
|
||||
'current_snapshot': n_object['current_snapshot'] if 'current_snapshot' in n_object else ''
|
||||
})
|
||||
|
||||
return tokens
|
||||
|
||||
11
changedetectionio/processors/README.md
Normal file
@@ -0,0 +1,11 @@
|
||||
# Change detection post-processors
|
||||
|
||||
The concept here is to be able to switch between different domain specific problems to solve.
|
||||
|
||||
- `text_json_diff` The traditional text and JSON comparison handler
|
||||
- `restock_diff` Only cares about detecting if a product looks like it has some text that suggests that it's out of stock, otherwise assumes that it's in stock.
|
||||
|
||||
Some suggestions for the future
|
||||
|
||||
- `graphical`
|
||||
- `restock_and_price` - extract price AND stock text
|
||||
24
changedetectionio/processors/__init__.py
Normal file
@@ -0,0 +1,24 @@
|
||||
from abc import abstractmethod
|
||||
import hashlib
|
||||
|
||||
|
||||
class difference_detection_processor():
|
||||
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
@abstractmethod
|
||||
def run(self, uuid, skip_when_checksum_same=True):
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
some_data = 'xxxxx'
|
||||
update_obj["previous_md5"] = hashlib.md5(some_data.encode('utf-8')).hexdigest()
|
||||
changed_detected = False
|
||||
return changed_detected, update_obj, ''.encode('utf-8')
|
||||
|
||||
|
||||
def available_processors():
|
||||
from . import restock_diff, text_json_diff
|
||||
x=[('text_json_diff', text_json_diff.name), ('restock_diff', restock_diff.name)]
|
||||
# @todo Make this smarter with introspection of sorts.
|
||||
return x
|
||||
125
changedetectionio/processors/restock_diff.py
Normal file
@@ -0,0 +1,125 @@
|
||||
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import urllib3
|
||||
from . import difference_detection_processor
|
||||
from changedetectionio import content_fetcher
|
||||
from copy import deepcopy
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
name = 'Re-stock detection for single product pages'
|
||||
description = 'Detects if the product goes back to in-stock'
|
||||
|
||||
class perform_site_check(difference_detection_processor):
|
||||
screenshot = None
|
||||
xpath_data = None
|
||||
|
||||
def __init__(self, *args, datastore, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
def run(self, uuid, skip_when_checksum_same=True):
|
||||
|
||||
# DeepCopy so we can be sure we don't accidently change anything by reference
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
|
||||
if not watch:
|
||||
raise Exception("Watch no longer exists.")
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file', watch.get('url', ''), re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
extra_headers = watch.get('headers', [])
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = deepcopy(self.datastore.data['settings']['headers'])
|
||||
request_headers.update(extra_headers)
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
# Requests doesnt yet support brotli encoding, so don't put 'br' here, be totally sure that the user cannot
|
||||
# do this by accident.
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests'].get('timeout')
|
||||
|
||||
url = watch.link
|
||||
|
||||
request_body = self.datastore.data['watching'][uuid].get('body')
|
||||
request_method = self.datastore.data['watching'][uuid].get('method')
|
||||
ignore_status_codes = self.datastore.data['watching'][uuid].get('ignore_status_codes', False)
|
||||
|
||||
# Pluggable content fetcher
|
||||
prefer_backend = watch.get_fetch_backend
|
||||
if not prefer_backend or prefer_backend == 'system':
|
||||
prefer_backend = self.datastore.data['settings']['application']['fetch_backend']
|
||||
|
||||
if hasattr(content_fetcher, prefer_backend):
|
||||
klass = getattr(content_fetcher, prefer_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
proxy_url = None
|
||||
if proxy_id:
|
||||
proxy_url = self.datastore.proxy_list.get(proxy_id).get('url')
|
||||
print("UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||
|
||||
fetcher = klass(proxy_override=proxy_url)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if watch['webdriver_delay'] is not None:
|
||||
fetcher.render_extract_delay = watch.get('webdriver_delay')
|
||||
elif system_webdriver_delay is not None:
|
||||
fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
# Could be removed if requests/plaintext could also return some info?
|
||||
if prefer_backend != 'html_webdriver':
|
||||
raise Exception("Re-stock detection requires Chrome or compatible webdriver/playwright fetcher to work")
|
||||
|
||||
if watch.get('webdriver_js_execute_code') is not None and watch.get('webdriver_js_execute_code').strip():
|
||||
fetcher.webdriver_js_execute_code = watch.get('webdriver_js_execute_code')
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, watch.get('include_filters'))
|
||||
fetcher.quit()
|
||||
|
||||
self.screenshot = fetcher.screenshot
|
||||
self.xpath_data = fetcher.xpath_data
|
||||
|
||||
# Track the content type
|
||||
update_obj['content_type'] = fetcher.headers.get('Content-Type', '')
|
||||
update_obj["last_check_status"] = fetcher.get_last_status_code()
|
||||
|
||||
# Main detection method
|
||||
fetched_md5 = None
|
||||
if fetcher.instock_data:
|
||||
fetched_md5 = hashlib.md5(fetcher.instock_data.encode('utf-8')).hexdigest()
|
||||
# 'Possibly in stock' comes from stock-not-in-stock.js when no string found above the fold.
|
||||
update_obj["in_stock"] = True if fetcher.instock_data == 'Possibly in stock' else False
|
||||
|
||||
|
||||
# The main thing that all this at the moment comes down to :)
|
||||
changed_detected = False
|
||||
|
||||
if watch.get('previous_md5') and watch.get('previous_md5') != fetched_md5:
|
||||
# Yes if we only care about it going to instock, AND we are in stock
|
||||
if watch.get('in_stock_only') and update_obj["in_stock"]:
|
||||
changed_detected = True
|
||||
|
||||
if not watch.get('in_stock_only'):
|
||||
# All cases
|
||||
changed_detected = True
|
||||
|
||||
# Always record the new checksum
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
|
||||
return changed_detected, update_obj, fetcher.instock_data.encode('utf-8')
|
||||
416
changedetectionio/processors/text_json_diff.py
Normal file
@@ -0,0 +1,416 @@
|
||||
# HTML to TEXT/JSON DIFFERENCE FETCHER
|
||||
|
||||
import hashlib
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import urllib3
|
||||
|
||||
from changedetectionio import content_fetcher, html_tools
|
||||
from changedetectionio.blueprint.price_data_follower import PRICE_DATA_TRACK_ACCEPT, PRICE_DATA_TRACK_REJECT
|
||||
from copy import deepcopy
|
||||
from . import difference_detection_processor
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
|
||||
name = 'Webpage Text/HTML, JSON and PDF changes'
|
||||
description = 'Detects all text changes where possible'
|
||||
|
||||
class FilterNotFoundInResponse(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
class PDFToHTMLToolNotFound(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
# Some common stuff here that can be moved to a base class
|
||||
# (set_proxy_from_list)
|
||||
class perform_site_check(difference_detection_processor):
|
||||
screenshot = None
|
||||
xpath_data = None
|
||||
|
||||
def __init__(self, *args, datastore, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
# Doesn't look like python supports forward slash auto enclosure in re.findall
|
||||
# So convert it to inline flag "foobar(?i)" type configuration
|
||||
def forward_slash_enclosed_regex_to_options(self, regex):
|
||||
res = re.search(r'^/(.*?)/(\w+)$', regex, re.IGNORECASE)
|
||||
|
||||
if res:
|
||||
regex = res.group(1)
|
||||
regex += '(?{})'.format(res.group(2))
|
||||
else:
|
||||
regex += '(?{})'.format('i')
|
||||
|
||||
return regex
|
||||
|
||||
def run(self, uuid, skip_when_checksum_same=True):
|
||||
changed_detected = False
|
||||
screenshot = False # as bytes
|
||||
stripped_text_from_html = ""
|
||||
|
||||
# DeepCopy so we can be sure we don't accidently change anything by reference
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
|
||||
if not watch:
|
||||
raise Exception("Watch no longer exists.")
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file', watch.get('url', ''), re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
extra_headers = watch.get('headers', [])
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = deepcopy(self.datastore.data['settings']['headers'])
|
||||
request_headers.update(extra_headers)
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
# Requests doesnt yet support brotli encoding, so don't put 'br' here, be totally sure that the user cannot
|
||||
# do this by accident.
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests'].get('timeout')
|
||||
|
||||
url = watch.link
|
||||
|
||||
request_body = self.datastore.data['watching'][uuid].get('body')
|
||||
request_method = self.datastore.data['watching'][uuid].get('method')
|
||||
ignore_status_codes = self.datastore.data['watching'][uuid].get('ignore_status_codes', False)
|
||||
|
||||
# source: support
|
||||
is_source = False
|
||||
if url.startswith('source:'):
|
||||
url = url.replace('source:', '')
|
||||
is_source = True
|
||||
|
||||
# Pluggable content fetcher
|
||||
prefer_backend = watch.get_fetch_backend
|
||||
if not prefer_backend or prefer_backend == 'system':
|
||||
prefer_backend = self.datastore.data['settings']['application']['fetch_backend']
|
||||
|
||||
if hasattr(content_fetcher, prefer_backend):
|
||||
klass = getattr(content_fetcher, prefer_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
proxy_url = None
|
||||
if proxy_id:
|
||||
proxy_url = self.datastore.proxy_list.get(proxy_id).get('url')
|
||||
print("UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||
|
||||
fetcher = klass(proxy_override=proxy_url)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if watch['webdriver_delay'] is not None:
|
||||
fetcher.render_extract_delay = watch.get('webdriver_delay')
|
||||
elif system_webdriver_delay is not None:
|
||||
fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
# Possible conflict
|
||||
if prefer_backend == 'html_webdriver':
|
||||
fetcher.browser_steps = watch.get('browser_steps', None)
|
||||
fetcher.browser_steps_screenshot_path = os.path.join(self.datastore.datastore_path, uuid)
|
||||
|
||||
if watch.get('webdriver_js_execute_code') is not None and watch.get('webdriver_js_execute_code').strip():
|
||||
fetcher.webdriver_js_execute_code = watch.get('webdriver_js_execute_code')
|
||||
|
||||
# requests for PDF's, images etc should be passwd the is_binary flag
|
||||
is_binary = watch.is_pdf
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, watch.get('include_filters'), is_binary=is_binary)
|
||||
fetcher.quit()
|
||||
|
||||
self.screenshot = fetcher.screenshot
|
||||
self.xpath_data = fetcher.xpath_data
|
||||
|
||||
# Track the content type
|
||||
update_obj['content_type'] = fetcher.headers.get('Content-Type', '')
|
||||
|
||||
# Watches added automatically in the queue manager will skip if its the same checksum as the previous run
|
||||
# Saves a lot of CPU
|
||||
update_obj['previous_md5_before_filters'] = hashlib.md5(fetcher.content.encode('utf-8')).hexdigest()
|
||||
if skip_when_checksum_same:
|
||||
if update_obj['previous_md5_before_filters'] == watch.get('previous_md5_before_filters'):
|
||||
raise content_fetcher.checksumFromPreviousCheckWasTheSame()
|
||||
|
||||
|
||||
# Fetching complete, now filters
|
||||
# @todo move to class / maybe inside of fetcher abstract base?
|
||||
|
||||
# @note: I feel like the following should be in a more obvious chain system
|
||||
# - Check filter text
|
||||
# - Is the checksum different?
|
||||
# - Do we convert to JSON?
|
||||
# https://stackoverflow.com/questions/41817578/basic-method-chaining ?
|
||||
# return content().textfilter().jsonextract().checksumcompare() ?
|
||||
|
||||
is_json = 'application/json' in fetcher.headers.get('Content-Type', '')
|
||||
is_html = not is_json
|
||||
|
||||
# source: support, basically treat it as plaintext
|
||||
if is_source:
|
||||
is_html = False
|
||||
is_json = False
|
||||
|
||||
if watch.is_pdf or 'application/pdf' in fetcher.headers.get('Content-Type', '').lower():
|
||||
from shutil import which
|
||||
tool = os.getenv("PDF_TO_HTML_TOOL", "pdftohtml")
|
||||
if not which(tool):
|
||||
raise PDFToHTMLToolNotFound("Command-line `{}` tool was not found in system PATH, was it installed?".format(tool))
|
||||
|
||||
import subprocess
|
||||
proc = subprocess.Popen(
|
||||
[tool, '-stdout', '-', '-s', 'out.pdf', '-i'],
|
||||
stdout=subprocess.PIPE,
|
||||
stdin=subprocess.PIPE)
|
||||
proc.stdin.write(fetcher.raw_content)
|
||||
proc.stdin.close()
|
||||
fetcher.content = proc.stdout.read().decode('utf-8')
|
||||
proc.wait(timeout=60)
|
||||
|
||||
# Add a little metadata so we know if the file changes (like if an image changes, but the text is the same
|
||||
# @todo may cause problems with non-UTF8?
|
||||
metadata = "<p>Added by changedetection.io: Document checksum - {} Filesize - {} bytes</p>".format(
|
||||
hashlib.md5(fetcher.raw_content).hexdigest().upper(),
|
||||
len(fetcher.content))
|
||||
|
||||
fetcher.content = fetcher.content.replace('</body>', metadata + '</body>')
|
||||
|
||||
|
||||
include_filters_rule = deepcopy(watch.get('include_filters', []))
|
||||
# include_filters_rule = watch['include_filters']
|
||||
subtractive_selectors = watch.get(
|
||||
"subtractive_selectors", []
|
||||
) + self.datastore.data["settings"]["application"].get(
|
||||
"global_subtractive_selectors", []
|
||||
)
|
||||
|
||||
# Inject a virtual LD+JSON price tracker rule
|
||||
if watch.get('track_ldjson_price_data', '') == PRICE_DATA_TRACK_ACCEPT:
|
||||
include_filters_rule.append(html_tools.LD_JSON_PRODUCT_OFFER_SELECTOR)
|
||||
|
||||
has_filter_rule = include_filters_rule and len("".join(include_filters_rule).strip())
|
||||
has_subtractive_selectors = subtractive_selectors and len(subtractive_selectors[0].strip())
|
||||
|
||||
if is_json and not has_filter_rule:
|
||||
include_filters_rule.append("json:$")
|
||||
has_filter_rule = True
|
||||
|
||||
if is_json:
|
||||
# Sort the JSON so we dont get false alerts when the content is just re-ordered
|
||||
try:
|
||||
fetcher.content = json.dumps(json.loads(fetcher.content), sort_keys=True)
|
||||
except Exception as e:
|
||||
# Might have just been a snippet, or otherwise bad JSON, continue
|
||||
pass
|
||||
|
||||
if has_filter_rule:
|
||||
json_filter_prefixes = ['json:', 'jq:']
|
||||
for filter in include_filters_rule:
|
||||
if any(prefix in filter for prefix in json_filter_prefixes):
|
||||
stripped_text_from_html += html_tools.extract_json_as_string(content=fetcher.content, json_filter=filter)
|
||||
is_html = False
|
||||
|
||||
|
||||
|
||||
if is_html or is_source:
|
||||
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
fetcher.content = html_tools.workarounds_for_obfuscations(fetcher.content)
|
||||
html_content = fetcher.content
|
||||
|
||||
# If not JSON, and if it's not text/plain..
|
||||
if 'text/plain' in fetcher.headers.get('Content-Type', '').lower():
|
||||
# Don't run get_text or xpath/css filters on plaintext
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# Does it have some ld+json price data? used for easier monitoring
|
||||
update_obj['has_ldjson_price_data'] = html_tools.has_ldjson_product_info(fetcher.content)
|
||||
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
html_content = ""
|
||||
|
||||
for filter_rule in include_filters_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if filter_rule[0] == '/' or filter_rule.startswith('xpath:'):
|
||||
html_content += html_tools.xpath_filter(xpath_filter=filter_rule.replace('xpath:', ''),
|
||||
html_content=fetcher.content,
|
||||
append_pretty_line_formatting=not is_source)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content += html_tools.include_filters(include_filters=filter_rule,
|
||||
html_content=fetcher.content,
|
||||
append_pretty_line_formatting=not is_source)
|
||||
|
||||
if not html_content.strip():
|
||||
raise FilterNotFoundInResponse(include_filters_rule)
|
||||
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
if is_source:
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# extract text
|
||||
do_anchor = self.datastore.data["settings"]["application"].get("render_anchor_tag_content", False)
|
||||
stripped_text_from_html = \
|
||||
html_tools.html_to_text(
|
||||
html_content,
|
||||
render_anchor_tag_content=do_anchor
|
||||
)
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
|
||||
# @todo whitespace coming from missing rtrim()?
|
||||
# stripped_text_from_html could be based on their preferences, replace the processed text with only that which they want to know about.
|
||||
# Rewrite's the processing text based on only what diff result they want to see
|
||||
if watch.has_special_diff_filter_options_set() and len(watch.history.keys()):
|
||||
# Now the content comes from the diff-parser and not the returned HTTP traffic, so could be some differences
|
||||
from .. import diff
|
||||
# needs to not include (added) etc or it may get used twice
|
||||
# Replace the processed text with the preferred result
|
||||
rendered_diff = diff.render_diff(previous_version_file_contents=watch.get_last_fetched_before_filters(),
|
||||
newest_version_file_contents=stripped_text_from_html,
|
||||
include_equal=False, # not the same lines
|
||||
include_added=watch.get('filter_text_added', True),
|
||||
include_removed=watch.get('filter_text_removed', True),
|
||||
include_replaced=watch.get('filter_text_replaced', True),
|
||||
line_feed_sep="\n",
|
||||
include_change_type_prefix=False)
|
||||
|
||||
watch.save_last_fetched_before_filters(text_content_before_ignored_filter)
|
||||
|
||||
if not rendered_diff and stripped_text_from_html:
|
||||
# We had some content, but no differences were found
|
||||
# Store our new file as the MD5 so it will trigger in the future
|
||||
c = hashlib.md5(text_content_before_ignored_filter.translate(None, b'\r\n\t ')).hexdigest()
|
||||
return False, {'previous_md5': c}, stripped_text_from_html.encode('utf-8')
|
||||
else:
|
||||
stripped_text_from_html = rendered_diff
|
||||
|
||||
# Treat pages with no renderable text content as a change? No by default
|
||||
empty_pages_are_a_change = self.datastore.data['settings']['application'].get('empty_pages_are_a_change', False)
|
||||
if not is_json and not empty_pages_are_a_change and len(stripped_text_from_html.strip()) == 0:
|
||||
raise content_fetcher.ReplyWithContentButNoText(url=url, status_code=fetcher.get_last_status_code(), screenshot=screenshot)
|
||||
|
||||
# We rely on the actual text in the html output.. many sites have random script vars etc,
|
||||
# in the future we'll implement other mechanisms.
|
||||
|
||||
update_obj["last_check_status"] = fetcher.get_last_status_code()
|
||||
|
||||
# If there's text to skip
|
||||
# @todo we could abstract out the get_text() to handle this cleaner
|
||||
text_to_ignore = watch.get('ignore_text', []) + self.datastore.data['settings']['application'].get('global_ignore_text', [])
|
||||
if len(text_to_ignore):
|
||||
stripped_text_from_html = html_tools.strip_ignore_text(stripped_text_from_html, text_to_ignore)
|
||||
else:
|
||||
stripped_text_from_html = stripped_text_from_html.encode('utf8')
|
||||
|
||||
# 615 Extract text by regex
|
||||
extract_text = watch.get('extract_text', [])
|
||||
if len(extract_text) > 0:
|
||||
regex_matched_output = []
|
||||
for s_re in extract_text:
|
||||
# incase they specified something in '/.../x'
|
||||
regex = self.forward_slash_enclosed_regex_to_options(s_re)
|
||||
result = re.findall(regex.encode('utf-8'), stripped_text_from_html)
|
||||
|
||||
for l in result:
|
||||
if type(l) is tuple:
|
||||
# @todo - some formatter option default (between groups)
|
||||
regex_matched_output += list(l) + [b'\n']
|
||||
else:
|
||||
# @todo - some formatter option default (between each ungrouped result)
|
||||
regex_matched_output += [l] + [b'\n']
|
||||
|
||||
# Now we will only show what the regex matched
|
||||
stripped_text_from_html = b''
|
||||
text_content_before_ignored_filter = b''
|
||||
if regex_matched_output:
|
||||
# @todo some formatter for presentation?
|
||||
stripped_text_from_html = b''.join(regex_matched_output)
|
||||
text_content_before_ignored_filter = stripped_text_from_html
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
else:
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html).hexdigest()
|
||||
|
||||
############ Blocking rules, after checksum #################
|
||||
blocked = False
|
||||
|
||||
trigger_text = watch.get('trigger_text', [])
|
||||
if len(trigger_text):
|
||||
# Assume blocked
|
||||
blocked = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
# It should return the line numbers that match
|
||||
# Unblock flow if the trigger was found (some text remained after stripped what didnt match)
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=trigger_text,
|
||||
mode="line numbers")
|
||||
# Unblock if the trigger was found
|
||||
if result:
|
||||
blocked = False
|
||||
|
||||
text_should_not_be_present = watch.get('text_should_not_be_present', [])
|
||||
if len(text_should_not_be_present):
|
||||
# If anything matched, then we should block a change from happening
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=text_should_not_be_present,
|
||||
mode="line numbers")
|
||||
if result:
|
||||
blocked = True
|
||||
|
||||
# The main thing that all this at the moment comes down to :)
|
||||
if watch.get('previous_md5') != fetched_md5:
|
||||
changed_detected = True
|
||||
|
||||
# Looks like something changed, but did it match all the rules?
|
||||
if blocked:
|
||||
changed_detected = False
|
||||
|
||||
# Extract title as title
|
||||
if is_html:
|
||||
if self.datastore.data['settings']['application'].get('extract_title_as_title') or watch['extract_title_as_title']:
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
|
||||
|
||||
if changed_detected:
|
||||
if watch.get('check_unique_lines', False):
|
||||
has_unique_lines = watch.lines_contain_something_unique_compared_to_history(lines=stripped_text_from_html.splitlines())
|
||||
# One or more lines? unsure?
|
||||
if not has_unique_lines:
|
||||
logging.debug("check_unique_lines: UUID {} didnt have anything new setting change_detected=False".format(uuid))
|
||||
changed_detected = False
|
||||
else:
|
||||
logging.debug("check_unique_lines: UUID {} had unique content".format(uuid))
