Compare commits
48 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
114344f950 | ||
|
|
560d465c59 | ||
|
|
7929aeddfc | ||
|
|
8294519f43 | ||
|
|
8ba8a220b6 | ||
|
|
aa3c8a9370 | ||
|
|
dbb5468cdc | ||
|
|
329c7620fb | ||
|
|
1f974bfbb0 | ||
|
|
437c8525af | ||
|
|
a2a1d5ae90 | ||
|
|
2566de2aae | ||
|
|
dfec8dbb39 | ||
|
|
5cefb16e52 | ||
|
|
341ae24b73 | ||
|
|
f47c2fb7f6 | ||
|
|
9d742446ab | ||
|
|
e3e022b0f4 | ||
|
|
6de4027c27 | ||
|
|
cda3837355 | ||
|
|
7983675325 | ||
|
|
eef56e52c6 | ||
|
|
8e3195f394 | ||
|
|
e17c2121f7 | ||
|
|
07e279b38d | ||
|
|
2c834cfe37 | ||
|
|
dbb5c666f0 | ||
|
|
70b3493866 | ||
|
|
3b11c474d1 | ||
|
|
890e1e6dcd | ||
|
|
6734fb91a2 | ||
|
|
16809b48f8 | ||
|
|
67c833d2bc | ||
|
|
31fea55ee4 | ||
|
|
b6c50d3b1a | ||
|
|
034507f14f | ||
|
|
0e385b1c22 | ||
|
|
f28c260576 | ||
|
|
18f0b63b7d | ||
|
|
97045e7a7b | ||
|
|
9807cf0cda | ||
|
|
d4b5237103 | ||
|
|
dc6f76ba64 | ||
|
|
1f2f93184e | ||
|
|
0f08c8dda3 | ||
|
|
68db20168e | ||
|
|
1d4474f5a3 | ||
|
|
613308881c |
@@ -1,9 +1,9 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Create a report to help us improve
|
||||
about: Create a bug report, if you don't follow this template, your report will be DELETED
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
labels: 'triage'
|
||||
assignees: 'dgtlmoon'
|
||||
|
||||
---
|
||||
|
||||
@@ -11,15 +11,18 @@ assignees: ''
|
||||
A clear and concise description of what the bug is.
|
||||
|
||||
**Version**
|
||||
In the top right area: 0....
|
||||
*Exact version* in the top right area: 0....
|
||||
|
||||
**To Reproduce**
|
||||
|
||||
Steps to reproduce the behavior:
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
4. See error
|
||||
|
||||
! ALWAYS INCLUDE AN EXAMPLE URL WHERE IT IS POSSIBLE TO RE-CREATE THE ISSUE !
|
||||
|
||||
**Expected behavior**
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
title: '[feature]'
|
||||
labels: 'enhancement'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
@@ -20,6 +20,11 @@ COPY requirements.txt /requirements.txt
|
||||
|
||||
RUN pip install --target=/dependencies -r /requirements.txt
|
||||
|
||||
# Playwright is an alternative to Selenium
|
||||
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
||||
RUN pip install --target=/dependencies playwright~=1.20 \
|
||||
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
||||
|
||||
# Final image stage
|
||||
FROM python:3.8-slim
|
||||
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
recursive-include changedetectionio/api *
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/model *
|
||||
include changedetection.py
|
||||
global-exclude *.pyc
|
||||
global-exclude node_modules
|
||||
|
||||
@@ -16,6 +16,13 @@ Live your data-life *pro-actively* instead of *re-actively*, do not rely on mani
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
|
||||
[**Try our $6.99/month subscription - unlimited checks, watches and notifications!**](https://lemonade.changedetection.io/start), choose from different geographical locations, let us handle everything for you.
|
||||
|
||||
|
||||
|
||||
#### Example use cases
|
||||
|
||||
Know when ...
|
||||
@@ -58,14 +65,3 @@ Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
|
||||
|
||||
See https://github.com/dgtlmoon/changedetection.io for more information.
|
||||
|
||||
|
||||
|
||||
### Support us
|
||||
|
||||
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
|
||||
|
||||
Please support us, even small amounts help a LOT.
|
||||
|
||||
BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/btc-support.png" style="max-width:50%;" alt="Support us!" />
|
||||
|
||||
@@ -12,7 +12,7 @@ Live your data-life *pro-actively* instead of *re-actively*.
|
||||
Free, Open-source web page monitoring, notification and change detection. Don't have time? [**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
@@ -48,12 +48,19 @@ _Need an actual Chrome runner with Javascript support? We support fetching via W
|
||||
|
||||
## Screenshots
|
||||
|
||||
Examining differences in content.
|
||||
### Examine differences in content.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
### Target elements with the Visual Selector tool.
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (available also as part of our subscription service)
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
## Installation
|
||||
|
||||
@@ -129,7 +136,7 @@ Just some examples
|
||||
|
||||
<a href="https://github.com/caronc/apprise#popular-notification-services">And everything else in this list!</a>
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
|
||||
Now you can also customise your notification content!
|
||||
|
||||
@@ -137,11 +144,11 @@ Now you can also customise your notification content!
|
||||
|
||||
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||
|
||||

|
||||

|
||||
|
||||
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
|
||||
|
||||

|
||||
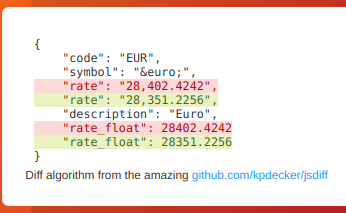
|
||||
|
||||
### Parse JSON embedded in HTML!
|
||||
|
||||
@@ -177,7 +184,7 @@ Or directly donate an amount PayPal [
|
||||
from flask_login import login_required
|
||||
from flask_restful import abort, Api
|
||||
|
||||
from flask_wtf import CSRFProtect
|
||||
|
||||
from changedetectionio import html_tools
|
||||
from changedetectionio.api import api_v1
|
||||
|
||||
__version__ = '0.39.12'
|
||||
__version__ = '0.39.14'
|
||||
|
||||
datastore = None
|
||||
|
||||
@@ -78,6 +81,8 @@ csrf.init_app(app)
|
||||
|
||||
notification_debug_log=[]
|
||||
|
||||
watch_api = Api(app, decorators=[csrf.exempt])
|
||||
|
||||
def init_app_secret(datastore_path):
|
||||
secret = ""
|
||||
|
||||
@@ -173,12 +178,35 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
global datastore
|
||||
datastore = datastore_o
|
||||
|
||||
# so far just for read-only via tests, but this will be moved eventually to be the main source
|
||||
# (instead of the global var)
|
||||
app.config['DATASTORE']=datastore_o
|
||||
|
||||
#app.config.update(config or {})
|
||||
|
||||
login_manager = flask_login.LoginManager(app)
|
||||
login_manager.login_view = 'login'
|
||||
app.secret_key = init_app_secret(config['datastore_path'])
|
||||
|
||||
|
||||
watch_api.add_resource(api_v1.WatchSingleHistory,
|
||||
'/api/v1/watch/<string:uuid>/history/<string:timestamp>',
|
||||
resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
|
||||
|
||||
watch_api.add_resource(api_v1.WatchHistory,
|
||||
'/api/v1/watch/<string:uuid>/history',
|
||||
resource_class_kwargs={'datastore': datastore})
|
||||
|
||||
watch_api.add_resource(api_v1.CreateWatch, '/api/v1/watch',
|
||||
resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
|
||||
|
||||
watch_api.add_resource(api_v1.Watch, '/api/v1/watch/<string:uuid>',
|
||||
resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# Setup cors headers to allow all domains
|
||||
# https://flask-cors.readthedocs.io/en/latest/
|
||||
# CORS(app)
|
||||
@@ -293,25 +321,19 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
for watch in sorted_watches:
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
dates = list(watch.history.keys())
|
||||
# Re #521 - Don't bother processing this one if theres less than 2 snapshots, means we never had a change detected.
|
||||
if len(dates) < 2:
|
||||
continue
|
||||
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
prev_fname = watch['history'][dates[1]]
|
||||
prev_fname = watch.history[dates[-2]]
|
||||
|
||||
if not watch['viewed']:
|
||||
if not watch.viewed:
|
||||
# Re #239 - GUID needs to be individual for each event
|
||||
# @todo In the future make this a configurable link back (see work on BASE_URL https://github.com/dgtlmoon/changedetection.io/pull/228)
|
||||
guid = "{}/{}".format(watch['uuid'], watch['last_changed'])
|
||||
fe = fg.add_entry()
|
||||
|
||||
|
||||
# Include a link to the diff page, they will have to login here to see if password protection is enabled.
|
||||
# Description is the page you watch, link takes you to the diff JS UI page
|
||||
base_url = datastore.data['settings']['application']['base_url']
|
||||
@@ -326,13 +348,15 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
watch_title = watch.get('title') if watch.get('title') else watch.get('url')
|
||||
fe.title(title=watch_title)
|
||||
latest_fname = watch['history'][dates[0]]
|
||||
latest_fname = watch.history[dates[-1]]
|
||||
|
||||
html_diff = diff.render_diff(prev_fname, latest_fname, include_equal=False, line_feed_sep="</br>")
|
||||
fe.description(description="<![CDATA[<html><body><h4>{}</h4>{}</body></html>".format(watch_title, html_diff))
|
||||
fe.description(description="<![CDATA["
|
||||
"<html><body><h4>{}</h4>{}</body></html>"
|
||||
"]]>".format(watch_title, html_diff))
|
||||
|
||||
fe.guid(guid, permalink=False)
|
||||
dt = datetime.datetime.fromtimestamp(int(watch['newest_history_key']))
|
||||
dt = datetime.datetime.fromtimestamp(int(watch.newest_history_key))
|
||||
dt = dt.replace(tzinfo=pytz.UTC)
|
||||
fe.pubDate(dt)
|
||||
|
||||
@@ -367,6 +391,8 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
if limit_tag != None:
|
||||
# Support for comma separated list of tags.
|
||||
if watch['tag'] is None:
|
||||
continue
|
||||
for tag_in_watch in watch['tag'].split(','):
|
||||
tag_in_watch = tag_in_watch.strip()
|
||||
if tag_in_watch == limit_tag:
|
||||
@@ -389,11 +415,13 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
tags=existing_tags,
|
||||
active_tag=limit_tag,
|
||||
app_rss_token=datastore.data['settings']['application']['rss_access_token'],
|
||||
has_unviewed=datastore.data['has_unviewed'],
|
||||
has_unviewed=datastore.has_unviewed,
|
||||
# Don't link to hosting when we're on the hosting environment
|
||||
hosted_sticky=os.getenv("SALTED_PASS", False) == False,
|
||||
guid=datastore.data['app_guid'],
|
||||
queued_uuids=update_q.queue)
|
||||
|
||||
|
||||
if session.get('share-link'):
|
||||
del(session['share-link'])
|
||||
return output
|
||||
@@ -434,48 +462,21 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
@login_required
|
||||
def scrub_page():
|
||||
|
||||
import re
|
||||
|
||||
if request.method == 'POST':
|
||||
confirmtext = request.form.get('confirmtext')
|
||||
limit_date = request.form.get('limit_date')
|
||||
limit_timestamp = 0
|
||||
|
||||
# Re #149 - allow empty/0 timestamp limit
|
||||
if len(limit_date):
|
||||
try:
|
||||
limit_date = limit_date.replace('T', ' ')
|
||||
# I noticed chrome will show '/' but actually submit '-'
|
||||
limit_date = limit_date.replace('-', '/')
|
||||
# In the case that :ss seconds are supplied
|
||||
limit_date = re.sub(r'(\d\d:\d\d)(:\d\d)', '\\1', limit_date)
|
||||
|
||||
str_to_dt = datetime.datetime.strptime(limit_date, '%Y/%m/%d %H:%M')
|
||||
limit_timestamp = int(str_to_dt.timestamp())
|
||||
|
||||
if limit_timestamp > time.time():
|
||||
flash("Timestamp is in the future, cannot continue.", 'error')
|
||||
return redirect(url_for('scrub_page'))
|
||||
|
||||
except ValueError:
|
||||
flash('Incorrect date format, cannot continue.', 'error')
|
||||
return redirect(url_for('scrub_page'))
|
||||
|
||||
if confirmtext == 'scrub':
|
||||
changes_removed = 0
|
||||
for uuid, watch in datastore.data['watching'].items():
|
||||
if limit_timestamp:
|
||||
changes_removed += datastore.scrub_watch(uuid, limit_timestamp=limit_timestamp)
|
||||
else:
|
||||
changes_removed += datastore.scrub_watch(uuid)
|
||||
for uuid in datastore.data['watching'].keys():
|
||||
datastore.scrub_watch(uuid)
|
||||
|
||||
flash("Cleared snapshot history ({} snapshots removed)".format(changes_removed))
|
||||
flash("Cleared all snapshot history")
|
||||
else:
|
||||
flash('Incorrect confirmation text.', 'error')
|
||||
|
||||
return redirect(url_for('index'))
|
||||
|
||||
output = render_template("scrub.html")
|
||||
output = render_template("scrub.html")
|
||||
return output
|
||||
|
||||
|
||||
@@ -492,10 +493,10 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# 0 means that theres only one, so that there should be no 'unviewed' history available
|
||||
if newest_history_key == 0:
|
||||
newest_history_key = list(datastore.data['watching'][uuid]['history'].keys())[0]
|
||||
newest_history_key = list(datastore.data['watching'][uuid].history.keys())[0]
|
||||
|
||||
if newest_history_key:
|
||||
with open(datastore.data['watching'][uuid]['history'][newest_history_key],
|
||||
with open(datastore.data['watching'][uuid].history[newest_history_key],
|
||||
encoding='utf-8') as file:
|
||||
raw_content = file.read()
|
||||
|
||||
@@ -545,10 +546,22 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
if all(value == 0 or value == None for value in datastore.data['watching'][uuid]['time_between_check'].values()):
|
||||
default['time_between_check'] = deepcopy(datastore.data['settings']['requests']['time_between_check'])
|
||||
|
||||
form = forms.watchForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=default
|
||||
)
|
||||
# Defaults for proxy choice
|
||||
if datastore.proxy_list is not None: # When enabled
|
||||
# Radio needs '' not None, or incase that the chosen one no longer exists
|
||||
if default['proxy'] is None or not any(default['proxy'] in tup for tup in datastore.proxy_list):
|
||||
default['proxy'] = ''
|
||||
|
||||
# proxy_override set to the json/text list of the items
|
||||
form = forms.watchForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=default,
|
||||
)
|
||||
|
||||
if datastore.proxy_list is None:
|
||||
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
||||
del form.proxy
|
||||
else:
|
||||
form.proxy.choices = [('', 'Default')] + datastore.proxy_list
|
||||
|
||||
if request.method == 'POST' and form.validate():
|
||||
extra_update_obj = {}
|
||||
@@ -577,14 +590,18 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
|
||||
if form_ignore_text:
|
||||
if len(datastore.data['watching'][uuid]['history']):
|
||||
if len(datastore.data['watching'][uuid].history):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
|
||||
if form.css_filter.data.strip() != datastore.data['watching'][uuid]['css_filter']:
|
||||
if len(datastore.data['watching'][uuid]['history']):
|
||||
if len(datastore.data['watching'][uuid].history):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
# Be sure proxy value is None
|
||||
if datastore.proxy_list is not None and form.data['proxy'] == '':
|
||||
extra_update_obj['proxy'] = None
|
||||
|
||||
datastore.data['watching'][uuid].update(form.data)
|
||||
datastore.data['watching'][uuid].update(extra_update_obj)
|
||||
|
||||
@@ -611,14 +628,22 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
if request.method == 'POST' and not form.validate():
|
||||
flash("An error occurred, please see below.", "error")
|
||||
|
||||
visualselector_data_is_ready = datastore.visualselector_data_is_ready(uuid)
|
||||
|
||||
# Only works reliably with Playwright
|
||||
visualselector_enabled = os.getenv('PLAYWRIGHT_DRIVER_URL', False) and default['fetch_backend'] == 'html_webdriver'
|
||||
|
||||
|
||||
output = render_template("edit.html",
|
||||
uuid=uuid,
|
||||
watch=datastore.data['watching'][uuid],
|
||||
form=form,
|
||||
has_empty_checktime=using_default_check_time,
|
||||
using_global_webdriver_wait=default['webdriver_delay'] is None,
|
||||
current_base_url=datastore.data['settings']['application']['base_url'],
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False)
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False),
|
||||
visualselector_data_is_ready=visualselector_data_is_ready,
|
||||
visualselector_enabled=visualselector_enabled
|
||||
)
|
||||
|
||||
return output
|
||||
@@ -628,10 +653,28 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
def settings_page():
|
||||
from changedetectionio import content_fetcher, forms
|
||||
|
||||
default = deepcopy(datastore.data['settings'])
|
||||
if datastore.proxy_list is not None:
|
||||
# When enabled
|
||||
system_proxy = datastore.data['settings']['requests']['proxy']
|
||||
# In the case it doesnt exist anymore
|
||||
if not any([system_proxy in tup for tup in datastore.proxy_list]):
|
||||
system_proxy = None
|
||||
|
||||
default['requests']['proxy'] = system_proxy if system_proxy is not None else datastore.proxy_list[0][0]
|
||||
# Used by the form handler to keep or remove the proxy settings
|
||||
default['proxy_list'] = datastore.proxy_list
|
||||
|
||||
|
||||
# Don't use form.data on POST so that it doesnt overrid the checkbox status from the POST status
|
||||
form = forms.globalSettingsForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=datastore.data['settings']
|
||||
data=default
|
||||
)
|
||||
if datastore.proxy_list is None:
|
||||
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
||||
del form.requests.form.proxy
|
||||
else:
|
||||
form.requests.form.proxy.choices = datastore.proxy_list
|
||||
|
||||
if request.method == 'POST':
|
||||
# Password unset is a GET, but we can lock the session to a salted env password to always need the password
|
||||
@@ -664,6 +707,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
form=form,
|
||||
current_base_url = datastore.data['settings']['application']['base_url'],
|
||||
hide_remove_pass=os.getenv("SALTED_PASS", False),
|
||||
api_key=datastore.data['settings']['application'].get('api_access_token'),
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False))
|
||||
|
||||
return output
|
||||
@@ -671,57 +715,49 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
@app.route("/import", methods=['GET', "POST"])
|
||||
@login_required
|
||||
def import_page():
|
||||
import validators
|
||||
remaining_urls = []
|
||||
|
||||
good = 0
|
||||
|
||||
if request.method == 'POST':
|
||||
now=time.time()
|
||||
urls = request.values.get('urls').split("\n")
|
||||
from .importer import import_url_list, import_distill_io_json
|
||||
|
||||
if (len(urls) > 5000):
|
||||
flash("Importing 5,000 of the first URLs from your list, the rest can be imported again.")
