Compare commits
28 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6e40278566 | ||
|
|
8c8d4066d7 | ||
|
|
277dc9e1c1 | ||
|
|
fc0fd1ce9d | ||
|
|
bd6127728a | ||
|
|
4101ae00c6 | ||
|
|
62f14df3cb | ||
|
|
560d465c59 | ||
|
|
7929aeddfc | ||
|
|
8294519f43 | ||
|
|
8ba8a220b6 | ||
|
|
aa3c8a9370 | ||
|
|
dbb5468cdc | ||
|
|
329c7620fb | ||
|
|
1f974bfbb0 | ||
|
|
437c8525af | ||
|
|
a2a1d5ae90 | ||
|
|
2566de2aae | ||
|
|
dfec8dbb39 | ||
|
|
5cefb16e52 | ||
|
|
341ae24b73 | ||
|
|
f47c2fb7f6 | ||
|
|
9d742446ab | ||
|
|
e3e022b0f4 | ||
|
|
6de4027c27 | ||
|
|
cda3837355 | ||
|
|
7983675325 | ||
|
|
eef56e52c6 |
@@ -1,9 +1,9 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Create a report to help us improve
|
||||
about: Create a bug report, if you don't follow this template, your report will be DELETED
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
labels: 'triage'
|
||||
assignees: 'dgtlmoon'
|
||||
|
||||
---
|
||||
|
||||
@@ -11,15 +11,18 @@ assignees: ''
|
||||
A clear and concise description of what the bug is.
|
||||
|
||||
**Version**
|
||||
In the top right area: 0....
|
||||
*Exact version* in the top right area: 0....
|
||||
|
||||
**To Reproduce**
|
||||
|
||||
Steps to reproduce the behavior:
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
4. See error
|
||||
|
||||
! ALWAYS INCLUDE AN EXAMPLE URL WHERE IT IS POSSIBLE TO RE-CREATE THE ISSUE !
|
||||
|
||||
**Expected behavior**
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
title: '[feature]'
|
||||
labels: 'enhancement'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
@@ -8,5 +8,6 @@ __pycache__
|
||||
build
|
||||
dist
|
||||
venv
|
||||
test-datastore
|
||||
*.egg-info*
|
||||
.vscode/settings.json
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
recursive-include changedetectionio/api *
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/model *
|
||||
|
||||
@@ -12,7 +12,7 @@ Live your data-life *pro-actively* instead of *re-actively*.
|
||||
Free, Open-source web page monitoring, notification and change detection. Don't have time? [**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
@@ -48,12 +48,19 @@ _Need an actual Chrome runner with Javascript support? We support fetching via W
|
||||
|
||||
## Screenshots
|
||||
|
||||
Examining differences in content.
|
||||
### Examine differences in content.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
### Target elements with the Visual Selector tool.
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (available also as part of our subscription service)
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
## Installation
|
||||
|
||||
@@ -129,7 +136,7 @@ Just some examples
|
||||
|
||||
<a href="https://github.com/caronc/apprise#popular-notification-services">And everything else in this list!</a>
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
|
||||
Now you can also customise your notification content!
|
||||
|
||||
@@ -137,11 +144,11 @@ Now you can also customise your notification content!
|
||||
|
||||
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||
|
||||

|
||||

|
||||
|
||||
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
|
||||
|
||||

|
||||
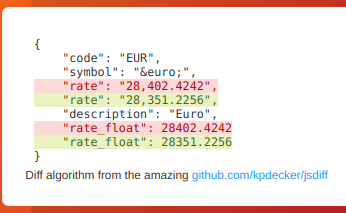
|
||||
|
||||
### Parse JSON embedded in HTML!
|
||||
|
||||
@@ -177,7 +184,7 @@ Or directly donate an amount PayPal [:
|
||||
global datastore
|
||||
datastore = datastore_o
|
||||
|
||||
# so far just for read-only via tests, but this will be moved eventually to be the main source
|
||||
# (instead of the global var)
|
||||
app.config['DATASTORE']=datastore_o
|
||||
|
||||
#app.config.update(config or {})
|
||||
|
||||
login_manager = flask_login.LoginManager(app)
|
||||
@@ -317,25 +322,19 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
for watch in sorted_watches:
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
dates = list(watch.history.keys())
|
||||
# Re #521 - Don't bother processing this one if theres less than 2 snapshots, means we never had a change detected.
|
||||
if len(dates) < 2:
|
||||
continue
|
||||
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
prev_fname = watch['history'][dates[1]]
|
||||
prev_fname = watch.history[dates[-2]]
|
||||
|
||||
if not watch['viewed']:
|
||||
if not watch.viewed:
|
||||
# Re #239 - GUID needs to be individual for each event
|
||||
# @todo In the future make this a configurable link back (see work on BASE_URL https://github.com/dgtlmoon/changedetection.io/pull/228)
|
||||
guid = "{}/{}".format(watch['uuid'], watch['last_changed'])
|
||||
fe = fg.add_entry()
|
||||
|
||||
|
||||
# Include a link to the diff page, they will have to login here to see if password protection is enabled.
|
||||
# Description is the page you watch, link takes you to the diff JS UI page
|
||||
base_url = datastore.data['settings']['application']['base_url']
|
||||
@@ -350,13 +349,15 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
watch_title = watch.get('title') if watch.get('title') else watch.get('url')
|
||||
fe.title(title=watch_title)
|
||||
latest_fname = watch['history'][dates[0]]
|
||||
latest_fname = watch.history[dates[-1]]
|
||||
|
||||
html_diff = diff.render_diff(prev_fname, latest_fname, include_equal=False, line_feed_sep="</br>")
|
||||
fe.description(description="<![CDATA[<html><body><h4>{}</h4>{}</body></html>".format(watch_title, html_diff))
|
||||
fe.description(description="<![CDATA["
|
||||
"<html><body><h4>{}</h4>{}</body></html>"
|
||||
"]]>".format(watch_title, html_diff))
|
||||
|
||||
fe.guid(guid, permalink=False)
|
||||
dt = datetime.datetime.fromtimestamp(int(watch['newest_history_key']))
|
||||
dt = datetime.datetime.fromtimestamp(int(watch.newest_history_key))
|
||||
dt = dt.replace(tzinfo=pytz.UTC)
|
||||
fe.pubDate(dt)
|
||||
|
||||
@@ -415,11 +416,13 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
tags=existing_tags,
|
||||
active_tag=limit_tag,
|
||||
app_rss_token=datastore.data['settings']['application']['rss_access_token'],
|
||||
has_unviewed=datastore.data['has_unviewed'],
|
||||
has_unviewed=datastore.has_unviewed,
|
||||
# Don't link to hosting when we're on the hosting environment
|
||||
hosted_sticky=os.getenv("SALTED_PASS", False) == False,
|
||||
guid=datastore.data['app_guid'],
|
||||
queued_uuids=update_q.queue)
|
||||
|
||||
|
||||
if session.get('share-link'):
|
||||
del(session['share-link'])
|
||||
return output
|
||||
@@ -491,10 +494,10 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# 0 means that theres only one, so that there should be no 'unviewed' history available
|
||||
if newest_history_key == 0:
|
||||
newest_history_key = list(datastore.data['watching'][uuid]['history'].keys())[0]
|
||||
newest_history_key = list(datastore.data['watching'][uuid].history.keys())[0]
|
||||
|
||||
if newest_history_key:
|
||||
with open(datastore.data['watching'][uuid]['history'][newest_history_key],
|
||||
with open(datastore.data['watching'][uuid].history[newest_history_key],
|
||||
encoding='utf-8') as file:
|
||||
raw_content = file.read()
|
||||
|
||||
@@ -588,12 +591,12 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
|
||||
if form_ignore_text:
|
||||
if len(datastore.data['watching'][uuid]['history']):
|
||||
if len(datastore.data['watching'][uuid].history):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
|
||||
if form.css_filter.data.strip() != datastore.data['watching'][uuid]['css_filter']:
|
||||
if len(datastore.data['watching'][uuid]['history']):
|
||||
if len(datastore.data['watching'][uuid].history):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
# Be sure proxy value is None
|
||||
@@ -748,15 +751,14 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
return output
|
||||
|
||||
# Clear all statuses, so we do not see the 'unviewed' class
|
||||
@app.route("/api/mark-all-viewed", methods=['GET'])
|
||||