|
||||
|
||||
# Always record the new checksum
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
|
||||
# On the first run of a site, watch['previous_md5'] will be None, set it the current one.
|
||||
if not watch.get('previous_md5'):
|
||||
watch['previous_md5'] = fetched_md5
|
||||
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter
|
||||
10
changedetectionio/queuedWatchMetaData.py
Normal file
@@ -0,0 +1,10 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any
|
||||
|
||||
# So that we can queue some metadata in `item`
|
||||
# https://docs.python.org/3/library/queue.html#queue.PriorityQueue
|
||||
#
|
||||
@dataclass(order=True)
|
||||
class PrioritizedItem:
|
||||
priority: int
|
||||
item: Any=field(compare=False)
|
||||
179
changedetectionio/res/puppeteer_fetch.js
Normal file
@@ -0,0 +1,179 @@
|
||||
module.exports = async ({page, context}) => {
|
||||
|
||||
var {
|
||||
url,
|
||||
execute_js,
|
||||
user_agent,
|
||||
extra_wait_ms,
|
||||
req_headers,
|
||||
include_filters,
|
||||
xpath_element_js,
|
||||
screenshot_quality,
|
||||
proxy_username,
|
||||
proxy_password,
|
||||
disk_cache_dir,
|
||||
no_cache_list,
|
||||
block_url_list,
|
||||
} = context;
|
||||
|
||||
await page.setBypassCSP(true)
|
||||
await page.setExtraHTTPHeaders(req_headers);
|
||||
await page.setUserAgent(user_agent);
|
||||
// https://ourcodeworld.com/articles/read/1106/how-to-solve-puppeteer-timeouterror-navigation-timeout-of-30000-ms-exceeded
|
||||
|
||||
await page.setDefaultNavigationTimeout(0);
|
||||
|
||||
if (proxy_username) {
|
||||
await page.authenticate({
|
||||
username: proxy_username,
|
||||
password: proxy_password
|
||||
});
|
||||
}
|
||||
|
||||
await page.setViewport({
|
||||
width: 1024,
|
||||
height: 768,
|
||||
deviceScaleFactor: 1,
|
||||
});
|
||||
|
||||
await page.setRequestInterception(true);
|
||||
if (disk_cache_dir) {
|
||||
console.log(">>>>>>>>>>>>>>> LOCAL DISK CACHE ENABLED <<<<<<<<<<<<<<<<<<<<<");
|
||||
}
|
||||
const fs = require('fs');
|
||||
const crypto = require('crypto');
|
||||
|
||||
function file_is_expired(file_path) {
|
||||
if (!fs.existsSync(file_path)) {
|
||||
return true;
|
||||
}
|
||||
var stats = fs.statSync(file_path);
|
||||
const now_date = new Date();
|
||||
const expire_seconds = 300;
|
||||
if ((now_date / 1000) - (stats.mtime.getTime() / 1000) > expire_seconds) {
|
||||
console.log("CACHE EXPIRED: " + file_path);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
|
||||
}
|
||||
|
||||
page.on('request', async (request) => {
|
||||
// General blocking of requests that waste traffic
|
||||
if (block_url_list.some(substring => request.url().toLowerCase().includes(substring))) return request.abort();
|
||||
|
||||
if (disk_cache_dir) {
|
||||
const url = request.url();
|
||||
const key = crypto.createHash('md5').update(url).digest("hex");
|
||||
const dir_path = disk_cache_dir + key.slice(0, 1) + '/' + key.slice(1, 2) + '/' + key.slice(2, 3) + '/';
|
||||
|
||||
// https://stackoverflow.com/questions/4482686/check-synchronously-if-file-directory-exists-in-node-js
|
||||
|
||||
if (fs.existsSync(dir_path + key)) {
|
||||
console.log("* CACHE HIT , using - " + dir_path + key + " - " + url);
|
||||
const cached_data = fs.readFileSync(dir_path + key);
|
||||
// @todo headers can come from dir_path+key+".meta" json file
|
||||
request.respond({
|
||||
status: 200,
|
||||
//contentType: 'text/html', //@todo
|
||||
body: cached_data
|
||||
});
|
||||
return;
|
||||
}
|
||||
}
|
||||
request.continue();
|
||||
});
|
||||
|
||||
|
||||
if (disk_cache_dir) {
|
||||
page.on('response', async (response) => {
|
||||
const url = response.url();
|
||||
// Basic filtering for sane responses
|
||||
if (response.request().method() != 'GET' || response.request().resourceType() == 'xhr' || response.request().resourceType() == 'document' || response.status() != 200) {
|
||||
console.log("Skipping (not useful) - Status:" + response.status() + " Method:" + response.request().method() + " ResourceType:" + response.request().resourceType() + " " + url);
|
||||
return;
|
||||
}
|
||||
if (no_cache_list.some(substring => url.toLowerCase().includes(substring))) {
|
||||
console.log("Skipping (no_cache_list) - " + url);
|
||||
return;
|
||||
}
|
||||
response.buffer().then(buffer => {
|
||||
if (buffer.length > 100) {
|
||||
console.log("Cache - Saving " + response.request().method() + " - " + url + " - " + response.request().resourceType());
|
||||
|
||||
const key = crypto.createHash('md5').update(url).digest("hex");
|
||||
const dir_path = disk_cache_dir + key.slice(0, 1) + '/' + key.slice(1, 2) + '/' + key.slice(2, 3) + '/';
|
||||
|
||||
if (!fs.existsSync(dir_path)) {
|
||||
fs.mkdirSync(dir_path, {recursive: true})
|
||||
}
|
||||
|
||||
if (fs.existsSync(dir_path + key)) {
|
||||
if (file_is_expired(dir_path + key)) {
|
||||
fs.writeFileSync(dir_path + key, buffer);
|
||||
}
|
||||
} else {
|
||||
fs.writeFileSync(dir_path + key, buffer);
|
||||
}
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
const r = await page.goto(url, {
|
||||
waitUntil: 'load'
|
||||
});
|
||||
|
||||
await page.waitForTimeout(1000);
|
||||
await page.waitForTimeout(extra_wait_ms);
|
||||
|
||||
if (execute_js) {
|
||||
await page.evaluate(execute_js);
|
||||
await page.waitForTimeout(200);
|
||||
}
|
||||
|
||||
var xpath_data;
|
||||
var instock_data;
|
||||
try {
|
||||
// Not sure the best way here, in the future this should be a new package added to npm then run in browserless
|
||||
// (Once the old playwright is removed)
|
||||
xpath_data = await page.evaluate((include_filters) => {%xpath_scrape_code%}, include_filters);
|
||||
instock_data = await page.evaluate(() => {%instock_scrape_code%});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// Protocol error (Page.captureScreenshot): Cannot take screenshot with 0 width can come from a proxy auth failure
|
||||
// Wrap it here (for now)
|
||||
|
||||
var b64s = false;
|
||||
try {
|
||||
b64s = await page.screenshot({encoding: "base64", fullPage: true, quality: screenshot_quality, type: 'jpeg'});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// May fail on very large pages with 'WARNING: tile memory limits exceeded, some content may not draw'
|
||||
if (!b64s) {
|
||||
// @todo after text extract, we can place some overlay text with red background to say 'croppped'
|
||||
console.error('ERROR: content-fetcher page was maybe too large for a screenshot, reverting to viewport only screenshot');
|
||||
try {
|
||||
b64s = await page.screenshot({encoding: "base64", quality: screenshot_quality, type: 'jpeg'});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
}
|
||||
|
||||
var html = await page.content();
|
||||
return {
|
||||
data: {
|
||||
'content': html,
|
||||
'headers': r.headers(),
|
||||
'instock_data': instock_data,
|
||||
'screenshot': b64s,
|
||||
'status_code': r.status(),
|
||||
'xpath_data': xpath_data
|
||||
},
|
||||
type: 'application/json',
|
||||
};
|
||||
};
|
||||
97
changedetectionio/res/stock-not-in-stock.js
Normal file
@@ -0,0 +1,97 @@
|
||||
function isItemInStock() {
|
||||
// @todo Pass these in so the same list can be used in non-JS fetchers
|
||||
const outOfStockTexts = [
|
||||
'0 in stock',
|
||||
'agotado',
|
||||
'artikel zurzeit vergriffen',
|
||||
'as soon as stock is available',
|
||||
'available for back order',
|
||||
'backordered',
|
||||
'brak na stanie',
|
||||
'brak w magazynie',
|
||||
'coming soon',
|
||||
'currently unavailable',
|
||||
'en rupture de stock',
|
||||
'item is no longer available',
|
||||
'message if back in stock',
|
||||
'nachricht bei',
|
||||
'nicht auf lager',
|
||||
'nicht lieferbar',
|
||||
'nicht zur verfügung',
|
||||
'no disponible temporalmente',
|
||||
'no longer in stock',
|
||||
'not available',
|
||||
'not in stock',
|
||||
'notify me when available',
|
||||
'não estamos a aceitar encomendas',
|
||||
'out of stock',
|
||||
'out-of-stock',
|
||||
'produkt niedostępny',
|
||||
'sold out',
|
||||
'temporarily out of stock',
|
||||
'temporarily unavailable',
|
||||
'we do not currently have an estimate of when this product will be back in stock.',
|
||||
'zur zeit nicht an lager',
|
||||
];
|
||||
|
||||
|
||||
const negateOutOfStockRegexs = [
|
||||
'[0-9] in stock'
|
||||
]
|
||||
var negateOutOfStockRegexs_r = [];
|
||||
for (let i = 0; i < negateOutOfStockRegexs.length; i++) {
|
||||
negateOutOfStockRegexs_r.push(new RegExp(negateOutOfStockRegexs[0], 'g'));
|
||||
}
|
||||
|
||||
|
||||
const elementsWithZeroChildren = Array.from(document.getElementsByTagName('*')).filter(element => element.children.length === 0);
|
||||
|
||||
// REGEXS THAT REALLY MEAN IT'S IN STOCK
|
||||
for (let i = elementsWithZeroChildren.length - 1; i >= 0; i--) {
|
||||
const element = elementsWithZeroChildren[i];
|
||||
if (element.offsetWidth > 0 || element.offsetHeight > 0 || element.getClientRects().length > 0) {
|
||||
var elementText="";
|
||||
if (element.tagName.toLowerCase() === "input") {
|
||||
elementText = element.value.toLowerCase();
|
||||
} else {
|
||||
elementText = element.textContent.toLowerCase();
|
||||
}
|
||||
|
||||
if (elementText.length) {
|
||||
// try which ones could mean its in stock
|
||||
for (let i = 0; i < negateOutOfStockRegexs.length; i++) {
|
||||
if (negateOutOfStockRegexs_r[i].test(elementText)) {
|
||||
return 'Possibly in stock';
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// OTHER STUFF THAT COULD BE THAT IT'S OUT OF STOCK
|
||||
for (let i = elementsWithZeroChildren.length - 1; i >= 0; i--) {
|
||||
const element = elementsWithZeroChildren[i];
|
||||
if (element.offsetWidth > 0 || element.offsetHeight > 0 || element.getClientRects().length > 0) {
|
||||
var elementText="";
|
||||
if (element.tagName.toLowerCase() === "input") {
|
||||
elementText = element.value.toLowerCase();
|
||||
} else {
|
||||
elementText = element.textContent.toLowerCase();
|
||||
}
|
||||
|
||||
if (elementText.length) {
|
||||
// and these mean its out of stock
|
||||
for (const outOfStockText of outOfStockTexts) {
|
||||
if (elementText.includes(outOfStockText)) {
|
||||
return elementText; // item is out of stock
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return 'Possibly in stock'; // possibly in stock, cant decide otherwise.
|
||||
}
|
||||
|
||||
// returns the element text that makes it think it's out of stock
|
||||
return isItemInStock();
|
||||
221
changedetectionio/res/xpath_element_scraper.js
Normal file
@@ -0,0 +1,221 @@
|
||||
// Copyright (C) 2021 Leigh Morresi (dgtlmoon@gmail.com)
|
||||
// All rights reserved.
|
||||
|
||||
// @file Scrape the page looking for elements of concern (%ELEMENTS%)
|
||||
// http://matatk.agrip.org.uk/tests/position-and-width/
|
||||
// https://stackoverflow.com/questions/26813480/when-is-element-getboundingclientrect-guaranteed-to-be-updated-accurate
|
||||
//
|
||||
// Some pages like https://www.londonstockexchange.com/stock/NCCL/ncondezi-energy-limited/analysis
|
||||
// will automatically force a scroll somewhere, so include the position offset
|
||||
// Lets hope the position doesnt change while we iterate the bbox's, but this is better than nothing
|
||||
var scroll_y = 0;
|
||||
try {
|
||||
scroll_y = +document.documentElement.scrollTop || document.body.scrollTop
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
|
||||
|
||||
// Include the getXpath script directly, easier than fetching
|
||||
function getxpath(e) {
|
||||
var n = e;
|
||||
if (n && n.id) return '//*[@id="' + n.id + '"]';
|
||||
for (var o = []; n && Node.ELEMENT_NODE === n.nodeType;) {
|
||||
for (var i = 0, r = !1, d = n.previousSibling; d;) d.nodeType !== Node.DOCUMENT_TYPE_NODE && d.nodeName === n.nodeName && i++, d = d.previousSibling;
|
||||
for (d = n.nextSibling; d;) {
|
||||
if (d.nodeName === n.nodeName) {
|
||||
r = !0;
|
||||
break
|
||||
}
|
||||
d = d.nextSibling
|
||||
}
|
||||
o.push((n.prefix ? n.prefix + ":" : "") + n.localName + (i || r ? "[" + (i + 1) + "]" : "")), n = n.parentNode
|
||||
}
|
||||
return o.length ? "/" + o.reverse().join("/") : ""
|
||||
}
|
||||
|
||||
const findUpTag = (el) => {
|
||||
let r = el
|
||||
chained_css = [];
|
||||
depth = 0;
|
||||
|
||||
// Strategy 1: If it's an input, with name, and there's only one, prefer that
|
||||
if (el.name !== undefined && el.name.length) {
|
||||
var proposed = el.tagName + "[name=" + el.name + "]";
|
||||
var proposed_element = window.document.querySelectorAll(proposed);
|
||||
if (proposed_element.length) {
|
||||
if (proposed_element.length === 1) {
|
||||
return proposed;
|
||||
} else {
|
||||
// Some sites change ID but name= stays the same, we can hit it if we know the index
|
||||
// Find all the elements that match and work out the input[n]
|
||||
var n = Array.from(proposed_element).indexOf(el);
|
||||
// Return a Playwright selector for nthinput[name=zipcode]
|
||||
return proposed + " >> nth=" + n;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Strategy 2: Keep going up until we hit an ID tag, imagine it's like #list-widget div h4
|
||||
while (r.parentNode) {
|
||||
if (depth == 5) {
|
||||
break;
|
||||
}
|
||||
if ('' !== r.id) {
|
||||
chained_css.unshift("#" + CSS.escape(r.id));
|
||||
final_selector = chained_css.join(' > ');
|
||||
// Be sure theres only one, some sites have multiples of the same ID tag :-(
|
||||
if (window.document.querySelectorAll(final_selector).length == 1) {
|
||||
return final_selector;
|
||||
}
|
||||
return null;
|
||||
} else {
|
||||
chained_css.unshift(r.tagName.toLowerCase());
|
||||
}
|
||||
r = r.parentNode;
|
||||
depth += 1;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
// @todo - if it's SVG or IMG, go into image diff mode
|
||||
// %ELEMENTS% replaced at injection time because different interfaces use it with different settings
|
||||
var elements = window.document.querySelectorAll("%ELEMENTS%");
|
||||
var size_pos = [];
|
||||
// after page fetch, inject this JS
|
||||
// build a map of all elements and their positions (maybe that only include text?)
|
||||
var bbox;
|
||||
for (var i = 0; i < elements.length; i++) {
|
||||
bbox = elements[i].getBoundingClientRect();
|
||||
|
||||
// Exclude items that are not interactable or visible
|
||||
if(elements[i].style.opacity === "0") {
|
||||
continue
|
||||
}
|
||||
if(elements[i].style.display === "none" || elements[i].style.pointerEvents === "none" ) {
|
||||
continue
|
||||
}
|
||||
|
||||
// Skip really small ones, and where width or height ==0
|
||||
if (bbox['width'] * bbox['height'] < 100) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// Don't include elements that are offset from canvas
|
||||
if (bbox['top']+scroll_y < 0 || bbox['left'] < 0) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo the getXpath kind of sucks, it doesnt know when there is for example just one ID sometimes
|
||||
// it should not traverse when we know we can anchor off just an ID one level up etc..
|
||||
// maybe, get current class or id, keep traversing up looking for only class or id until there is just one match
|
||||
|
||||
// 1st primitive - if it has class, try joining it all and select, if theres only one.. well thats us.
|
||||
xpath_result = false;
|
||||
|
||||
try {
|
||||
var d = findUpTag(elements[i]);
|
||||
if (d) {
|
||||
xpath_result = d;
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getxpath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if (window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo Possible to ONLY list where it's clickable to save JSON xfer size
|
||||
size_pos.push({
|
||||
xpath: xpath_result,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top'])+scroll_y,
|
||||
tagName: (elements[i].tagName) ? elements[i].tagName.toLowerCase() : '',
|
||||
tagtype: (elements[i].tagName == 'INPUT' && elements[i].type) ? elements[i].type.toLowerCase() : '',
|
||||
isClickable: (elements[i].onclick) || window.getComputedStyle(elements[i]).cursor == "pointer"
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
// Inject the current one set in the include_filters, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (include_filters.length) {
|
||||
// Foreach filter, go and find it on the page and add it to the results so we can visualise it again
|
||||
for (const f of include_filters) {
|
||||
bbox = false;
|
||||
q = false;
|
||||
|
||||
if (!f.length) {
|
||||
console.log("xpath_element_scraper: Empty filter, skipping");
|
||||
continue;
|
||||
}
|
||||
|
||||
try {
|
||||
// is it xpath?
|
||||
if (f.startsWith('/') || f.startsWith('xpath:')) {
|
||||
q = document.evaluate(f.replace('xpath:', ''), document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q = document.querySelector(f);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log("xpath_element_scraper: Exception selecting element from filter "+f);
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
if (q) {
|
||||
// #1231 - IN the case XPath attribute filter is applied, we will have to traverse up and find the element.
|
||||
if (q.hasOwnProperty('getBoundingClientRect')) {
|
||||
bbox = q.getBoundingClientRect();
|
||||
console.log("xpath_element_scraper: Got filter element, scroll from top was " + scroll_y)
|
||||
} else {
|
||||
try {
|
||||
// Try and see we can find its ownerElement
|
||||
bbox = q.ownerElement.getBoundingClientRect();
|
||||
console.log("xpath_element_scraper: Got filter by ownerElement element, scroll from top was " + scroll_y)
|
||||
} catch (e) {
|
||||
console.log("xpath_element_scraper: error looking up ownerElement")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if(!q) {
|
||||
console.log("xpath_element_scraper: filter element " + f + " was not found");
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] > 0 && bbox['height'] > 0) {
|
||||
size_pos.push({
|
||||
xpath: f,
|
||||
width: parseInt(bbox['width']),
|
||||
height: parseInt(bbox['height']),
|
||||
left: parseInt(bbox['left']),
|
||||
top: parseInt(bbox['top'])+scroll_y
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Sort the elements so we find the smallest one first, in other words, we find the smallest one matching in that area
|
||||
// so that we dont select the wrapping element by mistake and be unable to select what we want
|
||||
size_pos.sort((a, b) => (a.width*a.height > b.width*b.height) ? 1 : -1)
|
||||
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos': size_pos, 'browser_width': window.innerWidth};
|
||||
@@ -9,6 +9,8 @@
|
||||
# exit when any command fails
|
||||
set -e
|
||||
|
||||
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
||||
|
||||
find tests/test_*py -type f|while read test_name
|
||||
do
|
||||
echo "TEST RUNNING $test_name"
|
||||
@@ -22,3 +24,15 @@ echo "RUNNING WITH BASE_URL SET"
|
||||
export BASE_URL="https://really-unique-domain.io"