|
||||
# URL List import
|
||||
if request.values.get('urls') and len(request.values.get('urls').strip()):
|
||||
# Import and push into the queue for immediate update check
|
||||
importer = import_url_list()
|
||||
importer.run(data=request.values.get('urls'), flash=flash, datastore=datastore)
|
||||
for uuid in importer.new_uuids:
|
||||
update_q.put(uuid)
|
||||
|
||||
for url in urls:
|
||||
url = url.strip()
|
||||
url, *tags = url.split(" ")
|
||||
# Flask wtform validators wont work with basic auth, use validators package
|
||||
# Up to 5000 per batch so we dont flood the server
|
||||
if len(url) and validators.url(url.replace('source:', '')) and good < 5000:
|
||||
new_uuid = datastore.add_watch(url=url.strip(), tag=" ".join(tags), write_to_disk_now=False)
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
update_q.put(new_uuid)
|
||||
good += 1
|
||||
continue
|
||||
if len(importer.remaining_data) == 0:
|
||||
return redirect(url_for('index'))
|
||||
else:
|
||||
remaining_urls = importer.remaining_data
|
||||
|
||||
if len(url.strip()):
|
||||
remaining_urls.append(url)
|
||||
# Distill.io import
|
||||
if request.values.get('distill-io') and len(request.values.get('distill-io').strip()):
|
||||
# Import and push into the queue for immediate update check
|
||||
d_importer = import_distill_io_json()
|
||||
d_importer.run(data=request.values.get('distill-io'), flash=flash, datastore=datastore)
|
||||
for uuid in d_importer.new_uuids:
|
||||
update_q.put(uuid)
|
||||
|
||||
flash("{} Imported in {:.2f}s, {} Skipped.".format(good, time.time()-now,len(remaining_urls)))
|
||||
datastore.needs_write = True
|
||||
|
||||
if len(remaining_urls) == 0:
|
||||
# Looking good, redirect to index.
|
||||
return redirect(url_for('index'))
|
||||
|
||||
# Could be some remaining, or we could be on GET
|
||||
output = render_template("import.html",
|
||||
remaining="\n".join(remaining_urls)
|
||||
import_url_list_remaining="\n".join(remaining_urls),
|
||||
original_distill_json=''
|
||||
)
|
||||
return output
|
||||
|
||||
# Clear all statuses, so we do not see the 'unviewed' class
|
||||
@app.route("/api/mark-all-viewed", methods=['GET'])
|
||||
@app.route("/form/mark-all-viewed", methods=['GET'])
|
||||
@login_required
|
||||
def mark_all_viewed():
|
||||
|
||||
# Save the current newest history as the most recently viewed
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
datastore.set_last_viewed(watch_uuid, watch['newest_history_key'])
|
||||
datastore.set_last_viewed(watch_uuid, int(time.time()))
|
||||
|
||||
flash("Cleared all statuses.")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
@app.route("/diff/<string:uuid>", methods=['GET'])
|
||||
@@ -739,20 +775,17 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
flash("No history found for the specified link, bad link?", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
history = watch.history
|
||||
dates = list(history.keys())
|
||||
|
||||
if len(dates) < 2:
|
||||
flash("Not enough saved change detection snapshots to produce a report.", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
# Save the current newest history as the most recently viewed
|
||||
datastore.set_last_viewed(uuid, dates[0])
|
||||
newest_file = watch['history'][dates[0]]
|
||||
datastore.set_last_viewed(uuid, time.time())
|
||||
|
||||
newest_file = history[dates[-1]]
|
||||
|
||||
try:
|
||||
with open(newest_file, 'r') as f:
|
||||
@@ -762,10 +795,10 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
previous_version = request.args.get('previous_version')
|
||||
try:
|
||||
previous_file = watch['history'][previous_version]
|
||||
previous_file = history[previous_version]
|
||||
except KeyError:
|
||||
# Not present, use a default value, the second one in the sorted list.
|
||||
previous_file = watch['history'][dates[1]]
|
||||
previous_file = history[dates[-2]]
|
||||
|
||||
try:
|
||||
with open(previous_file, 'r') as f:
|
||||
@@ -782,7 +815,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
extra_stylesheets=extra_stylesheets,
|
||||
versions=dates[1:],
|
||||
uuid=uuid,
|
||||
newest_version_timestamp=dates[0],
|
||||
newest_version_timestamp=dates[-1],
|
||||
current_previous_version=str(previous_version),
|
||||
current_diff_url=watch['url'],
|
||||
extra_title=" - Diff - {}".format(watch['title'] if watch['title'] else watch['url']),
|
||||
@@ -810,9 +843,9 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
flash("No history found for the specified link, bad link?", "error")
|
||||
return redirect(url_for('index'))
|
||||
|
||||
if len(watch['history']):
|
||||
timestamps = sorted(watch['history'].keys(), key=lambda x: int(x))
|
||||
filename = watch['history'][timestamps[-1]]
|
||||
if watch.history_n >0:
|
||||
timestamps = sorted(watch.history.keys(), key=lambda x: int(x))
|
||||
filename = watch.history[timestamps[-1]]
|
||||
try:
|
||||
with open(filename, 'r') as f:
|
||||
tmp = f.readlines()
|
||||
@@ -869,27 +902,6 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
return output
|
||||
|
||||
@app.route("/api/<string:uuid>/snapshot/current", methods=['GET'])
|
||||
@login_required
|
||||
def api_snapshot(uuid):
|
||||
|
||||
# More for testing, possible to return the first/only
|
||||
if uuid == 'first':
|
||||
uuid = list(datastore.data['watching'].keys()).pop()
|
||||
|
||||
try:
|
||||
watch = datastore.data['watching'][uuid]
|
||||
except KeyError:
|
||||
return abort(400, "No history found for the specified link, bad link?")
|
||||
|
||||
newest = list(watch['history'].keys())[-1]
|
||||
with open(watch['history'][newest], 'r') as f:
|
||||
content = f.read()
|
||||
|
||||
resp = make_response(content)
|
||||
resp.headers['Content-Type'] = 'text/plain'
|
||||
return resp
|
||||
|
||||
@app.route("/favicon.ico", methods=['GET'])
|
||||
def favicon():
|
||||
return send_from_directory("static/images", path="favicon.ico")
|
||||
@@ -970,10 +982,9 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/static/<string:group>/<string:filename>", methods=['GET'])
|
||||
def static_content(group, filename):
|
||||
from flask import make_response
|
||||
|
||||
if group == 'screenshot':
|
||||
|
||||
from flask import make_response
|
||||
|
||||
# Could be sensitive, follow password requirements
|
||||
if datastore.data['settings']['application']['password'] and not flask_login.current_user.is_authenticated:
|
||||
abort(403)
|
||||
@@ -992,6 +1003,26 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
except FileNotFoundError:
|
||||
abort(404)
|
||||
|
||||
|
||||
if group == 'visual_selector_data':
|
||||
# Could be sensitive, follow password requirements
|
||||
if datastore.data['settings']['application']['password'] and not flask_login.current_user.is_authenticated:
|
||||
abort(403)
|
||||
|
||||
# These files should be in our subdirectory
|
||||
try:
|
||||
# set nocache, set content-type
|
||||
watch_dir = datastore_o.datastore_path + "/" + filename
|
||||
response = make_response(send_from_directory(filename="elements.json", directory=watch_dir, path=watch_dir + "/elements.json"))
|
||||
response.headers['Content-type'] = 'application/json'
|
||||
response.headers['Cache-Control'] = 'no-cache, no-store, must-revalidate'
|
||||
response.headers['Pragma'] = 'no-cache'
|
||||
response.headers['Expires'] = 0
|
||||
return response
|
||||
|
||||
except FileNotFoundError:
|
||||
abort(404)
|
||||
|
||||
# These files should be in our subdirectory
|
||||
try:
|
||||
return send_from_directory("static/{}".format(group), path=filename)
|
||||
@@ -1000,7 +1031,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/api/add", methods=['POST'])
|
||||
@login_required
|
||||
def api_watch_add():
|
||||
def form_watch_add():
|
||||
from changedetectionio import forms
|
||||
form = forms.quickWatchForm(request.form)
|
||||
|
||||
@@ -1026,7 +1057,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/api/delete", methods=['GET'])
|
||||
@login_required
|
||||
def api_delete():
|
||||
def form_delete():
|
||||
uuid = request.args.get('uuid')
|
||||
|
||||
if uuid != 'all' and not uuid in datastore.data['watching'].keys():
|
||||
@@ -1043,7 +1074,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/api/clone", methods=['GET'])
|
||||
@login_required
|
||||
def api_clone():
|
||||
def form_clone():
|
||||
uuid = request.args.get('uuid')
|
||||
# More for testing, possible to return the first/only
|
||||
if uuid == 'first':
|
||||
@@ -1057,7 +1088,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/api/checknow", methods=['GET'])
|
||||
@login_required
|
||||
def api_watch_checknow():
|
||||
def form_watch_checknow():
|
||||
|
||||
tag = request.args.get('tag')
|
||||
uuid = request.args.get('uuid')
|
||||
@@ -1094,7 +1125,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
@app.route("/api/share-url", methods=['GET'])
|
||||
@login_required
|
||||
def api_share_put_watch():
|
||||
def form_share_put_watch():
|
||||
"""Given a watch UUID, upload the info and return a share-link
|
||||
the share-link can be imported/added"""
|
||||
import requests
|
||||
@@ -1108,6 +1139,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# copy it to memory as trim off what we dont need (history)
|
||||
watch = deepcopy(datastore.data['watching'][uuid])
|
||||
# For older versions that are not a @property
|
||||
if (watch.get('history')):
|
||||
del (watch['history'])
|
||||
|
||||
@@ -1144,7 +1176,6 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
# paste in etc
|
||||
return redirect(url_for('index'))
|
||||
|
||||
|
||||
# @todo handle ctrl break
|
||||
ticker_thread = threading.Thread(target=ticker_thread_check_time_launch_checks).start()
|
||||
|
||||
@@ -1217,6 +1248,7 @@ def notification_runner():
|
||||
# Thread runner to check every minute, look for new watches to feed into the Queue.
|
||||
def ticker_thread_check_time_launch_checks():
|
||||
from changedetectionio import update_worker
|
||||
import logging
|
||||
|
||||
# Spin up Workers that do the fetching
|
||||
# Can be overriden by ENV or use the default settings
|
||||
@@ -1235,9 +1267,10 @@ def ticker_thread_check_time_launch_checks():
|
||||
running_uuids.append(t.current_uuid)
|
||||
|
||||
# Re #232 - Deepcopy the data incase it changes while we're iterating through it all
|
||||
watch_uuid_list = []
|
||||
while True:
|
||||
try:
|
||||
copied_datastore = deepcopy(datastore)
|
||||
watch_uuid_list = datastore.data['watching'].keys()
|
||||
except RuntimeError as e:
|
||||
# RuntimeError: dictionary changed size during iteration
|
||||
time.sleep(0.1)
|
||||
@@ -1254,7 +1287,12 @@ def ticker_thread_check_time_launch_checks():
|
||||
recheck_time_minimum_seconds = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
recheck_time_system_seconds = datastore.threshold_seconds
|
||||
|
||||
for uuid, watch in copied_datastore.data['watching'].items():
|
||||
for uuid in watch_uuid_list:
|
||||
|
||||
watch = datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
logging.error("Watch: {} no longer present.".format(uuid))
|
||||
continue
|
||||
|
||||
# No need todo further processing if it's paused
|
||||
if watch['paused']:
|
||||
|
||||
@@ -0,0 +1,124 @@
|
||||
from flask_restful import abort, Resource
|
||||
from flask import request, make_response
|
||||
import validators
|
||||
from . import auth
|
||||
|
||||
|
||||
|
||||
# https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
|
||||
class Watch(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
# Get information about a single watch, excluding the history list (can be large)
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>
|
||||
# ?recheck=true
|
||||
@auth.check_token
|
||||
def get(self, uuid):
|
||||
from copy import deepcopy
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if request.args.get('recheck'):
|
||||
self.update_q.put(uuid)
|
||||
return "OK", 200
|
||||
|
||||
# Return without history, get that via another API call
|
||||
watch['history_n'] = watch.history_n
|
||||
return watch
|
||||
|
||||
@auth.check_token
|
||||
def delete(self, uuid):
|
||||
if not self.datastore.data['watching'].get(uuid):
|
||||
abort(400, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
self.datastore.delete(uuid)
|
||||
return 'OK', 204
|
||||
|
||||
|
||||
class WatchHistory(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
# Get a list of available history for a watch by UUID
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>/history
|
||||
def get(self, uuid):
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
return watch.history, 200
|
||||
|
||||
|
||||
class WatchSingleHistory(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
# Read a given history snapshot and return its content
|
||||
# <string:timestamp> or "latest"
|
||||
# curl http://localhost:4000/api/v1/watch/<string:uuid>/history/<int:timestamp>
|
||||
@auth.check_token
|
||||
def get(self, uuid, timestamp):
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if not len(watch.history):
|
||||
abort(404, message='Watch found but no history exists for the UUID {}'.format(uuid))
|
||||
|
||||
if timestamp == 'latest':
|
||||
timestamp = list(watch.history.keys())[-1]
|
||||
|
||||
with open(watch.history[timestamp], 'r') as f:
|
||||
content = f.read()
|
||||
|
||||
response = make_response(content, 200)
|
||||
response.mimetype = "text/plain"
|
||||
return response
|
||||
|
||||
|
||||
class CreateWatch(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
def post(self):
|
||||
# curl http://localhost:4000/api/v1/watch -H "Content-Type: application/json" -d '{"url": "https://my-nice.com", "tag": "one, two" }'
|
||||
json_data = request.get_json()
|
||||
tag = json_data['tag'].strip() if json_data.get('tag') else ''
|
||||
|
||||
if not validators.url(json_data['url'].strip()):
|
||||
return "Invalid or unsupported URL", 400
|
||||
|
||||
extras = {'title': json_data['title'].strip()} if json_data.get('title') else {}
|
||||
|
||||
new_uuid = self.datastore.add_watch(url=json_data['url'].strip(), tag=tag, extras=extras)
|
||||
self.update_q.put(new_uuid)
|
||||
return {'uuid': new_uuid}, 201
|
||||
|
||||
# Return concise list of available watches and some very basic info
|
||||
# curl http://localhost:4000/api/v1/watch|python -mjson.tool
|
||||
# ?recheck_all=1 to recheck all
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
list = {}
|
||||
for k, v in self.datastore.data['watching'].items():
|
||||
list[k] = {'url': v['url'],
|
||||
'title': v['title'],
|
||||
'last_checked': v['last_checked'],
|
||||
'last_changed': v['last_changed'],
|
||||
'last_error': v['last_error']}
|
||||
|
||||
if request.args.get('recheck_all'):
|
||||
for uuid in self.datastore.data['watching'].keys():
|
||||
self.update_q.put(uuid)
|
||||
return {'status': "OK"}, 200
|
||||
|
||||
return list, 200
|
||||
@@ -0,0 +1,33 @@
|
||||
from flask import request, make_response, jsonify
|
||||
from functools import wraps
|
||||
|
||||
|
||||
# Simple API auth key comparison
|
||||
# @todo - Maybe short lived token in the future?
|
||||
|
||||
def check_token(f):
|
||||
@wraps(f)
|
||||
def decorated(*args, **kwargs):
|
||||
datastore = args[0].datastore
|
||||
|
||||
config_api_token_enabled = datastore.data['settings']['application'].get('api_access_token_enabled')
|
||||
if not config_api_token_enabled:
|
||||
return
|
||||
|
||||
try:
|
||||
api_key_header = request.headers['x-api-key']
|
||||
except KeyError:
|
||||
return make_response(
|
||||
jsonify("No authorization x-api-key header."), 403
|
||||
)
|
||||
|
||||
config_api_token = datastore.data['settings']['application'].get('api_access_token')
|
||||
|
||||
if api_key_header != config_api_token:
|
||||
return make_response(
|
||||
jsonify("Invalid access - API key invalid."), 403
|
||||
)
|
||||
|
||||
return f(*args, **kwargs)
|
||||
|
||||
return decorated
|
||||
@@ -8,7 +8,7 @@ import sys
|
||||
|
||||
import eventlet
|
||||
import eventlet.wsgi
|
||||
from . import store, changedetection_app
|
||||
from . import store, changedetection_app, content_fetcher
|
||||
from . import __version__
|
||||
|
||||
def main():
|
||||
|
||||
@@ -1,14 +1,18 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import chardet
|
||||
import json
|
||||
import os
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
import requests
|
||||
import time
|
||||
import urllib3.exceptions
|
||||
import sys
|
||||
|
||||
class PageUnloadable(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
pass
|
||||
|
||||
class EmptyReply(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
@@ -16,16 +20,167 @@ class EmptyReply(Exception):
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
|
||||
pass
|
||||
|
||||
class ScreenshotUnavailable(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
pass
|
||||
|
||||
class ReplyWithContentButNoText(Exception):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
return
|
||||
pass
|
||||
|
||||
|
||||
class Fetcher():
|
||||
error = None
|
||||
status_code = None
|
||||
content = None
|
||||
headers = None
|
||||
|
||||
fetcher_description ="No description"
|
||||
fetcher_description = "No description"
|
||||
xpath_element_js = """
|
||||
// Include the getXpath script directly, easier than fetching
|
||||
!function(e,n){"object"==typeof exports&&"undefined"!=typeof module?module.exports=n():"function"==typeof define&&define.amd?define(n):(e=e||self).getXPath=n()}(this,function(){return function(e){var n=e;if(n&&n.id)return'//*[@id="'+n.id+'"]';for(var o=[];n&&Node.ELEMENT_NODE===n.nodeType;){for(var i=0,r=!1,d=n.previousSibling;d;)d.nodeType!==Node.DOCUMENT_TYPE_NODE&&d.nodeName===n.nodeName&&i++,d=d.previousSibling;for(d=n.nextSibling;d;){if(d.nodeName===n.nodeName){r=!0;break}d=d.nextSibling}o.push((n.prefix?n.prefix+":":"")+n.localName+(i||r?"["+(i+1)+"]":"")),n=n.parentNode}return o.length?"/"+o.reverse().join("/"):""}});
|
||||
|
||||
|
||||
const findUpTag = (el) => {
|
||||
let r = el
|
||||
chained_css = [];
|
||||
depth=0;
|
||||
|
||||
// Strategy 1: Keep going up until we hit an ID tag, imagine it's like #list-widget div h4
|
||||
while (r.parentNode) {
|
||||
if(depth==5) {
|
||||
break;
|
||||
}
|
||||
if('' !==r.id) {
|
||||
chained_css.unshift("#"+r.id);
|
||||
final_selector= chained_css.join('>');
|
||||
// Be sure theres only one, some sites have multiples of the same ID tag :-(
|
||||
if (window.document.querySelectorAll(final_selector).length ==1 ) {
|
||||
return final_selector;
|
||||
}
|
||||
return null;
|
||||
} else {
|
||||
chained_css.unshift(r.tagName.toLowerCase());
|
||||
}
|
||||
r=r.parentNode;
|
||||
depth+=1;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
// @todo - if it's SVG or IMG, go into image diff mode
|
||||
var elements = window.document.querySelectorAll("div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary");
|
||||
var size_pos=[];
|
||||
// after page fetch, inject this JS
|
||||
// build a map of all elements and their positions (maybe that only include text?)
|
||||
var bbox;
|
||||
for (var i = 0; i < elements.length; i++) {
|
||||
bbox = elements[i].getBoundingClientRect();
|
||||
|
||||
// forget really small ones
|
||||
if (bbox['width'] <20 && bbox['height'] < 20 ) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo the getXpath kind of sucks, it doesnt know when there is for example just one ID sometimes
|
||||
// it should not traverse when we know we can anchor off just an ID one level up etc..
|
||||
// maybe, get current class or id, keep traversing up looking for only class or id until there is just one match
|
||||
|
||||
// 1st primitive - if it has class, try joining it all and select, if theres only one.. well thats us.
|
||||
xpath_result=false;
|
||||
|
||||
try {
|
||||
var d= findUpTag(elements[i]);
|
||||
if (d) {
|
||||
xpath_result =d;
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getXPath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if(window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
|
||||
size_pos.push({
|
||||
xpath: xpath_result,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top']),
|
||||
childCount: elements[i].childElementCount
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
// inject the current one set in the css_filter, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (css_filter.length) {
|
||||
q=false;
|
||||
try {
|
||||
// is it xpath?