@app.route("/form/mark-all-viewed", methods=['GET'])
|
||||
@login_required
|
||||
def mark_all_viewed():
|
||||
|
||||
# Save the current newest history as the most recently viewed
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
datastore.set_last_viewed(watch_uuid, watch['newest_history_key'])
|
||||
datastore.set_last_viewed(watch_uuid, int(time.time()))
|
||||
|
||||
flash("Cleared all statuses.")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
@app.route("/diff/<string:uuid>", methods=['GET'])
|
||||
@@ -774,20 +776,17 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
flash("No history found for the specified link, bad link?", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
history = watch.history
|
||||
dates = list(history.keys())
|
||||
|
||||
if len(dates) < 2:
|
||||
flash("Not enough saved change detection snapshots to produce a report.", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
# Save the current newest history as the most recently viewed
|
||||
datastore.set_last_viewed(uuid, dates[0])
|
||||
newest_file = watch['history'][dates[0]]
|
||||
datastore.set_last_viewed(uuid, time.time())
|
||||
|
||||
newest_file = history[dates[-1]]
|
||||
|
||||
try:
|
||||
with open(newest_file, 'r') as f:
|
||||
@@ -797,10 +796,10 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
previous_version = request.args.get('previous_version')
|
||||
try:
|
||||
previous_file = watch['history'][previous_version]
|
||||
previous_file = history[previous_version]
|
||||
except KeyError:
|
||||
# Not present, use a default value, the second one in the sorted list.
|
||||
previous_file = watch['history'][dates[1]]
|
||||
previous_file = history[dates[-2]]
|
||||
|
||||
try:
|
||||
with open(previous_file, 'r') as f:
|
||||
@@ -817,7 +816,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
extra_stylesheets=extra_stylesheets,
|
||||
versions=dates[1:],
|
||||
uuid=uuid,
|
||||
newest_version_timestamp=dates[0],
|
||||
newest_version_timestamp=dates[-1],
|
||||
current_previous_version=str(previous_version),
|
||||
current_diff_url=watch['url'],
|
||||
extra_title=" - Diff - {}".format(watch['title'] if watch['title'] else watch['url']),
|
||||
@@ -845,9 +844,9 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
flash("No history found for the specified link, bad link?", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
if len(watch['history']):
|
||||
timestamps = sorted(watch['history'].keys(), key=lambda x: int(x))
|
||||
filename = watch['history'][timestamps[-1]]
|
||||
if watch.history_n >0:
|
||||
timestamps = sorted(watch.history.keys(), key=lambda x: int(x))
|
||||
filename = watch.history[timestamps[-1]]
|
||||
try:
|
||||
with open(filename, 'r') as f:
|
||||
tmp = f.readlines()
|
||||
@@ -1141,6 +1140,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# copy it to memory as trim off what we dont need (history)
|
||||
watch = deepcopy(datastore.data['watching'][uuid])
|
||||
# For older versions that are not a @property
|
||||
if (watch.get('history')):
|
||||
del (watch['history'])
|
||||
|
||||
@@ -1170,7 +1170,8 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
|
||||
except Exception as e:
|
||||
flash("Could not share, something went wrong while communicating with the share server.", 'error')
|
||||
logging.error("Error sharing -{}".format(str(e)))
|
||||
flash("Could not share, something went wrong while communicating with the share server - {}".format(str(e)), 'error')
|
||||
|
||||
# https://changedetection.io/share/VrMv05wpXyQa
|
||||
# in the browser - should give you a nice info page - wtf
|
||||
@@ -1232,7 +1233,7 @@ def notification_runner():
|
||||
notification.process_notification(n_object, datastore)
|
||||
|
||||
except Exception as e:
|
||||
print("Watch URL: {} Error {}".format(n_object['watch_url'], str(e)))
|
||||
logging.error("Watch URL: {} Error {}".format(n_object['watch_url'], str(e)))
|
||||
|
||||
# UUID wont be present when we submit a 'test' from the global settings
|
||||
if 'uuid' in n_object:
|
||||
@@ -1249,6 +1250,7 @@ def notification_runner():
|
||||
# Thread runner to check every minute, look for new watches to feed into the Queue.
|
||||
def ticker_thread_check_time_launch_checks():
|
||||
from changedetectionio import update_worker
|
||||
import logging
|
||||
|
||||
# Spin up Workers that do the fetching
|
||||
# Can be overriden by ENV or use the default settings
|
||||
@@ -1267,9 +1269,10 @@ def ticker_thread_check_time_launch_checks():
|
||||
running_uuids.append(t.current_uuid)
|
||||
|
||||
# Re #232 - Deepcopy the data incase it changes while we're iterating through it all
|
||||
watch_uuid_list = []
|
||||
while True:
|
||||
try:
|
||||
copied_datastore = deepcopy(datastore)
|
||||
watch_uuid_list = datastore.data['watching'].keys()
|
||||
except RuntimeError as e:
|
||||
# RuntimeError: dictionary changed size during iteration
|
||||
time.sleep(0.1)
|
||||
@@ -1286,7 +1289,12 @@ def ticker_thread_check_time_launch_checks():
|
||||
recheck_time_minimum_seconds = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
recheck_time_system_seconds = datastore.threshold_seconds
|
||||
|
||||
for uuid, watch in copied_datastore.data['watching'].items():
|
||||
for uuid in watch_uuid_list:
|
||||
|
||||
watch = datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
logging.error("Watch: {} no longer present.".format(uuid))
|
||||
continue
|
||||
|
||||
# No need todo further processing if it's paused
|
||||
if watch['paused']:
|
||||
|
||||
@@ -28,8 +28,7 @@ class Watch(Resource):
|
||||
return "OK", 200
|
||||
|
||||
# Return without history, get that via another API call
|
||||
watch['history_n'] = len(watch['history'])
|
||||
del (watch['history'])
|
||||
watch['history_n'] = watch.history_n
|
||||
return watch
|
||||
|
||||
@auth.check_token
|
||||
@@ -52,7 +51,7 @@ class WatchHistory(Resource):
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
return watch['history'], 200
|
||||
return watch.history, 200
|
||||
|
||||
|
||||
class WatchSingleHistory(Resource):
|
||||
@@ -69,13 +68,13 @@ class WatchSingleHistory(Resource):
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if not len(watch['history']):
|
||||
if not len(watch.history):
|
||||
abort(404, message='Watch found but no history exists for the UUID {}'.format(uuid))
|
||||
|
||||
if timestamp == 'latest':
|
||||
timestamp = list(watch['history'].keys())[-1]
|
||||
timestamp = list(watch.history.keys())[-1]
|
||||
|
||||
with open(watch['history'][timestamp], 'r') as f:
|
||||
with open(watch.history[timestamp], 'r') as f:
|
||||
content = f.read()
|
||||
|
||||
response = make_response(content, 200)
|
||||
|
||||
@@ -1,10 +1,19 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import chardet
|
||||
import json
|
||||
import os
|
||||
import requests
|
||||
import time
|
||||
import sys
|
||||
|
||||
class PageUnloadable(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
pass
|
||||
|
||||
class EmptyReply(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
@@ -13,6 +22,14 @@ class EmptyReply(Exception):
|
||||
return
|
||||
pass
|
||||
|
||||
class ScreenshotUnavailable(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
pass
|
||||
|
||||
class ReplyWithContentButNoText(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
@@ -89,14 +106,22 @@ class Fetcher():
|
||||
xpath_result =d;
|
||||
}
|
||||
} catch (e) {
|
||||
var x=1;
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
xpath_result = getXPath(elements[i]);
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getXPath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if(window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
@@ -115,13 +140,23 @@ class Fetcher():
|
||||
// inject the current one set in the css_filter, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (css_filter.length) {
|
||||
// is it xpath?
