Compare commits
1 Commits
skip-empty
...
scrub-simp
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e1b4055330 |
@@ -1,18 +1,2 @@
|
||||
.git
|
||||
.github
|
||||
changedetectionio/processors/__pycache__
|
||||
changedetectionio/api/__pycache__
|
||||
changedetectionio/model/__pycache__
|
||||
changedetectionio/blueprint/price_data_follower/__pycache__
|
||||
changedetectionio/blueprint/tags/__pycache__
|
||||
changedetectionio/blueprint/__pycache__
|
||||
changedetectionio/blueprint/browser_steps/__pycache__
|
||||
changedetectionio/fetchers/__pycache__
|
||||
changedetectionio/tests/visualselector/__pycache__
|
||||
changedetectionio/tests/restock/__pycache__
|
||||
changedetectionio/tests/__pycache__
|
||||
changedetectionio/tests/fetchers/__pycache__
|
||||
changedetectionio/tests/unit/__pycache__
|
||||
changedetectionio/tests/proxy_list/__pycache__
|
||||
changedetectionio/__pycache__
|
||||
|
||||
|
||||
25
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -1,42 +1,25 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Create a bug report, if you don't follow this template, your report will be DELETED
|
||||
about: Create a report to help us improve
|
||||
title: ''
|
||||
labels: 'triage'
|
||||
assignees: 'dgtlmoon'
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**DO NOT USE THIS FORM TO REPORT THAT A PARTICULAR WEBSITE IS NOT SCRAPING/WATCHING AS EXPECTED**
|
||||
|
||||
This form is only for direct bugs and feature requests todo directly with the software.
|
||||
|
||||
Please report watched websites (full URL and _any_ settings) that do not work with changedetection.io as expected [**IN THE DISCUSSION FORUMS**](https://github.com/dgtlmoon/changedetection.io/discussions) or your report will be deleted
|
||||
|
||||
CONSIDER TAKING OUT A SUBSCRIPTION FOR A SMALL PRICE PER MONTH, YOU GET THE BENEFIT OF USING OUR PAID PROXIES AND FURTHERING THE DEVELOPMENT OF CHANGEDETECTION.IO
|
||||
|
||||
THANK YOU
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**Describe the bug**
|
||||
A clear and concise description of what the bug is.
|
||||
|
||||
**Version**
|
||||
*Exact version* in the top right area: 0....
|
||||
In the top right area: 0....
|
||||
|
||||
**To Reproduce**
|
||||
|
||||
Steps to reproduce the behavior:
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
4. See error
|
||||
|
||||
! ALWAYS INCLUDE AN EXAMPLE URL WHERE IT IS POSSIBLE TO RE-CREATE THE ISSUE - USE THE 'SHARE WATCH' FEATURE AND PASTE IN THE SHARE-LINK!
|
||||
|
||||
**Expected behavior**
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
|
||||
4
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -1,8 +1,8 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for this project
|
||||
title: '[feature]'
|
||||
labels: 'enhancement'
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
10
.github/dependabot.yml
vendored
@@ -1,10 +0,0 @@
|
||||
version: 2
|
||||
updates:
|
||||
- package-ecosystem: github-actions
|
||||
directory: /
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
groups:
|
||||
all:
|
||||
patterns:
|
||||
- "*"
|
||||
31
.github/test/Dockerfile-alpine
vendored
@@ -1,31 +0,0 @@
|
||||
# Taken from https://github.com/linuxserver/docker-changedetection.io/blob/main/Dockerfile
|
||||
# Test that we can still build on Alpine (musl modified libc https://musl.libc.org/)
|
||||
# Some packages wont install via pypi because they dont have a wheel available under this architecture.
|
||||
|
||||
FROM ghcr.io/linuxserver/baseimage-alpine:3.18
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
|
||||
COPY requirements.txt /requirements.txt
|
||||
|
||||
RUN \
|
||||
apk add --update --no-cache --virtual=build-dependencies \
|
||||
cargo \
|
||||
g++ \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libxslt-dev \
|
||||
make \
|
||||
openssl-dev \
|
||||
py3-wheel \
|
||||
python3-dev \
|
||||
zlib-dev && \
|
||||
apk add --update --no-cache \
|
||||
libxslt \
|
||||
python3 \
|
||||
py3-pip && \
|
||||
echo "**** pip3 install test of changedetection.io ****" && \
|
||||
pip3 install -U pip wheel setuptools && \
|
||||
pip3 install -U --no-cache-dir --find-links https://wheel-index.linuxserver.io/alpine-3.18/ -r /requirements.txt && \
|
||||
apk del --purge \
|
||||
build-dependencies
|
||||
8
.github/workflows/codeql-analysis.yml
vendored
@@ -30,11 +30,11 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@v2
|
||||
|
||||
# Initializes the CodeQL tools for scanning.
|
||||
- name: Initialize CodeQL
|
||||
uses: github/codeql-action/init@v3
|
||||
uses: github/codeql-action/init@v1
|
||||
with:
|
||||
languages: ${{ matrix.language }}
|
||||
# If you wish to specify custom queries, you can do so here or in a config file.
|
||||
@@ -45,7 +45,7 @@ jobs:
|
||||
# Autobuild attempts to build any compiled languages (C/C++, C#, or Java).
|
||||
# If this step fails, then you should remove it and run the build manually (see below)
|
||||
- name: Autobuild
|
||||
uses: github/codeql-action/autobuild@v3
|
||||
uses: github/codeql-action/autobuild@v1
|
||||
|
||||
# ℹ️ Command-line programs to run using the OS shell.
|
||||
# 📚 https://git.io/JvXDl
|
||||
@@ -59,4 +59,4 @@ jobs:
|
||||
# make release
|
||||
|
||||
- name: Perform CodeQL Analysis
|
||||
uses: github/codeql-action/analyze@v3
|
||||
uses: github/codeql-action/analyze@v1
|
||||
|
||||
60
.github/workflows/containers.yml
vendored
@@ -39,17 +39,18 @@ jobs:
|
||||
# Or if we are in a tagged release scenario.
|
||||
if: ${{ github.event.workflow_run.conclusion == 'success' }} || ${{ github.event.release.tag_name }} != ''
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.11
|
||||
uses: actions/setup-python@v5
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.11
|
||||
python-version: 3.9
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install flake8 pytest
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
|
||||
- name: Create release metadata
|
||||
run: |
|
||||
@@ -58,70 +59,71 @@ jobs:
|
||||
echo ${{ github.ref }} > changedetectionio/tag.txt
|
||||
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v3
|
||||
uses: docker/setup-qemu-action@v1
|
||||
with:
|
||||
image: tonistiigi/binfmt:latest
|
||||
platforms: all
|
||||
|
||||
- name: Login to GitHub Container Registry
|
||||
uses: docker/login-action@v3
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.actor }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Login to Docker Hub Container Registry
|
||||
uses: docker/login-action@v3
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_HUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_HUB_ACCESS_TOKEN }}
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
id: buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
uses: docker/setup-buildx-action@v1
|
||||
with:
|
||||
install: true
|
||||
version: latest
|
||||
driver-opts: image=moby/buildkit:master
|
||||
|
||||
# master branch -> :dev container tag
|
||||
- name: Build and push :dev
|
||||
# master always builds :latest
|
||||
- name: Build and push :latest
|
||||
id: docker_build
|
||||
if: ${{ github.ref }} == "refs/heads/master"
|
||||
uses: docker/build-push-action@v5
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: ./
|
||||
file: ./Dockerfile
|
||||
push: true
|
||||
tags: |
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:dev,ghcr.io/${{ github.repository }}:dev
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7,linux/arm/v8
|
||||
cache-from: type=gha
|
||||
cache-to: type=gha,mode=max
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest,ghcr.io/${{ github.repository }}:latest
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
# Looks like this was disabled
|
||||
# provenance: false
|
||||
|
||||
# A new tagged release is required, which builds :tag and :latest
|
||||
# A new tagged release is required, which builds :tag
|
||||
- name: Build and push :tag
|
||||
id: docker_build_tag_release
|
||||
if: github.event_name == 'release' && startsWith(github.event.release.tag_name, '0.')
