mirror of
https://github.com/dgtlmoon/changedetection.io.git
synced 2025-10-30 22:27:52 +00:00
Compare commits
103 Commits
fetchers-a
...
jinja2-url
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8677b65cc8 | ||
|
|
10813b130c | ||
|
|
0988bef2cd | ||
|
|
5b281f2c34 | ||
|
|
a224f64cd6 | ||
|
|
7ee97ae37f | ||
|
|
69756f20f2 | ||
|
|
326b7aacbb | ||
|
|
fde7b3fd97 | ||
|
|
9d04cb014a | ||
|
|
5b530ff61c | ||
|
|
c98536ace4 | ||
|
|
463747d3b7 | ||
|
|
791bdb42aa | ||
|
|
ce6c2737a8 | ||
|
|
ade9e1138b | ||
|
|
68d5178367 | ||
|
|
41dc57aee3 | ||
|
|
943704cd04 | ||
|
|
883561f979 | ||
|
|
35d44c8277 | ||
|
|
d07d7a1b18 | ||
|
|
f066a1c38f | ||
|
|
d0d191a7d1 | ||
|
|
d7482c8d6a | ||
|
|
bcf7417f63 | ||
|
|
df6e835035 | ||
|
|
ab28f20eba | ||
|
|
1174b95ab4 | ||
|
|
a564475325 | ||
|
|
85d8d57997 | ||
|
|
359dcb63e3 | ||
|
|
b043d477dc | ||
|
|
06bcfb28e5 | ||
|
|
ca3b351bae | ||
|
|
b7e0f0a5e4 | ||
|
|
61f0ac2937 | ||
|
|
fca66eb558 | ||
|
|
359fc48fb4 | ||
|
|
d0efeb9770 | ||
|
|
3416532cd6 | ||
|
|
defc7a340e | ||
|
|
c197c062e1 | ||
|
|
77b59809ca | ||
|
|
f90b170e68 | ||
|
|
c93ca1841c | ||
|
|
57f604dff1 | ||
|
|
8499468749 | ||
|
|
7f6a13ea6c | ||
|
|
9874f0cbc7 | ||
|
|
72834a42fd | ||
|
|
724cb17224 | ||
|
|
4eb4b401a1 | ||
|
|
5d40e16c73 | ||
|
|
492bbce6b6 | ||
|
|
0394a56be5 | ||
|
|
7839551d6b | ||
|
|
9c5588c791 | ||
|
|
5a43a350de | ||
|
|
3c31f023ce | ||
|
|
4cbcc59461 | ||
|
|
4be0260381 | ||
|
|
957a3c1c16 | ||
|
|
85897e0bf9 | ||
|
|
63095f70ea | ||
|
|
8d5b0b5576 | ||
|
|
1b077abd93 | ||
|
|
32ea1a8721 | ||
|
|
fff32cef0d | ||
|
|
8fb146f3e4 | ||
|
|
770b0faa45 | ||
|
|
f6faa90340 | ||
|
|
669fd3ae0b | ||
|
|
17d37fb626 | ||
|
|
dfa7fc3a81 | ||
|
|
cd467df97a | ||
|
|
71bc2fed82 | ||
|
|
738fcfe01c | ||
|
|
3ebb2ab9ba | ||
|
|
ac98bc9144 | ||
|
|
3705ce6681 | ||
|
|
f7ea99412f | ||
|
|
d4715e2bc8 | ||
|
|
8567a83c47 | ||
|
|
77fdf59ae3 | ||
|
|
0e194aa4b4 | ||
|
|
2ba55bb477 | ||
|
|
4c759490da | ||
|
|
58a52c1f60 | ||
|
|
22638399c1 | ||
|
|
e3381776f2 | ||
|
|
26e2f21a80 | ||
|
|
b6009ae9ff | ||
|
|
b046d6ef32 | ||
|
|
e154a3cb7a | ||
|
|
1262700263 | ||
|
|
434c5813b9 | ||
|
|
0a3dc7d77b | ||
|
|
a7e296de65 | ||
|
|
bd0fbaaf27 | ||
|
|
0c111bd9ae | ||
|
|
ed9ac0b7fb | ||
|
|
743a3069bb |
31
.github/test/Dockerfile-alpine
vendored
Normal file
31
.github/test/Dockerfile-alpine
vendored
Normal file
@@ -0,0 +1,31 @@
|
||||
# Taken from https://github.com/linuxserver/docker-changedetection.io/blob/main/Dockerfile
|
||||
# Test that we can still build on Alpine (musl modified libc https://musl.libc.org/)
|
||||
# Some packages wont install via pypi because they dont have a wheel available under this architecture.
|
||||
|
||||
FROM ghcr.io/linuxserver/baseimage-alpine:3.16
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
|
||||
COPY requirements.txt /requirements.txt
|
||||
|
||||
RUN \
|
||||
apk add --update --no-cache --virtual=build-dependencies \
|
||||
cargo \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libxslt-dev \
|
||||
make \
|
||||
openssl-dev \
|
||||
py3-wheel \
|
||||
python3-dev \
|
||||
zlib-dev && \
|
||||
apk add --update --no-cache \
|
||||
libxslt \
|
||||
python3 \
|
||||
py3-pip && \
|
||||
echo "**** pip3 install test of changedetection.io ****" && \
|
||||
pip3 install -U pip wheel setuptools && \
|
||||
pip3 install -U --no-cache-dir --find-links https://wheel-index.linuxserver.io/alpine-3.16/ -r /requirements.txt && \
|
||||
apk del --purge \
|
||||
build-dependencies
|
||||
66
.github/workflows/test-container-build.yml
vendored
Normal file
66
.github/workflows/test-container-build.yml
vendored
Normal file
@@ -0,0 +1,66 @@
|
||||
name: ChangeDetection.io Container Build Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
|
||||
# This line doesnt work, even tho it is the documented one
|
||||
#on: [push, pull_request]
|
||||
|
||||
on:
|
||||
push:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
|
||||
pull_request:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
|
||||
# Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
|
||||
# @todo: some kind of path filter for requirements.txt and Dockerfile
|
||||
jobs:
|
||||
test-container-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
# Just test that the build works, some libraries won't compile on ARM/rPi etc
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v1
|
||||
with:
|
||||
image: tonistiigi/binfmt:latest
|
||||
platforms: all
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
id: buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
with:
|
||||
install: true
|
||||
version: latest
|
||||
driver-opts: image=moby/buildkit:master
|
||||
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067
|
||||
# Check we can still build under alpine/musl
|
||||
- name: Test that the docker containers can build (musl via alpine check)
|
||||
id: docker_build_musl
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: ./
|
||||
file: ./.github/test/Dockerfile-alpine
|
||||
platforms: linux/amd64,linux/arm64
|
||||
|
||||
- name: Test that the docker containers can build
|
||||
id: docker_build
|
||||
uses: docker/build-push-action@v2
|
||||
# https://github.com/docker/build-push-action#customizing
|
||||
with:
|
||||
context: ./
|
||||
file: ./Dockerfile
|
||||
platforms: linux/arm/v7,linux/arm/v6,linux/amd64,linux/arm64,
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
12
.github/workflows/test-only.yml
vendored
12
.github/workflows/test-only.yml
vendored
@@ -1,28 +1,25 @@
|
||||
name: ChangeDetection.io Test
|
||||
name: ChangeDetection.io App Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
on: [push, pull_request]
|
||||
|
||||
jobs:
|
||||
test-build:
|
||||
test-application:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
- name: Show env vars
|
||||
run: set
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install flake8 pytest
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
|
||||
- name: Lint with flake8
|
||||
run: |
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
@@ -39,7 +36,4 @@ jobs:
|
||||
# Each test is totally isolated and performs its own cleanup/reset
|
||||
cd changedetectionio; ./run_all_tests.sh
|
||||
|
||||
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||
|
||||
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||
|
||||
1
.gitignore
vendored
1
.gitignore
vendored
@@ -8,6 +8,7 @@ __pycache__
|
||||
build
|
||||
dist
|
||||
venv
|
||||
test-datastore/*
|
||||
test-datastore
|
||||
*.egg-info*
|
||||
.vscode/settings.json
|
||||
|
||||
@@ -6,7 +6,7 @@ Otherwise, it's always best to PR into the `dev` branch.
|
||||
|
||||
Please be sure that all new functionality has a matching test!
|
||||
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notifications.py` for example
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notification.py` for example
|
||||
|
||||
```
|
||||
pip3 install -r requirements-dev
|
||||
|
||||
23
Dockerfile
23
Dockerfile
@@ -5,13 +5,15 @@ FROM python:3.8-slim as builder
|
||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libjpeg-dev \
|
||||
libssl-dev \
|
||||
libxslt-dev \
|
||||
zlib1g-dev \
|
||||
g++
|
||||
make \
|
||||
zlib1g-dev
|
||||
|
||||
RUN mkdir /install
|
||||
WORKDIR /install
|
||||
@@ -22,7 +24,8 @@ RUN pip install --target=/dependencies -r /requirements.txt
|
||||
|
||||
# Playwright is an alternative to Selenium
|
||||
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
||||
RUN pip install --target=/dependencies playwright~=1.24 \
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067 also musl/alpine (not supported)
|
||||
RUN pip install --target=/dependencies playwright~=1.27.1 \
|
||||
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
||||
|
||||
# Final image stage
|
||||
@@ -34,13 +37,14 @@ ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
# Re #93, #73, excluding rustc (adds another 430Mb~)
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libjpeg-dev \
|
||||
libssl-dev \
|
||||
libxslt-dev \
|
||||
zlib1g-dev \
|
||||
g++
|
||||
zlib1g-dev
|
||||
|
||||
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
@@ -58,6 +62,7 @@ EXPOSE 5000
|
||||
|
||||
# The actual flask app
|
||||
COPY changedetectionio /app/changedetectionio
|
||||
|
||||
# The eventlet server wrapper
|
||||
COPY changedetection.py /app/changedetection.py
|
||||
|
||||
|
||||
@@ -2,7 +2,12 @@ recursive-include changedetectionio/api *
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/model *
|
||||
recursive-include changedetectionio/tests *
|
||||
recursive-include changedetectionio/res *
|
||||
prune changedetectionio/static/package-lock.json
|
||||
prune changedetectionio/static/styles/node_modules
|
||||
prune changedetectionio/static/styles/package-lock.json
|
||||
include changedetection.py
|
||||
global-exclude *.pyc
|
||||
global-exclude node_modules
|
||||
global-exclude venv
|
||||
global-exclude venv
|
||||
|
||||
@@ -1,45 +1,48 @@
|
||||
# changedetection.io
|
||||

|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io" alt="Docker Pulls"/>
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/github/v/release/dgtlmoon/changedetection.io" alt="Change detection latest tag version"/>
|
||||
</a>
|
||||
## Web Site Change Detection, Monitoring and Notification.
|
||||
|
||||
## Self-hosted open source change monitoring of web pages.
|
||||
Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
|
||||
|
||||
_Know when web pages change! Stay ontop of new information!_
|
||||
|
||||
Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start?src=pip)
|
||||
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />
|
||||
|
||||
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
|
||||
[**Try our $6.99/month subscription - unlimited checks, watches and notifications!**](https://lemonade.changedetection.io/start), choose from different geographical locations, let us handle everything for you.
|
||||
|
||||
[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
#### Example use cases
|
||||
|
||||
Know when ...
|
||||
|
||||
- Government department updates (changes are often only on their websites)
|
||||
- Local government news (changes are often only on their websites)
|
||||
- Products and services have a change in pricing
|
||||
- _Out of stock notification_ and _Back In stock notification_
|
||||
- Governmental department updates (changes are often only on their websites)
|
||||
- New software releases, security advisories when you're not on their mailing list.
|
||||
- Festivals with changes
|
||||
- Realestate listing changes
|
||||
- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
|
||||
- COVID related news from government websites
|
||||
- University/organisation news from their website
|
||||
- Detect and monitor changes in JSON API responses
|
||||
- API monitoring and alerting
|
||||
- JSON API monitoring and alerting
|
||||
- Changes in legal and other documents
|
||||
- Trigger API calls via notifications when text appears on a website
|
||||
- Glue together APIs using the JSON filter and JSON notifications
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
|
||||
#### Key Features
|
||||
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
|
||||
**Get monitoring now!**
|
||||
|
||||
```bash
|
||||
$ pip3 install changedetection.io
|
||||
$ pip3 install changedetection.io
|
||||
```
|
||||
|
||||
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
|
||||
@@ -51,17 +54,5 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
|
||||
|
||||
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
|
||||
|
||||
### Features
|
||||
- Website monitoring
|
||||
- Change detection of content and analyses
|
||||
- Filters on change (Select by CSS or JSON)
|
||||
- Triggers (Wait for text, wait for regex)
|
||||
- Notification support
|
||||
- JSON API Monitoring
|
||||
- Parse JSON embedded in HTML
|
||||
- (Reverse) Proxy support
|
||||
- Javascript support via WebDriver
|
||||
- RaspberriPi (arm v6/v7/64 support)
|
||||
|
||||
See https://github.com/dgtlmoon/changedetection.io for more information.
|
||||
|
||||
|
||||
66
README.md
66
README.md
@@ -1,22 +1,24 @@
|
||||
## Web Site Change Detection, Monitoring and Notification.
|
||||
|
||||
Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
|
||||
_Live your data-life pro-actively, Detect website changes and perform meaningful actions, trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start?src=github)
|
||||
|
||||
[![Release Version][release-shield]][release-link] [![Docker Pulls][docker-pulls]][docker-link] [![License][license-shield]](LICENSE.md)
|
||||
|
||||

|
||||
|
||||
Know when important content changes, we support notifications via Discord, Telegram, Home-Assistant, Slack, Email and 70+ more
|
||||
|
||||
[**Don't have time? Let us host it for you! try our $6.99/month subscription - use our proxies and support!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
||||
|
||||
- Chrome browser included.
|
||||
- Super fast, no registration needed setup.
|
||||
- Start watching and receiving change notifications instantly.
|
||||
|
||||
|
||||
- Automatic Updates, Automatic Backups, No Heroku "paused application", don't miss a change!
|
||||
- Javascript browser included
|
||||
- Unlimited checks and watches!
|
||||
Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
|
||||
#### Example use cases
|
||||
@@ -38,36 +40,46 @@ Know when important content changes, we support notifications via Discord, Teleg
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
- Get notified when certain keywords appear in Twitter search results
|
||||
- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
|
||||
#### Key Features
|
||||
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JsonPath rules
|
||||
- Target elements with xPath and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
|
||||
- Send a screenshot with the notification when a change is detected in the web page
|
||||
|
||||
We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
|
||||
|
||||
## Screenshots
|
||||
|
||||
### Examine differences in content.
|
||||
|
||||
Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
### Filter by elements using the Visual Selector tool.
|
||||
### Target specific parts of the webpage using the Visual Selector tool.
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (included as part of our subscription service)
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
### Perform interactive browser steps
|
||||
|
||||
Fill in text boxes, click buttons and more, setup your changedetection scenario.
|
||||
|
||||
Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
|
||||
|
||||
<img src="docs/browsersteps-anim.gif" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Website change detection with interactive browser steps, login, cookies etc" />
|
||||
|
||||
After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
|
||||
Requires Playwright to be enabled.
|
||||
|
||||
## Installation
|
||||
|
||||
### Docker
|
||||
@@ -107,8 +119,8 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
|
||||
### Docker
|
||||
```
|
||||
docker pull dgtlmoon/changedetection.io
|
||||
docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker kill $(docker ps -a -f name=changedetection.io -q)
|
||||
docker rm $(docker ps -a -f name=changedetection.io -q)
|
||||
docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
|
||||
```
|
||||
|
||||
@@ -122,8 +134,8 @@ See the wiki for more information https://github.com/dgtlmoon/changedetection.io
|
||||
|
||||
|
||||
## Filters
|
||||
XPath, JSONPath and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
|
||||
XPath, JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
(We support LXML `re:test`, `re:math` and `re:replace`.)
|
||||
|
||||
## Notifications
|
||||
@@ -152,7 +164,7 @@ Now you can also customise your notification content!
|
||||
|
||||
## JSON API Monitoring
|
||||
|
||||
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||
Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
|
||||
|
||||

|
||||
|
||||
@@ -160,9 +172,17 @@ This will re-parse the JSON and apply formatting to the text, making it super ea
|
||||
|
||||
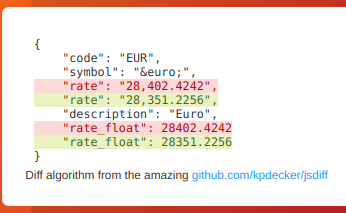
|
||||
|
||||
### JSONPath or jq?
|
||||
|
||||
For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specifc information on jq.
|
||||
|
||||
One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
|
||||
|
||||
### Parse JSON embedded in HTML!
|
||||
|
||||
When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
|
||||
```
|
||||
<html>
|
||||
@@ -172,11 +192,11 @@ When you enable a `json:` filter, you can even automatically extract and parse e
|
||||
</script>
|
||||
```
|
||||
|
||||
`json:$.price` would give `23.50`, or you can extract the whole structure
|
||||
`json:$.price` or `jq:.price` would give `23.50`, or you can extract the whole structure
|
||||
|
||||
## Proxy configuration
|
||||
## Proxy Configuration
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [BrightData proxy services where possible]( https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support)
|
||||
|
||||
## Raspberry Pi support?
|
||||
|
||||
|
||||
@@ -1,29 +1,20 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
|
||||
# @todo logging
|
||||
# @todo extra options for url like , verify=False etc.
|
||||
# @todo enable https://urllib3.readthedocs.io/en/latest/user-guide.html#ssl as option?
|
||||
# @todo option for interval day/6 hour/etc
|
||||
# @todo on change detected, config for calling some API
|
||||
# @todo fetch title into json
|
||||
# https://distill.io/features
|
||||
# proxy per check
|
||||
# - flask_cors, itsdangerous,MarkupSafe
|
||||
|
||||
import datetime
|
||||
import flask_login
|
||||
import logging
|
||||
import os
|
||||
import pytz
|
||||
import queue
|
||||
import threading
|
||||
import time
|
||||
import timeago
|
||||
|
||||
from copy import deepcopy
|
||||
from distutils.util import strtobool
|
||||
from feedgen.feed import FeedGenerator
|
||||
from threading import Event
|
||||
|
||||
import flask_login
|
||||
import logging
|
||||
import pytz
|
||||
import timeago
|
||||
from feedgen.feed import FeedGenerator
|
||||
from flask import (
|
||||
Flask,
|
||||
abort,
|
||||
@@ -38,13 +29,12 @@ from flask import (
|
||||
)
|
||||
from flask_login import login_required
|
||||
from flask_restful import abort, Api
|
||||
|
||||
from flask_wtf import CSRFProtect
|
||||
|
||||
from changedetectionio import html_tools
|
||||
from changedetectionio.api import api_v1
|
||||
|
||||
__version__ = '0.39.18'
|
||||
__version__ = '0.39.22.1'
|
||||
|
||||
datastore = None
|
||||
|
||||
@@ -55,7 +45,6 @@ ticker_thread = None
|
||||
extra_stylesheets = []
|
||||
|
||||
update_q = queue.PriorityQueue()
|
||||
|
||||
notification_q = queue.Queue()
|
||||
|
||||
app = Flask(__name__,
|
||||
@@ -108,7 +97,7 @@ def _jinja2_filter_datetime(watch_obj, format="%Y-%m-%d %H:%M:%S"):
|
||||
# Worker thread tells us which UUID it is currently processing.
|
||||
for t in running_update_threads:
|
||||
if t.current_uuid == watch_obj['uuid']:
|
||||
return '<span class="loader"></span><span> Checking now</span>'
|
||||
return '<span class="spinner"></span><span> Checking now</span>'
|
||||
|
||||
if watch_obj['last_checked'] == 0:
|
||||
return 'Not yet'
|
||||
@@ -205,7 +194,8 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
watch_api.add_resource(api_v1.Watch, '/api/v1/watch/<string:uuid>',
|
||||
resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
|
||||
|
||||
|
||||
watch_api.add_resource(api_v1.SystemInfo, '/api/v1/systeminfo',
|
||||
resource_class_kwargs={'datastore': datastore, 'update_q': update_q})
|
||||
|
||||
|
||||
|
||||
@@ -535,6 +525,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
def edit_page(uuid):
|
||||
from changedetectionio import forms
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import browser_step_ui_config
|
||||
|
||||
using_default_check_time = True
|
||||
# More for testing, possible to return the first/only
|
||||
@@ -552,16 +543,13 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
# be sure we update with a copy instead of accidently editing the live object by reference
|
||||
default = deepcopy(datastore.data['watching'][uuid])
|
||||
|
||||
# Show system wide default if nothing configured
|
||||
if datastore.data['watching'][uuid]['fetch_backend'] is None:
|
||||
default['fetch_backend'] = datastore.data['settings']['application']['fetch_backend']
|
||||
|
||||
# Show system wide default if nothing configured
|
||||
if all(value == 0 or value == None for value in datastore.data['watching'][uuid]['time_between_check'].values()):
|
||||
default['time_between_check'] = deepcopy(datastore.data['settings']['requests']['time_between_check'])
|
||||
|
||||
# Defaults for proxy choice
|
||||
if datastore.proxy_list is not None: # When enabled
|
||||
# @todo
|
||||
# Radio needs '' not None, or incase that the chosen one no longer exists
|
||||
if default['proxy'] is None or not any(default['proxy'] in tup for tup in datastore.proxy_list):
|
||||
default['proxy'] = ''
|
||||
@@ -571,11 +559,16 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
data=default,
|
||||
)
|
||||
|
||||
# form.browser_steps[0] can be assumed that we 'goto url' first
|
||||
|
||||
if datastore.proxy_list is None:
|
||||
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
||||
del form.proxy
|
||||
else:
|
||||
form.proxy.choices = [('', 'Default')] + datastore.proxy_list
|
||||
form.proxy.choices = [('', 'Default')]
|
||||
for p in datastore.proxy_list:
|
||||
form.proxy.choices.append(tuple((p, datastore.proxy_list[p]['label'])))
|
||||
|
||||
|
||||
if request.method == 'POST' and form.validate():
|
||||
extra_update_obj = {}
|
||||
@@ -598,10 +591,8 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
if form.fetch_backend.data == datastore.data['settings']['application']['fetch_backend']:
|
||||
extra_update_obj['fetch_backend'] = None
|
||||
|
||||
# Notification URLs
|
||||
datastore.data['watching'][uuid]['notification_urls'] = form.notification_urls.data
|
||||
|
||||
# Ignore text
|
||||
# Ignore text
|
||||
form_ignore_text = form.ignore_text.data
|
||||
datastore.data['watching'][uuid]['ignore_text'] = form_ignore_text
|
||||
|
||||
@@ -611,7 +602,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
# Reset the previous_md5 so we process a new snapshot including stripping ignore text.
|
||||
if form.css_filter.data.strip() != datastore.data['watching'][uuid]['css_filter']:
|
||||
if form.include_filters.data != datastore.data['watching'][uuid].get('include_filters', []):
|
||||
if len(datastore.data['watching'][uuid].history):
|
||||
extra_update_obj['previous_md5'] = get_current_checksum_include_ignore_text(uuid=uuid)
|
||||
|
||||
@@ -649,18 +640,33 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
# Only works reliably with Playwright
|
||||
visualselector_enabled = os.getenv('PLAYWRIGHT_DRIVER_URL', False) and default['fetch_backend'] == 'html_webdriver'
|
||||
|
||||
# JQ is difficult to install on windows and must be manually added (outside requirements.txt)
|
||||
jq_support = True
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
jq_support = False
|
||||
|
||||
watch = datastore.data['watching'].get(uuid)
|
||||
system_uses_webdriver = datastore.data['settings']['application']['fetch_backend'] == 'html_webdriver'
|
||||
is_html_webdriver = True if watch.get('fetch_backend') == 'html_webdriver' or (
|
||||
watch.get('fetch_backend', None) is None and system_uses_webdriver) else False
|
||||
|
||||
output = render_template("edit.html",
|
||||
uuid=uuid,
|
||||
watch=datastore.data['watching'][uuid],
|
||||
form=form,
|
||||
has_empty_checktime=using_default_check_time,
|
||||
using_global_webdriver_wait=default['webdriver_delay'] is None,
|
||||
browser_steps_config=browser_step_ui_config,
|
||||
current_base_url=datastore.data['settings']['application']['base_url'],
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False),
|
||||
visualselector_data_is_ready=visualselector_data_is_ready,
|
||||
form=form,
|
||||
has_default_notification_urls=True if len(datastore.data['settings']['application']['notification_urls']) else False,
|
||||
has_empty_checktime=using_default_check_time,
|
||||
is_html_webdriver=is_html_webdriver,
|
||||
jq_support=jq_support,
|
||||
playwright_enabled=os.getenv('PLAYWRIGHT_DRIVER_URL', False),
|
||||
settings_application=datastore.data['settings']['application'],
|
||||
using_global_webdriver_wait=default['webdriver_delay'] is None,
|
||||
uuid=uuid,
|
||||
visualselector_enabled=visualselector_enabled,
|
||||
playwright_enabled=os.getenv('PLAYWRIGHT_DRIVER_URL', False)
|
||||
watch=watch
|
||||
)
|
||||
|
||||
return output
|
||||
@@ -672,26 +678,34 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
default = deepcopy(datastore.data['settings'])
|
||||
if datastore.proxy_list is not None:
|
||||
available_proxies = list(datastore.proxy_list.keys())
|
||||
# When enabled
|
||||
system_proxy = datastore.data['settings']['requests']['proxy']
|
||||
# In the case it doesnt exist anymore
|
||||
if not any([system_proxy in tup for tup in datastore.proxy_list]):
|
||||
if not system_proxy in available_proxies:
|
||||
system_proxy = None
|
||||
|
||||
default['requests']['proxy'] = system_proxy if system_proxy is not None else datastore.proxy_list[0][0]
|
||||
default['requests']['proxy'] = system_proxy if system_proxy is not None else available_proxies[0]
|
||||
# Used by the form handler to keep or remove the proxy settings
|
||||
default['proxy_list'] = datastore.proxy_list
|
||||
default['proxy_list'] = available_proxies[0]
|
||||
|
||||
|
||||
# Don't use form.data on POST so that it doesnt overrid the checkbox status from the POST status
|
||||
form = forms.globalSettingsForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=default
|
||||
)
|
||||
|
||||
# Remove the last option 'System default'
|
||||
form.application.form.notification_format.choices.pop()
|
||||
|
||||
if datastore.proxy_list is None:
|
||||
# @todo - Couldn't get setattr() etc dynamic addition working, so remove it instead
|
||||
del form.requests.form.proxy
|
||||
else:
|
||||
form.requests.form.proxy.choices = datastore.proxy_list
|
||||
form.requests.form.proxy.choices = []
|
||||
for p in datastore.proxy_list:
|
||||
form.requests.form.proxy.choices.append(tuple((p, datastore.proxy_list[p]['label'])))
|
||||
|
||||
|
||||
if request.method == 'POST':
|
||||
# Password unset is a GET, but we can lock the session to a salted env password to always need the password
|
||||
@@ -732,7 +746,8 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
current_base_url = datastore.data['settings']['application']['base_url'],
|
||||
hide_remove_pass=os.getenv("SALTED_PASS", False),
|
||||
api_key=datastore.data['settings']['application'].get('api_access_token'),
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False))
|
||||
emailprefix=os.getenv('NOTIFICATION_MAIL_BUTTON_PREFIX', False),
|
||||
settings_application=datastore.data['settings']['application'])
|
||||
|
||||
return output
|
||||
|
||||
@@ -811,8 +826,10 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
newest_file = history[dates[-1]]
|
||||
|
||||
# Read as binary and force decode as UTF-8
|
||||
# Windows may fail decode in python if we just use 'r' mode (chardet decode exception)
|
||||
try:
|
||||
with open(newest_file, 'r') as f:
|
||||
with open(newest_file, 'r', encoding='utf-8', errors='ignore') as f:
|
||||
newest_version_file_contents = f.read()
|
||||
except Exception as e:
|
||||
newest_version_file_contents = "Unable to read {}.\n".format(newest_file)
|
||||
@@ -825,7 +842,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
previous_file = history[dates[-2]]
|
||||
|
||||
try:
|
||||
with open(previous_file, 'r') as f:
|
||||
with open(previous_file, 'r', encoding='utf-8', errors='ignore') as f:
|
||||
previous_version_file_contents = f.read()
|
||||
except Exception as e:
|
||||
previous_version_file_contents = "Unable to read {}.\n".format(previous_file)
|
||||
@@ -902,7 +919,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
timestamp = list(watch.history.keys())[-1]
|
||||
filename = watch.history[timestamp]
|
||||
try:
|
||||
with open(filename, 'r') as f:
|
||||
with open(filename, 'r', encoding='utf-8', errors='ignore') as f:
|
||||
tmp = f.readlines()
|
||||
|
||||
# Get what needs to be highlighted
|
||||
@@ -977,9 +994,6 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
# create a ZipFile object
|
||||
backupname = "changedetection-backup-{}.zip".format(int(time.time()))
|
||||
|
||||
# We only care about UUIDS from the current index file
|
||||
uuids = list(datastore.data['watching'].keys())
|
||||
backup_filepath = os.path.join(datastore_o.datastore_path, backupname)
|
||||
|
||||
with zipfile.ZipFile(backup_filepath, "w",
|
||||
@@ -995,12 +1009,12 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
# Add the flask app secret
|
||||
zipObj.write(os.path.join(datastore_o.datastore_path, "secret.txt"), arcname="secret.txt")
|
||||
|
||||
# Add any snapshot data we find, use the full path to access the file, but make the file 'relative' in the Zip.
|
||||
for txt_file_path in Path(datastore_o.datastore_path).rglob('*.txt'):
|
||||
parent_p = txt_file_path.parent
|
||||
if parent_p.name in uuids:
|
||||
zipObj.write(txt_file_path,
|
||||
arcname=str(txt_file_path).replace(datastore_o.datastore_path, ''),
|
||||
# Add any data in the watch data directory.
|
||||
for uuid, w in datastore.data['watching'].items():
|
||||
for f in Path(w.watch_data_dir).glob('*'):
|
||||
zipObj.write(f,
|
||||
# Use the full path to access the file, but make the file 'relative' in the Zip.
|
||||
arcname=os.path.join(f.parts[-2], f.parts[-1]),
|
||||
compress_type=zipfile.ZIP_DEFLATED,
|
||||
compresslevel=8)
|
||||
|
||||
@@ -1179,7 +1193,6 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
else:
|
||||
# No tag, no uuid, add everything.
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
|
||||
if watch_uuid not in running_uuids and not datastore.data['watching'][watch_uuid]['paused']:
|
||||
update_q.put((1, watch_uuid))
|
||||
i += 1
|
||||
@@ -1199,7 +1212,7 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
datastore.delete(uuid.strip())
|
||||
flash("{} watches deleted".format(len(uuids)))
|
||||
|
||||
if (op == 'pause'):
|
||||
elif (op == 'pause'):
|
||||
for uuid in uuids:
|
||||
uuid = uuid.strip()
|
||||
if datastore.data['watching'].get(uuid):
|
||||
@@ -1207,13 +1220,40 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
|
||||
flash("{} watches paused".format(len(uuids)))
|
||||
|
||||
if (op == 'unpause'):
|
||||
elif (op == 'unpause'):
|
||||
for uuid in uuids:
|
||||
uuid = uuid.strip()
|
||||
if datastore.data['watching'].get(uuid):
|
||||
datastore.data['watching'][uuid.strip()]['paused'] = False
|
||||
flash("{} watches unpaused".format(len(uuids)))
|
||||
|
||||
elif (op == 'mute'):
|
||||
for uuid in uuids:
|
||||
uuid = uuid.strip()
|
||||
if datastore.data['watching'].get(uuid):
|
||||
datastore.data['watching'][uuid.strip()]['notification_muted'] = True
|
||||
flash("{} watches muted".format(len(uuids)))
|
||||
|
||||
elif (op == 'unmute'):
|
||||
for uuid in uuids:
|
||||
uuid = uuid.strip()
|
||||
if datastore.data['watching'].get(uuid):
|
||||
datastore.data['watching'][uuid.strip()]['notification_muted'] = False
|
||||
flash("{} watches un-muted".format(len(uuids)))
|
||||
|
||||
elif (op == 'notification-default'):
|
||||
from changedetectionio.notification import (
|
||||
default_notification_format_for_watch
|
||||
)
|
||||
for uuid in uuids:
|
||||
uuid = uuid.strip()
|
||||
if datastore.data['watching'].get(uuid):
|
||||
datastore.data['watching'][uuid.strip()]['notification_title'] = None
|
||||
datastore.data['watching'][uuid.strip()]['notification_body'] = None
|
||||
datastore.data['watching'][uuid.strip()]['notification_urls'] = []
|
||||
datastore.data['watching'][uuid.strip()]['notification_format'] = default_notification_format_for_watch
|
||||
flash("{} watches set to use default notification settings".format(len(uuids)))
|
||||
|
||||
return redirect(url_for('index'))
|
||||
|
||||
@app.route("/api/share-url", methods=['GET'])
|
||||
@@ -1270,13 +1310,15 @@ def changedetection_app(config=None, datastore_o=None):
|
||||
# paste in etc
|
||||
return redirect(url_for('index'))
|
||||
|
||||
import changedetectionio.blueprint.browser_steps as browser_steps
|
||||
app.register_blueprint(browser_steps.construct_blueprint(datastore), url_prefix='/browser-steps')
|
||||
|
||||
# @todo handle ctrl break
|
||||
ticker_thread = threading.Thread(target=ticker_thread_check_time_launch_checks).start()
|
||||
|
||||
threading.Thread(target=notification_runner).start()
|
||||
|
||||
# Check for new release version, but not when running in test/build
|
||||
if not os.getenv("GITHUB_REF", False):
|
||||
# Check for new release version, but not when running in test/build or pytest
|
||||
if not os.getenv("GITHUB_REF", False) and not config.get('disable_checkver') == True:
|
||||
threading.Thread(target=check_for_new_version).start()
|
||||
|
||||
return app
|
||||
@@ -1336,7 +1378,7 @@ def notification_runner():
|
||||
# UUID wont be present when we submit a 'test' from the global settings
|
||||
if 'uuid' in n_object:
|
||||
datastore.update_watch(uuid=n_object['uuid'],
|
||||
update_obj={'last_notification_error': "Notification error detected, please see logs."})
|
||||
update_obj={'last_notification_error': "Notification error detected, goto notification log."})
|
||||
|
||||
log_lines = str(e).splitlines()
|
||||
notification_debug_log += log_lines
|
||||
@@ -1351,6 +1393,8 @@ def ticker_thread_check_time_launch_checks():
|
||||
import random
|
||||
from changedetectionio import update_worker
|
||||
|
||||
proxy_last_called_time = {}
|
||||
|
||||
recheck_time_minimum_seconds = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 20))
|
||||
print("System env MINIMUM_SECONDS_RECHECK_TIME", recheck_time_minimum_seconds)
|
||||
|
||||
@@ -1411,10 +1455,30 @@ def ticker_thread_check_time_launch_checks():
|
||||
if watch.jitter_seconds == 0:
|
||||
watch.jitter_seconds = random.uniform(-abs(jitter), jitter)
|
||||
|
||||
|
||||
seconds_since_last_recheck = now - watch['last_checked']
|
||||
|
||||
if seconds_since_last_recheck >= (threshold + watch.jitter_seconds) and seconds_since_last_recheck >= recheck_time_minimum_seconds:
|
||||
if not uuid in running_uuids and uuid not in [q_uuid for p,q_uuid in update_q.queue]:
|
||||
|
||||
# Proxies can be set to have a limit on seconds between which they can be called
|
||||
watch_proxy = datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
if watch_proxy and watch_proxy in list(datastore.proxy_list.keys()):
|
||||
# Proxy may also have some threshold minimum
|
||||
proxy_list_reuse_time_minimum = int(datastore.proxy_list.get(watch_proxy, {}).get('reuse_time_minimum', 0))
|
||||
if proxy_list_reuse_time_minimum:
|
||||
proxy_last_used_time = proxy_last_called_time.get(watch_proxy, 0)
|
||||
time_since_proxy_used = int(time.time() - proxy_last_used_time)
|
||||
if time_since_proxy_used < proxy_list_reuse_time_minimum:
|
||||
# Not enough time difference reached, skip this watch
|
||||
print("> Skipped UUID {} using proxy '{}', not enough time between proxy requests {}s/{}s".format(uuid,
|
||||
watch_proxy,
|
||||
time_since_proxy_used,
|
||||
proxy_list_reuse_time_minimum))
|
||||
continue
|
||||
else:
|
||||
# Record the last used time
|
||||
proxy_last_called_time[watch_proxy] = int(time.time())