|
||||
pytest tests/test_notification.py
|
||||
|
||||
|
||||
# Re-run with HIDE_REFERER set - could affect login
|
||||
export HIDE_REFERER=True
|
||||
pytest tests/test_access_control.py
|
||||
|
||||
# Re-run a few tests that will trigger brotli based storage
|
||||
export SNAPSHOT_BROTLI_COMPRESSION_THRESHOLD=5
|
||||
pytest tests/test_access_control.py
|
||||
pytest tests/test_notification.py
|
||||
pytest tests/test_backend.py
|
||||
pytest tests/test_rss.py
|
||||
pytest tests/test_unique_lines.py
|
||||
61
changedetectionio/run_proxy_tests.sh
Executable file
@@ -0,0 +1,61 @@
|
||||
#!/bin/bash
|
||||
|
||||
# exit when any command fails
|
||||
set -e
|
||||
|
||||
# Test proxy list handling, starting two squids on different ports
|
||||
# Each squid adds a different header to the response, which is the main thing we test for.
|
||||
docker run --network changedet-network -d --name squid-one --hostname squid-one --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf ubuntu/squid:4.13-21.10_edge
|
||||
docker run --network changedet-network -d --name squid-two --hostname squid-two --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf ubuntu/squid:4.13-21.10_edge
|
||||
|
||||
# Used for configuring a custom proxy URL via the UI
|
||||
docker run --network changedet-network -d \
|
||||
--name squid-custom \
|
||||
--hostname squid-custom \
|
||||
--rm \
|
||||
-v `pwd`/tests/proxy_list/squid-auth.conf:/etc/squid/conf.d/debian.conf \
|
||||
-v `pwd`/tests/proxy_list/squid-passwords.txt:/etc/squid3/passwords \
|
||||
ubuntu/squid:4.13-21.10_edge
|
||||
|
||||
|
||||
## 2nd test actually choose the preferred proxy from proxies.json
|
||||
|
||||
docker run --network changedet-network \
|
||||
-v `pwd`/tests/proxy_list/proxies.json-example:/app/changedetectionio/test-datastore/proxies.json \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_list/test_multiple_proxy.py'
|
||||
|
||||
|
||||
## Should be a request in the default "first" squid
|
||||
docker logs squid-one 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy - squid one)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# And one in the 'second' squid (user selects this as preferred)
|
||||
docker logs squid-two 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy - squid two)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
|
||||
# Test the UI configurable proxies
|
||||
|
||||
docker run --network changedet-network \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_list/test_select_custom_proxy.py'
|
||||
|
||||
|
||||
# Should see a request for one.changedetection.io in there
|
||||
docker logs squid-custom 2>/dev/null|grep "TCP_TUNNEL.200.*changedetection.io"
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a valid request to changedetection.io in the squid logs (while checking preferred proxy - squid two)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
docker kill squid-one squid-two squid-custom
|
||||
BIN
changedetectionio/static/favicons/android-chrome-192x192.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 33 KiB |
BIN
changedetectionio/static/favicons/android-chrome-256x256.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
changedetectionio/static/favicons/apple-touch-icon.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 31 KiB |
9
changedetectionio/static/favicons/browserconfig.xml
Normal file
@@ -0,0 +1,9 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<browserconfig>
|
||||
<msapplication>
|
||||
<tile>
|
||||
<square150x150logo src="favicons/mstile-150x150.png"/>
|
||||
<TileColor>#da532c</TileColor>
|
||||
</tile>
|
||||
</msapplication>
|
||||
</browserconfig>
|
||||
BIN
changedetectionio/static/favicons/favicon-16x16.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
changedetectionio/static/favicons/favicon-32x32.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
changedetectionio/static/favicons/favicon.ico
Normal file
|
After Width: | Height: | Size: 12 KiB |
BIN
changedetectionio/static/favicons/mstile-150x150.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
35
changedetectionio/static/favicons/safari-pinned-tab.svg
Normal file
{kind=link}
@@ -0,0 +1,35 @@
|
||||
<?xml version="1.0" standalone="no"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20010904//EN"
|
||||
"http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd">
|
||||
<svg version="1.0" xmlns="http://www.w3.org/2000/svg"
|
||||
width="256.000000pt" height="256.000000pt" viewBox="0 0 256.000000 256.000000"
|
||||
preserveAspectRatio="xMidYMid meet">
|
||||
<metadata>
|
||||
Created by potrace 1.14, written by Peter Selinger 2001-2017
|
||||
</metadata>
|
||||
<g transform="translate(0.000000,256.000000) scale(0.100000,-0.100000)"
|
||||
fill="#000000" stroke="none">
|
||||
<path d="M0 1280 l0 -1280 1280 0 1280 0 0 1280 0 1280 -1280 0 -1280 0 0
|
||||
-1280z m1555 936 c387 -112 675 -426 741 -810 24 -138 15 -352 -20 -470 -106
|
||||
-353 -360 -606 -713 -712 -75 -22 -113 -27 -253 -31 -144 -5 -176 -2 -252 16
|
||||
-316 75 -564 271 -707 557 -67 136 -92 237 -98 401 -7 164 5 253 47 378 106
|
||||
315 349 556 665 659 114 37 180 45 350 41 125 -2 165 -7 240 -29z"/>
|
||||
<path d="M1091 2165 c-364 -82 -629 -328 -738 -682 -24 -80 -27 -103 -27 -258
|
||||
-1 -146 2 -182 21 -251 74 -271 259 -497 508 -621 477 -238 1061 -35 1294 450
|
||||
61 126 83 220 88 379 7 194 -15 307 -93 461 -126 251 -340 428 -614 507 -99
|
||||
29 -343 37 -439 15z m829 -473 c55 -54 100 -106 100 -116 0 -21 -184 -213
|
||||
-212 -222 -24 -7 -48 12 -48 38 0 11 26 47 58 80 l57 60 -151 -3 c-145 -4
|
||||
-152 -5 -190 -31 -22 -15 -78 -73 -124 -128 l-85 -99 -32 31 -32 31 30 38 c17
|
||||
22 70 79 117 128 66 67 97 92 127 100 22 6 106 11 188 11 81 0 147 3 147 8 0
|
||||
4 -25 31 -55 61 -55 55 -65 77 -43 99 25 25 50 10 148 -86z m-1002 -101 c46
|
||||
-24 141 -121 312 -321 203 -236 290 -330 322 -346 22 -11 60 -14 169 -12 l141
|
||||
3 -51 58 c-28 32 -51 64 -51 71 0 18 21 36 43 36 24 0 217 -193 217 -217 0
|
||||
-19 -185 -210 -212 -219 -24 -7 -48 12 -48 38 0 10 23 43 50 72 l50 53 -52 7
|
||||
c-29 3 -93 6 -142 6 -104 0 -152 12 -200 52 -19 15 -135 144 -258 286 -274
|
||||
316 -305 347 -354 361 -22 6 -94 11 -161 11 -67 0 -128 3 -137 6 -22 9 -21 61
|
||||
2 67 9 3 86 5 170 6 133 1 158 -2 190 -18z m227 -468 c23 -34 17 -43 -103
|
||||
-172 -119 -128 -131 -133 -343 -129 l-154 3 0 35 c0 34 1 35 50 42 28 3 96 7
|
||||
153 7 64 1 115 6 136 15 20 8 71 56 127 120 52 58 99 106 105 106 7 0 20 -12
|
||||
29 -27z"/>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 2.0 KiB |
19
changedetectionio/static/favicons/site.webmanifest
Normal file
@@ -0,0 +1,19 @@
|
||||
{
|
||||
"name": "",
|
||||
"short_name": "",
|
||||
"icons": [
|
||||
{
|
||||
"src": "android-chrome-192x192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
},
|
||||
{
|
||||
"src": "android-chrome-256x256.png",
|
||||
"sizes": "256x256",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"theme_color": "#ffffff",
|
||||
"background_color": "#ffffff",
|
||||
"display": "standalone"
|
||||
}
|
||||
BIN
changedetectionio/static/images/Playwright-icon.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.2 KiB |
4
changedetectionio/static/images/bell-off.svg
Normal file
{kind=link}
@@ -0,0 +1,4 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg width="15" height="16.363636" viewBox="0 0 15 16.363636" xmlns="http://www.w3.org/2000/svg" xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<path d="m 14.318182,11.762045 v 1.1925 H 5.4102273 L 11.849318,7.1140909 C 12.234545,9.1561364 12.54,11.181818 14.318182,11.762045 Z m -6.7984093,4.601591 c 1.0759091,0 2.0256823,-0.955909 2.0256823,-2.045454 H 5.4545455 c 0,1.089545 0.9879545,2.045454 2.0652272,2.045454 z M 15,2.8622727 0.9177273,15.636136 0,14.627045 l 1.8443182,-1.6725 h -1.1625 v -1.1925 C 4.0070455,10.677273 2.1784091,4.5388636 5.3611364,2.6897727 5.8009091,2.4347727 6.0709091,1.9609091 6.0702273,1.4488636 v -0.00205 C 6.0702273,0.64772727 6.7104545,0 7.5,0 8.2895455,0 8.9297727,0.64772727 8.9297727,1.4468182 v 0.00205 C 8.9290909,1.9602319 9.199773,2.4354591 9.638864,2.6897773 10.364318,3.111141 10.827273,3.7568228 11.1525,4.5129591 L 14.085682,1.8531818 Z M 6.8181818,1.3636364 C 6.8181818,1.74 7.1236364,2.0454545 7.5,2.0454545 7.8763636,2.0454545 8.1818182,1.74 8.1818182,1.3636364 8.1818182,0.98795455 7.8763636,0.68181818 7.5,0.68181818 c -0.3763636,0 -0.6818182,0.30613637 -0.6818182,0.68181822 z" id="path2" style="fill:#f8321b;stroke-width:0.681818;fill-opacity:1"/>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 1.2 KiB |
BIN
changedetectionio/static/images/beta-logo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
37
changedetectionio/static/images/email.svg
Normal file
{kind=link}
@@ -0,0 +1,37 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Uploaded to: SVG Repo, www.svgrepo.com, Generator: SVG Repo Mixer Tools -->
|
||||
|
||||
<svg
|
||||
fill="#FFFFFF"
|
||||
height="7.5005589"
|
||||
width="11.248507"
|
||||
version="1.1"
|
||||
id="Layer_1"
|
||||
viewBox="0 0 7.1975545 4.7993639"
|
||||
xml:space="preserve"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"><defs
|
||||
id="defs19" />
|
||||
<g
|
||||
id="g14"
|
||||
transform="matrix(-0.01406065,0,0,0.01406065,7.1975543,-1.1990922)">
|
||||
<g
|
||||
id="g12">
|
||||
<g
|
||||
id="g10">
|
||||
<path
|
||||
d="M 468.373,85.28 H 45.333 C 21.227,85.28 0,105.76 0,129.014 V 383.2 c 0,23.147 21.227,43.413 45.333,43.413 h 422.933 c 23.68,0 43.627,-19.84 43.627,-43.413 V 129.014 C 512,105.334 492.053,85.28 468.373,85.28 Z m 0,320 H 45.333 c -12.373,0 -24,-10.773 -24,-22.08 V 129.014 c 0,-11.307 11.84,-22.4 24,-22.4 h 422.933 c 11.733,0 22.293,10.667 22.293,22.4 V 383.2 h 0.107 c 10e-4,11.734 -10.453,22.08 -22.293,22.08 z"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 440.853,153.974 c -3.307,-4.907 -9.92,-6.187 -14.827,-2.987 L 256,264.48 85.973,151.094 c -4.907,-3.2 -11.52,-1.707 -14.72,3.2 -3.093,4.8 -1.813,11.307 2.88,14.507 l 176,117.333 c 3.627,2.347 8.213,2.347 11.84,0 l 176,-117.333 c 4.8,-3.201 6.187,-9.921 2.88,-14.827 z"
|
||||
id="path4" />
|
||||
<path
|
||||
d="m 143.573,257.654 c -0.107,0.107 -0.32,0.213 -0.427,0.32 L 68.48,311.307 c -4.907,3.307 -6.187,9.92 -2.88,14.827 3.307,4.907 9.92,6.187 14.827,2.88 0.107,-0.107 0.32,-0.213 0.427,-0.32 l 74.667,-53.333 c 4.907,-3.307 6.187,-9.92 2.88,-14.827 -3.308,-4.907 -9.921,-6.187 -14.828,-2.88 z"
|
||||
id="path6" />
|
||||
<path
|
||||
d="m 443.947,311.627 c -0.107,-0.107 -0.32,-0.213 -0.427,-0.32 l -74.667,-53.333 c -4.693,-3.52 -11.413,-2.56 -14.933,2.133 -3.52,4.693 -2.56,11.413 2.133,14.933 0.107,0.107 0.32,0.213 0.427,0.32 l 74.667,53.333 c 4.693,3.52 11.413,2.56 14.933,-2.133 3.52,-4.693 2.56,-11.413 -2.133,-14.933 z"
|
||||
id="path8" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 1.9 KiB |
|
Before Width: | Height: | Size: 31 KiB |
3
changedetectionio/static/images/generic-icon.svg
Normal file
{kind=link}
@@ -0,0 +1,3 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
<svg width="61.649mm" height="61.649mm" version="1.1" viewBox="0 0 61.649 61.649" xml:space="preserve" xmlns="http://www.w3.org/2000/svg"><g transform="translate(66.269 -15.463)" fill="#3056d3"><g transform="matrix(1.423 0 0 1.423 101.16 69.23)" fill="#3056d3"><g transform="matrix(.8229 0 0 .8229 -23.378 -2.3935)" fill="#3056d3"><path d="m-88.248-43.007a26.323 26.323 0 0 0-26.323 26.323 26.323 26.323 0 0 0 26.323 26.323 26.323 26.323 0 0 0 26.323-26.323 26.323 26.323 0 0 0-26.323-26.323zm0 2.8417a23.482 23.482 0 0 1 23.482 23.482 23.482 23.482 0 0 1-23.482 23.482 23.482 23.482 0 0 1-23.482-23.482 23.482 23.482 0 0 1 23.482-23.482z"/><g transform="matrix(.26458 0 0 .26458 -115.65 -44.085)"><path d="m33.02 64.43c0.35-0.05 2.04-0.13 2.04-0.13h25.53s3.17 0.32 3.67 0.53c2.5 1.05 3.98 1.89 6.04 3.57 0.72 0.58 4.12 4.01 4.12 4.01l51.67 57.39s1.61 1.65 1.97 1.94c1.2 0.97 2.48 1.96 3.98 2.32 0.5 0.12 2.72 0.21 2.72 0.21h27.32l-8.83-9.04s-1.31-1.65-1.44-1.94c-0.45-0.93-0.59-2.59-0.13-3.51 0.35-0.69 1.46-1.87 2.23-1.98 1.03-0.14 2.12-0.39 3.02 0.14 0.33 0.2 1.64 1.32 1.64 1.32l17.49 17.49s1.35 1.09 1.6 1.6c0.17 0.34 0.29 0.82 0.15 1.18-0.17 0.42-1.42 1.63-1.42 1.63l-0.94 0.98-15.69 16.37s-1.44 1.4-1.79 1.67c-0.76 0.6-1.99 0.89-2.96 0.9-1.03 0-2.62-1.11-3.26-1.91-0.6-0.76-1.1-2.22-0.77-3.13 0.16-0.45 1.28-1.85 1.28-1.85l11.36-11.3-29.47-0.02-1.68 0.09s-4.16-0.66-5.26-1.03c-1.63-0.56-3.44-1.82-4.75-2.93-0.39-0.33-1.8-1.92-1.8-1.92l-51.7-59.28s-2-2.06-2.43-2.43c-1.37-1.17-2-1.62-3.76-2.34-0.44-0.18-3.45-0.55-3.45-0.55l-24.13-0.22s-2.23-0.15-2.61-0.22c-1.08-0.21-2.16-1.07-2.81-1.83-0.79-0.92-0.59-3.06 0.06-4.09 0.57-0.89 2.14-1.52 3.19-1.66z"/><path d="m86.1 109.7-17.13 19.65s-2 2.06-2.43 2.43c-1.37 1.17-2 1.62-3.76 2.34-0.44 0.18-3.45 0.55-3.45 0.55l-24.13 0.22s-2.23 0.15-2.61 0.22c-1.08 0.21-2.16 1.07-2.81 1.83-0.79 0.92-0.59 3.06 0.06 4.09 0.57 0.89 2.14 1.52 3.19 1.66 0.35 0.05 2.04 0.13 2.04 0.13h25.53s3.17-0.32 3.67-0.53c2.5-1.05 3.98-1.89 6.04-3.57 0.72-0.58 4.12-4.01 4.12-4.01l17.38-19.3z"/><path d="m177.81 67.6c-0.17-0.42-1.42-1.63-1.42-1.63l-0.94-0.98-15.69-16.37s-1.44-1.4-1.79-1.67c-0.76-0.6-1.99-0.89-2.96-0.9-1.03 0-2.62 1.11-3.26 1.91-0.6 0.76-1.1 2.22-0.77 3.13 0.16 0.45 1.28 1.85 1.28 1.85l11.36 11.3-29.47 0.02-1.68-0.09s-4.16 0.66-5.26 1.03c-1.63 0.56-3.44 1.82-4.75 2.93-0.39 0.33-1.8 1.92-1.8 1.92l-18.91 21.69 5.98 5.98 18.38-20.41s1.61-1.65 1.97-1.94c1.2-0.97 2.48-1.96 3.98-2.32 0.5-0.12 2.72-0.21 2.72-0.21h27.32l-8.83 9.04s-1.31 1.65-1.44 1.94c-0.45 0.93-0.59 2.59-0.13 3.51 0.35 0.69 1.46 1.87 2.23 1.98 1.03 0.14 2.12 0.39 3.02-0.14 0.33-0.2 1.64-1.32 1.64-1.32l17.49-17.49s1.35-1.09 1.6-1.6c0.17-0.34 0.29-0.82 0.15-1.18z"/></g></g></g></g></svg>
|
||||
|
After Width: | Height: | Size: 2.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 43 KiB After Width: | Height: | Size: 22 KiB |
51
changedetectionio/static/images/notice.svg
Normal file
{kind=link}
@@ -0,0 +1,51 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
|
||||
<svg
|
||||
width="20.108334mm"
|
||||
height="21.43125mm"
|
||||
viewBox="0 0 20.108334 21.43125"
|
||||
version="1.1"
|
||||
id="svg5"
|
||||
xmlns:xlink="http://www.w3.org/1999/xlink"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs2" />
|
||||
<g
|
||||
id="layer1"
|
||||
transform="translate(-141.05873,-76.816635)">
|
||||
<image
|
||||
width="20.108334"
|
||||
height="21.43125"
|
||||
preserveAspectRatio="none"
|
||||
style="image-rendering:optimizeQuality"
|
||||
xlink:href="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEwAAABRCAYAAAB430BuAAAABHNCSVQICAgIfAhkiAAABLxJREFU
|
||||
eJztnN2Z2jgUhl8Z7petIGwF0WMXsFBBoIKwFWS2gmQryKSCJRXsTAUDBTDRVBCmgkAB9tkLexh+
|
||||
bIONLGwP7xU2RjafpaOjoyNBCxHNQAJEfG5sl+3ZLrAWeAyST5/sF91mFH3bRbZbsAq4ClaQq2B7
|
||||
iKYnmg9Z318F20ICRnj8pMOd6E3HscNVsATxmQD/oeghPCnDLO26q2AkYin+TQ7XREyyrn3zgu2J
|
||||
BSEjZTBZ179pwQ7EEv7KaoovvFnBUsV6ZHrsd+0WTHhKPV1SLGivYEsA1KEtEs2grFitRjQ65VxP
|
||||
fH5JgEjAKsvXupKwFfYxaYJeSeHcWqVSCuwD7/HQQD8lRHLWDStBWG3slbAElkTc5/lTZdkIJhpN
|
||||
h6/UUZDyzAgZK8PKVoEKErE8HlD0bBVcI2ZqwdBWYbFgAT+g1UZwrBbcvRyIpofHJ1Sh1rQCZt1k
|
||||
lN5msQAm8CoYoFF8KVHOsFtQ5aayExBUhpnopJl6J/3/FREGWCrxmaH40/4z1oyQ320Yf5dDozXC
|
||||
P4QMCRkCY4S5w/tbMTtd4L2Ngo6wJmSQ4hfdScAU+OjgGazgOXEl8oJyof3Z6Spx0iTzgnLKsMoK
|
||||
w9SRuoR3rHniVVMXwRpDXQR7d+kHOJV6CFZB0khVOBGsTcE6VzWsNVGQizfJptU+N4LlD3AbVfsu
|
||||
XsOahhvB8nrB08IrtcGNYNIct+EYl2+S6mr0D8kLUMrV6BfFRTzOGs4Ey8p1aNrUnssaliaMO/vV
|
||||
sfNi3AmW5j54DgUTO/dyJ1hab9iwHhLcNskP23ZMND0kewFBXek6vZvHg/hMiUPSN00z+OBasFig
|
||||
y8wSRfnZ0adSBz+sUVwFK4jbJhnPP06To1ETczpcCnavHhltHd82LU0AXDbJMGXBU8PSBAA8Jxk0
|
||||
wnNaqlGSJuAyg+dsXIV38iZqXU3iWsmodhetSNlDQgJGriZxbWVSe1hS/gQ+S/C6j4QEfES21vxU
|
||||
icXsoC4vC5mqJvbybyXgduucG/YWaYmmj+IdHvpoxFdt8ltRP5h3iZjRqfBh60C4t1rNY7rxAU95
|
||||
aYnhEp+/u8pgxGfeRCfyJIR5SkLfFOHYXMMzu63PEDF9WQnSo8MUmhduyUWYEzGyvnRmU3683ugG
|
||||
GAG/2bqJU4RnFDNCpsfWb5chswUnwb5Xg+hxiyo9w7MGJoSVpmYulam+A8scS+5nPYtf+s9mpZw7
|
||||
J1nayDnCVuu4Ck+E6DqIBYDHHR1+is/n8kVUhfBExMBFMzm4taafkXcWL9BSfBG/nNN8sutYcE3S
|
||||
d7XI3o6lSpIe/xcAIX/svzDxMVu22BAyLNKL2q9hwrdLiZWwXbP6B99GDLaGSpoOD6JPn4yxK1i8
|
||||
B0StY1zKsCJiQNxzQ0HRbAm2BsZN2TBDGVaE5USzIVjsNix2VrzWHmUwB6J5fD32uyKCzQ7OxG5D
|
||||
vzZuQ0E2osXjRlBMjvWe5WtYPE4b2BynXQJlMEToTUegmEiwM1mzQ1nBvqvH5ov1wlZHcA+AZHdc
|
||||
xQW7vNuQS9kBtzKs1IIRMM7b0q/YvGTzto4qbFutdV5FnLtLk2x3JVWUfXKTbIu9Opc2J6Osj19S
|
||||
HLfJKO64r6rg/wFBX3+2ZapW8wAAAABJRU5ErkJggg==
|
||||
"
|
||||
id="image832"
|
||||
x="141.05873"
|
||||
y="76.816635" />
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 2.4 KiB |
9
changedetectionio/static/images/pdf-icon.svg
Normal file
{kind=link}
@@ -0,0 +1,9 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" width="75.320129mm" height="92.604164mm" viewBox="0 0 75.320129 92.604164">
|
||||
<g transform="translate(53.548057 -183.975276) scale(1.4843)">
|
||||
<path fill="#ff2116" d="M-29.632812 123.94727c-3.551967 0-6.44336 2.89347-6.44336 6.44531v49.49804c0 3.55185 2.891393 6.44532 6.44336 6.44532H8.2167969c3.5519661 0 6.4433591-2.89335 6.4433591-6.44532v-40.70117s.101353-1.19181-.416015-2.35156c-.484969-1.08711-1.275391-1.84375-1.275391-1.84375a1.0584391 1.0584391 0 0 0-.0059-.008l-9.3906254-9.21094a1.0584391 1.0584391 0 0 0-.015625-.0156s-.8017392-.76344-1.9902344-1.27344c-1.39939552-.6005-2.8417968-.53711-2.8417968-.53711l.021484-.002z" color="#000" font-family="sans-serif" overflow="visible" paint-order="markers fill stroke" style="line-height:normal;font-variant-ligatures:normal;font-variant-position:normal;font-variant-caps:normal;font-variant-numeric:normal;font-variant-alternates:normal;font-feature-settings:normal;text-indent:0;text-align:start;text-decoration-line:none;text-decoration-style:solid;text-decoration-color:#000000;text-transform:none;text-orientation:mixed;white-space:normal;shape-padding:0;isolation:auto;mix-blend-mode:normal;solid-color:#000000;solid-opacity:1"/>
|
||||
<path fill="#f5f5f5" d="M-29.632812 126.06445h28.3789058a1.0584391 1.0584391 0 0 0 .021484 0s1.13480448.011 1.96484378.36719c.79889772.34282 1.36536982.86176 1.36914062.86524.0000125.00001.00391.004.00391.004l9.3671868 9.18945s.564354.59582.837891 1.20899c.220779.49491.234375 1.40039.234375 1.40039a1.0584391 1.0584391 0 0 0-.002.0449v40.74609c0 2.41592-1.910258 4.32813-4.3261717 4.32813H-29.632812c-2.415914 0-4.326172-1.91209-4.326172-4.32813v-49.49804c0-2.41603 1.910258-4.32813 4.326172-4.32813z" color="#000" font-family="sans-serif" overflow="visible" paint-order="markers fill stroke" style="line-height:normal;font-variant-ligatures:normal;font-variant-position:normal;font-variant-caps:normal;font-variant-numeric:normal;font-variant-alternates:normal;font-feature-settings:normal;text-indent:0;text-align:start;text-decoration-line:none;text-decoration-style:solid;text-decoration-color:#000000;text-transform:none;text-orientation:mixed;white-space:normal;shape-padding:0;isolation:auto;mix-blend-mode:normal;solid-color:#000000;solid-opacity:1"/>
|
||||
<path fill="#ff2116" d="M-23.40766 161.09299c-1.45669-1.45669.11934-3.45839 4.39648-5.58397l2.69124-1.33743 1.04845-2.29399c.57665-1.26169 1.43729-3.32036 1.91254-4.5748l.8641-2.28082-.59546-1.68793c-.73217-2.07547-.99326-5.19438-.52872-6.31588.62923-1.51909 2.69029-1.36323 3.50626.26515.63727 1.27176.57212 3.57488-.18329 6.47946l-.6193 2.38125.5455.92604c.30003.50932 1.1764 1.71867 1.9475 2.68743l1.44924 1.80272 1.8033728-.23533c5.72900399-.74758 7.6912472.523 7.6912472 2.34476 0 2.29921-4.4984914 2.48899-8.2760865-.16423-.8499666-.59698-1.4336605-1.19001-1.4336605-1.19001s-2.3665326.48178-3.531704.79583c-1.202707.32417-1.80274.52719-3.564509 1.12186 0 0-.61814.89767-1.02094 1.55026-1.49858 2.4279-3.24833 4.43998-4.49793 5.1723-1.3991.81993-2.86584.87582-3.60433.13733zm2.28605-.81668c.81883-.50607 2.47616-2.46625 3.62341-4.28553l.46449-.73658-2.11497 1.06339c-3.26655 1.64239-4.76093 3.19033-3.98386 4.12664.43653.52598.95874.48237 2.01093-.16792zm21.21809-5.95578c.80089-.56097.68463-1.69142-.22082-2.1472-.70466-.35471-1.2726074-.42759-3.1031574-.40057-1.1249.0767-2.9337647.3034-3.2403347.37237 0 0 .993716.68678 1.434896.93922.58731.33544 2.0145161.95811 3.0565161 1.27706 1.02785.31461 1.6224.28144 2.0729-.0409zm-8.53152-3.54594c-.4847-.50952-1.30889-1.57296-1.83152-2.3632-.68353-.89643-1.02629-1.52887-1.02629-1.52887s-.4996 1.60694-.90948 2.57394l-1.27876 3.16076-.37075.71695s1.971043-.64627 2.97389-.90822c1.0621668-.27744 3.21787-.70134 3.21787-.70134zm-2.74938-11.02573c.12363-1.0375.1761-2.07346-.15724-2.59587-.9246-1.01077-2.04057-.16787-1.85154 2.23517.0636.8084.26443 2.19033.53292 3.04209l.48817 1.54863.34358-1.16638c.18897-.64151.47882-2.02015.64411-3.06364z"/>
|
||||