|
||||
if (css_filter.startsWith('/') ) {
|
||||
q=document.evaluate(css_filter, document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q=document.querySelector(css_filter);
|
||||
q=false;
|
||||
try {
|
||||
// is it xpath?
|
||||
if (css_filter.startsWith('/') || css_filter.startsWith('xpath:')) {
|
||||
q=document.evaluate(css_filter.replace('xpath:',''), document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q=document.querySelector(css_filter);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log(e);
|
||||
}
|
||||
bbox = q.getBoundingClientRect();
|
||||
bbox=false;
|
||||
if(q) {
|
||||
bbox = q.getBoundingClientRect();
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] >0 && bbox['height']>0) {
|
||||
size_pos.push({
|
||||
xpath: css_filter,
|
||||
@@ -133,8 +168,8 @@ class Fetcher():
|
||||
});
|
||||
}
|
||||
}
|
||||
// https://stackoverflow.com/questions/1145850/how-to-get-height-of-entire-document-with-javascript
|
||||
return {'size_pos':size_pos, 'browser_width': window.innerWidth, 'browser_height':document.body.scrollHeight};
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos':size_pos, 'browser_width': window.innerWidth};
|
||||
"""
|
||||
xpath_data = None
|
||||
|
||||
@@ -258,8 +293,13 @@ class base_html_playwright(Fetcher):
|
||||
# Use the default one configured in the App.py model that's passed from fetch_site_status.py
|
||||
context = browser.new_context(
|
||||
user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
proxy=self.proxy
|
||||
proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should never be needed
|
||||
accept_downloads=False
|
||||
)
|
||||
|
||||
page = context.new_page()
|
||||
try:
|
||||
# Bug - never set viewport size BEFORE page.goto
|
||||
@@ -271,34 +311,48 @@ class base_html_playwright(Fetcher):
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
page.wait_for_timeout(extra_wait * 1000)
|
||||
except playwright._impl._api_types.TimeoutError as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None)
|
||||
|
||||
if response is None:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
if len(page.content().strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
# Bug 2(?) Set the viewport size AFTER loading the page
|
||||
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
# Bugish - Let the page redraw/reflow
|
||||
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
|
||||
self.status_code = response.status
|
||||
self.content = page.content()
|
||||
self.headers = response.all_headers()
|
||||
|
||||
if current_css_filter is not None:
|
||||
page.evaluate("var css_filter='{}'".format(current_css_filter))
|
||||
page.evaluate("var css_filter={}".format(json.dumps(current_css_filter)))
|
||||
else:
|
||||
page.evaluate("var css_filter=''")
|
||||
|
||||
self.xpath_data = page.evaluate("async () => {" + self.xpath_element_js + "}")
|
||||
|
||||
# Bug 3 in Playwright screenshot handling
|
||||
# Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
|
||||
# JPEG is better here because the screenshots can be very very large
|
||||
page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
|
||||
self.screenshot = page.screenshot(type='jpeg', full_page=True, quality=92)
|
||||
try:
|
||||
page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
|
||||
self.screenshot = page.screenshot(type='jpeg', full_page=True, quality=92)
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
context.close()
|
||||
browser.close()
|
||||
|
||||
@@ -204,6 +204,20 @@ class perform_site_check():
|
||||
else:
|
||||
stripped_text_from_html = stripped_text_from_html.encode('utf8')
|
||||
|
||||
# 615 Extract text by regex
|
||||
extract_text = watch.get('extract_text', [])
|
||||
if len(extract_text) > 0:
|
||||
regex_matched_output = []
|
||||
for s_re in extract_text:
|
||||
result = re.findall(s_re.encode('utf8'), stripped_text_from_html,
|
||||
flags=re.MULTILINE | re.DOTALL | re.LOCALE)
|
||||
if result:
|
||||
regex_matched_output.append(result[0])
|
||||
|
||||
if regex_matched_output:
|
||||
stripped_text_from_html = b'\n'.join(regex_matched_output)
|
||||
text_content_before_ignored_filter = stripped_text_from_html
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
@@ -221,9 +235,11 @@ class perform_site_check():
|
||||
# Yeah, lets block first until something matches
|
||||
blocked_by_not_found_trigger_text = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
# It should return the line numbers that match
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['trigger_text'],
|
||||
mode="line numbers")