|
||||
|
||||
# Use Epoch time as priority, so we get a "sorted" PriorityQueue, but we can still push a priority 1 into it.
|
||||
priority = int(time.time())
|
||||
print(
|
||||
|
||||
@@ -122,3 +122,37 @@ class CreateWatch(Resource):
|
||||
return {'status': "OK"}, 200
|
||||
|
||||
return list, 200
|
||||
|
||||
class SystemInfo(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
import time
|
||||
overdue_watches = []
|
||||
|
||||
# Check all watches and report which have not been checked but should have been
|
||||
|
||||
for uuid, watch in self.datastore.data.get('watching', {}).items():
|
||||
# see if now - last_checked is greater than the time that should have been
|
||||
# this is not super accurate (maybe they just edited it) but better than nothing
|
||||
t = watch.threshold_seconds()
|
||||
if not t:
|
||||
# Use the system wide default
|
||||
t = self.datastore.threshold_seconds
|
||||
|
||||
time_since_check = time.time() - watch.get('last_checked')
|
||||
|
||||
# Allow 5 minutes of grace time before we decide it's overdue
|
||||
if time_since_check - (5 * 60) > t:
|
||||
overdue_watches.append(uuid)
|
||||
|
||||
return {
|
||||
'queue_size': self.update_q.qsize(),
|
||||
'overdue_watches': overdue_watches,
|
||||
'uptime': round(time.time() - self.datastore.start_time, 2),
|
||||
'watch_count': len(self.datastore.data.get('watching', {}))
|
||||
}, 200
|
||||
|
||||
0
changedetectionio/blueprint/__init__.py
Normal file
0
changedetectionio/blueprint/__init__.py
Normal file
226
changedetectionio/blueprint/browser_steps/__init__.py
Normal file
226
changedetectionio/blueprint/browser_steps/__init__.py
Normal file
@@ -0,0 +1,226 @@
|
||||
|
||||
# HORRIBLE HACK BUT WORKS :-) PR anyone?
|
||||
#
|
||||
# Why?
|
||||
# `browsersteps_playwright_browser_interface.chromium.connect_over_cdp()` will only run once without async()
|
||||
# - this flask app is not async()
|
||||
# - browserless has a single timeout/keepalive which applies to the session made at .connect_over_cdp()
|
||||
#
|
||||
# So it means that we must unfortunately for now just keep a single timer since .connect_over_cdp() was run
|
||||
# and know when that reaches timeout/keepalive :( when that time is up, restart the connection and tell the user
|
||||
# that their time is up, insert another coin. (reload)
|
||||
#
|
||||
# Bigger picture
|
||||
# - It's horrible that we have this click+wait deal, some nice socket.io solution using something similar
|
||||
# to what the browserless debug UI already gives us would be smarter..
|
||||
#
|
||||
# OR
|
||||
# - Some API call that should be hacked into browserless or playwright that we can "/api/bump-keepalive/{session_id}/60"
|
||||
# So we can tell it that we need more time (run this on each action)
|
||||
#
|
||||
# OR
|
||||
# - use multiprocessing to bump this over to its own process and add some transport layer (queue/pipes)
|
||||
|
||||
|
||||
|
||||
|
||||
from distutils.util import strtobool
|
||||
from flask import Blueprint, request, make_response
|
||||
from flask_login import login_required
|
||||
import os
|
||||
import logging
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
|
||||
browsersteps_live_ui_o = {}
|
||||
browsersteps_playwright_browser_interface = None
|
||||
browsersteps_playwright_browser_interface_start_time = None
|
||||
browsersteps_playwright_browser_interface_browser = None
|
||||
browsersteps_playwright_browser_interface_end_time = None
|
||||
|
||||
|
||||
def cleanup_playwright_session():
|
||||
print("Cleaning up old playwright session because time was up")
|
||||
global browsersteps_playwright_browser_interface
|
||||
global browsersteps_live_ui_o
|
||||
global browsersteps_playwright_browser_interface_browser
|
||||
global browsersteps_playwright_browser_interface
|
||||
global browsersteps_playwright_browser_interface_start_time
|
||||
global browsersteps_playwright_browser_interface_end_time
|
||||
|
||||
import psutil
|
||||
|
||||
current_process = psutil.Process()
|
||||
children = current_process.children(recursive=True)
|
||||
for child in children:
|
||||
print (child)
|
||||
print('Child pid is {}'.format(child.pid))
|
||||
|
||||
# .stop() hangs sometimes if its called when there are no children to process
|
||||
# but how do we know this is our child? dunno
|
||||
if children:
|
||||
browsersteps_playwright_browser_interface.stop()
|
||||
|
||||
browsersteps_live_ui_o = {}
|
||||
browsersteps_playwright_browser_interface = None
|
||||
browsersteps_playwright_browser_interface_start_time = None
|
||||
browsersteps_playwright_browser_interface_browser = None
|
||||
browsersteps_playwright_browser_interface_end_time = None
|
||||
print ("Cleaning up old playwright session because time was up - done")
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore):
|
||||
|
||||
browser_steps_blueprint = Blueprint('browser_steps', __name__, template_folder="templates")
|
||||
|
||||
@login_required
|
||||
@browser_steps_blueprint.route("/browsersteps_update", methods=['GET', 'POST'])
|
||||
def browsersteps_ui_update():
|
||||
import base64
|
||||
import playwright._impl._api_types
|
||||
import time
|
||||
|
||||
from changedetectionio.blueprint.browser_steps import browser_steps
|
||||
|
||||
global browsersteps_live_ui_o, browsersteps_playwright_browser_interface_end_time
|
||||
global browsersteps_playwright_browser_interface_browser
|
||||
global browsersteps_playwright_browser_interface
|
||||
global browsersteps_playwright_browser_interface_start_time
|
||||
|
||||
step_n = None
|
||||
remaining =0
|
||||
uuid = request.args.get('uuid')
|
||||
|
||||
browsersteps_session_id = request.args.get('browsersteps_session_id')
|
||||
|
||||
if not browsersteps_session_id:
|
||||
return make_response('No browsersteps_session_id specified', 500)
|
||||
|
||||
# Because we don't "really" run in a context manager ( we make the playwright interface global/long-living )
|
||||
# We need to manage the shutdown when the time is up
|
||||
if browsersteps_playwright_browser_interface_end_time:
|
||||
remaining = browsersteps_playwright_browser_interface_end_time-time.time()
|
||||
if browsersteps_playwright_browser_interface_end_time and remaining <= 0:
|
||||
|
||||
|
||||
cleanup_playwright_session()
|
||||
|
||||
return make_response('Browser session expired, please reload the Browser Steps interface', 500)
|
||||
|
||||
|
||||
# Actions - step/apply/etc, do the thing and return state
|
||||
if request.method == 'POST':
|
||||
# @todo - should always be an existing session
|
||||
step_operation = request.form.get('operation')
|
||||
step_selector = request.form.get('selector')
|
||||
step_optional_value = request.form.get('optional_value')
|
||||
step_n = int(request.form.get('step_n'))
|
||||
is_last_step = strtobool(request.form.get('is_last_step'))
|
||||
|
||||
if step_operation == 'Goto site':
|
||||
step_operation = 'goto_url'
|
||||
step_optional_value = None
|
||||
step_selector = datastore.data['watching'][uuid].get('url')
|
||||
|
||||
# @todo try.. accept.. nice errors not popups..
|
||||
try:
|
||||
|
||||
this_session = browsersteps_live_ui_o.get(browsersteps_session_id)
|
||||
if not this_session:
|
||||
print("Browser exited")
|
||||
return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
this_session.call_action(action_name=step_operation,
|
||||
selector=step_selector,
|
||||
optional_value=step_optional_value)
|
||||
except playwright._impl._api_types.TimeoutError as e:
|
||||
print("Element wasnt found :-(", step_operation)
|
||||
return make_response("Element was not found on page", 401)
|
||||
|
||||
except playwright._impl._api_types.Error as e:
|
||||
# Browser/playwright level error
|
||||
print("Browser error - got playwright._impl._api_types.Error, try reloading the session/browser")
|
||||
print (str(e))
|
||||
|
||||
# Try to find something of value to give back to the user
|
||||
for l in str(e).splitlines():
|
||||
if 'DOMException' in l:
|
||||
return make_response(l, 401)
|
||||
|
||||
return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
# Get visual selector ready/update its data (also use the current filter info from the page?)
|
||||
# When the last 'apply' button was pressed
|
||||
# @todo this adds overhead because the xpath selection is happening twice
|
||||
u = this_session.page.url
|
||||
if is_last_step and u:
|
||||
(screenshot, xpath_data) = this_session.request_visualselector_data()
|
||||
datastore.save_screenshot(watch_uuid=uuid, screenshot=screenshot)
|
||||
datastore.save_xpath_data(watch_uuid=uuid, data=xpath_data)
|
||||
|
||||
# Setup interface
|
||||
if request.method == 'GET':
|
||||
|
||||
if not browsersteps_playwright_browser_interface:
|
||||
print("Starting connection with playwright")
|
||||
logging.debug("browser_steps.py connecting")
|
||||
from playwright.sync_api import sync_playwright
|
||||
|
||||
browsersteps_playwright_browser_interface = sync_playwright().start()
|
||||
|
||||
|
||||
time.sleep(1)
|
||||
# At 20 minutes, some other variable is closing it
|
||||
# @todo find out what it is and set it
|
||||
seconds_keepalive = int(os.getenv('BROWSERSTEPS_MINUTES_KEEPALIVE', 10)) * 60
|
||||
|
||||
# keep it alive for 10 seconds more than we advertise, sometimes it helps to keep it shutting down cleanly
|
||||
keepalive = "&timeout={}".format(((seconds_keepalive+3) * 1000))
|
||||
try:
|
||||
browsersteps_playwright_browser_interface_browser = browsersteps_playwright_browser_interface.chromium.connect_over_cdp(
|
||||
os.getenv('PLAYWRIGHT_DRIVER_URL', '') + keepalive)
|
||||
except Exception as e:
|
||||
if 'ECONNREFUSED' in str(e):
|
||||
return make_response('Unable to start the Playwright session properly, is it running?', 401)
|
||||
|
||||
browsersteps_playwright_browser_interface_end_time = time.time() + (seconds_keepalive-3)
|
||||
print("Starting connection with playwright - done")
|
||||
|
||||
if not browsersteps_live_ui_o.get(browsersteps_session_id):
|
||||
# Boot up a new session
|
||||
proxy_id = datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
proxy = None
|
||||
if proxy_id:
|
||||
proxy_url = datastore.proxy_list.get(proxy_id).get('url')
|
||||
if proxy_url:
|
||||
proxy = {'server': proxy_url}
|
||||
print("Browser Steps: UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||
|
||||
# Begin the new "Playwright Context" that re-uses the playwright interface
|
||||
# Each session is a "Playwright Context" as a list, that uses the playwright interface
|
||||
browsersteps_live_ui_o[browsersteps_session_id] = browser_steps.browsersteps_live_ui(
|
||||
playwright_browser=browsersteps_playwright_browser_interface_browser,
|
||||
proxy=proxy)
|
||||
this_session = browsersteps_live_ui_o[browsersteps_session_id]
|
||||
|
||||
if not this_session.page:
|
||||
cleanup_playwright_session()
|
||||
return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
try:
|
||||
state = this_session.get_current_state()
|
||||
except playwright._impl._api_types.Error as e:
|
||||
return make_response("Browser session ran out of time :( Please reload this page."+str(e), 401)
|
||||
|
||||
p = {'screenshot': "data:image/png;base64,{}".format(
|
||||
base64.b64encode(state[0]).decode('ascii')),
|
||||
'xpath_data': state[1],
|
||||
'session_age_start': this_session.age_start,
|
||||
'browser_time_remaining': round(remaining)
|
||||
}
|
||||
|
||||
|
||||
# @todo BSON/binary JSON, faster xfer, OR pick it off the disk
|
||||
return p
|
||||
|
||||
return browser_steps_blueprint
|
||||
|
||||
|
||||
266
changedetectionio/blueprint/browser_steps/browser_steps.py
Normal file
266
changedetectionio/blueprint/browser_steps/browser_steps.py
Normal file
@@ -0,0 +1,266 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
from random import randint
|
||||
|
||||
# Two flags, tell the JS which of the "Selector" or "Value" field should be enabled in the front end
|
||||
# 0- off, 1- on
|
||||
browser_step_ui_config = {'Choose one': '0 0',
|
||||
# 'Check checkbox': '1 0',
|
||||
# 'Click button containing text': '0 1',
|
||||
# 'Scroll to bottom': '0 0',
|
||||
# 'Scroll to element': '1 0',
|
||||
# 'Scroll to top': '0 0',
|
||||
# 'Switch to iFrame by index number': '0 1'
|
||||
# 'Uncheck checkbox': '1 0',
|
||||
# @todo
|
||||
'Check checkbox': '1 0',
|
||||
'Click X,Y': '0 1',
|
||||
'Click element if exists': '1 0',
|
||||
'Click element': '1 0',
|
||||
'Click element containing text': '0 1',
|
||||
'Enter text in field': '1 1',
|
||||
# 'Extract text and use as filter': '1 0',
|
||||
'Goto site': '0 0',
|
||||
'Press Enter': '0 0',
|
||||
'Select by label': '1 1',
|
||||
'Scroll down': '0 0',
|
||||
'Uncheck checkbox': '1 0',
|
||||
'Wait for seconds': '0 1',
|
||||
'Wait for text': '0 1',
|
||||
# 'Press Page Down': '0 0',
|
||||
# 'Press Page Up': '0 0',
|
||||
# weird bug, come back to it later
|
||||
}
|
||||
|
||||
|
||||
# Good reference - https://playwright.dev/python/docs/input
|
||||
# https://pythonmana.com/2021/12/202112162236307035.html
|
||||
#
|
||||
# ONLY Works in Playwright because we need the fullscreen screenshot
|
||||
class steppable_browser_interface():
|
||||
page = None
|
||||
|
||||
# Convert and perform "Click Button" for example
|
||||
def call_action(self, action_name, selector=None, optional_value=None):
|
||||
now = time.time()
|
||||
call_action_name = re.sub('[^0-9a-zA-Z]+', '_', action_name.lower())
|
||||
if call_action_name == 'choose_one':
|
||||
return
|
||||
|
||||
print("> action calling", call_action_name)
|
||||
# https://playwright.dev/python/docs/selectors#xpath-selectors
|
||||
if selector.startswith('/') and not selector.startswith('//'):
|
||||
selector = "xpath=" + selector
|
||||
|
||||
action_handler = getattr(self, "action_" + call_action_name)
|
||||
|
||||
# Support for Jinja2 variables in the value and selector
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
if selector and ('{%' in selector or '{{' in selector):
|
||||
selector = str(jinja2_env.from_string(selector).render())
|
||||
|
||||
if optional_value and ('{%' in optional_value or '{{' in optional_value):
|
||||
optional_value = str(jinja2_env.from_string(optional_value).render())
|
||||
|
||||
action_handler(selector, optional_value)
|
||||
self.page.wait_for_timeout(3 * 1000)
|
||||
print("Call action done in", time.time() - now)
|
||||
|
||||
def action_goto_url(self, url, optional_value):
|
||||
# self.page.set_viewport_size({"width": 1280, "height": 5000})
|
||||
now = time.time()
|
||||
response = self.page.goto(url, timeout=0, wait_until='domcontentloaded')
|
||||
print("Time to goto URL", time.time() - now)
|
||||
|
||||
# Wait_until = commit
|
||||
# - `'commit'` - consider operation to be finished when network response is received and the document started loading.
|
||||
# Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
|
||||
# This seemed to solve nearly all 'TimeoutErrors'
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5))
|
||||
self.page.wait_for_timeout(extra_wait * 1000)
|
||||
|
||||
def action_click_element_containing_text(self, selector=None, value=''):
|
||||
if not len(value.strip()):
|
||||
return
|
||||
elem = self.page.get_by_text(value)
|
||||
if elem.count():
|
||||
elem.first.click(delay=randint(200, 500))
|
||||
|
||||
def action_enter_text_in_field(self, selector, value):
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
|
||||
self.page.fill(selector, value, timeout=10 * 1000)
|
||||
|
||||
def action_click_element(self, selector, value):
|
||||
print("Clicking element")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
|
||||
|
||||
def action_click_element_if_exists(self, selector, value):
|
||||
import playwright._impl._api_types as _api_types
|
||||
print("Clicking element if exists")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
try:
|
||||
self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
|
||||
except _api_types.TimeoutError as e:
|
||||
return
|
||||
except _api_types.Error as e:
|
||||
# Element was there, but page redrew and now its long long gone
|
||||
return
|
||||
|
||||
def action_click_x_y(self, selector, value):
|
||||
x, y = value.strip().split(',')
|
||||
x = int(float(x.strip()))
|
||||
y = int(float(y.strip()))
|
||||
self.page.mouse.click(x=x, y=y, delay=randint(200, 500))
|
||||
|
||||
def action_scroll_down(self, selector, value):
|
||||
# Some sites this doesnt work on for some reason
|
||||
self.page.mouse.wheel(0, 600)
|
||||
self.page.wait_for_timeout(1000)
|
||||
|
||||
def action_wait_for_seconds(self, selector, value):
|
||||
self.page.wait_for_timeout(int(value) * 1000)
|
||||
|
||||
# @todo - in the future make some popout interface to capture what needs to be set
|
||||
# https://playwright.dev/python/docs/api/class-keyboard
|
||||
def action_press_enter(self, selector, value):
|
||||
self.page.keyboard.press("Enter", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_up(self, selector, value):
|
||||
self.page.keyboard.press("PageUp", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_down(self, selector, value):
|
||||
self.page.keyboard.press("PageDown", delay=randint(200, 500))
|
||||
|
||||
def action_check_checkbox(self, selector, value):
|
||||
self.page.locator(selector).check()
|
||||
|
||||
def action_uncheck_checkbox(self, selector, value):
|
||||
self.page.locator(selector).uncheck()
|
||||
|
||||
|
||||
# Responsible for maintaining a live 'context' with browserless
|
||||
# @todo - how long do contexts live for anyway?
|
||||
class browsersteps_live_ui(steppable_browser_interface):
|
||||
context = None
|
||||
page = None
|
||||
render_extra_delay = 1
|
||||
stale = False
|
||||
# bump and kill this if idle after X sec
|
||||
age_start = 0
|
||||
|
||||
# use a special driver, maybe locally etc
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_BROWSERSTEPS_DRIVER_URL"
|
||||
)
|
||||
# if not..
|
||||
if not command_executor:
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_DRIVER_URL",
|
||||
'ws://playwright-chrome:3000'
|
||||
).strip('"')
|
||||
|
||||
browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
|
||||
def __init__(self, playwright_browser, proxy=None):
|
||||
self.age_start = time.time()
|
||||
self.playwright_browser = playwright_browser
|
||||
if self.context is None:
|
||||
self.connect(proxy=proxy)
|
||||
|
||||
# Connect and setup a new context
|
||||
def connect(self, proxy=None):
|
||||
# Should only get called once - test that
|
||||
keep_open = 1000 * 60 * 5
|
||||
now = time.time()
|
||||
|
||||
# @todo handle multiple contexts, bind a unique id from the browser on each req?
|
||||
self.context = self.playwright_browser.new_context(
|
||||
# @todo
|
||||
# user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
# proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should never be needed
|
||||
accept_downloads=False,
|
||||
proxy=proxy
|
||||
)
|
||||
|
||||
self.page = self.context.new_page()
|
||||
|
||||
# self.page.set_default_navigation_timeout(keep_open)
|
||||
self.page.set_default_timeout(keep_open)
|
||||
# @todo probably this doesnt work
|
||||
self.page.on(
|
||||
"close",
|
||||
self.mark_as_closed,
|
||||
)
|
||||
# Listen for all console events and handle errors
|
||||
self.page.on("console", lambda msg: print(f"Browser steps console - {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
print("time to browser setup", time.time() - now)
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
def mark_as_closed(self):
|
||||
print("Page closed, cleaning up..")
|
||||
|
||||
@property
|
||||
def has_expired(self):
|
||||
if not self.page:
|
||||
return True
|
||||
|
||||
|
||||
def get_current_state(self):
|
||||
"""Return the screenshot and interactive elements mapping, generally always called after action_()"""
|
||||
from pkg_resources import resource_string
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
now = time.time()
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
# The actual screenshot
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=40)
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
# Go find the interactive elements
|
||||
# @todo in the future, something smarter that can scan for elements with .click/focus etc event handlers?
|
||||
elements = 'a,button,input,select,textarea,i,th,td,p,li,h1,h2,h3,h4'
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', elements)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
# So the JS will find the smallest one first
|
||||
xpath_data['size_pos'] = sorted(xpath_data['size_pos'], key=lambda k: k['width'] * k['height'], reverse=True)
|
||||
print("Time to complete get_current_state of browser", time.time() - now)
|
||||
# except
|
||||
# playwright._impl._api_types.Error: Browser closed.
|
||||
# @todo show some countdown timer?
|
||||
return (screenshot, xpath_data)
|
||||
|
||||
def request_visualselector_data(self):
|
||||
"""
|
||||
Does the same that the playwright operation in content_fetcher does
|
||||
This is used to just bump the VisualSelector data so it' ready to go if they click on the tab
|
||||
@todo refactor and remove duplicate code, add include_filters
|
||||
:param xpath_data:
|
||||
:param screenshot:
|
||||
:param current_include_filters:
|
||||
:return:
|
||||
"""
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
from changedetectionio.content_fetcher import visualselector_xpath_selectors
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
|
||||
return (screenshot, xpath_data)
|
||||
@@ -2,19 +2,20 @@
|
||||
|
||||
# Launch as a eventlet.wsgi server instance.
|
||||
|
||||
from distutils.util import strtobool
|
||||
import eventlet
|
||||
import eventlet.wsgi
|
||||
import getopt
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
|
||||
import eventlet
|
||||
import eventlet.wsgi
|
||||
from . import store, changedetection_app, content_fetcher
|
||||
from . import __version__
|
||||
|
||||
# Only global so we can access it in the signal handler
|
||||
datastore = None
|
||||
app = None
|
||||
datastore = None
|
||||
|
||||
def sigterm_handler(_signo, _stack_frame):
|
||||
global app
|
||||
@@ -102,6 +103,15 @@ def main():
|
||||
has_password=datastore.data['settings']['application']['password'] != False
|
||||
)
|
||||
|
||||
# Monitored websites will not receive a Referer header when a user clicks on an outgoing link.
|
||||
# @Note: Incompatible with password login (and maybe other features) for now, submit a PR!
|
||||
@app.after_request
|
||||
def hide_referrer(response):
|
||||
if strtobool(os.getenv("HIDE_REFERER", 'false')):
|
||||
response.headers["Referrer-Policy"] = "no-referrer"
|
||||
|
||||
return response
|
||||
|
||||
# Proxy sub-directory support
|
||||
# Set environment var USE_X_SETTINGS=1 on this script
|
||||
# And then in your proxy_pass settings
|
||||
|
||||
@@ -1,11 +1,13 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from abc import abstractmethod
|
||||
import chardet
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import requests
|
||||
import time
|
||||
import sys
|
||||
import time
|
||||
|
||||
visualselector_xpath_selectors = 'div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary'
|
||||
|
||||
class Non200ErrorCodeReceived(Exception):
|
||||
def __init__(self, status_code, url, screenshot=None, xpath_data=None, page_html=None):
|
||||
@@ -30,6 +32,12 @@ class JSActionExceptions(Exception):
|
||||
self.message = message
|
||||
return
|
||||
|
||||
class BrowserStepsStepTimout(Exception):
|
||||
def __init__(self, step_n):
|
||||
self.step_n = step_n
|
||||
return
|
||||
|
||||
|
||||
class PageUnloadable(Exception):
|
||||
def __init__(self, status_code, url, screenshot=False, message=False):
|
||||
# Set this so we can use it in other parts of the app
|
||||
@@ -70,134 +78,13 @@ class Fetcher():
|
||||
status_code = None
|
||||
content = None
|
||||
headers = None
|
||||
browser_steps = None
|
||||
browser_steps_screenshot_path = None
|
||||
|
||||
fetcher_description = "No description"
|
||||
webdriver_js_execute_code = None
|
||||
xpath_element_js = """
|
||||
// Include the getXpath script directly, easier than fetching
|
||||
!function(e,n){"object"==typeof exports&&"undefined"!=typeof module?module.exports=n():"function"==typeof define&&define.amd?define(n):(e=e||self).getXPath=n()}(this,function(){return function(e){var n=e;if(n&&n.id)return'//*[@id="'+n.id+'"]';for(var o=[];n&&Node.ELEMENT_NODE===n.nodeType;){for(var i=0,r=!1,d=n.previousSibling;d;)d.nodeType!==Node.DOCUMENT_TYPE_NODE&&d.nodeName===n.nodeName&&i++,d=d.previousSibling;for(d=n.nextSibling;d;){if(d.nodeName===n.nodeName){r=!0;break}d=d.nextSibling}o.push((n.prefix?n.prefix+":":"")+n.localName+(i||r?"["+(i+1)+"]":"")),n=n.parentNode}return o.length?"/"+o.reverse().join("/"):""}});
|
||||
xpath_element_js = ""
|
||||
|
||||
|
||||
const findUpTag = (el) => {
|
||||
let r = el
|
||||
chained_css = [];
|
||||
depth=0;
|
||||
|
||||
// Strategy 1: Keep going up until we hit an ID tag, imagine it's like #list-widget div h4
|
||||
while (r.parentNode) {
|
||||
if(depth==5) {
|
||||
break;
|
||||
}
|
||||
if('' !==r.id) {
|
||||
chained_css.unshift("#"+CSS.escape(r.id));
|
||||
final_selector= chained_css.join(' > ');
|
||||
// Be sure theres only one, some sites have multiples of the same ID tag :-(
|
||||
if (window.document.querySelectorAll(final_selector).length ==1 ) {
|
||||
return final_selector;
|
||||
}
|
||||
return null;
|
||||
} else {
|
||||
chained_css.unshift(r.tagName.toLowerCase());
|
||||
}
|
||||
r=r.parentNode;
|
||||
depth+=1;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
// @todo - if it's SVG or IMG, go into image diff mode
|
||||
var elements = window.document.querySelectorAll("div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary");
|
||||
var size_pos=[];
|
||||
// after page fetch, inject this JS
|
||||
// build a map of all elements and their positions (maybe that only include text?)
|
||||
var bbox;
|
||||
for (var i = 0; i < elements.length; i++) {
|
||||
bbox = elements[i].getBoundingClientRect();
|
||||
|
||||
// forget really small ones
|
||||
if (bbox['width'] <20 && bbox['height'] < 20 ) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo the getXpath kind of sucks, it doesnt know when there is for example just one ID sometimes
|
||||
// it should not traverse when we know we can anchor off just an ID one level up etc..
|
||||
// maybe, get current class or id, keep traversing up looking for only class or id until there is just one match
|
||||
|
||||
// 1st primitive - if it has class, try joining it all and select, if theres only one.. well thats us.
|
||||
xpath_result=false;
|
||||
|
||||
try {
|
||||
var d= findUpTag(elements[i]);
|
||||
if (d) {
|
||||
xpath_result =d;
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getXPath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if(window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
|
||||
size_pos.push({
|
||||
xpath: xpath_result,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top']),
|
||||
childCount: elements[i].childElementCount
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
// inject the current one set in the css_filter, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (css_filter.length) {
|
||||
q=false;
|
||||
try {
|
||||
// is it xpath?
|
||||
if (css_filter.startsWith('/') || css_filter.startsWith('xpath:')) {
|
||||
q=document.evaluate(css_filter.replace('xpath:',''), document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q=document.querySelector(css_filter);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log(e);
|
||||
}
|
||||
bbox=false;
|
||||
if(q) {
|
||||
bbox = q.getBoundingClientRect();
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] >0 && bbox['height']>0) {
|
||||
size_pos.push({
|
||||
xpath: css_filter,
|
||||
width: bbox['width'],
|
||||
height: bbox['height'],
|
||||
left: bbox['left'],
|
||||
top: bbox['top'],
|
||||
childCount: q.childElementCount
|
||||
});
|
||||
}
|
||||
}
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos':size_pos, 'browser_width': window.innerWidth};
|
||||
"""
|
||||
xpath_data = None
|
||||
|
||||
# Will be needed in the future by the VisualSelector, always get this where possible.
|
||||
@@ -208,6 +95,12 @@ class Fetcher():
|
||||
# Time ONTOP of the system defined env minimum time
|
||||
render_extract_delay = 0
|
||||
|
||||
def __init__(self):
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
self.xpath_element_js = resource_string(__name__, "res/xpath_element_scraper.js").decode('utf-8')
|
||||
|
||||
|
||||
@abstractmethod
|
||||
def get_error(self):
|
||||
return self.error
|
||||
@@ -220,7 +113,7 @@ class Fetcher():
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
current_include_filters=None):
|
||||
# Should set self.error, self.status_code and self.content
|
||||
pass
|
||||
|
||||
@@ -232,11 +125,62 @@ class Fetcher():
|
||||
def get_last_status_code(self):
|
||||
return self.status_code
|
||||
|
||||
@abstractmethod
|
||||
def screenshot_step(self, step_n):
|
||||
return None
|
||||
|
||||
@abstractmethod
|
||||
# Return true/false if this checker is ready to run, in the case it needs todo some special config check etc
|
||||
def is_ready(self):
|
||||
return True
|
||||
|
||||
def iterate_browser_steps(self):
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import steppable_browser_interface
|
||||
from playwright._impl._api_types import TimeoutError
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
step_n = 0
|
||||
|
||||
if self.browser_steps is not None and len(self.browser_steps):
|
||||
interface = steppable_browser_interface()
|
||||
interface.page = self.page
|
||||
|
||||
valid_steps = filter(lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'), self.browser_steps)
|
||||
|
||||
for step in valid_steps:
|
||||
step_n += 1
|
||||
print(">> Iterating check - browser Step n {} - {}...".format(step_n, step['operation']))
|
||||
self.screenshot_step("before-"+str(step_n))
|
||||
self.save_step_html("before-"+str(step_n))
|
||||
try:
|
||||
optional_value = step['optional_value']
|
||||
selector = step['selector']
|
||||
# Support for jinja2 template in step values, with date module added
|
||||
if '{%' in step['optional_value'] or '{{' in step['optional_value']:
|
||||
optional_value = str(jinja2_env.from_string(step['optional_value']).render())
|
||||
if '{%' in step['selector'] or '{{' in step['selector']:
|
||||
selector = str(jinja2_env.from_string(step['selector']).render())
|
||||
|
||||
getattr(interface, "call_action")(action_name=step['operation'],
|
||||
selector=selector,
|
||||
optional_value=optional_value)
|
||||
self.screenshot_step(step_n)
|
||||
self.save_step_html(step_n)
|
||||
except TimeoutError:
|
||||
# Stop processing here
|
||||
raise BrowserStepsStepTimout(step_n=step_n)
|
||||
|
||||
|
||||
|
||||
# It's always good to reset these
|
||||
def delete_browser_steps_screenshots(self):
|
||||
import glob
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
dest = os.path.join(self.browser_steps_screenshot_path, 'step_*.jpeg')
|
||||
files = glob.glob(dest)
|
||||
for f in files:
|
||||
os.unlink(f)
|
||||
|
||||
# Maybe for the future, each fetcher provides its own diff output, could be used for text, image
|
||||
# the current one would return javascript output (as we use JS to generate the diff)
|
||||
@@ -255,7 +199,6 @@ def available_fetchers():
|
||||
|
||||
return p
|
||||
|
||||
|
||||
class base_html_playwright(Fetcher):
|
||||
fetcher_description = "Playwright {}/Javascript".format(
|
||||
os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').capitalize()
|
||||
@@ -273,7 +216,7 @@ class base_html_playwright(Fetcher):
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
|
||||
super().__init__()
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
self.browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
self.command_executor = os.getenv(
|
||||
@@ -293,15 +236,26 @@ class base_html_playwright(Fetcher):
|
||||
|
||||
# allow per-watch proxy selection override
|
||||
if proxy_override:
|
||||
# https://playwright.dev/docs/network#http-proxy
|
||||
from urllib.parse import urlparse
|
||||
parsed = urlparse(proxy_override)
|
||||
proxy_url = "{}://{}:{}".format(parsed.scheme, parsed.hostname, parsed.port)
|
||||
self.proxy = {'server': proxy_url}
|
||||
if parsed.username:
|
||||
self.proxy['username'] = parsed.username
|
||||
if parsed.password:
|
||||
self.proxy['password'] = parsed.password
|
||||
self.proxy = {'server': proxy_override}
|
||||
|
||||
def screenshot_step(self, step_n=''):
|
||||
|
||||
# There's a bug where we need to do it twice or it doesnt take the whole page, dont know why.
|
||||
self.page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024})
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=85)
|
||||
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.jpeg'.format(step_n))
|
||||
logging.debug("Saving step screenshot to {}".format(destination))
|
||||
with open(destination, 'wb') as f:
|
||||
f.write(screenshot)
|
||||
|
||||
def save_step_html(self, step_n):
|
||||
content = self.page.content()
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.html'.format(step_n))
|
||||
logging.debug("Saving step HTML to {}".format(destination))
|
||||
with open(destination, 'w') as f:
|
||||
f.write(content)
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
@@ -310,11 +264,12 @@ class base_html_playwright(Fetcher):
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
current_include_filters=None):
|
||||
|
||||
from playwright.sync_api import sync_playwright
|
||||
import playwright._impl._api_types
|
||||
from playwright._impl._api_types import Error, TimeoutError
|
||||
|
||||
self.delete_browser_steps_screenshots()
|
||||
response = None
|
||||
with sync_playwright() as p:
|
||||
browser_type = getattr(p, self.browser_type)
|
||||
@@ -335,79 +290,86 @@ class base_html_playwright(Fetcher):
|
||||
accept_downloads=False
|
||||
)
|
||||
|
||||
self.page = context.new_page()
|
||||
if len(request_headers):
|
||||
context.set_extra_http_headers(request_headers)
|
||||
|
||||
page = context.new_page()
|
||||
try:
|
||||
page.set_default_navigation_timeout(90000)
|
||||
page.set_default_timeout(90000)
|
||||
self.page.set_default_navigation_timeout(90000)
|
||||
self.page.set_default_timeout(90000)
|
||||
|
||||
# Listen for all console events and handle errors
|
||||
page.on("console", lambda msg: print(f"Playwright console: Watch URL: {url} {msg.type}: {msg.text} {msg.args}"))
|
||||
self.page.on("console", lambda msg: print(f"Playwright console: Watch URL: {url} {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
# Bug - never set viewport size BEFORE page.goto
|
||||
|
||||
|
||||
# Waits for the next navigation. Using Python context manager
|
||||
# prevents a race condition between clicking and waiting for a navigation.
|
||||
with page.expect_navigation():
|
||||
response = page.goto(url, wait_until='load')
|
||||
with self.page.expect_navigation():
|
||||
response = self.page.goto(url, wait_until='load')