|
||||
if (css_filter.startsWith('/') || css_filter.startsWith('xpath:')) {
|
||||
q=document.evaluate(css_filter.replace('xpath:',''), document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q=document.querySelector(css_filter);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log(e);
|
||||
}
|
||||
bbox=false;
|
||||
if(q) {
|
||||
bbox = q.getBoundingClientRect();
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] >0 && bbox['height']>0) {
|
||||
size_pos.push({
|
||||
xpath: css_filter,
|
||||
width: bbox['width'],
|
||||
height: bbox['height'],
|
||||
left: bbox['left'],
|
||||
top: bbox['top'],
|
||||
childCount: q.childElementCount
|
||||
});
|
||||
}
|
||||
}
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos':size_pos, 'browser_width': window.innerWidth};
|
||||
"""
|
||||
xpath_data = None
|
||||
|
||||
# Will be needed in the future by the VisualSelector, always get this where possible.
|
||||
screenshot = False
|
||||
fetcher_description = "No description"
|
||||
system_http_proxy = os.getenv('HTTP_PROXY')
|
||||
system_https_proxy = os.getenv('HTTPS_PROXY')
|
||||
|
||||
# Time ONTOP of the system defined env minimum time
|
||||
render_extract_delay=0
|
||||
|
||||
@abstractmethod
|
||||
def get_error(self):
|
||||
@@ -38,7 +193,8 @@ class Fetcher():
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
# Should set self.error, self.status_code and self.content
|
||||
pass
|
||||
|
||||
@@ -46,10 +202,6 @@ class Fetcher():
|
||||
def quit(self):
|
||||
return
|
||||
|
||||
@abstractmethod
|
||||
def screenshot(self):
|
||||
return
|
||||
|
||||
@abstractmethod
|
||||
def get_last_status_code(self):
|
||||
return self.status_code
|
||||
@@ -59,29 +211,154 @@ class Fetcher():
|
||||
def is_ready(self):
|
||||
return True
|
||||
|
||||
|
||||
# Maybe for the future, each fetcher provides its own diff output, could be used for text, image
|
||||
# the current one would return javascript output (as we use JS to generate the diff)
|
||||
#
|
||||
# Returns tuple(mime_type, stream)
|
||||
# @abstractmethod
|
||||
# def return_diff(self, stream_a, stream_b):
|
||||
# return
|
||||
|
||||
def available_fetchers():
|
||||
import inspect
|
||||
from changedetectionio import content_fetcher
|
||||
p=[]
|
||||
for name, obj in inspect.getmembers(content_fetcher):
|
||||
if inspect.isclass(obj):
|
||||
# @todo html_ is maybe better as fetcher_ or something
|
||||
# In this case, make sure to edit the default one in store.py and fetch_site_status.py
|
||||
if "html_" in name:
|
||||
t=tuple([name,obj.fetcher_description])
|
||||
p.append(t)
|
||||
# See the if statement at the bottom of this file for how we switch between playwright and webdriver
|
||||
import inspect
|
||||
p = []
|
||||
for name, obj in inspect.getmembers(sys.modules[__name__], inspect.isclass):
|
||||
if inspect.isclass(obj):
|
||||
# @todo html_ is maybe better as fetcher_ or something
|
||||
# In this case, make sure to edit the default one in store.py and fetch_site_status.py
|
||||
if name.startswith('html_'):
|
||||
t = tuple([name, obj.fetcher_description])
|
||||
p.append(t)
|
||||
|
||||
return p
|
||||
return p
|
||||
|
||||
class html_webdriver(Fetcher):
|
||||
|
||||
class base_html_playwright(Fetcher):
|
||||
fetcher_description = "Playwright {}/Javascript".format(
|
||||
os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').capitalize()
|
||||
)
|
||||
if os.getenv("PLAYWRIGHT_DRIVER_URL"):
|
||||
fetcher_description += " via '{}'".format(os.getenv("PLAYWRIGHT_DRIVER_URL"))
|
||||
|
||||
browser_type = ''
|
||||
command_executor = ''
|
||||
|
||||
# Configs for Proxy setup
|
||||
# In the ENV vars, is prefixed with "playwright_proxy_", so it is for example "playwright_proxy_server"
|
||||
playwright_proxy_settings_mappings = ['bypass', 'server', 'username', 'password']
|
||||
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
self.browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
self.command_executor = os.getenv(
|
||||
"PLAYWRIGHT_DRIVER_URL",
|
||||
'ws://playwright-chrome:3000'
|
||||
).strip('"')
|
||||
|
||||
# If any proxy settings are enabled, then we should setup the proxy object
|
||||
proxy_args = {}
|
||||
for k in self.playwright_proxy_settings_mappings:
|
||||
v = os.getenv('playwright_proxy_' + k, False)
|
||||
if v:
|
||||
proxy_args[k] = v.strip('"')
|
||||
|
||||
if proxy_args:
|
||||
self.proxy = proxy_args
|
||||
|
||||
# allow per-watch proxy selection override
|
||||
if proxy_override:
|
||||
self.proxy = {'server': proxy_override}
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
|
||||
from playwright.sync_api import sync_playwright
|
||||
import playwright._impl._api_types
|
||||
from playwright._impl._api_types import Error, TimeoutError
|
||||
|
||||
with sync_playwright() as p:
|
||||
browser_type = getattr(p, self.browser_type)
|
||||
|
||||
# Seemed to cause a connection Exception even tho I can see it connect
|
||||
# self.browser = browser_type.connect(self.command_executor, timeout=timeout*1000)
|
||||
browser = browser_type.connect_over_cdp(self.command_executor, timeout=timeout * 1000)
|
||||
|
||||
# Set user agent to prevent Cloudflare from blocking the browser
|
||||
# Use the default one configured in the App.py model that's passed from fetch_site_status.py
|
||||
context = browser.new_context(
|
||||
user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should never be needed
|
||||
accept_downloads=False
|
||||
)
|
||||
|
||||
page = context.new_page()
|
||||
try:
|
||||
# Bug - never set viewport size BEFORE page.goto
|
||||
response = page.goto(url, timeout=timeout * 1000, wait_until='commit')
|
||||
# Wait_until = commit
|
||||
# - `'commit'` - consider operation to be finished when network response is received and the document started loading.
|
||||
# Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
|
||||
# This seemed to solve nearly all 'TimeoutErrors'
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
page.wait_for_timeout(extra_wait * 1000)
|
||||
except playwright._impl._api_types.TimeoutError as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None)
|
||||
|
||||
if response is None:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
if len(page.content().strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
# Bug 2(?) Set the viewport size AFTER loading the page
|
||||
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
|
||||
self.status_code = response.status
|
||||
self.content = page.content()
|
||||
self.headers = response.all_headers()
|
||||
|
||||
if current_css_filter is not None:
|
||||
page.evaluate("var css_filter={}".format(json.dumps(current_css_filter)))
|
||||
else:
|
||||
page.evaluate("var css_filter=''")
|
||||
|
||||
self.xpath_data = page.evaluate("async () => {" + self.xpath_element_js + "}")
|
||||
|
||||
# Bug 3 in Playwright screenshot handling
|
||||
# Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
|
||||
# JPEG is better here because the screenshots can be very very large
|
||||
try:
|
||||
page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
|
||||
self.screenshot = page.screenshot(type='jpeg', full_page=True, quality=92)
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
context.close()
|
||||
browser.close()
|
||||
|
||||
|
||||
class base_html_webdriver(Fetcher):
|
||||
if os.getenv("WEBDRIVER_URL"):
|
||||
fetcher_description = "WebDriver Chrome/Javascript via '{}'".format(os.getenv("WEBDRIVER_URL"))
|
||||
else:
|
||||
@@ -94,12 +371,11 @@ class html_webdriver(Fetcher):
|
||||
selenium_proxy_settings_mappings = ['proxyType', 'ftpProxy', 'httpProxy', 'noProxy',
|
||||
'proxyAutoconfigUrl', 'sslProxy', 'autodetect',
|
||||
'socksProxy', 'socksVersion', 'socksUsername', 'socksPassword']
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
|
||||
|
||||
proxy=None
|
||||
|
||||
def __init__(self):
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
self.command_executor = os.getenv("WEBDRIVER_URL", 'http://browser-chrome:4444/wd/hub').strip('"')
|
||||
|
||||
@@ -110,6 +386,16 @@ class html_webdriver(Fetcher):
|
||||
if v:
|
||||
proxy_args[k] = v.strip('"')
|
||||
|
||||
# Map back standard HTTP_ and HTTPS_PROXY to webDriver httpProxy/sslProxy
|
||||
if not proxy_args.get('webdriver_httpProxy') and self.system_http_proxy:
|
||||
proxy_args['httpProxy'] = self.system_http_proxy
|
||||
if not proxy_args.get('webdriver_sslProxy') and self.system_https_proxy:
|
||||
proxy_args['httpsProxy'] = self.system_https_proxy
|
||||
|
||||
# Allows override the proxy on a per-request basis
|
||||
if proxy_override is not None:
|
||||
proxy_args['httpProxy'] = proxy_override
|
||||
|
||||
if proxy_args:
|
||||
self.proxy = SeleniumProxy(raw=proxy_args)
|
||||
|
||||
@@ -119,8 +405,12 @@ class html_webdriver(Fetcher):
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
# request_body, request_method unused for now, until some magic in the future happens.
|
||||
|
||||
# check env for WEBDRIVER_URL
|
||||
@@ -136,19 +426,20 @@ class html_webdriver(Fetcher):
|
||||
self.quit()
|
||||
raise
|
||||
|
||||
self.driver.set_window_size(1280, 1024)
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
self.screenshot = self.driver.get_screenshot_as_png()
|
||||
|
||||
# @todo - how to check this? is it possible?
|
||||
self.status_code = 200
|
||||
# @todo somehow we should try to get this working for WebDriver
|
||||
# raise EmptyReply(url=url, status_code=r.status_code)
|
||||
|
||||
# @todo - dom wait loaded?
|
||||
time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay)
|
||||
self.content = self.driver.page_source
|
||||
self.headers = {}
|
||||
|
||||
def screenshot(self):
|
||||
return self.driver.get_screenshot_as_png()
|
||||
|
||||
# Does the connection to the webdriver work? run a test connection.
|
||||
def is_ready(self):
|
||||
from selenium import webdriver
|
||||
@@ -170,24 +461,41 @@ class html_webdriver(Fetcher):
|
||||
except Exception as e:
|
||||
print("Exception in chrome shutdown/quit" + str(e))
|
||||
|
||||
|
||||
# "html_requests" is listed as the default fetcher in store.py!
|
||||
class html_requests(Fetcher):
|
||||
fetcher_description = "Basic fast Plaintext/HTTP Client"
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
self.proxy_override = proxy_override
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False):
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
|
||||
proxies={}
|
||||
|
||||
# Allows override the proxy on a per-request basis
|
||||
if self.proxy_override:
|
||||
proxies = {'http': self.proxy_override, 'https': self.proxy_override, 'ftp': self.proxy_override}
|
||||
else:
|
||||
if self.system_http_proxy:
|
||||
proxies['http'] = self.system_http_proxy
|
||||
if self.system_https_proxy:
|
||||
proxies['https'] = self.system_https_proxy
|
||||
|
||||
r = requests.request(method=request_method,
|
||||
data=request_body,
|
||||
url=url,
|
||||
headers=request_headers,
|
||||
timeout=timeout,
|
||||
verify=False)
|
||||
data=request_body,
|
||||
url=url,
|
||||
headers=request_headers,
|
||||
timeout=timeout,
|
||||
proxies=proxies,
|
||||
verify=False)
|
||||
|
||||
# If the response did not tell us what encoding format to expect, Then use chardet to override what `requests` thinks.
|
||||
# For example - some sites don't tell us it's utf-8, but return utf-8 content
|
||||
@@ -207,3 +515,11 @@ class html_requests(Fetcher):
|
||||
self.content = r.text
|
||||
self.headers = r.headers
|
||||
|
||||
|
||||
# Decide which is the 'real' HTML webdriver, this is more a system wide config
|
||||
# rather than site-specific.
|
||||
use_playwright_as_chrome_fetcher = os.getenv('PLAYWRIGHT_DRIVER_URL', False)
|
||||
if use_playwright_as_chrome_fetcher:
|
||||
html_webdriver = base_html_playwright
|
||||
else:
|
||||
html_webdriver = base_html_webdriver
|
||||
|
||||
@@ -16,6 +16,34 @@ class perform_site_check():
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
# If there was a proxy list enabled, figure out what proxy_args/which proxy to use
|
||||
# if watch.proxy use that
|
||||
# fetcher.proxy_override = watch.proxy or main config proxy
|
||||
# Allows override the proxy on a per-request basis
|
||||
# ALWAYS use the first one is nothing selected
|
||||
|
||||
def set_proxy_from_list(self, watch):
|
||||
proxy_args = None
|
||||
if self.datastore.proxy_list is None:
|
||||
return None
|
||||
|
||||
# If its a valid one
|
||||
if any([watch['proxy'] in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = watch['proxy']
|
||||
|
||||
# not valid (including None), try the system one
|
||||
else:
|
||||
system_proxy = self.datastore.data['settings']['requests']['proxy']
|
||||
# Is not None and exists
|
||||
if any([system_proxy in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = system_proxy
|
||||
|
||||
# Fallback - Did not resolve anything, use the first available
|
||||
if proxy_args is None:
|
||||
proxy_args = self.datastore.proxy_list[0][0]
|
||||
|
||||
return proxy_args
|
||||
|
||||
def run(self, uuid):
|
||||
timestamp = int(time.time()) # used for storage etc too
|
||||
|
||||
@@ -66,8 +94,20 @@ class perform_site_check():
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
fetcher = klass()
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_code)
|
||||
|
||||
proxy_args = self.set_proxy_from_list(watch)
|
||||
fetcher = klass(proxy_override=proxy_args)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if watch['webdriver_delay'] is not None:
|
||||
fetcher.render_extract_delay = watch['webdriver_delay']
|
||||
elif system_webdriver_delay is not None:
|
||||
fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_code, watch['css_filter'])
|
||||
fetcher.quit()
|
||||
|
||||
# Fetching complete, now filters
|
||||
# @todo move to class / maybe inside of fetcher abstract base?
|
||||
|
||||
@@ -117,11 +157,13 @@ class perform_site_check():
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if css_filter_rule[0] == '/':
|
||||
html_content = html_tools.xpath_filter(xpath_filter=css_filter_rule, html_content=fetcher.content)
|
||||
if css_filter_rule[0] == '/' or css_filter_rule.startswith('xpath:'):
|
||||
html_content = html_tools.xpath_filter(xpath_filter=css_filter_rule.replace('xpath:', ''),
|
||||
html_content=fetcher.content)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
|
||||
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
@@ -141,10 +183,14 @@ class perform_site_check():
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# Treat pages with no renderable text content as a change? No by default
|
||||
empty_pages_are_a_change = self.datastore.data['settings']['application'].get('empty_pages_are_a_change', False)
|
||||
if not is_json and not empty_pages_are_a_change and len(stripped_text_from_html.strip()) == 0:
|
||||
raise content_fetcher.ReplyWithContentButNoText(url=url, status_code=200)
|
||||
|
||||
# We rely on the actual text in the html output.. many sites have random script vars etc,
|
||||
# in the future we'll implement other mechanisms.
|
||||
|
||||
@@ -178,6 +224,7 @@ class perform_site_check():
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['trigger_text'],
|
||||
mode="line numbers")
|
||||
# If it returned any lines that matched..
|
||||
if result:
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
@@ -192,9 +239,4 @@ class perform_site_check():
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
|
||||
|
||||
if self.datastore.data['settings']['application'].get('real_browser_save_screenshot', True):
|
||||
screenshot = fetcher.screenshot()
|
||||
|
||||
fetcher.quit()
|
||||
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter, screenshot
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter, fetcher.screenshot, fetcher.xpath_data
|
||||
|
||||
@@ -307,7 +307,7 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
|
||||
class quickWatchForm(Form):
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)])
|
||||
tag = StringField('Group tag', [validators.Optional()])
|
||||
|
||||
# Common to a single watch and the global settings
|
||||
class commonSettingsForm(Form):
|
||||
@@ -318,11 +318,12 @@ class commonSettingsForm(Form):
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys(), default=default_notification_format)
|
||||
fetch_backend = RadioField(u'Fetch method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
extract_title_as_title = BooleanField('Extract <title> from document and use as watch title', default=False)
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1, message="Should contain one or more seconds")] )
|
||||
|
||||
class watchForm(commonSettingsForm):
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)], default='')
|
||||
tag = StringField('Group tag', [validators.Optional()], default='')
|
||||
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
|
||||
@@ -337,9 +338,9 @@ class watchForm(commonSettingsForm):
|
||||
method = SelectField('Request method', choices=valid_method, default=default_method)
|
||||
ignore_status_codes = BooleanField('Ignore status codes (process non-2xx status codes as normal)', default=False)
|
||||
trigger_text = StringListField('Trigger/wait for text', [validators.Optional(), ValidateListRegex()])
|
||||
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
save_and_preview_button = SubmitField('Save & Preview', render_kw={"class": "pure-button pure-button-primary"})
|
||||
proxy = RadioField('Proxy')
|
||||
|
||||
def validate(self, **kwargs):
|
||||
if not super().validate():
|
||||
@@ -358,6 +359,7 @@ class watchForm(commonSettingsForm):
|
||||
# datastore.data['settings']['requests']..
|
||||
class globalSettingsRequestForm(Form):
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
proxy = RadioField('Proxy')
|
||||
|
||||
|
||||
# datastore.data['settings']['application']..
|
||||
@@ -369,8 +371,10 @@ class globalSettingsApplicationForm(commonSettingsForm):
|
||||
ignore_whitespace = BooleanField('Ignore whitespace')
|
||||
real_browser_save_screenshot = BooleanField('Save last screenshot when using Chrome?')
|
||||
removepassword_button = SubmitField('Remove password', render_kw={"class": "pure-button pure-button-primary"})
|
||||
empty_pages_are_a_change = BooleanField('Treat empty pages as a change?', default=False)
|
||||
render_anchor_tag_content = BooleanField('Render anchor tag content', default=False)
|
||||
fetch_backend = RadioField('Fetch Method', default="html_requests", choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
api_access_token_enabled = BooleanField('API access token security check enabled', default=True, validators=[validators.Optional()])
|
||||
password = SaltyPasswordField()
|
||||
|
||||
|
||||
@@ -382,4 +386,3 @@ class globalSettingsForm(Form):
|
||||
requests = FormField(globalSettingsRequestForm)
|
||||
application = FormField(globalSettingsApplicationForm)
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
|
||||
@@ -39,7 +39,7 @@ def element_removal(selectors: List[str], html_content):
|
||||
def xpath_filter(xpath_filter, html_content):
|
||||
from lxml import etree, html
|
||||
|
||||
tree = html.fromstring(html_content)
|
||||
tree = html.fromstring(bytes(html_content, encoding='utf-8'))
|
||||
html_block = ""
|
||||
|
||||
for item in tree.xpath(xpath_filter.strip(), namespaces={'re':'http://exslt.org/regular-expressions'}):
|
||||
|
||||
@@ -0,0 +1,130 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import time
|
||||
import validators
|
||||
|
||||
|
||||
class Importer():
|
||||
remaining_data = []
|
||||
new_uuids = []
|
||||
good = 0
|
||||
|
||||
def __init__(self):
|
||||
self.new_uuids = []
|
||||
self.good = 0
|
||||
self.remaining_data = []
|
||||
|
||||
@abstractmethod
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore):
|
||||
pass
|
||||
|
||||
|
||||
class import_url_list(Importer):
|
||||
"""
|
||||
Imports a list, can be in <code>https://example.com tag1, tag2, last tag</code> format
|
||||
"""
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
):
|
||||
|
||||
urls = data.split("\n")
|
||||
good = 0
|
||||
now = time.time()
|
||||
|
||||
if (len(urls) > 5000):
|
||||
flash("Importing 5,000 of the first URLs from your list, the rest can be imported again.")
|
||||
|
||||
for url in urls:
|
||||
url = url.strip()
|
||||
if not len(url):
|
||||
continue
|
||||
|
||||
tags = ""
|
||||
|
||||
# 'tags' should be a csv list after the URL
|
||||
if ' ' in url:
|
||||
url, tags = url.split(" ", 1)
|
||||
|
||||
# Flask wtform validators wont work with basic auth, use validators package
|
||||
# Up to 5000 per batch so we dont flood the server
|
||||
if len(url) and validators.url(url.replace('source:', '')) and good < 5000:
|
||||
new_uuid = datastore.add_watch(url=url.strip(), tag=tags, write_to_disk_now=False)
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
continue
|
||||
|
||||
# Worked past the 'continue' above, append it to the bad list
|
||||
if self.remaining_data is None:
|
||||
self.remaining_data = []
|
||||
self.remaining_data.append(url)
|
||||
|
||||
flash("{} Imported from list in {:.2f}s, {} Skipped.".format(good, time.time() - now, len(self.remaining_data)))
|
||||
|
||||
|
||||
class import_distill_io_json(Importer):
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
):
|
||||
|
||||
import json
|
||||
good = 0
|
||||
now = time.time()
|
||||
self.new_uuids=[]
|
||||
|
||||
|
||||
try:
|
||||
data = json.loads(data.strip())
|
||||
except json.decoder.JSONDecodeError:
|
||||
flash("Unable to read JSON file, was it broken?", 'error')
|
||||
return
|
||||
|
||||
if not data.get('data'):
|
||||
flash("JSON structure looks invalid, was it broken?", 'error')
|
||||
return
|
||||
|
||||
for d in data.get('data'):
|
||||
d_config = json.loads(d['config'])
|
||||
extras = {'title': d.get('name', None)}
|
||||
|
||||
if len(d['uri']) and good < 5000:
|
||||
try:
|
||||
# @todo we only support CSS ones at the moment
|
||||
if d_config['selections'][0]['frames'][0]['excludes'][0]['type'] == 'css':
|
||||
extras['subtractive_selectors'] = d_config['selections'][0]['frames'][0]['excludes'][0]['expr']
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
try:
|
||||
extras['css_filter'] = d_config['selections'][0]['frames'][0]['includes'][0]['expr']
|
||||
if d_config['selections'][0]['frames'][0]['includes'][0]['type'] == 'xpath':
|
||||
extras['css_filter'] = 'xpath:' + extras['css_filter']
|
||||
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
|
||||
if d.get('tags', False):
|
||||
extras['tag'] = ", ".join(d['tags'])
|
||||
|
||||
new_uuid = datastore.add_watch(url=d['uri'].strip(),
|
||||
extras=extras,
|
||||
write_to_disk_now=False)
|
||||
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
|
||||
flash("{} Imported from Distill.io in {:.2f}s, {} Skipped.".format(len(self.new_uuids), time.time() - now, len(self.remaining_data)))
|
||||
@@ -23,16 +23,19 @@ class model(dict):
|
||||
'requests': {
|
||||
'timeout': 15, # Default 15 seconds
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': 3, 'minutes': None, 'seconds': None},
|
||||
'workers': 10 # Number of threads, lower is better for slow connections
|
||||
'workers': 10, # Number of threads, lower is better for slow connections
|
||||
'proxy': None # Preferred proxy connection
|
||||
},
|
||||
'application': {
|
||||
'api_access_token_enabled': True,
|
||||
'password': False,
|
||||
'base_url' : None,
|
||||
'extract_title_as_title': False,
|
||||
'empty_pages_are_a_change': False,
|
||||
'fetch_backend': os.getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'global_ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'global_subtractive_selectors': [],
|
||||
'ignore_whitespace': False,
|
||||
'ignore_whitespace': True,
|
||||
'render_anchor_tag_content': False,
|
||||
'notification_urls': [], # Apprise URL list
|
||||
# Custom notification content
|
||||
@@ -40,7 +43,8 @@ class model(dict):
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'real_browser_save_screenshot': True,
|
||||
'schema_version' : 0
|
||||
'schema_version' : 0,
|
||||
'webdriver_delay': None # Extra delay in seconds before extracting text
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import os
|
||||
|
||||
import uuid as uuid_builder
|
||||
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
@@ -12,22 +11,24 @@ from changedetectionio.notification import (
|
||||
|
||||
|
||||
class model(dict):
|
||||
base_config = {
|
||||
__newest_history_key = None
|
||||
__history_n=0
|
||||
|
||||
__base_config = {
|
||||
'url': None,
|
||||
'tag': None,
|
||||
'last_checked': 0,
|
||||
'last_changed': 0,
|
||||
'paused': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'newest_history_key': 0,
|
||||
#'newest_history_key': 0,
|
||||
'title': None,
|
||||
'previous_md5': False,
|
||||
# UUID not needed, should be generated only as a key
|
||||
# 'uuid':
|
||||
'uuid': str(uuid_builder.uuid4()),
|
||||
'headers': {}, # Extra headers to send
|
||||
'body': None,
|
||||
'method': 'GET',
|
||||
'history': {}, # Dict of timestamp and output stripped filename
|
||||
#'history': {}, # Dict of timestamp and output stripped filename
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
# Custom notification content
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
@@ -39,17 +40,112 @@ class model(dict):
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'fetch_backend': None,
|
||||
'extract_title_as_title': False,
|
||||
'proxy': None, # Preferred proxy connection
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None}
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None},
|
||||
'webdriver_delay': None
|
||||
}
|
||||
|
||||
def __init__(self, *arg, **kw):
|
||||
self.update(self.base_config)
|
||||
import uuid
|
||||
self.update(self.__base_config)
|
||||
self.__datastore_path = kw['datastore_path']
|
||||
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
del kw['datastore_path']
|
||||
|
||||
if kw.get('default'):
|
||||
self.update(kw['default'])
|
||||
del kw['default']
|
||||
|
||||
# goes at the end so we update the default object with the initialiser
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
|
||||
@property
|
||||
def viewed(self):
|
||||
if int(self['last_viewed']) >= int(self.newest_history_key) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
@property
|
||||
def history_n(self):
|
||||
return self.__history_n
|
||||
|
||||
@property
|
||||
def history(self):
|
||||
tmp_history = {}
|
||||
import logging
|
||||
import time
|
||||
|
||||
# Read the history file as a dict
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
if os.path.isfile(fname):
|
||||
logging.debug("Disk IO accessed " + str(time.time()))
|
||||
with open(fname, "r") as f:
|
||||
tmp_history = dict(i.strip().split(',', 2) for i in f.readlines())
|
||||
|
||||
if len(tmp_history):
|
||||
self.__newest_history_key = list(tmp_history.keys())[-1]
|
||||
|
||||
self.__history_n = len(tmp_history)
|
||||
|
||||
return tmp_history
|
||||
|
||||
@property
|
||||
def has_history(self):
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
return os.path.isfile(fname)
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
@property
|
||||
def newest_history_key(self):
|
||||
if self.__newest_history_key is not None:
|
||||
return self.__newest_history_key
|
||||
|
||||
if len(self.history) <= 1:
|
||||
return 0
|
||||
|
||||
|
||||
bump = self.history
|
||||
return self.__newest_history_key
|
||||
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, contents, timestamp):
|
||||
import uuid
|
||||
from os import mkdir, path, unlink
|
||||
import logging
|
||||
|
||||
output_path = "{}/{}".format(self.__datastore_path, self['uuid'])