|
||||
uses: docker/build-push-action@v5
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
context: ./
|
||||
file: ./Dockerfile
|
||||
push: true
|
||||
tags: |
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:${{ github.event.release.tag_name }}
|
||||
ghcr.io/dgtlmoon/changedetection.io:${{ github.event.release.tag_name }}
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:latest
|
||||
ghcr.io/dgtlmoon/changedetection.io:latest
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7,linux/arm/v8
|
||||
cache-from: type=gha
|
||||
cache-to: type=gha,mode=max
|
||||
# Looks like this was disabled
|
||||
# provenance: false
|
||||
${{ secrets.DOCKER_HUB_USERNAME }}/changedetection.io:${{ github.event.release.tag_name }},ghcr.io/dgtlmoon/changedetection.io:${{ github.event.release.tag_name }}
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
- name: Image digest
|
||||
run: echo step SHA ${{ steps.vars.outputs.sha_short }} tag ${{steps.vars.outputs.tag}} branch ${{steps.vars.outputs.branch}} digest ${{ steps.docker_build.outputs.digest }}
|
||||
|
||||
- name: Cache Docker layers
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: /tmp/.buildx-cache
|
||||
key: ${{ runner.os }}-buildx-${{ github.sha }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-buildx-
|
||||
|
||||
|
||||
|
||||
72
.github/workflows/pypi-release.yml
vendored
@@ -1,72 +0,0 @@
|
||||
name: Publish Python 🐍distribution 📦 to PyPI and TestPyPI
|
||||
|
||||
on: push
|
||||
jobs:
|
||||
build:
|
||||
name: Build distribution 📦
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.x"
|
||||
- name: Install pypa/build
|
||||
run: >-
|
||||
python3 -m
|
||||
pip install
|
||||
build
|
||||
--user
|
||||
- name: Build a binary wheel and a source tarball
|
||||
run: python3 -m build
|
||||
- name: Store the distribution packages
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
|
||||
|
||||
test-pypi-package:
|
||||
name: Test the built 📦 package works basically.
|
||||
runs-on: ubuntu-latest
|
||||
needs:
|
||||
- build
|
||||
steps:
|
||||
- name: Download all the dists
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
- name: Test that the basic pip built package runs without error
|
||||
run: |
|
||||
set -e
|
||||
pip3 install dist/changedetection.io*.whl
|
||||
changedetection.io -d /tmp -p 10000 &
|
||||
sleep 3
|
||||
curl http://127.0.0.1:10000/static/styles/pure-min.css >/dev/null
|
||||
curl http://127.0.0.1:10000/ >/dev/null
|
||||
killall changedetection.io
|
||||
|
||||
|
||||
publish-to-pypi:
|
||||
name: >-
|
||||
Publish Python 🐍 distribution 📦 to PyPI
|
||||
if: startsWith(github.ref, 'refs/tags/') # only publish to PyPI on tag pushes
|
||||
needs:
|
||||
- test-pypi-package
|
||||
runs-on: ubuntu-latest
|
||||
environment:
|
||||
name: release
|
||||
url: https://pypi.org/p/changedetection.io
|
||||
permissions:
|
||||
id-token: write # IMPORTANT: mandatory for trusted publishing
|
||||
|
||||
steps:
|
||||
- name: Download all the dists
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: python-package-distributions
|
||||
path: dist/
|
||||
- name: Publish distribution 📦 to PyPI
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
44
.github/workflows/pypi.yml
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
name: PyPi Test and Push tagged release
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
on:
|
||||
workflow_run:
|
||||
workflows: ["ChangeDetection.io Test"]
|
||||
tags: '*.*'
|
||||
types: [completed]
|
||||
|
||||
|
||||
jobs:
|
||||
test-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# python -m pip install --upgrade pip
|
||||
# pip install flake8 pytest
|
||||
# if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
# if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
|
||||
- name: Test that pip builds without error
|
||||
run: |
|
||||
pip3 --version
|
||||
python3 -m pip install wheel
|
||||
python3 setup.py bdist_wheel
|
||||
python3 -m pip install dist/changedetection.io-*-none-any.whl --force
|
||||
changedetection.io -d /tmp -p 10000 &
|
||||
sleep 3
|
||||
curl http://127.0.0.1:10000/static/styles/pure-min.css >/dev/null
|
||||
killall -9 changedetection.io
|
||||
|
||||
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||
|
||||
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||
#if: ${{ github.event_name == 'release'}}
|
||||
68
.github/workflows/test-container-build.yml
vendored
@@ -1,68 +0,0 @@
|
||||
name: ChangeDetection.io Container Build Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
|
||||
# This line doesnt work, even tho it is the documented one
|
||||
#on: [push, pull_request]
|
||||
|
||||
on:
|
||||
push:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
- .github/workflows/*
|
||||
|
||||
pull_request:
|
||||
paths:
|
||||
- requirements.txt
|
||||
- Dockerfile
|
||||
- .github/workflows/*
|
||||
|
||||
# Changes to requirements.txt packages and Dockerfile may or may not always be compatible with arm etc, so worth testing
|
||||
# @todo: some kind of path filter for requirements.txt and Dockerfile
|
||||
jobs:
|
||||
test-container-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.11
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: 3.11
|
||||
|
||||
# Just test that the build works, some libraries won't compile on ARM/rPi etc
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v3
|
||||
with:
|
||||
image: tonistiigi/binfmt:latest
|
||||
platforms: all
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
id: buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
with:
|
||||
install: true
|
||||
version: latest
|
||||
driver-opts: image=moby/buildkit:master
|
||||
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067
|
||||
# Check we can still build under alpine/musl
|
||||
- name: Test that the docker containers can build (musl via alpine check)
|
||||
id: docker_build_musl
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./
|
||||
file: ./.github/test/Dockerfile-alpine
|
||||
platforms: linux/amd64,linux/arm64
|
||||
|
||||
- name: Test that the docker containers can build
|
||||
id: docker_build
|
||||
uses: docker/build-push-action@v5
|
||||
# https://github.com/docker/build-push-action#customizing
|
||||
with:
|
||||
context: ./
|
||||
file: ./Dockerfile
|
||||
platforms: linux/amd64,linux/arm64,linux/arm/v6,linux/arm/v7,linux/arm/v8
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
172
.github/workflows/test-only.yml
vendored
@@ -1,171 +1,45 @@
|
||||
name: ChangeDetection.io App Test
|
||||
name: ChangeDetection.io Test
|
||||
|
||||
# Triggers the workflow on push or pull request events
|
||||
on: [push, pull_request]
|
||||
|
||||
jobs:
|
||||
test-application:
|
||||
test-build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
# Mainly just for link/flake8
|
||||
- name: Set up Python 3.11
|
||||
uses: actions/setup-python@v5
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: '3.11'
|
||||
python-version: 3.9
|
||||
|
||||
- name: Show env vars
|
||||
run: set
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install flake8 pytest
|
||||
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
|
||||
if [ -f requirements-dev.txt ]; then pip install -r requirements-dev.txt; fi
|
||||
- name: Lint with flake8
|
||||
run: |
|
||||
pip3 install flake8
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
|
||||
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
||||
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
|
||||
|
||||
- name: Spin up ancillary testable services
|
||||
- name: Unit tests
|
||||
run: |
|
||||
|
||||
docker network create changedet-network
|
||||
python3 -m unittest changedetectionio.tests.unit.test_notification_diff
|
||||
|
||||
# Selenium+browserless
|
||||
docker run --network changedet-network -d --hostname selenium -p 4444:4444 --rm --shm-size="2g" selenium/standalone-chrome:4
|
||||
docker run --network changedet-network -d --name browserless --hostname browserless -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]" -e "DEFAULT_LAUNCH_ARGS=[\"--window-size=1920,1080\"]" --rm -p 3000:3000 --shm-size="2g" browserless/chrome:1.60-chrome-stable
|
||||
|
||||
# For accessing custom browser tests
|
||||
docker run --network changedet-network -d --name browserless-custom-url --hostname browserless-custom-url -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]" -e "DEFAULT_LAUNCH_ARGS=[\"--window-size=1920,1080\"]" --rm --shm-size="2g" browserless/chrome:1.60-chrome-stable
|
||||
|
||||
- name: Build changedetection.io container for testing
|
||||
run: |
|
||||
# Build a changedetection.io container and start testing inside
|
||||
docker build --build-arg LOGGER_LEVEL=TRACE -t test-changedetectionio .