<path fill="#2c2c2c" d="M-20.930423 167.83862h2.364986q1.133514 0 1.840213.2169.706698.20991 1.189489.9446.482795.72769.482795 1.75625 0 .94459-.391832 1.6233-.391833.67871-1.056548.97958-.65772.30087-2.02913.30087h-.818651v3.72941h-1.581322zm1.581322 1.22447v3.33058h.783664q1.049552 0 1.44838-.39184.405826-.39183.405826-1.27345 0-.65772-.265887-1.06355-.265884-.41282-.587747-.50378-.314866-.098-1.000572-.098zm5.50664-1.22447h2.148082q1.560333 0 2.4909318.55276.9375993.55276 1.4133973 1.6443.482791 1.09153.482791 2.42096 0 1.3994-.4338151 2.49793-.4268149 1.09153-1.3154348 1.76324-.8816233.67172-2.5189212.67172h-2.267031zm1.581326 1.26645v7.018h.657715q1.378411 0 2.001144-.9516.6227329-.95858.6227329-2.5539 0-3.5125-2.6238769-3.5125zm6.4722254-1.26645h5.30372941v1.26645H-4.2075842v2.85478h2.9807225v1.26646h-2.9807225v4.16322h-1.5813254z" font-family="Franklin Gothic Medium Cond" letter-spacing="0" style="line-height:125%;-inkscape-font-specification:'Franklin Gothic Medium Cond'" word-spacing="4.26000023"/>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 5.0 KiB |
122
changedetectionio/static/images/play.svg
Normal file
{kind=link}
@@ -0,0 +1,122 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
version="1.1"
|
||||
id="Capa_1"
|
||||
x="0px"
|
||||
y="0px"
|
||||
viewBox="0 0 15 14.998326"
|
||||
xml:space="preserve"
|
||||
width="15"
|
||||
height="14.998326"
|
||||
sodipodi:docname="play.svg"
|
||||
inkscape:version="1.1.1 (1:1.1+202109281949+c3084ef5ed)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"><sodipodi:namedview
|
||||
id="namedview21"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
inkscape:zoom="45.47174"
|
||||
inkscape:cx="7.4991632"
|
||||
inkscape:cy="7.4991632"
|
||||
inkscape:window-width="1554"
|
||||
inkscape:window-height="896"
|
||||
inkscape:window-x="3048"
|
||||
inkscape:window-y="227"
|
||||
inkscape:window-maximized="0"
|
||||
inkscape:current-layer="Capa_1" /><metadata
|
||||
id="metadata39"><rdf:RDF><cc:Work
|
||||
rdf:about=""><dc:format>image/svg+xml</dc:format><dc:type
|
||||
rdf:resource="http://purl.org/dc/dcmitype/StillImage" /></cc:Work></rdf:RDF></metadata><defs
|
||||
id="defs37" />
|
||||
<path
|
||||
id="path2"
|
||||
style="fill:#1b98f8;fill-opacity:1;stroke-width:0.0292893"
|
||||
d="M 7.4980469,0 C 4.5496028,-0.04093755 1.7047721,1.8547661 0.58789062,4.5800781 -0.57819305,7.2574082 0.02636631,10.583252 2.0703125,12.671875 4.0368718,14.788335 7.2754393,15.560096 9.9882812,14.572266 12.800219,13.617028 14.874915,10.855516 14.986328,7.8847656 15.172991,4.9968456 13.497714,2.109448 10.910156,0.8203125 9.858961,0.28011352 8.6796569,-0.00179908 7.4980469,0 Z"
|
||||
sodipodi:nodetypes="ccccccc" />
|
||||
<g
|
||||
id="g4"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g6"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g8"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g10"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g12"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g14"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g16"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g18"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g20"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g22"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g24"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g26"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g28"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g30"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g32"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<path
|
||||
sodipodi:type="star"
|
||||
style="fill:#ffffff;fill-opacity:1;stroke-width:37.7953;paint-order:stroke fill markers"
|
||||
id="path1203"
|
||||
inkscape:flatsided="false"
|
||||
sodipodi:sides="3"
|
||||
sodipodi:cx="7.2964563"
|
||||
sodipodi:cy="7.3240671"
|
||||
sodipodi:r1="3.805218"
|
||||
sodipodi:r2="1.9026089"
|
||||
sodipodi:arg1="-0.0017436774"
|
||||
sodipodi:arg2="1.0454539"
|
||||
inkscape:rounded="0"
|
||||
inkscape:randomized="0"
|
||||
d="M 11.101669,7.317432 8.2506324,8.9701135 5.3995964,10.622795 5.3938504,7.3273846 5.3881041,4.0319742 8.2448863,5.6747033 Z"
|
||||
inkscape:transform-center-x="-0.94843001"
|
||||
inkscape:transform-center-y="0.0033175346" /></svg>
|
||||
|
After Width: | Height: | Size: 3.5 KiB |
2
changedetectionio/static/images/price-tag-icon.svg
Normal file
{kind=link}
@@ -0,0 +1,2 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<svg width="83.39" height="89.648" enable-background="new 0 0 122.406 122.881" version="1.1" viewBox="0 0 83.39 89.648" xml:space="preserve" xmlns="http://www.w3.org/2000/svg"><g transform="translate(5e-4 -33.234)"><path d="m44.239 42.946-39.111 39.896 34.908 34.91 39.09-39.876-1.149-34.931zm-0.91791 42.273c0.979-0.979 1.507-1.99 1.577-3.027 0.077-1.043-0.248-2.424-0.967-4.135-0.725-1.717-1.348-3.346-1.87-4.885s-0.814-3.014-0.897-4.432c-0.07-1.42 0.134-2.768 0.624-4.045 0.477-1.279 1.348-2.545 2.607-3.804 2.099-2.099 4.535-3.123 7.314-3.065 2.773 0.063 5.457 1.158 8.04 3.294l2.881 3.034c1.946 2.607 2.799 5.33 2.557 8.166-0.235 2.83-1.532 5.426-3.893 7.785l-6.296-6.297c1.291-1.291 2.035-2.531 2.238-3.727 0.191-1.197-0.165-2.252-1.081-3.168-0.821-0.82-1.717-1.195-2.69-1.139-0.967 0.064-1.908 0.547-2.817 1.457-0.922 0.922-1.393 1.914-1.412 2.977s0.306 2.416 0.973 4.064c0.661 1.652 1.24 3.25 1.736 4.801 0.496 1.553 0.782 3.035 0.858 4.445 0.076 1.426-0.127 2.787-0.591 4.104-0.477 1.316-1.336 2.596-2.588 3.848-2.125 2.125-4.522 3.186-7.212 3.18s-5.311-1.063-7.855-3.16l-3.747 3.746-2.964-2.965 3.766-3.764c-2.423-2.996-3.568-5.998-3.447-9.02 0.127-3.014 1.476-5.813 4.045-8.383l6.278 6.277c-1.412 1.412-2.175 2.799-2.277 4.16-0.108 1.367 0.414 2.627 1.571 3.783 0.839 0.84 1.755 1.26 2.741 1.242 0.985-0.017 1.92-0.47 2.798-1.347zm21.127-46.435h17.457c-0.0269 2.2368 0.69936 16.025 0.69936 16.025l0.785 23.858c0.019 0.609-0.221 1.164-0.619 1.564l5e-3 4e-3 -41.236 42.022c-0.82213 0.8378-2.175 0.83-3.004 0l-37.913-37.91c-0.83-0.83-0.83-2.176 0-3.006l41.236-42.021c0.39287-0.42671 1.502-0.53568 1.502-0.53568zm18.011 11.59c-59.392-29.687-29.696-14.843 0 0z"/></g></svg>
|
||||
|
After Width: | Height: | Size: 1.7 KiB |
20
changedetectionio/static/images/spread-white.svg
Normal file
{kind=link}
@@ -0,0 +1,20 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
width="18"
|
||||
height="19.92"
|
||||
viewBox="0 0 18 19.92"
|
||||
version="1.1"
|
||||
id="svg6"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs10" />
|
||||
<path
|
||||
d="M -3,-2 H 21 V 22 H -3 Z"
|
||||
fill="none"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z"
|
||||
id="path4"
|
||||
style="fill:#ffffff;fill-opacity:1" />
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 892 B |
{kind=link}
@@ -1,46 +1,5 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
width="18"
|
||||
height="19.92"
|
||||
viewBox="0 0 18 19.92"
|
||||
version="1.1"
|
||||
id="svg6"
|
||||
sodipodi:docname="spread.svg"
|
||||
inkscape:version="1.1.1 (1:1.1+202109281949+c3084ef5ed)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs10" />
|
||||
<sodipodi:namedview
|
||||
id="namedview8"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
fit-margin-top="0"
|
||||
fit-margin-left="0"
|
||||
fit-margin-right="0"
|
||||
fit-margin-bottom="0"
|
||||
inkscape:zoom="28.416667"
|
||||
inkscape:cx="9.0087975"
|
||||
inkscape:cy="9.9941348"
|
||||
inkscape:window-width="1920"
|
||||
inkscape:window-height="1056"
|
||||
inkscape:window-x="1920"
|
||||
inkscape:window-y="0"
|
||||
inkscape:window-maximized="1"
|
||||
inkscape:current-layer="svg6" />
|
||||
<path
|
||||
d="M -3,-2 H 21 V 22 H -3 Z"
|
||||
fill="none"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z"
|
||||
id="path4"
|
||||
style="fill:#0078e7;fill-opacity:1" />
|
||||
<svg width="18" height="19.92" viewBox="0 0 18 19.92" xmlns="http://www.w3.org/2000/svg" xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<path d="M -3,-2 H 21 V 22 H -3 Z" fill="none" id="path2"/>
|
||||
<path d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z" id="path4" style="fill:#0078e7;fill-opacity:1"/>
|
||||
</svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 1.7 KiB After Width: | Height: | Size: 787 B |
454
changedetectionio/static/js/browser-steps.js
Normal file
@@ -0,0 +1,454 @@
|
||||
$(document).ready(function () {
|
||||
|
||||
// duplicate
|
||||
var csrftoken = $('input[name=csrf_token]').val();
|
||||
$.ajaxSetup({
|
||||
beforeSend: function (xhr, settings) {
|
||||
if (!/^(GET|HEAD|OPTIONS|TRACE)$/i.test(settings.type) && !this.crossDomain) {
|
||||
xhr.setRequestHeader("X-CSRFToken", csrftoken)
|
||||
}
|
||||
}
|
||||
})
|
||||
var browsersteps_session_id;
|
||||
var browserless_seconds_remaining = 0;
|
||||
var apply_buttons_disabled = false;
|
||||
var include_text_elements = $("#include_text_elements");
|
||||
var xpath_data = false;
|
||||
var current_selected_i;
|
||||
var state_clicked = false;
|
||||
var c;
|
||||
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
var last_click_xy = {'x': -1, 'y': -1}
|
||||
|
||||
$(window).resize(function () {
|
||||
set_scale();
|
||||
});
|
||||
// Should always be disabled
|
||||
$('#browser_steps >li:first-child select').val('Goto site').attr('disabled', 'disabled');
|
||||
|
||||
$('#browsersteps-click-start').click(function () {
|
||||
$("#browsersteps-click-start").fadeOut();
|
||||
$("#browsersteps-selector-wrapper .spinner").fadeIn();
|
||||
start();
|
||||
});
|
||||
|
||||
$('a#browsersteps-tab').click(function () {
|
||||
reset();
|
||||
});
|
||||
|
||||
window.addEventListener('hashchange', function () {
|
||||
if (window.location.hash == '#browser-steps') {
|
||||
reset();
|
||||
}
|
||||
});
|
||||
|
||||
function reset() {
|
||||
xpath_data = false;
|
||||
$('#browsersteps-img').removeAttr('src');
|
||||
$("#browsersteps-click-start").show();
|
||||
$("#browsersteps-selector-wrapper .spinner").hide();
|
||||
browserless_seconds_remaining = 0;
|
||||
browsersteps_session_id = false;
|
||||
apply_buttons_disabled = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
set_first_gotosite_disabled();
|
||||
}
|
||||
|
||||
function set_first_gotosite_disabled() {
|
||||
$('#browser_steps >li:first-child select').val('Goto site').attr('disabled', 'disabled');
|
||||
$('#browser_steps >li:first-child').css('opacity', '0.5');
|
||||
}
|
||||
|
||||
// Show seconds remaining until playwright/browserless needs to restart the session
|
||||
// (See comment at the top of changedetectionio/blueprint/browser_steps/__init__.py )
|
||||
setInterval(() => {
|
||||
if (browserless_seconds_remaining >= 1) {
|
||||
document.getElementById('browserless-seconds-remaining').innerText = browserless_seconds_remaining + " seconds remaining in session";
|
||||
browserless_seconds_remaining -= 1;
|
||||
}
|
||||
}, "1000")
|
||||
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
selector_image = $("img#browsersteps-img")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas and input steps the same size as the image
|
||||
$('#browsersteps-selector-canvas').attr('height', selector_image_rect.height).attr('width', selector_image_rect.width);
|
||||
//$('#browsersteps-selector-wrapper').attr('width', selector_image_rect.width);
|
||||
$('#browser-steps-ui').attr('width', selector_image_rect.width);
|
||||
|
||||
x_scale = selector_image_rect.width / xpath_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: " + x_scale + " by y:" + y_scale);
|
||||
}
|
||||
|
||||
// bootstrap it, this will trigger everything else
|
||||
$('#browsersteps-img').bind('load', function () {
|
||||
$('body').addClass('full-width');
|
||||
console.log("Loaded background...");
|
||||
|
||||
document.getElementById("browsersteps-selector-canvas");
|
||||
c = document.getElementById("browsersteps-selector-canvas");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
// @todo is click better?
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
// Undo disable_browsersteps_ui
|
||||
$("#browser-steps-ui").css('opacity', '1.0');
|
||||
|
||||
// init
|
||||
set_scale();
|
||||
|
||||
// @todo click ? some better library?
|
||||
$('#browsersteps-selector-canvas').bind('click', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
});
|
||||
|
||||
$('#browsersteps-selector-canvas').bind('mousedown', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
console.log(e);
|
||||
console.log("current xpath in index is " + current_selected_i);
|
||||
last_click_xy = {'x': parseInt((1 / x_scale) * e.offsetX), 'y': parseInt((1 / y_scale) * e.offsetY)}
|
||||
process_selected(current_selected_i);
|
||||
current_selected_i = false;
|
||||
|
||||
// if process selected returned false, then best we can do is offer a x,y click :(
|
||||
if (!found_something) {
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
$('select', first_available).val('Click X,Y').change();
|
||||
$('input[type=text]', first_available).first().val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
draw_circle_on_canvas(e.offsetX, e.offsetY);
|
||||
}
|
||||
});
|
||||
|
||||
$('#browsersteps-selector-canvas').bind('mousemove', function (e) {
|
||||
if (!xpath_data) {
|
||||
return;
|
||||
}
|
||||
|
||||
// checkbox if find elements is enabled
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
current_selected_i = false;
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
//$('#browsersteps-selector-canvas').css('cursor', 'pointer');
|
||||
for (var i = xpath_data['size_pos'].length; i !== 0; i--) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = xpath_data['size_pos'][i - 1];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
// Only highlight these interesting types
|
||||
if (1) {
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
current_selected_i = i - 1;
|
||||
break;
|
||||
|
||||
// find the smallest one at this x,y
|
||||
// does it mean sort the xpath list by size (w*h) i think so!
|
||||
} else {
|
||||
|
||||
if (include_text_elements[0].checked === true) {
|
||||
// blue one with background instead?
|
||||
ctx.fillStyle = 'rgba(0,0,255, 0.1)';
|
||||
ctx.strokeStyle = 'rgba(0,0,200, 0.7)';
|
||||
$('#browsersteps-selector-canvas').css('cursor', 'grab');
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
current_selected_i = i - 1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(10));
|
||||
});
|
||||
|
||||
// $("#browser-steps-fieldlist").bind('mouseover', function(e) {
|
||||
// console.log(e.xpath_data_index);
|
||||
// });
|
||||
|
||||
|
||||
// callback for clicking on an xpath on the canvas
|
||||
function process_selected(xpath_data_index) {
|
||||
found_something = false;
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
|
||||
|
||||
if (xpath_data_index !== false) {
|
||||
// Nothing focused, so fill in a new one
|
||||
// if inpt type button or <button>
|
||||
// from the top, find the next not used one and use it
|
||||
var x = xpath_data['size_pos'][xpath_data_index];
|
||||
console.log(x);
|
||||
if (x && first_available.length) {
|
||||
// @todo will it let you click shit that has a layer ontop? probably not.
|
||||
if (x['tagtype'] === 'text' || x['tagtype'] === 'email' || x['tagName'] === 'textarea' || x['tagtype'] === 'password' || x['tagtype'] === 'search') {
|
||||
$('select', first_available).val('Enter text in field').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
$('input[placeholder="Value"]', first_available).addClass('ok').click().focus();
|
||||
found_something = true;
|
||||
} else {
|
||||
if (x['isClickable'] || x['tagName'].startsWith('h') || x['tagName'] === 'a' || x['tagName'] === 'button' || x['tagtype'] === 'submit' || x['tagtype'] === 'checkbox' || x['tagtype'] === 'radio' || x['tagtype'] === 'li') {
|
||||
$('select', first_available).val('Click element').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
found_something = true;
|
||||
}
|
||||
}
|
||||
|
||||
first_available.xpath_data_index = xpath_data_index;
|
||||
|
||||
if (!found_something) {
|
||||
if (include_text_elements[0].checked === true) {
|
||||
// Suggest that we use as filter?
|
||||
// @todo filters should always be in the last steps, nothing non-filter after it
|
||||
found_something = true;
|
||||
ctx.strokeStyle = 'rgba(0,0,255, 0.9)';
|
||||
ctx.fillStyle = 'rgba(0,0,255, 0.1)';
|
||||
$('select', first_available).val('Extract text and use as filter').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
include_text_elements[0].checked = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function draw_circle_on_canvas(x, y) {
|
||||
ctx.beginPath();
|
||||
ctx.arc(x, y, 8, 0, 2 * Math.PI, false);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.6)';
|
||||
ctx.fill();
|
||||
}
|
||||
|
||||
function start() {
|
||||
console.log("Starting browser-steps UI");
|
||||
browsersteps_session_id = Date.now();
|
||||
// @todo This setting of the first one should be done at the datalayer but wtforms doesnt wanna play nice
|
||||
$('#browser_steps >li:first-child').removeClass('empty');
|
||||
set_first_gotosite_disabled();
|
||||
$('#browser-steps-ui .loader .spinner').show();
|
||||
$('.clear,.remove', $('#browser_steps >li:first-child')).hide();
|
||||
$.ajax({
|
||||
type: "GET",
|
||||
url: browser_steps_sync_url + "&browsersteps_session_id=" + browsersteps_session_id,
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
xpath_data = data.xpath_data;
|
||||
$("#loading-status-text").fadeIn();
|
||||
// This should trigger 'Goto site'
|
||||
console.log("Got startup response, requesting Goto-Site (first) step fake click");
|
||||
$('#browser_steps >li:first-child .apply').click();
|
||||
browserless_seconds_remaining = data.browser_time_remaining;
|
||||
set_first_gotosite_disabled();
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
alert('There was an error communicating with the server.');
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
function disable_browsersteps_ui() {
|
||||
set_first_gotosite_disabled();
|
||||
$("#browser-steps-ui").css('opacity', '0.3');
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
}
|
||||
|
||||
|
||||
////////////////////////// STEPS UI ////////////////////
|
||||
$('ul#browser_steps [type="text"]').keydown(function (e) {
|
||||
if (e.keyCode === 13) {
|
||||
// hitting [enter] in a browser-step input should trigger the 'Apply'
|
||||
e.preventDefault();
|
||||
$(".apply", $(this).closest('li')).click();
|
||||
return false;
|
||||
}
|
||||
});
|
||||
|
||||
// Look up which step was selected, and enable or disable the related extra fields
|
||||
// So that people using it dont' get confused
|
||||
$('ul#browser_steps select').on("change", function () {
|
||||
var config = browser_steps_config[$(this).val()].split(' ');
|
||||
var elem_selector = $('tr:nth-child(2) input', $(this).closest('tbody'));
|
||||
var elem_value = $('tr:nth-child(3) input', $(this).closest('tbody'));
|
||||
|
||||
if (config[0] == 0) {
|
||||
$(elem_selector).fadeOut();
|
||||
} else {
|
||||
$(elem_selector).fadeIn();
|
||||
}
|
||||
if (config[1] == 0) {
|
||||
$(elem_value).fadeOut();
|
||||
} else {
|
||||
$(elem_value).fadeIn();
|
||||
}
|
||||
|
||||
if ($(this).val() === 'Click X,Y' && last_click_xy['x'] > 0 && $(elem_value).val().length === 0) {
|
||||
// @todo handle scale
|
||||
$(elem_value).val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
}
|
||||
}).change();
|
||||
|
||||
function set_greyed_state() {
|
||||
$('ul#browser_steps select').not('option:selected[value="Choose one"]').closest('li').removeClass('empty');
|
||||
$('ul#browser_steps select option:selected[value="Choose one"]').closest('li').addClass('empty');
|
||||
}
|
||||
|
||||
// Add the extra buttons to the steps
|
||||
$('ul#browser_steps li').each(function (i) {
|
||||
var s = '<div class="control">' + '<a data-step-index=' + i + ' class="pure-button button-secondary button-green button-xsmall apply" >Apply</a> ';
|
||||
if (i > 0) {
|
||||
// The first step never gets these (Goto-site)
|
||||
s += '<a data-step-index=' + i + ' class="pure-button button-secondary button-xsmall clear" >Clear</a> ' +
|
||||
'<a data-step-index=' + i + ' class="pure-button button-secondary button-red button-xsmall remove" >Remove</a>';
|
||||
}
|
||||
s += '</div>';
|
||||
$(this).append(s)
|
||||
}
|
||||
);
|
||||
|
||||
$('ul#browser_steps li .control .clear').click(function (element) {
|
||||
$("select", $(this).closest('li')).val("Choose one").change();
|
||||
$(":text", $(this).closest('li')).val('');
|
||||
});
|
||||
|
||||
|
||||
$('ul#browser_steps li .control .remove').click(function (element) {
|
||||
// so you wanna remove the 2nd (3rd spot 0,1,2,...)