|
||||
|
||||
# Incase the operator deleted it, check and create.
|
||||
if not os.path.isdir(output_path):
|
||||
mkdir(output_path)
|
||||
|
||||
snapshot_fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
logging.debug("Saving history text {}".format(snapshot_fname))
|
||||
|
||||
with open(snapshot_fname, 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
# Append to index
|
||||
# @todo check last char was \n
|
||||
index_fname = "{}/history.txt".format(output_path)
|
||||
with open(index_fname, 'a') as f:
|
||||
f.write("{},{}\n".format(timestamp, snapshot_fname))
|
||||
f.close()
|
||||
|
||||
self.__newest_history_key = timestamp
|
||||
self.__history_n+=1
|
||||
|
||||
#@todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
return snapshot_fname
|
||||
|
||||
@property
|
||||
def has_empty_checktime(self):
|
||||
|
||||
@@ -22,3 +22,26 @@ echo "RUNNING WITH BASE_URL SET"
|
||||
export BASE_URL="https://really-unique-domain.io"
|
||||
pytest tests/test_notification.py
|
||||
|
||||
|
||||
# Now for the selenium and playwright/browserless fetchers
|
||||
# Note - this is not UI functional tests - just checking that each one can fetch the content
|
||||
|
||||
echo "TESTING WEBDRIVER FETCH > SELENIUM/WEBDRIVER..."
|
||||
docker run -d --name $$-test_selenium -p 4444:4444 --rm --shm-size="2g" selenium/standalone-chrome-debug:3.141.59
|
||||
# takes a while to spin up
|
||||
sleep 5
|
||||
export WEBDRIVER_URL=http://localhost:4444/wd/hub
|
||||
pytest tests/fetchers/test_content.py
|
||||
unset WEBDRIVER_URL
|
||||
docker kill $$-test_selenium
|
||||
|
||||
echo "TESTING WEBDRIVER FETCH > PLAYWRIGHT/BROWSERLESS..."
|
||||
# Not all platforms support playwright (not ARM/rPI), so it's not packaged in requirements.txt
|
||||
pip3 install playwright~=1.22
|
||||
docker run -d --name $$-test_browserless -e "DEFAULT_LAUNCH_ARGS=[\"--window-size=1920,1080\"]" --rm -p 3000:3000 --shm-size="2g" browserless/chrome:1.53-chrome-stable
|
||||
# takes a while to spin up
|
||||
sleep 5
|
||||
export PLAYWRIGHT_DRIVER_URL=ws://127.0.0.1:3000
|
||||
pytest tests/fetchers/test_content.py
|
||||
unset PLAYWRIGHT_DRIVER_URL
|
||||
docker kill $$-test_browserless
|
||||
{kind=link}
|
After Width: | Height: | Size: 6.2 KiB |
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
@@ -0,0 +1,36 @@
|
||||
$(document).ready(function () {
|
||||
function toggle() {
|
||||
if ($('input[name="application-fetch_backend"]:checked').val() != 'html_requests') {
|
||||
$('#requests-override-options').hide();
|
||||
$('#webdriver-override-options').show();
|
||||
} else {
|
||||
$('#requests-override-options').show();
|
||||
$('#webdriver-override-options').hide();
|
||||
}
|
||||
}
|
||||
|
||||
$('input[name="application-fetch_backend"]').click(function (e) {
|
||||
toggle();
|
||||
});
|
||||
toggle();
|
||||
|
||||
$("#api-key").hover(
|
||||
function () {
|
||||
$("#api-key-copy").html('copy').fadeIn();
|
||||
},
|
||||
function () {
|
||||
$("#api-key-copy").hide();
|
||||
}
|
||||
).click(function (e) {
|
||||
$("#api-key-copy").html('copied');
|
||||
var range = document.createRange();
|
||||
var n = $("#api-key")[0];
|
||||
range.selectNode(n);
|
||||
window.getSelection().removeAllRanges();
|
||||
window.getSelection().addRange(range);
|
||||
document.execCommand("copy");
|
||||
window.getSelection().removeAllRanges();
|
||||
|
||||
});
|
||||
});
|
||||
|
||||
@@ -0,0 +1,56 @@
|
||||
/**
|
||||
* debounce
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait after the last call before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds after the last call before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.debounce = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
timer = null,
|
||||
wait = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments;
|
||||
|
||||
function complete() {
|
||||
baseFunction.apply(self, args);
|
||||
timer = null;
|
||||
}
|
||||
|
||||
if (timer) {
|
||||
clearTimeout(timer);
|
||||
}
|
||||
|
||||
timer = setTimeout(complete, wait);
|
||||
};
|
||||
};
|
||||
|
||||
/**
|
||||
* throttle
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait between calls before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds between calls before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.throttle = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
lastEventTimestamp = null,
|
||||
limit = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments,
|
||||
now = Date.now();
|
||||
|
||||
if (!lastEventTimestamp || now - lastEventTimestamp >= limit) {
|
||||
lastEventTimestamp = now;
|
||||
baseFunction.apply(self, args);
|
||||
}
|
||||
};
|
||||
};
|
||||
@@ -1,13 +0,0 @@
|
||||
window.addEventListener("load", (event) => {
|
||||
// just an example for now
|
||||
function toggleVisible(elem) {
|
||||
// theres better ways todo this
|
||||
var x = document.getElementById(elem);
|
||||
if (x.style.display === "block") {
|
||||
x.style.display = "none";
|
||||
} else {
|
||||
x.style.display = "block";
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
@@ -0,0 +1,228 @@
|
||||
// Horrible proof of concept code :)
|
||||
// yes - this is really a hack, if you are a front-ender and want to help, please get in touch!
|
||||
|
||||
$(document).ready(function() {
|
||||
|
||||
var current_selected_i;
|
||||
var state_clicked=false;
|
||||
|
||||
var c;
|
||||
|
||||
// greyed out fill context
|
||||
var xctx;
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
|
||||
var current_default_xpath;
|
||||
var x_scale=1;
|
||||
var y_scale=1;
|
||||
var selector_image;
|
||||
var selector_image_rect;
|
||||
var selector_data;
|
||||
|
||||
$('#visualselector-tab').click(function () {
|
||||
$("img#selector-background").off('load');
|
||||
state_clicked = false;
|
||||
current_selected_i = false;
|
||||
bootstrap_visualselector();
|
||||
});
|
||||
|
||||
$(document).on('keydown', function(event) {
|
||||
if ($("img#selector-background").is(":visible")) {
|
||||
if (event.key == "Escape") {
|
||||
state_clicked=false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
// For when the page loads
|
||||
if(!window.location.hash || window.location.hash != '#visualselector') {
|
||||
$("img#selector-background").attr('src','');
|
||||
return;
|
||||
}
|
||||
|
||||
// Handle clearing button/link
|
||||
$('#clear-selector').on('click', function(event) {
|
||||
if(!state_clicked) {
|
||||
alert('Oops, Nothing selected!');
|
||||
}
|
||||
state_clicked=false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
});
|
||||
|
||||
|
||||
bootstrap_visualselector();
|
||||
|
||||
|
||||
|
||||
function bootstrap_visualselector() {
|
||||
if ( 1 ) {
|
||||
// bootstrap it, this will trigger everything else
|
||||
$("img#selector-background").bind('load', function () {
|
||||
console.log("Loaded background...");
|
||||
c = document.getElementById("selector-canvas");
|
||||
// greyed out fill context
|
||||
xctx = c.getContext("2d");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
current_default_xpath =$("#css_filter").val();
|
||||
fetch_data();
|
||||
$('#selector-canvas').off("mousemove mousedown");
|
||||
// screenshot_url defined in the edit.html template
|
||||
}).attr("src", screenshot_url);
|
||||
}
|
||||
}
|
||||
|
||||
function fetch_data() {
|
||||
// Image is ready
|
||||
$('.fetching-update-notice').html("Fetching element data..");
|
||||
|
||||
$.ajax({
|
||||
url: watch_visual_selector_data_url,
|
||||
context: document.body
|
||||
}).done(function (data) {
|
||||
$('.fetching-update-notice').html("Rendering..");
|
||||
selector_data = data;
|
||||
console.log("Reported browser width from backend: "+data['browser_width']);
|
||||
state_clicked=false;
|
||||
set_scale();
|
||||
reflow_selector();
|
||||
$('.fetching-update-notice').fadeOut();
|
||||
});
|
||||
};
|
||||
|
||||
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
selector_image = $("img#selector-background")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas the same size as the image
|
||||
$('#selector-canvas').attr('height', selector_image_rect.height);
|
||||
$('#selector-canvas').attr('width', selector_image_rect.width);
|
||||
$('#selector-wrapper').attr('width', selector_image_rect.width);
|
||||
x_scale = selector_image_rect.width / selector_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: "+x_scale+" by y:"+y_scale);
|
||||
$("#selector-current-xpath").css('max-width', selector_image_rect.width);
|
||||
}
|
||||
|
||||
function reflow_selector() {
|
||||
$(window).resize(function() {
|
||||
set_scale();
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
var selector_currnt_xpath_text=$("#selector-current-xpath span");
|
||||
|
||||
set_scale();
|
||||
|
||||
console.log(selector_data['size_pos'].length + " selectors found");
|
||||
|
||||
// highlight the default one if we can find it in the xPath list
|
||||
// or the xpath matches the default one
|
||||
found = false;
|
||||
if(current_default_xpath.length) {
|
||||
for (var i = selector_data['size_pos'].length; i!==0; i--) {
|
||||
var sel = selector_data['size_pos'][i-1];
|
||||
if(selector_data['size_pos'][i - 1].xpath == current_default_xpath) {
|
||||
console.log("highlighting "+current_default_xpath);
|
||||
current_selected_i = i-1;
|
||||
highlight_current_selected_i();
|
||||
found = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
if(!found) {
|
||||
alert("Unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousemove', function (e) {
|
||||
if(state_clicked) {
|
||||
return;
|
||||
}
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
current_selected_i=null;
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var found=0;
|
||||
ctx.fillStyle = 'rgba(205,0,0,0.35)';
|
||||
for (var i = selector_data['size_pos'].length; i!==0; i--) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = selector_data['size_pos'][i-1];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
|
||||
// FOUND ONE
|
||||
set_current_selected_text(sel.xpath);
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
|
||||
// no need to keep digging
|
||||
// @todo or, O to go out/up, I to go in
|
||||
// or double click to go up/out the selector?
|
||||
current_selected_i=i-1;
|
||||
found+=1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(5));
|
||||
|
||||
function set_current_selected_text(s) {
|
||||
selector_currnt_xpath_text[0].innerHTML=s;
|
||||
}
|
||||
|
||||
function highlight_current_selected_i() {
|
||||
if(state_clicked) {
|
||||
state_clicked=false;
|
||||
xctx.clearRect(0,0,c.width, c.height);
|
||||
return;
|
||||
}
|
||||
|
||||
var sel = selector_data['size_pos'][current_selected_i];
|
||||
if (sel[0] == '/') {
|
||||
// @todo - not sure just checking / is right
|
||||
$("#css_filter").val('xpath:'+sel.xpath);
|
||||
} else {
|
||||
$("#css_filter").val(sel.xpath);
|
||||
}
|
||||
xctx.fillStyle = 'rgba(205,205,205,0.95)';
|
||||
xctx.strokeStyle = 'rgba(225,0,0,0.9)';
|
||||
xctx.lineWidth = 3;
|
||||
xctx.fillRect(0,0,c.width, c.height);
|
||||
// Clear out what only should be seen (make a clear/clean spot)
|
||||
xctx.clearRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
xctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
state_clicked=true;
|
||||
set_current_selected_text(sel.xpath);
|
||||
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousedown', function (e) {
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
}
|
||||
|
||||
});
|
||||
@@ -4,6 +4,7 @@ $(function () {
|
||||
$(this).closest('.unviewed').removeClass('unviewed');
|
||||
});
|
||||
|
||||
|
||||
$('.with-share-link > *').click(function () {
|
||||
$("#copied-clipboard").remove();
|
||||
|
||||
@@ -20,5 +21,6 @@ $(function () {
|
||||
$(this).remove();
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
|
||||
@@ -0,0 +1,16 @@
|
||||
$(document).ready(function() {
|
||||
function toggle() {
|
||||
if ($('input[name="fetch_backend"]:checked').val() != 'html_requests') {
|
||||
$('#requests-override-options').hide();
|
||||
$('#webdriver-override-options').show();
|
||||
} else {
|
||||
$('#requests-override-options').show();
|
||||
$('#webdriver-override-options').hide();
|
||||
}
|
||||
}
|
||||
$('input[name="fetch_backend"]').click(function (e) {
|
||||
toggle();
|
||||
});
|
||||
toggle();
|
||||
|
||||
});
|
||||
@@ -284,6 +284,11 @@ footer {
|
||||
.pure-form {
|
||||
/* The input fields with errors */
|
||||
/* The list of errors */ }
|
||||
.pure-form fieldset {
|
||||
padding-top: 0px; }
|
||||
.pure-form fieldset ul {
|
||||
padding-bottom: 0px;
|
||||
margin-bottom: 0px; }
|
||||
.pure-form .pure-control-group, .pure-form .pure-group, .pure-form .pure-controls {
|
||||
padding-bottom: 1em; }
|
||||
.pure-form .pure-control-group div, .pure-form .pure-group div, .pure-form .pure-controls div {
|
||||
@@ -309,10 +314,10 @@ footer {
|
||||
font-weight: bold; }
|
||||
.pure-form textarea {
|
||||
width: 100%; }
|
||||
.pure-form ul.fetch-backend {
|
||||
.pure-form .inline-radio ul {
|
||||
margin: 0px;
|
||||
list-style: none; }
|
||||
.pure-form ul.fetch-backend li > * {
|
||||
.pure-form .inline-radio ul li > * {
|
||||
display: inline-block; }
|
||||
|
||||
@media only screen and (max-width: 760px), (min-device-width: 768px) and (max-device-width: 1024px) {
|
||||
@@ -333,7 +338,8 @@ footer {
|
||||
padding-top: 110px; }
|
||||
div.tabs.collapsable ul li {
|
||||
display: block;
|
||||
border-radius: 0px; }
|
||||
border-radius: 0px;
|
||||
margin-right: 0px; }
|
||||
input[type='text'] {
|
||||
width: 100%; }
|
||||
/*
|
||||
@@ -424,6 +430,15 @@ and also iPads specifically.
|
||||
.tab-pane-inner:target {
|
||||
display: block; }
|
||||
|
||||
#beta-logo {
|
||||
height: 50px;
|
||||
right: -3px;
|
||||
top: -3px;
|
||||
position: absolute; }
|
||||
|
||||
#selector-header {
|
||||
padding-bottom: 1em; }
|
||||
|
||||
.edit-form {
|
||||
min-width: 70%;
|
||||
/* so it cant overflow */
|
||||
@@ -447,4 +462,31 @@ ul {
|
||||
.time-check-widget tr {
|
||||
display: inline; }
|
||||
.time-check-widget tr input[type="number"] {
|
||||
width: 4em; }
|
||||
width: 5em; }
|
||||
|
||||
#selector-wrapper {
|
||||
height: 600px;
|
||||
overflow-y: scroll;
|
||||
position: relative; }
|
||||
#selector-wrapper > img {
|
||||
position: absolute;
|
||||
z-index: 4;
|
||||
max-width: 100%; }
|
||||
#selector-wrapper > canvas {
|
||||
position: relative;
|
||||
z-index: 5;
|
||||
max-width: 100%; }
|
||||
#selector-wrapper > canvas:hover {
|
||||
cursor: pointer; }
|
||||
|
||||
#selector-current-xpath {
|
||||
font-size: 80%; }
|
||||
|
||||
#webdriver-override-options input[type="number"] {
|
||||
width: 5em; }
|
||||
|
||||
#api-key:hover {
|
||||
cursor: pointer; }
|
||||
|
||||
#api-key-copy {
|
||||
color: #0078e7; }
|
||||
|
||||
@@ -375,6 +375,13 @@ footer {
|
||||
|
||||
|
||||
.pure-form {
|
||||
fieldset {
|
||||
padding-top: 0px;
|
||||
ul {
|
||||
padding-bottom: 0px;
|
||||
margin-bottom: 0px;
|
||||
}
|
||||
}
|
||||
.pure-control-group, .pure-group, .pure-controls {
|
||||
padding-bottom: 1em;
|
||||
div {
|
||||
@@ -418,14 +425,16 @@ footer {
|
||||
textarea {
|
||||
width: 100%;
|
||||
}
|
||||
ul.fetch-backend {
|
||||
margin: 0px;
|
||||
list-style: none;
|
||||
li {
|
||||
> * {
|
||||
display: inline-block;
|
||||
.inline-radio {
|
||||
ul {
|
||||
margin: 0px;
|
||||
list-style: none;
|
||||
li {
|
||||
> * {
|
||||
display: inline-block;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -460,6 +469,7 @@ footer {
|
||||
div.tabs.collapsable ul li {
|
||||
display: block;
|
||||
border-radius: 0px;
|
||||
margin-right: 0px;
|
||||
}
|
||||
|
||||
input[type='text'] {
|
||||
@@ -604,6 +614,18 @@ $form-edge-padding: 20px;
|
||||
padding: 0px;
|
||||
}
|
||||
|
||||
#beta-logo {
|
||||
height: 50px;
|
||||
// looks better when it's hanging off a little
|
||||
right: -3px;
|
||||
top: -3px;
|
||||
position: absolute;
|
||||
}
|
||||
|
||||
#selector-header {
|
||||
padding-bottom: 1em;
|
||||
}
|
||||
|
||||
.edit-form {
|
||||
min-width: 70%;
|
||||
/* so it cant overflow */
|
||||
@@ -635,7 +657,47 @@ ul {
|
||||
tr {
|
||||
display: inline;
|
||||
input[type="number"] {
|
||||
width: 4em;
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#selector-wrapper {
|
||||
height: 600px;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
//width: 100%;
|
||||
> img {
|
||||
position: absolute;
|
||||
z-index: 4;
|
||||
max-width: 100%;
|
||||
}
|
||||
>canvas {
|
||||
position: relative;
|
||||
z-index: 5;
|
||||
max-width: 100%;
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#selector-current-xpath {
|
||||
font-size: 80%;
|
||||
}
|
||||
|
||||
#webdriver-override-options {
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
|
||||
#api-key {
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
|
||||
#api-key-copy {
|
||||
color: #0078e7;