|
||||
# Debug info
|
||||
docker run test-changedetectionio bash -c 'pip list'
|
||||
|
||||
- name: Spin up ancillary SMTP+Echo message test server
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
# Debug SMTP server/echo message back server
|
||||
docker run --network changedet-network -d -p 11025:11025 -p 11080:11080 --hostname mailserver test-changedetectionio bash -c 'python changedetectionio/tests/smtp/smtp-test-server.py'
|
||||
# Each test is totally isolated and performs its own cleanup/reset
|
||||
cd changedetectionio; ./run_all_tests.sh
|
||||
|
||||
- name: Test built container with pytest
|
||||
run: |
|
||||
# Unit tests
|
||||
echo "run test with unittest"
|
||||
docker run test-changedetectionio bash -c 'python3 -m unittest changedetectionio.tests.unit.test_notification_diff'
|
||||
docker run test-changedetectionio bash -c 'python3 -m unittest changedetectionio.tests.unit.test_watch_model'
|
||||
|
||||
# All tests
|
||||
echo "run test with pytest"
|
||||
# The default pytest logger_level is TRACE
|
||||
# To change logger_level for pytest(test/conftest.py),
|
||||
# append the docker option. e.g. '-e LOGGER_LEVEL=DEBUG'
|
||||
docker run --network changedet-network test-changedetectionio bash -c 'cd changedetectionio && ./run_basic_tests.sh'
|
||||
# https://github.com/docker/build-push-action/blob/master/docs/advanced/test-before-push.md ?
|
||||
# https://github.com/docker/buildx/issues/59 ? Needs to be one platform?
|
||||
|
||||
- name: Test built container selenium+browserless/playwright
|
||||
run: |
|
||||
|
||||
# Selenium fetch
|
||||
docker run --rm -e "WEBDRIVER_URL=http://selenium:4444/wd/hub" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py'
|
||||
|
||||
# Playwright/Browserless fetch
|
||||
docker run --rm -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py && pytest tests/visualselector/test_fetch_data.py'
|
||||
|
||||
# Settings headers playwright tests - Call back in from Browserless, check headers
|
||||
docker run --name "changedet" --hostname changedet --rm -e "FLASK_SERVER_NAME=changedet" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000?dumpio=true" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio; pytest --live-server-host=0.0.0.0 --live-server-port=5004 tests/test_request.py'
|
||||
docker run --name "changedet" --hostname changedet --rm -e "FLASK_SERVER_NAME=changedet" -e "WEBDRIVER_URL=http://selenium:4444/wd/hub" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio; pytest --live-server-host=0.0.0.0 --live-server-port=5004 tests/test_request.py'
|
||||
docker run --name "changedet" --hostname changedet --rm -e "FLASK_SERVER_NAME=changedet" -e "USE_EXPERIMENTAL_PUPPETEER_FETCH=yes" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000?dumpio=true" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio; pytest --live-server-host=0.0.0.0 --live-server-port=5004 tests/test_request.py'
|
||||
|
||||
# restock detection via playwright - added name=changedet here so that playwright/browserless can connect to it
|
||||
docker run --rm --name "changedet" -e "FLASK_SERVER_NAME=changedet" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest --live-server-port=5004 --live-server-host=0.0.0.0 tests/restock/test_restock.py'
|
||||
|
||||
- name: Test SMTP notification mime types
|
||||
run: |
|
||||
# SMTP content types - needs the 'Debug SMTP server/echo message back server' container from above
|
||||
docker run --rm --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/smtp/test_notification_smtp.py'
|
||||
|
||||
- name: Test with puppeteer fetcher and disk cache
|
||||
run: |
|
||||
docker run --rm -e "PUPPETEER_DISK_CACHE=/tmp/data/" -e "USE_EXPERIMENTAL_PUPPETEER_FETCH=yes" -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/fetchers/test_content.py && pytest tests/test_errorhandling.py && pytest tests/visualselector/test_fetch_data.py'
|
||||
# Browserless would have had -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]" added above
|
||||
|
||||
- name: Test proxy interaction
|
||||
run: |
|
||||
cd changedetectionio
|
||||
./run_proxy_tests.sh
|
||||
# And again with PLAYWRIGHT_DRIVER_URL=..
|
||||
cd ..
|
||||
|
||||
- name: Test custom browser URL
|
||||
run: |
|
||||
cd changedetectionio
|
||||
./run_custom_browser_url_tests.sh
|
||||
cd ..