|
||||
var p = $("#browser_steps li").index($(this).closest('li'));
|
||||
|
||||
var elem_to_remove = $("#browser_steps li")[p];
|
||||
$('.clear', elem_to_remove).click();
|
||||
$("#browser_steps li").slice(p, 10).each(function (index) {
|
||||
// get the next one's value from where we clicked
|
||||
var next = $("#browser_steps li")[p + index + 1];
|
||||
if (next) {
|
||||
// and set THIS ones value from the next one
|
||||
var n = $('input', next);
|
||||
$("select", $(this)).val($('select', next).val());
|
||||
$('input', this)[0].value = $(n)[0].value;
|
||||
$('input', this)[1].value = $(n)[1].value;
|
||||
// Triggers reconfiguring the field based on the system config
|
||||
$("select", $(this)).change();
|
||||
}
|
||||
|
||||
});
|
||||
|
||||
// Reset their hidden/empty states
|
||||
set_greyed_state();
|
||||
});
|
||||
|
||||
$('ul#browser_steps li .control .apply').click(function (event) {
|
||||
// sequential requests @todo refactor
|
||||
if (apply_buttons_disabled) {
|
||||
return;
|
||||
}
|
||||
|
||||
var current_data = $(event.currentTarget).closest('li');
|
||||
$('#browser-steps-ui .loader .spinner').fadeIn();
|
||||
apply_buttons_disabled = true;
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 0.5);
|
||||
$("#browsersteps-img").css('opacity', 0.65);
|
||||
|
||||
var is_last_step = 0;
|
||||
var step_n = $(event.currentTarget).data('step-index');
|
||||
|
||||
// On the last step, we should also be getting data ready for the visual selector
|
||||
$('ul#browser_steps li select').each(function (i) {
|
||||
if ($(this).val() !== 'Choose one') {
|
||||
is_last_step += 1;
|
||||
}
|
||||
});
|
||||
|
||||
if (is_last_step == (step_n + 1)) {
|
||||
is_last_step = true;
|
||||
} else {
|
||||
is_last_step = false;
|
||||
}
|
||||
|
||||
console.log("Requesting step via POST " + $("select[id$='operation']", current_data).first().val());
|
||||
// POST the currently clicked step form widget back and await response, redraw
|
||||
$.ajax({
|
||||
method: "POST",
|
||||
url: browser_steps_sync_url + "&browsersteps_session_id=" + browsersteps_session_id,
|
||||
data: {
|
||||
'operation': $("select[id$='operation']", current_data).first().val(),
|
||||
'selector': $("input[id$='selector']", current_data).first().val(),
|
||||
'optional_value': $("input[id$='optional_value']", current_data).first().val(),
|
||||
'step_n': step_n,
|
||||
'is_last_step': is_last_step
|
||||
},
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
$("#loading-status-text").hide();
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
},
|
||||
401: function (data) {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert(data.responseText);
|
||||
$("#loading-status-text").hide();
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
// it should return the new state (selectors available and screenshot)
|
||||
xpath_data = data.xpath_data;
|
||||
$('#browsersteps-img').attr('src', data.screenshot);
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
apply_buttons_disabled = false;
|
||||
$("#browsersteps-img").css('opacity', 1);
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 1);
|
||||
browserless_seconds_remaining = data.browser_time_remaining;
|
||||
$("#loading-status-text").hide();
|
||||
set_first_gotosite_disabled();
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
if (data.responseText.includes("Browser session expired")) {
|
||||
disable_browsersteps_ui();
|
||||
}
|
||||
apply_buttons_disabled = false;
|
||||
$("#loading-status-text").hide();
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 1);
|
||||
$("#browsersteps-img").css('opacity', 1);
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
|
||||
$("ul#browser_steps select").change(function () {
|
||||
set_greyed_state();
|
||||
}).change();
|
||||
|
||||
});
|
||||
25
changedetectionio/static/js/diff-overview.js
Normal file
@@ -0,0 +1,25 @@
|
||||
$(document).ready(function () {
|
||||
// Load it when the #screenshot tab is in use, so we dont give a slow experience when waiting for the text diff to load
|
||||
window.addEventListener('hashchange', function (e) {
|
||||
toggle(location.hash);
|
||||
}, false);
|
||||
|
||||
toggle(location.hash);
|
||||
|
||||
function toggle(hash_name) {
|
||||
if (hash_name === '#screenshot') {
|
||||
$("img#screenshot-img").attr('src', screenshot_url);
|
||||
$("#settings").hide();
|
||||
} else if (hash_name === '#error-screenshot') {
|
||||
$("img#error-screenshot-img").attr('src', error_screenshot_url);
|
||||
$("#settings").hide();
|
||||
} else if (hash_name === '#extract') {
|
||||
$("#settings").hide();
|
||||
}
|
||||
|
||||
|
||||
else {
|
||||
$("#settings").show();
|
||||
}
|
||||
}
|
||||
});
|
||||
110
changedetectionio/static/js/diff-render.js
Normal file
@@ -0,0 +1,110 @@
|
||||
var a = document.getElementById("a");
|
||||
var b = document.getElementById("b");
|
||||
var result = document.getElementById("result");
|
||||
|
||||
function changed() {
|
||||
// https://github.com/kpdecker/jsdiff/issues/389
|
||||
// I would love to use `{ignoreWhitespace: true}` here but it breaks the formatting
|
||||
options = {
|
||||
ignoreWhitespace: document.getElementById("ignoreWhitespace").checked,
|
||||
};
|
||||
|
||||
var diff = Diff[window.diffType](a.textContent, b.textContent, options);
|
||||
var fragment = document.createDocumentFragment();
|
||||
for (var i = 0; i < diff.length; i++) {
|
||||
if (diff[i].added && diff[i + 1] && diff[i + 1].removed) {
|
||||
var swap = diff[i];
|
||||
diff[i] = diff[i + 1];
|
||||
diff[i + 1] = swap;
|
||||
}
|
||||
|
||||
var node;
|
||||
if (diff[i].removed) {
|
||||
node = document.createElement("del");
|
||||
node.classList.add("change");
|
||||
const wrapper = node.appendChild(document.createElement("span"));
|
||||
wrapper.appendChild(document.createTextNode(diff[i].value));
|
||||
} else if (diff[i].added) {
|
||||
node = document.createElement("ins");
|
||||
node.classList.add("change");
|
||||
const wrapper = node.appendChild(document.createElement("span"));
|
||||
wrapper.appendChild(document.createTextNode(diff[i].value));
|
||||
} else {
|
||||
node = document.createTextNode(diff[i].value);
|
||||
}
|
||||
fragment.appendChild(node);
|
||||
}
|
||||
|
||||
result.textContent = "";
|
||||
result.appendChild(fragment);
|
||||
|
||||
// Jump at start
|
||||
inputs.current = 0;
|
||||
next_diff();
|
||||
}
|
||||
|
||||
window.onload = function () {
|
||||
/* Convert what is options from UTC time.time() to local browser time */
|
||||
var diffList = document.getElementById("diff-version");
|
||||
if (typeof diffList != "undefined" && diffList != null) {
|
||||
for (var option of diffList.options) {
|
||||
var dateObject = new Date(option.value * 1000);
|
||||
option.label = dateObject.toLocaleString();
|
||||
}
|
||||
}
|
||||
|
||||
/* Set current version date as local time in the browser also */
|
||||
var current_v = document.getElementById("current-v-date");
|
||||
var dateObject = new Date(newest_version_timestamp * 1000);
|
||||
current_v.innerHTML = dateObject.toLocaleString();
|
||||
onDiffTypeChange(
|
||||
document.querySelector('#settings [name="diff_type"]:checked'),
|
||||
);
|
||||
changed();
|
||||
};
|
||||
|
||||
a.onpaste = a.onchange = b.onpaste = b.onchange = changed;
|
||||
|
||||
if ("oninput" in a) {
|
||||
a.oninput = b.oninput = changed;
|
||||
} else {
|
||||
a.onkeyup = b.onkeyup = changed;
|
||||
}
|
||||
|
||||
function onDiffTypeChange(radio) {
|
||||
window.diffType = radio.value;
|
||||
// Not necessary
|
||||
// document.title = "Diff " + radio.value.slice(4);
|
||||
}
|
||||
|
||||
var radio = document.getElementsByName("diff_type");
|
||||
for (var i = 0; i < radio.length; i++) {
|
||||
radio[i].onchange = function (e) {
|
||||
onDiffTypeChange(e.target);
|
||||
changed();
|
||||
};
|
||||
}
|
||||
|
||||
document.getElementById("ignoreWhitespace").onchange = function (e) {
|
||||
changed();
|
||||
};
|
||||
|
||||
var inputs = document.getElementsByClassName("change");
|
||||
inputs.current = 0;
|
||||
|
||||
function next_diff() {
|
||||
var element = inputs[inputs.current];
|
||||
var headerOffset = 80;
|
||||
var elementPosition = element.getBoundingClientRect().top;
|
||||
var offsetPosition = elementPosition - headerOffset + window.scrollY;
|
||||
|
||||
window.scrollTo({
|
||||
top: offsetPosition,
|
||||
behavior: "smooth",
|
||||
});
|
||||
|
||||
inputs.current++;
|
||||
if (inputs.current >= inputs.length) {
|
||||
inputs.current = 0;
|
||||
}
|
||||
}
|
||||
38
changedetectionio/static/js/diff.min.js
vendored
Normal file
56
changedetectionio/static/js/limit.js
Normal file
@@ -0,0 +1,56 @@
|
||||
/**
|
||||
* debounce
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait after the last call before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds after the last call before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.debounce = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
timer = null,
|
||||
wait = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments;
|
||||
|
||||
function complete() {
|
||||
baseFunction.apply(self, args);
|
||||
timer = null;
|
||||
}
|
||||
|
||||
if (timer) {
|
||||
clearTimeout(timer);
|
||||
}
|
||||
|
||||
timer = setTimeout(complete, wait);
|
||||
};
|
||||
};
|
||||
|
||||
/**
|
||||
* throttle
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait between calls before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds between calls before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.throttle = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
lastEventTimestamp = null,
|
||||
limit = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments,
|
||||
now = Date.now();
|
||||
|
||||
if (!lastEventTimestamp || now - lastEventTimestamp >= limit) {
|
||||
lastEventTimestamp = now;
|
||||
baseFunction.apply(self, args);
|
||||
}
|
||||
};
|
||||
};
|
||||
@@ -26,9 +26,6 @@ $(document).ready(function() {
|
||||
data = {
|
||||
window_url : window.location.href,
|
||||
notification_urls : $('.notification-urls').val(),
|
||||
notification_title : $('.notification-title').val(),
|
||||
notification_body : $('.notification-body').val(),
|
||||
notification_format : $('.notification-format').val(),
|
||||
}
|
||||
for (key in data) {
|
||||
if (!data[key].length) {
|
||||
@@ -40,13 +37,19 @@ $(document).ready(function() {
|
||||
$.ajax({
|
||||
type: "POST",
|
||||
url: notification_base_url,
|
||||
data : data
|
||||
data : data,
|
||||
statusCode: {
|
||||
400: function() {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
}).done(function(data){
|
||||
console.log(data);
|
||||
alert('Sent');
|
||||
}).fail(function(data){
|
||||
console.log(data);
|
||||
alert('Error: '+data.responseJSON.error);
|
||||
alert('There was an error communicating with the server.');
|
||||
})
|
||||
});
|
||||
});
|
||||
|
||||
34
changedetectionio/static/js/stepper.js
Normal file
@@ -0,0 +1,34 @@
|
||||
$(document).ready(function(){
|
||||
checkUserVal();
|
||||
$('#fetch_backend input').on('change', checkUserVal);
|
||||
});
|
||||
|
||||
var checkUserVal = function(){
|
||||
if($('#fetch_backend input:checked').val()=='html_requests') {
|
||||
$('#request-override').show();
|
||||
$('#webdriver-stepper').hide();
|
||||
} else {
|
||||
$('#request-override').hide();
|
||||
$('#webdriver-stepper').show();
|
||||
}
|
||||
};
|
||||
|
||||
$('a.row-options').on('click', function(){
|
||||
var row=$(this.closest('tr'));
|
||||
switch($(this).data("action")) {
|
||||
case 'remove':
|
||||
$(row).remove();
|
||||
break;
|
||||
case 'add':
|
||||
var new_row=$(row).clone(true).insertAfter($(row));
|
||||
$('input', new_new).val("");
|
||||
break;
|
||||
case 'add':
|
||||
var new_row=$(row).clone(true).insertAfter($(row));
|
||||
$('input', new_new).val("");
|
||||
break;
|
||||
case 'resend-step':
|
||||
|
||||
break;
|
||||
}
|
||||
});
|
||||
@@ -1,55 +1,49 @@
|
||||
// Rewrite this is a plugin.. is all this JS really 'worth it?'
|
||||
|
||||
|
||||
if(!window.location.hash) {
|
||||
var tab=document.querySelectorAll("#default-tab a");
|
||||
tab[0].click();
|
||||
}
|
||||
|
||||
window.addEventListener('hashchange', function() {
|
||||
var tabs = document.getElementsByClassName('active');
|
||||
while (tabs[0]) {
|
||||
tabs[0].classList.remove('active')
|
||||
}
|
||||
set_active_tab();
|
||||
window.addEventListener('hashchange', function () {
|
||||
var tabs = document.getElementsByClassName('active');
|
||||
while (tabs[0]) {
|
||||
tabs[0].classList.remove('active');
|
||||
document.body.classList.remove('full-width');
|
||||
}
|
||||
set_active_tab();
|
||||
}, false);
|
||||
|
||||
var has_errors=document.querySelectorAll(".messages .error");
|
||||
var has_errors = document.querySelectorAll(".messages .error");
|
||||
if (!has_errors.length) {
|
||||
if (document.location.hash == "" ) {
|
||||
document.location.hash = "#general";
|
||||
document.getElementById("default-tab").className = "active";
|
||||
if (document.location.hash == "") {
|
||||
location.replace(document.querySelector(".tabs ul li:first-child a").hash);
|
||||
} else {
|
||||
set_active_tab();
|
||||
}
|
||||
} else {
|
||||
focus_error_tab();
|
||||
focus_error_tab();
|
||||
}
|
||||
|
||||
function set_active_tab() {
|
||||
var tab=document.querySelectorAll("a[href='"+location.hash+"']");
|
||||
if (tab.length) {
|
||||
tab[0].parentElement.className="active";
|
||||
}
|
||||
document.body.classList.remove('full-width');
|
||||
var tab = document.querySelectorAll("a[href='" + location.hash + "']");
|
||||
if (tab.length) {
|
||||
tab[0].parentElement.className = "active";
|
||||
}
|
||||
// hash could move the page down
|
||||
window.scrollTo(0, 0);
|
||||
}
|
||||
|
||||
function focus_error_tab() {
|
||||
// time to use jquery or vuejs really,
|
||||
// activate the tab with the error
|
||||
var tabs = document.querySelectorAll('.tabs li a'),i;
|
||||
// time to use jquery or vuejs really,
|
||||
// activate the tab with the error
|
||||
var tabs = document.querySelectorAll('.tabs li a'), i;
|
||||
for (i = 0; i < tabs.length; ++i) {
|
||||
var tab_name=tabs[i].hash.replace('#','');
|
||||
var pane_errors=document.querySelectorAll('#'+tab_name+' .error')
|
||||
if (pane_errors.length) {
|
||||
document.location.hash = '#'+tab_name;
|
||||
return true;
|
||||
}
|
||||
var tab_name = tabs[i].hash.replace('#', '');
|
||||
var pane_errors = document.querySelectorAll('#' + tab_name + ' .error')
|
||||
if (pane_errors.length) {
|
||||
document.location.hash = '#' + tab_name;
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
24
changedetectionio/static/js/toggle-theme.js
Normal file
@@ -0,0 +1,24 @@
|
||||
/**
|
||||
* @file
|
||||
* Toggles theme between light and dark mode.
|
||||
*/
|
||||
$(document).ready(function () {
|
||||
const button = document.getElementsByClassName("toggle-theme")[0];
|
||||
|
||||
button.onclick = () => {
|
||||
const htmlElement = document.getElementsByTagName("html");
|
||||
const isDarkMode = htmlElement[0].dataset.darkmode === "true";
|
||||
htmlElement[0].dataset.darkmode = !isDarkMode;
|
||||
if (isDarkMode) {
|
||||
button.classList.remove("dark");
|
||||
setCookieValue(false);
|
||||
} else {
|
||||
button.classList.add("dark");
|
||||
setCookieValue(true);
|
||||
}
|
||||
};
|
||||
|
||||
const setCookieValue = (value) => {
|
||||
document.cookie = `css_dark_mode=${value};max-age=31536000;path=/`
|
||||
}
|
||||
});
|
||||
244
changedetectionio/static/js/visual-selector.js
Normal file
@@ -0,0 +1,244 @@
|
||||
// Copyright (C) 2021 Leigh Morresi (dgtlmoon@gmail.com)
|
||||
// All rights reserved.
|
||||
// yes - this is really a hack, if you are a front-ender and want to help, please get in touch!
|
||||
|
||||
$(document).ready(function () {
|
||||
|
||||
var current_selected_i;
|
||||
var state_clicked = false;
|
||||
|
||||
var c;
|
||||
|
||||
// greyed out fill context
|
||||
var xctx;
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
|
||||
var current_default_xpath = [];
|
||||
var x_scale = 1;
|
||||
var y_scale = 1;
|
||||
var selector_image;
|
||||
var selector_image_rect;
|
||||
var selector_data;
|
||||
|
||||
$('#visualselector-tab').click(function () {
|
||||
$("img#selector-background").off('load');
|
||||
state_clicked = false;
|
||||
current_selected_i = false;
|
||||
bootstrap_visualselector();
|
||||
});
|
||||
|
||||
$(document).on('keydown', function (event) {
|
||||
if ($("img#selector-background").is(":visible")) {
|
||||
if (event.key == "Escape") {
|
||||
state_clicked = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
// For when the page loads
|
||||
if (!window.location.hash || window.location.hash != '#visualselector') {
|
||||
$("img#selector-background").attr('src', '');
|
||||
return;
|
||||
}
|
||||
|
||||
// Handle clearing button/link
|
||||
$('#clear-selector').on('click', function (event) {
|
||||
if (!state_clicked) {
|
||||
alert('Oops, Nothing selected!');
|
||||
}
|
||||
state_clicked = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
xctx.clearRect(0, 0, c.width, c.height);
|
||||
$("#include_filters").val('');
|
||||
});
|
||||
|
||||
|
||||
bootstrap_visualselector();
|
||||
|
||||
|
||||
function bootstrap_visualselector() {
|
||||
if (1) {
|
||||
// bootstrap it, this will trigger everything else
|
||||
$("img#selector-background").bind('load', function () {
|
||||
console.log("Loaded background...");
|
||||
c = document.getElementById("selector-canvas");
|
||||
// greyed out fill context
|
||||
xctx = c.getContext("2d");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
if ($("#include_filters").val().trim().length) {
|
||||
current_default_xpath = $("#include_filters").val().split(/\r?\n/g);
|
||||
} else {
|
||||
current_default_xpath = [];
|
||||
}
|
||||
fetch_data();
|
||||
$('#selector-canvas').off("mousemove mousedown");
|
||||
// screenshot_url defined in the edit.html template
|
||||
}).attr("src", screenshot_url);
|
||||
}
|
||||
// Tell visualSelector that the image should update
|
||||
var s = $("img#selector-background").attr('src')+"?"+ new Date().getTime();
|
||||
$("img#selector-background").attr('src',s)
|
||||
}
|
||||
|
||||
function fetch_data() {
|
||||
// Image is ready
|
||||
$('.fetching-update-notice').html("Fetching element data..");
|
||||
|
||||
$.ajax({
|
||||
url: watch_visual_selector_data_url,
|
||||
context: document.body
|
||||
}).done(function (data) {
|
||||
$('.fetching-update-notice').html("Rendering..");
|
||||
selector_data = data;
|
||||
console.log("Reported browser width from backend: " + data['browser_width']);
|
||||
state_clicked = false;
|
||||
set_scale();
|
||||
reflow_selector();
|
||||
$('.fetching-update-notice').fadeOut();
|
||||
});
|
||||
};
|
||||
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
$("#selector-wrapper").show();
|
||||
selector_image = $("img#selector-background")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas the same size as the image
|
||||
$('#selector-canvas').attr('height', selector_image_rect.height);
|
||||
$('#selector-canvas').attr('width', selector_image_rect.width);
|
||||
$('#selector-wrapper').attr('width', selector_image_rect.width);
|
||||
x_scale = selector_image_rect.width / selector_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: " + x_scale + " by y:" + y_scale);
|
||||
$("#selector-current-xpath").css('max-width', selector_image_rect.width);
|
||||
}
|
||||
|
||||
function reflow_selector() {
|
||||
$(window).resize(function () {
|
||||
set_scale();
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
var selector_currnt_xpath_text = $("#selector-current-xpath span");
|
||||
|
||||
set_scale();
|
||||
|
||||
console.log(selector_data['size_pos'].length + " selectors found");
|
||||
|
||||
// highlight the default one if we can find it in the xPath list
|
||||
// or the xpath matches the default one
|
||||
found = false;
|
||||
if (current_default_xpath.length) {
|
||||
// Find the first one that matches
|
||||
// @todo In the future paint all that match
|
||||
for (const c of current_default_xpath) {
|
||||
for (var i = selector_data['size_pos'].length; i !== 0; i--) {
|
||||
if (selector_data['size_pos'][i - 1].xpath === c) {
|
||||
console.log("highlighting " + c);
|
||||
current_selected_i = i - 1;
|
||||
highlight_current_selected_i();
|
||||
found = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (found) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (!found) {
|
||||
alert("Unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousemove', function (e) {
|
||||
if (state_clicked) {
|
||||
return;
|
||||
}
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
current_selected_i = null;
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var found = 0;
|
||||
ctx.fillStyle = 'rgba(205,0,0,0.35)';
|
||||
// Will be sorted by smallest width*height first
|
||||
for (var i = 0; i <= selector_data['size_pos'].length; i++) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = selector_data['size_pos'][i];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
|
||||
// FOUND ONE
|
||||
set_current_selected_text(sel.xpath);
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
|
||||
// no need to keep digging
|
||||
// @todo or, O to go out/up, I to go in
|
||||
// or double click to go up/out the selector?
|
||||
current_selected_i = i;
|
||||
found += 1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(5));
|
||||
|
||||
function set_current_selected_text(s) {
|
||||
selector_currnt_xpath_text[0].innerHTML = s;
|
||||
}
|
||||
|
||||
function highlight_current_selected_i() {
|
||||
if (state_clicked) {
|
||||
state_clicked = false;
|
||||
xctx.clearRect(0, 0, c.width, c.height);
|
||||
return;
|
||||
}
|
||||
|
||||
var sel = selector_data['size_pos'][current_selected_i];
|
||||
if (sel[0] == '/') {
|
||||
// @todo - not sure just checking / is right
|
||||
$("#include_filters").val('xpath:' + sel.xpath);
|
||||
} else {
|
||||
$("#include_filters").val(sel.xpath);
|
||||
}
|
||||
xctx.fillStyle = 'rgba(205,205,205,0.95)';
|
||||
xctx.strokeStyle = 'rgba(225,0,0,0.9)';
|
||||
xctx.lineWidth = 3;
|
||||
xctx.fillRect(0, 0, c.width, c.height);
|
||||
// Clear out what only should be seen (make a clear/clean spot)
|
||||
xctx.clearRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
xctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
state_clicked = true;
|
||||
set_current_selected_text(sel.xpath);
|
||||
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousedown', function (e) {
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
}
|
||||
|
||||
});
|
||||
@@ -4,6 +4,7 @@ $(function () {
|
||||
$(this).closest('.unviewed').removeClass('unviewed');
|
||||
});
|
||||
|
||||
|
||||
$('.with-share-link > *').click(function () {
|
||||
$("#copied-clipboard").remove();
|
||||
|
||||
@@ -20,5 +21,19 @@ $(function () {
|
||||
$(this).remove();
|
||||
});
|
||||
});
|
||||
|
||||
// checkboxes - check all
|
||||
$("#check-all").click(function (e) {
|
||||
$('input[type=checkbox]').not(this).prop('checked', this.checked);
|
||||
});
|
||||
// checkboxes - show/hide buttons
|
||||
$("input[type=checkbox]").click(function (e) {
|
||||
if ($('input[type=checkbox]:checked').length) {
|
||||
$('#checkbox-operations').slideDown();
|
||||
} else {
|
||||
$('#checkbox-operations').slideUp();
|
||||
}
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
|
||||
@@ -1,16 +1,45 @@
|
||||
$(document).ready(function() {
|
||||
$(document).ready(function () {
|
||||
function toggle() {
|
||||
if ($('input[name="fetch_backend"]:checked').val() != 'html_requests') {
|
||||
$('#requests-override-options').hide();
|
||||
if ($('input[name="fetch_backend"]:checked').val() == 'html_webdriver') {
|
||||
if (playwright_enabled) {
|
||||
// playwright supports headers, so hide everything else
|
||||
// See #664
|
||||
$('#requests-override-options #request-method').hide();
|
||||
$('#requests-override-options #request-body').hide();
|
||||
|
||||
// @todo connect this one up
|
||||
$('#ignore-status-codes-option').hide();
|
||||
} else {
|
||||
// selenium/webdriver doesnt support anything afaik, hide it all
|
||||
$('#requests-override-options').hide();
|
||||
}
|
||||
|
||||
$('#webdriver-override-options').show();
|
||||
|
||||
} else if ($('input[name="fetch_backend"]:checked').val() == 'system') {
|
||||
$('#requests-override-options #request-method').hide();
|
||||
$('#requests-override-options #request-body').hide();
|
||||
$('#ignore-status-codes-option').hide();
|
||||
$('#requests-override-options').hide();
|
||||
$('#webdriver-override-options').hide();
|
||||
} else {
|
||||
|
||||
$('#requests-override-options').show();
|
||||
$('#requests-override-options *:hidden').show();
|
||||
$('#webdriver-override-options').hide();
|
||||
}
|
||||
}
|
||||
|
||||
$('input[name="fetch_backend"]').click(function (e) {
|
||||
toggle();
|
||||
});
|
||||
toggle();
|
||||
|
||||
$('#notification-setting-reset-to-default').click(function (e) {
|
||||
$('#notification_title').val('');
|
||||
$('#notification_body').val('');
|
||||
$('#notification_format').val('System default');
|
||||
$('#notification_urls').val('');
|
||||
e.preventDefault();
|
||||
});
|
||||
});
|
||||
|
||||
3
changedetectionio/static/styles/.dockerignore
Normal file
@@ -0,0 +1,3 @@
|
||||
node_modules
|
||||
package-lock.json
|
||||
|
||||
2
changedetectionio/static/styles/.gitignore
vendored
@@ -1 +1,3 @@
|
||||
node_modules
|
||||
package-lock.json
|
||||
|
||||
|
||||
@@ -1,10 +1,148 @@
|
||||
/**
|
||||
* CSS custom properties (aka variables).