|
||||
# Wait_until = commit
|
||||
# - `'commit'` - consider operation to be finished when network response is received and the document started loading.
|
||||
# Better to not use any smarts from Playwright and just wait an arbitrary number of seconds
|
||||
# This seemed to solve nearly all 'TimeoutErrors'
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
self.page.wait_for_timeout(extra_wait * 1000)
|
||||
|
||||
if self.webdriver_js_execute_code is not None and len(self.webdriver_js_execute_code):
|
||||
self.page.evaluate(self.webdriver_js_execute_code)
|
||||
|
||||
except playwright._impl._api_types.TimeoutError as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
# This can be ok, we will try to grab what we could retrieve
|
||||
pass
|
||||
|
||||
except Exception as e:
|
||||
print("other exception when page.goto")
|
||||
print(str(e))
|
||||
print ("other exception when page.goto")
|
||||
print (str(e))
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None, message=e.message)
|
||||
raise PageUnloadable(url=url, status_code=None)
|
||||
|
||||
|
||||
if response is None:
|
||||
context.close()
|
||||
browser.close()
|
||||
print("response object was none")
|
||||
print ("response object was none")
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
# Bug 2(?) Set the viewport size AFTER loading the page
|
||||
page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
self.page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
|
||||
# Run Browser Steps here
|
||||
self.iterate_browser_steps()
|
||||
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
time.sleep(extra_wait)
|
||||
|
||||
if self.webdriver_js_execute_code is not None:
|
||||
try:
|
||||
page.evaluate(self.webdriver_js_execute_code)
|
||||
except Exception as e:
|
||||
# Is it possible to get a screenshot?
|
||||
error_screenshot = False
|
||||
try:
|
||||
page.screenshot(type='jpeg',
|
||||
clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024},
|
||||
quality=1)
|
||||
|
||||
# The actual screenshot
|
||||
error_screenshot = page.screenshot(type='jpeg',
|
||||
full_page=True,
|
||||
quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
except Exception as s:
|
||||
pass
|
||||
|
||||
raise JSActionExceptions(status_code=response.status, screenshot=error_screenshot, message=str(e), url=url)
|
||||
|
||||
self.content = page.content()
|
||||
self.content = self.page.content()
|
||||
self.status_code = response.status
|
||||
|
||||
if len(self.page.content().strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
print ("Content was empty")
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
# Bug 2(?) Set the viewport size AFTER loading the page
|
||||
self.page.set_viewport_size({"width": 1280, "height": 1024})
|
||||
|
||||
self.status_code = response.status
|
||||
self.content = self.page.content()
|
||||
self.headers = response.all_headers()
|
||||
|
||||
if current_css_filter is not None:
|
||||
page.evaluate("var css_filter={}".format(json.dumps(current_css_filter)))
|
||||
# So we can find an element on the page where its selector was entered manually (maybe not xPath etc)
|
||||
if current_include_filters is not None:
|
||||
self.page.evaluate("var include_filters={}".format(json.dumps(current_include_filters)))
|
||||
else:
|
||||
page.evaluate("var css_filter=''")
|
||||
self.page.evaluate("var include_filters=''")
|
||||
|
||||
self.xpath_data = page.evaluate("async () => {" + self.xpath_element_js + "}")
|
||||
self.xpath_data = self.page.evaluate("async () => {" + self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors) + "}")
|
||||
|
||||
# Bug 3 in Playwright screenshot handling
|
||||
# Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
|
||||
@@ -418,26 +380,17 @@ class base_html_playwright(Fetcher):
|
||||
# acceptable screenshot quality here
|
||||
try:
|
||||
# Quality set to 1 because it's not used, just used as a work-around for a bug, no need to change this.
|
||||
page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024}, quality=1)
|
||||
self.page.screenshot(type='jpeg', clip={'x': 1.0, 'y': 1.0, 'width': 1280, 'height': 1024}, quality=1)
|
||||
# The actual screenshot
|
||||
self.screenshot = page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
self.screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
if len(self.content.strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
print("Content was empty")
|
||||
raise EmptyReply(url=url, status_code=None, screenshot=self.screenshot)
|
||||
|
||||
context.close()
|
||||
browser.close()
|
||||
|
||||
if not ignore_status_codes and self.status_code!=200:
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=self.status_code, page_html=self.content, screenshot=self.screenshot)
|
||||
|
||||
class base_html_webdriver(Fetcher):
|
||||
if os.getenv("WEBDRIVER_URL"):
|
||||
fetcher_description = "WebDriver Chrome/Javascript via '{}'".format(os.getenv("WEBDRIVER_URL"))
|
||||
@@ -454,6 +407,7 @@ class base_html_webdriver(Fetcher):
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None):
|
||||
super().__init__()
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
@@ -486,7 +440,7 @@ class base_html_webdriver(Fetcher):
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
current_include_filters=None):
|
||||
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
@@ -514,8 +468,6 @@ class base_html_webdriver(Fetcher):
|
||||
# Selenium doesn't automatically wait for actions as good as Playwright, so wait again
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
|
||||
self.screenshot = self.driver.get_screenshot_as_png()
|
||||
|
||||
# @todo - how to check this? is it possible?
|
||||
self.status_code = 200
|
||||
# @todo somehow we should try to get this working for WebDriver
|
||||
@@ -526,11 +478,12 @@ class base_html_webdriver(Fetcher):
|
||||
self.content = self.driver.page_source
|
||||
self.headers = {}
|
||||
|
||||
self.screenshot = self.driver.get_screenshot_as_png()
|
||||
|
||||
# Does the connection to the webdriver work? run a test connection.
|
||||
def is_ready(self):
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
|
||||
self.driver = webdriver.Remote(
|
||||
command_executor=self.command_executor,
|
||||
@@ -562,7 +515,12 @@ class html_requests(Fetcher):
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_css_filter=None):
|
||||
current_include_filters=None):
|
||||
|
||||
# Make requests use a more modern looking user-agent
|
||||
if not 'User-Agent' in request_headers:
|
||||
request_headers['User-Agent'] = os.getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT",
|
||||
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36')
|
||||
|
||||
proxies = {}
|
||||
|
||||
|
||||
@@ -10,6 +10,11 @@ from changedetectionio import content_fetcher, html_tools
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
|
||||
class FilterNotFoundInResponse(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
# Some common stuff here that can be moved to a base class
|
||||
# (set_proxy_from_list)
|
||||
class perform_site_check():
|
||||
@@ -20,34 +25,6 @@ class perform_site_check():
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
# If there was a proxy list enabled, figure out what proxy_args/which proxy to use
|
||||
# if watch.proxy use that
|
||||
# fetcher.proxy_override = watch.proxy or main config proxy
|
||||
# Allows override the proxy on a per-request basis
|
||||
# ALWAYS use the first one is nothing selected
|
||||
|
||||
def set_proxy_from_list(self, watch):
|
||||
proxy_args = None
|
||||
if self.datastore.proxy_list is None:
|
||||
return None
|
||||
|
||||
# If its a valid one
|
||||
if any([watch['proxy'] in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = watch['proxy']
|
||||
|
||||
# not valid (including None), try the system one
|
||||
else:
|
||||
system_proxy = self.datastore.data['settings']['requests']['proxy']
|
||||
# Is not None and exists
|
||||
if any([system_proxy in p for p in self.datastore.proxy_list]):
|
||||
proxy_args = system_proxy
|
||||
|
||||
# Fallback - Did not resolve anything, use the first available
|
||||
if proxy_args is None:
|
||||
proxy_args = self.datastore.proxy_list[0][0]
|
||||
|
||||
return proxy_args
|
||||
|
||||
# Doesn't look like python supports forward slash auto enclosure in re.findall
|
||||
# So convert it to inline flag "foobar(?i)" type configuration
|
||||
def forward_slash_enclosed_regex_to_options(self, regex):
|
||||
@@ -61,16 +38,20 @@ class perform_site_check():
|
||||
|
||||
return regex
|
||||
|
||||
|
||||
def run(self, uuid):
|
||||
from copy import deepcopy
|
||||
changed_detected = False
|
||||
screenshot = False # as bytes
|
||||
stripped_text_from_html = ""
|
||||
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
# DeepCopy so we can be sure we don't accidently change anything by reference
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
|
||||
if not watch:
|
||||
return
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file', watch['url'], re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
if re.search(r'^file', watch.get('url', ''), re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
@@ -78,10 +59,10 @@ class perform_site_check():
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
extra_headers =self.datastore.data['watching'][uuid].get('headers')
|
||||
extra_headers = watch.get('headers', [])
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = self.datastore.data['settings']['headers'].copy()
|
||||
request_headers = deepcopy(self.datastore.data['settings']['headers'])
|
||||
request_headers.update(extra_headers)
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
@@ -90,8 +71,10 @@ class perform_site_check():
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests']['timeout']
|
||||
url = watch.get('url')
|
||||
timeout = self.datastore.data['settings']['requests'].get('timeout')
|
||||
|
||||
url = watch.link
|
||||
|
||||
request_body = self.datastore.data['watching'][uuid].get('body')
|
||||
request_method = self.datastore.data['watching'][uuid].get('method')
|
||||
ignore_status_codes = self.datastore.data['watching'][uuid].get('ignore_status_codes', False)
|
||||
@@ -103,28 +86,37 @@ class perform_site_check():
|
||||
is_source = True
|
||||
|
||||
# Pluggable content fetcher
|
||||
prefer_backend = watch['fetch_backend']
|
||||
prefer_backend = watch.get('fetch_backend')
|
||||
if hasattr(content_fetcher, prefer_backend):
|
||||
klass = getattr(content_fetcher, prefer_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=uuid)
|
||||
proxy_url = None
|
||||
if proxy_id:
|
||||
proxy_url = self.datastore.proxy_list.get(proxy_id).get('url')
|
||||
print("UUID {} Using proxy {}".format(uuid, proxy_url))
|
||||
|
||||
proxy_args = self.set_proxy_from_list(watch)
|
||||
fetcher = klass(proxy_override=proxy_args)
|
||||
fetcher = klass(proxy_override=proxy_url)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if watch['webdriver_delay'] is not None:
|
||||
fetcher.render_extract_delay = watch['webdriver_delay']
|
||||
fetcher.render_extract_delay = watch.get('webdriver_delay')
|
||||
elif system_webdriver_delay is not None:
|
||||
fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
if watch['webdriver_js_execute_code'] is not None and watch['webdriver_js_execute_code'].strip():
|
||||
fetcher.webdriver_js_execute_code = watch['webdriver_js_execute_code']
|
||||
# Possible conflict
|
||||
if prefer_backend == 'html_webdriver':
|
||||
fetcher.browser_steps = watch.get('browser_steps', None)
|
||||
fetcher.browser_steps_screenshot_path = os.path.join(self.datastore.datastore_path, uuid)
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, watch['css_filter'])
|
||||
if watch.get('webdriver_js_execute_code') is not None and watch.get('webdriver_js_execute_code').strip():
|
||||
fetcher.webdriver_js_execute_code = watch.get('webdriver_js_execute_code')
|
||||
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, watch.get('include_filters'))
|
||||
fetcher.quit()
|
||||
|
||||
self.screenshot = fetcher.screenshot
|
||||
@@ -148,27 +140,30 @@ class perform_site_check():
|
||||
is_html = False
|
||||
is_json = False
|
||||
|
||||
css_filter_rule = watch['css_filter']
|
||||
include_filters_rule = watch.get('include_filters', [])
|
||||
# include_filters_rule = watch['include_filters']
|
||||
subtractive_selectors = watch.get(
|
||||
"subtractive_selectors", []
|
||||
) + self.datastore.data["settings"]["application"].get(
|
||||
"global_subtractive_selectors", []
|
||||
)
|
||||
|
||||
has_filter_rule = css_filter_rule and len(css_filter_rule.strip())
|
||||
has_filter_rule = include_filters_rule and len("".join(include_filters_rule).strip())
|
||||
has_subtractive_selectors = subtractive_selectors and len(subtractive_selectors[0].strip())
|
||||
|
||||
if is_json and not has_filter_rule:
|
||||
css_filter_rule = "json:$"
|
||||
include_filters_rule.append("json:$")
|
||||
has_filter_rule = True
|
||||
|
||||
if has_filter_rule:
|
||||
if 'json:' in css_filter_rule:
|
||||
stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, jsonpath_filter=css_filter_rule)
|
||||
is_html = False
|
||||
json_filter_prefixes = ['json:', 'jq:']
|
||||
for filter in include_filters_rule:
|
||||
if any(prefix in filter for prefix in json_filter_prefixes):
|
||||
stripped_text_from_html += html_tools.extract_json_as_string(content=fetcher.content, json_filter=filter)
|
||||
is_html = False
|
||||
|
||||
if is_html or is_source:
|
||||
|
||||
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
fetcher.content = html_tools.workarounds_for_obfuscations(fetcher.content)
|
||||
html_content = fetcher.content
|
||||
@@ -180,33 +175,36 @@ class perform_site_check():
|
||||
else:
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if css_filter_rule[0] == '/' or css_filter_rule.startswith('xpath:'):
|
||||
html_content = html_tools.xpath_filter(xpath_filter=css_filter_rule.replace('xpath:', ''),
|
||||
html_content=fetcher.content)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
|
||||
html_content = ""
|
||||
for filter_rule in include_filters_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if filter_rule[0] == '/' or filter_rule.startswith('xpath:'):
|
||||
html_content += html_tools.xpath_filter(xpath_filter=filter_rule.replace('xpath:', ''),
|
||||
html_content=fetcher.content,
|
||||
append_pretty_line_formatting=not is_source)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content += html_tools.include_filters(include_filters=filter_rule,
|
||||
html_content=fetcher.content,
|
||||
append_pretty_line_formatting=not is_source)
|
||||
|
||||
if not html_content.strip():
|
||||
raise FilterNotFoundInResponse(include_filters_rule)
|
||||
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
if not is_source:
|
||||
if is_source:
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# extract text
|
||||
do_anchor = self.datastore.data["settings"]["application"].get("render_anchor_tag_content", False)
|
||||
stripped_text_from_html = \
|
||||
html_tools.html_to_text(
|
||||
html_content,
|
||||
render_anchor_tag_content=self.datastore.data["settings"][
|
||||
"application"].get(
|
||||
"render_anchor_tag_content", False)
|
||||
render_anchor_tag_content=do_anchor
|
||||
)
|
||||
|
||||
elif is_source:
|
||||
stripped_text_from_html = html_content
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
@@ -239,7 +237,7 @@ class perform_site_check():
|
||||
|
||||
for l in result:
|
||||
if type(l) is tuple:
|
||||
#@todo - some formatter option default (between groups)
|
||||
# @todo - some formatter option default (between groups)
|
||||
regex_matched_output += list(l) + [b'\n']
|
||||
else:
|
||||
# @todo - some formatter option default (between each ungrouped result)
|
||||
@@ -253,7 +251,6 @@ class perform_site_check():
|
||||
stripped_text_from_html = b''.join(regex_matched_output)
|
||||
text_content_before_ignored_filter = stripped_text_from_html
|
||||
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
@@ -263,29 +260,30 @@ class perform_site_check():
|
||||
############ Blocking rules, after checksum #################
|
||||
blocked = False
|
||||
|
||||
if len(watch['trigger_text']):
|
||||
trigger_text = watch.get('trigger_text', [])
|
||||
if len(trigger_text):
|
||||
# Assume blocked
|
||||
blocked = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
# It should return the line numbers that match
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['trigger_text'],
|
||||
wordlist=trigger_text,
|
||||
mode="line numbers")
|
||||
# Unblock if the trigger was found
|
||||
if result:
|
||||
blocked = False
|
||||
|
||||
|
||||
if len(watch['text_should_not_be_present']):
|
||||
text_should_not_be_present = watch.get('text_should_not_be_present', [])
|
||||
if len(text_should_not_be_present):
|
||||
# If anything matched, then we should block a change from happening
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['text_should_not_be_present'],
|
||||
wordlist=text_should_not_be_present,
|
||||
mode="line numbers")
|
||||
if result:
|
||||
blocked = True
|
||||
|
||||
# The main thing that all this at the moment comes down to :)
|
||||
if watch['previous_md5'] != fetched_md5:
|
||||
if watch.get('previous_md5') != fetched_md5:
|
||||
changed_detected = True
|
||||
|
||||
# Looks like something changed, but did it match all the rules?
|
||||
@@ -294,7 +292,7 @@ class perform_site_check():
|
||||
|
||||
# Extract title as title
|
||||
if is_html:
|
||||
if self.datastore.data['settings']['application']['extract_title_as_title'] or watch['extract_title_as_title']:
|
||||
if self.datastore.data['settings']['application'].get('extract_title_as_title') or watch['extract_title_as_title']:
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
|
||||
|
||||
|
||||
@@ -1,11 +1,10 @@
|
||||
import os
|
||||
import re
|
||||
|
||||
from wtforms import (
|
||||
BooleanField,
|
||||
Field,
|
||||
Form,
|
||||
IntegerField,
|
||||
PasswordField,
|
||||
RadioField,
|
||||
SelectField,
|
||||
StringField,
|
||||
@@ -13,15 +12,17 @@ from wtforms import (
|
||||
TextAreaField,
|
||||
fields,
|
||||
validators,
|
||||
widgets,
|
||||
widgets
|
||||
)
|
||||
from wtforms.fields import FieldList
|
||||
from wtforms.validators import ValidationError
|
||||
|
||||
# default
|
||||
# each select <option data-enabled="enabled-0-0"
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import browser_step_ui_config
|
||||
|
||||
from changedetectionio import content_fetcher
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
valid_notification_formats,
|
||||
)
|
||||
|
||||
@@ -303,7 +304,25 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
|
||||
# Re #265 - maybe in the future fetch the page and offer a
|
||||
# warning/notice that its possible the rule doesnt yet match anything?
|
||||
if not self.allow_json:
|
||||
raise ValidationError("jq not permitted in this field!")
|
||||
|
||||
if 'jq:' in line:
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise ValidationError("jq not support not found")
|
||||
|
||||
input = line.replace('jq:', '')
|
||||
|
||||
try:
|
||||
jq.compile(input)
|
||||
except (ValueError) as e:
|
||||
message = field.gettext('\'%s\' is not a valid jq expression. (%s)')
|
||||
raise ValidationError(message % (input, str(e)))
|
||||
except:
|
||||
raise ValidationError("A system-error occurred when validating your jq expression")
|
||||
|
||||
class quickWatchForm(Form):
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
@@ -314,14 +333,25 @@ class quickWatchForm(Form):
|
||||
|
||||
# Common to a single watch and the global settings
|
||||
class commonSettingsForm(Form):
|
||||
|
||||
notification_urls = StringListField('Notification URL list', validators=[validators.Optional(), ValidateNotificationBodyAndTitleWhenURLisSet(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification title', default=default_notification_title, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_body = TextAreaField('Notification body', default=default_notification_body, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys(), default=default_notification_format)
|
||||
notification_urls = StringListField('Notification URL list', validators=[validators.Optional(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification title', validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_body = TextAreaField('Notification body', validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys())
|
||||
fetch_backend = RadioField(u'Fetch method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
extract_title_as_title = BooleanField('Extract <title> from document and use as watch title', default=False)
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1, message="Should contain one or more seconds")] )
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1,
|
||||
message="Should contain one or more seconds")])
|
||||
|
||||
class SingleBrowserStep(Form):
|
||||
|
||||
operation = SelectField('Operation', [validators.Optional()], choices=browser_step_ui_config.keys())
|
||||
|
||||
# maybe better to set some <script>var..
|
||||
selector = StringField('Selector', [validators.Optional()], render_kw={"placeholder": "CSS or xPath selector"})
|
||||
optional_value = StringField('value', [validators.Optional()], render_kw={"placeholder": "Value"})
|
||||
# @todo move to JS? ajax fetch new field?
|
||||
# remove_button = SubmitField('-', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Remove'})
|
||||
# add_button = SubmitField('+', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Add new step after'})
|
||||
|
||||
class watchForm(commonSettingsForm):
|
||||
|
||||
@@ -330,7 +360,7 @@ class watchForm(commonSettingsForm):
|
||||
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
|
||||
css_filter = StringField('CSS/JSON/XPATH Filter', [ValidateCSSJSONXPATHInput()], default='')
|
||||
include_filters = StringListField('CSS/JSONPath/JQ/XPath Filters', [ValidateCSSJSONXPATHInput()], default='')
|
||||
|
||||
subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
|
||||
@@ -345,8 +375,9 @@ class watchForm(commonSettingsForm):
|
||||
ignore_status_codes = BooleanField('Ignore status codes (process non-2xx status codes as normal)', default=False)
|
||||
check_unique_lines = BooleanField('Only trigger when new lines appear', default=False)
|
||||
trigger_text = StringListField('Trigger/wait for text', [validators.Optional(), ValidateListRegex()])
|
||||
if os.getenv("PLAYWRIGHT_DRIVER_URL"):
|
||||
browser_steps = FieldList(FormField(SingleBrowserStep), min_entries=10)
|
||||
text_should_not_be_present = StringListField('Block change-detection if text matches', [validators.Optional(), ValidateListRegex()])
|
||||
|
||||
webdriver_js_execute_code = TextAreaField('Execute JavaScript before change detection', render_kw={"rows": "5"}, validators=[validators.Optional()])
|
||||
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
@@ -355,7 +386,8 @@ class watchForm(commonSettingsForm):
|
||||
filter_failure_notification_send = BooleanField(
|
||||
'Send a notification when the filter can no longer be found on the page', default=False)
|
||||
|
||||
notification_use_default = BooleanField('Use default/system notification settings', default=True)
|
||||
notification_muted = BooleanField('Notifications Muted / Off', default=False)
|
||||
notification_screenshot = BooleanField('Attach screenshot to notification (where possible)', default=False)
|
||||
|
||||
def validate(self, **kwargs):
|
||||
if not super().validate():
|
||||
@@ -368,6 +400,15 @@ class watchForm(commonSettingsForm):
|
||||
self.body.errors.append('Body must be empty when Request Method is set to GET')
|
||||
result = False
|
||||
|
||||
# Attempt to validate jinja2 templates in the URL
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(self.url.data).render())
|
||||
except Exception as e:
|
||||
self.url.errors.append('Invalid template syntax')
|
||||
result = False
|
||||
return result
|
||||
|
||||
|
||||
|
||||
@@ -1,32 +1,36 @@
|
||||
import json
|
||||
from typing import List
|
||||
|
||||
from bs4 import BeautifulSoup
|
||||
from jsonpath_ng.ext import parse
|
||||
import re
|
||||
from inscriptis import get_text
|
||||
from inscriptis.model.config import ParserConfig
|
||||
from jsonpath_ng.ext import parse
|
||||
from typing import List
|
||||
import json
|
||||
import re
|
||||
|
||||
class FilterNotFoundInResponse(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
# HTML added to be sure each result matching a filter (.example) gets converted to a new line by Inscriptis
|
||||
TEXT_FILTER_LIST_LINE_SUFFIX = "<br/>"
|
||||
|
||||
class JSONNotFound(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
|
||||
# Given a CSS Rule, and a blob of HTML, return the blob of HTML that matches
|
||||
def css_filter(css_filter, html_content):
|
||||
def include_filters(include_filters, html_content, append_pretty_line_formatting=False):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
html_block = ""
|
||||
r = soup.select(css_filter, separator="")
|
||||
if len(html_content) > 0 and len(r) == 0:
|
||||
raise FilterNotFoundInResponse(css_filter)
|
||||
for item in r:
|
||||
html_block += str(item)
|
||||
r = soup.select(include_filters, separator="")
|
||||
|
||||
return html_block + "\n"
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and not element.name in (['br', 'hr', 'div', 'p']):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
html_block += str(element)
|
||||
|
||||
return html_block
|
||||
|
||||
def subtractive_css_selector(css_selector, html_content):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
@@ -42,25 +46,29 @@ def element_removal(selectors: List[str], html_content):
|
||||
|
||||
|
||||
# Return str Utf-8 of matched rules
|
||||
def xpath_filter(xpath_filter, html_content):
|
||||
def xpath_filter(xpath_filter, html_content, append_pretty_line_formatting=False):
|
||||
from lxml import etree, html
|
||||
|
||||
tree = html.fromstring(bytes(html_content, encoding='utf-8'))
|
||||
html_block = ""
|
||||
|
||||
r = tree.xpath(xpath_filter.strip(), namespaces={'re': 'http://exslt.org/regular-expressions'})
|
||||
if len(html_content) > 0 and len(r) == 0:
|
||||
raise FilterNotFoundInResponse(xpath_filter)
|
||||
|
||||
#@note: //title/text() wont work where <title>CDATA..
|
||||
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and (not hasattr( element, 'tag' ) or not element.tag in (['br', 'hr', 'div', 'p'])):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
if type(element) == etree._ElementStringResult:
|
||||
html_block += str(element) + "<br/>"
|
||||
html_block += str(element)
|
||||
elif type(element) == etree._ElementUnicodeResult:
|
||||
html_block += str(element) + "<br/>"
|
||||
html_block += str(element)
|
||||
else:
|
||||
html_block += etree.tostring(element, pretty_print=True).decode('utf-8') + "<br/>"
|
||||
html_block += etree.tostring(element, pretty_print=True).decode('utf-8')
|
||||
|
||||
return html_block
|
||||
|
||||
@@ -79,19 +87,35 @@ def extract_element(find='title', html_content=''):
|
||||
return element_text
|
||||
|
||||
#
|
||||
def _parse_json(json_data, jsonpath_filter):
|
||||
s=[]
|
||||
jsonpath_expression = parse(jsonpath_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
def _parse_json(json_data, json_filter):
|
||||
if 'json:' in json_filter:
|
||||
jsonpath_expression = parse(json_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
|
||||
if 'jq:' in json_filter:
|
||||
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise Exception("jq not support not found")
|
||||
|
||||
jq_expression = jq.compile(json_filter.replace('jq:', ''))
|
||||
match = jq_expression.input(json_data).all()
|
||||
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
|
||||
def _get_stripped_text_from_json_match(match):
|
||||
s = []
|
||||
# More than one result, we will return it as a JSON list.
|
||||
if len(match) > 1:
|
||||
for i in match:
|
||||
s.append(i.value)
|
||||
s.append(i.value if hasattr(i, 'value') else i)
|
||||
|
||||
# Single value, use just the value, as it could be later used in a token in notifications.
|
||||
if len(match) == 1:
|
||||
s = match[0].value
|
||||
s = match[0].value if hasattr(match[0], 'value') else match[0]
|
||||
|
||||
# Re #257 - Better handling where it does not exist, in the case the original 's' value was False..
|
||||
if not match:
|
||||
@@ -103,16 +127,16 @@ def _parse_json(json_data, jsonpath_filter):
|
||||
|
||||
return stripped_text_from_html
|
||||
|
||||
def extract_json_as_string(content, jsonpath_filter):
|
||||
def extract_json_as_string(content, json_filter):
|
||||
|
||||
stripped_text_from_html = False
|
||||
|
||||
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded <script type=ldjson>
|
||||
try:
|
||||
stripped_text_from_html = _parse_json(json.loads(content), jsonpath_filter)
|
||||
stripped_text_from_html = _parse_json(json.loads(content), json_filter)
|
||||
except json.JSONDecodeError:
|
||||
|
||||
# Foreach <script json></script> blob.. just return the first that matches jsonpath_filter
|
||||
# Foreach <script json></script> blob.. just return the first that matches json_filter
|
||||
s = []
|
||||
soup = BeautifulSoup(content, 'html.parser')
|
||||
bs_result = soup.findAll('script')
|
||||
@@ -131,7 +155,7 @@ def extract_json_as_string(content, jsonpath_filter):
|
||||
# Just skip it
|
||||
continue
|
||||
else:
|
||||
stripped_text_from_html = _parse_json(json_data, jsonpath_filter)
|
||||
stripped_text_from_html = _parse_json(json_data, json_filter)
|
||||
if stripped_text_from_html:
|
||||
break
|
||||
|
||||
|
||||
@@ -103,12 +103,12 @@ class import_distill_io_json(Importer):
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
extras['include_filters'] = []
|
||||
try:
|
||||
extras['css_filter'] = d_config['selections'][0]['frames'][0]['includes'][0]['expr']
|
||||
if d_config['selections'][0]['frames'][0]['includes'][0]['type'] == 'xpath':
|
||||
extras['css_filter'] = 'xpath:' + extras['css_filter']
|
||||
|
||||
extras['include_filters'].append('xpath:' + d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
else:
|
||||
extras['include_filters'].append(d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
|
||||
@@ -13,10 +13,6 @@ class model(dict):
|
||||
'watching': {},
|
||||
'settings': {
|
||||
'headers': {
|
||||
'User-Agent': getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT", 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'),
|
||||
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
|
||||
'Accept-Encoding': 'gzip, deflate', # No support for brolti in python requests yet.
|
||||
'Accept-Language': 'en-GB,en-US;q=0.9,en;'
|
||||
},
|
||||
'requests': {
|
||||
'timeout': int(getenv("DEFAULT_SETTINGS_REQUESTS_TIMEOUT", "45")), # Default 45 seconds
|
||||
|
||||
@@ -1,14 +1,14 @@
|
||||
import os
|
||||
import uuid as uuid_builder
|
||||
from distutils.util import strtobool
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
import uuid
|
||||
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
default_notification_format_for_watch
|
||||
)
|
||||
|
||||
|
||||
@@ -16,43 +16,44 @@ class model(dict):
|
||||
__newest_history_key = None
|
||||
__history_n=0
|
||||
__base_config = {
|
||||
'url': None,
|
||||
'tag': None,
|
||||
'last_checked': 0,
|
||||
'paused': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
#'newest_history_key': 0,
|
||||
'title': None,
|
||||
'previous_md5': False,
|
||||
'uuid': str(uuid_builder.uuid4()),
|
||||
'headers': {}, # Extra headers to send
|
||||
#'history': {}, # Dict of timestamp and output stripped filename (removed)
|
||||
#'newest_history_key': 0, (removed, taken from history.txt index)
|
||||
'body': None,
|
||||
'method': 'GET',
|
||||
#'history': {}, # Dict of timestamp and output stripped filename
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
# Custom notification content
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'notification_use_default': True, # Use default for new
|
||||
'notification_muted': False,
|
||||
'css_filter': '',
|
||||
'last_error': False,
|
||||
'check_unique_lines': False, # On change-detected, compare against all history if its something new
|
||||
'check_count': 0,
|
||||
'consecutive_filter_failures': 0, # Every time the CSS/xPath filter cannot be located, reset when all is fine.
|
||||
'extract_text': [], # Extract text by regex after filters
|
||||
'subtractive_selectors': [],
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'text_should_not_be_present': [], # Text that should not present
|
||||
'extract_title_as_title': False,
|
||||
'fetch_backend': None,
|
||||
'filter_failure_notification_send': strtobool(os.getenv('FILTER_FAILURE_NOTIFICATION_SEND_DEFAULT', 'True')),
|
||||
'consecutive_filter_failures': 0, # Every time the CSS/xPath filter cannot be located, reset when all is fine.