|
||||
|
||||
- name: Test changedetection.io container starts+runs basically without error
|
||||
run: |
|
||||
docker run --name test-changedetectionio -p 5556:5000 -d test-changedetectionio
|
||||
sleep 3
|
||||
# Should return 0 (no error) when grep finds it
|
||||
curl -s http://localhost:5556 |grep -q checkbox-uuid
|
||||
|
||||
# and IPv6
|
||||
curl -s -g -6 "http://[::1]:5556"|grep -q checkbox-uuid
|
||||
|
||||
# Check whether TRACE log is enabled.
|
||||
# Also, check whether TRACE is came from STDERR
|
||||
docker logs test-changedetectionio 2>&1 1>/dev/null | grep 'TRACE log is enabled' || exit 1
|
||||
# Check whether DEBUG is came from STDOUT
|
||||
docker logs test-changedetectionio 2>/dev/null | grep 'DEBUG' || exit 1
|
||||
|
||||
docker kill test-changedetectionio
|
||||
|
||||
- name: Test changedetection.io SIGTERM and SIGINT signal shutdown
|
||||
run: |
|
||||
|
||||
echo SIGINT Shutdown request test
|
||||
docker run --name sig-test -d test-changedetectionio
|
||||
sleep 3
|
||||
echo ">>> Sending SIGINT to sig-test container"
|
||||
docker kill --signal=SIGINT sig-test
|
||||
sleep 3
|
||||
# invert the check (it should be not 0/not running)
|
||||
docker ps
|
||||
# check signal catch(STDERR) log. Because of
|
||||
# changedetectionio/__init__.py: logger.add(sys.stderr, level=logger_level)
|
||||
docker logs sig-test 2>&1 | grep 'Shutdown: Got Signal - SIGINT' || exit 1
|
||||
test -z "`docker ps|grep sig-test`"
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Looks like container was running when it shouldnt be"
|
||||
docker ps
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# @todo - scan the container log to see the right "graceful shutdown" text exists
|
||||
docker rm sig-test
|
||||
|
||||
echo SIGTERM Shutdown request test
|
||||
docker run --name sig-test -d test-changedetectionio
|
||||
sleep 3
|
||||
echo ">>> Sending SIGTERM to sig-test container"
|
||||
docker kill --signal=SIGTERM sig-test
|
||||
sleep 3
|
||||
# invert the check (it should be not 0/not running)
|
||||
docker ps
|
||||
# check signal catch(STDERR) log. Because of
|
||||
# changedetectionio/__init__.py: logger.add(sys.stderr, level=logger_level)
|
||||
docker logs sig-test 2>&1 | grep 'Shutdown: Got Signal - SIGTERM' || exit 1
|
||||
test -z "`docker ps|grep sig-test`"
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Looks like container was running when it shouldnt be"
|
||||
docker ps
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# @todo - scan the container log to see the right "graceful shutdown" text exists
|
||||
docker rm sig-test
|
||||
|
||||
#export WEBDRIVER_URL=http://localhost:4444/wd/hub
|
||||
#pytest tests/fetchers/test_content.py
|
||||
#pytest tests/test_errorhandling.py
|
||||
# https://github.com/docker/buildx/issues/495#issuecomment-918925854
|
||||
|
||||
2
.gitignore
vendored
@@ -8,7 +8,5 @@ __pycache__
|
||||
build
|
||||
dist
|
||||
venv
|
||||
test-datastore/*
|
||||
test-datastore
|
||||
*.egg-info*
|
||||
.vscode/settings.json
|
||||
|
||||
@@ -6,4 +6,10 @@ Otherwise, it's always best to PR into the `dev` branch.
|
||||
|
||||
Please be sure that all new functionality has a matching test!
|
||||
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notification.py` for example
|
||||
Use `pytest` to validate/test, you can run the existing tests as `pytest tests/test_notifications.py` for example
|
||||
|
||||
```
|
||||
pip3 install -r requirements-dev
|
||||
```
|
||||
|
||||
this is from https://github.com/dgtlmoon/changedetection.io/blob/master/requirements-dev.txt
|
||||
|
||||
52
Dockerfile
@@ -1,19 +1,17 @@
|
||||
# pip dependencies install stage
|
||||
FROM python:3.11-slim-bookworm as builder
|
||||
FROM python:3.8-slim as builder
|
||||
|
||||
# See `cryptography` pin comment in requirements.txt
|
||||
# rustc compiler would be needed on ARM type devices but theres an issue with some deps not building..
|
||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
g++ \
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libffi-dev \
|
||||
libjpeg-dev \
|
||||
libssl-dev \
|
||||
libxslt-dev \
|
||||
make \
|
||||
zlib1g-dev
|
||||
zlib1g-dev \
|
||||
g++
|
||||
|
||||
RUN mkdir /install
|
||||
WORKDIR /install
|
||||
@@ -22,22 +20,22 @@ COPY requirements.txt /requirements.txt
|
||||
|
||||
RUN pip install --target=/dependencies -r /requirements.txt
|
||||
|
||||
# Playwright is an alternative to Selenium
|
||||
# Excluded this package from requirements.txt to prevent arm/v6 and arm/v7 builds from failing
|
||||
# https://github.com/dgtlmoon/changedetection.io/pull/1067 also musl/alpine (not supported)
|
||||
RUN pip install --target=/dependencies playwright~=1.40 \
|
||||
|| echo "WARN: Failed to install Playwright. The application can still run, but the Playwright option will be disabled."
|
||||
|
||||
# Final image stage
|
||||
FROM python:3.11-slim-bookworm
|
||||
FROM python:3.8-slim
|
||||
|
||||
# Actual packages needed at runtime, usually due to the notification (apprise) backend
|
||||
# rustc compiler would be needed on ARM type devices but theres an issue with some deps not building..
|
||||
ARG CRYPTOGRAPHY_DONT_BUILD_RUST=1
|
||||
|
||||
# Re #93, #73, excluding rustc (adds another 430Mb~)
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
libxslt1.1 \
|
||||
# For pdftohtml
|
||||
poppler-utils \
|
||||
zlib1g \
|
||||
&& apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
libssl-dev \
|
||||
libffi-dev \
|
||||
gcc \
|
||||
libc-dev \
|
||||
libxslt-dev \
|
||||
zlib1g-dev \
|
||||
g++
|
||||
|
||||
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
@@ -53,17 +51,11 @@ ENV PYTHONPATH=/usr/local
|
||||
|
||||
EXPOSE 5000
|
||||
|
||||
# The actual flask app module
|
||||
# The actual flask app
|
||||
COPY changedetectionio /app/changedetectionio
|
||||
# Starting wrapper
|
||||
# The eventlet server wrapper
|
||||
COPY changedetection.py /app/changedetection.py
|
||||
|
||||
# Github Action test purpose(test-only.yml).
|
||||
# On production, it is effectively LOGGER_LEVEL=''.
|
||||
ARG LOGGER_LEVEL=''
|
||||
ENV LOGGER_LEVEL "$LOGGER_LEVEL"
|
||||
|
||||
WORKDIR /app
|
||||
CMD ["python", "./changedetection.py", "-d", "/datastore"]
|
||||
|
||||
|
||||
CMD [ "python", "./changedetection.py" , "-d", "/datastore"]
|
||||
|
||||
19
MANIFEST.in
@@ -1,21 +1,6 @@
|
||||
recursive-include changedetectionio/api *
|
||||
recursive-include changedetectionio/blueprint *
|
||||
recursive-include changedetectionio/model *
|
||||
recursive-include changedetectionio/processors *
|
||||
recursive-include changedetectionio/res *
|
||||
recursive-include changedetectionio/static *
|
||||
recursive-include changedetectionio/templates *
|
||||
recursive-include changedetectionio/tests *
|
||||
prune changedetectionio/static/package-lock.json
|
||||
prune changedetectionio/static/styles/node_modules
|
||||
prune changedetectionio/static/styles/package-lock.json
|
||||
recursive-include changedetectionio/static *
|
||||
include changedetection.py
|
||||
include requirements.txt
|
||||
include README-pip.md
|
||||
global-exclude *.pyc
|
||||
global-exclude node_modules
|
||||
global-exclude venv
|
||||
|
||||
global-exclude test-datastore
|
||||
global-exclude changedetection.io*dist-info
|
||||
global-exclude changedetectionio/tests/proxy_socks5/test-datastore
|
||||
global-exclude venv
|
||||
1
Procfile
Normal file
@@ -0,0 +1 @@
|
||||
web: python3 ./changedetection.py -C -d ./datastore -p $PORT
|
||||
116
README-pip.md
@@ -1,89 +1,38 @@
|
||||
## Web Site Change Detection, Monitoring and Notification.
|
||||
# changedetection.io
|
||||

|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/docker/pulls/dgtlmoon/changedetection.io" alt="Docker Pulls"/>
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/dgtlmoon/changedetection.io" target="_blank" title="Change detection docker hub">
|
||||
<img src="https://img.shields.io/github/v/release/dgtlmoon/changedetection.io" alt="Change detection latest tag version"/>
|
||||
</a>
|
||||
|
||||
Live your data-life pro-actively, track website content changes and receive notifications via Discord, Email, Slack, Telegram and 70+ more
|
||||
## Self-hosted open source change monitoring of web pages.
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring, list of websites with changes" title="Self-hosted web page change monitoring, list of websites with changes" />](https://changedetection.io)
|
||||
_Know when web pages change! Stay ontop of new information!_
|
||||
|
||||
Live your data-life *pro-actively* instead of *re-actively*, do not rely on manipulative social media for consuming important information.
|
||||
|
||||
|
||||
[**Don't have time? Let us host it for you! try our extremely affordable subscription use our proxies and support!**](https://changedetection.io)
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />
|
||||
|
||||
#### Example use cases
|
||||
|
||||
### Target specific parts of the webpage using the Visual Selector tool.
|
||||
Know when ...