|
||||
# If it returned any lines that matched..
|
||||
if result:
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
|
||||
@@ -223,7 +223,7 @@ class validateURL(object):
|
||||
except validators.ValidationFailure:
|
||||
message = field.gettext('\'%s\' is not a valid URL.' % (field.data.strip()))
|
||||
raise ValidationError(message)
|
||||
|
||||
|
||||
class ValidateListRegex(object):
|
||||
"""
|
||||
Validates that anything that looks like a regex passes as a regex
|
||||
@@ -307,7 +307,7 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
|
||||
class quickWatchForm(Form):
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)])
|
||||
tag = StringField('Group tag', [validators.Optional()])
|
||||
|
||||
# Common to a single watch and the global settings
|
||||
class commonSettingsForm(Form):
|
||||
@@ -323,13 +323,16 @@ class commonSettingsForm(Form):
|
||||
class watchForm(commonSettingsForm):
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)], default='')
|
||||
tag = StringField('Group tag', [validators.Optional()], default='')
|
||||
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
|
||||
css_filter = StringField('CSS/JSON/XPATH Filter', [ValidateCSSJSONXPATHInput()], default='')
|
||||
|
||||
subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
|
||||
extract_text = StringListField('Extract text', [ValidateListRegex()])
|
||||
|
||||
title = StringField('Title', default='')
|
||||
|
||||
ignore_text = StringListField('Ignore text', [ValidateListRegex()])
|
||||
|
||||
@@ -92,7 +92,7 @@ class import_distill_io_json(Importer):
|
||||
|
||||
for d in data.get('data'):
|
||||
d_config = json.loads(d['config'])
|
||||
extras = {'title': d['name']}
|
||||
extras = {'title': d.get('name', None)}
|
||||
|
||||
if len(d['uri']) and good < 5000:
|
||||
try:
|
||||
@@ -114,12 +114,9 @@ class import_distill_io_json(Importer):
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
try:
|
||||
|
||||
if d.get('tags', False):
|
||||
extras['tag'] = ", ".join(d['tags'])
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
new_uuid = datastore.add_watch(url=d['uri'].strip(),
|
||||
extras=extras,
|
||||
|
||||
@@ -35,7 +35,7 @@ class model(dict):
|
||||
'fetch_backend': os.getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'global_ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'global_subtractive_selectors': [],
|
||||
'ignore_whitespace': False,
|
||||
'ignore_whitespace': True,
|
||||
'render_anchor_tag_content': False,
|
||||
'notification_urls': [], # Apprise URL list
|
||||
# Custom notification content
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import os
|
||||
|
||||
import uuid as uuid_builder
|
||||
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
@@ -12,29 +11,32 @@ from changedetectionio.notification import (
|
||||
|
||||
|
||||
class model(dict):
|
||||
base_config = {
|
||||
__newest_history_key = None
|
||||
__history_n=0
|
||||
|
||||
__base_config = {
|
||||
'url': None,
|
||||
'tag': None,
|
||||
'last_checked': 0,
|
||||
'last_changed': 0,
|
||||
'paused': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'newest_history_key': 0,
|
||||
#'newest_history_key': 0,
|
||||
'title': None,
|
||||
'previous_md5': False,
|
||||
# UUID not needed, should be generated only as a key
|
||||
# 'uuid':
|
||||
'uuid': str(uuid_builder.uuid4()),
|
||||
'headers': {}, # Extra headers to send
|
||||
'body': None,
|
||||
'method': 'GET',
|
||||
'history': {}, # Dict of timestamp and output stripped filename
|
||||
#'history': {}, # Dict of timestamp and output stripped filename
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
# Custom notification content
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'css_filter': "",
|
||||
'css_filter': '',
|
||||
'extract_text': [], # Extract text by regex after filters
|
||||
'subtractive_selectors': [],
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'fetch_backend': None,
|
||||
@@ -48,10 +50,103 @@ class model(dict):
|
||||
}
|
||||
|
||||
def __init__(self, *arg, **kw):
|
||||
self.update(self.base_config)
|
||||
import uuid
|
||||
self.update(self.__base_config)
|
||||
self.__datastore_path = kw['datastore_path']
|
||||
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
del kw['datastore_path']
|
||||
|
||||
if kw.get('default'):
|
||||
self.update(kw['default'])
|
||||
del kw['default']
|
||||
|
||||
# goes at the end so we update the default object with the initialiser
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
|
||||
@property
|
||||
def viewed(self):
|
||||
if int(self['last_viewed']) >= int(self.newest_history_key) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
@property
|
||||
def history_n(self):
|
||||
return self.__history_n
|
||||
|
||||
@property
|
||||
def history(self):
|
||||
tmp_history = {}
|
||||
import logging
|
||||
import time
|
||||
|
||||
# Read the history file as a dict
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
if os.path.isfile(fname):
|
||||
logging.debug("Disk IO accessed " + str(time.time()))
|
||||
with open(fname, "r") as f:
|
||||
tmp_history = dict(i.strip().split(',', 2) for i in f.readlines())
|
||||
|
||||
if len(tmp_history):
|
||||
self.__newest_history_key = list(tmp_history.keys())[-1]
|
||||
|
||||
self.__history_n = len(tmp_history)
|
||||
|
||||
return tmp_history
|
||||
|
||||
@property
|
||||
def has_history(self):
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
return os.path.isfile(fname)
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
@property
|
||||
def newest_history_key(self):
|
||||
if self.__newest_history_key is not None:
|
||||
return self.__newest_history_key
|
||||
|
||||
if len(self.history) <= 1:
|
||||
return 0
|
||||
|
||||
|
||||
bump = self.history
|
||||
return self.__newest_history_key
|
||||
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, contents, timestamp):
|
||||
import uuid
|
||||
from os import mkdir, path, unlink
|
||||
import logging
|
||||
|
||||
output_path = "{}/{}".format(self.__datastore_path, self['uuid'])
|
||||
|
||||
# Incase the operator deleted it, check and create.
|
||||
if not os.path.isdir(output_path):
|
||||
mkdir(output_path)
|
||||
|
||||
snapshot_fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
logging.debug("Saving history text {}".format(snapshot_fname))
|
||||
|
||||
with open(snapshot_fname, 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
# Append to index
|
||||
# @todo check last char was \n
|
||||
index_fname = "{}/history.txt".format(output_path)
|
||||
with open(index_fname, 'a') as f:
|
||||
f.write("{},{}\n".format(timestamp, snapshot_fname))
|
||||
f.close()
|
||||
|
||||
self.__newest_history_key = timestamp
|
||||
self.__history_n+=1
|
||||
|
||||
#@todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
return snapshot_fname
|
||||
|
||||
@property
|
||||
def has_empty_checktime(self):
|
||||
|
||||
@@ -3,8 +3,27 @@
|
||||
|
||||
$(document).ready(function() {
|
||||
|
||||
var current_selected_i;
|
||||
var state_clicked=false;
|
||||
|
||||
var c;
|
||||
|
||||
// greyed out fill context
|
||||
var xctx;
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
|
||||
var current_default_xpath;
|
||||
var x_scale=1;
|
||||
var y_scale=1;
|
||||
var selector_image;
|
||||
var selector_image_rect;
|
||||
var selector_data;
|
||||
|
||||
$('#visualselector-tab').click(function () {
|
||||
$("img#selector-background").off('load');
|
||||
state_clicked = false;
|
||||
current_selected_i = false;
|
||||
bootstrap_visualselector();
|
||||
});
|
||||
|
||||
@@ -30,28 +49,13 @@ $(document).ready(function() {
|
||||
}
|
||||
state_clicked=false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
xctx.clearRect(0, 0, c.width, c.height);
|
||||
$("#css_filter").val('');
|
||||
});
|
||||
|
||||
|
||||
bootstrap_visualselector();
|
||||
|
||||
var current_selected_i;
|
||||
var state_clicked=false;
|
||||
|
||||
var c;
|
||||
|
||||
// greyed out fill context
|
||||
var xctx;
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
|
||||
var current_default_xpath;
|
||||
var x_scale=1;
|
||||
var y_scale=1;
|
||||
var selector_image;
|
||||
var selector_image_rect;
|
||||
var vh;
|
||||
var selector_data;
|
||||
|
||||
|
||||
function bootstrap_visualselector() {
|
||||
@@ -66,7 +70,7 @@ $(document).ready(function() {
|
||||
ctx = c.getContext("2d");
|
||||
current_default_xpath =$("#css_filter").val();
|
||||
fetch_data();
|
||||
$('#selector-canvas').off("mousemove");
|
||||
$('#selector-canvas').off("mousemove mousedown");
|
||||
// screenshot_url defined in the edit.html template
|
||||
}).attr("src", screenshot_url);
|
||||
}
|
||||
@@ -138,7 +142,7 @@ $(document).ready(function() {
|
||||
}
|
||||
}
|
||||
if(!found) {
|
||||
alert("unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
alert("Unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
}
|
||||
}
|
||||
|
||||
@@ -150,6 +154,13 @@ $(document).ready(function() {
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
current_selected_i=null;
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var found=0;
|
||||
|
||||
@@ -40,7 +40,7 @@ class ChangeDetectionStore:
|
||||
|
||||
# Base definition for all watchers
|
||||
# deepcopy part of #569 - not sure why its needed exactly
|
||||
self.generic_definition = deepcopy(Watch.model())
|
||||
self.generic_definition = deepcopy(Watch.model(datastore_path = datastore_path, default={}))
|
||||
|
||||
if path.isfile('changedetectionio/source.txt'):
|
||||
with open('changedetectionio/source.txt') as f:
|
||||
@@ -71,13 +71,10 @@ class ChangeDetectionStore:
|
||||
if 'application' in from_disk['settings']:
|
||||
self.__data['settings']['application'].update(from_disk['settings']['application'])