|
||||
'extract_title_as_title': False,
|
||||
'check_unique_lines': False, # On change-detected, compare against all history if its something new
|
||||
'headers': {}, # Extra headers to send
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'include_filters': [],
|
||||
'last_checked': 0,
|
||||
'last_error': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'method': 'GET',
|
||||
# Custom notification content
|
||||
'notification_body': None,
|
||||
'notification_format': default_notification_format_for_watch,
|
||||
'notification_muted': False,
|
||||
'notification_title': None,
|
||||
'notification_screenshot': False, # Include the latest screenshot if available and supported by the apprise URL
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'paused': False,
|
||||
'previous_md5': False,
|
||||
'proxy': None, # Preferred proxy connection
|
||||
'subtractive_selectors': [],
|
||||
'tag': None,
|
||||
'text_should_not_be_present': [], # Text that should not present
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None},
|
||||
'title': None,
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'url': None,
|
||||
'uuid': str(uuid.uuid4()),
|
||||
'webdriver_delay': None,
|
||||
'webdriver_js_execute_code': None, # Run before change-detection
|
||||
}
|
||||
@@ -63,7 +64,7 @@ class model(dict):
|
||||
self.update(self.__base_config)
|
||||
self.__datastore_path = kw['datastore_path']
|
||||
|
||||
self['uuid'] = str(uuid_builder.uuid4())
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
del kw['datastore_path']
|
||||
|
||||
@@ -85,10 +86,30 @@ class model(dict):
|
||||
return False
|
||||
|
||||
def ensure_data_dir_exists(self):
|
||||
target_path = os.path.join(self.__datastore_path, self['uuid'])
|
||||
if not os.path.isdir(target_path):
|
||||
print ("> Creating data dir {}".format(target_path))
|
||||
os.mkdir(target_path)
|
||||
if not os.path.isdir(self.watch_data_dir):
|
||||
print ("> Creating data dir {}".format(self.watch_data_dir))
|
||||
os.mkdir(self.watch_data_dir)
|
||||
|
||||
@property
|
||||
def link(self):
|
||||
url = self.get('url', '')
|
||||
ready_url = url
|
||||
if '{%' in url or '{{' in url:
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(url).render())
|
||||
except Exception as e:
|
||||
from flask import (
|
||||
flash, Markup, url_for
|
||||
)
|
||||
message = Markup('<a href="{}#general">The URL {} is invalid and cannot be used, click to edit</a>'.format(
|
||||
url_for('edit_page', uuid=self.get('uuid')), self.get('url', '')))
|
||||
flash(message, 'error')
|
||||
return ''
|
||||
|
||||
return ready_url
|
||||
|
||||
@property
|
||||
def label(self):
|
||||
@@ -112,16 +133,40 @@ class model(dict):
|
||||
|
||||
@property
|
||||
def history(self):
|
||||
"""History index is just a text file as a list
|
||||
{watch-uuid}/history.txt
|
||||
|
||||
contains a list like
|
||||
|
||||
{epoch-time},{filename}\n
|
||||
|
||||
We read in this list as the history information
|
||||
|
||||
"""
|
||||
tmp_history = {}
|
||||
import logging
|
||||
import time
|
||||
|
||||
# Read the history file as a dict
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
if os.path.isfile(fname):
|
||||
logging.debug("Reading history index " + str(time.time()))
|
||||
with open(fname, "r") as f:
|
||||
tmp_history = dict(i.strip().split(',', 2) for i in f.readlines())
|
||||
for i in f.readlines():
|
||||
if ',' in i:
|
||||
k, v = i.strip().split(',', 2)
|
||||
|
||||
# The index history could contain a relative path, so we need to make the fullpath
|
||||
# so that python can read it
|
||||
if not '/' in v and not '\'' in v:
|
||||
v = os.path.join(self.watch_data_dir, v)
|
||||
else:
|
||||
# It's possible that they moved the datadir on older versions
|
||||
# So the snapshot exists but is in a different path
|
||||
snapshot_fname = v.split('/')[-1]
|
||||
proposed_new_path = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(v) and os.path.exists(proposed_new_path):
|
||||
v = proposed_new_path
|
||||
|
||||
tmp_history[k] = v
|
||||
|
||||
if len(tmp_history):
|
||||
self.__newest_history_key = list(tmp_history.keys())[-1]
|
||||
@@ -132,7 +177,7 @@ class model(dict):
|
||||
|
||||
@property
|
||||
def has_history(self):
|
||||
fname = os.path.join(self.__datastore_path, self.get('uuid'), "history.txt")
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
return os.path.isfile(fname)
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
@@ -151,31 +196,33 @@ class model(dict):
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, contents, timestamp):
|
||||
import uuid
|
||||
import logging
|
||||
|
||||
output_path = "{}/{}".format(self.__datastore_path, self['uuid'])
|
||||
|
||||
self.ensure_data_dir_exists()
|
||||
|
||||
snapshot_fname = "{}/{}.stripped.txt".format(output_path, uuid.uuid4())
|
||||
logging.debug("Saving history text {}".format(snapshot_fname))
|
||||
# Small hack so that we sleep just enough to allow 1 second between history snapshots
|
||||
# this is because history.txt indexes/keys snapshots by epoch seconds and we dont want dupe keys
|
||||
if self.__newest_history_key and int(timestamp) == int(self.__newest_history_key):
|
||||
time.sleep(timestamp - self.__newest_history_key)
|
||||
|
||||
with open(snapshot_fname, 'wb') as f:
|
||||
snapshot_fname = "{}.txt".format(str(uuid.uuid4()))
|
||||
|
||||
# in /diff/ and /preview/ we are going to assume for now that it's UTF-8 when reading
|
||||
# most sites are utf-8 and some are even broken utf-8
|
||||
with open(os.path.join(self.watch_data_dir, snapshot_fname), 'wb') as f:
|
||||
f.write(contents)
|
||||
f.close()
|
||||
|
||||
# Append to index
|
||||
# @todo check last char was \n
|
||||
index_fname = "{}/history.txt".format(output_path)
|
||||
index_fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
with open(index_fname, 'a') as f:
|
||||
f.write("{},{}\n".format(timestamp, snapshot_fname))
|
||||
f.close()
|
||||
|
||||
self.__newest_history_key = timestamp
|
||||
self.__history_n+=1
|
||||
self.__history_n += 1
|
||||
|
||||
#@todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
# @todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
return snapshot_fname
|
||||
|
||||
@property
|
||||
@@ -208,14 +255,26 @@ class model(dict):
|
||||
return not local_lines.issubset(existing_history)
|
||||
|
||||
def get_screenshot(self):
|
||||
fname = os.path.join(self.__datastore_path, self['uuid'], "last-screenshot.png")
|
||||
fname = os.path.join(self.watch_data_dir, "last-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
|
||||
return False
|
||||
# False is not an option for AppRise, must be type None
|
||||
return None
|
||||
|
||||
def get_screenshot_as_jpeg(self):
|
||||
|
||||
# Created by save_screenshot()
|
||||
fname = os.path.join(self.watch_data_dir, "last-screenshot.jpg")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
|
||||
# False is not an option for AppRise, must be type None
|
||||
return None
|
||||
|
||||
|
||||
def __get_file_ctime(self, filename):
|
||||
fname = os.path.join(self.__datastore_path, self['uuid'], filename)
|
||||
fname = os.path.join(self.watch_data_dir, filename)
|
||||
if os.path.isfile(fname):
|
||||
return int(os.path.getmtime(fname))
|
||||
return False
|
||||
@@ -240,9 +299,14 @@ class model(dict):
|
||||
def snapshot_error_screenshot_ctime(self):
|
||||
return self.__get_file_ctime('last-error-screenshot.png')
|
||||
|
||||
@property
|
||||
def watch_data_dir(self):
|
||||
# The base dir of the watch data
|
||||
return os.path.join(self.__datastore_path, self['uuid'])
|
||||
|
||||
def get_error_text(self):
|
||||
"""Return the text saved from a previous request that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.__datastore_path, self['uuid'], "last-error.txt")
|
||||
fname = os.path.join(self.watch_data_dir, "last-error.txt")
|
||||
if os.path.isfile(fname):
|
||||
with open(fname, 'r') as f:
|
||||
return f.read()
|
||||
@@ -250,7 +314,7 @@ class model(dict):
|
||||
|
||||
def get_error_snapshot(self):
|
||||
"""Return path to the screenshot that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.__datastore_path, self['uuid'], "last-error-screenshot.png")
|
||||
fname = os.path.join(self.watch_data_dir, "last-error-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
return False
|
||||
|
||||
@@ -14,16 +14,19 @@ valid_tokens = {
|
||||
'current_snapshot': ''
|
||||
}
|
||||
|
||||
default_notification_format_for_watch = 'System default'
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{watch_url} had a change.\n---\n{diff}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {watch_url}'
|
||||
|
||||
valid_notification_formats = {
|
||||
'Text': NotifyFormat.TEXT,
|
||||
'Markdown': NotifyFormat.MARKDOWN,
|
||||
'HTML': NotifyFormat.HTML,
|
||||
# Used only for editing a watch (not for global)
|
||||
default_notification_format_for_watch: default_notification_format_for_watch
|
||||
}
|
||||
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{watch_url} had a change.\n---\n{diff}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {watch_url}'
|
||||
|
||||
def process_notification(n_object, datastore):
|
||||
|
||||
# Get the notification body from datastore
|
||||
@@ -98,7 +101,10 @@ def process_notification(n_object, datastore):
|
||||
apobj.notify(
|
||||
title=n_title,
|
||||
body=n_body,
|
||||
body_format=n_format)
|
||||
body_format=n_format,
|
||||
# False is not an option for AppRise, must be type None
|
||||
attach=n_object.get('screenshot', None)
|
||||
)
|
||||
|
||||
apobj.clear()
|
||||
|
||||
|
||||
170
changedetectionio/res/xpath_element_scraper.js
Normal file
170
changedetectionio/res/xpath_element_scraper.js
Normal file
@@ -0,0 +1,170 @@
|
||||
// Include the getXpath script directly, easier than fetching
|
||||
function getxpath(e) {
|
||||
var n = e;
|
||||
if (n && n.id) return '//*[@id="' + n.id + '"]';
|
||||
for (var o = []; n && Node.ELEMENT_NODE === n.nodeType;) {
|
||||
for (var i = 0, r = !1, d = n.previousSibling; d;) d.nodeType !== Node.DOCUMENT_TYPE_NODE && d.nodeName === n.nodeName && i++, d = d.previousSibling;
|
||||
for (d = n.nextSibling; d;) {
|
||||
if (d.nodeName === n.nodeName) {
|
||||
r = !0;
|
||||
break
|
||||
}
|
||||
d = d.nextSibling
|
||||
}
|
||||
o.push((n.prefix ? n.prefix + ":" : "") + n.localName + (i || r ? "[" + (i + 1) + "]" : "")), n = n.parentNode
|
||||
}
|
||||
return o.length ? "/" + o.reverse().join("/") : ""
|
||||
}
|
||||
|
||||
const findUpTag = (el) => {
|
||||
let r = el
|
||||
chained_css = [];
|
||||
depth = 0;
|
||||
|
||||
// Strategy 1: If it's an input, with name, and there's only one, prefer that
|
||||
if (el.name !== undefined && el.name.length) {
|
||||
var proposed = el.tagName + "[name=" + el.name + "]";
|
||||
var proposed_element = window.document.querySelectorAll(proposed);
|
||||
if(proposed_element.length) {
|
||||
if (proposed_element.length === 1) {
|
||||
return proposed;
|
||||
} else {
|
||||
// Some sites change ID but name= stays the same, we can hit it if we know the index
|
||||
// Find all the elements that match and work out the input[n]
|
||||
var n=Array.from(proposed_element).indexOf(el);
|
||||
// Return a Playwright selector for nthinput[name=zipcode]
|
||||
return proposed+" >> nth="+n;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Strategy 2: Keep going up until we hit an ID tag, imagine it's like #list-widget div h4
|
||||
while (r.parentNode) {
|
||||
if (depth == 5) {
|
||||
break;
|
||||
}
|
||||
if ('' !== r.id) {
|
||||
chained_css.unshift("#" + CSS.escape(r.id));
|
||||
final_selector = chained_css.join(' > ');
|
||||
// Be sure theres only one, some sites have multiples of the same ID tag :-(
|
||||
if (window.document.querySelectorAll(final_selector).length == 1) {
|
||||
return final_selector;
|
||||
}
|
||||
return null;
|
||||
} else {
|
||||
chained_css.unshift(r.tagName.toLowerCase());
|
||||
}
|
||||
r = r.parentNode;
|
||||
depth += 1;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
// @todo - if it's SVG or IMG, go into image diff mode
|
||||
// %ELEMENTS% replaced at injection time because different interfaces use it with different settings
|
||||
var elements = window.document.querySelectorAll("%ELEMENTS%");
|
||||
var size_pos = [];
|
||||
// after page fetch, inject this JS
|
||||
// build a map of all elements and their positions (maybe that only include text?)
|
||||
var bbox;
|
||||
for (var i = 0; i < elements.length; i++) {
|
||||
bbox = elements[i].getBoundingClientRect();
|
||||
|
||||
// forget really small ones
|
||||
if (bbox['width'] < 15 && bbox['height'] < 15) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo the getXpath kind of sucks, it doesnt know when there is for example just one ID sometimes
|
||||
// it should not traverse when we know we can anchor off just an ID one level up etc..
|
||||
// maybe, get current class or id, keep traversing up looking for only class or id until there is just one match
|
||||
|
||||
// 1st primitive - if it has class, try joining it all and select, if theres only one.. well thats us.
|
||||
xpath_result = false;
|
||||
|
||||
try {
|
||||
var d = findUpTag(elements[i]);
|
||||
if (d) {
|
||||
xpath_result = d;
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getxpath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if (window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
|
||||
size_pos.push({
|
||||
xpath: xpath_result,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top']),
|
||||
tagName: (elements[i].tagName) ? elements[i].tagName.toLowerCase() : '',
|
||||
tagtype: (elements[i].tagName == 'INPUT' && elements[i].type) ? elements[i].type.toLowerCase() : ''
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
|
||||
// Inject the current one set in the include_filters, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (include_filters.length) {
|
||||
// Foreach filter, go and find it on the page and add it to the results so we can visualise it again
|
||||
for (const f of include_filters) {
|
||||
bbox = false;
|
||||
q = false;
|
||||
|
||||
if (!f.length) {
|
||||
console.log("xpath_element_scraper: Empty filter, skipping");
|
||||
continue;
|
||||
}
|
||||
|
||||
try {
|
||||
// is it xpath?
|
||||
if (f.startsWith('/') || f.startsWith('xpath:')) {
|
||||
q = document.evaluate(f.replace('xpath:', ''), document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
q = document.querySelector(f);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log("xpath_element_scraper: Exception selecting element from filter "+f);
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
if (q) {
|
||||
bbox = q.getBoundingClientRect();
|
||||
} else {
|
||||
console.log("xpath_element_scraper: filter element "+f+" was not found");
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] > 0 && bbox['height'] > 0) {
|
||||
size_pos.push({
|
||||
xpath: f,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top'])
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos': size_pos, 'browser_width': window.innerWidth};
|
||||
@@ -9,6 +9,8 @@
|
||||
# exit when any command fails
|
||||
set -e
|
||||
|
||||
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
||||
|
||||
find tests/test_*py -type f|while read test_name
|
||||
do
|
||||
echo "TEST RUNNING $test_name"
|
||||
@@ -23,6 +25,11 @@ export BASE_URL="https://really-unique-domain.io"
|
||||
pytest tests/test_notification.py
|
||||
|
||||
|
||||
# Re-run with HIDE_REFERER set - could affect login
|
||||
export HIDE_REFERER=True
|
||||
pytest tests/test_access_control.py
|
||||
|
||||
|
||||
# Now for the selenium and playwright/browserless fetchers
|
||||
# Note - this is not UI functional tests - just checking that each one can fetch the content
|
||||
|
||||
@@ -38,7 +45,9 @@ docker kill $$-test_selenium
|
||||
|
||||
echo "TESTING WEBDRIVER FETCH > PLAYWRIGHT/BROWSERLESS..."
|
||||
# Not all platforms support playwright (not ARM/rPI), so it's not packaged in requirements.txt
|
||||
pip3 install playwright~=1.24
|
||||
PLAYWRIGHT_VERSION=$(grep -i -E "RUN pip install.+" "$SCRIPT_DIR/../Dockerfile" | grep --only-matching -i -E "playwright[=><~+]+[0-9\.]+")
|
||||
echo "using $PLAYWRIGHT_VERSION"
|
||||
pip3 install "$PLAYWRIGHT_VERSION"
|
||||
docker run -d --name $$-test_browserless -e "DEFAULT_LAUNCH_ARGS=[\"--window-size=1920,1080\"]" --rm -p 3000:3000 --shm-size="2g" browserless/chrome:1.53-chrome-stable
|
||||
# takes a while to spin up
|
||||
sleep 5
|
||||
@@ -48,4 +57,48 @@ pytest tests/test_errorhandling.py
|
||||
pytest tests/visualselector/test_fetch_data.py
|
||||
|
||||
unset PLAYWRIGHT_DRIVER_URL
|
||||
docker kill $$-test_browserless
|
||||
docker kill $$-test_browserless
|
||||
|
||||
# Test proxy list handling, starting two squids on different ports
|
||||
# Each squid adds a different header to the response, which is the main thing we test for.
|
||||
docker run -d --name $$-squid-one --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf -p 3128:3128 ubuntu/squid:4.13-21.10_edge
|
||||
docker run -d --name $$-squid-two --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf -p 3129:3128 ubuntu/squid:4.13-21.10_edge
|
||||
|
||||
|
||||
# So, basic HTTP as env var test
|
||||
export HTTP_PROXY=http://localhost:3128
|
||||
export HTTPS_PROXY=http://localhost:3128
|
||||
pytest tests/proxy_list/test_proxy.py
|
||||
docker logs $$-squid-one 2>/dev/null|grep one.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to one.changedetection.io in the squid logs (while checking env vars HTTP_PROXY/HTTPS_PROXY)"
|
||||
fi
|
||||
unset HTTP_PROXY
|
||||
unset HTTPS_PROXY
|
||||
|
||||
|
||||
# 2nd test actually choose the preferred proxy from proxies.json
|
||||
cp tests/proxy_list/proxies.json-example ./test-datastore/proxies.json
|
||||
# Makes a watch use a preferred proxy
|
||||
pytest tests/proxy_list/test_multiple_proxy.py
|
||||
|
||||
# Should be a request in the default "first" squid
|
||||
docker logs $$-squid-one 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy)"
|
||||
fi
|
||||
|
||||
# And one in the 'second' squid (user selects this as preferred)
|
||||
docker logs $$-squid-two 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy)"
|
||||
fi
|
||||
|
||||
# @todo - test system override proxy selection and watch defaults, setup a 3rd squid?
|
||||
docker kill $$-squid-one
|
||||
docker kill $$-squid-two
|
||||
|
||||
|
||||
|
||||
51
changedetectionio/static/images/notice.svg
Normal file
51
changedetectionio/static/images/notice.svg
Normal file
{kind=link}
@@ -0,0 +1,51 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
|
||||
<svg
|
||||
width="20.108334mm"
|
||||
height="21.43125mm"
|
||||
viewBox="0 0 20.108334 21.43125"
|
||||
version="1.1"
|
||||
id="svg5"
|
||||
xmlns:xlink="http://www.w3.org/1999/xlink"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs2" />
|
||||
<g
|
||||
id="layer1"
|
||||
transform="translate(-141.05873,-76.816635)">
|
||||
<image
|
||||
width="20.108334"
|
||||
height="21.43125"
|
||||
preserveAspectRatio="none"
|
||||
style="image-rendering:optimizeQuality"
|
||||
xlink:href="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEwAAABRCAYAAAB430BuAAAABHNCSVQICAgIfAhkiAAABLxJREFU
|
||||
eJztnN2Z2jgUhl8Z7petIGwF0WMXsFBBoIKwFWS2gmQryKSCJRXsTAUDBTDRVBCmgkAB9tkLexh+
|
||||
bIONLGwP7xU2RjafpaOjoyNBCxHNQAJEfG5sl+3ZLrAWeAyST5/sF91mFH3bRbZbsAq4ClaQq2B7
|
||||
iKYnmg9Z318F20ICRnj8pMOd6E3HscNVsATxmQD/oeghPCnDLO26q2AkYin+TQ7XREyyrn3zgu2J
|
||||
BSEjZTBZ179pwQ7EEv7KaoovvFnBUsV6ZHrsd+0WTHhKPV1SLGivYEsA1KEtEs2grFitRjQ65VxP
|
||||
fH5JgEjAKsvXupKwFfYxaYJeSeHcWqVSCuwD7/HQQD8lRHLWDStBWG3slbAElkTc5/lTZdkIJhpN
|
||||
h6/UUZDyzAgZK8PKVoEKErE8HlD0bBVcI2ZqwdBWYbFgAT+g1UZwrBbcvRyIpofHJ1Sh1rQCZt1k
|
||||
lN5msQAm8CoYoFF8KVHOsFtQ5aayExBUhpnopJl6J/3/FREGWCrxmaH40/4z1oyQ320Yf5dDozXC
|
||||
P4QMCRkCY4S5w/tbMTtd4L2Ngo6wJmSQ4hfdScAU+OjgGazgOXEl8oJyof3Z6Spx0iTzgnLKsMoK
|
||||
w9SRuoR3rHniVVMXwRpDXQR7d+kHOJV6CFZB0khVOBGsTcE6VzWsNVGQizfJptU+N4LlD3AbVfsu
|
||||
XsOahhvB8nrB08IrtcGNYNIct+EYl2+S6mr0D8kLUMrV6BfFRTzOGs4Ey8p1aNrUnssaliaMO/vV
|
||||
sfNi3AmW5j54DgUTO/dyJ1hab9iwHhLcNskP23ZMND0kewFBXek6vZvHg/hMiUPSN00z+OBasFig
|
||||
y8wSRfnZ0adSBz+sUVwFK4jbJhnPP06To1ETczpcCnavHhltHd82LU0AXDbJMGXBU8PSBAA8Jxk0
|
||||
wnNaqlGSJuAyg+dsXIV38iZqXU3iWsmodhetSNlDQgJGriZxbWVSe1hS/gQ+S/C6j4QEfES21vxU
|
||||
icXsoC4vC5mqJvbybyXgduucG/YWaYmmj+IdHvpoxFdt8ltRP5h3iZjRqfBh60C4t1rNY7rxAU95
|
||||
aYnhEp+/u8pgxGfeRCfyJIR5SkLfFOHYXMMzu63PEDF9WQnSo8MUmhduyUWYEzGyvnRmU3683ugG
|
||||
GAG/2bqJU4RnFDNCpsfWb5chswUnwb5Xg+hxiyo9w7MGJoSVpmYulam+A8scS+5nPYtf+s9mpZw7
|
||||
J1nayDnCVuu4Ck+E6DqIBYDHHR1+is/n8kVUhfBExMBFMzm4taafkXcWL9BSfBG/nNN8sutYcE3S
|
||||
d7XI3o6lSpIe/xcAIX/svzDxMVu22BAyLNKL2q9hwrdLiZWwXbP6B99GDLaGSpoOD6JPn4yxK1i8
|
||||
B0StY1zKsCJiQNxzQ0HRbAm2BsZN2TBDGVaE5USzIVjsNix2VrzWHmUwB6J5fD32uyKCzQ7OxG5D
|
||||
vzZuQ0E2osXjRlBMjvWe5WtYPE4b2BynXQJlMEToTUegmEiwM1mzQ1nBvqvH5ov1wlZHcA+AZHdc
|
||||
xQW7vNuQS9kBtzKs1IIRMM7b0q/YvGTzto4qbFutdV5FnLtLk2x3JVWUfXKTbIu9Opc2J6Osj19S
|
||||
HLfJKO64r6rg/wFBX3+2ZapW8wAAAABJRU5ErkJggg==
|
||||
"
|
||||
id="image832"
|
||||
x="141.05873"
|
||||
y="76.816635" />
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 2.4 KiB |
122
changedetectionio/static/images/play.svg
Normal file
122
changedetectionio/static/images/play.svg
Normal file
{kind=link}
@@ -0,0 +1,122 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
version="1.1"
|
||||
id="Capa_1"
|
||||
x="0px"
|
||||
y="0px"
|
||||
viewBox="0 0 15 14.998326"
|
||||
xml:space="preserve"
|
||||
width="15"
|
||||
height="14.998326"
|
||||
sodipodi:docname="play.svg"
|
||||
inkscape:version="1.1.1 (1:1.1+202109281949+c3084ef5ed)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"><sodipodi:namedview
|
||||
id="namedview21"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
inkscape:zoom="45.47174"
|
||||
inkscape:cx="7.4991632"
|
||||
inkscape:cy="7.4991632"
|
||||
inkscape:window-width="1554"
|
||||
inkscape:window-height="896"
|
||||
inkscape:window-x="3048"
|
||||
inkscape:window-y="227"
|
||||
inkscape:window-maximized="0"
|
||||
inkscape:current-layer="Capa_1" /><metadata
|
||||
id="metadata39"><rdf:RDF><cc:Work
|
||||
rdf:about=""><dc:format>image/svg+xml</dc:format><dc:type
|
||||
rdf:resource="http://purl.org/dc/dcmitype/StillImage" /></cc:Work></rdf:RDF></metadata><defs
|
||||
id="defs37" />
|
||||
<path
|
||||
id="path2"
|
||||
style="fill:#1b98f8;fill-opacity:1;stroke-width:0.0292893"
|
||||
d="M 7.4980469,0 C 4.5496028,-0.04093755 1.7047721,1.8547661 0.58789062,4.5800781 -0.57819305,7.2574082 0.02636631,10.583252 2.0703125,12.671875 4.0368718,14.788335 7.2754393,15.560096 9.9882812,14.572266 12.800219,13.617028 14.874915,10.855516 14.986328,7.8847656 15.172991,4.9968456 13.497714,2.109448 10.910156,0.8203125 9.858961,0.28011352 8.6796569,-0.00179908 7.4980469,0 Z"
|
||||
sodipodi:nodetypes="ccccccc" />
|
||||
<g
|
||||
id="g4"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g6"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g8"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g10"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g12"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g14"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g16"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g18"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g20"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g22"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g24"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g26"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g28"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g30"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g32"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<path
|
||||
sodipodi:type="star"
|
||||
style="fill:#ffffff;fill-opacity:1;stroke-width:37.7953;paint-order:stroke fill markers"
|
||||
id="path1203"
|
||||
inkscape:flatsided="false"
|
||||
sodipodi:sides="3"
|
||||
sodipodi:cx="7.2964563"
|
||||
sodipodi:cy="7.3240671"
|
||||
sodipodi:r1="3.805218"
|
||||
sodipodi:r2="1.9026089"
|
||||
sodipodi:arg1="-0.0017436774"
|
||||
sodipodi:arg2="1.0454539"
|
||||
inkscape:rounded="0"
|
||||
inkscape:randomized="0"
|
||||
d="M 11.101669,7.317432 8.2506324,8.9701135 5.3995964,10.622795 5.3938504,7.3273846 5.3881041,4.0319742 8.2448863,5.6747033 Z"
|
||||
inkscape:transform-center-x="-0.94843001"
|
||||
inkscape:transform-center-y="0.0033175346" /></svg>
|
||||
|
After Width: | Height: | Size: 3.5 KiB |
429
changedetectionio/static/js/browser-steps.js
Normal file
429
changedetectionio/static/js/browser-steps.js
Normal file
@@ -0,0 +1,429 @@
|
||||
$(document).ready(function () {
|
||||
|
||||
// duplicate
|
||||
var csrftoken = $('input[name=csrf_token]').val();
|
||||
$.ajaxSetup({
|
||||
beforeSend: function (xhr, settings) {
|
||||
if (!/^(GET|HEAD|OPTIONS|TRACE)$/i.test(settings.type) && !this.crossDomain) {
|
||||
xhr.setRequestHeader("X-CSRFToken", csrftoken)
|
||||
}
|
||||
}
|
||||
})
|
||||
var browsersteps_session_id;
|
||||
var browserless_seconds_remaining=0;
|
||||
var apply_buttons_disabled = false;
|
||||
var include_text_elements = $("#include_text_elements");
|
||||
var xpath_data;
|
||||
var current_selected_i;
|
||||
var state_clicked = false;
|
||||
var c;
|
||||
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
var last_click_xy = {'x': -1, 'y': -1}
|
||||
|
||||
$(window).resize(function () {
|
||||
set_scale();
|
||||
});
|
||||
|
||||
$('a#browsersteps-tab').click(function () {
|
||||
start();
|
||||
});
|
||||
|
||||
// Show seconds remaining until playwright/browserless needs to restart the session
|
||||
// (See comment at the top of changedetectionio/blueprint/browser_steps/__init__.py )
|
||||
setInterval(() => {
|
||||
if (browserless_seconds_remaining >= 1) {
|
||||
document.getElementById('browserless-seconds-remaining').innerText = browserless_seconds_remaining + " seconds remaining in session";
|
||||
browserless_seconds_remaining -= 1;
|
||||
}
|
||||
}, "1000")
|
||||
|
||||
|
||||
if (window.location.hash == '#browser-steps') {
|
||||
start();
|
||||
}
|
||||
|
||||
window.addEventListener('hashchange', function () {
|
||||
if (window.location.hash == '#browser-steps') {
|
||||
start();
|
||||
}
|
||||
// For when the page loads
|
||||
if (!window.location.hash || window.location.hash != '#browser-steps') {
|
||||
$("img#browsersteps-img").attr('src', '');
|
||||
return;
|
||||
}
|
||||
});
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
selector_image = $("img#browsersteps-img")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas and input steps the same size as the image
|
||||
$('#browsersteps-selector-canvas').attr('height', selector_image_rect.height).attr('width', selector_image_rect.width);
|
||||
//$('#browsersteps-selector-wrapper').attr('width', selector_image_rect.width);
|
||||
$('#browser-steps-ui').attr('width', selector_image_rect.width);
|
||||
|
||||
x_scale = selector_image_rect.width / xpath_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: " + x_scale + " by y:" + y_scale);
|
||||
}
|
||||
|
||||
// bootstrap it, this will trigger everything else
|
||||
$('#browsersteps-img').bind('load', function () {
|
||||
$('body').addClass('full-width');
|
||||
console.log("Loaded background...");
|
||||
|
||||
document.getElementById("browsersteps-selector-canvas");
|
||||
c = document.getElementById("browsersteps-selector-canvas");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
// @todo is click better?
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
// Undo disable_browsersteps_ui
|
||||
$("#browser_steps select,input").removeAttr('disabled').css('opacity', '1.0');
|
||||
$("#browser-steps-ui").css('opacity', '1.0');
|
||||
|
||||
// init
|
||||
set_scale();
|
||||
|
||||
// @todo click ? some better library?
|
||||
$('#browsersteps-selector-canvas').bind('click', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
});
|
||||
|
||||
$('#browsersteps-selector-canvas').bind('mousedown', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
console.log(e);
|
||||
console.log("current xpath in index is "+current_selected_i);
|
||||
last_click_xy = {'x': parseInt((1 / x_scale) * e.offsetX), 'y': parseInt((1 / y_scale) * e.offsetY)}
|
||||
process_selected(current_selected_i);
|
||||
current_selected_i = false;
|
||||
|
||||
// if process selected returned false, then best we can do is offer a x,y click :(
|
||||
if (!found_something) {
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
$('select', first_available).val('Click X,Y').change();
|
||||
$('input[type=text]', first_available).first().val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
draw_circle_on_canvas(e.offsetX, e.offsetY);
|
||||
}
|
||||
});
|
||||
|
||||
$('#browsersteps-selector-canvas').bind('mousemove', function (e) {
|
||||
// checkbox if find elements is enabled
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
current_selected_i = false;
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
//$('#browsersteps-selector-canvas').css('cursor', 'pointer');
|
||||
for (var i = xpath_data['size_pos'].length; i !== 0; i--) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = xpath_data['size_pos'][i - 1];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
// Only highlight these interesting types
|
||||
if (1) {
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
current_selected_i = i - 1;
|
||||
break;
|
||||
|
||||
// find the smallest one at this x,y
|
||||
// does it mean sort the xpath list by size (w*h) i think so!
|
||||
} else {
|
||||
|
||||
if ( include_text_elements[0].checked === true) {
|
||||
// blue one with background instead?
|
||||
ctx.fillStyle = 'rgba(0,0,255, 0.1)';
|
||||
ctx.strokeStyle = 'rgba(0,0,200, 0.7)';
|
||||
$('#browsersteps-selector-canvas').css('cursor', 'grab');
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
current_selected_i = i - 1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(10));
|
||||
});
|
||||
|
||||
// $("#browser-steps-fieldlist").bind('mouseover', function(e) {
|
||||
// console.log(e.xpath_data_index);
|
||||
// });
|
||||
|
||||
|
||||
|
||||
// callback for clicking on an xpath on the canvas
|
||||
function process_selected(xpath_data_index) {
|
||||
found_something = false;
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
|
||||
|
||||
if (xpath_data_index !== false) {
|
||||
// Nothing focused, so fill in a new one
|
||||
// if inpt type button or <button>
|
||||
// from the top, find the next not used one and use it
|
||||
var x = xpath_data['size_pos'][xpath_data_index];
|
||||
console.log(x);
|
||||
if (x && first_available.length) {
|
||||
// @todo will it let you click shit that has a layer ontop? probably not.
|
||||
if (x['tagtype'] === 'text' || x['tagtype'] === 'email' || x['tagName'] === 'textarea' || x['tagtype'] === 'password' || x['tagtype'] === 'search' ) {
|
||||
$('select', first_available).val('Enter text in field').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
$('input[placeholder="Value"]', first_available).addClass('ok').click().focus();
|
||||
found_something = true;
|
||||
} else {
|
||||
// Assume it's just for clicking on
|
||||
// what are we clicking on?
|
||||
if (x['tagName'].startsWith('h')|| x['tagName'] === 'a' || x['tagName'] === 'button' || x['tagtype'] === 'submit'|| x['tagtype'] === 'checkbox'|| x['tagtype'] === 'radio'|| x['tagtype'] === 'li') {
|
||||
$('select', first_available).val('Click element').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
found_something = true;
|
||||
}
|
||||
}
|
||||
|
||||
first_available.xpath_data_index=xpath_data_index;
|
||||
|
||||
if (!found_something) {
|
||||
if ( include_text_elements[0].checked === true) {
|
||||
// Suggest that we use as filter?
|
||||
// @todo filters should always be in the last steps, nothing non-filter after it
|
||||
found_something = true;
|
||||
ctx.strokeStyle = 'rgba(0,0,255, 0.9)';
|
||||
ctx.fillStyle = 'rgba(0,0,255, 0.1)';
|
||||
$('select', first_available).val('Extract text and use as filter').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
include_text_elements[0].checked = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
} else {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
function draw_circle_on_canvas(x, y) {
|
||||
ctx.beginPath();
|
||||
ctx.arc(x, y, 8, 0, 2 * Math.PI, false);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.6)';
|
||||
ctx.fill();
|
||||
}
|
||||
|
||||
function start() {
|
||||
console.log("Starting browser-steps UI");
|
||||
browsersteps_session_id=Date.now();
|
||||
// @todo This setting of the first one should be done at the datalayer but wtforms doesnt wanna play nice
|
||||
$('#browser_steps >li:first-child').removeClass('empty');
|
||||
$('#browser_steps >li:first-child select').val('Goto site').attr('disabled', 'disabled');
|
||||
$('#browser-steps-ui .loader').show();
|
||||
$('.clear,.remove', $('#browser_steps >li:first-child')).hide();
|
||||
$.ajax({
|
||||
type: "GET",
|
||||
url: browser_steps_sync_url+"&browsersteps_session_id="+browsersteps_session_id,
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
xpath_data = data.xpath_data;
|
||||
$('#browsersteps-img').attr('src', data.screenshot);
|
||||
$("#loading-status-text").fadeIn();
|
||||
// This should trigger 'Goto site'
|
||||
$('#browser_steps >li:first-child .apply').click();
|
||||
browserless_seconds_remaining = data.browser_time_remaining;
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
alert('There was an error communicating with the server.');
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
function disable_browsersteps_ui() {
|
||||
$("#browser_steps select,input").attr('disabled', 'disabled').css('opacity', '0.5');
|
||||
$("#browser-steps-ui").css('opacity', '0.3');
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
}
|
||||
|
||||
|
||||
////////////////////////// STEPS UI ////////////////////
|
||||
$('ul#browser_steps [type="text"]').keydown(function (e) {
|
||||
if (e.keyCode === 13) {
|
||||
// hitting [enter] in a browser-step input should trigger the 'Apply'
|
||||
e.preventDefault();
|
||||
$(".apply", $(this).closest('li')).click();
|
||||
return false;
|
||||
}
|
||||
});
|
||||
|
||||
// Look up which step was selected, and enable or disable the related extra fields
|
||||
// So that people using it dont' get confused
|
||||
$('ul#browser_steps select').on("change", function () {
|
||||
var config = browser_steps_config[$(this).val()].split(' ');
|
||||
var elem_selector = $('tr:nth-child(2) input', $(this).closest('tbody'));
|
||||
var elem_value = $('tr:nth-child(3) input', $(this).closest('tbody'));
|
||||
|
||||
if (config[0] == 0) {
|
||||
$(elem_selector).fadeOut();
|
||||
} else {
|
||||
$(elem_selector).fadeIn();
|
||||
}
|
||||
if (config[1] == 0) {
|
||||
$(elem_value).fadeOut();
|
||||
} else {
|
||||
$(elem_value).fadeIn();
|
||||
}
|
||||
|
||||
if ($(this).val() === 'Click X,Y' && last_click_xy['x'] > 0 && $(elem_value).val().length === 0) {
|
||||
// @todo handle scale
|
||||
$(elem_value).val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
}
|
||||
}).change();
|
||||
|
||||
function set_greyed_state() {
|
||||
$('ul#browser_steps select').not('option:selected[value="Choose one"]').closest('li').removeClass('empty');
|
||||
$('ul#browser_steps select option:selected[value="Choose one"]').closest('li').addClass('empty');
|
||||
}
|
||||
|
||||
// Add the extra buttons to the steps
|
||||
$('ul#browser_steps li').each(function (i) {
|
||||
$(this).append('<div class="control">' +
|
||||
'<a data-step-index=' + i + ' class="pure-button button-secondary button-green button-xsmall apply" >Apply</a> ' +
|
||||
'<a data-step-index=' + i + ' class="pure-button button-secondary button-xsmall clear" >Clear</a> ' +
|
||||
'<a data-step-index=' + i + ' class="pure-button button-secondary button-red button-xsmall remove" >Remove</a>' +
|
||||
'</div>')
|
||||
}
|
||||
);
|
||||
|
||||
$('ul#browser_steps li .control .clear').click(function (element) {
|
||||
$("select", $(this).closest('li')).val("Choose one").change();
|
||||
$(":text", $(this).closest('li')).val('');
|
||||
});
|
||||
|
||||
|
||||
$('ul#browser_steps li .control .remove').click(function (element) {
|
||||
// so you wanna remove the 2nd (3rd spot 0,1,2,...)