|
||||
*/
|
||||
:root {
|
||||
--color-white: #fff;
|
||||
--color-grey-50: #111;
|
||||
--color-grey-100: #262626;
|
||||
--color-grey-200: #333;
|
||||
--color-grey-300: #444;
|
||||
--color-grey-325: #555;
|
||||
--color-grey-350: #565d64;
|
||||
--color-grey-400: #666;
|
||||
--color-grey-500: #777;
|
||||
--color-grey-600: #999;
|
||||
--color-grey-700: #cbcbcb;
|
||||
--color-grey-750: #ddd;
|
||||
--color-grey-800: #e0e0e0;
|
||||
--color-grey-850: #eee;
|
||||
--color-grey-900: #f2f2f2;
|
||||
--color-black: #000;
|
||||
--color-dark-red: #a00;
|
||||
--color-light-red: #dd0000;
|
||||
--color-background-page: var(--color-grey-100);
|
||||
--color-background-gradient-first: #5ad8f7;
|
||||
--color-background-gradient-second: #2f50af;
|
||||
--color-background-gradient-third: #9150bf;
|
||||
--color-background: var(--color-white);
|
||||
--color-text: var(--color-grey-200);
|
||||
--color-link: #1b98f8;
|
||||
--color-menu-accent: #ed5900;
|
||||
--color-background-code: var(--color-grey-850);
|
||||
--color-error: var(--color-dark-red);
|
||||
--color-error-input: #ffebeb;
|
||||
--color-error-list: var(--color-light-red);
|
||||
--color-table-background: var(--color-background);
|
||||
--color-table-stripe: var(--color-grey-900);
|
||||
--color-text-tab: var(--color-white);
|
||||
--color-background-tab: rgba(255, 255, 255, 0.2);
|
||||
--color-background-tab-hover: rgba(255, 255, 255, 0.5);
|
||||
--color-text-tab-active: #222;
|
||||
--color-api-key: #0078e7;
|
||||
--color-background-button-primary: #0078e7;
|
||||
--color-background-button-green: #42dd53;
|
||||
--color-background-button-red: #dd4242;
|
||||
--color-background-button-success: rgb(28, 184, 65);
|
||||
--color-background-button-error: rgb(202, 60, 60);
|
||||
--color-text-button-error: var(--color-white);
|
||||
--color-background-button-warning: rgb(202, 60, 60);
|
||||
--color-text-button-warning: var(--color-white);
|
||||
--color-background-button-secondary: rgb(66, 184, 221);
|
||||
--color-background-button-cancel: rgb(200, 200, 200);
|
||||
--color-text-button: var(--color-white);
|
||||
--color-background-button-tag: rgb(99, 99, 99);
|
||||
--color-background-snapshot-age: #dfdfdf;
|
||||
--color-error-text-snapshot-age: var(--color-white);
|
||||
--color-error-background-snapshot-age: #ff0000;
|
||||
--color-background-button-tag-active: #9c9c9c;
|
||||
--color-text-messages: var(--color-white);
|
||||
--color-background-messages-message: rgba(255, 255, 255, .2);
|
||||
--color-background-messages-error: rgba(255, 1, 1, .5);
|
||||
--color-background-messages-notice: rgba(255, 255, 255, .5);
|
||||
--color-border-notification: #ccc;
|
||||
--color-background-checkbox-operations: rgba(0, 0, 0, 0.05);
|
||||
--color-warning: #ff3300;
|
||||
--color-border-warning: var(--color-warning);
|
||||
--color-text-legend: var(--color-white);
|
||||
--color-link-new-version: #e07171;
|
||||
--color-last-checked: #bbb;
|
||||
--color-text-footer: #444;
|
||||
--color-border-watch-table-cell: #eee;
|
||||
--color-text-watch-tag-list: #e70069;
|
||||
--color-background-new-watch-form: rgba(0, 0, 0, 0.05);
|
||||
--color-background-new-watch-input: var(--color-white);
|
||||
--color-text-new-watch-input: var(--color-text);
|
||||
--color-border-input: var(--color-grey-500);
|
||||
--color-shadow-input: var(--color-grey-400);
|
||||
--color-background-input: var(--color-white);
|
||||
--color-text-input: var(--color-text);
|
||||
--color-text-input-description: var(--color-grey-500);
|
||||
--color-text-input-placeholder: var(--color-grey-600);
|
||||
--color-background-table-thead: var(--color-grey-800);
|
||||
--color-border-table-cell: var(--color-grey-700);
|
||||
--color-text-menu-heading: var(--color-grey-350);
|
||||
--color-text-menu-link: var(--color-grey-500);
|
||||
--color-background-menu-link-hover: var(--color-grey-850);
|
||||
--color-text-menu-link-hover: var(--color-grey-300);
|
||||
--color-shadow-jump: var(--color-grey-500);
|
||||
--color-icon-github: var(--color-black);
|
||||
--color-icon-github-hover: var(--color-grey-300);
|
||||
--color-watch-table-error: var(--color-dark-red);
|
||||
--color-watch-table-row-text: var(--color-grey-100); }
|
||||
|
||||
html[data-darkmode="true"] {
|
||||
--color-link: #59bdfb;
|
||||
--color-text: var(--color-white);
|
||||
--color-background-gradient-first: #3f90a5;
|
||||
--color-background-gradient-second: #1e316c;
|
||||
--color-background-gradient-third: #4d2c64;
|
||||
--color-background-new-watch-input: var(--color-grey-100);
|
||||
--color-text-new-watch-input: var(--color-text);
|
||||
--color-background-table-thead: var(--color-grey-200);
|
||||
--color-table-background: var(--color-grey-300);
|
||||
--color-table-stripe: var(--color-grey-325);
|
||||
--color-background: var(--color-grey-300);
|
||||
--color-text-menu-heading: var(--color-grey-850);
|
||||
--color-text-menu-link: var(--color-grey-800);
|
||||
--color-border-table-cell: var(--color-grey-400);
|
||||
--color-text-tab-active: var(--color-text);
|
||||
--color-border-input: var(--color-grey-400);
|
||||
--color-shadow-input: var(--color-grey-50);
|
||||
--color-background-input: var(--color-grey-350);
|
||||
--color-text-input-description: var(--color-grey-600);
|
||||
--color-text-input-placeholder: var(--color-grey-600);
|
||||
--color-text-watch-tag-list: #fa3e92;
|
||||
--color-background-code: var(--color-grey-200);
|
||||
--color-background-tab: rgba(0, 0, 0, 0.2);
|
||||
--color-background-tab-hover: rgba(0, 0, 0, 0.5);
|
||||
--color-background-snapshot-age: var(--color-grey-200);
|
||||
--color-shadow-jump: var(--color-grey-200);
|
||||
--color-icon-github: var(--color-white);
|
||||
--color-icon-github-hover: var(--color-grey-700);
|
||||
--color-watch-table-error: var(--color-light-red);
|
||||
--color-watch-table-row-text: var(--color-grey-800); }
|
||||
html[data-darkmode="true"] .icon-spread {
|
||||
filter: hue-rotate(-10deg) brightness(1.5); }
|
||||
html[data-darkmode="true"] .watch-table .title-col a[target="_blank"]::after,
|
||||
html[data-darkmode="true"] .watch-table .current-diff-url::after {
|
||||
filter: invert(0.5) hue-rotate(10deg) brightness(2); }
|
||||
html[data-darkmode="true"] .watch-table .watch-controls .state-off img {
|
||||
opacity: 0.3; }
|
||||
html[data-darkmode="true"] .watch-table .watch-controls .state-on img {
|
||||
opacity: 1.0; }
|
||||
html[data-darkmode="true"] .watch-table .unviewed {
|
||||
color: #fff; }
|
||||
html[data-darkmode="true"] .watch-table .unviewed.error {
|
||||
color: var(--color-watch-table-error); }
|
||||
|
||||
#diff-ui {
|
||||
background: #fff;
|
||||
background: var(--color-background);
|
||||
padding: 2em;
|
||||
margin-left: 1em;
|
||||
margin-right: 1em;
|
||||
border-radius: 5px;
|
||||
font-size: 11px; }
|
||||
border-radius: 5px; }
|
||||
#diff-ui #text {
|
||||
font-size: 11px; }
|
||||
#diff-ui table {
|
||||
table-layout: fixed;
|
||||
width: 100%; }
|
||||
@@ -45,6 +183,10 @@ ins {
|
||||
margin-left: 1em;
|
||||
display: inline-block;
|
||||
font-weight: normal; }
|
||||
#settings del {
|
||||
padding: 0.5em; }
|
||||
#settings ins {
|
||||
padding: 0.5em; }
|
||||
|
||||
.source {
|
||||
position: absolute;
|
||||
|
||||
@@ -1,96 +0,0 @@
|
||||
#diff-ui {
|
||||
|
||||
background: #fff;
|
||||
padding: 2em;
|
||||
margin-left: 1em;
|
||||
margin-right: 1em;
|
||||
border-radius: 5px;
|
||||
font-size: 11px;
|
||||
|
||||
table {
|
||||
table-layout: fixed;
|
||||
width: 100%;
|
||||
}
|
||||
td {
|
||||
padding: 3px 4px;
|
||||
border: 1px solid transparent;
|
||||
vertical-align: top;
|
||||
font: 1em monospace;
|
||||
text-align: left;
|
||||
}
|
||||
pre {
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
}
|
||||
h1 {
|
||||
display: inline;
|
||||
font-size: 100%;
|
||||
}
|
||||
del {
|
||||
text-decoration: none;
|
||||
color: #b30000;
|
||||
background: #fadad7;
|
||||
}
|
||||
|
||||
ins {
|
||||
background: #eaf2c2;
|
||||
color: #406619;
|
||||
text-decoration: none;
|
||||
}
|
||||
|
||||
#result {
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
|
||||
#settings {
|
||||
background: rgba(0,0,0,.05);
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
margin-bottom: 1em;
|
||||
color: #fff;
|
||||
font-size: 80%;
|
||||
label {
|
||||
margin-left: 1em;
|
||||
display: inline-block;
|
||||
font-weight: normal;
|
||||
}
|
||||
}
|
||||
|
||||
.source {
|
||||
position: absolute;
|
||||
right: 1%;
|
||||
top: .2em;
|
||||
}
|
||||
|
||||
@-moz-document url-prefix() {
|
||||
body {
|
||||
height: 99%; /* Hide scroll bar in Firefox */
|
||||
}
|
||||
}
|
||||
|
||||
td#diff-col div {
|
||||
text-align: justify;
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
|
||||
.ignored {
|
||||
background-color: #ccc;
|
||||
/* border: #0d91fa 1px solid; */
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.triggered {
|
||||
background-color: #1b98f8;
|
||||
}
|
||||
|
||||
/* ignored and triggered? make it obvious error */
|
||||
.ignored.triggered {
|
||||
background-color: #ff0000;
|
||||
}
|
||||
|
||||
.tab-pane-inner#screenshot {
|
||||
text-align: center;
|
||||
img {
|
||||
max-width: 99%;
|
||||
}
|
||||
}
|
||||
3719
changedetectionio/static/styles/package-lock.json
generated
@@ -4,7 +4,8 @@
|
||||
"description": "",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"build": "node-sass styles.scss -o .;node-sass diff.scss -o ."
|
||||
"watch": "node-sass -w scss -o .",
|
||||
"build": "node-sass scss -o ."
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
|
||||
121
changedetectionio/static/styles/scss/diff.scss
Normal file
@@ -0,0 +1,121 @@
|
||||
@import "parts/_variables.scss";
|
||||
|
||||
#diff-ui {
|
||||
|
||||
background: var(--color-background);
|
||||
padding: 2em;
|
||||
margin-left: 1em;
|
||||
margin-right: 1em;
|
||||
border-radius: 5px;
|
||||
|
||||
// The first tab 'text' diff
|
||||
#text {
|
||||
font-size: 11px;
|
||||
}
|
||||
|
||||
table {
|
||||
table-layout: fixed;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
td {
|
||||
padding: 3px 4px;
|
||||
border: 1px solid transparent;
|
||||
vertical-align: top;
|
||||
font: 1em monospace;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
pre {
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
}
|
||||
|
||||
h1 {
|
||||
display: inline;
|
||||
font-size: 100%;
|
||||
}
|
||||
|
||||
del {
|
||||
text-decoration: none;
|
||||
color: #b30000;
|
||||
background: #fadad7;
|
||||
}
|
||||
|
||||
ins {
|
||||
background: #eaf2c2;
|
||||
color: #406619;
|
||||
text-decoration: none;
|
||||
}
|
||||
|
||||
#result {
|
||||
white-space: pre-wrap;
|
||||
|
||||
.change {
|
||||
span {}
|
||||
}
|
||||
}
|
||||
|
||||
#settings {
|
||||
background: rgba(0, 0, 0, .05);
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
margin-bottom: 1em;
|
||||
color: #fff;
|
||||
font-size: 80%;
|
||||
|
||||
label {
|
||||
margin-left: 1em;
|
||||
display: inline-block;
|
||||
font-weight: normal;
|
||||
}
|
||||
|
||||
del {
|
||||
padding: 0.5em;
|
||||
}
|
||||
|
||||
ins {
|
||||
padding: 0.5em;
|
||||
}
|
||||
}
|
||||
|
||||
.source {
|
||||
position: absolute;
|
||||
right: 1%;
|
||||
top: .2em;
|
||||
}
|
||||
|
||||
@-moz-document url-prefix() {
|
||||
body {
|
||||
height: 99%;
|
||||
/* Hide scroll bar in Firefox */
|
||||
}
|
||||
}
|
||||
|
||||
td#diff-col div {
|
||||
text-align: justify;
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
|
||||
.ignored {
|
||||
background-color: #ccc;
|
||||
/* border: #0d91fa 1px solid; */
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.triggered {
|
||||
background-color: #1b98f8;
|
||||
}
|
||||
|
||||
/* ignored and triggered? make it obvious error */
|
||||
.ignored.triggered {
|
||||
background-color: #ff0000;
|
||||
}
|
||||
|
||||
.tab-pane-inner#screenshot {
|
||||
text-align: center;
|
||||
|
||||
img {
|
||||
max-width: 99%;
|
||||
}
|
||||
}
|
||||
26
changedetectionio/static/styles/scss/parts/_arrows.scss
Normal file
@@ -0,0 +1,26 @@
|
||||
.arrow {
|
||||
border: solid #1b98f8;
|
||||
border-width: 0 2px 2px 0;
|
||||
display: inline-block;
|
||||
padding: 3px;
|
||||
|
||||
&.right {
|
||||
transform: rotate(-45deg);
|
||||
-webkit-transform: rotate(-45deg);
|
||||
}
|
||||
|
||||
&.left {
|
||||
transform: rotate(135deg);
|
||||
-webkit-transform: rotate(135deg);
|
||||
}
|
||||
|
||||
&.up, &.asc {
|
||||
transform: rotate(-135deg);
|
||||
-webkit-transform: rotate(-135deg);
|
||||
}
|
||||
|
||||
&.down, &.desc {
|
||||
transform: rotate(45deg);
|
||||
-webkit-transform: rotate(45deg);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,95 @@
|
||||
|
||||
#browser_steps {
|
||||
/* convert rows to horizontal cells */
|
||||
th {
|
||||
display: none;
|
||||
}
|
||||
|
||||
li {
|
||||
&:not(:first-child) {
|
||||
&:hover {
|
||||
opacity: 1.0;
|
||||
}
|
||||
}
|
||||
list-style: decimal;
|
||||
padding: 5px;
|
||||
.control {
|
||||
padding-left: 5px;
|
||||
padding-right: 5px;
|
||||
a {
|
||||
font-size: 70%;
|
||||
}
|
||||
}
|
||||
&.empty {
|
||||
padding: 0px;
|
||||
opacity: 0.35;
|
||||
.control {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
&:hover {
|
||||
background: #eee;
|
||||
}
|
||||
> label {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#browser-steps-fieldlist {
|
||||
height: 100%;
|
||||
overflow-y: scroll;
|
||||
}
|
||||
|
||||
#browser-steps .flex-wrapper {
|
||||
display: flex;
|
||||
flex-flow: row;
|
||||
height: 600px; /*@todo make this dynamic */
|
||||
}
|
||||
|
||||
/* this is duplicate :( */
|
||||
#browsersteps-selector-wrapper {
|
||||
height: 100%;
|
||||
width: 100%;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
//width: 100%;
|
||||
> img {
|
||||
position: absolute;
|
||||
max-width: 100%;
|
||||
}
|
||||
|
||||
> canvas {
|
||||
position: relative;
|
||||
max-width: 100%;
|
||||
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
|
||||
.loader {
|
||||
position: absolute;
|
||||
left: 50%;
|
||||
top: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
margin-left: -40px;
|
||||
z-index: 100;
|
||||
max-width: 350px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
/* nice tall skinny one */
|
||||
.spinner, .spinner:after {
|
||||
width: 80px;
|
||||
height: 80px;
|
||||
font-size: 3px;
|
||||
}
|
||||
|
||||
#browsersteps-click-start {
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
color: var(--color-grey-400);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,17 @@
|
||||
ul#requests-extra_proxies {
|
||||
list-style: none;
|
||||
/* tidy up the table to look more "inline" */
|
||||
li {
|
||||
> label {
|
||||
display: none;
|
||||
}
|
||||
|
||||
}
|
||||
/* each proxy entry is a `table` */
|
||||
table {
|
||||
tr {
|
||||
display: inline;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
37
changedetectionio/static/styles/scss/parts/_pagination.scss
Normal file
@@ -0,0 +1,37 @@
|
||||
.pagination-page-info {
|
||||
color: #fff;
|
||||
font-size: 0.85rem;
|
||||
text-transform: capitalize;
|
||||
}
|
||||
|
||||
.pagination.menu {
|
||||
> * {
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
li {
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
a {
|
||||
padding: 0.65rem;
|
||||
margin: 3px;
|
||||
border: none;
|
||||
background: #444;
|
||||
border-radius: 2px;
|
||||
color: var(--color-text-button);
|
||||
&.disabled {
|
||||
display: none;
|
||||
}
|
||||
&.active {
|
||||
font-weight: bold;
|
||||
background: #888;
|
||||
}
|
||||
|
||||
&:hover {
|
||||
background: #999;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
44
changedetectionio/static/styles/scss/parts/_spinners.scss
Normal file
@@ -0,0 +1,44 @@
|
||||
|
||||
/* spinner */
|
||||
.spinner,
|
||||
.spinner:after {
|
||||
border-radius: 50%;
|
||||
width: 10px;
|
||||
height: 10px;
|
||||
}
|
||||
.spinner {
|
||||
margin: 0px auto;
|
||||
font-size: 3px;
|
||||
vertical-align: middle;
|
||||
display: inline-block;
|
||||
text-indent: -9999em;
|
||||
border-top: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-right: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-bottom: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-left: 1.1em solid #2668ed;
|
||||
-webkit-transform: translateZ(0);
|
||||
-ms-transform: translateZ(0);
|
||||
transform: translateZ(0);
|
||||
-webkit-animation: load8 1.1s infinite linear;
|
||||
animation: load8 1.1s infinite linear;
|
||||
}
|
||||
@-webkit-keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
175
changedetectionio/static/styles/scss/parts/_variables.scss
Normal file
@@ -0,0 +1,175 @@
|
||||
/**
|
||||
* CSS custom properties (aka variables).
|
||||
*/
|
||||
|
||||
:root {
|
||||
--color-white: #fff;
|
||||
--color-grey-50: #111;
|
||||
--color-grey-100: #262626;
|
||||
--color-grey-200: #333;
|
||||
--color-grey-300: #444;
|
||||
--color-grey-325: #555;
|
||||
--color-grey-350: #565d64;
|
||||
--color-grey-400: #666;
|
||||
--color-grey-500: #777;
|
||||
--color-grey-600: #999;
|
||||
--color-grey-700: #cbcbcb;
|
||||
--color-grey-750: #ddd;
|
||||
--color-grey-800: #e0e0e0;
|
||||
--color-grey-850: #eee;
|
||||
--color-grey-900: #f2f2f2;
|
||||
--color-black: #000;
|
||||
--color-dark-red: #a00;
|
||||
--color-light-red: #dd0000;
|
||||
|
||||
--color-background-page: var(--color-grey-100);
|
||||
--color-background-gradient-first: #5ad8f7;
|
||||
--color-background-gradient-second: #2f50af;
|
||||
--color-background-gradient-third: #9150bf;
|
||||
--color-background: var(--color-white);
|
||||
--color-text: var(--color-grey-200);
|
||||
--color-link: #1b98f8;
|
||||
--color-menu-accent: #ed5900;
|
||||
--color-background-code: var(--color-grey-850);
|
||||
--color-error: var(--color-dark-red);
|
||||
--color-error-input: #ffebeb;
|
||||
--color-error-list: var(--color-light-red);
|
||||
--color-table-background: var(--color-background);
|
||||
--color-table-stripe: var(--color-grey-900);
|
||||
--color-text-tab: var(--color-white);
|
||||
--color-background-tab: rgba(255, 255, 255, 0.2);
|
||||
--color-background-tab-hover: rgba(255, 255, 255, 0.5);
|
||||
--color-text-tab-active: #222;
|
||||
--color-api-key: #0078e7;
|
||||
|
||||
--color-background-button-primary: #0078e7;
|
||||
--color-background-button-green: #42dd53;
|
||||
--color-background-button-red: #dd4242;
|
||||
--color-background-button-success: rgb(28, 184, 65);
|
||||
--color-background-button-error: rgb(202, 60, 60);
|
||||
--color-text-button-error: var(--color-white);
|
||||
--color-background-button-warning: rgb(202, 60, 60);
|
||||
--color-text-button-warning: var(--color-white);
|
||||
--color-background-button-secondary: rgb(66, 184, 221);
|
||||
--color-background-button-cancel: rgb(200, 200, 200);
|
||||
--color-text-button: var(--color-white);
|
||||
--color-background-button-tag: rgb(99, 99, 99);
|
||||
--color-background-snapshot-age: #dfdfdf;
|
||||
--color-error-text-snapshot-age: var(--color-white);
|
||||
--color-error-background-snapshot-age: #ff0000;
|
||||
--color-background-button-tag-active: #9c9c9c;
|
||||
|
||||
--color-text-messages: var(--color-white);
|
||||
--color-background-messages-message: rgba(255, 255, 255, .2);
|
||||
--color-background-messages-error: rgba(255, 1, 1, .5);
|
||||
--color-background-messages-notice: rgba(255, 255, 255, .5);
|
||||
--color-border-notification: #ccc;
|
||||
|
||||
--color-background-checkbox-operations: rgba(0, 0, 0, 0.05);
|
||||
--color-warning: #ff3300;
|
||||
--color-border-warning: var(--color-warning);
|
||||
--color-text-legend: var(--color-white);
|
||||
|
||||
--color-link-new-version: #e07171;
|
||||
--color-last-checked: #bbb;
|
||||
--color-text-footer: #444;
|
||||
--color-border-watch-table-cell: #eee;
|
||||
|
||||
--color-text-watch-tag-list: #e70069;
|
||||
--color-background-new-watch-form: rgba(0, 0, 0, 0.05);
|
||||
--color-background-new-watch-input: var(--color-white);
|
||||
--color-text-new-watch-input: var(--color-text);
|
||||
|
||||
--color-border-input: var(--color-grey-500);
|
||||
--color-shadow-input: var(--color-grey-400);
|
||||
--color-background-input: var(--color-white);
|
||||
--color-text-input: var(--color-text);
|
||||
--color-text-input-description: var(--color-grey-500);
|
||||
--color-text-input-placeholder: var(--color-grey-600);
|
||||
|
||||
--color-background-table-thead: var(--color-grey-800);
|
||||
--color-border-table-cell: var(--color-grey-700);
|
||||
|
||||
--color-text-menu-heading: var(--color-grey-350);
|
||||
--color-text-menu-link: var(--color-grey-500);
|
||||
--color-background-menu-link-hover: var(--color-grey-850);
|
||||
--color-text-menu-link-hover: var(--color-grey-300);
|
||||
|
||||
--color-shadow-jump: var(--color-grey-500);
|
||||
--color-icon-github: var(--color-black);
|
||||
--color-icon-github-hover: var(--color-grey-300);
|
||||
|
||||
--color-watch-table-error: var(--color-dark-red);
|
||||
--color-watch-table-row-text: var(--color-grey-100);
|
||||
}
|
||||
|
||||
html[data-darkmode="true"] {
|
||||
--color-link: #59bdfb;
|
||||
--color-text: var(--color-white);
|
||||
|
||||
--color-background-gradient-first: #3f90a5;
|
||||
--color-background-gradient-second: #1e316c;
|
||||
--color-background-gradient-third: #4d2c64;
|
||||
|
||||
--color-background-new-watch-input: var(--color-grey-100);
|
||||
--color-text-new-watch-input: var(--color-text);
|
||||
--color-background-table-thead: var(--color-grey-200);
|
||||
--color-table-background: var(--color-grey-300);
|
||||
--color-table-stripe: var(--color-grey-325);
|
||||
--color-background: var(--color-grey-300);
|
||||
--color-text-menu-heading: var(--color-grey-850);
|
||||
--color-text-menu-link: var(--color-grey-800);
|
||||
--color-border-table-cell: var(--color-grey-400);
|
||||
--color-text-tab-active: var(--color-text);
|
||||
|
||||
--color-border-input: var(--color-grey-400);
|
||||
--color-shadow-input: var(--color-grey-50);
|
||||
--color-background-input: var(--color-grey-350);
|
||||
--color-text-input-description: var(--color-grey-600);
|
||||
--color-text-input-placeholder: var(--color-grey-600);
|
||||
--color-text-watch-tag-list: #fa3e92;
|
||||
--color-background-code: var(--color-grey-200);
|
||||
|
||||
--color-background-tab: rgba(0, 0, 0, 0.2);
|
||||
--color-background-tab-hover: rgba(0, 0, 0, 0.5);
|
||||
|
||||
--color-background-snapshot-age: var(--color-grey-200);
|
||||
--color-shadow-jump: var(--color-grey-200);
|
||||
--color-icon-github: var(--color-white);
|
||||
--color-icon-github-hover: var(--color-grey-700);
|
||||
--color-watch-table-error: var(--color-light-red);
|
||||
--color-watch-table-row-text: var(--color-grey-800);
|
||||
|
||||
|
||||
.icon-spread {
|
||||
filter: hue-rotate(-10deg) brightness(1.5);
|
||||
}
|
||||
|
||||
.watch-table {
|
||||
|
||||
.title-col a[target="_blank"]::after,
|
||||
.current-diff-url::after {
|
||||
filter: invert(.5) hue-rotate(10deg) brightness(2);
|
||||
}
|
||||
|
||||
.watch-controls {
|
||||
.state-off {
|
||||
img {
|
||||
opacity: 0.3;
|
||||
}
|
||||
}
|
||||
.state-on {
|
||||
img {
|
||||
opacity: 1.0;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.unviewed {
|
||||
color: #fff;
|
||||
&.error {
|
||||
color: var(--color-watch-table-error);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
1093
changedetectionio/static/styles/scss/styles.scss
Normal file
@@ -1,666 +0,0 @@
|
||||
/*
|
||||
* -- BASE STYLES --
|
||||
* Most of these are inherited from Base, but I want to change a few.