|
||||
|
||||
# Reinitialise each `watching` with our generic_definition in the case that we add a new var in the future.
|
||||
# @todo pretty sure theres a python we todo this with an abstracted(?) object!
|
||||
# Convert each existing watch back to the Watch.model object
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
_blank = deepcopy(self.generic_definition)
|
||||
_blank.update(watch)
|
||||
self.__data['watching'].update({uuid: _blank})
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
watch['uuid']=uuid
|
||||
self.__data['watching'][uuid] = Watch.model(datastore_path=self.datastore_path, default=watch)
|
||||
print("Watching:", uuid, self.__data['watching'][uuid]['url'])
|
||||
|
||||
# First time ran, doesnt exist.
|
||||
@@ -87,8 +84,7 @@ class ChangeDetectionStore:
|
||||
|
||||
self.add_watch(url='http://www.quotationspage.com/random.php', tag='test')
|
||||
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
||||
self.add_watch(url='https://www.gov.uk/coronavirus', tag='Covid')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt', tag='changedetection.io')
|
||||
|
||||
self.__data['version_tag'] = version_tag
|
||||
|
||||
@@ -131,23 +127,8 @@ class ChangeDetectionStore:
|
||||
# Finally start the thread that will manage periodic data saves to JSON
|
||||
save_data_thread = threading.Thread(target=self.save_datastore).start()
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
def get_newest_history_key(self, uuid):
|
||||
if len(self.__data['watching'][uuid]['history']) == 1:
|
||||
return 0
|
||||
|
||||
dates = list(self.__data['watching'][uuid]['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
if len(dates):
|
||||
# always keyed as str
|
||||
return str(dates[0])
|
||||
|
||||
return 0
|
||||
|
||||
def set_last_viewed(self, uuid, timestamp):
|
||||
logging.debug("Setting watch UUID: {} last viewed to {}".format(uuid, int(timestamp)))
|
||||
self.data['watching'][uuid].update({'last_viewed': int(timestamp)})
|
||||
self.needs_write = True
|
||||
|
||||
@@ -171,7 +152,6 @@ class ChangeDetectionStore:
|
||||
del (update_obj[dict_key])
|
||||
|
||||
self.__data['watching'][uuid].update(update_obj)
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
|
||||
self.needs_write = True
|
||||
|
||||
@@ -186,20 +166,20 @@ class ChangeDetectionStore:
|
||||
seconds += x * n
|
||||
return max(seconds, minimum_seconds_recheck_time)
|
||||
|
||||
@property
|
||||
def has_unviewed(self):
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
if watch.viewed == False:
|
||||
return True
|
||||
return False
|
||||
|
||||
@property
|
||||
def data(self):
|
||||
has_unviewed = False
|
||||
for uuid, v in self.__data['watching'].items():
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
if int(v['newest_history_key']) <= int(v['last_viewed']):
|
||||
self.__data['watching'][uuid]['viewed'] = True
|
||||
|
||||
else:
|
||||
self.__data['watching'][uuid]['viewed'] = False
|
||||
has_unviewed = True
|
||||
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
# #106 - Be sure this is None on empty string, False, None, etc
|
||||
# Default var for fetch_backend
|
||||
# @todo this may not be needed anymore, or could be easily removed
|
||||
if not self.__data['watching'][uuid]['fetch_backend']:
|
||||
self.__data['watching'][uuid]['fetch_backend'] = self.__data['settings']['application']['fetch_backend']
|
||||
|
||||
@@ -208,8 +188,6 @@ class ChangeDetectionStore:
|
||||
if not self.__data['settings']['application']['base_url']:
|
||||
self.__data['settings']['application']['base_url'] = env_base_url.strip('" ')
|
||||
|
||||
self.__data['has_unviewed'] = has_unviewed
|
||||
|
||||
return self.__data
|
||||
|
||||
def get_all_tags(self):
|
||||
@@ -240,11 +218,11 @@ class ChangeDetectionStore:
|
||||
|
||||
# GitHub #30 also delete history records
|
||||
for uuid in self.data['watching']:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
for path in self.data['watching'][uuid].history.values():
|
||||
self.unlink_history_file(path)
|
||||
|
||||
else:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
for path in self.data['watching'][uuid].history.values():
|
||||
self.unlink_history_file(path)
|
||||
|
||||
del self.data['watching'][uuid]
|
||||
@@ -276,13 +254,14 @@ class ChangeDetectionStore:
|
||||
def scrub_watch(self, uuid):
|
||||
import pathlib
|
||||
|
||||
self.__data['watching'][uuid].update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'newest_history_key': 0, 'previous_md5': False})
|
||||
self.__data['watching'][uuid].update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': False})
|
||||
self.needs_write_urgent = True
|
||||
|
||||
for item in pathlib.Path(self.datastore_path).rglob(uuid+"/*.txt"):
|
||||
unlink(item)
|
||||
|
||||
def add_watch(self, url, tag="", extras=None, write_to_disk_now=True):
|
||||
|
||||
if extras is None:
|
||||
extras = {}
|
||||
# should always be str
|
||||
@@ -308,7 +287,7 @@ class ChangeDetectionStore:
|
||||
'body', 'method',
|
||||
'ignore_text', 'css_filter',
|
||||
'subtractive_selectors', 'trigger_text',
|
||||
'extract_title_as_title']:
|
||||
'extract_title_as_title', 'extract_text']:
|
||||
if res.get(k):
|
||||
apply_extras[k] = res[k]
|
||||
|
||||
@@ -318,16 +297,15 @@ class ChangeDetectionStore:
|
||||
return False
|
||||
|
||||
with self.lock:
|
||||
# @todo use a common generic version of this
|
||||
new_uuid = str(uuid_builder.uuid4())
|
||||
|
||||
# #Re 569
|
||||
# Not sure why deepcopy was needed here, sometimes new watches would appear to already have 'history' set
|
||||
# I assumed this would instantiate a new object but somehow an existing dict was getting used
|
||||
new_watch = deepcopy(Watch.model({
|
||||
new_watch = Watch.model(datastore_path=self.datastore_path, default={
|
||||
'url': url,
|
||||
'tag': tag
|
||||
}))
|
||||
})
|
||||
|
||||
new_uuid = new_watch['uuid']
|
||||
logging.debug("Added URL {} - {}".format(url, new_uuid))
|
||||
|
||||
for k in ['uuid', 'history', 'last_checked', 'last_changed', 'newest_history_key', 'previous_md5', 'viewed']:
|
||||
if k in apply_extras:
|
||||
@@ -347,23 +325,6 @@ class ChangeDetectionStore:
|
||||
self.sync_to_json()
|
||||
return new_uuid
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, watch_uuid, contents):