|
||||
}
|
||||
|
||||
@@ -12,9 +12,9 @@ from os import mkdir, path, unlink
|
||||
from threading import Lock
|
||||
import re
|
||||
import requests
|
||||
import secrets
|
||||
|
||||
from changedetectionio.model import Watch, App
|
||||
|
||||
from . model import App, Watch
|
||||
|
||||
# Is there an existing library to ensure some data store (JSON etc) is in sync with CRUD methods?
|
||||
# Open a github issue if you know something :)
|
||||
@@ -33,13 +33,14 @@ class ChangeDetectionStore:
|
||||
self.needs_write = False
|
||||
self.datastore_path = datastore_path
|
||||
self.json_store_path = "{}/url-watches.json".format(self.datastore_path)
|
||||
self.proxy_list = None
|
||||
self.stop_thread = False
|
||||
|
||||
self.__data = App.model()
|
||||
|
||||
# Base definition for all watchers
|
||||
# deepcopy part of #569 - not sure why its needed exactly
|
||||
self.generic_definition = deepcopy(Watch.model())
|
||||
self.generic_definition = deepcopy(Watch.model(datastore_path = datastore_path, default={}))
|
||||
|
||||
if path.isfile('changedetectionio/source.txt'):
|
||||
with open('changedetectionio/source.txt') as f:
|
||||
@@ -70,13 +71,10 @@ class ChangeDetectionStore:
|
||||
if 'application' in from_disk['settings']:
|
||||
self.__data['settings']['application'].update(from_disk['settings']['application'])
|
||||
|
||||
# Reinitialise each `watching` with our generic_definition in the case that we add a new var in the future.
|
||||
# @todo pretty sure theres a python we todo this with an abstracted(?) object!
|
||||
# Convert each existing watch back to the Watch.model object
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
_blank = deepcopy(self.generic_definition)
|
||||
_blank.update(watch)
|
||||
self.__data['watching'].update({uuid: _blank})
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
watch['uuid']=uuid
|
||||
self.__data['watching'][uuid] = Watch.model(datastore_path=self.datastore_path, default=watch)
|
||||
print("Watching:", uuid, self.__data['watching'][uuid]['url'])
|
||||
|
||||
# First time ran, doesnt exist.
|
||||
@@ -86,8 +84,7 @@ class ChangeDetectionStore:
|
||||
|
||||
self.add_watch(url='http://www.quotationspage.com/random.php', tag='test')
|
||||
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
||||
self.add_watch(url='https://www.gov.uk/coronavirus', tag='Covid')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt', tag='changedetection.io')
|
||||
|
||||
self.__data['version_tag'] = version_tag
|
||||
|
||||
@@ -107,10 +104,21 @@ class ChangeDetectionStore:
|
||||
|
||||
# Generate the URL access token for RSS feeds
|
||||
if not 'rss_access_token' in self.__data['settings']['application']:
|
||||
import secrets
|
||||
secret = secrets.token_hex(16)
|
||||
self.__data['settings']['application']['rss_access_token'] = secret
|
||||
|
||||
# Generate the API access token
|
||||
if not 'api_access_token' in self.__data['settings']['application']:
|
||||
secret = secrets.token_hex(16)
|
||||
self.__data['settings']['application']['api_access_token'] = secret
|
||||
|
||||
# Proxy list support - available as a selection in settings when text file is imported
|
||||
# CSV list
|
||||
# "name, address", or just "name"
|
||||
proxy_list_file = "{}/proxies.txt".format(self.datastore_path)
|
||||
if path.isfile(proxy_list_file):
|
||||
self.import_proxy_list(proxy_list_file)
|
||||
|
||||
# Bump the update version by running updates
|
||||
self.run_updates()
|
||||
|
||||
@@ -119,23 +127,8 @@ class ChangeDetectionStore:
|
||||
# Finally start the thread that will manage periodic data saves to JSON
|
||||
save_data_thread = threading.Thread(target=self.save_datastore).start()
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
def get_newest_history_key(self, uuid):
|
||||
if len(self.__data['watching'][uuid]['history']) == 1:
|
||||
return 0
|
||||
|
||||
dates = list(self.__data['watching'][uuid]['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
if len(dates):
|
||||
# always keyed as str
|
||||
return str(dates[0])
|
||||
|
||||
return 0
|
||||
|
||||
def set_last_viewed(self, uuid, timestamp):
|
||||
logging.debug("Setting watch UUID: {} last viewed to {}".format(uuid, int(timestamp)))
|
||||
self.data['watching'][uuid].update({'last_viewed': int(timestamp)})
|
||||
self.needs_write = True
|
||||
|
||||
@@ -145,6 +138,10 @@ class ChangeDetectionStore:
|
||||
|
||||
def update_watch(self, uuid, update_obj):
|
||||
|
||||
# It's possible that the watch could be deleted before update
|
||||
if not self.__data['watching'].get(uuid):
|
||||
return
|
||||
|
||||
with self.lock:
|
||||
|
||||
# In python 3.9 we have the |= dict operator, but that still will lose data on nested structures...
|
||||
@@ -155,7 +152,6 @@ class ChangeDetectionStore:
|
||||
del (update_obj[dict_key])
|
||||
|
||||
self.__data['watching'][uuid].update(update_obj)
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
|
||||
self.needs_write = True
|
||||
|
||||
@@ -170,20 +166,20 @@ class ChangeDetectionStore:
|
||||
seconds += x * n
|
||||
return max(seconds, minimum_seconds_recheck_time)
|
||||
|
||||
@property
|
||||
def has_unviewed(self):
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
if watch.viewed == False:
|
||||
return True
|
||||
return False
|
||||
|
||||
@property
|
||||
def data(self):
|
||||
has_unviewed = False
|
||||
for uuid, v in self.__data['watching'].items():
|
||||
self.__data['watching'][uuid]['newest_history_key'] = self.get_newest_history_key(uuid)
|
||||
if int(v['newest_history_key']) <= int(v['last_viewed']):
|
||||
self.__data['watching'][uuid]['viewed'] = True
|
||||
|
||||
else:
|
||||
self.__data['watching'][uuid]['viewed'] = False
|
||||
has_unviewed = True
|
||||
|
||||
for uuid, watch in self.__data['watching'].items():
|
||||
# #106 - Be sure this is None on empty string, False, None, etc
|
||||
# Default var for fetch_backend
|
||||
# @todo this may not be needed anymore, or could be easily removed
|
||||
if not self.__data['watching'][uuid]['fetch_backend']:
|
||||
self.__data['watching'][uuid]['fetch_backend'] = self.__data['settings']['application']['fetch_backend']
|
||||
|
||||
@@ -192,14 +188,13 @@ class ChangeDetectionStore:
|
||||
if not self.__data['settings']['application']['base_url']:
|
||||
self.__data['settings']['application']['base_url'] = env_base_url.strip('" ')
|
||||
|
||||
self.__data['has_unviewed'] = has_unviewed
|
||||
|
||||
return self.__data
|
||||
|
||||
def get_all_tags(self):
|
||||
tags = []
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
|
||||
if watch['tag'] is None:
|
||||
continue
|
||||
# Support for comma separated list of tags.
|
||||
for tag in watch['tag'].split(','):
|
||||
tag = tag.strip()
|
||||
@@ -223,11 +218,11 @@ class ChangeDetectionStore:
|
||||
|
||||
# GitHub #30 also delete history records
|
||||
for uuid in self.data['watching']:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
for path in self.data['watching'][uuid].history.values():
|
||||
self.unlink_history_file(path)
|
||||
|
||||
else:
|
||||
for path in self.data['watching'][uuid]['history'].values():
|
||||
for path in self.data['watching'][uuid].history.values():
|
||||
self.unlink_history_file(path)
|
||||
|
||||
del self.data['watching'][uuid]
|
||||
@@ -256,50 +251,23 @@ class ChangeDetectionStore:
|
||||
return self.data['watching'][uuid].get(val)
|
||||
|
||||
# Remove a watchs data but keep the entry (URL etc)
|
||||
def scrub_watch(self, uuid, limit_timestamp = False):
|
||||
def scrub_watch(self, uuid):
|
||||
import pathlib
|
||||
|
||||
import hashlib
|
||||
del_timestamps = []
|
||||
self.__data['watching'][uuid].update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': False})
|
||||
self.needs_write_urgent = True
|
||||
|
||||
changes_removed = 0
|
||||
|
||||
for timestamp, path in self.data['watching'][uuid]['history'].items():
|
||||
if not limit_timestamp or (limit_timestamp is not False and int(timestamp) > limit_timestamp):
|
||||
self.unlink_history_file(path)
|
||||
del_timestamps.append(timestamp)
|
||||
changes_removed += 1
|
||||
|
||||
if not limit_timestamp:
|
||||
self.data['watching'][uuid]['last_checked'] = 0
|
||||
self.data['watching'][uuid]['last_changed'] = 0
|
||||
self.data['watching'][uuid]['previous_md5'] = ""
|
||||
|
||||
|
||||
for timestamp in del_timestamps:
|
||||
del self.data['watching'][uuid]['history'][str(timestamp)]
|
||||
|
||||
# If there was a limitstamp, we need to reset some meta data about the entry
|
||||
# This has to happen after we remove the others from the list
|
||||
if limit_timestamp:
|
||||
newest_key = self.get_newest_history_key(uuid)
|
||||
if newest_key:
|
||||
self.data['watching'][uuid]['last_checked'] = int(newest_key)
|
||||
# @todo should be the original value if it was less than newest key
|
||||
self.data['watching'][uuid]['last_changed'] = int(newest_key)
|
||||
try:
|
||||
with open(self.data['watching'][uuid]['history'][str(newest_key)], "rb") as fp:
|
||||
content = fp.read()
|
||||
self.data['watching'][uuid]['previous_md5'] = hashlib.md5(content).hexdigest()
|
||||
except (FileNotFoundError, IOError):
|
||||
self.data['watching'][uuid]['previous_md5'] = ""
|
||||
pass
|
||||
|
||||
self.needs_write = True
|
||||
return changes_removed
|
||||
for item in pathlib.Path(self.datastore_path).rglob(uuid+"/*.txt"):
|
||||
unlink(item)
|
||||
|
||||
def add_watch(self, url, tag="", extras=None, write_to_disk_now=True):
|
||||
|
||||
if extras is None:
|
||||
extras = {}
|
||||
# should always be str
|
||||
if tag is None or not tag:
|
||||
tag=''
|
||||
|
||||
# Incase these are copied across, assume it's a reference and deepcopy()
|
||||
apply_extras = deepcopy(extras)
|
||||
|
||||
@@ -329,16 +297,15 @@ class ChangeDetectionStore:
|
||||
return False
|
||||
|
||||
with self.lock:
|
||||
# @todo use a common generic version of this
|
||||
new_uuid = str(uuid_builder.uuid4())
|
||||
|
||||
# #Re 569
|
||||
# Not sure why deepcopy was needed here, sometimes new watches would appear to already have 'history' set
|
||||
# I assumed this would instantiate a new object but somehow an existing dict was getting used
|
||||
new_watch = deepcopy(Watch.model({
|
||||
new_watch = Watch.model(datastore_path=self.datastore_path, default={
|
||||
'url': url,
|
||||
'tag': tag
|
||||
}))
|
||||
})
|
||||
|
||||
new_uuid = new_watch['uuid']
|
||||
logging.debug("Added URL {} - {}".format(url, new_uuid))
|
||||
|
||||
for k in ['uuid', 'history', 'last_checked', 'last_changed', 'newest_history_key', 'previous_md5', 'viewed']:
|
||||
if k in apply_extras:
|
||||
@@ -358,23 +325,6 @@ class ChangeDetectionStore:
|
||||
self.sync_to_json()
|
||||
return new_uuid
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, watch_uuid, contents):
|
||||
import uuid
|
||||
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
# Incase the operator deleted it, check and create.
|
||||
if not os.path.isdir(output_path):
|
||||
mkdir(output_path)
|
||||
|
||||
fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
with open(fname, 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
return fname
|
||||
|
||||
def get_screenshot(self, watch_uuid):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
fname = "{}/last-screenshot.png".format(output_path)
|
||||
@@ -383,6 +333,15 @@ class ChangeDetectionStore:
|
||||
|
||||
return False
|
||||
|
||||
def visualselector_data_is_ready(self, watch_uuid):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
screenshot_filename = "{}/last-screenshot.png".format(output_path)
|
||||
elements_index_filename = "{}/elements.json".format(output_path)
|
||||
if path.isfile(screenshot_filename) and path.isfile(elements_index_filename) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
# Save as PNG, PNG is larger but better for doing visual diff in the future
|
||||
def save_screenshot(self, watch_uuid, screenshot: bytes):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
@@ -391,6 +350,14 @@ class ChangeDetectionStore:
|
||||
f.write(screenshot)
|
||||
f.close()
|
||||
|
||||
def save_xpath_data(self, watch_uuid, data):
|
||||
output_path = "{}/{}".format(self.datastore_path, watch_uuid)
|
||||
fname = "{}/elements.json".format(output_path)
|
||||
with open(fname, 'w') as f:
|
||||
f.write(json.dumps(data))
|
||||
f.close()
|
||||
|
||||
|
||||
def sync_to_json(self):
|
||||
logging.info("Saving JSON..")
|
||||
print("Saving JSON..")
|
||||
@@ -443,16 +410,32 @@ class ChangeDetectionStore:
|
||||
|
||||
index=[]
|
||||
for uuid in self.data['watching']:
|
||||
for id in self.data['watching'][uuid]['history']:
|
||||
index.append(self.data['watching'][uuid]['history'][str(id)])
|
||||
for id in self.data['watching'][uuid].history:
|
||||
index.append(self.data['watching'][uuid].history[str(id)])
|
||||
|
||||
import pathlib
|
||||
|
||||
# Only in the sub-directories
|
||||
for item in pathlib.Path(self.datastore_path).rglob("*/*txt"):
|
||||
if not str(item) in index:
|
||||
print ("Removing",item)
|
||||
unlink(item)
|
||||
for uuid in self.data['watching']:
|
||||
for item in pathlib.Path(self.datastore_path).rglob(uuid+"/*.txt"):
|
||||
if not str(item) in index:
|
||||
print ("Removing",item)
|
||||
unlink(item)
|
||||
|
||||
def import_proxy_list(self, filename):
|
||||
import csv
|
||||
with open(filename, newline='') as f:
|
||||
reader = csv.reader(f, skipinitialspace=True)
|
||||
# @todo This loop can could be improved
|
||||
l = []
|
||||
for row in reader:
|
||||
if len(row):
|
||||
if len(row)>=2:
|
||||
l.append(tuple(row[:2]))
|
||||
else:
|
||||
l.append(tuple([row[0], row[0]]))
|
||||
self.proxy_list = l if len(l) else None
|
||||
|
||||
|
||||
# Run all updates
|
||||
# IMPORTANT - Each update could be run even when they have a new install and the schema is correct
|
||||
@@ -499,3 +482,28 @@ class ChangeDetectionStore:
|
||||
# Only upgrade individual watch time if it was set
|
||||
if watch.get('minutes_between_check', False):
|
||||
self.data['watching'][uuid]['time_between_check']['minutes'] = watch['minutes_between_check']
|
||||
|
||||
# Move the history list to a flat text file index
|
||||
# Better than SQLite because this list is only appended to, and works across NAS / NFS type setups
|
||||
def update_2(self):
|
||||
# @todo test running this on a newly updated one (when this already ran)
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
history = []
|
||||
|
||||
if watch.get('history', False):
|
||||
for d, p in watch['history'].items():
|
||||
d = int(d) # Used to be keyed as str, we'll fix this now too
|
||||
history.append("{},{}\n".format(d,p))
|
||||
|
||||
if len(history):
|
||||
target_path = os.path.join(self.datastore_path, uuid)
|
||||
if os.path.exists(target_path):
|
||||
with open(os.path.join(target_path, "history.txt"), "w") as f:
|
||||
f.writelines(history)
|
||||
else:
|
||||
logging.warning("Datastore history directory {} does not exist, skipping history import.".format(target_path))
|
||||
|
||||
# No longer needed, dynamically pulled from the disk when needed.
|
||||
# But we should set it back to a empty dict so we don't break if this schema runs on an earlier version.
|
||||
# In the distant future we can remove this entirely
|
||||
self.data['watching'][uuid]['history'] = {}
|
||||
|
||||
@@ -2,7 +2,6 @@
|
||||
{% from '_helpers.jinja' import render_field %}
|
||||
|
||||
{% macro render_common_settings_form(form, current_base_url, emailprefix) %}
|
||||
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.notification_urls, rows=5, placeholder="Examples:
|
||||
Gitter - gitter://token/room
|
||||
|
||||
@@ -39,9 +39,6 @@
|
||||
<div class="tabs">
|
||||
<ul>
|
||||
<li class="tab" id="default-tab"><a href="#text">Text</a></li>
|
||||
{% if screenshot %}
|
||||
<li class="tab"><a href="#screenshot">Current screenshot</a></li>
|
||||
{% endif %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
@@ -63,17 +60,6 @@
|
||||
</table>
|
||||
Diff algorithm from the amazing <a href="https://github.com/kpdecker/jsdiff">github.com/kpdecker/jsdiff</a>
|
||||
</div>
|
||||
|
||||
{% if screenshot %}
|
||||
<div class="tab-pane-inner" id="screenshot">
|
||||
<p>
|
||||
<i>For now, only the most recent screenshot is saved and displayed.</i>
|
||||
</p>
|
||||
|
||||
<img src="{{url_for('static_content', group='screenshot', filename=uuid)}}">
|
||||
</div>
|
||||
{% endif %}
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
@@ -5,11 +5,18 @@
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='tabs.js')}}" defer></script>
|
||||
<script>
|
||||
const notification_base_url="{{url_for('ajax_callback_send_notification_test')}}";
|
||||
const watch_visual_selector_data_url="{{url_for('static_content', group='visual_selector_data', filename=uuid)}}";
|
||||
const screenshot_url="{{url_for('static_content', group='screenshot', filename=uuid)}}";
|
||||
|
||||
{% if emailprefix %}
|
||||
const email_notification_prefix=JSON.parse('{{ emailprefix|tojson }}');
|
||||
{% endif %}
|
||||
|
||||
</script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='watch-settings.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='notifications.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='visual-selector.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='limit.js')}}" defer></script>
|
||||
|
||||
<div class="edit-form monospaced-textarea">
|
||||
|
||||
@@ -17,6 +24,7 @@
|
||||
<ul>
|
||||
<li class="tab" id="default-tab"><a href="#general">General</a></li>
|
||||
<li class="tab"><a href="#request">Request</a></li>
|
||||
<li class="tab"><a id="visualselector-tab" href="#visualselector">Visual Selector</a></li>
|
||||
<li class="tab"><a href="#filters-and-triggers">Filters & Triggers</a></li>
|
||||
<li class="tab"><a href="#notifications">Notifications</a></li>
|
||||
</ul>
|
||||
@@ -57,20 +65,40 @@
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="request">
|
||||
<div class="pure-control-group">
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_field(form.fetch_backend, class="fetch-backend") }}
|
||||
<span class="pure-form-message-inline">
|
||||
<p>Use the <strong>Basic</strong> method (default) where your watched site doesn't need Javascript to render.</p>
|
||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||
</span>
|
||||
</div>
|
||||
|
||||
<hr/>
|
||||
<fieldset class="pure-group">
|
||||
|
||||
<span class="pure-form-message-inline">
|
||||
{% if form.proxy %}
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_field(form.proxy, class="fetch-backend-proxy") }}
|
||||
<span class="pure-form-message-inline">
|
||||
Choose a proxy for this watch
|
||||
</span>
|
||||
</div>
|
||||
{% endif %}
|
||||
<fieldset id="webdriver-override-options">
|
||||
<div class="pure-form-message-inline">
|
||||
<strong>If you're having trouble waiting for the page to be fully rendered (text missing etc), try increasing the 'wait' time here.</strong>
|
||||
<br/>
|
||||
This will wait <i>n</i> seconds before extracting the text.