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (included as part of our subscription service)
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Select parts and elements of a web page to monitor for changes" title="Select parts and elements of a web page to monitor for changes" />](https://changedetection.io?src=pip)
|
||||
|
||||
### Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />](https://changedetection.io?src=pip)
|
||||
|
||||
|
||||
### Perform interactive browser steps
|
||||
|
||||
Fill in text boxes, click buttons and more, setup your changedetection scenario.
|
||||
|
||||
Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
|
||||
|
||||
[<img src="docs/browsersteps-anim.gif" style="max-width:100%;" alt="Website change detection with interactive browser steps, detect changes behind login and password, search queries and more" title="Website change detection with interactive browser steps, detect changes behind login and password, search queries and more" />](https://changedetection.io?src=pip)
|
||||
|
||||
After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
|
||||
Requires Playwright to be enabled.
|
||||
|
||||
|
||||
### Example use cases
|
||||
|
||||
- Products and services have a change in pricing
|
||||
- _Out of stock notification_ and _Back In stock notification_
|
||||
- Monitor and track PDF file changes, know when a PDF file has text changes.
|
||||
- Governmental department updates (changes are often only on their websites)
|
||||
- Government department updates (changes are often only on their websites)
|
||||
- Local government news (changes are often only on their websites)
|
||||
- New software releases, security advisories when you're not on their mailing list.
|
||||
- Festivals with changes
|
||||
- Discogs restock alerts and monitoring
|
||||
- Realestate listing changes
|
||||
- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
|
||||
- COVID related news from government websites
|
||||
- University/organisation news from their website
|
||||
- Detect and monitor changes in JSON API responses
|
||||
- JSON API monitoring and alerting
|
||||
- Changes in legal and other documents
|
||||
- Trigger API calls via notifications when text appears on a website
|
||||
- Glue together APIs using the JSON filter and JSON notifications
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
- Get notified when certain keywords appear in Twitter search results
|
||||
- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
|
||||
- Get alerts when new job positions are open on Bamboo HR and other job platforms
|
||||
- Website defacement monitoring
|
||||
- Pokémon Card Restock Tracker / Pokémon TCG Tracker
|
||||
- RegTech - stay ahead of regulatory changes, regulatory compliance
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
|
||||
#### Key Features
|
||||
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath(1.0) and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Track changes in PDF files (Monitor text changed in the PDF, Also monitor PDF filesize and checksums)
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
|
||||
- Send a screenshot with the notification when a change is detected in the web page
|
||||
|
||||
We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
|
||||
|
||||
[Oxylabs](https://oxylabs.go2cloud.org/SH2d) is also an excellent proxy provider and well worth using, they offer Residental, ISP, Rotating and many other proxy types to suit your project.
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
- API monitoring and alerting
|
||||
|
||||
**Get monitoring now!**
|
||||
|
||||
```bash
|
||||
$ pip3 install changedetection.io
|
||||
$ pip3 install changedetection.io
|
||||
```
|
||||
|
||||
Specify a target for the *datastore path* with `-d` (required) and a *listening port* with `-p` (defaults to `5000`)
|
||||
@@ -95,5 +44,28 @@ $ changedetection.io -d /path/to/empty/data/dir -p 5000
|
||||
|
||||
Then visit http://127.0.0.1:5000 , You should now be able to access the UI.
|
||||
|
||||
See https://changedetection.io for more information.
|
||||
### Features
|
||||
- Website monitoring
|
||||
- Change detection of content and analyses
|
||||
- Filters on change (Select by CSS or JSON)
|
||||
- Triggers (Wait for text, wait for regex)
|
||||
- Notification support
|
||||
- JSON API Monitoring
|
||||
- Parse JSON embedded in HTML
|
||||
- (Reverse) Proxy support
|
||||
- Javascript support via WebDriver
|
||||
- RaspberriPi (arm v6/v7/64 support)
|
||||
|
||||
See https://github.com/dgtlmoon/changedetection.io for more information.
|
||||
|
||||
|
||||
|
||||
### Support us
|
||||
|
||||
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
|
||||
|
||||
Please support us, even small amounts help a LOT.
|
||||
|
||||
BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/btc-support.png" style="max-width:50%;" alt="Support us!" />
|
||||
|
||||
174
README.md
@@ -1,58 +1,38 @@
|
||||
## Web Site Change Detection, Restock monitoring and notifications.
|
||||
|
||||
**_Detect website content changes and perform meaningful actions - trigger notifications via Discord, Email, Slack, Telegram, API calls and many more._**
|
||||
|
||||
_Live your data-life pro-actively._
|
||||
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot.png" style="max-width:100%;" alt="Self-hosted web site page change monitoring" title="Self-hosted web site page change monitoring" />](https://changedetection.io?src=github)
|
||||
|
||||
# changedetection.io
|
||||
[![Release Version][release-shield]][release-link] [![Docker Pulls][docker-pulls]][docker-link] [![License][license-shield]](LICENSE.md)
|
||||
|
||||

|
||||
|
||||
[**Get started with website page change monitoring straight away. Don't have time? Try our $8.99/month subscription, use our proxies and support!**](https://changedetection.io) , _half the price of other website change monitoring services!_
|
||||
## Self-Hosted, Open Source, Change Monitoring of Web Pages
|
||||
|
||||
- Chrome browser included.
|
||||
- Nothing to install, access via browser login after signup.
|
||||
- Super fast, no registration needed setup.
|
||||
- Get started watching and receiving website change notifications straight away.
|
||||
- See our [tutorials and how-to page for more inspiration](https://changedetection.io/tutorials)
|
||||
_Know when web pages change! Stay ontop of new information!_
|
||||
|
||||
### Target specific parts of the webpage using the Visual Selector tool.
|
||||
Live your data-life *pro-actively* instead of *re-actively*.
|
||||
|
||||
Available when connected to a <a href="https://github.com/dgtlmoon/changedetection.io/wiki/Playwright-content-fetcher">playwright content fetcher</a> (included as part of our subscription service)
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/visualselector-anim.gif" style="max-width:100%;" alt="Select parts and elements of a web page to monitor for changes" title="Select parts and elements of a web page to monitor for changes" />](https://changedetection.io?src=github)
|
||||
|
||||
### Easily see what changed, examine by word, line, or individual character.
|
||||
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />](https://changedetection.io?src=github)
|
||||
Free, Open-source web page monitoring, notification and change detection. Don't have time? [**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
### Perform interactive browser steps
|
||||
|
||||
Fill in text boxes, click buttons and more, setup your changedetection scenario.
|
||||
|
||||
Using the **Browser Steps** configuration, add basic steps before performing change detection, such as logging into websites, adding a product to a cart, accept cookie logins, entering dates and refining searches.
|
||||
|
||||
[<img src="docs/browsersteps-anim.gif" style="max-width:100%;" alt="Website change detection with interactive browser steps, detect changes behind login and password, search queries and more" title="Website change detection with interactive browser steps, detect changes behind login and password, search queries and more" />](https://changedetection.io?src=github)
|
||||
|
||||
After **Browser Steps** have been run, then visit the **Visual Selector** tab to refine the content you're interested in.
|
||||
Requires Playwright to be enabled.