|
||||
* nvm use v14.18.1
|
||||
* npm install
|
||||
* npm run build
|
||||
* or npm run watch
|
||||
*/
|
||||
body {
|
||||
color: #333;
|
||||
background: #262626;
|
||||
}
|
||||
.pure-table-even {
|
||||
background: #fff;
|
||||
}
|
||||
|
||||
/* Some styles from https://css-tricks.com/ */
|
||||
a {
|
||||
text-decoration: none;
|
||||
color: #1b98f8;
|
||||
}
|
||||
|
||||
a.github-link {
|
||||
color: #fff;
|
||||
}
|
||||
|
||||
.pure-menu-horizontal {
|
||||
background: #fff;
|
||||
padding: 5px;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
border-bottom: 2px solid #ed5900;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
section.content {
|
||||
padding-top: 5em;
|
||||
padding-bottom: 1em;
|
||||
flex-direction: column;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
code {
|
||||
background: #eee;
|
||||
}
|
||||
|
||||
/* table related */
|
||||
.watch-table {
|
||||
width: 100%;
|
||||
font-size: 80%;
|
||||
|
||||
tr.unviewed {
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.error {
|
||||
color: #a00;
|
||||
}
|
||||
|
||||
td {
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
td.title-col {
|
||||
word-break: break-all;
|
||||
white-space: normal;
|
||||
}
|
||||
|
||||
th {
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
.title-col a[target="_blank"]::after, .current-diff-url::after {
|
||||
content: url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAKCAYAAACNMs+9AAAAQElEQVR42qXKwQkAIAxDUUdxtO6/RBQkQZvSi8I/pL4BoGw/XPkh4XigPmsUgh0626AjRsgxHTkUThsG2T/sIlzdTsp52kSS1wAAAABJRU5ErkJggg==);
|
||||
margin: 0 3px 0 5px;
|
||||
}
|
||||
}
|
||||
|
||||
.watch-tag-list {
|
||||
color: #e70069;
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
.box {
|
||||
max-width: 80%;
|
||||
flex-direction: column;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
|
||||
#post-list-buttons {
|
||||
text-align: right;
|
||||
padding: 0px;
|
||||
margin: 0px;
|
||||
|
||||
li {
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
a {
|
||||
border-top-left-radius: initial;
|
||||
border-top-right-radius: initial;
|
||||
border-bottom-left-radius: 5px;
|
||||
border-bottom-right-radius: 5px;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
body:after {
|
||||
content: "";
|
||||
background: linear-gradient(130deg, #5ad8f7, #2f50af 41.07%, #9150bf 84.05%);
|
||||
}
|
||||
|
||||
body:after, body:before {
|
||||
display: block;
|
||||
height: 650px;
|
||||
position: absolute;
|
||||
top: 0;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
z-index: -1;
|
||||
}
|
||||
|
||||
body::after {
|
||||
opacity: 0.91;
|
||||
}
|
||||
|
||||
body::before {
|
||||
// background-image set in base.html so it works with reverse proxies etc
|
||||
content: "";
|
||||
background-size: cover
|
||||
}
|
||||
|
||||
body:after, body:before {
|
||||
-webkit-clip-path: polygon(100% 0, 0 0, 0 77.5%, 1% 77.4%, 2% 77.1%, 3% 76.6%, 4% 75.9%, 5% 75.05%, 6% 74.05%, 7% 72.95%, 8% 71.75%, 9% 70.55%, 10% 69.3%, 11% 68.05%, 12% 66.9%, 13% 65.8%, 14% 64.8%, 15% 64%, 16% 63.35%, 17% 62.85%, 18% 62.6%, 19% 62.5%, 20% 62.65%, 21% 63%, 22% 63.5%, 23% 64.2%, 24% 65.1%, 25% 66.1%, 26% 67.2%, 27% 68.4%, 28% 69.65%, 29% 70.9%, 30% 72.15%, 31% 73.3%, 32% 74.35%, 33% 75.3%, 34% 76.1%, 35% 76.75%, 36% 77.2%, 37% 77.45%, 38% 77.5%, 39% 77.3%, 40% 76.95%, 41% 76.4%, 42% 75.65%, 43% 74.75%, 44% 73.75%, 45% 72.6%, 46% 71.4%, 47% 70.15%, 48% 68.9%, 49% 67.7%, 50% 66.55%, 51% 65.5%, 52% 64.55%, 53% 63.75%, 54% 63.15%, 55% 62.75%, 56% 62.55%, 57% 62.5%, 58% 62.7%, 59% 63.1%, 60% 63.7%, 61% 64.45%, 62% 65.4%, 63% 66.45%, 64% 67.6%, 65% 68.8%, 66% 70.05%, 67% 71.3%, 68% 72.5%, 69% 73.6%, 70% 74.65%, 71% 75.55%, 72% 76.35%, 73% 76.9%, 74% 77.3%, 75% 77.5%, 76% 77.45%, 77% 77.25%, 78% 76.8%, 79% 76.2%, 80% 75.4%, 81% 74.45%, 82% 73.4%, 83% 72.25%, 84% 71.05%, 85% 69.8%, 86% 68.55%, 87% 67.35%, 88% 66.2%, 89% 65.2%, 90% 64.3%, 91% 63.55%, 92% 63%, 93% 62.65%, 94% 62.5%, 95% 62.55%, 96% 62.8%, 97% 63.3%, 98% 63.9%, 99% 64.75%, 100% 65.7%);
|
||||
clip-path: polygon(100% 0, 0 0, 0 77.5%, 1% 77.4%, 2% 77.1%, 3% 76.6%, 4% 75.9%, 5% 75.05%, 6% 74.05%, 7% 72.95%, 8% 71.75%, 9% 70.55%, 10% 69.3%, 11% 68.05%, 12% 66.9%, 13% 65.8%, 14% 64.8%, 15% 64%, 16% 63.35%, 17% 62.85%, 18% 62.6%, 19% 62.5%, 20% 62.65%, 21% 63%, 22% 63.5%, 23% 64.2%, 24% 65.1%, 25% 66.1%, 26% 67.2%, 27% 68.4%, 28% 69.65%, 29% 70.9%, 30% 72.15%, 31% 73.3%, 32% 74.35%, 33% 75.3%, 34% 76.1%, 35% 76.75%, 36% 77.2%, 37% 77.45%, 38% 77.5%, 39% 77.3%, 40% 76.95%, 41% 76.4%, 42% 75.65%, 43% 74.75%, 44% 73.75%, 45% 72.6%, 46% 71.4%, 47% 70.15%, 48% 68.9%, 49% 67.7%, 50% 66.55%, 51% 65.5%, 52% 64.55%, 53% 63.75%, 54% 63.15%, 55% 62.75%, 56% 62.55%, 57% 62.5%, 58% 62.7%, 59% 63.1%, 60% 63.7%, 61% 64.45%, 62% 65.4%, 63% 66.45%, 64% 67.6%, 65% 68.8%, 66% 70.05%, 67% 71.3%, 68% 72.5%, 69% 73.6%, 70% 74.65%, 71% 75.55%, 72% 76.35%, 73% 76.9%, 74% 77.3%, 75% 77.5%, 76% 77.45%, 77% 77.25%, 78% 76.8%, 79% 76.2%, 80% 75.4%, 81% 74.45%, 82% 73.4%, 83% 72.25%, 84% 71.05%, 85% 69.8%, 86% 68.55%, 87% 67.35%, 88% 66.2%, 89% 65.2%, 90% 64.3%, 91% 63.55%, 92% 63%, 93% 62.65%, 94% 62.5%, 95% 62.55%, 96% 62.8%, 97% 63.3%, 98% 63.9%, 99% 64.75%, 100% 65.7%)
|
||||
}
|
||||
|
||||
.arrow {
|
||||
border: solid black;
|
||||
border-width: 0 3px 3px 0;
|
||||
display: inline-block;
|
||||
padding: 3px;
|
||||
&.right {
|
||||
transform: rotate(-45deg);
|
||||
-webkit-transform: rotate(-45deg);
|
||||
}
|
||||
&.left {
|
||||
transform: rotate(135deg);
|
||||
-webkit-transform: rotate(135deg);
|
||||
}
|
||||
&.up {
|
||||
transform: rotate(-135deg);
|
||||
-webkit-transform: rotate(-135deg);
|
||||
}
|
||||
&.down {
|
||||
transform: rotate(45deg);
|
||||
-webkit-transform: rotate(45deg);
|
||||
}
|
||||
}
|
||||
|
||||
.button-small {
|
||||
font-size: 85%;
|
||||
}
|
||||
|
||||
.fetch-error {
|
||||
padding-top: 1em;
|
||||
font-size: 60%;
|
||||
max-width: 400px;
|
||||
display: block;
|
||||
}
|
||||
|
||||
|
||||
.button-secondary {
|
||||
color: white;
|
||||
border-radius: 4px;
|
||||
text-shadow: 0 1px 1px rgba(0, 0, 0, 0.2);
|
||||
}
|
||||
|
||||
.button-success {
|
||||
background: rgb(28, 184, 65);
|
||||
/* this is a green */
|
||||
}
|
||||
|
||||
.button-tag {
|
||||
background: rgb(99, 99, 99);
|
||||
color: #fff;
|
||||
font-size: 65%;
|
||||
border-bottom-left-radius: initial;
|
||||
border-bottom-right-radius: initial;
|
||||
|
||||
&.active {
|
||||
background: #9c9c9c;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
.button-error {
|
||||
background: rgb(202, 60, 60);
|
||||
/* this is a maroon */
|
||||
}
|
||||
|
||||
.button-warning {
|
||||
background: rgb(223, 117, 20);
|
||||
/* this is an orange */
|
||||
}
|
||||
|
||||
.button-secondary {
|
||||
background: rgb(66, 184, 221);
|
||||
/* this is a light blue */
|
||||
}
|
||||
|
||||
|
||||
.button-cancel {
|
||||
background: rgb(200, 200, 200);
|
||||
/* this is a green */
|
||||
}
|
||||
|
||||
.messages {
|
||||
li {
|
||||
list-style: none;
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
color: #fff;
|
||||
font-weight: bold;
|
||||
&.message {
|
||||
background: rgba(255, 255, 255, .2);
|
||||
}
|
||||
&.error {
|
||||
background: rgba(255, 1, 1, .5);
|
||||
}
|
||||
&.notice {
|
||||
background: rgba(255, 255, 255, .5);
|
||||
}
|
||||
}
|
||||
&.with-share-link {
|
||||
> *:hover {
|
||||
cursor:pointer;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#notification-customisation {
|
||||
border: 1px solid #ccc;
|
||||
padding: 0.5rem;
|
||||
border-radius: 5px;
|
||||
}
|
||||
|
||||
#notification-error-log {
|
||||
border: 1px solid #ccc;
|
||||
padding: 1rem;
|
||||
border-radius: 5px;
|
||||
overflow-wrap: break-word;
|
||||
}
|
||||
|
||||
#token-table {
|
||||
&.pure-table td, &.pure-table th {
|
||||
font-size: 80%;
|
||||
}
|
||||
}
|
||||
|
||||
#new-watch-form {
|
||||
background: rgba(0, 0, 0, .05);
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
margin-bottom: 1em;
|
||||
input {
|
||||
width: auto !important;
|
||||
display: inline-block;
|
||||
}
|
||||
.label {
|
||||
display: none;
|
||||
}
|
||||
legend {
|
||||
color: #fff;
|
||||
font-weight: bold;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
#diff-col {
|
||||
padding-left: 40px;
|
||||
}
|
||||
|
||||
#diff-jump {
|
||||
position: fixed;
|
||||
left: 0px;
|
||||
top: 120px;
|
||||
background: #fff;
|
||||
padding: 10px;
|
||||
border-top-right-radius: 5px;
|
||||
border-bottom-right-radius: 5px;
|
||||
box-shadow: 5px 0 5px -2px #888;
|
||||
a {
|
||||
color: #1b98f8;
|
||||
cursor: grabbing;
|
||||
-moz-user-select: none;
|
||||
-webkit-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
-o-user-select: none;
|
||||
}
|
||||
}
|
||||
|
||||
footer {
|
||||
padding: 10px;
|
||||
background: #fff;
|
||||
color: #444;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
#feed-icon {
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
#top-right-menu {
|
||||
// Just let flex overflow the x axis for now
|
||||
/*
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
background: linear-gradient(to right, #fff0, #fff 10%);
|
||||
padding-left: 20px;
|
||||
padding-right: 10px;
|
||||
*/
|
||||
}
|
||||
|
||||
.sticky-tab {
|
||||
position: absolute;
|
||||
top: 60px;
|
||||
font-size: 65%;
|
||||
background: #fff;
|
||||
padding: 10px;
|
||||
&#left-sticky {
|
||||
left: 0px;
|
||||
}
|
||||
&#right-sticky {
|
||||
right: 0px;
|
||||
}
|
||||
&#hosted-sticky {
|
||||
right: 0px;
|
||||
top: 100px;
|
||||
font-weight: bold;
|
||||
}
|
||||
}
|
||||
|
||||
#new-version-text a {
|
||||
color: #e07171;
|
||||
}
|
||||
|
||||
.paused-state {
|
||||
&.state-False img {
|
||||
opacity: 0.2;
|
||||
}
|
||||
|
||||
&.state-False:hover img {
|
||||
opacity: 0.8;
|
||||
}
|
||||
}
|
||||
|
||||
.monospaced-textarea {
|
||||
textarea {
|
||||
width: 100%;
|
||||
font-family: monospace;
|
||||
white-space: pre;
|
||||
overflow-wrap: normal;
|
||||
overflow-x: scroll;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
.pure-form {
|
||||
fieldset {
|
||||
padding-top: 0px;
|
||||
ul {
|
||||
padding-bottom: 0px;
|
||||
margin-bottom: 0px;
|
||||
}
|
||||
}
|
||||
.pure-control-group, .pure-group, .pure-controls {
|
||||
padding-bottom: 1em;
|
||||
div {
|
||||
margin: 0px;
|
||||
}
|
||||
.checkbox {
|
||||
> * {
|
||||
display: inline;
|
||||
vertical-align: middle;
|
||||
}
|
||||
> label {
|
||||
padding-left: 5px;
|
||||
}
|
||||
}
|
||||
}
|
||||
/* The input fields with errors */
|
||||
.error {
|
||||
input {
|
||||
background-color: #ffebeb;
|
||||
}
|
||||
}
|
||||
|
||||
/* The list of errors */
|
||||
ul.errors {
|
||||
padding: .5em .6em;
|
||||
border: 1px solid #dd0000;
|
||||
border-radius: 4px;
|
||||
vertical-align: middle;
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
li {
|
||||
margin-left: 1em;
|
||||
color: #dd0000;
|
||||
}
|
||||
}
|
||||
|
||||
label {
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
textarea {
|
||||
width: 100%;
|
||||
}
|
||||
.inline-radio {
|
||||
ul {
|
||||
margin: 0px;
|
||||
list-style: none;
|
||||
li {
|
||||
> * {
|
||||
display: inline-block;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (max-width: 760px), (min-device-width: 768px) and (max-device-width: 1024px) {
|
||||
.box {
|
||||
max-width: 95%
|
||||
}
|
||||
.edit-form {
|
||||
padding: 0.5em;
|
||||
margin: 0;
|
||||
}
|
||||
#nav-menu {
|
||||
overflow-x: scroll;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
@media only screen and (max-width: 760px), (min-device-width: 768px) and (max-device-width: 800px) {
|
||||
|
||||
div.sticky-tab#hosted-sticky {
|
||||
top: 60px;
|
||||
left: 0px;
|
||||
right: auto;
|
||||
}
|
||||
|
||||
section.content {
|
||||
padding-top: 110px;
|
||||
}
|
||||
|
||||
// Make the tabs easier to hit, they will be all nice and horizontal
|
||||
div.tabs.collapsable ul li {
|
||||
display: block;
|
||||
border-radius: 0px;
|
||||
}
|
||||
|
||||
input[type='text'] {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
/*
|
||||
Max width before this PARTICULAR table gets nasty
|
||||
This query will take effect for any screen smaller than 760px
|
||||
and also iPads specifically.
|
||||
*/
|
||||
.watch-table {
|
||||
/* Force table to not be like tables anymore */
|
||||
thead, tbody, th, td, tr {
|
||||
display: block;
|
||||
}
|
||||
|
||||
.last-checked::before {
|
||||
color: #555;
|
||||
content: "Last Checked ";
|
||||
}
|
||||
|
||||
.last-changed::before {
|
||||
color: #555;
|
||||
content: "Last Changed ";
|
||||
}
|
||||
|
||||
/* Force table to not be like tables anymore */
|
||||
td.inline {
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
/* Hide table headers (but not display: none;, for accessibility) */
|
||||
thead tr {
|
||||
position: absolute;
|
||||
top: -9999px;
|
||||
left: -9999px;
|
||||
}
|
||||
|
||||
.pure-table td, .pure-table th {
|
||||
border: none;
|
||||
}
|
||||
|
||||
td {
|
||||
/* Behave like a "row" */
|
||||
border: none;
|
||||
border-bottom: 1px solid #eee;
|
||||
|
||||
&:before {
|
||||
/* Top/left values mimic padding */
|
||||
top: 6px;
|
||||
left: 6px;
|
||||
width: 45%;
|
||||
padding-right: 10px;
|
||||
white-space: nowrap;
|
||||
}
|
||||
}
|
||||
|
||||
&.pure-table-striped {
|
||||
tr {
|
||||
background-color: #fff;
|
||||
}
|
||||
|
||||
tr:nth-child(2n-1) {
|
||||
background-color: #eee;
|
||||
}
|
||||
|
||||
tr:nth-child(2n-1) td {
|
||||
background-color: inherit;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/** Desktop vs mobile input field strategy
|
||||
- We dont use 'size' with <input> because `size` is too unreliable to override, and will often push-out
|
||||
- Rely always on width in CSS
|
||||
*/
|
||||
@media only screen and (min-width: 761px) {
|
||||
/* m-d is medium-desktop */
|
||||
.m-d {
|
||||
min-width: 80%;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
.tabs {
|
||||
ul {
|
||||
margin: 0px;
|
||||
padding: 0px;
|
||||
display:block;
|
||||
li {
|
||||
margin-right: 3px;
|
||||
display: inline-block;
|
||||
color: #fff;
|
||||
border-top-left-radius: 5px;
|
||||
border-top-right-radius: 5px;
|
||||
background-color: rgba(255, 255, 255, 0.2);
|
||||
|
||||
&.active,:target {
|
||||
background-color: #fff;
|
||||
a {
|
||||
color: #222;
|
||||
font-weight: bold;
|
||||
}
|
||||
}
|
||||
a {
|
||||
display: block;
|
||||
padding: 0.8em;
|
||||
color: #fff;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
$form-edge-padding: 20px;
|
||||
.pure-form-stacked {
|
||||
>div:first-child {
|
||||
display: block;
|
||||
}
|
||||
}
|
||||
|
||||
.login-form {
|
||||
.inner {
|
||||
background: #fff;;
|
||||
padding: $form-edge-padding;
|
||||
border-radius: 5px;
|
||||
}
|
||||
}
|
||||
|
||||
.tab-pane-inner {
|
||||
&:not(:target) {
|
||||
display: none;
|
||||
}
|
||||
&:target {
|
||||
display: block;
|
||||
}
|
||||
// doesnt need padding because theres another row of buttons/activity
|
||||
padding: 0px;
|
||||
}
|
||||
|
||||
.edit-form {
|
||||
min-width: 70%;
|
||||
/* so it cant overflow */
|
||||
max-width: 95%;
|
||||
.box-wrap {
|
||||
position: relative;
|
||||
}
|
||||
.inner {
|
||||
background: #fff;;
|
||||
padding: $form-edge-padding;
|
||||
}
|
||||
#actions {
|
||||
display: block;
|
||||
background: #fff;
|
||||
}
|
||||
|
||||
.pure-form-message-inline {
|
||||
padding-left: 0;
|
||||
}
|
||||
}
|
||||
|
||||
ul {
|
||||
padding-left: 1em;
|
||||
padding-top: 0px;
|
||||
margin-top: 4px;
|
||||
}
|
||||
|
||||
.time-check-widget {
|
||||
tr {
|
||||
display: inline;
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#webdriver-override-options {
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
|
||||
#api-key {
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
|
||||
#api-key-copy {
|
||||
color: #0078e7;
|
||||
}
|
||||
@@ -1,20 +1,20 @@
|
||||
from flask import (
|
||||
flash
|
||||
)
|
||||
|
||||
from . model import App, Watch
|
||||
from copy import deepcopy
|
||||
from os import path, unlink
|
||||
from threading import Lock
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import threading
|
||||
import time
|
||||
import uuid as uuid_builder
|
||||
from copy import deepcopy
|
||||
from os import mkdir, path, unlink
|
||||
from threading import Lock
|
||||
import re
|
||||
import requests
|
||||
import secrets
|
||||
|
||||
from . model import App, Watch
|
||||
import threading
|
||||
import time
|
||||
import uuid as uuid_builder
|
||||
|
||||
# Is there an existing library to ensure some data store (JSON etc) is in sync with CRUD methods?
|
||||
# Open a github issue if you know something :)
|
||||
@@ -27,20 +27,20 @@ class ChangeDetectionStore:
|
||||
# For when we edit, we should write to disk
|
||||
needs_write_urgent = False
|
||||
|
||||
__version_check = True
|
||||
|
||||
def __init__(self, datastore_path="/datastore", include_default_watches=True, version_tag="0.0.0"):
|
||||
# Should only be active for docker
|
||||
# logging.basicConfig(filename='/dev/stdout', level=logging.INFO)
|
||||
self.needs_write = False
|
||||
self.__data = App.model()
|
||||
self.datastore_path = datastore_path
|
||||
self.json_store_path = "{}/url-watches.json".format(self.datastore_path)
|
||||
self.proxy_list = None
|
||||
self.needs_write = False
|
||||
self.start_time = time.time()
|
||||
self.stop_thread = False
|
||||
|
||||
self.__data = App.model()
|
||||
|
||||
# Base definition for all watchers
|
||||
# deepcopy part of #569 - not sure why its needed exactly
|
||||
self.generic_definition = deepcopy(Watch.model())
|
||||
self.generic_definition = deepcopy(Watch.model(datastore_path = datastore_path, default={}))
|
||||
|
||||
if path.isfile('changedetectionio/source.txt'):
|
||||
with open('changedetectionio/source.txt') as f:
|
||||
@@ -71,27 +71,28 @@ class ChangeDetectionStore:
|
||||
if 'application' in from_disk['settings']:
|
||||
self.__data['settings']['application'].update(from_disk['settings']['application'])