|
||||
var p = $("#browser_steps li").index($(this).closest('li'));
|
||||
|
||||
var elem_to_remove = $("#browser_steps li")[p];
|
||||
$('.clear', elem_to_remove).click();
|
||||
$("#browser_steps li").slice(p, 10).each(function (index) {
|
||||
// get the next one's value from where we clicked
|
||||
var next = $("#browser_steps li")[p + index + 1];
|
||||
if (next) {
|
||||
// and set THIS ones value from the next one
|
||||
var n = $('input', next);
|
||||
$("select", $(this)).val($('select', next).val());
|
||||
$('input', this)[0].value = $(n)[0].value;
|
||||
$('input', this)[1].value = $(n)[1].value;
|
||||
// Triggers reconfiguring the field based on the system config
|
||||
$("select", $(this)).change();
|
||||
}
|
||||
|
||||
});
|
||||
|
||||
// Reset their hidden/empty states
|
||||
set_greyed_state();
|
||||
});
|
||||
|
||||
$('ul#browser_steps li .control .apply').click(function (event) {
|
||||
// sequential requests @todo refactor
|
||||
if(apply_buttons_disabled) {
|
||||
return;
|
||||
}
|
||||
|
||||
var current_data = $(event.currentTarget).closest('li');
|
||||
$('#browser-steps-ui .loader').fadeIn();
|
||||
apply_buttons_disabled=true;
|
||||
$('ul#browser_steps li .control .apply').css('opacity',0.5);
|
||||
$("#browsersteps-img").css('opacity',0.65);
|
||||
|
||||
var is_last_step = 0;
|
||||
var step_n = $(event.currentTarget).data('step-index');
|
||||
|
||||
// On the last step, we should also be getting data ready for the visual selector
|
||||
$('ul#browser_steps li select').each(function (i) {
|
||||
if ($(this).val() !== 'Choose one') {
|
||||
is_last_step += 1;
|
||||
}
|
||||
});
|
||||
|
||||
if (is_last_step == (step_n+1)) {
|
||||
is_last_step = true;
|
||||
} else {
|
||||
is_last_step = false;
|
||||
}
|
||||
|
||||
|
||||
// POST the currently clicked step form widget back and await response, redraw
|
||||
$.ajax({
|
||||
method: "POST",
|
||||
url: browser_steps_sync_url+"&browsersteps_session_id="+browsersteps_session_id,
|
||||
data: {
|
||||
'operation': $("select[id$='operation']", current_data).first().val(),
|
||||
'selector': $("input[id$='selector']", current_data).first().val(),
|
||||
'optional_value': $("input[id$='optional_value']", current_data).first().val(),
|
||||
'step_n': step_n,
|
||||
'is_last_step': is_last_step
|
||||
},
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
$("#loading-status-text").hide();
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
// it should return the new state (selectors available and screenshot)
|
||||
xpath_data = data.xpath_data;
|
||||
$('#browsersteps-img').attr('src', data.screenshot);
|
||||
$('#browser-steps-ui .loader').fadeOut();
|
||||
apply_buttons_disabled=false;
|
||||
$("#browsersteps-img").css('opacity',1);
|
||||
$('ul#browser_steps li .control .apply').css('opacity',1);
|
||||
browserless_seconds_remaining = data.browser_time_remaining;
|
||||
$("#loading-status-text").hide();
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
if (data.responseText.includes("Browser session expired")) {
|
||||
disable_browsersteps_ui();
|
||||
}
|
||||
apply_buttons_disabled=false;
|
||||
$("#loading-status-text").hide();
|
||||
$('ul#browser_steps li .control .apply').css('opacity',1);
|
||||
$("#browsersteps-img").css('opacity',1);
|
||||
//$('#browsersteps-selector-wrapper .loader').fadeOut(2500);
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
|
||||
$("ul#browser_steps select").change(function () {
|
||||
set_greyed_state();
|
||||
}).change();
|
||||
|
||||
});
|
||||
112
changedetectionio/static/js/diff-render.js
Normal file
112
changedetectionio/static/js/diff-render.js
Normal file
@@ -0,0 +1,112 @@
|
||||
var a = document.getElementById('a');
|
||||
var b = document.getElementById('b');
|
||||
var result = document.getElementById('result');
|
||||
|
||||
function changed() {
|
||||
// https://github.com/kpdecker/jsdiff/issues/389
|
||||
// I would love to use `{ignoreWhitespace: true}` here but it breaks the formatting
|
||||
options = {ignoreWhitespace: document.getElementById('ignoreWhitespace').checked};
|
||||
|
||||
var diff = Diff[window.diffType](a.textContent, b.textContent, options);
|
||||
var fragment = document.createDocumentFragment();
|
||||
for (var i = 0; i < diff.length; i++) {
|
||||
|
||||
if (diff[i].added && diff[i + 1] && diff[i + 1].removed) {
|
||||
var swap = diff[i];
|
||||
diff[i] = diff[i + 1];
|
||||
diff[i + 1] = swap;
|
||||
}
|
||||
|
||||
var node;
|
||||
if (diff[i].removed) {
|
||||
node = document.createElement('del');
|
||||
node.classList.add("change");
|
||||
node.appendChild(document.createTextNode(diff[i].value));
|
||||
|
||||
} else if (diff[i].added) {
|
||||
node = document.createElement('ins');
|
||||
node.classList.add("change");
|
||||
node.appendChild(document.createTextNode(diff[i].value));
|
||||
} else {
|
||||
node = document.createTextNode(diff[i].value);
|
||||
}
|
||||
fragment.appendChild(node);
|
||||
}
|
||||
|
||||
result.textContent = '';
|
||||
result.appendChild(fragment);
|
||||
|
||||
// Jump at start
|
||||
inputs.current = 0;
|
||||
next_diff();
|
||||
}
|
||||
|
||||
window.onload = function () {
|
||||
|
||||
|
||||
/* Convert what is options from UTC time.time() to local browser time */
|
||||
var diffList = document.getElementById("diff-version");
|
||||
if (typeof (diffList) != 'undefined' && diffList != null) {
|
||||
for (var option of diffList.options) {
|
||||
var dateObject = new Date(option.value * 1000);
|
||||
option.label = dateObject.toLocaleString();
|
||||
}
|
||||
}
|
||||
|
||||
/* Set current version date as local time in the browser also */
|
||||
var current_v = document.getElementById("current-v-date");
|
||||
var dateObject = new Date(newest_version_timestamp*1000);
|
||||
current_v.innerHTML = dateObject.toLocaleString();
|
||||
onDiffTypeChange(document.querySelector('#settings [name="diff_type"]:checked'));
|
||||
changed();
|
||||
};
|
||||
|
||||
a.onpaste = a.onchange =
|
||||
b.onpaste = b.onchange = changed;
|
||||
|
||||
if ('oninput' in a) {
|
||||
a.oninput = b.oninput = changed;
|
||||
} else {
|
||||
a.onkeyup = b.onkeyup = changed;
|
||||
}
|
||||
|
||||
function onDiffTypeChange(radio) {
|
||||
window.diffType = radio.value;
|
||||
// Not necessary
|
||||
// document.title = "Diff " + radio.value.slice(4);
|
||||
}
|
||||
|
||||
var radio = document.getElementsByName('diff_type');
|
||||
for (var i = 0; i < radio.length; i++) {
|
||||
radio[i].onchange = function (e) {
|
||||
onDiffTypeChange(e.target);
|
||||
changed();
|
||||
}
|
||||
}
|
||||
|
||||
document.getElementById('ignoreWhitespace').onchange = function (e) {
|
||||
changed();
|
||||
}
|
||||
|
||||
|
||||
var inputs = document.getElementsByClassName('change');
|
||||
inputs.current = 0;
|
||||
|
||||
|
||||
function next_diff() {
|
||||
|
||||
var element = inputs[inputs.current];
|
||||
var headerOffset = 80;
|
||||
var elementPosition = element.getBoundingClientRect().top;
|
||||
var offsetPosition = elementPosition - headerOffset + window.scrollY;
|
||||
|
||||
window.scrollTo({
|
||||
top: offsetPosition,
|
||||
behavior: "smooth"
|
||||
});
|
||||
|
||||
inputs.current++;
|
||||
if (inputs.current >= inputs.length) {
|
||||
inputs.current = 0;
|
||||
}
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
38
changedetectionio/static/js/diff.min.js
vendored
Normal file
38
changedetectionio/static/js/diff.min.js
vendored
Normal file
File diff suppressed because one or more lines are too long
34
changedetectionio/static/js/stepper.js
Normal file
34
changedetectionio/static/js/stepper.js
Normal file
@@ -0,0 +1,34 @@
|
||||
$(document).ready(function(){
|
||||
checkUserVal();
|
||||
$('#fetch_backend input').on('change', checkUserVal);
|
||||
});
|
||||
|
||||
var checkUserVal = function(){
|
||||
if($('#fetch_backend input:checked').val()=='html_requests') {
|
||||
$('#request-override').show();
|
||||
$('#webdriver-stepper').hide();
|
||||
} else {
|
||||
$('#request-override').hide();
|
||||
$('#webdriver-stepper').show();
|
||||
}
|
||||
};
|
||||
|
||||
$('a.row-options').on('click', function(){
|
||||
var row=$(this.closest('tr'));
|
||||
switch($(this).data("action")) {
|
||||
case 'remove':
|
||||
$(row).remove();
|
||||
break;
|
||||
case 'add':
|
||||
var new_row=$(row).clone(true).insertAfter($(row));
|
||||
$('input', new_new).val("");
|
||||
break;
|
||||
case 'add':
|
||||
var new_row=$(row).clone(true).insertAfter($(row));
|
||||
$('input', new_new).val("");
|
||||
break;
|
||||
case 'resend-step':
|
||||
|
||||
break;
|
||||
}
|
||||
});
|
||||
@@ -3,7 +3,8 @@
|
||||
window.addEventListener('hashchange', function () {
|
||||
var tabs = document.getElementsByClassName('active');
|
||||
while (tabs[0]) {
|
||||
tabs[0].classList.remove('active')
|
||||
tabs[0].classList.remove('active');
|
||||
document.body.classList.remove('full-width');
|
||||
}
|
||||
set_active_tab();
|
||||
}, false);
|
||||
@@ -20,6 +21,7 @@ if (!has_errors.length) {
|
||||
}
|
||||
|
||||
function set_active_tab() {
|
||||
document.body.classList.remove('full-width');
|
||||
var tab = document.querySelectorAll("a[href='" + location.hash + "']");
|
||||
if (tab.length) {
|
||||
tab[0].parentElement.className = "active";
|
||||
@@ -45,4 +47,3 @@ function focus_error_tab() {
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
// Horrible proof of concept code :)
|
||||
// yes - this is really a hack, if you are a front-ender and want to help, please get in touch!
|
||||
|
||||
$(document).ready(function() {
|
||||
$(document).ready(function () {
|
||||
|
||||
var current_selected_i;
|
||||
var state_clicked=false;
|
||||
var state_clicked = false;
|
||||
|
||||
var c;
|
||||
|
||||
@@ -13,9 +13,9 @@ $(document).ready(function() {
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
|
||||
var current_default_xpath;
|
||||
var x_scale=1;
|
||||
var y_scale=1;
|
||||
var current_default_xpath = [];
|
||||
var x_scale = 1;
|
||||
var y_scale = 1;
|
||||
var selector_image;
|
||||
var selector_image_rect;
|
||||
var selector_data;
|
||||
@@ -27,204 +27,216 @@ $(document).ready(function() {
|
||||
bootstrap_visualselector();
|
||||
});
|
||||
|
||||
$(document).on('keydown', function(event) {
|
||||
$(document).on('keydown', function (event) {
|
||||
if ($("img#selector-background").is(":visible")) {
|
||||
if (event.key == "Escape") {
|
||||
state_clicked=false;
|
||||
state_clicked = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
// For when the page loads
|
||||
if(!window.location.hash || window.location.hash != '#visualselector') {
|
||||
$("img#selector-background").attr('src','');
|
||||
if (!window.location.hash || window.location.hash != '#visualselector') {
|
||||
$("img#selector-background").attr('src', '');
|
||||
return;
|
||||
}
|
||||
|
||||
// Handle clearing button/link
|
||||
$('#clear-selector').on('click', function(event) {
|
||||
if(!state_clicked) {
|
||||
$('#clear-selector').on('click', function (event) {
|
||||
if (!state_clicked) {
|
||||
alert('Oops, Nothing selected!');
|
||||
}
|
||||
state_clicked=false;
|
||||
state_clicked = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
xctx.clearRect(0, 0, c.width, c.height);
|
||||
$("#css_filter").val('');
|
||||
$("#include_filters").val('');
|
||||
});
|
||||
|
||||
|
||||
bootstrap_visualselector();
|
||||
|
||||
|
||||
|
||||
function bootstrap_visualselector() {
|
||||
if ( 1 ) {
|
||||
if (1) {
|
||||
// bootstrap it, this will trigger everything else
|
||||
$("img#selector-background").bind('load', function () {
|
||||
console.log("Loaded background...");
|
||||
c = document.getElementById("selector-canvas");
|
||||
c = document.getElementById("selector-canvas");
|
||||
// greyed out fill context
|
||||
xctx = c.getContext("2d");
|
||||
xctx = c.getContext("2d");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
current_default_xpath =$("#css_filter").val();
|
||||
fetch_data();
|
||||
$('#selector-canvas').off("mousemove mousedown");
|
||||
// screenshot_url defined in the edit.html template
|
||||
ctx = c.getContext("2d");
|
||||
if ($("#include_filters").val().trim().length) {
|
||||
current_default_xpath = $("#include_filters").val().split(/\r?\n/g);
|
||||
} else {
|
||||
current_default_xpath = [];
|
||||
}
|
||||
fetch_data();
|
||||
$('#selector-canvas').off("mousemove mousedown");
|
||||
// screenshot_url defined in the edit.html template
|
||||
}).attr("src", screenshot_url);
|
||||
}
|
||||
// Tell visualSelector that the image should update
|
||||
var s = $("img#selector-background").attr('src')+"?"+ new Date().getTime();
|
||||
$("img#selector-background").attr('src',s)
|
||||
}
|
||||
|
||||
function fetch_data() {
|
||||
// Image is ready
|
||||
$('.fetching-update-notice').html("Fetching element data..");
|
||||
// Image is ready
|
||||
$('.fetching-update-notice').html("Fetching element data..");
|
||||
|
||||
$.ajax({
|
||||
url: watch_visual_selector_data_url,
|
||||
context: document.body
|
||||
}).done(function (data) {
|
||||
$('.fetching-update-notice').html("Rendering..");
|
||||
selector_data = data;
|
||||
console.log("Reported browser width from backend: "+data['browser_width']);
|
||||
state_clicked=false;
|
||||
set_scale();
|
||||
reflow_selector();
|
||||
$('.fetching-update-notice').fadeOut();
|
||||
});
|
||||
$.ajax({
|
||||
url: watch_visual_selector_data_url,
|
||||
context: document.body
|
||||
}).done(function (data) {
|
||||
$('.fetching-update-notice').html("Rendering..");
|
||||
selector_data = data;
|
||||
console.log("Reported browser width from backend: " + data['browser_width']);
|
||||
state_clicked = false;
|
||||
set_scale();
|
||||
reflow_selector();
|
||||
$('.fetching-update-notice').fadeOut();
|
||||
});
|
||||
};
|
||||
|
||||
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
selector_image = $("img#selector-background")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
$("#selector-wrapper").show();
|
||||
selector_image = $("img#selector-background")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas the same size as the image
|
||||
$('#selector-canvas').attr('height', selector_image_rect.height);
|
||||
$('#selector-canvas').attr('width', selector_image_rect.width);
|
||||
$('#selector-wrapper').attr('width', selector_image_rect.width);
|
||||
x_scale = selector_image_rect.width / selector_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: "+x_scale+" by y:"+y_scale);
|
||||
$("#selector-current-xpath").css('max-width', selector_image_rect.width);
|
||||
// make the canvas the same size as the image
|
||||
$('#selector-canvas').attr('height', selector_image_rect.height);
|
||||
$('#selector-canvas').attr('width', selector_image_rect.width);
|
||||
$('#selector-wrapper').attr('width', selector_image_rect.width);
|
||||
x_scale = selector_image_rect.width / selector_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: " + x_scale + " by y:" + y_scale);
|
||||
$("#selector-current-xpath").css('max-width', selector_image_rect.width);
|
||||
}
|
||||
|
||||
function reflow_selector() {
|
||||
$(window).resize(function() {
|
||||
$(window).resize(function () {
|
||||
set_scale();
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
var selector_currnt_xpath_text=$("#selector-current-xpath span");
|
||||
var selector_currnt_xpath_text = $("#selector-current-xpath span");
|
||||
|
||||
set_scale();
|
||||
set_scale();
|
||||
|
||||
console.log(selector_data['size_pos'].length + " selectors found");
|
||||
console.log(selector_data['size_pos'].length + " selectors found");
|
||||
|
||||
// highlight the default one if we can find it in the xPath list
|
||||
// or the xpath matches the default one
|
||||
found = false;
|
||||
if(current_default_xpath.length) {
|
||||
for (var i = selector_data['size_pos'].length; i!==0; i--) {
|
||||
var sel = selector_data['size_pos'][i-1];
|
||||
if(selector_data['size_pos'][i - 1].xpath == current_default_xpath) {
|
||||
console.log("highlighting "+current_default_xpath);
|
||||
current_selected_i = i-1;
|
||||
highlight_current_selected_i();
|
||||
found = true;
|
||||
break;
|
||||
// highlight the default one if we can find it in the xPath list
|
||||
// or the xpath matches the default one
|
||||
found = false;
|
||||
if (current_default_xpath.length) {
|
||||
// Find the first one that matches
|
||||
// @todo In the future paint all that match
|
||||
for (const c of current_default_xpath) {
|
||||
for (var i = selector_data['size_pos'].length; i !== 0; i--) {
|
||||
if (selector_data['size_pos'][i - 1].xpath === c) {
|
||||
console.log("highlighting " + c);
|
||||
current_selected_i = i - 1;
|
||||
highlight_current_selected_i();
|
||||
found = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (found) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (!found) {
|
||||
alert("Unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
}
|
||||
}
|
||||
if(!found) {
|
||||
alert("Unfortunately your existing CSS/xPath Filter was no longer found!");
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousemove', function (e) {
|
||||
if(state_clicked) {
|
||||
return;
|
||||
}
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
current_selected_i=null;
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var found=0;
|
||||
ctx.fillStyle = 'rgba(205,0,0,0.35)';
|
||||
for (var i = selector_data['size_pos'].length; i!==0; i--) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = selector_data['size_pos'][i-1];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
$('#selector-canvas').bind('mousemove', function (e) {
|
||||
if (state_clicked) {
|
||||
return;
|
||||
}
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
current_selected_i = null;
|
||||
|
||||
// FOUND ONE
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var found = 0;
|
||||
ctx.fillStyle = 'rgba(205,0,0,0.35)';
|
||||
for (var i = selector_data['size_pos'].length; i !== 0; i--) {
|
||||
// draw all of them? let them choose somehow?
|
||||
var sel = selector_data['size_pos'][i - 1];
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > sel.top * y_scale && e.offsetY < sel.top * y_scale + sel.height * y_scale
|
||||
&&
|
||||
e.offsetX > sel.left * y_scale && e.offsetX < sel.left * y_scale + sel.width * y_scale
|
||||
|
||||
) {
|
||||
|
||||
// FOUND ONE
|
||||
set_current_selected_text(sel.xpath);
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
|
||||
// no need to keep digging
|
||||
// @todo or, O to go out/up, I to go in
|
||||
// or double click to go up/out the selector?
|
||||
current_selected_i = i - 1;
|
||||
found += 1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(5));
|
||||
|
||||
function set_current_selected_text(s) {
|
||||
selector_currnt_xpath_text[0].innerHTML = s;
|
||||
}
|
||||
|
||||
function highlight_current_selected_i() {
|
||||
if (state_clicked) {
|
||||
state_clicked = false;
|
||||
xctx.clearRect(0, 0, c.width, c.height);
|
||||
return;
|
||||
}
|
||||
|
||||
var sel = selector_data['size_pos'][current_selected_i];
|
||||
if (sel[0] == '/') {
|
||||
// @todo - not sure just checking / is right
|
||||
$("#include_filters").val('xpath:' + sel.xpath);
|
||||
} else {
|
||||
$("#include_filters").val(sel.xpath);
|
||||
}
|
||||
xctx.fillStyle = 'rgba(205,205,205,0.95)';
|
||||
xctx.strokeStyle = 'rgba(225,0,0,0.9)';
|
||||
xctx.lineWidth = 3;
|
||||
xctx.fillRect(0, 0, c.width, c.height);
|
||||
// Clear out what only should be seen (make a clear/clean spot)
|
||||
xctx.clearRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
xctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
state_clicked = true;
|
||||
set_current_selected_text(sel.xpath);
|
||||
ctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
ctx.fillRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
|
||||
// no need to keep digging
|
||||
// @todo or, O to go out/up, I to go in
|
||||
// or double click to go up/out the selector?
|
||||
current_selected_i=i-1;
|
||||
found+=1;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
}.debounce(5));
|
||||
|
||||
function set_current_selected_text(s) {
|
||||
selector_currnt_xpath_text[0].innerHTML=s;
|
||||
}
|
||||
|
||||
function highlight_current_selected_i() {
|
||||
if(state_clicked) {
|
||||
state_clicked=false;
|
||||
xctx.clearRect(0,0,c.width, c.height);
|
||||
return;
|
||||
}
|
||||
|
||||
var sel = selector_data['size_pos'][current_selected_i];
|
||||
if (sel[0] == '/') {
|
||||
// @todo - not sure just checking / is right
|
||||
$("#css_filter").val('xpath:'+sel.xpath);
|
||||
} else {
|
||||
$("#css_filter").val(sel.xpath);
|
||||
}
|
||||
xctx.fillStyle = 'rgba(205,205,205,0.95)';
|
||||
xctx.strokeStyle = 'rgba(225,0,0,0.9)';
|
||||
xctx.lineWidth = 3;
|
||||
xctx.fillRect(0,0,c.width, c.height);
|
||||
// Clear out what only should be seen (make a clear/clean spot)
|
||||
xctx.clearRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
xctx.strokeRect(sel.left * x_scale, sel.top * y_scale, sel.width * x_scale, sel.height * y_scale);
|
||||
state_clicked=true;
|
||||
set_current_selected_text(sel.xpath);
|
||||
|
||||
}
|
||||
|
||||
|
||||
$('#selector-canvas').bind('mousedown', function (e) {
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
$('#selector-canvas').bind('mousedown', function (e) {
|
||||
highlight_current_selected_i();
|
||||
});
|
||||
}
|
||||
|
||||
});
|
||||
});
|
||||
@@ -1,7 +1,7 @@
|
||||
$(document).ready(function () {
|
||||
function toggle_fetch_backend() {
|
||||
$(document).ready(function() {
|
||||
function toggle() {
|
||||
if ($('input[name="fetch_backend"]:checked').val() == 'html_webdriver') {
|
||||
if (playwright_enabled) {
|
||||
if(playwright_enabled) {
|
||||
// playwright supports headers, so hide everything else
|
||||
// See #664
|
||||
$('#requests-override-options #request-method').hide();
|
||||
@@ -13,8 +13,12 @@ $(document).ready(function () {
|
||||
// selenium/webdriver doesnt support anything afaik, hide it all
|
||||
$('#requests-override-options').hide();
|
||||
}
|
||||
|
||||
|
||||
$('#webdriver-override-options').show();
|
||||
|
||||
} else {
|
||||
|
||||
$('#requests-override-options').show();
|
||||
$('#requests-override-options *:hidden').show();
|
||||
$('#webdriver-override-options').hide();
|
||||
@@ -22,27 +26,15 @@ $(document).ready(function () {
|
||||
}
|
||||
|
||||
$('input[name="fetch_backend"]').click(function (e) {
|
||||
toggle_fetch_backend();
|
||||
toggle();
|
||||
});
|
||||
toggle_fetch_backend();
|
||||
toggle();
|
||||
|
||||
function toggle_default_notifications() {
|
||||
var n=$('#notification_urls, #notification_title, #notification_body, #notification_format');
|
||||
if ($('#notification_use_default').is(':checked')) {
|
||||
$('#notification-field-group').fadeOut();
|
||||
$(n).each(function (e) {
|
||||
$(this).attr('readonly', true);
|
||||
});
|
||||
} else {
|
||||
$('#notification-field-group').show();
|
||||
$(n).each(function (e) {
|
||||
$(this).attr('readonly', false);
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
$('#notification_use_default').click(function (e) {
|
||||
toggle_default_notifications();
|
||||
$('#notification-setting-reset-to-default').click(function (e) {
|
||||
$('#notification_title').val('');
|
||||
$('#notification_body').val('');
|
||||
$('#notification_format').val('System default');
|
||||
$('#notification_urls').val('');
|
||||
e.preventDefault();
|
||||
});
|
||||
toggle_default_notifications();
|
||||
});
|
||||
|
||||
81
changedetectionio/static/styles/parts/browser-steps.scss
Normal file
81
changedetectionio/static/styles/parts/browser-steps.scss
Normal file
@@ -0,0 +1,81 @@
|
||||
|
||||
#browser_steps {
|
||||
/* convert rows to horizontal cells */
|
||||
th {
|
||||
display: none;
|
||||
}
|
||||
|
||||
li {
|
||||
list-style: decimal;
|
||||
padding: 5px;
|
||||
.control {
|
||||
padding-left: 5px;
|
||||
padding-right: 5px;
|
||||
a {
|
||||
font-size: 70%;
|
||||
}
|
||||
}
|
||||
&.empty {
|
||||
padding: 0px;
|
||||
opacity: 0.35;
|
||||
.control {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
&:hover {
|
||||
background: #eee;
|
||||
}
|
||||
> label {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#browser-steps-fieldlist {
|
||||
height: 100%;
|
||||
overflow-y: scroll;
|
||||
}
|
||||
|
||||
#browser-steps .flex-wrapper {
|
||||
display: flex;
|
||||
flex-flow: row;
|
||||
height: 600px; /*@todo make this dynamic */
|
||||
}
|
||||
|
||||
/* this is duplicate :( */
|
||||
#browsersteps-selector-wrapper {
|
||||
height: 100%;
|
||||
width: 100%;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
//width: 100%;
|
||||
> img {
|
||||
position: absolute;
|
||||
max-width: 100%;
|
||||
}
|
||||
|
||||
> canvas {
|
||||
position: relative;
|
||||
max-width: 100%;
|
||||
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
|
||||
.loader {
|
||||
position: absolute;
|
||||
left: 50%;
|
||||
top: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
margin-left: -40px;
|
||||
z-index: 100;
|
||||
}
|
||||
|
||||
/* nice tall skinny one */
|
||||
.spinner, .spinner:after {
|
||||
width: 80px;
|
||||
height: 80px;
|
||||
font-size: 3px;
|
||||
}
|
||||
}
|
||||
44
changedetectionio/static/styles/parts/spinners.scss
Normal file
44
changedetectionio/static/styles/parts/spinners.scss
Normal file
@@ -0,0 +1,44 @@
|
||||
|
||||
/* spinner */
|
||||
.spinner,
|
||||
.spinner:after {
|
||||
border-radius: 50%;
|
||||
width: 10px;
|
||||
height: 10px;
|
||||
}
|
||||
.spinner {
|
||||
margin: 0px auto;
|
||||
font-size: 3px;
|
||||
vertical-align: middle;
|
||||
display: inline-block;
|
||||
text-indent: -9999em;
|
||||
border-top: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-right: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-bottom: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-left: 1.1em solid #2668ed;
|
||||
-webkit-transform: translateZ(0);
|
||||
-ms-transform: translateZ(0);
|
||||
transform: translateZ(0);
|
||||
-webkit-animation: load8 1.1s infinite linear;
|
||||
animation: load8 1.1s infinite linear;
|
||||
}
|
||||
@-webkit-keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@@ -1,9 +1,107 @@
|
||||
/*
|
||||
* -- BASE STYLES --
|
||||
* Most of these are inherited from Base, but I want to change a few.
|
||||
* nvm use v14.18.1 && npm install && npm run build
|
||||
nvm use v14.18.1 && npm install && npm run build
|
||||
* or npm run watch
|
||||
*/
|
||||
/* spinner */
|
||||
.spinner,
|
||||
.spinner:after {
|
||||
border-radius: 50%;
|
||||
width: 10px;
|
||||
height: 10px; }
|
||||
|
||||
.spinner {
|
||||
margin: 0px auto;
|
||||
font-size: 3px;
|
||||
vertical-align: middle;
|
||||
display: inline-block;
|
||||
text-indent: -9999em;
|
||||
border-top: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-right: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-bottom: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-left: 1.1em solid #2668ed;
|
||||
-webkit-transform: translateZ(0);
|
||||
-ms-transform: translateZ(0);
|
||||
transform: translateZ(0);
|
||||
-webkit-animation: load8 1.1s infinite linear;
|
||||
animation: load8 1.1s infinite linear; }
|
||||
|
||||
@-webkit-keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg); }
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg); } }
|
||||
|
||||
@keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg); }
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg); } }
|
||||
|
||||
#browser_steps {
|
||||
/* convert rows to horizontal cells */ }
|
||||
#browser_steps th {
|
||||
display: none; }
|
||||
#browser_steps li {
|
||||
list-style: decimal;
|
||||
padding: 5px; }
|
||||
#browser_steps li .control {
|
||||
padding-left: 5px;
|
||||
padding-right: 5px; }
|
||||
#browser_steps li .control a {
|
||||
font-size: 70%; }
|
||||
#browser_steps li.empty {
|
||||
padding: 0px;
|
||||
opacity: 0.35; }
|
||||
#browser_steps li.empty .control {
|
||||
display: none; }
|
||||
#browser_steps li:hover {
|
||||
background: #eee; }
|
||||
#browser_steps li > label {
|
||||
display: none; }
|
||||
|
||||
#browser-steps-fieldlist {
|
||||
height: 100%;
|
||||
overflow-y: scroll; }
|
||||
|
||||
#browser-steps .flex-wrapper {
|
||||
display: flex;
|
||||
flex-flow: row;
|
||||
height: 600px;
|
||||
/*@todo make this dynamic */ }
|
||||
|
||||
/* this is duplicate :( */
|
||||
#browsersteps-selector-wrapper {
|
||||
height: 100%;
|
||||
width: 100%;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
/* nice tall skinny one */ }
|
||||
#browsersteps-selector-wrapper > img {
|
||||
position: absolute;
|
||||
max-width: 100%; }
|
||||
#browsersteps-selector-wrapper > canvas {
|
||||
position: relative;
|
||||
max-width: 100%; }
|
||||
#browsersteps-selector-wrapper > canvas:hover {
|
||||
cursor: pointer; }
|
||||
#browsersteps-selector-wrapper .loader {
|
||||
position: absolute;
|
||||
left: 50%;
|
||||
top: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
margin-left: -40px;
|
||||
z-index: 100; }
|
||||
#browsersteps-selector-wrapper .spinner, #browsersteps-selector-wrapper .spinner:after {
|
||||
width: 80px;
|
||||
height: 80px;
|
||||
font-size: 3px; }
|
||||
|
||||
.arrow {
|
||||
border: solid #1b98f8;
|
||||
border-width: 0 2px 2px 0;
|
||||
@@ -132,7 +230,7 @@ body:after, body:before {
|
||||
|
||||
.fetch-error {
|
||||
padding-top: 1em;
|
||||
font-size: 60%;
|
||||
font-size: 80%;
|
||||
max-width: 400px;
|
||||
display: block; }
|
||||
|
||||
@@ -252,12 +350,12 @@ footer {
|
||||
|
||||
#top-right-menu {
|
||||
/*
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
background: linear-gradient(to right, #fff0, #fff 10%);
|
||||
padding-left: 20px;
|
||||
padding-right: 10px;
|
||||
*/ }
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
background: linear-gradient(to right, #fff0, #fff 10%);
|
||||
padding-left: 20px;
|
||||
padding-right: 10px;
|
||||
*/ }
|
||||
|
||||
.sticky-tab {
|
||||
position: absolute;
|
||||
@@ -356,10 +454,10 @@ footer {
|
||||
input[type='text'] {
|
||||
width: 100%; }
|
||||
/*
|
||||
Max width before this PARTICULAR table gets nasty
|
||||
This query will take effect for any screen smaller than 760px
|
||||
and also iPads specifically.
|
||||
*/
|
||||
Max width before this PARTICULAR table gets nasty
|
||||
This query will take effect for any screen smaller than 760px
|
||||
and also iPads specifically.
|
||||
*/
|
||||
.watch-table {
|
||||
/* Force table to not be like tables anymore */
|
||||
/* Force table to not be like tables anymore */
|
||||
@@ -446,7 +544,7 @@ and also iPads specifically.
|
||||
.tab-pane-inner:target {
|
||||
display: block; }
|
||||
|
||||
#beta-logo {
|
||||
.beta-logo {
|
||||
height: 50px;
|
||||
right: -3px;
|
||||
top: -3px;
|
||||
@@ -455,6 +553,9 @@ and also iPads specifically.
|
||||
#selector-header {
|
||||
padding-bottom: 1em; }
|
||||
|
||||
body.full-width .edit-form {
|
||||
width: 95%; }
|
||||
|
||||
.edit-form {
|
||||
min-width: 70%;
|
||||
/* so it cant overflow */
|
||||
@@ -481,7 +582,7 @@ ul {
|
||||
width: 5em; }
|
||||
|
||||
#selector-wrapper {
|
||||
height: 600px;
|
||||
height: 100%;
|
||||
overflow-y: scroll;
|
||||
position: relative; }
|
||||
#selector-wrapper > img {
|
||||
@@ -507,44 +608,24 @@ ul {
|
||||
#api-key-copy {
|
||||
color: #0078e7; }
|
||||
|
||||
/* spinner */
|
||||
.loader,
|
||||
.loader:after {
|
||||
border-radius: 50%;
|
||||
width: 10px;
|
||||
height: 10px; }
|
||||
.button-green {
|
||||
background-color: #42dd53; }
|
||||
|
||||
.loader {
|
||||
margin: 0px auto;
|
||||
font-size: 3px;
|
||||
vertical-align: middle;
|
||||
display: inline-block;
|
||||
text-indent: -9999em;
|
||||
border-top: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-right: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-bottom: 1.1em solid rgba(38, 104, 237, 0.2);
|
||||
border-left: 1.1em solid #2668ed;
|
||||
-webkit-transform: translateZ(0);
|
||||
-ms-transform: translateZ(0);
|
||||
transform: translateZ(0);
|
||||
-webkit-animation: load8 1.1s infinite linear;
|
||||
animation: load8 1.1s infinite linear; }
|
||||
.button-red {
|
||||
background-color: #dd4242; }
|
||||
|
||||
@-webkit-keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg); }
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg); } }
|
||||
|
||||
@keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg); }
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg); } }
|
||||
.noselect {
|
||||
-webkit-touch-callout: none;
|
||||
/* iOS Safari */
|
||||
-webkit-user-select: none;
|
||||
/* Safari */
|
||||
-moz-user-select: none;
|
||||
/* Old versions of Firefox */
|
||||
-ms-user-select: none;
|
||||
/* Internet Explorer/Edge */
|
||||
user-select: none;
|
||||
/* Non-prefixed version, currently
|
||||
supported by Chrome, Edge, Opera and Firefox */ }
|
||||
|
||||
.snapshot-age {
|
||||
padding: 4px;
|
||||
@@ -565,3 +646,16 @@ ul {
|
||||
|
||||
.checkbox-uuid > * {
|
||||
vertical-align: middle; }
|
||||
|
||||
.inline-warning {
|
||||
border: 1px solid #ff3300;
|
||||
padding: 0.5rem;
|
||||
border-radius: 5px;
|
||||
color: #ff3300; }
|
||||
.inline-warning > span {
|
||||
display: inline-block;
|
||||
vertical-align: middle; }
|
||||
.inline-warning img.inline-warning-icon {
|
||||
display: inline;
|
||||
height: 26px;
|
||||
vertical-align: middle; }
|
||||
|
||||
@@ -1,15 +1,19 @@
|
||||
/*
|
||||
* -- BASE STYLES --
|
||||
* Most of these are inherited from Base, but I want to change a few.