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.webdriver_delay) }}
|
||||
</div>
|
||||
{% if using_global_webdriver_wait %}
|
||||
<div class="pure-form-message-inline">
|
||||
<strong>Using the current global default settings</strong>
|
||||
</div>
|
||||
{% endif %}
|
||||
</fieldset>
|
||||
<fieldset class="pure-group" id="requests-override-options">
|
||||
<div class="pure-form-message-inline">
|
||||
<strong>Request override is currently only used by the <i>Basic fast Plaintext/HTTP Client</i> method.</strong>
|
||||
</span>
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.method) }}
|
||||
</div>
|
||||
@@ -104,8 +132,7 @@ User-Agent: wonderbra 1.0") }}
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="filters-and-triggers">
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
<div class="pure-control-group">
|
||||
<strong>Pro-tips:</strong><br/>
|
||||
<ul>
|
||||
<li>
|
||||
@@ -116,7 +143,6 @@ User-Agent: wonderbra 1.0") }}
|
||||
</li>
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.css_filter, placeholder=".class-name or #some-id, or other CSS selector rule.",
|
||||
class="m-d") }}
|
||||
@@ -125,14 +151,14 @@ User-Agent: wonderbra 1.0") }}
|
||||
<li>CSS - Limit text to this CSS rule, only text matching this CSS rule is included.</li>
|
||||
<li>JSON - Limit text to this JSON rule, using <a href="https://pypi.org/project/jsonpath-ng/">JSONPath</a>, prefix with <code>"json:"</code>, use <code>json:$</code> to force re-formatting if required, <a
|
||||
href="https://jsonpath.com/" target="new">test your JSONPath here</a></li>
|
||||
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash, example <code>//*[contains(@class, 'sametext')]</code>, <a
|
||||
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash, example <code>//*[contains(@class, 'sametext')]</code> or <code>xpath://*[contains(@class, 'sametext')]</code>, <a
|
||||
href="http://xpather.com/" target="new">test your XPath here</a></li>
|
||||
</ul>
|
||||
Please be sure that you thoroughly understand how to write CSS or JSONPath, XPath selector rules before filing an issue on GitHub! <a
|
||||
href="https://github.com/dgtlmoon/changedetection.io/wiki/CSS-Selector-help">here for more CSS selector help</a>.<br/>
|
||||
</span>
|
||||
</div>
|
||||
<fieldset class="pure-group">
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.subtractive_selectors, rows=5, placeholder="header
|
||||
footer
|
||||
nav
|
||||
@@ -143,8 +169,7 @@ nav
|
||||
<li> Add multiple elements or CSS selectors per line to ignore multiple parts of the HTML. </li>
|
||||
</ul>
|
||||
</span>
|
||||
</fieldset>
|
||||
</fieldset>
|
||||
</div>
|
||||
<fieldset class="pure-group">
|
||||
{{ render_field(form.ignore_text, rows=5, placeholder="Some text to ignore in a line
|
||||
/some.regex\d{2}/ for case-INsensitive regex
|
||||
@@ -176,14 +201,54 @@ nav
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner visual-selector-ui" id="visualselector">
|
||||
<img id="beta-logo" src="{{url_for('static_content', group='images', filename='beta-logo.png')}}">
|
||||
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
{% if visualselector_enabled %}
|
||||
{% if visualselector_data_is_ready %}
|
||||
<div id="selector-header">
|
||||
<a id="clear-selector" class="pure-button button-secondary button-xsmall" style="font-size: 70%">Clear selection</a>
|
||||
<i class="fetching-update-notice" style="font-size: 80%;">One moment, fetching screenshot and element information..</i>
|
||||
</div>
|
||||
<div id="selector-wrapper">
|
||||
<!-- request the screenshot and get the element offset info ready -->
|
||||
<!-- use img src ready load to know everything is ready to map out -->
|
||||
<!-- @todo: maybe something interesting like a field to select 'elements that contain text... and their parents n' -->
|
||||
<img id="selector-background" />
|
||||
<canvas id="selector-canvas"></canvas>
|
||||
|
||||
</div>
|
||||
<div id="selector-current-xpath" style="overflow-x: hidden"><strong>Currently:</strong> <span class="text">Loading...</span></div>
|
||||
|
||||
<span class="pure-form-message-inline">
|
||||
<p><span style="font-weight: bold">Beta!</span> The Visual Selector is new and there may be minor bugs, please report pages that dont work, help us to improve this software!</p>
|
||||
</span>
|
||||
|
||||
{% else %}
|
||||
<span class="pure-form-message-inline">Screenshot and element data is not available or not yet ready.</span>
|
||||
{% endif %}
|
||||
{% else %}
|
||||
<span class="pure-form-message-inline">
|
||||
<p>Sorry, this functionality only works with Playwright/Chrome enabled watches.</p>
|
||||
<p>Enable the Playwright Chrome fetcher, or alternatively try our <a href="https://lemonade.changedetection.io/start">very affordable subscription based service</a>.</p>
|
||||
<p>This is because Selenium/WebDriver can not extract full page screenshots reliably.</p>
|
||||
|
||||
</span>
|
||||
{% endif %}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div id="actions">
|
||||
<div class="pure-control-group">
|
||||
|
||||
{{ render_button(form.save_button) }} {{ render_button(form.save_and_preview_button) }}
|
||||
|
||||
<a href="{{url_for('api_delete', uuid=uuid)}}"
|
||||
<a href="{{url_for('form_delete', uuid=uuid)}}"
|
||||
class="pure-button button-small button-error ">Delete</a>
|
||||
<a href="{{url_for('api_clone', uuid=uuid)}}"
|
||||
<a href="{{url_for('form_clone', uuid=uuid)}}"
|
||||
class="pure-button button-small ">Create Copy</a>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -1,30 +1,86 @@
|
||||
{% extends 'base.html' %}
|
||||
|
||||
{% block content %}
|
||||
<div class="edit-form">
|
||||
<div class="inner">
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='tabs.js')}}" defer></script>
|
||||
<div class="edit-form monospaced-textarea">
|
||||
|
||||
<div class="tabs collapsable">
|
||||
<ul>
|
||||
<li class="tab" id="default-tab"><a href="#url-list">URL List</a></li>
|
||||
<li class="tab"><a href="#distill-io">Distill.io</a></li>
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<div class="box-wrap inner">
|
||||
<form class="pure-form pure-form-aligned" action="{{url_for('import_page')}}" method="POST">
|
||||
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
|
||||
<fieldset class="pure-group">
|
||||
<legend>
|
||||
Enter one URL per line, and optionally add tags for each URL after a space, delineated by comma (,):
|
||||
<br>
|
||||
<code>https://example.com tag1, tag2, last tag</code>
|
||||
<br>
|
||||
URLs which do not pass validation will stay in the textarea.
|
||||
</legend>
|
||||
|
||||
<div class="tab-pane-inner" id="url-list">
|
||||
<fieldset class="pure-group">
|
||||
<legend>
|
||||
Enter one URL per line, and optionally add tags for each URL after a space, delineated by comma
|
||||
(,):
|
||||
<br>
|
||||
<code>https://example.com tag1, tag2, last tag</code>
|
||||
<br>
|
||||
URLs which do not pass validation will stay in the textarea.
|
||||
</legend>
|
||||
|
||||
<textarea name="urls" class="pure-input-1-2" placeholder="https://"
|
||||
style="width: 100%;
|
||||
|
||||
<textarea name="urls" class="pure-input-1-2" placeholder="https://"
|
||||
style="width: 100%;
|
||||
font-family:monospace;
|
||||
white-space: pre;
|
||||
overflow-wrap: normal;
|
||||
overflow-x: scroll;" rows="25">{{ remaining }}</textarea>
|
||||
</fieldset>
|
||||
overflow-x: scroll;" rows="25">{{ import_url_list_remaining }}</textarea>
|
||||
</fieldset>
|
||||
|
||||
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="distill-io">
|
||||
|
||||
|
||||
<fieldset class="pure-group">
|
||||
<legend>
|
||||
Copy and Paste your Distill.io watch 'export' file, this should be a JSON file.</br>
|
||||
This is <i>experimental</i>, supported fields are <code>name</code>, <code>uri</code>, <code>tags</code>, <code>config:selections</code>, the rest (including <code>schedule</code>) are ignored.
|
||||
<br/>
|
||||
<p>
|
||||
How to export? <a href="https://distill.io/docs/web-monitor/how-export-and-import-monitors/">https://distill.io/docs/web-monitor/how-export-and-import-monitors/</a><br/>
|
||||
Be sure to set your default fetcher to Chrome if required.</br>
|
||||
</p>
|
||||
</legend>
|
||||
|
||||
|
||||
<textarea name="distill-io" class="pure-input-1-2" style="width: 100%;
|
||||
font-family:monospace;
|
||||
white-space: pre;
|
||||
overflow-wrap: normal;
|
||||
overflow-x: scroll;" placeholder="Example Distill.io JSON export file
|
||||
|
||||
{
|
||||
"client": {
|
||||
"local": 1
|
||||
},
|
||||
"data": [
|
||||
{
|
||||
"name": "Unraid | News",
|
||||
"uri": "https://unraid.net/blog",
|
||||
"config": "{\"selections\":[{\"frames\":[{\"index\":0,\"excludes\":[],\"includes\":[{\"type\":\"xpath\",\"expr\":\"(//div[@id='App']/div[contains(@class,'flex')]/main[contains(@class,'relative')]/section[contains(@class,'relative')]/div[@class='container']/div[contains(@class,'flex')]/div[contains(@class,'w-full')])[1]\"}]}],\"dynamic\":true,\"delay\":2}],\"ignoreEmptyText\":true,\"includeStyle\":false,\"dataAttr\":\"text\"}",
|
||||
"tags": [],
|
||||
"content_type": 2,
|
||||
"state": 40,
|
||||
"schedule": "{\"type\":\"INTERVAL\",\"params\":{\"interval\":4447}}",
|
||||
"ts": "2022-03-27T15:51:15.667Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
" rows="25">{{ original_distill_json }}</textarea>
|
||||
</fieldset>
|
||||
</div>
|
||||
<button type="submit" class="pure-button pure-input-1-2 pure-button-primary">Import</button>
|
||||
</form>
|
||||
</div>
|
||||
|
||||
</div>
|
||||
</div>
|
||||
|
||||
{% endblock %}
|
||||
|
||||
@@ -10,9 +10,6 @@
|
||||
<div class="tabs">
|
||||
<ul>
|
||||
<li class="tab" id="default-tab"><a href="#text">Text</a></li>
|
||||
{% if screenshot %}
|
||||
<li class="tab"><a href="#screenshot">Current screenshot</a></li>
|
||||
{% endif %}
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
@@ -31,15 +28,5 @@
|
||||
</tbody>
|
||||
</table>
|
||||
</div>
|
||||
|
||||
{% if screenshot %}
|
||||
<div class="tab-pane-inner" id="screenshot">
|
||||
<p>
|
||||
<i>For now, only the most recent screenshot is saved and displayed.</i>
|
||||
</p>
|
||||
|
||||
<img src="{{url_for('static_content', group='screenshot', filename=uuid)}}">
|
||||
</div>
|
||||
{% endif %}
|
||||
</div>
|
||||
{% endblock %}
|
||||
@@ -7,7 +7,7 @@
|
||||
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
This will remove all version snapshots/data, but keep your list of URLs. <br/>
|
||||
This will remove ALL version snapshots/data, but keep your list of URLs. <br/>
|
||||
You may like to use the <strong>BACKUP</strong> link first.<br/>
|
||||
</div>
|
||||
<br/>
|
||||
@@ -17,12 +17,6 @@
|
||||
<span class="pure-form-message-inline">Type in the word <strong>scrub</strong> to confirm that you understand!</span>
|
||||
</div>
|
||||
<br/>
|
||||
<div class="pure-control-group">
|
||||
<label for="confirmtext">Optional: Limit deletion of snapshots to snapshots <i>newer</i> than date/time</label>
|
||||
<input type="datetime-local" id="limit_date" name="limit_date" />
|
||||
<span class="pure-form-message-inline">dd/mm/yyyy hh:mm (24 hour format)</span>
|
||||
</div>
|
||||
<br/>
|
||||
<div class="pure-control-group">
|
||||
<button type="submit" class="pure-button pure-button-primary">Scrub!</button>
|
||||
</div>
|
||||
|
||||
@@ -9,10 +9,10 @@
|
||||
const email_notification_prefix=JSON.parse('{{emailprefix|tojson}}');
|
||||
{% endif %}
|
||||
</script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='settings.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='tabs.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='notifications.js')}}" defer></script>
|
||||
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='global-settings.js')}}" defer></script>
|
||||
<div class="edit-form">
|
||||
<div class="tabs collapsable">
|
||||
<ul>
|
||||
@@ -20,6 +20,7 @@
|
||||
<li class="tab"><a href="#notifications">Notifications</a></li>
|
||||
<li class="tab"><a href="#fetching">Fetching</a></li>
|
||||
<li class="tab"><a href="#filters">Global Filters</a></li>
|
||||
<li class="tab"><a href="#api">API</a></li>
|
||||
</ul>
|
||||
</div>
|
||||
<div class="box-wrap inner">
|
||||
@@ -43,6 +44,7 @@
|
||||
<span class="pure-form-message-inline">Password is locked.</span>
|
||||
{% endif %}
|
||||
</div>
|
||||
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.application.form.base_url, placeholder="http://yoursite.com:5000/",
|
||||
class="m-d") }}
|
||||
@@ -62,6 +64,18 @@
|
||||
<span class="pure-form-message-inline">When using a Chrome browser, a screenshot from the last check will be available on the Diff page</span>
|
||||
</div>
|
||||
|
||||
<div class="pure-control-group">
|
||||
{{ render_checkbox_field(form.application.form.empty_pages_are_a_change) }}
|
||||
<span class="pure-form-message-inline">When a page contains HTML, but no renderable text appears (empty page), is this considered a change?</span>
|
||||
</div>
|
||||
{% if form.requests.proxy %}
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_field(form.requests.form.proxy, class="fetch-backend-proxy") }}
|
||||
<span class="pure-form-message-inline">
|
||||
Choose a default proxy for all watches
|
||||
</span>
|
||||
</div>
|
||||
{% endif %}
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
@@ -74,16 +88,25 @@
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="fetching">
|
||||
<div class="pure-control-group">
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_field(form.application.form.fetch_backend, class="fetch-backend") }}
|
||||
<span class="pure-form-message-inline">
|
||||
<p>Use the <strong>Basic</strong> method (default) where your watched sites don't need Javascript to render.</p>
|
||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||
</span>
|
||||
</div>
|
||||
<fieldset class="pure-group" id="webdriver-override-options">
|
||||
<div class="pure-form-message-inline">
|
||||
<strong>If you're having trouble waiting for the page to be fully rendered (text missing etc), try increasing the 'wait' time here.</strong>
|
||||
<br/>
|
||||
This will wait <i>n</i> seconds before extracting the text.
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.application.form.webdriver_delay) }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
|
||||
<div class="tab-pane-inner" id="filters">
|
||||
|
||||
<fieldset class="pure-group">
|
||||
@@ -128,12 +151,26 @@ nav
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="api">
|
||||
|
||||
<p>Drive your changedetection.io via API, More about <a href="https://github.com/dgtlmoon/changedetection.io/wiki/API-Reference">API access here</a></p>
|
||||
|
||||
<div class="pure-control-group">
|
||||
{{ render_checkbox_field(form.application.form.api_access_token_enabled) }}
|
||||
<div class="pure-form-message-inline">Restrict API access limit by using <code>x-api-key</code> header</div><br/>
|
||||
<div class="pure-form-message-inline"><br/>API Key <span id="api-key">{{api_key}}</span>
|
||||
<span style="display:none;" id="api-key-copy" >copy</span>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div id="actions">
|
||||
<div class="pure-control-group">
|
||||
{{ render_button(form.save_button) }}
|
||||
<a href="{{url_for('index')}}" class="pure-button button-small button-cancel">Back</a>
|
||||
<a href="{{url_for('scrub_page')}}" class="pure-button button-small button-cancel">Delete History Snapshot Data</a>
|
||||
</div>
|
||||
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
|
||||
@@ -3,9 +3,10 @@
|
||||
{% from '_helpers.jinja' import render_simple_field %}
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='jquery-3.6.0.min.js')}}"></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='watch-overview.js')}}" defer></script>
|
||||
|
||||
<div class="box">
|
||||
|
||||
<form class="pure-form" action="{{ url_for('api_watch_add') }}" method="POST" id="new-watch-form">
|
||||
<form class="pure-form" action="{{ url_for('form_watch_add') }}" method="POST" id="new-watch-form">
|
||||
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
|
||||
<fieldset>
|
||||
<legend>Add a new change detection watch</legend>
|
||||
@@ -13,7 +14,7 @@
|
||||
{{ render_simple_field(form.tag, value=active_tag if active_tag else '', placeholder="watch group") }}
|
||||
<button type="submit" class="pure-button pure-button-primary">Watch</button>
|
||||
</fieldset>
|
||||
<span style="color:#eee; font-size: 80%;"><img style="height: 1em;display:inline-block;" src="{{url_for('static_content', group='images', filename='spread.svg')}}" /> Tip: You can also add 'shared' watches. <a href="#">More info</a></a></span>
|
||||
<span style="color:#eee; font-size: 80%;"><img style="height: 1em;display:inline-block;" src="{{url_for('static_content', group='images', filename='spread.svg')}}" /> Tip: You can also add 'shared' watches. <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Sharing-a-Watch">More info</a></a></span>
|
||||
</form>
|
||||
<div>
|
||||
<a href="{{url_for('index')}}" class="pure-button button-tag {{'active' if not active_tag }}">All</a>
|
||||
@@ -45,14 +46,14 @@
|
||||
{% if watch.last_error is defined and watch.last_error != False %}error{% endif %}
|
||||
{% if watch.last_notification_error is defined and watch.last_notification_error != False %}error{% endif %}
|
||||
{% if watch.paused is defined and watch.paused != False %}paused{% endif %}
|
||||
{% if watch.newest_history_key| int > watch.last_viewed| int %}unviewed{% endif %}
|
||||
{% if watch.newest_history_key| int > watch.last_viewed and watch.history_n>=2 %}unviewed{% endif %}
|
||||
{% if watch.uuid in queued_uuids %}queued{% endif %}">
|
||||
<td class="inline">{{ loop.index }}</td>
|
||||
<td class="inline paused-state state-{{watch.paused}}"><a href="{{url_for('index', pause=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='pause.svg')}}" alt="Pause" title="Pause"/></a></td>
|
||||
|
||||
<td class="title-col inline">{{watch.title if watch.title is not none and watch.title|length > 0 else watch.url}}
|
||||
<a class="external" target="_blank" rel="noopener" href="{{ watch.url.replace('source:','') }}"></a>
|
||||
<a href="{{url_for('api_share_put_watch', uuid=watch.uuid)}}"><img style="height: 1em;display:inline-block;" src="{{url_for('static_content', group='images', filename='spread.svg')}}" /></a>
|
||||
<a href="{{url_for('form_share_put_watch', uuid=watch.uuid)}}"><img style="height: 1em;display:inline-block;" src="{{url_for('static_content', group='images', filename='spread.svg')}}" /></a>
|
||||
|
||||
{%if watch.fetch_backend == "html_webdriver" %}<img style="height: 1em; display:inline-block;" src="{{url_for('static_content', group='images', filename='Google-Chrome-icon.png')}}" />{% endif %}
|
||||
|
||||
@@ -67,20 +68,20 @@
|
||||
{% endif %}
|
||||
</td>
|
||||
<td class="last-checked">{{watch|format_last_checked_time}}</td>
|
||||
<td class="last-changed">{% if watch.history|length >= 2 and watch.last_changed %}
|
||||
<td class="last-changed">{% if watch.history_n >=2 and watch.last_changed %}
|
||||
{{watch.last_changed|format_timestamp_timeago}}
|
||||
{% else %}
|
||||
Not yet
|
||||
{% endif %}
|
||||
</td>
|
||||
<td>
|
||||
<a {% if watch.uuid in queued_uuids %}disabled="true"{% endif %} href="{{ url_for('api_watch_checknow', uuid=watch.uuid, tag=request.args.get('tag')) }}"
|
||||
<a {% if watch.uuid in queued_uuids %}disabled="true"{% endif %} href="{{ url_for('form_watch_checknow', uuid=watch.uuid, tag=request.args.get('tag')) }}"
|
||||
class="recheck pure-button button-small pure-button-primary">{% if watch.uuid in queued_uuids %}Queued{% else %}Recheck{% endif %}</a>
|
||||
<a href="{{ url_for('edit_page', uuid=watch.uuid)}}" class="pure-button button-small pure-button-primary">Edit</a>
|
||||
{% if watch.history|length >= 2 %}
|
||||
{% if watch.history_n >= 2 %}
|
||||
<a href="{{ url_for('diff_history_page', uuid=watch.uuid) }}" target="{{watch.uuid}}" class="pure-button button-small pure-button-primary diff-link">Diff</a>
|
||||
{% else %}
|
||||
{% if watch.history|length == 1 %}
|
||||
{% if watch.history_n == 1 %}
|
||||
<a href="{{ url_for('preview_page', uuid=watch.uuid)}}" target="{{watch.uuid}}" class="pure-button button-small pure-button-primary">Preview</a>
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
@@ -96,7 +97,7 @@
|
||||
</li>
|
||||
{% endif %}
|
||||
<li>
|
||||
<a href="{{ url_for('api_watch_checknow', tag=active_tag) }}" class="pure-button button-tag ">Recheck
|
||||
<a href="{{ url_for('form_watch_checknow', tag=active_tag) }}" class="pure-button button-tag ">Recheck
|
||||
all {% if active_tag%}in "{{active_tag}}"{%endif%}</a>
|
||||
</li>
|
||||
<li>
|
||||
|
||||
@@ -0,0 +1,2 @@
|
||||
"""Tests for the app."""