|
||||
|
||||
# Reinitialise each `watching` with our generic_definition in the case that we add a new var in the future.
|
||||
# @todo pretty sure theres a python we todo this with an abstracted(?) object!
|
||||
# Convert each existing watch back to the Watch.model object
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
_blank = deepcopy(self.generic_definition)
|
||||
_blank.update(watch)
|
||||
self.__data['watching'].update({uuid: _blank})
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
watch['uuid']=uuid
|
||||
self.__data['watching'][uuid] = Watch.model(datastore_path=self.datastore_path, default=watch)
|
||||
print("Watching:", uuid, self.__data['watching'][uuid]['url'])
|
||||
|
||||
# First time ran, doesnt exist.
|
||||
except (FileNotFoundError, json.decoder.JSONDecodeError):
|
||||
# First time ran, Create the datastore.
|
||||
except (FileNotFoundError):
|
||||
if include_default_watches:
|
||||
print("Creating JSON store at", self.datastore_path)
|
||||
|
||||
self.add_watch(url='http://www.quotationspage.com/random.php', tag='test')
|
||||
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
||||
self.add_watch(url='https://www.gov.uk/coronavirus', tag='Covid')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt')
|
||||
print("No JSON DB found at {}, creating JSON store at {}".format(self.json_store_path, self.datastore_path))
|
||||
self.add_watch(url='https://news.ycombinator.com/',
|
||||
tag='Tech news',
|
||||
extras={'fetch_backend': 'html_requests'})
|
||||
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt',
|
||||
tag='changedetection.io',
|
||||
extras={'fetch_backend': 'html_requests'})
|
||||
self.__data['version_tag'] = version_tag
|
||||
|
||||
# Just to test that proxies.json if it exists, doesnt throw a parsing error on startup
|
||||
test_list = self.proxy_list
|
||||
|
||||
# Helper to remove password protection
|
||||
password_reset_lockfile = "{}/removepassword.lock".format(self.datastore_path)
|
||||
if path.isfile(password_reset_lockfile):
|
||||
@@ -116,13 +117,6 @@ class ChangeDetectionStore:
|
||||
secret = secrets.token_hex(16)
|
||||
self.__data['settings']['application']['api_access_token'] = secret
|
||||
|
||||
# Proxy list support - available as a selection in settings when text file is imported
|
||||
# CSV list
|
||||
# "name, address", or just "name"
|
||||
proxy_list_file = "{}/proxies.txt".format(self.datastore_path)
|
||||
if path.isfile(proxy_list_file):
|
||||
self.import_proxy_list(proxy_list_file)
|
||||
|
||||
# Bump the update version by running updates
|
||||
self.run_updates()
|
||||
|
||||
@@ -131,23 +125,8 @@ class ChangeDetectionStore:
|
||||
# Finally start the thread that will manage periodic data saves to JSON
|
||||
save_data_thread = threading.Thread(target=self.save_datastore).start()
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
def get_newest_history_key(self, uuid):
|
||||
if len(self.__data['watching'][uuid]['history']) == 1:
|
||||
return 0
|
||||
|
||||
dates = list(self.__data['watching'][uuid]['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
if len(dates):
|
||||
# always keyed as str
|
||||
return str(dates[0])
|
||||
|
||||
return 0
|
||||
|
||||
def set_last_viewed(self, uuid, timestamp):
|
||||
logging.debug("Setting watch UUID: {} last viewed to {}".format(uuid, int(timestamp)))
|
||||
self.data['watching'][uuid].update({'last_viewed': int(timestamp)})
|
||||
self.needs_write = True
|
||||
|
||||
@@ -171,45 +150,32 @@ class ChangeDetectionStore:
|
||||
del (update_obj[dict_key])
|
||||
|
||||
self.__data['watching'][uuid].update(update_obj)
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
|
||||
self.needs_write = True
|
||||
|
||||
@property
|
||||
def threshold_seconds(self):
|
||||
seconds = 0
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
for m, n in mtable.items():
|
||||
for m, n in Watch.mtable.items():
|
||||
x = self.__data['settings']['requests']['time_between_check'].get(m)
|
||||
if x:
|
||||
seconds += x * n
|
||||
return max(seconds, minimum_seconds_recheck_time)
|
||||
return seconds
|
||||
|
||||
@property
|
||||
def has_unviewed(self):
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
if watch.viewed == False:
|
||||
return True
|
||||
return False
|
||||
|
||||
@property
|
||||
def data(self):
|
||||
has_unviewed = False
|
||||
for uuid, v in self.__data['watching'].items():
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
if int(v['newest_history_key']) <= int(v['last_viewed']):
|
||||
self.__data['watching'][uuid]['viewed'] = True
|
||||
|
||||
else:
|
||||
self.__data['watching'][uuid]['viewed'] = False
|
||||
has_unviewed = True
|
||||
|
||||
# #106 - Be sure this is None on empty string, False, None, etc
|
||||
# Default var for fetch_backend
|
||||
if not self.__data['watching'][uuid]['fetch_backend']:
|
||||
self.__data['watching'][uuid]['fetch_backend'] = self.__data['settings']['application']['fetch_backend']
|
||||
|
||||
# Re #152, Return env base_url if not overriden, @todo also prefer the proxy pass url
|
||||
env_base_url = os.getenv('BASE_URL','')
|
||||
if not self.__data['settings']['application']['base_url']:
|
||||
self.__data['settings']['application']['base_url'] = env_base_url.strip('" ')
|
||||
|
||||
self.__data['has_unviewed'] = has_unviewed
|
||||
|
||||
return self.__data
|
||||
|
||||
def get_all_tags(self):
|
||||
@@ -226,27 +192,24 @@ class ChangeDetectionStore:
|
||||
tags.sort()
|
||||
return tags
|
||||
|
||||
def unlink_history_file(self, path):
|
||||
try:
|
||||
unlink(path)
|
||||
except (FileNotFoundError, IOError):
|
||||
pass
|
||||
|
||||
# Delete a single watch by UUID
|
||||
def delete(self, uuid):
|
||||
import pathlib
|
||||
import shutil
|
||||
|
||||
with self.lock:
|
||||
if uuid == 'all':
|
||||
self.__data['watching'] = {}
|
||||
|
||||
# GitHub #30 also delete history records
|
||||
for uuid in self.data['watching']:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
self.unlink_history_file(path)
|
||||
path = pathlib.Path(os.path.join(self.datastore_path, uuid))
|
||||
shutil.rmtree(path)
|
||||
self.needs_write_urgent = True
|
||||
|
||||
else:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
self.unlink_history_file(path)
|
||||
|
||||
path = pathlib.Path(os.path.join(self.datastore_path, uuid))
|
||||
shutil.rmtree(path)
|
||||
del self.data['watching'][uuid]
|
||||
|
||||
self.needs_write_urgent = True
|
||||
@@ -268,26 +231,36 @@ class ChangeDetectionStore:
|
||||
|
||||
return False
|
||||
|
||||
def get_val(self, uuid, val):
|
||||
# Probably their should be dict...
|
||||
return self.data['watching'][uuid].get(val)
|
||||
|
||||
# Remove a watchs data but keep the entry (URL etc)
|
||||
def scrub_watch(self, uuid):
|
||||
def clear_watch_history(self, uuid):
|
||||
import pathlib
|
||||
|
||||
self.__data['watching'][uuid].update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'newest_history_key': 0, 'previous_md5': False})
|
||||
self.needs_write_urgent = True
|
||||
self.__data['watching'][uuid].update({
|
||||
'last_checked': 0,
|
||||
'has_ldjson_price_data': None,
|
||||
'last_error': False,
|
||||
'last_notification_error': False,
|
||||
'last_viewed': 0,
|
||||
'previous_md5': False,
|
||||
'track_ldjson_price_data': None,
|
||||
})
|
||||
|
||||
for item in pathlib.Path(self.datastore_path).rglob(uuid+"/*.txt"):
|
||||
# JSON Data, Screenshots, Textfiles (history index and snapshots), HTML in the future etc
|
||||
for item in pathlib.Path(os.path.join(self.datastore_path, uuid)).rglob("*.*"):
|
||||
unlink(item)
|
||||
|
||||
# Force the attr to recalculate
|
||||
bump = self.__data['watching'][uuid].history
|
||||
|
||||
self.needs_write_urgent = True
|
||||
|
||||
def add_watch(self, url, tag="", extras=None, write_to_disk_now=True):
|
||||
|
||||
if extras is None:
|
||||
extras = {}
|
||||
# should always be str
|
||||
if tag is None or not tag:
|
||||
tag=''
|
||||
tag = ''
|
||||
|
||||
# Incase these are copied across, assume it's a reference and deepcopy()
|
||||
apply_extras = deepcopy(extras)
|
||||
@@ -301,85 +274,116 @@ class ChangeDetectionStore:
|
||||
headers={'App-Guid': self.__data['app_guid']})
|
||||
res = r.json()
|
||||
|
||||
# List of permisable stuff we accept from the wild internet
|
||||
for k in ['url', 'tag',
|
||||
'paused', 'title',
|
||||
'previous_md5', 'headers',
|
||||
'body', 'method',
|
||||
'ignore_text', 'css_filter',
|
||||
'subtractive_selectors', 'trigger_text',
|
||||
'extract_title_as_title']:
|
||||
# List of permissible attributes we accept from the wild internet
|
||||
for k in [
|
||||
'body',
|
||||
'browser_steps',
|
||||
'css_filter',
|
||||
'extract_text',
|
||||
'extract_title_as_title',
|
||||
'headers',
|
||||
'ignore_text',
|
||||
'include_filters',
|
||||
'method',
|
||||
'paused',
|
||||
'previous_md5',
|
||||
'processor',
|
||||
'subtractive_selectors',
|
||||
'tag',
|
||||
'text_should_not_be_present',
|
||||
'title',
|
||||
'trigger_text',
|
||||
'url',
|
||||
'webdriver_js_execute_code',
|
||||
]:
|
||||
if res.get(k):
|
||||
apply_extras[k] = res[k]
|
||||
if k != 'css_filter':
|
||||
apply_extras[k] = res[k]
|
||||
else:
|
||||
# We renamed the field and made it a list
|
||||
apply_extras['include_filters'] = [res['css_filter']]
|
||||
|
||||
except Exception as e:
|
||||
logging.error("Error fetching metadata for shared watch link", url, str(e))
|
||||
flash("Error fetching metadata for {}".format(url), 'error')
|
||||
return False
|
||||
from .model.Watch import is_safe_url
|
||||
if not is_safe_url(url):
|
||||
flash('Watch protocol is not permitted by SAFE_PROTOCOL_REGEX', 'error')
|
||||
return None
|
||||
|
||||
with self.lock:
|
||||
# @todo use a common generic version of this
|
||||
new_uuid = str(uuid_builder.uuid4())
|
||||
# #Re 569
|
||||
# Not sure why deepcopy was needed here, sometimes new watches would appear to already have 'history' set
|
||||
# I assumed this would instantiate a new object but somehow an existing dict was getting used
|
||||
new_watch = deepcopy(Watch.model({
|
||||
new_watch = Watch.model(datastore_path=self.datastore_path, default={
|
||||
'url': url,
|
||||
'tag': tag
|
||||
}))
|
||||
'tag': tag,
|
||||
'date_created': int(time.time())
|
||||
})
|
||||
|
||||
new_uuid = new_watch['uuid']
|
||||
logging.debug("Added URL {} - {}".format(url, new_uuid))
|
||||
|
||||
for k in ['uuid', 'history', 'last_checked', 'last_changed', 'newest_history_key', 'previous_md5', 'viewed']:
|
||||
if k in apply_extras:
|
||||
del apply_extras[k]
|
||||
|
||||
new_watch.update(apply_extras)
|
||||
self.__data['watching'][new_uuid]=new_watch
|
||||
self.__data['watching'][new_uuid] = new_watch
|
||||
|
||||
# Get the directory ready
|
||||
output_path = "{}/{}".format(self.datastore_path, new_uuid)
|
||||
try:
|
||||
mkdir(output_path)
|
||||
except FileExistsError:
|
||||
print(output_path, "already exists.")
|
||||
self.__data['watching'][new_uuid].ensure_data_dir_exists()
|
||||
|
||||
if write_to_disk_now:
|
||||
self.sync_to_json()
|
||||
|
||||
return new_uuid
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, watch_uuid, contents):
|
||||
import uuid
|
||||
|
||||
def visualselector_data_is_ready(self, watch_uuid):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
# Incase the operator deleted it, check and create.
|
||||
if not os.path.isdir(output_path):
|
||||
mkdir(output_path)
|
||||
|
||||
fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
with open(fname, 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
return fname
|
||||
|
||||
def get_screenshot(self, watch_uuid):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
fname = "{}/last-screenshot.png".format(output_path)
|
||||
if path.isfile(fname):
|
||||
return fname
|
||||
screenshot_filename = "{}/last-screenshot.png".format(output_path)
|
||||
elements_index_filename = "{}/elements.json".format(output_path)
|
||||
if path.isfile(screenshot_filename) and path.isfile(elements_index_filename) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
# Save as PNG, PNG is larger but better for doing visual diff in the future
|
||||
def save_screenshot(self, watch_uuid, screenshot: bytes):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
fname = "{}/last-screenshot.png".format(output_path)
|
||||
with open(fname, 'wb') as f:
|
||||
def save_screenshot(self, watch_uuid, screenshot: bytes, as_error=False):
|
||||
if not self.data['watching'].get(watch_uuid):
|
||||
return
|
||||
|
||||
if as_error:
|
||||
target_path = os.path.join(self.datastore_path, watch_uuid, "last-error-screenshot.png")
|
||||
else:
|
||||
target_path = os.path.join(self.datastore_path, watch_uuid, "last-screenshot.png")
|
||||
|
||||
self.data['watching'][watch_uuid].ensure_data_dir_exists()
|
||||
|
||||
with open(target_path, 'wb') as f:
|
||||
f.write(screenshot)
|
||||
f.close()
|
||||
|
||||
|
||||
def save_error_text(self, watch_uuid, contents):
|
||||
if not self.data['watching'].get(watch_uuid):
|
||||
return
|
||||
target_path = os.path.join(self.datastore_path, watch_uuid, "last-error.txt")
|
||||
|
||||
with open(target_path, 'w') as f:
|
||||
f.write(contents)
|
||||
|
||||
def save_xpath_data(self, watch_uuid, data, as_error=False):
|
||||
if not self.data['watching'].get(watch_uuid):
|
||||
return
|
||||
if as_error:
|
||||
target_path = os.path.join(self.datastore_path, watch_uuid, "elements-error.json")
|
||||
else:
|
||||
target_path = os.path.join(self.datastore_path, watch_uuid, "elements.json")
|
||||
|
||||
with open(target_path, 'w') as f:
|
||||
f.write(json.dumps(data))
|
||||
f.close()
|
||||
|
||||
|
||||
def sync_to_json(self):
|
||||
logging.info("Saving JSON..")
|
||||
print("Saving JSON..")
|
||||
@@ -432,8 +436,8 @@ class ChangeDetectionStore:
|
||||
|
||||
index=[]
|
||||
for uuid in self.data['watching']:
|
||||
for id in self.data['watching'][uuid]['history']:
|
||||
index.append(self.data['watching'][uuid]['history'][str(id)])
|
||||
for id in self.data['watching'][uuid].history:
|
||||
index.append(self.data['watching'][uuid].history[str(id)])
|
||||
|
||||
import pathlib
|
||||
|
||||
@@ -444,20 +448,62 @@ class ChangeDetectionStore:
|
||||
print ("Removing",item)
|
||||
unlink(item)
|
||||
|
||||
def import_proxy_list(self, filename):
|
||||
import csv
|
||||
with open(filename, newline='') as f:
|
||||
reader = csv.reader(f, skipinitialspace=True)
|
||||
# @todo This loop can could be improved
|
||||
l = []
|
||||
for row in reader:
|
||||
if len(row):
|
||||
if len(row)>=2:
|
||||
l.append(tuple(row[:2]))
|
||||
else:
|
||||
l.append(tuple([row[0], row[0]]))
|
||||
self.proxy_list = l if len(l) else None
|
||||
@property
|
||||
def proxy_list(self):
|
||||
proxy_list = {}
|
||||
proxy_list_file = os.path.join(self.datastore_path, 'proxies.json')
|
||||
|
||||
# Load from external config file
|
||||
if path.isfile(proxy_list_file):
|
||||
with open("{}/proxies.json".format(self.datastore_path)) as f:
|
||||
proxy_list = json.load(f)
|
||||
|
||||
# Mapping from UI config if available
|
||||
extras = self.data['settings']['requests'].get('extra_proxies')
|
||||
if extras:
|
||||
i=0
|
||||
for proxy in extras:
|
||||
i += 0
|
||||
if proxy.get('proxy_name') and proxy.get('proxy_url'):
|
||||
k = "ui-" + str(i) + proxy.get('proxy_name')
|
||||
proxy_list[k] = {'label': proxy.get('proxy_name'), 'url': proxy.get('proxy_url')}
|
||||
|
||||
|
||||
return proxy_list if len(proxy_list) else None
|
||||
|
||||
|
||||
|
||||
|
||||
def get_preferred_proxy_for_watch(self, uuid):
|
||||
"""
|
||||
Returns the preferred proxy by ID key
|
||||
:param uuid: UUID
|
||||
:return: proxy "key" id
|
||||
"""
|
||||
|
||||
if self.proxy_list is None:
|
||||
return None
|
||||
|
||||
# If it's a valid one
|
||||
watch = self.data['watching'].get(uuid)
|
||||
|
||||
if watch.get('proxy') and watch.get('proxy') in list(self.proxy_list.keys()):
|
||||
return watch.get('proxy')
|
||||
|
||||
# not valid (including None), try the system one
|
||||
else:
|
||||
system_proxy_id = self.data['settings']['requests'].get('proxy')
|
||||
# Is not None and exists
|
||||
if self.proxy_list.get(system_proxy_id):
|
||||
return system_proxy_id
|
||||
|
||||
|
||||
# Fallback - Did not resolve anything, or doesnt exist, use the first available
|
||||
if system_proxy_id is None or not self.proxy_list.get(system_proxy_id):
|
||||
first_default = list(self.proxy_list)[0]
|
||||
return first_default
|
||||
|
||||
return None
|
||||
|
||||
# Run all updates
|
||||
# IMPORTANT - Each update could be run even when they have a new install and the schema is correct
|
||||
@@ -504,3 +550,143 @@ class ChangeDetectionStore:
|
||||
# Only upgrade individual watch time if it was set
|
||||
if watch.get('minutes_between_check', False):
|
||||
self.data['watching'][uuid]['time_between_check']['minutes'] = watch['minutes_between_check']
|
||||
|
||||
# Move the history list to a flat text file index
|
||||
# Better than SQLite because this list is only appended to, and works across NAS / NFS type setups
|
||||
def update_2(self):
|
||||
# @todo test running this on a newly updated one (when this already ran)
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
history = []
|
||||
|
||||
if watch.get('history', False):
|
||||
for d, p in watch['history'].items():
|
||||
d = int(d) # Used to be keyed as str, we'll fix this now too
|
||||
history.append("{},{}\n".format(d,p))
|
||||
|
||||
if len(history):
|
||||
target_path = os.path.join(self.datastore_path, uuid)
|
||||
if os.path.exists(target_path):
|
||||
with open(os.path.join(target_path, "history.txt"), "w") as f:
|
||||
f.writelines(history)
|
||||
else:
|
||||
logging.warning("Datastore history directory {} does not exist, skipping history import.".format(target_path))
|
||||
|
||||
# No longer needed, dynamically pulled from the disk when needed.
|
||||
# But we should set it back to a empty dict so we don't break if this schema runs on an earlier version.
|
||||
# In the distant future we can remove this entirely
|
||||
self.data['watching'][uuid]['history'] = {}
|
||||
|
||||
# We incorrectly stored last_changed when there was not a change, and then confused the output list table
|
||||
def update_3(self):
|
||||
# see https://github.com/dgtlmoon/changedetection.io/pull/835
|
||||
return
|
||||
|
||||
# `last_changed` not needed, we pull that information from the history.txt index
|
||||
def update_4(self):
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
# Remove it from the struct
|
||||
del(watch['last_changed'])
|
||||
except:
|
||||
continue
|
||||
return
|
||||
|
||||
def update_5(self):
|
||||
# If the watch notification body, title look the same as the global one, unset it, so the watch defaults back to using the main settings
|
||||
# In other words - the watch notification_title and notification_body are not needed if they are the same as the default one
|
||||
current_system_body = self.data['settings']['application']['notification_body'].translate(str.maketrans('', '', "\r\n "))
|
||||
current_system_title = self.data['settings']['application']['notification_body'].translate(str.maketrans('', '', "\r\n "))
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
watch_body = watch.get('notification_body', '')
|
||||
if watch_body and watch_body.translate(str.maketrans('', '', "\r\n ")) == current_system_body:
|
||||
# Looks the same as the default one, so unset it
|
||||
watch['notification_body'] = None
|
||||
|
||||
watch_title = watch.get('notification_title', '')
|
||||
if watch_title and watch_title.translate(str.maketrans('', '', "\r\n ")) == current_system_title:
|
||||
# Looks the same as the default one, so unset it
|
||||
watch['notification_title'] = None
|
||||
except Exception as e:
|
||||
continue
|
||||
return
|
||||
|
||||
|
||||
# We incorrectly used common header overrides that should only apply to Requests
|
||||
# These are now handled in content_fetcher::html_requests and shouldnt be passed to Playwright/Selenium
|
||||
def update_7(self):
|
||||
# These were hard-coded in early versions
|
||||
for v in ['User-Agent', 'Accept', 'Accept-Encoding', 'Accept-Language']:
|
||||
if self.data['settings']['headers'].get(v):
|
||||
del self.data['settings']['headers'][v]
|
||||
|
||||
# Convert filters to a list of filters css_filter -> include_filters
|
||||
def update_8(self):
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
existing_filter = watch.get('css_filter', '')
|
||||
if existing_filter:
|
||||
watch['include_filters'] = [existing_filter]
|
||||
except:
|
||||
continue
|
||||
return
|
||||
|
||||
# Convert old static notification tokens to jinja2 tokens
|
||||
def update_9(self):
|
||||
# Each watch
|
||||
import re
|
||||
# only { } not {{ or }}
|
||||
r = r'(?<!{){(?!{)(\w+)(?<!})}(?!})'
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
n_body = watch.get('notification_body', '')
|
||||
if n_body:
|
||||
watch['notification_body'] = re.sub(r, r'{{\1}}', n_body)
|
||||
|
||||
n_title = watch.get('notification_title')
|
||||
if n_title:
|
||||
watch['notification_title'] = re.sub(r, r'{{\1}}', n_title)
|
||||
|
||||
n_urls = watch.get('notification_urls')
|
||||
if n_urls:
|
||||
for i, url in enumerate(n_urls):
|
||||
watch['notification_urls'][i] = re.sub(r, r'{{\1}}', url)
|
||||
|
||||
except:
|
||||
continue
|
||||
|
||||
# System wide
|
||||
n_body = self.data['settings']['application'].get('notification_body')
|
||||
if n_body:
|
||||
self.data['settings']['application']['notification_body'] = re.sub(r, r'{{\1}}', n_body)
|
||||
|
||||
n_title = self.data['settings']['application'].get('notification_title')
|
||||
if n_body:
|
||||
self.data['settings']['application']['notification_title'] = re.sub(r, r'{{\1}}', n_title)
|
||||
|
||||
n_urls = self.data['settings']['application'].get('notification_urls')
|
||||
if n_urls:
|
||||
for i, url in enumerate(n_urls):
|
||||
self.data['settings']['application']['notification_urls'][i] = re.sub(r, r'{{\1}}', url)
|
||||
|
||||
return
|
||||
|
||||
# Some setups may have missed the correct default, so it shows the wrong config in the UI, although it will default to system-wide
|
||||
def update_10(self):
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
if not watch.get('fetch_backend', ''):
|
||||
watch['fetch_backend'] = 'system'
|
||||
except:
|
||||
continue
|
||||
return
|
||||
|
||||
# We don't know when the date_created was in the past until now, so just add an index number for now.
|
||||
def update_11(self):
|
||||
i = 0
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
if not watch.get('date_created'):
|
||||
watch['date_created'] = i
|
||||
i+=1
|
||||
return
|
||||
|
||||
|
||||