|
||||
[<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot.png" style="max-width:100%;" alt="Self-hosted web page change monitoring" title="Self-hosted web page change monitoring" />](https://lemonade.changedetection.io/start)
|
||||
|
||||
|
||||
### Example use cases
|
||||
**Get your own private instance now! Let us host it for you!**
|
||||
|
||||
[**Try our $6.99/month subscription - unlimited checks and watches!**](https://lemonade.changedetection.io/start) , _half the price of other website change monitoring services and comes with unlimited watches & checks!_
|
||||
|
||||
|
||||
|
||||
- Automatic Updates, Automatic Backups, No Heroku "paused application", don't miss a change!
|
||||
- Javascript browser included
|
||||
- Unlimited checks and watches!
|
||||
|
||||
|
||||
#### Example use cases
|
||||
|
||||
- Products and services have a change in pricing
|
||||
- _Out of stock notification_ and _Back In stock notification_
|
||||
- Monitor and track PDF file changes, know when a PDF file has text changes.
|
||||
- Governmental department updates (changes are often only on their websites)
|
||||
- New software releases, security advisories when you're not on their mailing list.
|
||||
- Festivals with changes
|
||||
- Discogs restock alerts and monitoring
|
||||
- Realestate listing changes
|
||||
- Know when your favourite whiskey is on sale, or other special deals are announced before anyone else
|
||||
- COVID related news from government websites
|
||||
- University/organisation news from their website
|
||||
- Detect and monitor changes in JSON API responses
|
||||
@@ -63,53 +43,31 @@ Requires Playwright to be enabled.
|
||||
- Create RSS feeds based on changes in web content
|
||||
- Monitor HTML source code for unexpected changes, strengthen your PCI compliance
|
||||
- You have a very sensitive list of URLs to watch and you do _not_ want to use the paid alternatives. (Remember, _you_ are the product)
|
||||
- Get notified when certain keywords appear in Twitter search results
|
||||
- Proactively search for jobs, get notified when companies update their careers page, search job portals for keywords.
|
||||
- Get alerts when new job positions are open on Bamboo HR and other job platforms
|
||||
- Website defacement monitoring
|
||||
- Pokémon Card Restock Tracker / Pokémon TCG Tracker
|
||||
- RegTech - stay ahead of regulatory changes, regulatory compliance
|
||||
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver and Playwright!</a>_
|
||||
_Need an actual Chrome runner with Javascript support? We support fetching via WebDriver!</a>_
|
||||
|
||||
#### Key Features
|
||||
## Screenshots
|
||||
|
||||
- Lots of trigger filters, such as "Trigger on text", "Remove text by selector", "Ignore text", "Extract text", also using regular-expressions!
|
||||
- Target elements with xPath(1.0) and CSS Selectors, Easily monitor complex JSON with JSONPath or jq
|
||||
- Switch between fast non-JS and Chrome JS based "fetchers"
|
||||
- Track changes in PDF files (Monitor text changed in the PDF, Also monitor PDF filesize and checksums)
|
||||
- Easily specify how often a site should be checked
|
||||
- Execute JS before extracting text (Good for logging in, see examples in the UI!)
|
||||
- Override Request Headers, Specify `POST` or `GET` and other methods
|
||||
- Use the "Visual Selector" to help target specific elements
|
||||
- Configurable [proxy per watch](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration)
|
||||
- Send a screenshot with the notification when a change is detected in the web page
|
||||
Examining differences in content.
|
||||
|
||||
We [recommend and use Bright Data](https://brightdata.grsm.io/n0r16zf7eivq) global proxy services, Bright Data will match any first deposit up to $100 using our signup link.
|
||||
|
||||
[Oxylabs](https://oxylabs.go2cloud.org/SH2d) is also an excellent proxy provider and well worth using, they offer Residental, ISP, Rotating and many other proxy types to suit your project.
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-diff.png" style="max-width:100%;" alt="Self-hosted web page change monitoring context difference " title="Self-hosted web page change monitoring context difference " />
|
||||
|
||||
Please :star: star :star: this project and help it grow! https://github.com/dgtlmoon/changedetection.io/
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
### Docker
|
||||
|
||||
With Docker composer, just clone this repository and..
|
||||
|
||||
```bash
|
||||
$ docker compose up -d
|
||||
$ docker-compose up -d
|
||||
```
|
||||
|
||||
Docker standalone
|
||||
```bash
|
||||
$ docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
|
||||
```
|
||||
|
||||
`:latest` tag is our latest stable release, `:dev` tag is our bleeding edge `master` branch.
|
||||
|
||||
Alternative docker repository over at ghcr - [ghcr.io/dgtlmoon/changedetection.io](https://ghcr.io/dgtlmoon/changedetection.io)
|
||||
|
||||
### Windows
|
||||
|
||||
See the install instructions at the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Microsoft-Windows
|
||||
@@ -132,24 +90,24 @@ _Now with per-site configurable support for using a fast built in HTTP fetcher o
|
||||
### Docker
|
||||
```
|
||||
docker pull dgtlmoon/changedetection.io
|
||||
docker kill $(docker ps -a -f name=changedetection.io -q)
|
||||
docker rm $(docker ps -a -f name=changedetection.io -q)
|
||||
docker kill $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker rm $(docker ps -a|grep changedetection.io|awk '{print $1}')
|
||||
docker run -d --restart always -p "127.0.0.1:5000:5000" -v datastore-volume:/datastore --name changedetection.io dgtlmoon/changedetection.io
|
||||
```
|
||||
|
||||
### docker compose
|
||||
### docker-compose
|
||||
|
||||
```bash
|
||||
docker compose pull && docker compose up -d
|
||||
docker-compose pull && docker-compose up -d
|
||||
```
|
||||
|
||||
See the wiki for more information https://github.com/dgtlmoon/changedetection.io/wiki
|
||||
|
||||
|
||||
## Filters
|
||||
XPath, JSONPath and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
|
||||
XPath(1.0), JSONPath, jq, and CSS support comes baked in! You can be as specific as you need, use XPath exported from various XPath element query creation tools.
|
||||
(We support LXML `re:test`, `re:match` and `re:replace`.)
|
||||
(We support LXML re:test, re:math and re:replace.)
|
||||
|
||||
## Notifications
|
||||
|
||||
@@ -171,91 +129,55 @@ Just some examples
|
||||
|
||||
<a href="https://github.com/caronc/apprise#popular-notification-services">And everything else in this list!</a>
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/screenshot-notifications.png" style="max-width:100%;" alt="Self-hosted web page change monitoring notifications" title="Self-hosted web page change monitoring notifications" />
|
||||
|
||||
Now you can also customise your notification content and use <a target="_new" href="https://jinja.palletsprojects.com/en/3.0.x/templates/">Jinja2 templating</a> for their title and body!
|
||||
Now you can also customise your notification content!
|
||||
|
||||
## JSON API Monitoring
|
||||
|
||||
Detect changes and monitor data in JSON API's by using either JSONPath or jq to filter, parse, and restructure JSON as needed.
|
||||
Detect changes and monitor data in JSON API's by using the built-in JSONPath selectors as a filter / selector.
|
||||
|
||||

|
||||

|
||||
|
||||
This will re-parse the JSON and apply formatting to the text, making it super easy to monitor and detect changes in JSON API results
|
||||
|
||||
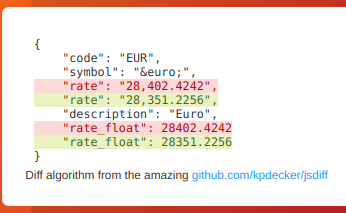
|
||||
|
||||
### JSONPath or jq?
|
||||
|
||||
For more complex parsing, filtering, and modifying of JSON data, jq is recommended due to the built-in operators and functions. Refer to the [documentation](https://stedolan.github.io/jq/manual/) for more specific information on jq.
|
||||
|
||||
One big advantage of `jq` is that you can use logic in your JSON filter, such as filters to only show items that have a value greater than/less than etc.