|
||||
import uuid
|
||||
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
# Incase the operator deleted it, check and create.
|
||||
if not os.path.isdir(output_path):
|
||||
mkdir(output_path)
|
||||
|
||||
fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
with open(fname, 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
return fname
|
||||
|
||||
def get_screenshot(self, watch_uuid):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
fname = "{}/last-screenshot.png".format(output_path)
|
||||
@@ -449,8 +410,8 @@ class ChangeDetectionStore:
|
||||
|
||||
index=[]
|
||||
for uuid in self.data['watching']:
|
||||
for id in self.data['watching'][uuid]['history']:
|
||||
index.append(self.data['watching'][uuid]['history'][str(id)])
|
||||
for id in self.data['watching'][uuid].history:
|
||||
index.append(self.data['watching'][uuid].history[str(id)])
|
||||
|
||||
import pathlib
|
||||
|
||||
@@ -521,3 +482,28 @@ class ChangeDetectionStore:
|
||||
# Only upgrade individual watch time if it was set
|
||||
if watch.get('minutes_between_check', False):
|
||||
self.data['watching'][uuid]['time_between_check']['minutes'] = watch['minutes_between_check']
|
||||
|
||||
# Move the history list to a flat text file index
|
||||
# Better than SQLite because this list is only appended to, and works across NAS / NFS type setups
|
||||
def update_2(self):
|
||||
# @todo test running this on a newly updated one (when this already ran)
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
history = []
|
||||
|
||||
if watch.get('history', False):
|
||||
for d, p in watch['history'].items():
|
||||
d = int(d) # Used to be keyed as str, we'll fix this now too
|
||||
history.append("{},{}\n".format(d,p))
|
||||
|
||||
if len(history):
|
||||
target_path = os.path.join(self.datastore_path, uuid)
|
||||
if os.path.exists(target_path):
|
||||
with open(os.path.join(target_path, "history.txt"), "w") as f:
|
||||
f.writelines(history)
|
||||
else:
|
||||
logging.warning("Datastore history directory {} does not exist, skipping history import.".format(target_path))
|
||||
|
||||
# No longer needed, dynamically pulled from the disk when needed.
|
||||
# But we should set it back to a empty dict so we don't break if this schema runs on an earlier version.
|
||||
# In the distant future we can remove this entirely
|
||||
self.data['watching'][uuid]['history'] = {}
|
||||
|
||||
@@ -199,6 +199,17 @@ nav
|
||||
</span>
|
||||
</div>
|
||||
</fieldset>
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.extract_text, rows=5, placeholder="\d+ online") }}
|
||||
<span class="pure-form-message-inline">
|
||||
<ul>
|
||||
<li>Extracts text in the final output after other filters using regular expressions, for example <code>\d+ online</code></li>
|
||||
<li>One line per regular-expression.</li>
|
||||
</ul>
|
||||
</span>
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner visual-selector-ui" id="visualselector">
|
||||
|
||||
@@ -46,7 +46,7 @@
|
||||
{% if watch.last_error is defined and watch.last_error != False %}error{% endif %}
|
||||
{% if watch.last_notification_error is defined and watch.last_notification_error != False %}error{% endif %}
|
||||
{% if watch.paused is defined and watch.paused != False %}paused{% endif %}
|
||||
{% if watch.newest_history_key| int > watch.last_viewed| int %}unviewed{% endif %}
|
||||
{% if watch.newest_history_key| int > watch.last_viewed and watch.history_n>=2 %}unviewed{% endif %}
|
||||
{% if watch.uuid in queued_uuids %}queued{% endif %}">
|
||||
<td class="inline">{{ loop.index }}</td>
|
||||
<td class="inline paused-state state-{{watch.paused}}"><a href="{{url_for('index', pause=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='pause.svg')}}" alt="Pause" title="Pause"/></a></td>
|
||||
@@ -68,7 +68,7 @@
|
||||
{% endif %}
|
||||
</td>
|
||||
<td class="last-checked">{{watch|format_last_checked_time}}</td>
|
||||
<td class="last-changed">{% if watch.history|length >= 2 and watch.last_changed %}
|
||||
<td class="last-changed">{% if watch.history_n >=2 and watch.last_changed %}
|
||||
{{watch.last_changed|format_timestamp_timeago}}
|
||||
{% else %}
|
||||
Not yet
|
||||
@@ -78,10 +78,10 @@
|
||||
<a {% if watch.uuid in queued_uuids %}disabled="true"{% endif %} href="{{ url_for('form_watch_checknow', uuid=watch.uuid, tag=request.args.get('tag')) }}"
|
||||
class="recheck pure-button button-small pure-button-primary">{% if watch.uuid in queued_uuids %}Queued{% else %}Recheck{% endif %}</a>
|
||||
<a href="{{ url_for('edit_page', uuid=watch.uuid)}}" class="pure-button button-small pure-button-primary">Edit</a>
|
||||
{% if watch.history|length >= 2 %}
|
||||
{% if watch.history_n >= 2 %}
|
||||
<a href="{{ url_for('diff_history_page', uuid=watch.uuid) }}" target="{{watch.uuid}}" class="pure-button button-small pure-button-primary diff-link">Diff</a>
|
||||
{% else %}
|
||||
{% if watch.history|length == 1 %}
|
||||
{% if watch.history_n == 1 %}
|
||||
<a href="{{ url_for('preview_page', uuid=watch.uuid)}}" target="{{watch.uuid}}" class="pure-button button-small pure-button-primary">Preview</a>
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from .util import live_server_setup
|
||||
from .util import live_server_setup, extract_api_key_from_UI
|
||||
|
||||
import json
|
||||
import uuid
|
||||
@@ -53,23 +53,10 @@ def is_valid_uuid(val):
|
||||
return False
|
||||
|
||||
|
||||
# kinda funky, but works for now
|
||||
def _extract_api_key_from_UI(client):
|
||||
import re
|
||||
res = client.get(
|
||||
url_for("settings_page"),
|
||||
)
|
||||
# <span id="api-key">{{api_key}}</span>
|
||||
|
||||
m = re.search('<span id="api-key">(.+?)</span>', str(res.data))
|
||||
api_key = m.group(1)
|
||||
return api_key.strip()
|
||||
|
||||
|
||||
def test_api_simple(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
api_key = _extract_api_key_from_UI(client)
|
||||
api_key = extract_api_key_from_UI(client)
|
||||
|
||||
# Create a watch
|
||||
set_original_response()
|
||||
|
||||
@@ -3,14 +3,15 @@
|
||||
import time
|
||||
from flask import url_for
|
||||
from urllib.request import urlopen
|
||||
from . util import set_original_response, set_modified_response, live_server_setup
|
||||
from .util import set_original_response, set_modified_response, live_server_setup
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
|
||||
# Basic test to check inscriptus is not adding return line chars, basically works etc
|
||||
def test_inscriptus():
|
||||
from inscriptis import get_text
|
||||
html_content="<html><body>test!<br/>ok man</body></html>"
|
||||
html_content = "<html><body>test!<br/>ok man</body></html>"
|
||||
stripped_text_from_html = get_text(html_content)
|
||||
assert stripped_text_from_html == 'test!\nok man'
|
||||
|
||||
@@ -82,7 +83,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# re #16 should have the diff in here too
|
||||
assert b'(into ) which has this one new line' in res.data
|
||||
assert b'CDATA' in res.data
|
||||
|
||||
|
||||
assert expected_url.encode('utf-8') in res.data
|
||||
|
||||
# Following the 'diff' link, it should no longer display as 'unviewed' even after we recheck it a few times
|
||||
@@ -101,7 +102,8 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
assert b'head title' not in res.data # Should not be present because this is off by default
|
||||
assert b'Mark all viewed' not in res.data
|
||||