|
||||
|
||||
@@ -0,0 +1,3 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
from .. import conftest
|
||||
@@ -0,0 +1,48 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from ..util import live_server_setup
|
||||
import logging
|
||||
|
||||
|
||||
def test_fetch_webdriver_content(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
#####################
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-empty_pages_are_a_change": "",
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_webdriver"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": "https://changedetection.io/ci-test.html"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(3)
|
||||
attempt = 0
|
||||
while attempt < 20:
|
||||
res = client.get(url_for("index"))
|
||||
if not b'Checking now' in res.data:
|
||||
break
|
||||
logging.getLogger().info("Waiting for check to not say 'Checking now'..")
|
||||
time.sleep(3)
|
||||
attempt += 1
|
||||
|
||||
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
logging.getLogger().info("Looking for correct fetched HTML (text) from server")
|
||||
|
||||
assert b'cool it works' in res.data
|
||||
@@ -2,73 +2,192 @@
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from . util import live_server_setup
|
||||
from .util import live_server_setup, extract_api_key_from_UI
|
||||
|
||||
def test_setup(live_server):
|
||||
live_server_setup(live_server)
|
||||
import json
|
||||
import uuid
|
||||
|
||||
|
||||
def set_response_data(test_return_data):
|
||||
def set_original_response():
|
||||
test_return_data = """<html>
|
||||
<body>
|
||||
Some initial text</br>
|
||||
<p>Which is across multiple lines</p>
|
||||
</br>
|
||||
So let's see what happens. </br>
|
||||
<div id="sametext">Some text thats the same</div>
|
||||
<div id="changetext">Some text that will change</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(test_return_data)
|
||||
return None
|
||||
|
||||
|
||||
def set_modified_response():
|
||||
test_return_data = """<html>
|
||||
<body>
|
||||
Some initial text</br>
|
||||
<p>which has this one new line</p>
|
||||
</br>
|
||||
So let's see what happens. </br>
|
||||
<div id="sametext">Some text thats the same</div>
|
||||
<div id="changetext">Some text that changes</div>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(test_return_data)
|
||||
|
||||
return None
|
||||
|
||||
def test_snapshot_api_detects_change(client, live_server):
|
||||
test_return_data = "Some initial text"
|
||||
|
||||
test_return_data_modified = "Some NEW nice initial text"
|
||||
def is_valid_uuid(val):
|
||||
try:
|
||||
uuid.UUID(str(val))
|
||||
return True
|
||||
except ValueError:
|
||||
return False
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
set_response_data(test_return_data)
|
||||
def test_api_simple(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
api_key = extract_api_key_from_UI(client)
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', content_type="text/plain",
|
||||
_external=True)
|
||||
# Create a watch
|
||||
set_original_response()
|
||||
watch_uuid = None
|
||||
|
||||
# Validate bad URL
|
||||
test_url = url_for('test_endpoint', _external=True,
|
||||
headers={'x-api-key': api_key}, )
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
url_for("createwatch"),
|
||||
data=json.dumps({"url": "h://xxxxxxxxxom"}),
|
||||
headers={'content-type': 'application/json', 'x-api-key': api_key},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(
|
||||
url_for("api_snapshot", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert test_return_data.encode() == res.data
|
||||
|
||||
# Make a change
|
||||
set_response_data(test_return_data_modified)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(
|
||||
url_for("api_snapshot", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert test_return_data_modified.encode() == res.data
|
||||
|
||||
def test_snapshot_api_invalid_uuid(client, live_server):
|
||||
|
||||
res = client.get(
|
||||
url_for("api_snapshot", uuid="invalid"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert res.status_code == 400
|
||||
|
||||
# Create new
|
||||
res = client.post(
|
||||
url_for("createwatch"),
|
||||
data=json.dumps({"url": test_url, 'tag': "One, Two", "title": "My test URL"}),
|
||||
headers={'content-type': 'application/json', 'x-api-key': api_key},
|
||||
follow_redirects=True
|
||||
)
|
||||
s = json.loads(res.data)
|
||||
assert is_valid_uuid(s['uuid'])
|
||||
watch_uuid = s['uuid']
|
||||
assert res.status_code == 201
|
||||
|
||||
time.sleep(3)
|
||||
|
||||
# Verify its in the list and that recheck worked
|
||||
res = client.get(
|
||||
url_for("createwatch"),
|
||||
headers={'x-api-key': api_key}
|
||||
)
|
||||
assert watch_uuid in json.loads(res.data).keys()
|
||||
before_recheck_info = json.loads(res.data)[watch_uuid]
|
||||
assert before_recheck_info['last_checked'] != 0
|
||||
assert before_recheck_info['title'] == 'My test URL'
|
||||
|
||||
set_modified_response()
|
||||
# Trigger recheck of all ?recheck_all=1
|
||||
client.get(
|
||||
url_for("createwatch", recheck_all='1'),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
time.sleep(3)
|
||||
|
||||
# Did the recheck fire?
|
||||
res = client.get(
|
||||
url_for("createwatch"),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
after_recheck_info = json.loads(res.data)[watch_uuid]
|
||||
assert after_recheck_info['last_checked'] != before_recheck_info['last_checked']
|
||||
assert after_recheck_info['last_changed'] != 0
|
||||
|
||||
# Check history index list
|
||||
res = client.get(
|
||||
url_for("watchhistory", uuid=watch_uuid),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
history = json.loads(res.data)
|
||||
assert len(history) == 2, "Should have two history entries (the original and the changed)"
|
||||
|
||||
# Fetch a snapshot by timestamp, check the right one was found
|
||||
res = client.get(
|
||||
url_for("watchsinglehistory", uuid=watch_uuid, timestamp=list(history.keys())[-1]),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
assert b'which has this one new line' in res.data
|
||||
|
||||
# Fetch a snapshot by 'latest'', check the right one was found
|
||||
res = client.get(
|
||||
url_for("watchsinglehistory", uuid=watch_uuid, timestamp='latest'),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
assert b'which has this one new line' in res.data
|
||||
|
||||
# Fetch the whole watch
|
||||
res = client.get(
|
||||
url_for("watch", uuid=watch_uuid),
|
||||
headers={'x-api-key': api_key}
|
||||
)
|
||||
watch = json.loads(res.data)
|
||||
# @todo how to handle None/default global values?
|
||||
assert watch['history_n'] == 2, "Found replacement history section, which is in its own API"
|
||||
|
||||
# Finally delete the watch
|
||||
res = client.delete(
|
||||
url_for("watch", uuid=watch_uuid),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
assert res.status_code == 204
|
||||
|
||||
# Check via a relist
|
||||
res = client.get(
|
||||
url_for("createwatch"),
|
||||
headers={'x-api-key': api_key}
|
||||
)
|
||||
watch_list = json.loads(res.data)
|
||||
assert len(watch_list) == 0, "Watch list should be empty"
|
||||
|
||||
|
||||
def test_access_denied(client, live_server):
|
||||
# `config_api_token_enabled` Should be On by default
|
||||
res = client.get(
|
||||
url_for("createwatch")
|
||||
)
|
||||
assert res.status_code == 403
|
||||
|
||||
res = client.get(
|
||||
url_for("createwatch"),
|
||||
headers={'x-api-key': "something horrible"}
|
||||
)
|
||||
assert res.status_code == 403
|
||||
|
||||
# Disable config_api_token_enabled and it should work
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={
|
||||
"requests-time_between_check-minutes": 180,
|
||||
"application-fetch_backend": "html_requests",
|
||||
"application-api_access_token_enabled": ""
|
||||
},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
res = client.get(
|
||||
url_for("createwatch")
|
||||
)
|
||||
assert res.status_code == 200
|
||||
|
||||
@@ -29,7 +29,7 @@ def test_basic_auth(client, live_server):
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(1)
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
|
||||
@@ -3,14 +3,15 @@
|
||||
import time
|
||||
from flask import url_for
|
||||
from urllib.request import urlopen
|
||||
from . util import set_original_response, set_modified_response, live_server_setup
|
||||
from .util import set_original_response, set_modified_response, live_server_setup
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
|
||||
# Basic test to check inscriptus is not adding return line chars, basically works etc
|
||||
def test_inscriptus():
|
||||
from inscriptis import get_text
|
||||
html_content="<html><body>test!<br/>ok man</body></html>"
|
||||
html_content = "<html><body>test!<br/>ok man</body></html>"
|
||||
stripped_text_from_html = get_text(html_content)
|
||||
assert stripped_text_from_html == 'test!\nok man'
|
||||
|
||||
@@ -32,7 +33,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
|
||||
# Do this a few times.. ensures we dont accidently set the status
|
||||
for n in range(3):
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -65,7 +66,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
assert b'which has this one new line' in res.read()
|
||||
|
||||
# Force recheck
|
||||
res = client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
res = client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert b'1 watches are queued for rechecking.' in res.data
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -82,7 +83,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# re #16 should have the diff in here too
|
||||
assert b'(into ) which has this one new line' in res.data
|
||||
assert b'CDATA' in res.data
|
||||
|
||||
|
||||
assert expected_url.encode('utf-8') in res.data
|
||||
|
||||
# Following the 'diff' link, it should no longer display as 'unviewed' even after we recheck it a few times
|
||||
@@ -93,7 +94,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
|
||||
# Do this a few times.. ensures we dont accidently set the status
|
||||
for n in range(2):
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -101,7 +102,8 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
assert b'head title' not in res.data # Should not be present because this is off by default
|
||||
assert b'Mark all viewed' not in res.data
|
||||
assert b'head title' not in res.data # Should not be present because this is off by default
|
||||
assert b'test-endpoint' in res.data
|
||||
|
||||
set_original_response()
|
||||
@@ -109,20 +111,28 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
# Enable auto pickup of <title> in settings
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-extract_title_as_title": "1", "requests-time_between_check-minutes": 180, 'application-fetch_backend': "html_requests"},
|
||||
data={"application-extract_title_as_title": "1", "requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
assert b'Mark all viewed' in res.data
|
||||
|
||||
# It should have picked up the <title>
|
||||
assert b'head title' in res.data
|
||||
|
||||
# hit the mark all viewed link
|
||||
res = client.get(url_for("mark_all_viewed"), follow_redirects=True)
|
||||
|
||||
assert b'Mark all viewed' not in res.data
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
#
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("api_delete", uuid="all"), follow_redirects=True)
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
@@ -23,7 +23,7 @@ def test_trigger_functionality(client, live_server):
|
||||
|
||||
|
||||
res = client.get(
|
||||
url_for("api_clone", uuid="first"),
|
||||
url_for("form_clone", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
|
||||
@@ -89,7 +89,7 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -110,7 +110,7 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
assert bytes(css_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -118,7 +118,7 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
|
||||
@@ -145,20 +145,19 @@ def test_element_removal_full(client, live_server):
|
||||
assert bytes(subtractive_selectors_data.encode("utf-8")) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# No change yet - first check
|
||||
res = client.get(url_for("index"))
|
||||
assert b"unviewed" not in res.data
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Make a change to header/footer/nav
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -39,7 +39,7 @@ def test_check_encoding_detection(client, live_server):
|
||||
)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(2)
|
||||
@@ -71,7 +71,7 @@ def test_check_encoding_detection_missing_content_type_header(client, live_serve
|
||||
)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(2)
|
||||
|
||||
@@ -29,7 +29,7 @@ def test_error_handler(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -54,7 +54,7 @@ def test_error_text_handler(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
|
||||
@@ -0,0 +1,84 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from flask import url_for
|
||||
from .util import live_server_setup
|
||||
from urllib.parse import urlparse, parse_qs
|
||||
|
||||
def test_consistent_history(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
r = range(1, 50)
|
||||
|
||||
for one in r:
|
||||
test_url = url_for('test_endpoint', content_type="text/html", content=str(one), _external=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
time.sleep(3)
|
||||
while True:
|
||||
res = client.get(url_for("index"))
|
||||
logging.debug("Waiting for 'Checking now' to go away..")
|
||||
if b'Checking now' not in res.data:
|
||||
break
|
||||
time.sleep(0.5)
|
||||
|
||||
time.sleep(3)
|
||||
# Essentially just triggers the DB write/update
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-empty_pages_are_a_change": "",
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
# Give it time to write it out
|
||||
time.sleep(3)
|
||||
json_db_file = os.path.join(live_server.app.config['DATASTORE'].datastore_path, 'url-watches.json')
|
||||
|
||||
json_obj = None
|
||||
with open(json_db_file, 'r') as f:
|
||||
json_obj = json.load(f)
|
||||
|
||||
# assert the right amount of watches was found in the JSON
|
||||
assert len(json_obj['watching']) == len(r), "Correct number of watches was found in the JSON"
|
||||
|
||||
# each one should have a history.txt containing just one line
|
||||
for w in json_obj['watching'].keys():
|
||||
history_txt_index_file = os.path.join(live_server.app.config['DATASTORE'].datastore_path, w, 'history.txt')
|
||||
assert os.path.isfile(history_txt_index_file), "History.txt should exist where I expect it - {}".format(history_txt_index_file)
|
||||
|
||||
# Same like in model.Watch
|
||||
with open(history_txt_index_file, "r") as f:
|
||||
tmp_history = dict(i.strip().split(',', 2) for i in f.readlines())
|
||||
assert len(tmp_history) == 1, "History.txt should contain 1 line"
|
||||
|
||||
# Should be two files,. the history.txt , and the snapshot.txt
|
||||
files_in_watch_dir = os.listdir(os.path.join(live_server.app.config['DATASTORE'].datastore_path,
|
||||
w))
|
||||
# Find the snapshot one
|
||||
for fname in files_in_watch_dir:
|
||||
if fname != 'history.txt':
|
||||
# contents should match what we requested as content returned from the test url
|
||||
with open(os.path.join(live_server.app.config['DATASTORE'].datastore_path, w, fname), 'r') as snapshot_f:
|
||||
contents = snapshot_f.read()
|
||||
watch_url = json_obj['watching'][w]['url']
|
||||
u = urlparse(watch_url)
|
||||
q = parse_qs(u[4])
|
||||
assert q['content'][0] == contents.strip(), "Snapshot file {} should contain {}".format(fname, q['content'][0])
|
||||
|
||||
|
||||
|
||||
assert len(files_in_watch_dir) == 2, "Should be just two files in the dir, history.txt and the snapshot"
|
||||
@@ -102,7 +102,7 @@ def test_check_ignore_text_functionality(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -123,7 +123,7 @@ def test_check_ignore_text_functionality(client, live_server):
|
||||
assert bytes(ignore_text.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -137,7 +137,7 @@ def test_check_ignore_text_functionality(client, live_server):
|
||||
set_modified_ignore_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -152,7 +152,7 @@ def test_check_ignore_text_functionality(client, live_server):
|
||||
|
||||
# Just to be sure.. set a regular modified change..
|
||||
set_modified_original_ignore_response()
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(url_for("index"))
|
||||
@@ -165,7 +165,7 @@ def test_check_ignore_text_functionality(client, live_server):
|
||||
# We should be able to see what we ignored
|
||||
assert b'<div class="ignored">new ignore stuff' in res.data
|
||||
|
||||
res = client.get(url_for("api_delete", uuid="all"), follow_redirects=True)
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
def test_check_global_ignore_text_functionality(client, live_server):
|
||||
@@ -200,7 +200,7 @@ def test_check_global_ignore_text_functionality(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -222,7 +222,7 @@ def test_check_global_ignore_text_functionality(client, live_server):
|
||||
assert bytes(ignore_text.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -240,7 +240,7 @@ def test_check_global_ignore_text_functionality(client, live_server):
|
||||
set_modified_ignore_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -251,10 +251,10 @@ def test_check_global_ignore_text_functionality(client, live_server):
|
||||
|
||||
# Just to be sure.. set a regular modified change that will trigger it
|
||||
set_modified_original_ignore_response()
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
res = client.get(url_for("api_delete", uuid="all"), follow_redirects=True)
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
@@ -72,14 +72,14 @@ def test_render_anchor_tag_content_true(client, live_server):
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# set a new html text with a modified link
|
||||
set_modified_ignore_response()
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -101,7 +101,7 @@ def test_render_anchor_tag_content_true(client, live_server):
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -119,7 +119,7 @@ def test_render_anchor_tag_content_true(client, live_server):
|
||||
assert b"/test-endpoint" in res.data
|
||||
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("api_delete", uuid="all"),
|
||||
res = client.get(url_for("form_delete", uuid="all"),
|
||||
follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
@@ -70,12 +70,12 @@ def test_normal_page_check_works_with_ignore_status_code(client, live_server):
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
set_some_changed_response()
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -105,7 +105,7 @@ def test_403_page_check_works_with_ignore_status_code(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -120,7 +120,7 @@ def test_403_page_check_works_with_ignore_status_code(client, live_server):
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -128,7 +128,7 @@ def test_403_page_check_works_with_ignore_status_code(client, live_server):
|
||||
set_some_changed_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -157,7 +157,7 @@ def test_403_page_check_fails_without_ignore_status_code(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -172,7 +172,7 @@ def test_403_page_check_fails_without_ignore_status_code(client, live_server):
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -180,7 +180,7 @@ def test_403_page_check_fails_without_ignore_status_code(client, live_server):
|
||||
set_some_changed_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
|
||||
@@ -80,12 +80,12 @@ def test_check_ignore_whitespace(client, live_server):
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
set_original_ignore_response_but_with_whitespace()
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -5,18 +5,17 @@ import time
|
||||
from flask import url_for
|
||||
|
||||
from .util import live_server_setup
|
||||
|
||||
|
||||
def test_import(client, live_server):
|
||||
|
||||
def test_setup(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
def test_import(client, live_server):
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={
|
||||
"distill-io": "",
|
||||
"urls": """https://example.com
|
||||
https://example.com tag1
|
||||
https://example.com tag1, other tag"""
|
||||
@@ -26,3 +25,96 @@ https://example.com tag1, other tag"""
|
||||
assert b"3 Imported" in res.data
|
||||
assert b"tag1" in res.data
|
||||
assert b"other tag" in res.data
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
|
||||
# Clear flask alerts
|
||||
res = client.get( url_for("index"))
|
||||
res = client.get( url_for("index"))
|
||||
|
||||
def xtest_import_skip_url(client, live_server):
|
||||
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={
|
||||
"distill-io": "",
|
||||
"urls": """https://example.com
|
||||
:ht000000broken
|
||||
"""
|
||||
},
|
||||
follow_redirects=True,
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
assert b"ht000000broken" in res.data
|
||||
assert b"1 Skipped" in res.data
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
# Clear flask alerts
|
||||
res = client.get( url_for("index"))
|
||||
|
||||
def test_import_distillio(client, live_server):
|
||||
|
||||
distill_data='''
|
||||
{
|
||||
"client": {
|
||||
"local": 1
|
||||
},
|
||||
"data": [
|
||||
{
|
||||
"name": "Unraid | News",
|
||||
"uri": "https://unraid.net/blog",
|
||||
"config": "{\\"selections\\":[{\\"frames\\":[{\\"index\\":0,\\"excludes\\":[],\\"includes\\":[{\\"type\\":\\"xpath\\",\\"expr\\":\\"(//div[@id='App']/div[contains(@class,'flex')]/main[contains(@class,'relative')]/section[contains(@class,'relative')]/div[@class='container']/div[contains(@class,'flex')]/div[contains(@class,'w-full')])[1]\\"}]}],\\"dynamic\\":true,\\"delay\\":2}],\\"ignoreEmptyText\\":true,\\"includeStyle\\":false,\\"dataAttr\\":\\"text\\"}",
|
||||
"tags": ["nice stuff", "nerd-news"],
|
||||
"content_type": 2,
|
||||
"state": 40,
|
||||
"schedule": "{\\"type\\":\\"INTERVAL\\",\\"params\\":{\\"interval\\":4447}}",
|
||||
"ts": "2022-03-27T15:51:15.667Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
'''
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={
|
||||
"distill-io": distill_data,
|
||||
"urls" : ''
|
||||
},
|
||||
follow_redirects=True,
|
||||
)
|
||||
|
||||
|
||||
assert b"Unable to read JSON file, was it broken?" not in res.data
|
||||
assert b"1 Imported from Distill.io" in res.data
|
||||
|
||||
res = client.get( url_for("edit_page", uuid="first"))
|
||||
|
||||
assert b"https://unraid.net/blog" in res.data
|
||||
assert b"Unraid | News" in res.data
|
||||
|
||||
|
||||
# flask/wtforms should recode this, check we see it
|
||||
# wtforms encodes it like id=' ,but html.escape makes it like id='
|
||||
# - so just check it manually :(
|
||||
#import json
|
||||
#import html
|
||||
#d = json.loads(distill_data)
|
||||
# embedded_d=json.loads(d['data'][0]['config'])
|
||||
# x=html.escape(embedded_d['selections'][0]['frames'][0]['includes'][0]['expr']).encode('utf-8')
|
||||
assert b"xpath:(//div[@id='App']/div[contains(@class,'flex')]/main[contains(@class,'relative')]/section[contains(@class,'relative')]/div[@class='container']/div[contains(@class,'flex')]/div[contains(@class,'w-full')])[1]" in res.data