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/JSON-Selector-Filter-help for more information and examples
|
||||

|
||||
|
||||
### Parse JSON embedded in HTML!
|
||||
|
||||
When you enable a `json:` or `jq:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
When you enable a `json:` filter, you can even automatically extract and parse embedded JSON inside a HTML page! Amazingly handy for sites that build content based on JSON, such as many e-commerce websites.
|
||||
|
||||
```
|
||||
<html>
|
||||
...
|
||||
<script type="application/ld+json">
|
||||
|
||||
{
|
||||
"@context":"http://schema.org/",
|
||||
"@type":"Product",
|
||||
"offers":{
|
||||
"@type":"Offer",
|
||||
"availability":"http://schema.org/InStock",
|
||||
"price":"3949.99",
|
||||
"priceCurrency":"USD",
|
||||
"url":"https://www.newegg.com/p/3D5-000D-001T1"
|
||||
},
|
||||
"description":"Cobratype King Cobra Hero Desktop Gaming PC",
|
||||
"name":"Cobratype King Cobra Hero Desktop Gaming PC",
|
||||
"sku":"3D5-000D-001T1",
|
||||
"itemCondition":"NewCondition"
|
||||
}
|
||||
{"@context":"http://schema.org","@type":"Product","name":"Nan Optipro Stage 1 Baby Formula 800g","price": 23.50 }
|
||||
</script>
|
||||
```
|
||||
|
||||
`json:$..price` or `jq:..price` would give `3949.99`, or you can extract the whole structure (use a JSONpath test website to validate with)
|
||||
`json:$.price` would give `23.50`, or you can extract the whole structure
|
||||
|
||||
The application also supports notifying you that it can follow this information automatically
|
||||
## Proxy configuration
|
||||
|
||||
|
||||
## Proxy Configuration
|
||||
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration , we also support using [Bright Data proxy services where possible](https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration#brightdata-proxy-support) and [Oxylabs](https://oxylabs.go2cloud.org/SH2d) proxy services.
|
||||
See the wiki https://github.com/dgtlmoon/changedetection.io/wiki/Proxy-configuration
|
||||
|
||||
## Raspberry Pi support?
|
||||
|
||||
Raspberry Pi and linux/arm/v6 linux/arm/v7 arm64 devices are supported! See the wiki for [details](https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver)
|
||||
|
||||
## Import support
|
||||
|
||||
Easily [import your list of websites to watch for changes in Excel .xslx file format](https://changedetection.io/tutorial/how-import-your-website-change-detection-lists-excel), or paste in lists of website URLs as plaintext.
|
||||
|
||||
Excel import is recommended - that way you can better organise tags/groups of websites and other features.
|
||||
|
||||
|
||||
## API Support
|
||||
|
||||
Supports managing the website watch list [via our API](https://changedetection.io/docs/api_v1/index.html)
|
||||
|
||||
## Support us
|
||||
|
||||
Do you use changedetection.io to make money? does it save you time or money? Does it make your life easier? less stressful? Remember, we write this software when we should be doing actual paid work, we have to buy food and pay rent just like you.
|
||||
|
||||
|
||||
Firstly, consider taking out an officially supported [website change detection subscription](https://changedetection.io?src=github) , even if you don't use it, you still get the warm fuzzy feeling of helping out the project. (And who knows, you might just use it!)
|
||||
Firstly, consider taking out a [change detection monthly subscription - unlimited checks and watches](https://lemonade.changedetection.io/start) , even if you don't use it, you still get the warm fuzzy feeling of helping out the project. (And who knows, you might just use it!)
|
||||
|
||||
Or directly donate an amount PayPal [](https://www.paypal.com/donate/?hosted_button_id=7CP6HR9ZCNDYJ)
|
||||
|
||||
Or BTC `1PLFN327GyUarpJd7nVe7Reqg9qHx5frNn`
|
||||
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/docs/btc-support.png" style="max-width:50%;" alt="Support us!" />
|
||||
<img src="https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/btc-support.png" style="max-width:50%;" alt="Support us!" />
|
||||
|
||||
## Commercial Support
|
||||
|
||||
@@ -267,15 +189,5 @@ I offer commercial support, this software is depended on by network security, ae
|
||||
[test-shield]: https://github.com/dgtlmoon/changedetection.io/actions/workflows/test-only.yml/badge.svg?branch=master
|
||||
|
||||
[license-shield]: https://img.shields.io/github/license/dgtlmoon/changedetection.io.svg?style=for-the-badge
|
||||
[release-link]: https://github.com/dgtlmoon/changedetection.io/releases
|
||||
[release-link]: https://github.com/dgtlmoon.com/changedetection.io/releases
|
||||
[docker-link]: https://hub.docker.com/r/dgtlmoon/changedetection.io
|
||||
|
||||
## Third-party licenses
|
||||
|
||||
changedetectionio.html_tools.elementpath_tostring: Copyright (c), 2018-2021, SISSA (Scuola Internazionale Superiore di Studi Avanzati), Licensed under [MIT license](https://github.com/sissaschool/elementpath/blob/master/LICENSE)
|
||||
|
||||
## Contributors
|
||||
|
||||
Recognition of fantastic contributors to the project
|
||||
|
||||
- Constantin Hong https://github.com/Constantin1489
|
||||
|
||||
21
app.json
Normal file
@@ -0,0 +1,21 @@
|
||||
{
|
||||
"name": "ChangeDetection.io",
|
||||
"description": "The best and simplest self-hosted open source website change detection monitoring and notification service.",
|
||||
"keywords": [
|
||||
"changedetection",
|
||||
"website monitoring"
|
||||
],
|
||||
"repository": "https://github.com/dgtlmoon/changedetection.io",
|
||||
"success_url": "/",
|
||||
"scripts": {
|
||||
},
|
||||
"env": {
|
||||
},
|
||||
"formation": {
|
||||
"web": {
|
||||
"quantity": 1,
|
||||
"size": "free"
|
||||
}
|
||||
},
|
||||
"image": "heroku/python"
|
||||
}
|
||||
{kind=link}
|
Before Width: | Height: | Size: 894 B After Width: | Height: | Size: 894 B |
@@ -1,6 +1,11 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
# Only exists for direct CLI usage
|
||||
# Entry-point for running from the CLI when not installed via Pip, Pip will handle the console_scripts entry_points's from setup.py
|
||||
# It's recommended to use `pip3 install changedetection.io` and start with `changedetection.py` instead, it will be linkd to your global path.