assert b'head title' not in res.data # Should not be present because this is off by default
|
||||
assert b'test-endpoint' in res.data
|
||||
|
||||
set_original_response()
|
||||
@@ -109,7 +111,8 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# Enable auto pickup of <title> in settings
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-extract_title_as_title": "1", "requests-time_between_check-minutes": 180, 'application-fetch_backend': "html_requests"},
|
||||
data={"application-extract_title_as_title": "1", "requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -118,11 +121,18 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
assert b'Mark all viewed' in res.data
|
||||
|
||||
# It should have picked up the <title>
|
||||
assert b'head title' in res.data
|
||||
|
||||
# hit the mark all viewed link
|
||||
res = client.get(url_for("mark_all_viewed"), follow_redirects=True)
|
||||
|
||||
assert b'Mark all viewed' not in res.data
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
#
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
@@ -150,9 +150,8 @@ def test_element_removal_full(client, live_server):
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# No change yet - first check
|
||||
res = client.get(url_for("index"))
|
||||
assert b"unviewed" not in res.data
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Make a change to header/footer/nav
|
||||
set_modified_response()
|
||||
|
||||
@@ -0,0 +1,127 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from .util import live_server_setup
|
||||
|
||||
from ..html_tools import *
|
||||
|
||||
|
||||
def set_original_response():
|
||||
test_return_data = """<html>
|
||||
<body>
|
||||
Some initial text</br>
|
||||
<p>Which is across multiple lines</p>
|
||||
</br>
|
||||
So let's see what happens. </br>
|
||||
<div id="sametext">Some text thats the same</div>
|
||||
<div id="changetext">Some text that will change</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(test_return_data)
|
||||
return None
|
||||
|
||||
|
||||
def set_modified_response():
|
||||
test_return_data = """<html>
|
||||
<body>
|
||||
Some initial text</br>
|
||||
<p>which has this one new line</p>
|
||||
</br>
|
||||
So let's see what happens. </br>
|
||||
<div id="sametext">Some text thats the same</div>
|
||||
<div id="changetext">Some text that did change ( 1000 online <br/> 80 guests)</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(test_return_data)
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def test_check_filter_and_regex_extract(client, live_server):
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
live_server_setup(live_server)
|
||||
css_filter = "#changetext"
|
||||
|
||||
set_original_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# Goto the edit page, add our ignore text
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": css_filter,
|
||||
'extract_text': '\d+ online\n\d+ guests',
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
'fetch_backend': "html_requests"
|
||||
},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Check it saved
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert b'\d+ online' in res.data
|
||||
|
||||
# Trigger a check
|
||||
# client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# Make a change
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should have 'unviewed' still
|
||||
# Because it should be looking at only that 'sametext' id
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
# Check HTML conversion detected and workd
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Class will be blank for now because the frontend didnt apply the diff
|
||||
assert b'<div class="">1000 online' in res.data
|
||||
|
||||
# Both regexs should be here
|
||||
assert b'<div class="">80 guests' in res.data
|
||||
|
||||
# Should not be here
|
||||
assert b'Some text that did change' not in res.data
|
||||
@@ -0,0 +1,84 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from flask import url_for
|
||||
from .util import live_server_setup
|
||||
from urllib.parse import urlparse, parse_qs
|
||||
|
||||
def test_consistent_history(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
r = range(1, 50)
|
||||
|
||||
for one in r:
|
||||
test_url = url_for('test_endpoint', content_type="text/html", content=str(one), _external=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
time.sleep(3)
|
||||
while True:
|
||||
res = client.get(url_for("index"))
|
||||
logging.debug("Waiting for 'Checking now' to go away..")
|
||||
if b'Checking now' not in res.data:
|
||||
break
|
||||
time.sleep(0.5)
|
||||
|
||||
time.sleep(3)
|
||||
# Essentially just triggers the DB write/update
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-empty_pages_are_a_change": "",
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
# Give it time to write it out
|
||||
time.sleep(3)
|
||||
json_db_file = os.path.join(live_server.app.config['DATASTORE'].datastore_path, 'url-watches.json')
|
||||
|
||||
json_obj = None
|
||||
with open(json_db_file, 'r') as f:
|
||||
json_obj = json.load(f)
|
||||
|
||||
# assert the right amount of watches was found in the JSON
|
||||
assert len(json_obj['watching']) == len(r), "Correct number of watches was found in the JSON"
|
||||
|
||||
# each one should have a history.txt containing just one line
|
||||
for w in json_obj['watching'].keys():
|
||||
history_txt_index_file = os.path.join(live_server.app.config['DATASTORE'].datastore_path, w, 'history.txt')
|
||||
assert os.path.isfile(history_txt_index_file), "History.txt should exist where I expect it - {}".format(history_txt_index_file)
|
||||
|
||||
# Same like in model.Watch
|
||||
with open(history_txt_index_file, "r") as f:
|
||||
tmp_history = dict(i.strip().split(',', 2) for i in f.readlines())
|
||||
assert len(tmp_history) == 1, "History.txt should contain 1 line"
|
||||
|
||||
# Should be two files,. the history.txt , and the snapshot.txt
|
||||
files_in_watch_dir = os.listdir(os.path.join(live_server.app.config['DATASTORE'].datastore_path,
|
||||
w))
|
||||
# Find the snapshot one
|
||||
for fname in files_in_watch_dir:
|
||||
if fname != 'history.txt':
|
||||
# contents should match what we requested as content returned from the test url
|
||||
with open(os.path.join(live_server.app.config['DATASTORE'].datastore_path, w, fname), 'r') as snapshot_f:
|
||||
contents = snapshot_f.read()
|
||||
watch_url = json_obj['watching'][w]['url']
|
||||
u = urlparse(watch_url)
|
||||
q = parse_qs(u[4])
|
||||
assert q['content'][0] == contents.strip(), "Snapshot file {} should contain {}".format(fname, q['content'][0])
|
||||
|
||||
|
||||
|
||||
assert len(files_in_watch_dir) == 2, "Should be just two files in the dir, history.txt and the snapshot"
|
||||
@@ -43,7 +43,7 @@ def set_modified_with_trigger_text_response():
|
||||
Some NEW nice initial text</br>
|
||||
<p>Which is across multiple lines</p>
|
||||
</br>
|
||||
foobar123
|
||||
Add to cart
|
||||
<br/>
|
||||
So let's see what happens. </br>
|
||||
</body>
|
||||
@@ -60,7 +60,7 @@ def test_trigger_functionality(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
trigger_text = "foobar123"
|
||||
trigger_text = "Add to cart"
|
||||
set_original_ignore_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -78,9 +78,6 @@ def test_trigger_functionality(client, live_server):
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# Goto the edit page, add our ignore text