|
||||
* nvm use v14.18.1 && npm install && npm run build
|
||||
nvm use v14.18.1 && npm install && npm run build
|
||||
* or npm run watch
|
||||
*/
|
||||
|
||||
@import "parts/spinners";
|
||||
@import "parts/browser-steps";
|
||||
@import "parts/_arrows.scss";
|
||||
|
||||
body {
|
||||
color: #333;
|
||||
background: #262626;
|
||||
}
|
||||
|
||||
.pure-table-even {
|
||||
background: #fff;
|
||||
}
|
||||
@@ -156,7 +160,7 @@ body:after, body:before {
|
||||
|
||||
.fetch-error {
|
||||
padding-top: 1em;
|
||||
font-size: 60%;
|
||||
font-size: 80%;
|
||||
max-width: 400px;
|
||||
display: block;
|
||||
}
|
||||
@@ -209,46 +213,50 @@ body:after, body:before {
|
||||
}
|
||||
|
||||
.messages {
|
||||
li {
|
||||
list-style: none;
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
color: #fff;
|
||||
font-weight: bold;
|
||||
&.message {
|
||||
background: rgba(255, 255, 255, .2);
|
||||
}
|
||||
&.error {
|
||||
background: rgba(255, 1, 1, .5);
|
||||
}
|
||||
&.notice {
|
||||
background: rgba(255, 255, 255, .5);
|
||||
}
|
||||
li {
|
||||
list-style: none;
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
color: #fff;
|
||||
font-weight: bold;
|
||||
|
||||
&.message {
|
||||
background: rgba(255, 255, 255, .2);
|
||||
}
|
||||
&.with-share-link {
|
||||
> *:hover {
|
||||
cursor:pointer;
|
||||
}
|
||||
|
||||
&.error {
|
||||
background: rgba(255, 1, 1, .5);
|
||||
}
|
||||
|
||||
&.notice {
|
||||
background: rgba(255, 255, 255, .5);
|
||||
}
|
||||
}
|
||||
|
||||
&.with-share-link {
|
||||
> *:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#notification-customisation {
|
||||
border: 1px solid #ccc;
|
||||
padding: 0.5rem;
|
||||
border-radius: 5px;
|
||||
border: 1px solid #ccc;
|
||||
padding: 0.5rem;
|
||||
border-radius: 5px;
|
||||
}
|
||||
|
||||
#notification-error-log {
|
||||
border: 1px solid #ccc;
|
||||
padding: 1rem;
|
||||
border-radius: 5px;
|
||||
overflow-wrap: break-word;
|
||||
border: 1px solid #ccc;
|
||||
padding: 1rem;
|
||||
border-radius: 5px;
|
||||
overflow-wrap: break-word;
|
||||
}
|
||||
|
||||
#token-table {
|
||||
&.pure-table td, &.pure-table th {
|
||||
font-size: 80%;
|
||||
}
|
||||
&.pure-table td, &.pure-table th {
|
||||
font-size: 80%;
|
||||
}
|
||||
}
|
||||
|
||||
#new-watch-form {
|
||||
@@ -256,13 +264,16 @@ body:after, body:before {
|
||||
padding: 1em;
|
||||
border-radius: 10px;
|
||||
margin-bottom: 1em;
|
||||
|
||||
input {
|
||||
display: inline-block;
|
||||
margin-bottom: 5px;
|
||||
}
|
||||
|
||||
.label {
|
||||
display: none;
|
||||
}
|
||||
|
||||
legend {
|
||||
color: #fff;
|
||||
font-weight: bold;
|
||||
@@ -281,8 +292,6 @@ body:after, body:before {
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
#diff-col {
|
||||
padding-left: 40px;
|
||||
}
|
||||
@@ -296,15 +305,16 @@ body:after, body:before {
|
||||
border-top-right-radius: 5px;
|
||||
border-bottom-right-radius: 5px;
|
||||
box-shadow: 5px 0 5px -2px #888;
|
||||
a {
|
||||
color: #1b98f8;
|
||||
cursor: grabbing;
|
||||
-moz-user-select: none;
|
||||
-webkit-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
-o-user-select: none;
|
||||
}
|
||||
|
||||
a {
|
||||
color: #1b98f8;
|
||||
cursor: grabbing;
|
||||
-moz-user-select: none;
|
||||
-webkit-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
-o-user-select: none;
|
||||
}
|
||||
}
|
||||
|
||||
footer {
|
||||
@@ -319,14 +329,14 @@ footer {
|
||||
}
|
||||
|
||||
#top-right-menu {
|
||||
// Just let flex overflow the x axis for now
|
||||
/*
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
background: linear-gradient(to right, #fff0, #fff 10%);
|
||||
padding-left: 20px;
|
||||
padding-right: 10px;
|
||||
*/
|
||||
// Just let flex overflow the x axis for now
|
||||
/*
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
background: linear-gradient(to right, #fff0, #fff 10%);
|
||||
padding-left: 20px;
|
||||
padding-right: 10px;
|
||||
*/
|
||||
}
|
||||
|
||||
.sticky-tab {
|
||||
@@ -335,12 +345,15 @@ footer {
|
||||
font-size: 65%;
|
||||
background: #fff;
|
||||
padding: 10px;
|
||||
|
||||
&#left-sticky {
|
||||
left: 0px;
|
||||
}
|
||||
|
||||
&#right-sticky {
|
||||
right: 0px;
|
||||
}
|
||||
|
||||
&#hosted-sticky {
|
||||
right: 0px;
|
||||
top: 100px;
|
||||
@@ -374,43 +387,49 @@ footer {
|
||||
}
|
||||
|
||||
.monospaced-textarea {
|
||||
textarea {
|
||||
width: 100%;
|
||||
font-family: monospace;
|
||||
white-space: pre;
|
||||
overflow-wrap: normal;
|
||||
overflow-x: scroll;
|
||||
}
|
||||
textarea {
|
||||
width: 100%;
|
||||
font-family: monospace;
|
||||
white-space: pre;
|
||||
overflow-wrap: normal;
|
||||
overflow-x: scroll;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
.pure-form {
|
||||
fieldset {
|
||||
padding-top: 0px;
|
||||
ul {
|
||||
padding-bottom: 0px;
|
||||
margin-bottom: 0px;
|
||||
}
|
||||
fieldset {
|
||||
padding-top: 0px;
|
||||
|
||||
ul {
|
||||
padding-bottom: 0px;
|
||||
margin-bottom: 0px;
|
||||
}
|
||||
.pure-control-group, .pure-group, .pure-controls {
|
||||
padding-bottom: 1em;
|
||||
div {
|
||||
margin: 0px;
|
||||
}
|
||||
.checkbox {
|
||||
> * {
|
||||
display: inline;
|
||||
vertical-align: middle;
|
||||
}
|
||||
> label {
|
||||
padding-left: 5px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.pure-control-group, .pure-group, .pure-controls {
|
||||
padding-bottom: 1em;
|
||||
|
||||
div {
|
||||
margin: 0px;
|
||||
}
|
||||
|
||||
.checkbox {
|
||||
> * {
|
||||
display: inline;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
> label {
|
||||
padding-left: 5px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/* The input fields with errors */
|
||||
.error {
|
||||
input {
|
||||
background-color: #ffebeb;
|
||||
background-color: #ffebeb;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -422,9 +441,10 @@ footer {
|
||||
vertical-align: middle;
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
|
||||
li {
|
||||
margin-left: 1em;
|
||||
color: #dd0000;
|
||||
margin-left: 1em;
|
||||
color: #dd0000;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -435,19 +455,22 @@ footer {
|
||||
textarea {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.inline-radio {
|
||||
ul {
|
||||
margin: 0px;
|
||||
list-style: none;
|
||||
li {
|
||||
> * {
|
||||
display: inline-block;
|
||||
}
|
||||
ul {
|
||||
margin: 0px;
|
||||
list-style: none;
|
||||
|
||||
li {
|
||||
> * {
|
||||
display: inline-block;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@media only screen and (max-width: 760px), (min-device-width: 768px) and (max-device-width: 1024px) {
|
||||
.box {
|
||||
max-width: 95%
|
||||
@@ -462,7 +485,6 @@ footer {
|
||||
}
|
||||
|
||||
|
||||
|
||||
@media only screen and (max-width: 760px), (min-device-width: 768px) and (max-device-width: 800px) {
|
||||
|
||||
div.sticky-tab#hosted-sticky {
|
||||
@@ -486,11 +508,11 @@ footer {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
/*
|
||||
Max width before this PARTICULAR table gets nasty
|
||||
This query will take effect for any screen smaller than 760px
|
||||
and also iPads specifically.
|
||||
*/
|
||||
/*
|
||||
Max width before this PARTICULAR table gets nasty
|
||||
This query will take effect for any screen smaller than 760px
|
||||
and also iPads specifically.
|
||||
*/
|
||||
.watch-table {
|
||||
/* Force table to not be like tables anymore */
|
||||
thead, tbody, th, td, tr {
|
||||
@@ -567,19 +589,19 @@ and also iPads specifically.
|
||||
- Rely always on width in CSS
|
||||
*/
|
||||
@media only screen and (min-width: 761px) {
|
||||
/* m-d is medium-desktop */
|
||||
.m-d {
|
||||
min-width: 80%;
|
||||
}
|
||||
/* m-d is medium-desktop */
|
||||
.m-d {
|
||||
min-width: 80%;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
.tabs {
|
||||
ul {
|
||||
margin: 0px;
|
||||
padding: 0px;
|
||||
display:block;
|
||||
display: block;
|
||||
|
||||
li {
|
||||
margin-right: 3px;
|
||||
display: inline-block;
|
||||
@@ -588,13 +610,15 @@ and also iPads specifically.
|
||||
border-top-right-radius: 5px;
|
||||
background-color: rgba(255, 255, 255, 0.2);
|
||||
|
||||
&.active,:target {
|
||||
&.active, :target {
|
||||
background-color: #fff;
|
||||
|
||||
a {
|
||||
color: #222;
|
||||
font-weight: bold;
|
||||
}
|
||||
}
|
||||
|
||||
a {
|
||||
display: block;
|
||||
padding: 0.8em;
|
||||
@@ -606,7 +630,7 @@ and also iPads specifically.
|
||||
|
||||
$form-edge-padding: 20px;
|
||||
.pure-form-stacked {
|
||||
>div:first-child {
|
||||
> div:first-child {
|
||||
display: block;
|
||||
}
|
||||
}
|
||||
@@ -620,39 +644,48 @@ $form-edge-padding: 20px;
|
||||
}
|
||||
|
||||
.tab-pane-inner {
|
||||
&:not(:target) {
|
||||
display: none;
|
||||
}
|
||||
&:target {
|
||||
display: block;
|
||||
}
|
||||
// doesnt need padding because theres another row of buttons/activity
|
||||
padding: 0px;
|
||||
&:not(:target) {
|
||||
display: none;
|
||||
}
|
||||
|
||||
&:target {
|
||||
display: block;
|
||||
}
|
||||
|
||||
// doesnt need padding because theres another row of buttons/activity
|
||||
padding: 0px;
|
||||
}
|
||||
|
||||
#beta-logo {
|
||||
height: 50px;
|
||||
// looks better when it's hanging off a little
|
||||
right: -3px;
|
||||
top: -3px;
|
||||
position: absolute;
|
||||
.beta-logo {
|
||||
height: 50px;
|
||||
// looks better when it's hanging off a little
|
||||
right: -3px;
|
||||
top: -3px;
|
||||
position: absolute;
|
||||
}
|
||||
|
||||
#selector-header {
|
||||
padding-bottom: 1em;
|
||||
padding-bottom: 1em;
|
||||
}
|
||||
body.full-width {
|
||||
.edit-form {
|
||||
width: 95%;
|
||||
}
|
||||
}
|
||||
|
||||
.edit-form {
|
||||
min-width: 70%;
|
||||
/* so it cant overflow */
|
||||
max-width: 95%;
|
||||
|
||||
.box-wrap {
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.inner {
|
||||
background: #fff;;
|
||||
padding: $form-edge-padding;
|
||||
}
|
||||
|
||||
#actions {
|
||||
display: block;
|
||||
background: #fff;
|
||||
@@ -664,38 +697,41 @@ $form-edge-padding: 20px;
|
||||
}
|
||||
|
||||
ul {
|
||||
padding-left: 1em;
|
||||
padding-top: 0px;
|
||||
margin-top: 4px;
|
||||
padding-left: 1em;
|
||||
padding-top: 0px;
|
||||
margin-top: 4px;
|
||||
}
|
||||
|
||||
.time-check-widget {
|
||||
tr {
|
||||
display: inline;
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
tr {
|
||||
display: inline;
|
||||
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#selector-wrapper {
|
||||
height: 600px;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
//width: 100%;
|
||||
> img {
|
||||
height: 100%;
|
||||
overflow-y: scroll;
|
||||
position: relative;
|
||||
//width: 100%;
|
||||
> img {
|
||||
position: absolute;
|
||||
z-index: 4;
|
||||
max-width: 100%;
|
||||
}
|
||||
>canvas {
|
||||
}
|
||||
|
||||
> canvas {
|
||||
position: relative;
|
||||
z-index: 5;
|
||||
max-width: 100%;
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
max-width: 100%;
|
||||
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#selector-current-xpath {
|
||||
@@ -703,9 +739,9 @@ ul {
|
||||
}
|
||||
|
||||
#webdriver-override-options {
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
input[type="number"] {
|
||||
width: 5em;
|
||||
}
|
||||
}
|
||||
|
||||
#api-key {
|
||||
@@ -718,48 +754,22 @@ ul {
|
||||
color: #0078e7;
|
||||
}
|
||||
|
||||
/* spinner */
|
||||
.loader,
|
||||
.loader:after {
|
||||
border-radius: 50%;
|
||||
width: 10px;
|
||||
height: 10px;
|
||||
.button-green {
|
||||
background-color: #42dd53;
|
||||
}
|
||||
.loader {
|
||||
margin: 0px auto;
|
||||
font-size: 3px;
|
||||
vertical-align: middle;
|
||||
display: inline-block;
|
||||
text-indent: -9999em;
|
||||
border-top: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-right: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-bottom: 1.1em solid rgba(38,104,237, 0.2);
|
||||
border-left: 1.1em solid #2668ed;
|
||||
-webkit-transform: translateZ(0);
|
||||
-ms-transform: translateZ(0);
|
||||
transform: translateZ(0);
|
||||
-webkit-animation: load8 1.1s infinite linear;
|
||||
animation: load8 1.1s infinite linear;
|
||||
|
||||
.button-red {
|
||||
background-color: #dd4242;
|
||||
}
|
||||
@-webkit-keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
@keyframes load8 {
|
||||
0% {
|
||||
-webkit-transform: rotate(0deg);
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
-webkit-transform: rotate(360deg);
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
|
||||
.noselect {
|
||||
-webkit-touch-callout: none; /* iOS Safari */
|
||||
-webkit-user-select: none; /* Safari */
|
||||
-moz-user-select: none; /* Old versions of Firefox */
|
||||
-ms-user-select: none; /* Internet Explorer/Edge */
|
||||
user-select: none;
|
||||
/* Non-prefixed version, currently
|
||||
supported by Chrome, Edge, Opera and Firefox */
|
||||
}
|
||||
|
||||
.snapshot-age {
|
||||
@@ -786,3 +796,21 @@ ul {
|
||||
vertical-align: middle;
|
||||
}
|
||||
}
|
||||
|
||||
.inline-warning {
|
||||
> span {
|
||||
display: inline-block;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
img.inline-warning-icon {
|
||||
display: inline;
|
||||
height: 26px;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
border: 1px solid #ff3300;
|
||||
padding: 0.5rem;
|
||||
border-radius: 5px;
|
||||
color: #ff3300;
|
||||
}
|
||||
|
||||
@@ -27,17 +27,18 @@ class ChangeDetectionStore:
|
||||
# For when we edit, we should write to disk
|
||||
needs_write_urgent = False
|
||||
|
||||
__version_check = True
|
||||
|
||||
def __init__(self, datastore_path="/datastore", include_default_watches=True, version_tag="0.0.0"):
|
||||
# Should only be active for docker
|
||||
# logging.basicConfig(filename='/dev/stdout', level=logging.INFO)
|
||||
self.needs_write = False
|
||||
self.__data = App.model()
|
||||
self.datastore_path = datastore_path
|
||||
self.json_store_path = "{}/url-watches.json".format(self.datastore_path)
|
||||
self.needs_write = False
|
||||
self.proxy_list = None
|
||||
self.start_time = time.time()
|
||||
self.stop_thread = False
|
||||
|
||||
self.__data = App.model()
|
||||
|
||||
# Base definition for all watchers
|
||||
# deepcopy part of #569 - not sure why its needed exactly
|
||||
self.generic_definition = deepcopy(Watch.model(datastore_path = datastore_path, default={}))
|
||||
@@ -81,10 +82,13 @@ class ChangeDetectionStore:
|
||||
except (FileNotFoundError, json.decoder.JSONDecodeError):
|
||||
if include_default_watches:
|
||||
print("Creating JSON store at", self.datastore_path)
|
||||
self.add_watch(url='https://news.ycombinator.com/',
|
||||
tag='Tech news',
|
||||
extras={'fetch_backend': 'html_requests'})
|
||||
|
||||
self.add_watch(url='http://www.quotationspage.com/random.php', tag='test')
|
||||
self.add_watch(url='https://news.ycombinator.com/', tag='Tech news')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt', tag='changedetection.io')
|
||||
self.add_watch(url='https://changedetection.io/CHANGELOG.txt',
|
||||
tag='changedetection.io',
|
||||
extras={'fetch_backend': 'html_requests'})
|
||||
|
||||
self.__data['version_tag'] = version_tag
|
||||
|
||||
@@ -113,9 +117,7 @@ class ChangeDetectionStore:
|
||||
self.__data['settings']['application']['api_access_token'] = secret
|
||||
|
||||
# Proxy list support - available as a selection in settings when text file is imported
|
||||
# CSV list
|
||||
# "name, address", or just "name"
|
||||
proxy_list_file = "{}/proxies.txt".format(self.datastore_path)
|
||||
proxy_list_file = "{}/proxies.json".format(self.datastore_path)
|
||||
if path.isfile(proxy_list_file):
|
||||
self.import_proxy_list(proxy_list_file)
|
||||
|
||||
@@ -270,7 +272,7 @@ class ChangeDetectionStore:
|
||||
extras = {}
|
||||
# should always be str
|
||||
if tag is None or not tag:
|
||||
tag=''
|
||||
tag = ''
|
||||
|
||||
# Incase these are copied across, assume it's a reference and deepcopy()
|
||||
apply_extras = deepcopy(extras)
|
||||
@@ -285,17 +287,31 @@ class ChangeDetectionStore:
|
||||
res = r.json()
|
||||
|
||||
# List of permissible attributes we accept from the wild internet
|
||||
for k in ['url', 'tag',
|
||||
'paused', 'title',
|
||||
'previous_md5', 'headers',
|
||||
'body', 'method',
|
||||
'ignore_text', 'css_filter',
|
||||
'subtractive_selectors', 'trigger_text',
|
||||
'extract_title_as_title', 'extract_text',
|
||||
'text_should_not_be_present',
|
||||
'webdriver_js_execute_code']:
|
||||
for k in [
|
||||
'body',
|
||||
'css_filter',
|
||||
'extract_text',
|
||||
'extract_title_as_title',
|
||||
'headers',
|
||||
'ignore_text',
|
||||
'include_filters',
|
||||
'method',
|
||||
'paused',
|
||||
'previous_md5',
|
||||
'subtractive_selectors',
|
||||
'tag',
|
||||
'text_should_not_be_present',
|
||||
'title',
|
||||
'trigger_text',
|
||||
'url',
|
||||
'webdriver_js_execute_code',
|
||||
]:
|
||||
if res.get(k):
|
||||
apply_extras[k] = res[k]
|
||||
if k != 'css_filter':
|
||||
apply_extras[k] = res[k]
|
||||
else:
|
||||
# We renamed the field and made it a list
|
||||
apply_extras['include_filters'] = [res['css_filter']]
|
||||
|
||||
except Exception as e:
|
||||
logging.error("Error fetching metadata for shared watch link", url, str(e))
|
||||
@@ -318,12 +334,13 @@ class ChangeDetectionStore:
|
||||
del apply_extras[k]
|
||||
|
||||
new_watch.update(apply_extras)
|
||||
self.__data['watching'][new_uuid]=new_watch
|
||||
self.__data['watching'][new_uuid] = new_watch
|
||||
|
||||
self.__data['watching'][new_uuid].ensure_data_dir_exists()
|
||||
|
||||
if write_to_disk_now:
|
||||
self.sync_to_json()
|
||||
|
||||
return new_uuid
|
||||
|
||||
def visualselector_data_is_ready(self, watch_uuid):
|
||||
@@ -351,6 +368,12 @@ class ChangeDetectionStore:
|
||||
f.write(screenshot)
|
||||
f.close()
|
||||
|
||||
# Make a JPEG that's used in notifications (due to being a smaller size) available
|
||||
from PIL import Image
|
||||
im1 = Image.open(target_path)
|
||||
im1.convert('RGB').save(target_path.replace('.png','.jpg'), quality=int(os.getenv("NOTIFICATION_SCREENSHOT_JPG_QUALITY", 75)))
|
||||
|
||||
|
||||
def save_error_text(self, watch_uuid, contents):
|
||||
if not self.data['watching'].get(watch_uuid):
|
||||
return
|
||||
@@ -437,20 +460,42 @@ class ChangeDetectionStore:
|
||||
unlink(item)
|
||||
|
||||
def import_proxy_list(self, filename):
|
||||
import csv
|
||||
with open(filename, newline='') as f:
|
||||
reader = csv.reader(f, skipinitialspace=True)
|
||||
# @todo This loop can could be improved
|
||||
l = []
|
||||
for row in reader:
|
||||
if len(row):
|
||||
if len(row)>=2:
|
||||
l.append(tuple(row[:2]))
|
||||
else:
|
||||
l.append(tuple([row[0], row[0]]))
|
||||
self.proxy_list = l if len(l) else None
|
||||
with open(filename) as f:
|
||||
self.proxy_list = json.load(f)
|
||||
print ("Registered proxy list", list(self.proxy_list.keys()))
|
||||
|
||||
|
||||
def get_preferred_proxy_for_watch(self, uuid):
|
||||
"""
|
||||
Returns the preferred proxy by ID key
|
||||
:param uuid: UUID
|
||||
:return: proxy "key" id
|
||||
"""
|
||||
|
||||
proxy_id = None
|
||||
if self.proxy_list is None:
|
||||
return None
|
||||
|
||||
# If its a valid one
|
||||
watch = self.data['watching'].get(uuid)
|
||||
|
||||
if watch.get('proxy') and watch.get('proxy') in list(self.proxy_list.keys()):
|
||||
return watch.get('proxy')
|
||||
|
||||
# not valid (including None), try the system one
|
||||
else:
|
||||
system_proxy_id = self.data['settings']['requests'].get('proxy')
|
||||
# Is not None and exists
|
||||
if self.proxy_list.get(system_proxy_id):
|
||||
return system_proxy_id
|
||||
|
||||
# Fallback - Did not resolve anything, use the first available
|
||||
if system_proxy_id is None:
|
||||
first_default = list(self.proxy_list)[0]
|
||||
return first_default
|
||||
|
||||
return None
|
||||
|
||||
# Run all updates
|
||||
# IMPORTANT - Each update could be run even when they have a new install and the schema is correct
|
||||
# So therefor - each `update_n` should be very careful about checking if it needs to actually run
|
||||
@@ -537,26 +582,42 @@ class ChangeDetectionStore:
|
||||
continue
|
||||
return
|
||||
|
||||
|
||||
def update_5(self):
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
)
|
||||
|
||||
# If the watch notification body, title look the same as the global one, unset it, so the watch defaults back to using the main settings
|
||||
# In other words - the watch notification_title and notification_body are not needed if they are the same as the default one
|
||||
current_system_body = self.data['settings']['application']['notification_body'].translate(str.maketrans('', '', "\r\n "))
|
||||
current_system_title = self.data['settings']['application']['notification_body'].translate(str.maketrans('', '', "\r\n "))
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
# If it's all the same to the system settings, then prefer system notification settings
|
||||
# include \r\n -> \n incase they already hit submit and the browser put \r in
|
||||
if watch.get('notification_body').replace('\r\n', '\n') == default_notification_body.replace('\r\n', '\n') and \
|
||||
watch.get('notification_format') == default_notification_format and \
|
||||
watch.get('notification_title').replace('\r\n', '\n') == default_notification_title.replace('\r\n', '\n') and \
|
||||
watch.get('notification_urls') == self.__data['settings']['application']['notification_urls']:
|
||||
watch['notification_use_default'] = True
|
||||
else:
|
||||
watch['notification_use_default'] = False
|
||||
watch_body = watch.get('notification_body', '')
|
||||
if watch_body and watch_body.translate(str.maketrans('', '', "\r\n ")) == current_system_body:
|
||||
# Looks the same as the default one, so unset it
|
||||
watch['notification_body'] = None
|
||||
|
||||
watch_title = watch.get('notification_title', '')
|
||||
if watch_title and watch_title.translate(str.maketrans('', '', "\r\n ")) == current_system_title:
|
||||
# Looks the same as the default one, so unset it
|
||||
watch['notification_title'] = None
|
||||
except Exception as e:
|
||||
continue
|
||||
return
|
||||
|
||||
|
||||
# We incorrectly used common header overrides that should only apply to Requests
|
||||
# These are now handled in content_fetcher::html_requests and shouldnt be passed to Playwright/Selenium
|
||||
def update_7(self):
|
||||
# These were hard-coded in early versions
|
||||
for v in ['User-Agent', 'Accept', 'Accept-Encoding', 'Accept-Language']:
|
||||
if self.data['settings']['headers'].get(v):
|
||||
del self.data['settings']['headers'][v]
|
||||
|
||||
# Convert filters to a list of filters css_filter -> include_filters
|
||||
def update_8(self):
|
||||
for uuid, watch in self.data['watching'].items():
|
||||
try:
|
||||
existing_filter = watch.get('css_filter', '')
|
||||
if existing_filter:
|
||||
watch['include_filters'] = [existing_filter]
|
||||
except:
|
||||
continue
|
||||
return
|
||||
@@ -1,13 +1,14 @@
|
||||
|
||||
{% from '_helpers.jinja' import render_field %}
|
||||
|
||||
{% macro render_common_settings_form(form, current_base_url, emailprefix) %}
|
||||
{% macro render_common_settings_form(form, emailprefix, settings_application) %}
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.notification_urls, rows=5, placeholder="Examples:
|
||||
Gitter - gitter://token/room
|
||||
Office365 - o365://TenantID:AccountEmail/ClientID/ClientSecret/TargetEmail
|
||||
AWS SNS - sns://AccessKeyID/AccessSecretKey/RegionName/+PhoneNo
|
||||
SMTPS - mailtos://user:pass@mail.domain.com?to=receivingAddress@example.com", class="notification-urls")
|
||||
SMTPS - mailtos://user:pass@mail.domain.com?to=receivingAddress@example.com",
|
||||
class="notification-urls" )
|
||||
}}
|
||||
<div class="pure-form-message-inline">
|
||||
<ul>
|
||||
@@ -26,15 +27,16 @@
|
||||
</div>
|
||||
<div id="notification-customisation" class="pure-control-group">
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.notification_title, class="m-d notification-title") }}
|
||||
{{ render_field(form.notification_title, class="m-d notification-title", placeholder=settings_application['notification_title']) }}
|
||||
<span class="pure-form-message-inline">Title for all notifications</span>
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.notification_body , rows=5, class="notification-body") }}
|
||||
{{ render_field(form.notification_body , rows=5, class="notification-body", placeholder=settings_application['notification_body']) }}
|
||||
<span class="pure-form-message-inline">Body for all notifications</span>
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.notification_format , rows=5, class="notification-format") }}
|
||||
<!-- unsure -->
|
||||
{{ render_field(form.notification_format , class="notification-format") }}
|
||||
<span class="pure-form-message-inline">Format for all notifications</span>
|
||||
</div>
|
||||
<div class="pure-controls">
|
||||
@@ -94,7 +96,7 @@
|
||||
</table>
|
||||
<br/>
|
||||
URLs generated by changedetection.io (such as <code>{diff_url}</code>) require the <code>BASE_URL</code> environment variable set.<br/>
|
||||
Your <code>BASE_URL</code> var is currently "{{current_base_url}}"
|
||||
Your <code>BASE_URL</code> var is currently "{{settings_application['current_base_url']}}"
|
||||
</span>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -21,6 +21,9 @@
|
||||
|
||||
<label for="diffChars" class="pure-checkbox">
|
||||
<input type="radio" name="diff_type" id="diffChars" value="diffChars"/> Chars</label>
|
||||
<!-- @todo - when mimetype is JSON, select this by default? -->
|
||||
<label for="diffJson" class="pure-checkbox">
|
||||
<input type="radio" name="diff_type" id="diffJson" value="diffJson" /> JSON</label>
|
||||
|
||||
{% if versions|length >= 1 %}
|
||||
<label for="diff-version">Compare newest (<span id="current-v-date"></span>) with</label>
|
||||
@@ -37,6 +40,11 @@
|
||||
</form>
|
||||
<del>Removed text</del>
|
||||
<ins>Inserted Text</ins>
|
||||
<span>
|
||||
<!-- https://github.com/kpdecker/jsdiff/issues/389 ? -->
|
||||
<label for="ignoreWhitespace" class="pure-checkbox" id="label-diff-ignorewhitespace">
|
||||
<input type="checkbox" id="ignoreWhitespace" name="ignoreWhitespace"/> Ignore Whitespace</label>
|
||||
</span>
|
||||
</div>
|
||||
|
||||
<div id="diff-jump">
|
||||
@@ -102,122 +110,12 @@
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='diff.js')}}"></script>
|
||||
|
||||
<script defer="">
|
||||
|
||||
var a = document.getElementById('a');
|
||||
var b = document.getElementById('b');
|
||||
var result = document.getElementById('result');
|
||||
|
||||
function changed() {
|
||||
var diff = JsDiff[window.diffType](a.textContent, b.textContent);
|
||||
var fragment = document.createDocumentFragment();
|
||||
for (var i=0; i < diff.length; i++) {
|
||||
|
||||
if (diff[i].added && diff[i + 1] && diff[i + 1].removed) {
|
||||
var swap = diff[i];
|
||||
diff[i] = diff[i + 1];
|
||||
diff[i + 1] = swap;
|
||||
}
|
||||
|
||||
var node;
|
||||
if (diff[i].removed) {
|
||||
node = document.createElement('del');
|
||||
node.classList.add("change");
|
||||
node.appendChild(document.createTextNode(diff[i].value));
|
||||
|
||||
} else if (diff[i].added) {
|
||||
node = document.createElement('ins');
|
||||
node.classList.add("change");
|
||||
node.appendChild(document.createTextNode(diff[i].value));
|
||||
} else {
|
||||
node = document.createTextNode(diff[i].value);
|
||||
}
|
||||
fragment.appendChild(node);
|
||||
}
|
||||
|
||||
result.textContent = '';
|
||||
result.appendChild(fragment);
|
||||
|
||||
// Jump at start
|
||||
inputs.current=0;
|
||||
next_diff();
|
||||
}
|
||||
|
||||
window.onload = function() {
|
||||
|
||||
|
||||
/* Convert what is options from UTC time.time() to local browser time */
|
||||
var diffList=document.getElementById("diff-version");
|
||||
if (typeof(diffList) != 'undefined' && diffList != null) {
|
||||
for (var option of diffList.options) {
|
||||
var dateObject = new Date(option.value*1000);
|
||||
option.label=dateObject.toLocaleString();
|
||||
}
|
||||
}
|
||||
|
||||
/* Set current version date as local time in the browser also */
|
||||
var current_v = document.getElementById("current-v-date");
|
||||
var dateObject = new Date({{ newest_version_timestamp }}*1000);
|
||||
current_v.innerHTML=dateObject.toLocaleString();
|
||||
|
||||
|
||||
onDiffTypeChange(document.querySelector('#settings [name="diff_type"]:checked'));
|
||||
changed();
|
||||
|
||||
};
|
||||
|
||||
a.onpaste = a.onchange =
|
||||
b.onpaste = b.onchange = changed;
|
||||
|
||||
if ('oninput' in a) {
|
||||
a.oninput = b.oninput = changed;
|
||||
} else {
|
||||
a.onkeyup = b.onkeyup = changed;
|
||||
}
|
||||
|
||||
function onDiffTypeChange(radio) {
|
||||
window.diffType = radio.value;
|
||||
// Not necessary
|
||||
// document.title = "Diff " + radio.value.slice(4);
|
||||
}
|
||||
|
||||
var radio = document.getElementsByName('diff_type');
|
||||
for (var i = 0; i < radio.length; i++) {
|
||||
radio[i].onchange = function(e) {
|
||||
onDiffTypeChange(e.target);
|
||||
changed();
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
var inputs = document.getElementsByClassName('change');
|
||||
inputs.current=0;
|
||||
|
||||
|
||||
function next_diff() {
|
||||
|
||||
var element = inputs[inputs.current];
|
||||
var headerOffset = 80;
|
||||
var elementPosition = element.getBoundingClientRect().top;
|
||||
var offsetPosition = elementPosition - headerOffset + window.scrollY;
|
||||
|
||||
window.scrollTo({
|
||||
top: offsetPosition,
|
||||
behavior: "smooth"
|
||||
});
|
||||
|
||||
inputs.current++;
|
||||
if(inputs.current >= inputs.length) {
|
||||
inputs.current=0;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
<script>
|
||||
const newest_version_timestamp = {{newest_version_timestamp}};
|
||||
</script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='diff.min.js')}}"></script>
|
||||
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='diff-render.js')}}"></script>
|
||||
|
||||
|
||||
{% endblock %}
|
||||
@@ -13,11 +13,17 @@
|
||||
const email_notification_prefix=JSON.parse('{{ emailprefix|tojson }}');
|
||||
{% endif %}
|
||||
|
||||
const browser_steps_config=JSON.parse('{{ browser_steps_config|tojson }}');
|
||||
const browser_steps_sync_url="{{url_for('browser_steps.browsersteps_ui_update', uuid=uuid)}}";
|
||||
</script>
|
||||
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='watch-settings.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='limit.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='notifications.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='visual-selector.js')}}" defer></script>
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='limit.js')}}" defer></script>
|
||||
{% if playwright_enabled %}
|
||||
<script type="text/javascript" src="{{url_for('static_content', group='js', filename='browser-steps.js')}}" defer></script>
|
||||
{% endif %}
|
||||
|
||||
<div class="edit-form monospaced-textarea">
|
||||
|
||||
@@ -25,6 +31,9 @@
|
||||
<ul>
|
||||
<li class="tab" id=""><a href="#general">General</a></li>
|
||||
<li class="tab"><a href="#request">Request</a></li>
|
||||
{% if playwright_enabled %}
|
||||
<li class="tab"><a id="browsersteps-tab" href="#browser-steps">Browser Steps</a></li>
|
||||
{% endif %}
|
||||
<li class="tab"><a id="visualselector-tab" href="#visualselector">Visual Filter Selector</a></li>
|
||||
<li class="tab"><a href="#filters-and-triggers">Filters & Triggers</a></li>
|
||||
<li class="tab"><a href="#notifications">Notifications</a></li>
|
||||
@@ -40,7 +49,8 @@
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.url, placeholder="https://...", required=true, class="m-d") }}
|
||||
<span class="pure-form-message-inline">Some sites use JavaScript to create the content, for this you should <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">use the Chrome/WebDriver Fetcher</a></span>
|
||||
<span class="pure-form-message-inline">Some sites use JavaScript to create the content, for this you should <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">use the Chrome/WebDriver Fetcher</a></span><br/>
|
||||
<span class="pure-form-message-inline">You can use variables in the URL, perfect for inserting the current date and other logic, <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Handling-variables-in-the-watched-URL">help and examples here</a></span><br/>
|
||||
</div>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.title, class="m-d") }}
|
||||
@@ -77,6 +87,7 @@
|
||||
<span class="pure-form-message-inline">
|
||||
<p>Use the <strong>Basic</strong> method (default) where your watched site doesn't need Javascript to render.</p>
|
||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||
Tip: <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support">Connect using BrightData Proxies, find out more here.</a>
|
||||
</span>
|
||||
</div>
|
||||
{% if form.proxy %}
|
||||
@@ -133,14 +144,68 @@ User-Agent: wonderbra 1.0") }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
{% if playwright_enabled %}
|
||||
<div class="tab-pane-inner" id="browser-steps">
|
||||
<img class="beta-logo" src="{{url_for('static_content', group='images', filename='beta-logo.png')}}">
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
<!--
|
||||
Too hard right now, better to just send the events to the fetcher for now and leave it in the final screenshot
|
||||
and/or report an error
|
||||
<a id="play-steps" class="pure-button button-secondary button-xsmall" style="font-size: 70%">Play steps ▶</a>
|
||||
-->
|
||||
|
||||
<!--- Do this later -->
|
||||
<div class="checkbox" style="display: none;">
|
||||
<input type=checkbox id="include_text_elements" > <label for="include_text_elements">Turn on text finder</label>
|
||||
</div>
|
||||
|
||||
<div id="loading-status-text" style="display: none;">Please wait, first browser step can take a little time to load..<div class="spinner"></div></div>
|
||||
<div class="flex-wrapper" >
|
||||
|
||||
<div id="browser-steps-ui" class="noselect" style="width: 100%; background-color: #eee; border-radius: 5px;">
|
||||
|
||||
<div class="noselect" id="browsersteps-selector-wrapper" style="width: 100%">
|
||||
<span class="loader">
|
||||
<div class="spinner"></div>
|
||||
</span>
|
||||
<img class="noselect" id="browsersteps-img" src="" style="max-width: 100%; width: 100%;" />
|
||||
<canvas class="noselect" id="browsersteps-selector-canvas" style="max-width: 100%; width: 100%;"></canvas>
|
||||
</div>
|
||||
</div>
|
||||
<div id="browser-steps-fieldlist" style="padding-left: 1em; width: 350px; font-size: 80%;" >
|
||||
<span id="browserless-seconds-remaining">Loading</span> <span style="font-size: 80%;"> (<a target=_new href="https://github.com/dgtlmoon/changedetection.io/pull/478/files#diff-1a79d924d1840c485238e66772391268a89c95b781d69091384cf1ea1ac146c9R4">?</a>) </span>
|
||||
{{ render_field(form.browser_steps) }}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
{% endif %}
|
||||
|
||||
<div class="tab-pane-inner" id="notifications">
|
||||
<fieldset>
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_checkbox_field(form.notification_use_default) }}
|
||||
{{ render_checkbox_field(form.notification_muted) }}
|
||||
</div>
|
||||
{% if is_html_webdriver %}
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_checkbox_field(form.notification_screenshot) }}
|
||||
<span class="pure-form-message-inline">
|
||||
<strong>Use with caution!</strong> This will easily fill up your email storage quota or flood other storages.