|
||||
|
||||
# did the tags work?
|
||||
res = client.get( url_for("index"))
|
||||
|
||||
assert b"nice stuff" in res.data
|
||||
assert b"nerd-news" in res.data
|
||||
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
# Clear flask alerts
|
||||
res = client.get(url_for("index"))
|
||||
|
||||
@@ -171,7 +171,7 @@ def test_check_json_without_filter(client, live_server):
|
||||
)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -203,7 +203,7 @@ def test_check_json_filter(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -229,7 +229,7 @@ def test_check_json_filter(client, live_server):
|
||||
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -237,7 +237,7 @@ def test_check_json_filter(client, live_server):
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(4)
|
||||
|
||||
@@ -288,7 +288,7 @@ def test_check_json_filter_bool_val(client, live_server):
|
||||
time.sleep(3)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -296,7 +296,7 @@ def test_check_json_filter_bool_val(client, live_server):
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
|
||||
@@ -327,7 +327,7 @@ def test_check_json_ext_filter(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -353,7 +353,7 @@ def test_check_json_ext_filter(client, live_server):
|
||||
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -361,7 +361,7 @@ def test_check_json_ext_filter(client, live_server):
|
||||
set_modified_ext_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(4)
|
||||
|
||||
|
||||
@@ -0,0 +1,102 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from urllib.request import urlopen
|
||||
from .util import set_original_response, set_modified_response, live_server_setup
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
|
||||
def set_nonrenderable_response():
|
||||
test_return_data = """<html>
|
||||
<head><title>modified head title</title></head>
|
||||
<!-- like when some angular app was broken and doesnt render or whatever -->
|
||||
<body>
|
||||
</body>
|
||||
</html>
|
||||
"""
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(test_return_data)
|
||||
|
||||
return None
|
||||
|
||||
def test_check_basic_change_detection_functionality(client, live_server):
|
||||
set_original_response()
|
||||
live_server_setup(live_server)
|
||||
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": url_for('test_endpoint', _external=True)},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# Do this a few times.. ensures we dont accidently set the status
|
||||
for n in range(3):
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
|
||||
#####################
|
||||
client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-empty_pages_are_a_change": "",
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# this should not trigger a change, because no good text could be converted from the HTML
|
||||
set_nonrenderable_response()
|
||||
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
|
||||
# ok now do the opposite
|
||||
|
||||
client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-empty_pages_are_a_change": "y",
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
set_modified_response()
|
||||
|
||||
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
|
||||
|
||||
|
||||
#
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
@@ -36,7 +36,7 @@ def test_check_notification(client, live_server):
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("api_watch_add"),
|
||||
url_for("form_watch_add"),
|
||||
data={"url": test_url, "tag": ''},
|
||||
follow_redirects=True
|
||||
)
|
||||
@@ -98,7 +98,7 @@ def test_check_notification(client, live_server):
|
||||
notification_submission = None
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(3)
|
||||
# Verify what was sent as a notification, this file should exist
|
||||
with open("test-datastore/notification.txt", "r") as f:
|
||||
@@ -133,7 +133,7 @@ def test_check_notification(client, live_server):
|
||||
|
||||
# This should insert the {current_snapshot}
|
||||
set_more_modified_response()
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(3)
|
||||
# Verify what was sent as a notification, this file should exist
|
||||
with open("test-datastore/notification.txt", "r") as f:
|
||||
@@ -146,17 +146,17 @@ def test_check_notification(client, live_server):
|
||||
os.unlink("test-datastore/notification.txt")
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(1)
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(1)
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(1)
|
||||
assert os.path.exists("test-datastore/notification.txt") == False
|
||||
|
||||
# cleanup for the next
|
||||
client.get(
|
||||
url_for("api_delete", uuid="all"),
|
||||
url_for("form_delete", uuid="all"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -168,7 +168,7 @@ def test_notification_validation(client, live_server):
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("api_watch_add"),
|
||||
url_for("form_watch_add"),
|
||||
data={"url": test_url, "tag": 'nice one'},
|
||||
follow_redirects=True
|
||||
)
|
||||
@@ -208,6 +208,6 @@ def test_notification_validation(client, live_server):
|
||||
|
||||
# cleanup for the next
|
||||
client.get(
|
||||
url_for("api_delete", uuid="all"),
|
||||
url_for("form_delete", uuid="all"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -16,7 +16,7 @@ def test_check_notification_error_handling(client, live_server):
|
||||
# use a different URL so that it doesnt interfere with the actual check until we are ready
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("api_watch_add"),
|
||||
url_for("form_watch_add"),
|
||||
data={"url": "https://changedetection.io/CHANGELOG.txt", "tag": ''},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -41,7 +41,7 @@ def test_share_watch(client, live_server):
|
||||
|
||||
# click share the link
|
||||
res = client.get(
|
||||
url_for("api_share_put_watch", uuid="first"),
|
||||
url_for("form_share_put_watch", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -54,7 +54,7 @@ def test_share_watch(client, live_server):
|
||||
|
||||
# Now delete what we have, we will try to re-import it
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("api_delete", uuid="all"), follow_redirects=True)
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
# Add our URL to the import page
|
||||
|
||||
@@ -39,7 +39,7 @@ def test_check_basic_change_detection_functionality_source(client, live_server):
|
||||
set_modified_response()
|
||||
|
||||
# Force recheck
|
||||
res = client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
res = client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert b'1 watches are queued for rechecking.' in res.data
|
||||
|
||||
time.sleep(5)
|
||||
|
||||
@@ -43,7 +43,7 @@ def set_modified_with_trigger_text_response():
|
||||
Some NEW nice initial text</br>
|
||||
<p>Which is across multiple lines</p>
|
||||
</br>
|
||||
foobar123
|
||||
Add to cart
|
||||
<br/>
|
||||
So let's see what happens. </br>
|
||||
</body>
|
||||
@@ -60,7 +60,7 @@ def test_trigger_functionality(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
trigger_text = "foobar123"
|
||||
trigger_text = "Add to cart"
|
||||
set_original_ignore_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -76,10 +76,7 @@ def test_trigger_functionality(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Goto the edit page, add our ignore text
|
||||
# Add our URL to the import page
|
||||
@@ -98,8 +95,14 @@ def test_trigger_functionality(client, live_server):
|
||||
)
|
||||
assert bytes(trigger_text.encode('utf-8')) in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -113,7 +116,7 @@ def test_trigger_functionality(client, live_server):
|
||||
set_modified_original_ignore_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -121,16 +124,22 @@ def test_trigger_functionality(client, live_server):
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
# Just to be sure.. set a regular modified change..
|
||||
# Now set the content which contains the trigger text
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
set_modified_with_trigger_text_response()
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
# https://github.com/dgtlmoon/changedetection.io/issues/616
|
||||
# Apparently the actual snapshot that contains the trigger never shows
|
||||
res = client.get(url_for("diff_history_page", uuid="first"))
|
||||
assert b'Add to cart' in res.data
|
||||
|
||||
# Check the preview/highlighter, we should be able to see what we triggered on, but it should be highlighted
|
||||
res = client.get(url_for("preview_page", uuid="first"))
|
||||
# We should be able to see what we ignored
|
||||
assert b'<div class="triggered">foobar' in res.data
|
||||
|
||||
# We should be able to see what we triggered on
|
||||
assert b'<div class="triggered">Add to cart' in res.data
|
||||
@@ -42,9 +42,6 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -60,12 +57,14 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
# so that we set the state to 'unviewed' after all the edits
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("some new noise")
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (nothing should match the regex)
|
||||
@@ -75,7 +74,11 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("regex test123<br/>\nsomething 123")
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
@@ -22,10 +22,9 @@ def set_original_ignore_response():
|
||||
|
||||
|
||||
|
||||
def test_trigger_regex_functionality(client, live_server):
|
||||
def test_trigger_regex_functionality_with_filter(client, live_server):
|
||||
|
||||
live_server_setup(live_server)
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
set_original_ignore_response()
|
||||
@@ -42,43 +41,44 @@ def test_trigger_regex_functionality(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
# it needs time to save the original version
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (just a new one shouldnt have anything)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
### test regex with filter
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"trigger_text": "/cool.stuff\d/",
|
||||
data={"trigger_text": "/cool.stuff/",
|
||||
"url": test_url,
|
||||
"css_filter": '#in-here',
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
client.get(url_for("diff_history_page", uuid="first"))
|
||||
|
||||
# Check that we have the expected text.. but it's not in the css filter we want
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("<html>some new noise with cool stuff2 ok</html>")
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
# It should report nothing found (nothing should match the regex and filter)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
|
||||
# now this should trigger something
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("<html>some new noise with <span id=in-here>cool stuff6</span> ok</html>")
|
||||
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
|
||||
# Cleanup everything
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
@@ -44,6 +44,61 @@ def set_modified_response():
|
||||
|
||||
return None
|
||||
|
||||
# Handle utf-8 charset replies https://github.com/dgtlmoon/changedetection.io/pull/613
|
||||
def test_check_xpath_filter_utf8(client, live_server):
|
||||
filter='//item/*[self::description]'
|
||||
|
||||
d='''<?xml version="1.0" encoding="UTF-8"?>
|
||||
<rss xmlns:taxo="http://purl.org/rss/1.0/modules/taxonomy/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd" xmlns:dc="http://purl.org/dc/elements/1.1/" version="2.0">
|
||||
<channel>
|
||||
<title>rpilocator.com</title>
|
||||
<link>https://rpilocator.com</link>
|
||||
<description>Find Raspberry Pi Computers in Stock</description>
|
||||
<lastBuildDate>Thu, 19 May 2022 23:27:30 GMT</lastBuildDate>
|
||||
<image>
|
||||
<url>https://rpilocator.com/favicon.png</url>
|
||||
<title>rpilocator.com</title>
|
||||
<link>https://rpilocator.com/</link>
|
||||
<width>32</width>
|
||||
<height>32</height>
|
||||
</image>
|
||||
<item>
|
||||
<title>Stock Alert (UK): RPi CM4 - 1GB RAM, No MMC, No Wifi is In Stock at Pimoroni</title>
|
||||
<description>Stock Alert (UK): RPi CM4 - 1GB RAM, No MMC, No Wifi is In Stock at Pimoroni</description>
|
||||
<link>https://rpilocator.com?vendor=pimoroni&utm_source=feed&utm_medium=rss</link>
|
||||
<category>pimoroni</category>
|
||||
<category>UK</category>
|
||||
<category>CM4</category>
|
||||
<guid isPermaLink="false">F9FAB0D9-DF6F-40C8-8DEE5FC0646BB722</guid>
|
||||
<pubDate>Thu, 19 May 2022 14:32:32 GMT</pubDate>
|
||||
</item>
|
||||
</channel>
|
||||
</rss>'''
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(d)
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True, content_type="application/rss+xml;charset=UTF-8")
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
time.sleep(3)
|
||||
res = client.get(url_for("index"))
|
||||
assert b'Unicode strings with encoding declaration are not supported.' not in res.data
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
|
||||
def test_check_markup_xpath_filter_restriction(client, live_server):
|
||||
sleep_time_for_fetch_thread = 3
|
||||
@@ -65,7 +120,7 @@ def test_check_markup_xpath_filter_restriction(client, live_server):
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -89,12 +144,14 @@ def test_check_markup_xpath_filter_restriction(client, live_server):
|
||||
set_modified_response()
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("api_watch_checknow"), follow_redirects=True)
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' not in res.data
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
def test_xpath_validation(client, live_server):
|
||||
@@ -116,4 +173,46 @@ def test_xpath_validation(client, live_server):
|
||||
data={"css_filter": "/something horrible", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"is not a valid XPath expression" in res.data
|
||||
assert b"is not a valid XPath expression" in res.data
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
|
||||
# actually only really used by the distll.io importer, but could be handy too
|
||||
def test_check_with_prefix_css_filter(client, live_server):
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
set_original_response()
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(3)
|
||||
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": "xpath://*[contains(@class, 'sametext')]", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Updated watch." in res.data
|
||||
time.sleep(3)
|
||||
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Some text thats the same" in res.data #in selector
|
||||
assert b"Some text that will change" not in res.data #not in selector
|
||||
|
||||
client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
from flask import make_response, request
|
||||
from flask import url_for
|
||||
|
||||
def set_original_response():
|
||||
test_return_data = """<html>
|
||||
@@ -55,14 +56,32 @@ def set_more_modified_response():
|
||||
return None
|
||||
|
||||
|
||||
# kinda funky, but works for now
|
||||
def extract_api_key_from_UI(client):
|
||||
import re
|
||||
res = client.get(
|
||||
url_for("settings_page"),
|
||||
)
|
||||
# <span id="api-key">{{api_key}}</span>
|
||||
|
||||
m = re.search('<span id="api-key">(.+?)</span>', str(res.data))
|
||||
api_key = m.group(1)
|
||||
return api_key.strip()
|
||||
|
||||
def live_server_setup(live_server):
|
||||
|
||||
@live_server.app.route('/test-endpoint')
|
||||
def test_endpoint():
|
||||
ctype = request.args.get('content_type')
|
||||
status_code = request.args.get('status_code')
|
||||
content = request.args.get('content') or None
|
||||
|
||||
try:
|
||||
if content is not None:
|
||||
resp = make_response(content, status_code)
|
||||
resp.headers['Content-Type'] = ctype if ctype else 'text/html'
|
||||
return resp
|
||||
|
||||
# Tried using a global var here but didn't seem to work, so reading from a file instead.
|
||||
with open("test-datastore/endpoint-content.txt", "r") as f:
|
||||
resp = make_response(f.read(), status_code)
|
||||
|
||||
@@ -40,10 +40,11 @@ class update_worker(threading.Thread):
|
||||
contents = ""
|
||||
screenshot = False
|
||||
update_obj= {}
|
||||
xpath_data = False
|
||||
now = time.time()
|
||||
|
||||
try:
|
||||
changed_detected, update_obj, contents, screenshot = update_handler.run(uuid)
|
||||
changed_detected, update_obj, contents, screenshot, xpath_data = update_handler.run(uuid)
|
||||
|
||||
# Re #342
|
||||
# In Python 3, all strings are sequences of Unicode characters. There is a bytes type that holds raw bytes.
|
||||
@@ -52,11 +53,25 @@ class update_worker(threading.Thread):
|
||||
raise Exception("Error - returned data from the fetch handler SHOULD be bytes")
|
||||
except PermissionError as e:
|
||||
self.app.logger.error("File permission error updating", uuid, str(e))
|
||||
except content_fetcher.ReplyWithContentButNoText as e:
|
||||
# Totally fine, it's by choice - just continue on, nothing more to care about
|
||||
# Page had elements/content but no renderable text
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': "Got HTML content but no text found."})
|
||||
pass
|
||||
except content_fetcher.EmptyReply as e:
|
||||
# Some kind of custom to-str handler in the exception handler that does this?
|
||||
err_text = "EmptyReply: Status Code {}".format(e.status_code)
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
except content_fetcher.ScreenshotUnavailable as e:
|
||||
err_text = "Screenshot unavailable, page did not render fully in the expected time"
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
except content_fetcher.PageUnloadable as e:
|
||||
err_text = "Page request from server didnt respond correctly"
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
'last_check_status': e.status_code})
|
||||
|
||||
except Exception as e:
|
||||
self.app.logger.error("Exception reached processing watch UUID: %s - %s", uuid, str(e))
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': str(e)})
|
||||
@@ -69,9 +84,7 @@ class update_worker(threading.Thread):
|
||||
# For the FIRST time we check a site, or a change detected, save the snapshot.
|
||||
if changed_detected or not watch['last_checked']:
|
||||
# A change was detected
|
||||
fname = self.datastore.save_history_text(watch_uuid=uuid, contents=contents)
|
||||
# Should always be keyed by string(timestamp)
|
||||
self.datastore.update_watch(uuid, {"history": {str(round(time.time())): fname}})
|
||||
fname = watch.save_history_text(contents=contents, timestamp=str(round(time.time())))
|
||||
|
||||
# Generally update anything interesting returned
|
||||
self.datastore.update_watch(uuid=uuid, update_obj=update_obj)
|
||||
@@ -82,16 +95,10 @@ class update_worker(threading.Thread):
|
||||
print (">> Change detected in UUID {} - {}".format(uuid, watch['url']))
|
||||
|
||||
# Notifications should only trigger on the second time (first time, we gather the initial snapshot)
|
||||
if len(watch['history']) > 1:
|
||||
if watch.history_n >= 2:
|
||||
|
||||
dates = list(watch['history'].keys())
|
||||
# Convert to int, sort and back to str again
|
||||
# @todo replace datastore getter that does this automatically
|
||||
dates = [int(i) for i in dates]
|
||||
dates.sort(reverse=True)
|
||||
dates = [str(i) for i in dates]
|
||||
|
||||
prev_fname = watch['history'][dates[1]]
|
||||
dates = list(watch.history.keys())
|
||||
prev_fname = watch.history[dates[-2]]
|
||||
|
||||
|
||||
# Did it have any notification alerts to hit?
|
||||
@@ -144,6 +151,9 @@ class update_worker(threading.Thread):
|
||||
# Always save the screenshot if it's available
|
||||
if screenshot:
|
||||
self.datastore.save_screenshot(watch_uuid=uuid, screenshot=screenshot)
|
||||
if xpath_data:
|
||||
self.datastore.save_xpath_data(watch_uuid=uuid, data=xpath_data)
|
||||
|
||||
|
||||
self.current_uuid = None # Done
|
||||
self.q.task_done()
|
||||
|
||||
@@ -17,12 +17,19 @@ services:
|
||||
# Alternative WebDriver/selenium URL, do not use "'s or 's!
|
||||
# - WEBDRIVER_URL=http://browser-chrome:4444/wd/hub
|
||||
#
|
||||
# WebDriver proxy settings webdriver_proxyType, webdriver_ftpProxy, webdriver_httpProxy, webdriver_noProxy,
|
||||
# webdriver_proxyAutoconfigUrl, webdriver_sslProxy, webdriver_autodetect,
|
||||
# WebDriver proxy settings webdriver_proxyType, webdriver_ftpProxy, webdriver_noProxy,
|
||||
# webdriver_proxyAutoconfigUrl, webdriver_autodetect,
|
||||
# webdriver_socksProxy, webdriver_socksUsername, webdriver_socksVersion, webdriver_socksPassword
|
||||
#
|
||||
# https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.proxy
|
||||
#
|
||||
# Alternative Playwright URL, do not use "'s or 's!
|
||||
# - PLAYWRIGHT_DRIVER_URL=ws://playwright-chrome:3000/
|
||||
#
|
||||
# Playwright proxy settings playwright_proxy_server, playwright_proxy_bypass, playwright_proxy_username, playwright_proxy_password
|
||||
#
|
||||
# https://playwright.dev/python/docs/api/class-browsertype#browser-type-launch-option-proxy
|
||||
#
|
||||
# Plain requsts - proxy support example.
|
||||
# - HTTP_PROXY=socks5h://10.10.1.10:1080
|
||||
# - HTTPS_PROXY=socks5h://10.10.1.10:1080
|
||||
@@ -58,6 +65,13 @@ services:
|
||||
# # Workaround to avoid the browser crashing inside a docker container
|
||||
# # See https://github.com/SeleniumHQ/docker-selenium#quick-start
|
||||
# - /dev/shm:/dev/shm
|
||||
# restart: unless-stopped
|
||||
|
||||
# Used for fetching pages via Playwright+Chrome where you need Javascript support.
|
||||
|
||||
# playwright-chrome:
|
||||
# hostname: playwright-chrome
|
||||
# image: browserless/chrome
|
||||
# restart: unless-stopped
|
||||
|
||||
volumes:
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 894 B After Width: | Height: | Size: 894 B |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 115 KiB After Width: | Height: | Size: 115 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB After Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 190 KiB After Width: | Height: | Size: 190 KiB |
{kind=link}
|
After Width: | Height: | Size: 238 KiB |
@@ -6,6 +6,7 @@ timeago ~=1.0
|
||||
inscriptis ~= 2.2
|
||||
feedgen ~= 0.9
|
||||
flask-login ~= 0.5
|
||||
flask_restful
|
||||
pytz
|
||||
|
||||
# Set these versions together to avoid a RequestsDependencyWarning
|
||||
@@ -17,7 +18,7 @@ wtforms ~= 3.0
|
||||
jsonpath-ng ~= 1.5.3
|
||||
|
||||
# Notification library
|
||||
apprise ~= 0.9.8.3
|
||||
apprise ~= 0.9.9
|
||||
|
||||
# apprise mqtt https://github.com/dgtlmoon/changedetection.io/issues/315
|
||||
paho-mqtt
|
||||
@@ -40,3 +41,4 @@ selenium ~= 4.1.0
|
||||
# need to revisit flask login versions
|
||||
werkzeug ~= 2.0.0
|
||||
|
||||
# playwright is installed at Dockerfile build time because it's not available on all platforms
|
||||
|
||||