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
@@ -98,6 +95,12 @@ def test_trigger_functionality(client, live_server):
|
||||
)
|
||||
assert bytes(trigger_text.encode('utf-8')) in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
@@ -129,14 +132,14 @@ def test_trigger_functionality(client, live_server):
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
|
||||
# https://github.com/dgtlmoon/changedetection.io/issues/616
|
||||
# Apparently the actual snapshot that contains the trigger never shows
|
||||
res = client.get(url_for("diff_history_page", uuid="first"))
|
||||
assert b'foobar123' in res.data
|
||||
|
||||
assert b'Add to cart' in res.data
|
||||
|
||||
# Check the preview/highlighter, we should be able to see what we triggered on, but it should be highlighted
|
||||
res = client.get(url_for("preview_page", uuid="first"))
|
||||
# We should be able to see what we ignored
|
||||
assert b'<div class="triggered">foobar' in res.data
|
||||
|
||||
# We should be able to see what we triggered on
|
||||
assert b'<div class="triggered">Add to cart' in res.data
|
||||
@@ -42,9 +42,6 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -60,7 +57,9 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("some new noise")
|
||||
@@ -78,4 +77,8 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
@@ -22,10 +22,9 @@ def set_original_ignore_response():
|
||||
|
||||
|
||||
|
||||
def test_trigger_regex_functionality(client, live_server):
|
||||
def test_trigger_regex_functionality_with_filter(client, live_server):
|
||||
|
||||
live_server_setup(live_server)
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
set_original_ignore_response()
|
||||
@@ -42,26 +41,24 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
# it needs time to save the original version
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (just a new one shouldnt have anything)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
### test regex with filter
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"trigger_text": "/cool.stuff\d/",
|
||||
data={"trigger_text": "/cool.stuff/",
|
||||
"url": test_url,
|
||||
"css_filter": '#in-here',
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Check that we have the expected text.. but it's not in the css filter we want
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("<html>some new noise with cool stuff2 ok</html>")
|
||||
@@ -73,6 +70,7 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
# now this should trigger something
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("<html>some new noise with <span id=in-here>cool stuff6</span> ok</html>")
|
||||
|
||||
@@ -81,4 +79,6 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
from flask import make_response, request
|
||||
from flask import url_for
|
||||
|
||||
def set_original_response():
|
||||
test_return_data = """<html>
|
||||
@@ -55,14 +56,32 @@ def set_more_modified_response():
|
||||
return None
|
||||
|
||||
|
||||
# kinda funky, but works for now
|
||||
def extract_api_key_from_UI(client):
|
||||
import re
|
||||
res = client.get(
|
||||
url_for("settings_page"),
|
||||
)
|
||||
# <span id="api-key">{{api_key}}</span>
|
||||
|
||||
m = re.search('<span id="api-key">(.+?)</span>', str(res.data))
|
||||
api_key = m.group(1)
|
||||
return api_key.strip()
|
||||
|
||||
def live_server_setup(live_server):
|
||||
|
||||
@live_server.app.route('/test-endpoint')
|
||||
def test_endpoint():
|
||||
ctype = request.args.get('content_type')
|
||||
status_code = request.args.get('status_code')
|
||||
content = request.args.get('content') or None
|
||||
|
||||
try:
|
||||
if content is not None:
|
||||
resp = make_response(content, status_code)
|
||||
resp.headers['Content-Type'] = ctype if ctype else 'text/html'
|
||||
return resp
|
||||
|
||||
# Tried using a global var here but didn't seem to work, so reading from a file instead.
|
||||
with open("test-datastore/endpoint-content.txt", "r") as f:
|
||||
resp = make_response(f.read(), status_code)
|
||||
|
||||
@@ -56,13 +56,25 @@ class update_worker(threading.Thread):
|
||||
except content_fetcher.ReplyWithContentButNoText as e:
|
||||
# Totally fine, it's by choice - just continue on, nothing more to care about
|
||||
# Page had elements/content but no renderable text
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': "Got HTML content but no text found."})
|
||||
if self.datastore.data['watching'][uuid].get('css_filter'):
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': "Got HTML content but no text found (CSS / xPath Filter not found in page?)"})
|
||||
else:
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': "Got HTML content but no text found."})
|
||||
pass
|
||||
except content_fetcher.EmptyReply as e:
|
||||
# Some kind of custom to-str handler in the exception handler that does this?
|
||||
err_text = "EmptyReply: Status Code {}".format(e.status_code)
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
except content_fetcher.ScreenshotUnavailable as e:
|
||||
err_text = "Screenshot unavailable, page did not render fully in the expected time"
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
except content_fetcher.PageUnloadable as e:
|
||||
err_text = "Page request from server didnt respond correctly"
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
|
||||
except Exception as e:
|
||||
self.app.logger.error("Exception reached processing watch UUID: %s - %s", uuid, str(e))
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': str(e)})
|
||||
@@ -75,9 +87,7 @@ class update_worker(threading.Thread):
|
||||
# For the FIRST time we check a site, or a change detected, save the snapshot.
|
||||
if changed_detected or not watch['last_checked']:
|
||||
# A change was detected
|
||||
fname = self.datastore.save_history_text(watch_uuid=uuid, contents=contents)
|
||||
# Should always be keyed by string(timestamp)
|
||||
self.datastore.update_watch(uuid, {"history": {str(round(time.time())): fname}})
|
||||
fname = watch.save_history_text(contents=contents, timestamp=str(round(time.time())))
|
||||
|
||||
# Generally update anything interesting returned
|
||||
self.datastore.update_watch(uuid=uuid, update_obj=update_obj)
|
||||
@@ -88,16 +98,10 @@ class update_worker(threading.Thread):
|
||||
print (">> Change detected in UUID {} - {}".format(uuid, watch['url']))
|
||||
|
||||
# Notifications should only trigger on the second time (first time, we gather the initial snapshot)
|
||||
if len(watch['history']) > 1:
|
||||
if watch.history_n >= 2:
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
|
||||
prev_fname = watch['history'][dates[1]]
|
||||
dates = list(watch.history.keys())
|
||||
prev_fname = watch.history[dates[-2]]
|
||||
|
||||
|
||||
# Did it have any notification alerts to hit?
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 894 B After Width: | Height: | Size: 894 B |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 115 KiB After Width: | Height: | Size: 115 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB After Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 190 KiB After Width: | Height: | Size: 190 KiB |
{kind=link}
|
After Width: | Height: | Size: 238 KiB |
@@ -18,7 +18,7 @@ wtforms ~= 3.0
|
||||
jsonpath-ng ~= 1.5.3
|
||||
|
||||
# Notification library
|
||||
apprise ~= 0.9.8.3
|
||||
apprise ~= 0.9.9
|
||||
|
||||
# apprise mqtt https://github.com/dgtlmoon/changedetection.io/issues/315
|
||||
paho-mqtt
|
||||
|
||||