|
||||
</span>
|
||||
</div>
|
||||
{% endif %}
|
||||
<div class="field-group" id="notification-field-group">
|
||||
{{ render_common_settings_form(form, current_base_url, emailprefix) }}
|
||||
{% if has_default_notification_urls %}
|
||||
<div class="inline-warning">
|
||||
<img class="inline-warning-icon" src="{{url_for('static_content', group='images', filename='notice.svg')}}" alt="Look out!" title="Lookout!"/>
|
||||
There are <a href="{{ url_for('settings_page')}}#notifications">system-wide notification URLs enabled</a>, this form will override notification settings for this watch only ‐ an empty Notification URL list here will still send notifications.
|
||||
</div>
|
||||
{% endif %}
|
||||
<a href="#notifications" id="notification-setting-reset-to-default" class="pure-button button-xsmall" style="right: 20px; top: 20px; position: absolute; background-color: #5f42dd; border-radius: 4px; font-size: 70%; color: #fff">Use system defaults</a>
|
||||
|
||||
{{ render_common_settings_form(form, emailprefix, settings_application) }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
@@ -164,19 +229,29 @@ User-Agent: wonderbra 1.0") }}
|
||||
</div>
|
||||
</fieldset>
|
||||
<div class="pure-control-group">
|
||||
{% set field = render_field(form.css_filter,
|
||||
placeholder=".class-name or #some-id, or other CSS selector rule.",
|
||||
{% set field = render_field(form.include_filters,
|
||||
rows=5,
|
||||
placeholder="#example
|
||||
xpath://body/div/span[contains(@class, 'example-class')]",
|
||||
class="m-d")
|
||||
%}
|
||||
{{ field }}
|
||||
{% if '/text()' in field %}
|
||||
<span class="pure-form-message-inline"><strong>Note!: //text() function does not work where the <element> contains <![CDATA[]]></strong></span><br/>
|
||||
{% endif %}
|
||||
<span class="pure-form-message-inline">
|
||||
<span class="pure-form-message-inline">One rule per line, <i>any</i> rules that matches will be used.<br/>
|
||||
<ul>
|
||||
<li>CSS - Limit text to this CSS rule, only text matching this CSS rule is included.</li>
|
||||
<li>JSON - Limit text to this JSON rule, using <a href="https://pypi.org/project/jsonpath-ng/">JSONPath</a>, prefix with <code>"json:"</code>, use <code>json:$</code> to force re-formatting if required, <a
|
||||
href="https://jsonpath.com/" target="new">test your JSONPath here</a></li>
|
||||
<li>JSON - Limit text to this JSON rule, using either <a href="https://pypi.org/project/jsonpath-ng/" target="new">JSONPath</a> or <a href="https://stedolan.github.io/jq/" target="new">jq</a> (if installed).
|
||||
<ul>
|
||||
<li>JSONPath: Prefix with <code>json:</code>, use <code>json:$</code> to force re-formatting if required, <a href="https://jsonpath.com/" target="new">test your JSONPath here</a>.</li>
|
||||
{% if jq_support %}
|
||||
<li>jq: Prefix with <code>jq:</code> and <a href="https://jqplay.org/" target="new">test your jq here</a>. Using <a href="https://stedolan.github.io/jq/" target="new">jq</a> allows for complex filtering and processing of JSON data with built-in functions, regex, filtering, and more. See examples and documentation <a href="https://stedolan.github.io/jq/manual/" target="new">here</a>.</li>
|
||||
{% else %}
|
||||
<li>jq support not installed</li>
|
||||
{% endif %}
|
||||
</ul>
|
||||
</li>
|
||||
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash,
|
||||
<ul>
|
||||
<li>Example: <code>//*[contains(@class, 'sametext')]</code> or <code>xpath://*[contains(@class, 'sametext')]</code>, <a
|
||||
@@ -185,7 +260,7 @@ User-Agent: wonderbra 1.0") }}
|
||||
</ul>
|
||||
</li>
|
||||
</ul>
|
||||
Please be sure that you thoroughly understand how to write CSS or JSONPath, XPath selector rules before filing an issue on GitHub! <a
|
||||
Please be sure that you thoroughly understand how to write CSS, JSONPath, XPath{% if jq_support %}, or jq selector{%endif%} rules before filing an issue on GitHub! <a
|
||||
href="https://github.com/dgtlmoon/changedetection.io/wiki/CSS-Selector-help">here for more CSS selector help</a>.<br/>
|
||||
</span>
|
||||
</div>
|
||||
@@ -267,39 +342,32 @@ Unavailable") }}
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner visual-selector-ui" id="visualselector">
|
||||
<img id="beta-logo" src="{{url_for('static_content', group='images', filename='beta-logo.png')}}">
|
||||
<strong>Pro-tip:</strong> This tool is only for limiting which elements will be included on a change-detection, not for interacting with browser directly.
|
||||
<img class="beta-logo" src="{{url_for('static_content', group='images', filename='beta-logo.png')}}">
|
||||
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
{% if visualselector_enabled %}
|
||||
{% if visualselector_data_is_ready %}
|
||||
<div id="selector-header">
|
||||
<a id="clear-selector" class="pure-button button-secondary button-xsmall" style="font-size: 70%">Clear selection</a>
|
||||
<i class="fetching-update-notice" style="font-size: 80%;">One moment, fetching screenshot and element information..</i>
|
||||
</div>
|
||||
<div id="selector-wrapper">
|
||||
<!-- request the screenshot and get the element offset info ready -->
|
||||
<!-- use img src ready load to know everything is ready to map out -->
|
||||
<!-- @todo: maybe something interesting like a field to select 'elements that contain text... and their parents n' -->
|
||||
<img id="selector-background" />
|
||||
<canvas id="selector-canvas"></canvas>
|
||||
|
||||
</div>
|
||||
<div id="selector-current-xpath" style="overflow-x: hidden"><strong>Currently:</strong> <span class="text">Loading...</span></div>
|
||||
|
||||
<span class="pure-form-message-inline">
|
||||
<p><span style="font-weight: bold">Beta!</span> The Visual Selector is new and there may be minor bugs, please report pages that dont work, help us to improve this software!</p>
|
||||
The Visual Selector tool lets you select the <i>text</i> elements that will be used for the change detection ‐ after the <i>Browser Steps</i> has completed.<br/><br/>
|
||||
</span>
|
||||
|
||||
{% else %}
|
||||
<span class="pure-form-message-inline">Screenshot and element data is not available or not yet ready.</span>
|
||||
{% endif %}
|
||||
<div id="selector-header">
|
||||
<a id="clear-selector" class="pure-button button-secondary button-xsmall" style="font-size: 70%">Clear selection</a>
|
||||
<i class="fetching-update-notice" style="font-size: 80%;">One moment, fetching screenshot and element information..</i>
|
||||
</div>
|
||||
<div id="selector-wrapper" style="display: none">
|
||||
<!-- request the screenshot and get the element offset info ready -->
|
||||
<!-- use img src ready load to know everything is ready to map out -->
|
||||
<!-- @todo: maybe something interesting like a field to select 'elements that contain text... and their parents n' -->
|
||||
<img id="selector-background" />
|
||||
<canvas id="selector-canvas"></canvas>
|
||||
</div>
|
||||
<div id="selector-current-xpath" style="overflow-x: hidden"><strong>Currently:</strong> <span class="text">Loading...</span></div>
|
||||
{% else %}
|
||||
<span class="pure-form-message-inline">
|
||||
<p>Sorry, this functionality only works with Playwright/Chrome enabled watches.</p>
|
||||
<p>Enable the Playwright Chrome fetcher, or alternatively try our <a href="https://lemonade.changedetection.io/start">very affordable subscription based service</a>.</p>
|
||||
<p>This is because Selenium/WebDriver can not extract full page screenshots reliably.</p>
|
||||
|
||||
</span>
|
||||
{% endif %}
|
||||
</div>
|
||||
|
||||
@@ -60,7 +60,7 @@
|
||||
{{ render_field(form.application.form.base_url, placeholder="http://yoursite.com:5000/",
|
||||
class="m-d") }}
|
||||
<span class="pure-form-message-inline">
|
||||
Base URL used for the {base_url} token in notifications and RSS links.<br/>Default value is the ENV var 'BASE_URL' (Currently "{{current_base_url}}"),
|
||||
Base URL used for the <code>{base_url}</code> token in notifications and RSS links.<br/>Default value is the ENV var 'BASE_URL' (Currently "{{settings_application['current_base_url']}}"),
|
||||
<a href="https://github.com/dgtlmoon/changedetection.io/wiki/Configurable-BASE_URL-setting">read more here</a>.
|
||||
</span>
|
||||
</div>
|
||||
@@ -87,7 +87,7 @@
|
||||
<div class="tab-pane-inner" id="notifications">
|
||||
<fieldset>
|
||||
<div class="field-group">
|
||||
{{ render_common_settings_form(form.application.form, current_base_url, emailprefix) }}
|
||||
{{ render_common_settings_form(form.application.form, emailprefix, settings_application) }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
@@ -99,6 +99,8 @@
|
||||
<p>Use the <strong>Basic</strong> method (default) where your watched sites don't need Javascript to render.</p>
|
||||
<p>The <strong>Chrome/Javascript</strong> method requires a network connection to a running WebDriver+Chrome server, set by the ENV var 'WEBDRIVER_URL'. </p>
|
||||
</span>
|
||||
<br/>
|
||||
Tip: <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support">Connect using BrightData Proxies, find out more here.</a>
|
||||
</div>
|
||||
<fieldset class="pure-group" id="webdriver-override-options">
|
||||
<div class="pure-form-message-inline">
|
||||
|
||||
@@ -30,6 +30,9 @@
|
||||
<div id="checkbox-operations">
|
||||
<button class="pure-button button-secondary button-xsmall" style="font-size: 70%" name="op" value="pause">Pause</button>
|
||||
<button class="pure-button button-secondary button-xsmall" style="font-size: 70%" name="op" value="unpause">UnPause</button>
|
||||
<button class="pure-button button-secondary button-xsmall" style="font-size: 70%" name="op" value="mute">Mute</button>
|
||||
<button class="pure-button button-secondary button-xsmall" style="font-size: 70%" name="op" value="unmute">UnMute</button>
|
||||
<button class="pure-button button-secondary button-xsmall" style="font-size: 70%" name="op" value="notification-default">Use default notification</button>
|
||||
<button class="pure-button button-secondary button-xsmall" style="background: #dd4242; font-size: 70%" name="op" value="delete">Delete</button>
|
||||
</div>
|
||||
<div>
|
||||
@@ -76,11 +79,15 @@
|
||||
{% if watch.uuid in queued_uuids %}queued{% endif %}">
|
||||
<td class="inline checkbox-uuid" ><input name="uuids" type="checkbox" value="{{ watch.uuid}} "/> <span>{{ loop.index }}</span></td>
|
||||
<td class="inline watch-controls">
|
||||
<a class="state-{{'on' if watch.paused }}" href="{{url_for('index', op='pause', uuid=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='pause.svg')}}" alt="Pause checks" title="Pause checks"/></a>
|
||||
{% if not watch.paused %}
|
||||
<a class="state-off" href="{{url_for('index', op='pause', uuid=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='pause.svg')}}" alt="Pause checks" title="Pause checks"/></a>
|
||||
{% else %}
|
||||
<a class="state-on" href="{{url_for('index', op='pause', uuid=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='play.svg')}}" alt="UnPause checks" title="UnPause checks"/></a>
|
||||
{% endif %}
|
||||
<a class="state-{{'on' if watch.notification_muted}}" href="{{url_for('index', op='mute', uuid=watch.uuid, tag=active_tag)}}"><img src="{{url_for('static_content', group='images', filename='bell-off.svg')}}" alt="Mute notifications" title="Mute notifications"/></a>
|
||||
</td>
|
||||
<td class="title-col inline">{{watch.title if watch.title is not none and watch.title|length > 0 else watch.url}}
|
||||
<a class="external" target="_blank" rel="noopener" href="{{ watch.url.replace('source:','') }}"></a>
|
||||
<a class="external" target="_blank" rel="noopener" href="{{ watch.link.replace('source:','') }}"></a>
|
||||
<a href="{{url_for('form_share_put_watch', uuid=watch.uuid)}}"><img style="height: 1em;display:inline-block;" src="{{url_for('static_content', group='images', filename='spread.svg')}}" /></a>
|
||||
|
||||
{%if watch.fetch_backend == "html_webdriver" %}<img style="height: 1em; display:inline-block;" src="{{url_for('static_content', group='images', filename='Google-Chrome-icon.png')}}" />{% endif %}
|
||||
@@ -89,7 +96,7 @@
|
||||
<div class="fetch-error">{{ watch.last_error }}</div>
|
||||
{% endif %}
|
||||
{% if watch.last_notification_error is defined and watch.last_notification_error != False %}
|
||||
<div class="fetch-error notification-error">{{ watch.last_notification_error }}</div>
|
||||
<div class="fetch-error notification-error"><a href="{{url_for('notification_logs')}}">{{ watch.last_notification_error }}</a></div>
|
||||
{% endif %}
|
||||
{% if not active_tag %}
|
||||
<span class="watch-tag-list">{{ watch.tag}}</span>
|
||||
|
||||
@@ -41,7 +41,7 @@ def app(request):
|
||||
|
||||
cleanup(datastore_path)
|
||||
|
||||
app_config = {'datastore_path': datastore_path}
|
||||
app_config = {'datastore_path': datastore_path, 'disable_checkver' : True}
|
||||
cleanup(app_config['datastore_path'])
|
||||
datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], include_default_watches=False)
|
||||
app = changedetection_app(app_config, datastore)
|
||||
|
||||
@@ -5,7 +5,7 @@ from flask import url_for
|
||||
from ..util import live_server_setup, wait_for_all_checks
|
||||
import logging
|
||||
|
||||
|
||||
# Requires playwright to be installed
|
||||
def test_fetch_webdriver_content(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
|
||||
2
changedetectionio/tests/proxy_list/__init__.py
Normal file
2
changedetectionio/tests/proxy_list/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
"""Tests for the app."""
|
||||
|
||||
14
changedetectionio/tests/proxy_list/conftest.py
Normal file
14
changedetectionio/tests/proxy_list/conftest.py
Normal file
@@ -0,0 +1,14 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
from .. import conftest
|
||||
|
||||
#def pytest_addoption(parser):
|
||||
# parser.addoption("--url_suffix", action="store", default="identifier for request")
|
||||
|
||||
|
||||
#def pytest_generate_tests(metafunc):
|
||||
# # This is called for every test. Only get/set command line arguments
|
||||
# # if the argument is specified in the list of test "fixturenames".
|
||||
# option_value = metafunc.config.option.url_suffix
|
||||
# if 'url_suffix' in metafunc.fixturenames and option_value is not None:
|
||||
# metafunc.parametrize("url_suffix", [option_value])
|
||||
10
changedetectionio/tests/proxy_list/proxies.json-example
Normal file
10
changedetectionio/tests/proxy_list/proxies.json-example
Normal file
@@ -0,0 +1,10 @@
|
||||
{
|
||||
"proxy-one": {
|
||||
"label": "One",
|
||||
"url": "http://127.0.0.1:3128"
|
||||
},
|
||||
"proxy-two": {
|
||||
"label": "two",
|
||||
"url": "http://127.0.0.1:3129"
|
||||
}
|
||||
}
|
||||
41
changedetectionio/tests/proxy_list/squid.conf
Normal file
41
changedetectionio/tests/proxy_list/squid.conf
Normal file
@@ -0,0 +1,41 @@
|
||||
acl localnet src 0.0.0.1-0.255.255.255 # RFC 1122 "this" network (LAN)
|
||||
acl localnet src 10.0.0.0/8 # RFC 1918 local private network (LAN)
|
||||
acl localnet src 100.64.0.0/10 # RFC 6598 shared address space (CGN)
|
||||
acl localnet src 169.254.0.0/16 # RFC 3927 link-local (directly plugged) machines
|
||||
acl localnet src 172.16.0.0/12 # RFC 1918 local private network (LAN)
|
||||
acl localnet src 192.168.0.0/16 # RFC 1918 local private network (LAN)
|
||||
acl localnet src fc00::/7 # RFC 4193 local private network range
|
||||
acl localnet src fe80::/10 # RFC 4291 link-local (directly plugged) machines
|
||||
acl localnet src 159.65.224.174
|
||||
acl SSL_ports port 443
|
||||
acl Safe_ports port 80 # http
|
||||
acl Safe_ports port 21 # ftp
|
||||
acl Safe_ports port 443 # https
|
||||
acl Safe_ports port 70 # gopher
|
||||
acl Safe_ports port 210 # wais
|
||||
acl Safe_ports port 1025-65535 # unregistered ports
|
||||
acl Safe_ports port 280 # http-mgmt
|
||||
acl Safe_ports port 488 # gss-http
|
||||
acl Safe_ports port 591 # filemaker
|
||||
acl Safe_ports port 777 # multiling http
|
||||
acl CONNECT method CONNECT
|
||||
|
||||
http_access deny !Safe_ports
|
||||
http_access deny CONNECT !SSL_ports
|
||||
http_access allow localhost manager
|
||||
http_access deny manager
|
||||
http_access allow localhost
|
||||
http_access allow localnet
|
||||
http_access deny all
|
||||
http_port 3128
|
||||
coredump_dir /var/spool/squid
|
||||
refresh_pattern ^ftp: 1440 20% 10080
|
||||
refresh_pattern ^gopher: 1440 0% 1440
|
||||
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
|
||||
refresh_pattern \/(Packages|Sources)(|\.bz2|\.gz|\.xz)$ 0 0% 0 refresh-ims
|
||||
refresh_pattern \/Release(|\.gpg)$ 0 0% 0 refresh-ims
|
||||
refresh_pattern \/InRelease$ 0 0% 0 refresh-ims
|
||||
refresh_pattern \/(Translation-.*)(|\.bz2|\.gz|\.xz)$ 0 0% 0 refresh-ims
|
||||
refresh_pattern . 0 20% 4320
|
||||
logfile_rotate 0
|
||||
|
||||
38
changedetectionio/tests/proxy_list/test_multiple_proxy.py
Normal file
38
changedetectionio/tests/proxy_list/test_multiple_proxy.py
Normal file
@@ -0,0 +1,38 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from ..util import live_server_setup
|
||||
|
||||
def test_preferred_proxy(client, live_server):
|
||||
time.sleep(1)
|
||||
live_server_setup(live_server)
|
||||
time.sleep(1)
|
||||
url = "http://chosen.changedetection.io"
|
||||
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
# Because a URL wont show in squid/proxy logs due it being SSLed
|
||||
# Use plain HTTP or a specific domain-name here
|
||||
data={"urls": url},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
time.sleep(2)
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={
|
||||
"include_filters": "",
|
||||
"fetch_backend": "html_requests",
|
||||
"headers": "",
|
||||
"proxy": "proxy-two",
|
||||
"tag": "",
|
||||
"url": url,
|
||||
},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
time.sleep(2)
|
||||
# Now the request should appear in the second-squid logs
|
||||
19
changedetectionio/tests/proxy_list/test_proxy.py
Normal file
19
changedetectionio/tests/proxy_list/test_proxy.py
Normal file
@@ -0,0 +1,19 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from ..util import live_server_setup, wait_for_all_checks, extract_UUID_from_client
|
||||
|
||||
# just make a request, we will grep in the docker logs to see it actually got called
|
||||
def test_check_basic_change_detection_functionality(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
# Because a URL wont show in squid/proxy logs due it being SSLed
|
||||
# Use plain HTTP or a specific domain-name here
|
||||
data={"urls": "http://one.changedetection.io"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(3)
|
||||
@@ -147,6 +147,16 @@ def test_api_simple(client, live_server):
|
||||
# @todo how to handle None/default global values?
|
||||
assert watch['history_n'] == 2, "Found replacement history section, which is in its own API"
|
||||
|
||||
# basic systeminfo check
|
||||
res = client.get(
|
||||
url_for("systeminfo"),
|
||||
headers={'x-api-key': api_key},
|
||||
)
|
||||
info = json.loads(res.data)
|
||||
assert info.get('watch_count') == 1
|
||||
assert info.get('uptime') > 0.5
|
||||
|
||||
|
||||
# Finally delete the watch
|
||||
res = client.delete(
|
||||
url_for("watch", uuid=watch_uuid),
|
||||
|
||||
@@ -19,17 +19,16 @@ def test_basic_auth(client, live_server):
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(1)
|
||||
|
||||
# Check form validation
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": "", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": "", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(1)
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
import time
|
||||
from flask import url_for
|
||||
from urllib.request import urlopen
|
||||
from .util import set_original_response, set_modified_response, live_server_setup
|
||||
from .util import set_original_response, set_modified_response, live_server_setup, wait_for_all_checks
|
||||
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
@@ -36,7 +36,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
wait_for_all_checks(client)
|
||||
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
@@ -69,7 +69,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
res = client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert b'1 watches are queued for rechecking.' in res.data
|
||||
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
wait_for_all_checks(client)
|
||||
|
||||
# Now something should be ready, indicated by having a 'unviewed' class
|
||||
res = client.get(url_for("index"))
|
||||
@@ -98,14 +98,14 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
assert b'which has this one new line' in res.data
|
||||
assert b'Which is across multiple lines' not in res.data
|
||||
|
||||
time.sleep(2)
|
||||
wait_for_all_checks(client)
|
||||
|
||||
# Do this a few times.. ensures we dont accidently set the status
|
||||
for n in range(2):
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
wait_for_all_checks(client)
|
||||
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(url_for("index"))
|
||||
@@ -125,7 +125,7 @@ def test_check_basic_change_detection_functionality(client, live_server):
|
||||
)
|
||||
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
wait_for_all_checks(client)
|
||||
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
@@ -1,18 +1,31 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from .util import set_original_response, set_modified_response, live_server_setup
|
||||
from flask import url_for
|
||||
from urllib.request import urlopen
|
||||
from . util import set_original_response, set_modified_response, live_server_setup
|
||||
from zipfile import ZipFile
|
||||
import re
|
||||
import time
|
||||
|
||||
|
||||
def test_backup(client, live_server):
|
||||
|
||||
live_server_setup(live_server)
|
||||
|
||||
set_original_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": url_for('test_endpoint', _external=True)},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(3)
|
||||
|
||||
res = client.get(
|
||||
url_for("get_backup"),
|
||||
follow_redirects=True
|
||||
@@ -20,6 +33,19 @@ def test_backup(client, live_server):
|
||||
|
||||
# Should get the right zip content type
|
||||
assert res.content_type == "application/zip"
|
||||
|
||||
# Should be PK/ZIP stream
|
||||
assert res.data.count(b'PK') >= 2
|
||||
|
||||
# ZipFile from buffer seems non-obvious, just save it instead
|
||||
with open("download.zip", 'wb') as f:
|
||||
f.write(res.data)
|
||||
|
||||
zip = ZipFile('download.zip')
|
||||
l = zip.namelist()
|
||||
uuid4hex = re.compile('^[a-f0-9]{8}-?[a-f0-9]{4}-?4[a-f0-9]{3}-?[89ab][a-f0-9]{3}-?[a-f0-9]{12}.*txt', re.I)
|
||||
newlist = list(filter(uuid4hex.match, l)) # Read Note below
|
||||
|
||||
# Should be two txt files in the archive (history and the snapshot)
|
||||
assert len(newlist) == 2
|
||||
|
||||
|
||||
@@ -46,22 +46,23 @@ def set_modified_response():
|
||||
|
||||
|
||||
# Test that the CSS extraction works how we expect, important here is the right placing of new lines \n's
|
||||
def test_css_filter_output():
|
||||
from changedetectionio import fetch_site_status
|
||||
def test_include_filters_output():
|
||||
from inscriptis import get_text
|
||||
|
||||
# Check text with sub-parts renders correctly
|
||||
content = """<html> <body><div id="thingthing" > Some really <b>bold</b> text </div> </body> </html>"""
|
||||
html_blob = css_filter(css_filter="#thingthing", html_content=content)
|
||||
html_blob = include_filters(include_filters="#thingthing", html_content=content)
|
||||
text = get_text(html_blob)
|
||||
assert text == " Some really bold text"
|
||||
|
||||
content = """<html> <body>
|
||||
<p>foo bar blah</p>
|
||||
<div class="parts">Block A</div> <div class="parts">Block B</div></body>
|
||||
<DIV class="parts">Block A</DiV> <div class="parts">Block B</DIV></body>
|
||||
</html>
|
||||
"""
|
||||
html_blob = css_filter(css_filter=".parts", html_content=content)
|
||||
|
||||
# in xPath this would be //*[@class='parts']
|
||||
html_blob = include_filters(include_filters=".parts", html_content=content)
|
||||
text = get_text(html_blob)
|
||||
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
@@ -69,10 +70,10 @@ def test_css_filter_output():
|
||||
|
||||
|
||||
# Tests the whole stack works with the CSS Filter
|
||||
def test_check_markup_css_filter_restriction(client, live_server):
|
||||
def test_check_markup_include_filters_restriction(client, live_server):
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
css_filter = "#sametext"
|
||||
include_filters = "#sametext"
|
||||
|
||||
set_original_response()
|
||||
|
||||
@@ -88,9 +89,6 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -98,19 +96,16 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": css_filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": include_filters, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
time.sleep(1)
|
||||
# Check it saved
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert bytes(css_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert bytes(include_filters.encode('utf-8')) in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
@@ -126,3 +121,58 @@ def test_check_markup_css_filter_restriction(client, live_server):
|
||||
# Because it should be looking at only that 'sametext' id
|
||||
res = client.get(url_for("index"))
|
||||
assert b'unviewed' in res.data
|
||||
|
||||
|
||||
# Tests the whole stack works with the CSS Filter
|
||||
def test_check_multiple_filters(client, live_server):
|
||||
sleep_time_for_fetch_thread = 3
|
||||
|
||||
include_filters = "#blob-a\r\nxpath://*[contains(@id,'blob-b')]"
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write("""<html><body>
|
||||
<div id="blob-a">Blob A</div>
|
||||
<div id="blob-b">Blob B</div>
|
||||
<div id="blob-c">Blob C</div>
|
||||
</body>
|
||||
</html>
|
||||
""")
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
res = client.post(
|
||||
url_for("import_page"),
|
||||
data={"urls": test_url},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(1)
|
||||
|
||||
# Goto the edit page, add our ignore text
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"include_filters": include_filters,
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Only the two blobs should be here
|
||||
assert b"Blob A" in res.data # CSS was ok
|
||||
assert b"Blob B" in res.data # xPath was ok
|
||||
assert b"Blob C" not in res.data # Should not be included
|
||||
|
||||
@@ -70,9 +70,6 @@ def test_check_encoding_detection_missing_content_type_header(client, live_serve
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(2)
|
||||
|
||||
|
||||
@@ -88,7 +88,7 @@ def test_check_filter_multiline(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": '',
|
||||
data={"include_filters": '',
|
||||
'extract_text': '/something.+?6 billion.+?lines/si',
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
@@ -116,7 +116,7 @@ def test_check_filter_multiline(client, live_server):
|
||||
|
||||
def test_check_filter_and_regex_extract(client, live_server):
|
||||
sleep_time_for_fetch_thread = 3
|
||||
css_filter = ".changetext"
|
||||
include_filters = ".changetext"
|
||||
|
||||
set_original_response()
|
||||
|
||||
@@ -143,7 +143,7 @@ def test_check_filter_and_regex_extract(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": css_filter,
|
||||
data={"include_filters": include_filters,
|
||||
'extract_text': '\d+ online\r\n\d+ guests\r\n/somecase insensitive \d+/i\r\n/somecase insensitive (345\d)/i',
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
|
||||
@@ -92,7 +92,7 @@ def test_filter_doesnt_exist_then_exists_should_get_notification(client, live_se
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
"headers": "",
|
||||
"css_filter": '.ticket-available',
|
||||
"include_filters": '.ticket-available',
|
||||
"fetch_backend": "html_requests"})
|
||||
|
||||
res = client.post(
|
||||
|
||||
@@ -76,7 +76,7 @@ def run_filter_test(client, content_filter):
|
||||
"title": "my title",
|
||||
"headers": "",
|
||||
"filter_failure_notification_send": 'y',
|
||||
"css_filter": content_filter,
|
||||
"include_filters": content_filter,
|
||||
"fetch_backend": "html_requests"})
|
||||
|
||||
res = client.post(
|
||||
@@ -95,7 +95,7 @@ def run_filter_test(client, content_filter):
|
||||
time.sleep(3)
|
||||
|
||||
# We should see something in the frontend
|
||||
assert b'Warning, filter' in res.data
|
||||
assert b'Warning, no filters were found' in res.data
|
||||
|
||||
# Now it should exist and contain our "filter not found" alert
|
||||
assert os.path.isfile("test-datastore/notification.txt")
|
||||
@@ -131,7 +131,7 @@ def run_filter_test(client, content_filter):
|
||||
def test_setup(live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
def test_check_css_filter_failure_notification(client, live_server):
|
||||
def test_check_include_filters_failure_notification(client, live_server):
|
||||
set_original_response()
|
||||
time.sleep(1)
|
||||
run_filter_test(client, '#nope-doesnt-exist')
|
||||
|
||||
33
changedetectionio/tests/test_jinja2.py
Normal file
33
changedetectionio/tests/test_jinja2.py
Normal file
@@ -0,0 +1,33 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from .util import live_server_setup
|
||||
|
||||
|
||||
# If there was only a change in the whitespacing, then we shouldnt have a change detected
|
||||
def test_jinja2_in_url_query(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
|
||||
# Add our URL to the import page
|
||||
test_url = url_for('test_return_query', _external=True)
|
||||
|
||||
# because url_for() will URL-encode the var, but we dont here
|
||||
full_url = "{}?{}".format(test_url,
|
||||
"date={% now 'Europe/Berlin', '%Y' %}.{% now 'Europe/Berlin', '%m' %}.{% now 'Europe/Berlin', '%d' %}", )
|
||||
res = client.post(
|
||||
url_for("form_quick_watch_add"),
|
||||
data={"url": full_url, "tag": "test"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Watch added" in res.data
|
||||
time.sleep(3)
|
||||
# It should report nothing found (no new 'unviewed' class)
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b'date=2' in res.data
|
||||
@@ -2,10 +2,15 @@
|
||||
# coding=utf-8
|
||||
|
||||
import time
|
||||
from flask import url_for
|
||||
from flask import url_for, escape
|
||||
from . util import live_server_setup
|
||||
import pytest
|
||||
jq_support = True
|
||||
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
jq_support = False
|
||||
|
||||
def test_setup(live_server):
|
||||
live_server_setup(live_server)
|
||||
@@ -36,16 +41,28 @@ and it can also be repeated
|
||||
from .. import html_tools
|
||||
|
||||
# See that we can find the second <script> one, which is not broken, and matches our filter
|
||||
text = html_tools.extract_json_as_string(content, "$.offers.price")
|
||||
text = html_tools.extract_json_as_string(content, "json:$.offers.price")
|
||||
assert text == "23.5"
|
||||
|
||||
text = html_tools.extract_json_as_string('{"id":5}', "$.id")
|
||||
# also check for jq
|
||||
if jq_support:
|
||||
text = html_tools.extract_json_as_string(content, "jq:.offers.price")
|
||||
assert text == "23.5"
|
||||
|
||||
text = html_tools.extract_json_as_string('{"id":5}', "jq:.id")
|
||||
assert text == "5"
|
||||
|
||||
text = html_tools.extract_json_as_string('{"id":5}', "json:$.id")
|
||||
assert text == "5"
|
||||
|
||||
# When nothing at all is found, it should throw JSONNOTFound
|
||||
# Which is caught and shown to the user in the watch-overview table
|
||||
with pytest.raises(html_tools.JSONNotFound) as e_info:
|
||||
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "$.id")
|
||||
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "json:$.id")
|
||||
|
||||
if jq_support:
|
||||
with pytest.raises(html_tools.JSONNotFound) as e_info:
|
||||
html_tools.extract_json_as_string('COMPLETE GIBBERISH, NO JSON!', "jq:.id")
|
||||
|
||||
def set_original_ext_response():
|
||||
data = """
|
||||
@@ -66,6 +83,7 @@ def set_original_ext_response():
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(data)
|
||||
return None
|
||||
|
||||
def set_modified_ext_response():
|
||||
data = """
|
||||
@@ -86,6 +104,7 @@ def set_modified_ext_response():
|
||||
|
||||
with open("test-datastore/endpoint-content.txt", "w") as f:
|
||||
f.write(data)
|
||||
return None
|
||||
|
||||
def set_original_response():
|
||||
test_return_data = """
|
||||
@@ -113,7 +132,7 @@ def set_original_response():
|
||||
return None
|
||||
|
||||
|
||||
def set_response_with_html():
|
||||
def set_json_response_with_html():
|
||||
test_return_data = """
|
||||
{
|
||||
"test": [
|
||||
@@ -157,7 +176,7 @@ def set_modified_response():
|
||||
def test_check_json_without_filter(client, live_server):
|
||||
# Request a JSON document from a application/json source containing HTML
|
||||
# and be sure it doesn't get chewed up by instriptis
|
||||
set_response_with_html()
|
||||
set_json_response_with_html()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
time.sleep(1)
|
||||
@@ -170,9 +189,6 @@ def test_check_json_without_filter(client, live_server):
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
|
||||
@@ -181,13 +197,14 @@ def test_check_json_without_filter(client, live_server):
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Should still see '"html": "<b>"'
|
||||
assert b'"<b>' in res.data
|
||||
assert res.data.count(b'{\n') >= 2
|
||||
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
def test_check_json_filter(client, live_server):
|
||||
json_filter = 'json:boss.name'
|
||||
|
||||
def check_json_filter(json_filter, client, live_server):
|
||||
set_original_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -202,9 +219,6 @@ def test_check_json_filter(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
|
||||
@@ -212,7 +226,7 @@ def test_check_json_filter(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": json_filter,
|
||||
data={"include_filters": json_filter,
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
@@ -226,10 +240,7 @@ def test_check_json_filter(client, live_server):
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert bytes(escape(json_filter).encode('utf-8')) in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -252,10 +263,17 @@ def test_check_json_filter(client, live_server):
|
||||
# And #462 - check we see the proper utf-8 string there
|
||||
assert "Örnsköldsvik".encode('utf-8') in res.data
|
||||
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
def test_check_json_filter_bool_val(client, live_server):
|
||||
json_filter = "json:$['available']"
|
||||
def test_check_jsonpath_filter(client, live_server):
|
||||
check_json_filter('json:boss.name', client, live_server)
|
||||
|
||||
def test_check_jq_filter(client, live_server):
|
||||
if jq_support:
|
||||
check_json_filter('jq:.boss.name', client, live_server)
|
||||
|
||||
def check_json_filter_bool_val(json_filter, client, live_server):
|
||||
set_original_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -275,7 +293,7 @@ def test_check_json_filter_bool_val(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": json_filter,
|
||||
data={"include_filters": json_filter,
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
@@ -285,11 +303,6 @@ def test_check_json_filter_bool_val(client, live_server):
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
time.sleep(3)
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
# Make a change
|
||||
@@ -304,14 +317,22 @@ def test_check_json_filter_bool_val(client, live_server):
|
||||
# But the change should be there, tho its hard to test the change was detected because it will show old and new versions
|
||||
assert b'false' in res.data
|
||||
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
def test_check_jsonpath_filter_bool_val(client, live_server):
|
||||
check_json_filter_bool_val("json:$['available']", client, live_server)
|
||||
|
||||
def test_check_jq_filter_bool_val(client, live_server):
|
||||
if jq_support:
|
||||
check_json_filter_bool_val("jq:.available", client, live_server)
|
||||
|
||||
# Re #265 - Extended JSON selector test
|
||||
# Stuff to consider here
|
||||
# - Selector should be allowed to return empty when it doesnt match (people might wait for some condition)
|
||||
# - The 'diff' tab could show the old and new content
|
||||
# - Form should let us enter a selector that doesnt (yet) match anything
|
||||
def test_check_json_ext_filter(client, live_server):
|
||||
json_filter = 'json:$[?(@.status==Sold)]'
|
||||
|
||||
def check_json_ext_filter(json_filter, client, live_server):
|
||||
set_original_ext_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -326,9 +347,6 @@ def test_check_json_ext_filter(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
|
||||
@@ -336,7 +354,7 @@ def test_check_json_ext_filter(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": json_filter,
|
||||
data={"include_filters": json_filter,
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
@@ -350,10 +368,7 @@ def test_check_json_ext_filter(client, live_server):
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert bytes(json_filter.encode('utf-8')) in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
assert bytes(escape(json_filter).encode('utf-8')) in res.data
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(3)
|
||||
@@ -376,3 +391,12 @@ def test_check_json_ext_filter(client, live_server):
|
||||
assert b'ForSale' not in res.data
|
||||
assert b'Sold' in res.data
|
||||
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
def test_check_jsonpath_ext_filter(client, live_server):
|
||||
check_json_ext_filter('json:$[?(@.status==Sold)]', client, live_server)
|
||||
|
||||
def test_check_jq_ext_filter(client, live_server):
|
||||
if jq_support:
|
||||
check_json_ext_filter('jq:.[] | select(.status | contains("Sold"))', client, live_server)
|
||||
@@ -1,10 +1,19 @@
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
from flask import url_for
|
||||
from . util import set_original_response, set_modified_response, set_more_modified_response, live_server_setup
|
||||
from . util import extract_UUID_from_client
|
||||
import logging
|
||||
from changedetectionio.notification import default_notification_body, default_notification_title
|
||||
import base64
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
valid_notification_formats,
|
||||
)
|
||||
|
||||
def test_setup(live_server):
|
||||
live_server_setup(live_server)
|
||||
@@ -12,7 +21,6 @@ def test_setup(live_server):
|
||||
# Hard to just add more live server URLs when one test is already running (I think)
|
||||
# So we add our test here (was in a different file)
|
||||
def test_check_notification(client, live_server):
|
||||
|
||||
set_original_response()
|
||||
|
||||
# Give the endpoint time to spin up
|
||||
@@ -20,9 +28,26 @@ def test_check_notification(client, live_server):
|
||||
|
||||
# Re 360 - new install should have defaults set
|
||||
res = client.get(url_for("settings_page"))
|
||||
notification_url = url_for('test_notification_endpoint', _external=True).replace('http', 'json')
|
||||
|
||||
assert default_notification_body.encode() in res.data
|
||||
assert default_notification_title.encode() in res.data
|
||||
|
||||
#####################
|
||||
# Set this up for when we remove the notification from the watch, it should fallback with these details
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-notification_urls": notification_url,
|
||||
"application-notification_title": "fallback-title "+default_notification_title,
|
||||
"application-notification_body": "fallback-body "+default_notification_body,
|
||||
"application-notification_format": default_notification_format,
|
||||
"requests-time_between_check-minutes": 180,
|
||||
'application-fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b"Settings updated." in res.data
|
||||
|
||||
# When test mode is in BASE_URL env mode, we should see this already configured
|
||||
env_base_url = os.getenv('BASE_URL', '').strip()
|
||||
if len(env_base_url):
|
||||
@@ -45,10 +70,22 @@ def test_check_notification(client, live_server):
|
||||
# Give the thread time to pick up the first version
|
||||
time.sleep(3)
|
||||
|
||||
# We write the PNG to disk, but a JPEG should appear in the notification
|
||||
# Write the last screenshot png
|
||||
testimage_png = 'iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII='
|
||||
# This one is created when we save the screenshot from the webdriver/playwright session (converted from PNG)
|
||||
testimage_jpg = '/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAMCAgMCAgMDAwMEAwMEBQgFBQQEBQoHBwYIDAoMDAsKCwsNDhIQDQ4RDgsLEBYQERMUFRUVDA8XGBYUGBIUFRT/wAALCAABAAEBAREA/8QAFAABAAAAAAAAAAAAAAAAAAAACf/EABQQAQAAAAAAAAAAAAAAAAAAAAD/2gAIAQEAAD8AKp//2Q=='
|
||||
|
||||
|
||||
uuid = extract_UUID_from_client(client)
|
||||
datastore = 'test-datastore'
|
||||
with open(os.path.join(datastore, str(uuid), 'last-screenshot.png'), 'wb') as f:
|
||||
f.write(base64.b64decode(testimage_png))
|
||||
with open(os.path.join(datastore, str(uuid), 'last-screenshot.jpg'), 'wb') as f:
|
||||
f.write(base64.b64decode(testimage_jpg))
|
||||
|
||||
# Goto the edit page, add our ignore text
|
||||
# Add our URL to the import page
|
||||
url = url_for('test_notification_endpoint', _external=True)
|
||||
notification_url = url.replace('http', 'json')
|
||||
|
||||
print (">>>> Notification URL: "+notification_url)
|
||||
|
||||
@@ -65,13 +102,13 @@ def test_check_notification(client, live_server):
|
||||
"Diff: {diff}\n"
|
||||
"Diff Full: {diff_full}\n"
|
||||
":-)",
|
||||
"notification_screenshot": True,
|
||||
"notification_format": "Text"}
|
||||
|
||||
notification_form_data.update({
|
||||
"url": test_url,
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
# No 'notification_use_default' here, so it's effectively False/off
|
||||
"headers": "",
|
||||
"fetch_backend": "html_requests"})
|
||||
|
||||
@@ -96,8 +133,6 @@ def test_check_notification(client, live_server):
|
||||
time.sleep(3)
|
||||
set_modified_response()
|
||||
|
||||
notification_submission = None
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(3)
|
||||
@@ -123,6 +158,19 @@ def test_check_notification(client, live_server):
|
||||
assert ":-)" in notification_submission
|
||||
assert "New ChangeDetection.io Notification - {}".format(test_url) in notification_submission
|
||||
|
||||
# Check the attachment was added, and that it is a JPEG from the original PNG
|
||||
notification_submission_object = json.loads(notification_submission)
|
||||
assert notification_submission_object['attachments'][0]['filename'] == 'last-screenshot.jpg'
|
||||
assert len(notification_submission_object['attachments'][0]['base64'])
|
||||
assert notification_submission_object['attachments'][0]['mimetype'] == 'image/jpeg'
|
||||
jpeg_in_attachment = base64.b64decode(notification_submission_object['attachments'][0]['base64'])
|
||||
assert b'JFIF' in jpeg_in_attachment
|
||||
assert testimage_png not in notification_submission
|
||||
# Assert that the JPEG is readable (didn't get chewed up somewhere)
|
||||
from PIL import Image
|
||||
import io
|
||||
assert Image.open(io.BytesIO(jpeg_in_attachment))
|
||||
|
||||
if env_base_url:
|
||||
# Re #65 - did we see our BASE_URl ?
|
||||
logging.debug (">>> BASE_URL checking in notification: %s", env_base_url)
|
||||
@@ -159,6 +207,30 @@ def test_check_notification(client, live_server):
|
||||
# be sure we see it in the output log
|
||||
assert b'New ChangeDetection.io Notification - ' + test_url.encode('utf-8') in res.data
|
||||
|
||||
set_original_response()
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={
|
||||
"url": test_url,
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
"notification_urls": '',
|
||||
"notification_title": '',
|
||||
"notification_body": '',
|
||||
"notification_format": default_notification_format,
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
|
||||
time.sleep(2)
|
||||
|
||||
# Verify what was sent as a notification, this file should exist
|
||||
with open("test-datastore/notification.txt", "r") as f:
|
||||
notification_submission = f.read()
|
||||
assert "fallback-title" in notification_submission
|
||||
assert "fallback-body" in notification_submission
|
||||
|
||||
# cleanup for the next
|
||||
client.get(
|
||||
url_for("form_delete", uuid="all"),
|
||||
@@ -181,20 +253,20 @@ def test_notification_validation(client, live_server):
|
||||
assert b"Watch added" in res.data
|
||||
|
||||
# Re #360 some validation
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"notification_urls": 'json://localhost/foobar',
|
||||
"notification_title": "",
|
||||
"notification_body": "",
|
||||
"notification_format": "Text",
|
||||
"url": test_url,
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
"headers": "",
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Notification Body and Title is required when a Notification URL is used" in res.data
|
||||
# res = client.post(
|
||||
# url_for("edit_page", uuid="first"),
|
||||
# data={"notification_urls": 'json://localhost/foobar',
|
||||
# "notification_title": "",
|
||||
# "notification_body": "",
|
||||
# "notification_format": "Text",
|
||||
# "url": test_url,
|
||||
# "tag": "my tag",
|
||||
# "title": "my title",
|
||||
# "headers": "",
|
||||
# "fetch_backend": "html_requests"},
|
||||
# follow_redirects=True
|
||||
# )
|
||||
# assert b"Notification Body and Title is required when a Notification URL is used" in res.data
|
||||
|
||||
# Now adding a wrong token should give us an error
|
||||
res = client.post(
|
||||
@@ -217,81 +289,4 @@ def test_notification_validation(client, live_server):
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# Check that the default VS watch specific notification is hit
|
||||
def test_check_notification_use_default(client, live_server):
|
||||
set_original_response()
|
||||
notification_url = url_for('test_notification_endpoint', _external=True).replace('http', 'json')
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
|
||||
res = client.post(
|
||||
url_for("form_quick_watch_add"),
|
||||
data={"url": test_url, "tag": ''},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Watch added" in res.data
|
||||
|
||||
## Setup the local one and enable it
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"notification_urls": notification_url,
|
||||
"notification_title": "watch-notification",
|
||||
"notification_body": "watch-body",
|
||||
'notification_use_default': "True",
|
||||
"notification_format": "Text",
|
||||
"url": test_url,
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
"headers": "",
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
res = client.post(
|
||||
url_for("settings_page"),
|
||||
data={"application-notification_title": "global-notifications-title",
|
||||
"application-notification_body": "global-notifications-body\n",
|
||||
"application-notification_format": "Text",
|
||||
"application-notification_urls": notification_url,
|
||||
"requests-time_between_check-minutes": 180,
|
||||
"fetch_backend": "html_requests"
|
||||
},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
# A change should by default trigger a notification of the global-notifications
|
||||
time.sleep(1)
|
||||
set_modified_response()
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(2)
|
||||
with open("test-datastore/notification.txt", "r") as f:
|
||||
assert 'global-notifications-title' in f.read()
|
||||
|
||||
## Setup the local one and enable it
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"notification_urls": notification_url,
|
||||
"notification_title": "watch-notification",
|
||||
"notification_body": "watch-body",
|
||||
# No 'notification_use_default' here, so it's effectively False/off = "dont use default, use this one"
|
||||
"notification_format": "Text",
|
||||
"url": test_url,
|
||||
"tag": "my tag",
|
||||
"title": "my title",
|
||||
"headers": "",
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
set_original_response()
|
||||
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
time.sleep(2)
|
||||
assert os.path.isfile("test-datastore/notification.txt")
|
||||
with open("test-datastore/notification.txt", "r") as f:
|
||||
assert 'watch-notification' in f.read()
|
||||
|
||||
|
||||
# cleanup for the next
|
||||
client.get(
|
||||
url_for("form_delete", uuid="all"),
|
||||
follow_redirects=True
|
||||
)
|
||||
@@ -14,7 +14,7 @@ def test_share_watch(client, live_server):
|
||||
live_server_setup(live_server)
|
||||
|
||||
test_url = url_for('test_endpoint', _external=True)
|
||||
css_filter = ".nice-filter"
|
||||
include_filters = ".nice-filter"
|
||||
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
@@ -29,7 +29,7 @@ def test_share_watch(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": css_filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": include_filters, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
@@ -37,7 +37,7 @@ def test_share_watch(client, live_server):
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert bytes(css_filter.encode('utf-8')) in res.data
|
||||
assert bytes(include_filters.encode('utf-8')) in res.data
|
||||
|
||||
# click share the link
|
||||
res = client.get(
|
||||
@@ -73,4 +73,8 @@ def test_share_watch(client, live_server):
|
||||
res = client.get(
|
||||
url_for("edit_page", uuid="first"),
|
||||
)
|
||||
assert bytes(css_filter.encode('utf-8')) in res.data
|
||||
assert bytes(include_filters.encode('utf-8')) in res.data
|
||||
|
||||
# Check it saved the URL
|
||||
res = client.get(url_for("index"))
|
||||
assert bytes(test_url.encode('utf-8')) in res.data
|
||||
|
||||
@@ -57,10 +57,9 @@ def test_check_basic_change_detection_functionality_source(client, live_server):
|
||||
|
||||
|
||||
|
||||
|
||||
# `subtractive_selectors` should still work in `source:` type requests
|
||||
def test_check_ignore_elements(client, live_server):
|
||||
set_original_response()
|
||||
|
||||
time.sleep(2)
|
||||
test_url = 'source:'+url_for('test_endpoint', _external=True)
|
||||
# Add our URL to the import page
|
||||
@@ -77,9 +76,9 @@ def test_check_ignore_elements(client, live_server):
|
||||
#####################
|
||||
# We want <span> and <p> ONLY, but ignore span with .foobar-detection
|
||||
|
||||
res = client.post(
|
||||
client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": 'span,p', "url": test_url, "tag": "", "subtractive_selectors": ".foobar-detection", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": 'span,p', "url": test_url, "tag": "", "subtractive_selectors": ".foobar-detection", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -89,7 +88,6 @@ def test_check_ignore_elements(client, live_server):
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
assert b'foobar-detection' not in res.data
|
||||
assert b'<br' not in res.data
|
||||
assert b'<p' in res.data
|
||||
@@ -49,7 +49,7 @@ def test_trigger_regex_functionality_with_filter(client, live_server):
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"trigger_text": "/cool.stuff/",
|
||||
"url": test_url,
|
||||
"css_filter": '#in-here',
|
||||
"include_filters": '#in-here',
|
||||
"fetch_backend": "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
@@ -22,7 +22,7 @@ def test_check_watch_field_storage(client, live_server):
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={ "notification_urls": "json://127.0.0.1:30000\r\njson://128.0.0.1\r\n",
|
||||
"time_between_check-minutes": 126,
|
||||
"css_filter" : ".fooclass",
|
||||
"include_filters" : ".fooclass",
|
||||
"title" : "My title",
|
||||
"ignore_text" : "ignore this",
|
||||
"url": test_url,
|
||||
|
||||
@@ -89,7 +89,7 @@ def test_check_xpath_filter_utf8(client, live_server):
|
||||
time.sleep(1)
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
@@ -143,7 +143,7 @@ def test_check_xpath_text_function_utf8(client, live_server):
|
||||
time.sleep(1)
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
@@ -182,9 +182,6 @@ def test_check_markup_xpath_filter_restriction(client, live_server):
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
|
||||
# Trigger a check
|
||||
client.get(url_for("form_watch_checknow"), follow_redirects=True)
|
||||
|
||||
# Give the thread time to pick it up
|
||||
time.sleep(sleep_time_for_fetch_thread)
|
||||
|
||||
@@ -192,7 +189,7 @@ def test_check_markup_xpath_filter_restriction(client, live_server):
|
||||
# Add our URL to the import page
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": xpath_filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": xpath_filter, "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"Updated watch." in res.data
|
||||
@@ -230,10 +227,11 @@ def test_xpath_validation(client, live_server):
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"1 Imported" in res.data
|
||||
time.sleep(2)
|
||||
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": "/something horrible", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": "/something horrible", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"is not a valid XPath expression" in res.data
|
||||
@@ -242,7 +240,7 @@ def test_xpath_validation(client, live_server):
|
||||
|
||||
|
||||
# actually only really used by the distll.io importer, but could be handy too
|
||||
def test_check_with_prefix_css_filter(client, live_server):
|
||||
def test_check_with_prefix_include_filters(client, live_server):
|
||||
res = client.get(url_for("form_delete", uuid="all"), follow_redirects=True)
|
||||
assert b'Deleted' in res.data
|
||||
|
||||
@@ -263,7 +261,7 @@ def test_check_with_prefix_css_filter(client, live_server):
|
||||
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first"),
|
||||
data={"css_filter": "xpath://*[contains(@class, 'sametext')]", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
data={"include_filters": "xpath://*[contains(@class, 'sametext')]", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_requests"},
|
||||
follow_redirects=True
|
||||
)
|
||||
|
||||
|
||||
@@ -86,6 +86,7 @@ def extract_UUID_from_client(client):
|
||||
def wait_for_all_checks(client):
|
||||
# Loop waiting until done..
|
||||
attempt=0
|
||||
time.sleep(0.1)
|
||||
while attempt < 60:
|
||||
time.sleep(1)
|
||||
res = client.get(url_for("index"))
|
||||
@@ -159,5 +160,10 @@ def live_server_setup(live_server):
|
||||
ret = " ".join([auth.username, auth.password, auth.type])
|
||||
return ret
|
||||
|
||||
# Just return some GET var
|
||||
@live_server.app.route('/test-return-query', methods=['GET'])
|
||||
def test_return_query():
|
||||
return request.query_string
|
||||
|
||||
live_server.start()
|
||||
|
||||
|
||||
@@ -10,12 +10,13 @@ def test_visual_selector_content_ready(client, live_server):
|
||||
import json
|
||||
|
||||
assert os.getenv('PLAYWRIGHT_DRIVER_URL'), "Needs PLAYWRIGHT_DRIVER_URL set for this test"
|
||||
live_server_setup(live_server)
|
||||
time.sleep(1)
|
||||
live_server_setup(live_server)
|
||||
|
||||
|
||||
# Add our URL to the import page, because the docker container (playwright/selenium) wont be able to connect to our usual test url
|
||||
test_url = "https://changedetection.io/ci-test/test-runjs.html"
|
||||
|
||||
# Add our URL to the import page, maybe better to use something we control?
|
||||
# We use an external URL because the docker container is too difficult to setup to connect back to the pytest socket
|
||||
test_url = 'https://news.ycombinator.com'
|
||||
res = client.post(
|
||||
url_for("form_quick_watch_add"),
|
||||
data={"url": test_url, "tag": '', 'edit_and_watch_submit_button': 'Edit > Watch'},
|
||||
@@ -25,13 +26,26 @@ def test_visual_selector_content_ready(client, live_server):
|
||||
|
||||
res = client.post(
|
||||
url_for("edit_page", uuid="first", unpause_on_save=1),
|
||||
data={"css_filter": ".does-not-exist", "url": test_url, "tag": "", "headers": "", 'fetch_backend': "html_webdriver"},
|
||||
data={
|
||||
"url": test_url,
|
||||
"tag": "",
|
||||
"headers": "",
|
||||
'fetch_backend': "html_webdriver",
|
||||
'webdriver_js_execute_code': 'document.querySelector("button[name=test-button]").click();'
|
||||
},
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b"unpaused" in res.data
|
||||
time.sleep(1)
|
||||
wait_for_all_checks(client)
|
||||
uuid = extract_UUID_from_client(client)
|
||||
|
||||
# Check the JS execute code before extract worked
|
||||
res = client.get(
|
||||
url_for("preview_page", uuid="first"),
|
||||
follow_redirects=True
|
||||
)
|
||||
assert b'I smell JavaScript' in res.data
|
||||
|
||||
assert os.path.isfile(os.path.join('test-datastore', uuid, 'last-screenshot.png')), "last-screenshot.png should exist"
|
||||
assert os.path.isfile(os.path.join('test-datastore', uuid, 'elements.json')), "xpath elements.json data should exist"
|
||||
|
||||
|
||||
@@ -4,18 +4,21 @@ import queue
|
||||
import time
|
||||
|
||||
from changedetectionio import content_fetcher
|
||||
from changedetectionio.html_tools import FilterNotFoundInResponse
|
||||
from changedetectionio.fetch_site_status import FilterNotFoundInResponse
|
||||
|
||||
# A single update worker
|
||||
#
|
||||
# Requests for checking on a single site(watch) from a queue of watches
|
||||
# (another process inserts watches into the queue that are time-ready for checking)
|
||||
|
||||
import logging
|
||||
import sys
|
||||
|
||||
class update_worker(threading.Thread):
|
||||
current_uuid = None
|
||||
|
||||
def __init__(self, q, notification_q, app, datastore, *args, **kwargs):
|
||||
logging.basicConfig(stream=sys.stderr, level=logging.DEBUG)
|
||||
self.q = q
|
||||
self.app = app
|
||||
self.notification_q = notification_q
|
||||
@@ -26,6 +29,10 @@ class update_worker(threading.Thread):
|
||||
|
||||
from changedetectionio import diff
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_format_for_watch
|
||||
)
|
||||
|
||||
n_object = {}
|
||||
watch = self.datastore.data['watching'].get(watch_uuid, False)
|
||||
if not watch:
|
||||
@@ -40,45 +47,42 @@ class update_worker(threading.Thread):
|
||||
"History index had 2 or more, but only 1 date loaded, timestamps were not unique? maybe two of the same timestamps got written, needs more delay?"
|
||||
)
|
||||
|
||||
# Did it have any notification alerts to hit?
|
||||
if not watch.get('notification_use_default') and len(watch['notification_urls']):
|
||||
print(">>> Notifications queued for UUID from watch {}".format(watch_uuid))
|
||||
n_object['notification_urls'] = watch['notification_urls']
|
||||
n_object['notification_title'] = watch['notification_title']
|
||||
n_object['notification_body'] = watch['notification_body']
|
||||
n_object['notification_format'] = watch['notification_format']
|
||||
n_object['notification_urls'] = watch['notification_urls'] if len(watch['notification_urls']) else \
|
||||
self.datastore.data['settings']['application']['notification_urls']
|
||||
|
||||
n_object['notification_title'] = watch['notification_title'] if watch['notification_title'] else \
|
||||
self.datastore.data['settings']['application']['notification_title']
|
||||
|
||||
n_object['notification_body'] = watch['notification_body'] if watch['notification_body'] else \
|
||||
self.datastore.data['settings']['application']['notification_body']
|
||||
|
||||
n_object['notification_format'] = watch['notification_format'] if watch['notification_format'] != default_notification_format_for_watch else \
|
||||
self.datastore.data['settings']['application']['notification_format']
|
||||
|
||||
# No? maybe theres a global setting, queue them all
|
||||
elif watch.get('notification_use_default') and len(self.datastore.data['settings']['application']['notification_urls']):
|
||||
print(">>> Watch notification URLs were empty, using GLOBAL notifications for UUID: {}".format(watch_uuid))
|
||||
n_object['notification_urls'] = self.datastore.data['settings']['application']['notification_urls']
|
||||
n_object['notification_title'] = self.datastore.data['settings']['application']['notification_title']
|
||||
n_object['notification_body'] = self.datastore.data['settings']['application']['notification_body']
|
||||
n_object['notification_format'] = self.datastore.data['settings']['application']['notification_format']
|
||||
else:
|
||||
print(">>> NO notifications queued, watch and global notification URLs were empty.")
|
||||
|
||||
# Only prepare to notify if the rules above matched
|
||||
if 'notification_urls' in n_object:
|
||||
if 'notification_urls' in n_object and n_object['notification_urls']:
|
||||
# HTML needs linebreak, but MarkDown and Text can use a linefeed
|
||||
if n_object['notification_format'] == 'HTML':
|
||||
line_feed_sep = "</br>"
|
||||
else:
|
||||
line_feed_sep = "\n"
|
||||
|
||||
snapshot_contents = ''
|
||||
with open(watch_history[dates[-1]], 'rb') as f:
|
||||
snapshot_contents = f.read()
|
||||
|
||||
n_object.update({
|
||||
'watch_url': watch['url'],
|
||||
'uuid': watch_uuid,
|
||||
'screenshot': watch.get_screenshot_as_jpeg() if watch.get('notification_screenshot') else None,
|
||||
'current_snapshot': snapshot_contents.decode('utf-8'),
|
||||
'diff': diff.render_diff(watch_history[dates[-2]], watch_history[dates[-1]], line_feed_sep=line_feed_sep),
|
||||
'diff_full': diff.render_diff(watch_history[dates[-2]], watch_history[dates[-1]], True, line_feed_sep=line_feed_sep)
|
||||
})
|
||||
|
||||
logging.info (">> SENDING NOTIFICATION")
|
||||
self.notification_q.put(n_object)
|
||||
else:
|
||||
logging.info (">> NO Notification sent, notification_url was empty in both watch and system")
|
||||
|
||||
def send_filter_failure_notification(self, watch_uuid):
|
||||
|
||||
@@ -88,8 +92,8 @@ class update_worker(threading.Thread):
|
||||
return
|
||||
|
||||
n_object = {'notification_title': 'Changedetection.io - Alert - CSS/xPath filter was not present in the page',
|
||||
'notification_body': "Your configured CSS/xPath filter of '{}' for {{watch_url}} did not appear on the page after {} attempts, did the page change layout?\n\nLink: {{base_url}}/edit/{{watch_uuid}}\n\nThanks - Your omniscient changedetection.io installation :)\n".format(
|
||||
watch['css_filter'],
|
||||
'notification_body': "Your configured CSS/xPath filters of '{}' for {{watch_url}} did not appear on the page after {} attempts, did the page change layout?\n\nLink: {{base_url}}/edit/{{watch_uuid}}\n\nThanks - Your omniscient changedetection.io installation :)\n".format(
|
||||
", ".join(watch['include_filters']),
|
||||
threshold),
|
||||
'notification_format': 'text'}
|
||||
|
||||
@@ -99,6 +103,34 @@ class update_worker(threading.Thread):
|
||||
elif len(self.datastore.data['settings']['application']['notification_urls']):
|
||||
n_object['notification_urls'] = self.datastore.data['settings']['application']['notification_urls']
|
||||
|
||||
# Only prepare to notify if the rules above matched
|
||||
if 'notification_urls' in n_object:
|
||||
n_object.update({
|
||||
'watch_url': watch['url'],
|
||||
'uuid': watch_uuid,
|
||||
'screenshot': None
|
||||
})
|
||||
self.notification_q.put(n_object)
|
||||
print("Sent filter not found notification for {}".format(watch_uuid))
|
||||
|
||||
def send_step_failure_notification(self, watch_uuid, step_n):
|
||||
watch = self.datastore.data['watching'].get(watch_uuid, False)
|
||||
if not watch:
|
||||
return
|
||||
threshold = self.datastore.data['settings']['application'].get('filter_failure_notification_threshold_attempts')
|
||||
n_object = {'notification_title': "Changedetection.io - Alert - Browser step at position {} could not be run".format(step_n+1),
|
||||
'notification_body': "Your configured browser step at position {} for {{watch['url']}} "
|
||||
"did not appear on the page after {} attempts, did the page change layout? "
|
||||
"Does it need a delay added?\n\nLink: {{base_url}}/edit/{{watch_uuid}}\n\n"
|
||||
"Thanks - Your omniscient changedetection.io installation :)\n".format(step_n+1, threshold),
|
||||
'notification_format': 'text'}
|
||||
|
||||
if len(watch['notification_urls']):
|
||||
n_object['notification_urls'] = watch['notification_urls']
|
||||
|
||||
elif len(self.datastore.data['settings']['application']['notification_urls']):
|
||||
n_object['notification_urls'] = self.datastore.data['settings']['application']['notification_urls']
|
||||
|
||||
# Only prepare to notify if the rules above matched
|
||||
if 'notification_urls' in n_object:
|
||||
n_object.update({
|
||||
@@ -106,7 +138,8 @@ class update_worker(threading.Thread):
|
||||
'uuid': watch_uuid
|
||||
})
|
||||
self.notification_q.put(n_object)
|
||||
print("Sent filter not found notification for {}".format(watch_uuid))
|
||||
print("Sent step not found notification for {}".format(watch_uuid))
|
||||
|
||||
|
||||
def cleanup_error_artifacts(self, uuid):
|
||||
# All went fine, remove error artifacts
|
||||
@@ -183,7 +216,10 @@ class update_worker(threading.Thread):
|
||||
process_changedetection_results = False
|
||||
|
||||
except FilterNotFoundInResponse as e:
|
||||
err_text = "Warning, filter '{}' not found".format(str(e))
|
||||
if not self.datastore.data['watching'].get(uuid):
|
||||
continue
|
||||
|
||||
err_text = "Warning, no filters were found, no change detection ran."
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
# So that we get a trigger when the content is added again
|
||||
'previous_md5': ''})
|
||||
@@ -205,6 +241,32 @@ class update_worker(threading.Thread):
|
||||
|
||||
process_changedetection_results = True
|
||||
|
||||
except content_fetcher.BrowserStepsStepTimout as e:
|
||||
|
||||
if not self.datastore.data['watching'].get(uuid):
|
||||
continue
|
||||
|
||||
err_text = "Warning, browser step at position {} could not run, target not found, check the watch, add a delay if necessary.".format(e.step_n+1)
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': err_text,
|
||||
# So that we get a trigger when the content is added again
|
||||
'previous_md5': ''})
|
||||
|
||||
|
||||
if self.datastore.data['watching'][uuid].get('filter_failure_notification_send', False):
|
||||
c = self.datastore.data['watching'][uuid].get('consecutive_filter_failures', 5)
|
||||
c += 1
|
||||
# Send notification if we reached the threshold?
|
||||
threshold = self.datastore.data['settings']['application'].get('filter_failure_notification_threshold_attempts',
|
||||
0)
|
||||
print("Step for {} not found, consecutive_filter_failures: {}".format(uuid, c))
|
||||
if threshold > 0 and c >= threshold:
|
||||
if not self.datastore.data['watching'][uuid].get('notification_muted'):
|
||||
self.send_step_failure_notification(watch_uuid=uuid, step_n=e.step_n)
|
||||
c = 0
|
||||
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'consecutive_filter_failures': c})
|
||||
process_changedetection_results = False
|
||||
|
||||
except content_fetcher.EmptyReply as e:
|
||||
# Some kind of custom to-str handler in the exception handler that does this?
|
||||
err_text = "EmptyReply - try increasing 'Wait seconds before extracting text', Status Code {}".format(e.status_code)
|
||||
@@ -276,16 +338,19 @@ class update_worker(threading.Thread):
|
||||
self.app.logger.error("Exception reached processing watch UUID: %s - %s", uuid, str(e))
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'last_error': str(e)})
|
||||
|
||||
if self.datastore.data['watching'].get(uuid):
|
||||
# Always record that we atleast tried
|
||||
count = self.datastore.data['watching'][uuid].get('check_count', 0) + 1
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'fetch_time': round(time.time() - now, 3),
|
||||
'last_checked': round(time.time()),
|
||||
'check_count': count
|
||||
})
|
||||
|
||||
# Always record that we atleast tried
|
||||
self.datastore.update_watch(uuid=uuid, update_obj={'fetch_time': round(time.time() - now, 3),
|
||||
'last_checked': round(time.time())})
|
||||
|
||||
# Always save the screenshot if it's available
|
||||
if update_handler.screenshot:
|
||||
self.datastore.save_screenshot(watch_uuid=uuid, screenshot=update_handler.screenshot)
|
||||
if update_handler.xpath_data:
|
||||
self.datastore.save_xpath_data(watch_uuid=uuid, data=update_handler.xpath_data)
|
||||
# Always save the screenshot if it's available
|
||||
if update_handler.screenshot:
|
||||
self.datastore.save_screenshot(watch_uuid=uuid, screenshot=update_handler.screenshot)
|
||||
if update_handler.xpath_data:
|
||||
self.datastore.save_xpath_data(watch_uuid=uuid, data=update_handler.xpath_data)
|
||||
|
||||
|
||||
self.current_uuid = None # Done
|
||||
|
||||
@@ -6,6 +6,8 @@ services:
|
||||
hostname: changedetection
|
||||
volumes:
|
||||
- changedetection-data:/datastore
|
||||
# Configurable proxy list support, see https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#proxy-list-support
|
||||
# - ./proxies.json:/datastore/proxies.json
|
||||
|
||||
# environment:
|
||||
# Default listening port, can also be changed with the -p option
|
||||
@@ -30,7 +32,7 @@ services:
|
||||
#
|
||||
# https://playwright.dev/python/docs/api/class-browsertype#browser-type-launch-option-proxy
|
||||
#
|
||||
# Plain requsts - proxy support example.
|
||||
# Plain requests - proxy support example.
|
||||
# - HTTP_PROXY=socks5h://10.10.1.10:1080
|
||||
# - HTTPS_PROXY=socks5h://10.10.1.10:1080
|
||||
#
|
||||
@@ -43,6 +45,9 @@ services:
|
||||
# Respect proxy_pass type settings, `proxy_set_header Host "localhost";` and `proxy_set_header X-Forwarded-Prefix /app;`
|
||||
# More here https://github.com/dgtlmoon/changedetection.io/wiki/Running-changedetection.io-behind-a-reverse-proxy-sub-directory
|
||||
# - USE_X_SETTINGS=1
|
||||
#
|
||||
# Hides the `Referer` header so that monitored websites can't see the changedetection.io hostname.
|
||||
# - HIDE_REFERER=true
|
||||
|
||||
# Comment out ports: when using behind a reverse proxy , enable networks: etc.
|
||||
ports:
|
||||
|
||||
BIN
docs/browsersteps-anim.gif
Normal file
BIN
docs/browsersteps-anim.gif
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 301 KiB |
BIN
docs/proxy-example.jpg
Normal file
BIN
docs/proxy-example.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 46 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 238 KiB After Width: | Height: | Size: 428 KiB |
@@ -1,31 +1,36 @@
|
||||
flask~= 2.0
|
||||
flask~=2.0
|
||||
flask_wtf
|
||||
eventlet>=0.31.0
|
||||
validators
|
||||
timeago ~=1.0
|
||||
inscriptis ~= 2.2
|
||||
feedgen ~= 0.9
|
||||
flask-login ~= 0.5
|
||||
timeago~=1.0
|
||||
inscriptis~=2.2
|
||||
feedgen~=0.9
|
||||
flask-login~=0.5
|
||||
flask_restful
|
||||
pytz
|
||||
|
||||
# Set these versions together to avoid a RequestsDependencyWarning
|
||||
requests[socks] ~= 2.26
|
||||
urllib3 > 1.26
|
||||
chardet > 2.3.0
|
||||
# >= 2.26 also adds Brotli support if brotli is installed
|
||||
brotli~=1.0
|
||||
requests[socks] ~=2.28
|
||||
|
||||
wtforms ~= 3.0
|
||||
jsonpath-ng ~= 1.5.3
|
||||
urllib3>1.26
|
||||
chardet>2.3.0
|
||||
|
||||
wtforms~=3.0
|
||||
jsonpath-ng~=1.5.3
|
||||
|
||||
# jq not available on Windows so must be installed manually
|
||||
|
||||
# Notification library
|
||||
apprise ~= 1.0.0
|
||||
apprise~=1.2.0
|
||||
|
||||
# apprise mqtt https://github.com/dgtlmoon/changedetection.io/issues/315
|
||||
paho-mqtt
|
||||
|
||||
# Pinned version of cryptography otherwise
|
||||
# ERROR: Could not build wheels for cryptography which use PEP 517 and cannot be installed directly
|
||||
cryptography ~= 3.4
|
||||
cryptography~=3.4
|
||||
|
||||
# Used for CSS filtering
|
||||
bs4
|
||||
@@ -34,11 +39,24 @@ bs4
|
||||
lxml
|
||||
|
||||
# 3.141 was missing socksVersion, 3.150 was not in pypi, so we try 4.1.0
|
||||
selenium ~= 4.1.0
|
||||
selenium~=4.1.0
|
||||
|
||||
# https://stackoverflow.com/questions/71652965/importerror-cannot-import-name-safe-str-cmp-from-werkzeug-security/71653849#71653849
|
||||
# ImportError: cannot import name 'safe_str_cmp' from 'werkzeug.security'
|
||||
# need to revisit flask login versions
|
||||
werkzeug ~= 2.0.0
|
||||
werkzeug~=2.0.0
|
||||
|
||||
# Templating, so far just in the URLs but in the future can be for the notifications also
|
||||
jinja2~=3.1
|
||||
jinja2-time
|
||||
|
||||
# https://peps.python.org/pep-0508/#environment-markers
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1009
|
||||
jq~=1.3 ;python_version >= "3.8" and sys_platform == "linux"
|
||||
|
||||
# Any current modern version, required so far for screenshot PNG->JPEG conversion but will be used more in the future
|
||||
pillow
|
||||
# playwright is installed at Dockerfile build time because it's not available on all platforms
|
||||
|
||||
# For shutting down playwright BrowserSteps nicely
|
||||
psutil
|
||||
Reference in New Issue
Block a user