|
||||
# or Docker.
|
||||
# Read more https://github.com/dgtlmoon/changedetection.io/wiki
|
||||
|
||||
import changedetectionio
|
||||
changedetectionio.main()
|
||||
from changedetectionio import changedetection
|
||||
|
||||
if __name__ == '__main__':
|
||||
changedetection.main()
|
||||
|
||||
1
changedetectionio/.gitignore
vendored
@@ -1,2 +1 @@
|
||||
test-datastore
|
||||
package-lock.json
|
||||
|
||||
@@ -1,117 +0,0 @@
|
||||
# Responsible for building the storage dict into a set of rules ("JSON Schema") acceptable via the API
|
||||
# Probably other ways to solve this when the backend switches to some ORM
|
||||
|
||||
def build_time_between_check_json_schema():
|
||||
# Setup time between check schema
|
||||
schema_properties_time_between_check = {
|
||||
"type": "object",
|
||||
"additionalProperties": False,
|
||||
"properties": {}
|
||||
}
|
||||
for p in ['weeks', 'days', 'hours', 'minutes', 'seconds']:
|
||||
schema_properties_time_between_check['properties'][p] = {
|
||||
"anyOf": [
|
||||
{
|
||||
"type": "integer"
|
||||
},
|
||||
{
|
||||
"type": "null"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
return schema_properties_time_between_check
|
||||
|
||||
def build_watch_json_schema(d):
|
||||
# Base JSON schema
|
||||
schema = {
|
||||
'type': 'object',
|
||||
'properties': {},
|
||||
}
|
||||
|
||||
for k, v in d.items():
|
||||
# @todo 'integer' is not covered here because its almost always for internal usage
|
||||
|
||||
if isinstance(v, type(None)):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "null"},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, list):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "array",
|
||||
# Always is an array of strings, like text or regex or something
|
||||
"items": {
|
||||
"type": "string",
|
||||
"maxLength": 5000
|
||||
}
|
||||
},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, bool):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "boolean"},
|
||||
]
|
||||
}
|
||||
elif isinstance(v, str):
|
||||
schema['properties'][k] = {
|
||||
"anyOf": [
|
||||
{"type": "string",
|
||||
"maxLength": 5000},
|
||||
]
|
||||
}
|
||||
|
||||
# Can also be a string (or None by default above)
|
||||
for v in ['body',
|
||||
'notification_body',
|
||||
'notification_format',
|
||||
'notification_title',
|
||||
'proxy',
|
||||
'tag',
|
||||
'title',
|
||||
'webdriver_js_execute_code'
|
||||
]:
|
||||
schema['properties'][v]['anyOf'].append({'type': 'string', "maxLength": 5000})
|
||||
|
||||
# None or Boolean
|
||||
schema['properties']['track_ldjson_price_data']['anyOf'].append({'type': 'boolean'})
|
||||
|
||||
schema['properties']['method'] = {"type": "string",
|
||||
"enum": ["GET", "POST", "DELETE", "PUT"]
|
||||
}
|
||||
|
||||
schema['properties']['fetch_backend']['anyOf'].append({"type": "string",
|
||||
"enum": ["html_requests", "html_webdriver"]
|
||||
})
|
||||
|
||||
|
||||
|
||||
# All headers must be key/value type dict
|
||||
schema['properties']['headers'] = {
|
||||
"type": "object",
|
||||
"patternProperties": {
|
||||
# Should always be a string:string type value
|
||||
".*": {"type": "string"},
|
||||
}
|
||||
}
|
||||
|
||||
from changedetectionio.notification import valid_notification_formats
|
||||
|
||||
schema['properties']['notification_format'] = {'type': 'string',
|
||||
'enum': list(valid_notification_formats.keys())
|
||||
}
|
||||
|
||||
# Stuff that shouldn't be available but is just state-storage
|
||||
for v in ['previous_md5', 'last_error', 'has_ldjson_price_data', 'previous_md5_before_filters', 'uuid']:
|
||||
del schema['properties'][v]
|
||||
|
||||
schema['properties']['webdriver_delay']['anyOf'].append({'type': 'integer'})
|
||||
|
||||
schema['properties']['time_between_check'] = build_time_between_check_json_schema()
|
||||
|
||||
# headers ?
|
||||
return schema
|
||||
|
||||
@@ -1,404 +0,0 @@
|
||||
import os
|
||||
from distutils.util import strtobool
|
||||
|
||||
from flask_expects_json import expects_json
|
||||
from changedetectionio import queuedWatchMetaData
|
||||
from flask_restful import abort, Resource
|
||||
from flask import request, make_response
|
||||
import validators
|
||||
from . import auth
|
||||
import copy
|
||||
|
||||
# See docs/README.md for rebuilding the docs/apidoc information
|
||||
|
||||
from . import api_schema
|
||||
|
||||
# Build a JSON Schema atleast partially based on our Watch model
|
||||
from changedetectionio.model.Watch import base_config as watch_base_config
|
||||
schema = api_schema.build_watch_json_schema(watch_base_config)
|
||||
|
||||
schema_create_watch = copy.deepcopy(schema)
|
||||
schema_create_watch['required'] = ['url']
|
||||
|
||||
schema_update_watch = copy.deepcopy(schema)
|
||||
schema_update_watch['additionalProperties'] = False
|
||||
|
||||
class Watch(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
# Get information about a single watch, excluding the history list (can be large)
|
||||
# curl http://localhost:5000/api/v1/watch/<string:uuid>
|
||||
# @todo - version2 - ?muted and ?paused should be able to be called together, return the watch struct not "OK"
|
||||
# ?recheck=true
|
||||
@auth.check_token
|
||||
def get(self, uuid):
|
||||
"""
|
||||
@api {get} /api/v1/watch/:uuid Single watch - get data, recheck, pause, mute.
|
||||
@apiDescription Retrieve watch information and set muted/paused status
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
curl "http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091?muted=unmuted" -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
curl "http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091?paused=unpaused" -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
@apiName Watch
|
||||
@apiGroup Watch
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiQuery {Boolean} [recheck] Recheck this watch `recheck=1`
|
||||
@apiQuery {String} [paused] =`paused` or =`unpaused` , Sets the PAUSED state
|
||||
@apiQuery {String} [muted] =`muted` or =`unmuted` , Sets the MUTE NOTIFICATIONS state
|
||||
@apiSuccess (200) {String} OK When paused/muted/recheck operation OR full JSON object of the watch
|
||||
@apiSuccess (200) {JSON} WatchJSON JSON Full JSON object of the watch
|
||||
"""
|
||||
from copy import deepcopy
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if request.args.get('recheck'):
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': True}))
|
||||
return "OK", 200
|
||||
if request.args.get('paused', '') == 'paused':
|
||||
self.datastore.data['watching'].get(uuid).pause()
|
||||
return "OK", 200
|
||||
elif request.args.get('paused', '') == 'unpaused':
|
||||
self.datastore.data['watching'].get(uuid).unpause()
|
||||
return "OK", 200
|
||||
if request.args.get('muted', '') == 'muted':
|
||||
self.datastore.data['watching'].get(uuid).mute()
|
||||
return "OK", 200
|
||||
elif request.args.get('muted', '') == 'unmuted':
|
||||
self.datastore.data['watching'].get(uuid).unmute()
|
||||
return "OK", 200
|
||||
|
||||
# Return without history, get that via another API call
|
||||
# Properties are not returned as a JSON, so add the required props manually
|
||||
watch['history_n'] = watch.history_n
|
||||
watch['last_changed'] = watch.last_changed
|
||||
watch['viewed'] = watch.viewed
|
||||
return watch
|
||||
|
||||
@auth.check_token
|
||||
def delete(self, uuid):
|
||||
"""
|
||||
@api {delete} /api/v1/watch/:uuid Delete a watch and related history
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -X DELETE -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiName Delete
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was deleted
|
||||
"""
|
||||
if not self.datastore.data['watching'].get(uuid):
|
||||
abort(400, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
self.datastore.delete(uuid)
|
||||
return 'OK', 204
|
||||
|
||||
@auth.check_token
|
||||
@expects_json(schema_update_watch)
|
||||
def put(self, uuid):
|
||||
"""
|
||||
@api {put} /api/v1/watch/:uuid Update watch information
|
||||
@apiExample {curl} Example usage:
|
||||
Update (PUT)
|
||||
curl http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091 -X PUT -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json" -d '{"url": "https://my-nice.com" , "tag": "new list"}'
|
||||
|
||||
@apiDescription Updates an existing watch using JSON, accepts the same structure as returned in <a href="#api-Watch-Watch">get single watch information</a>
|
||||
@apiParam {uuid} uuid Watch unique ID.
|
||||
@apiName Update a watch
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was updated
|
||||
@apiSuccess (500) {String} ERR Some other error
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if request.json.get('proxy'):
|
||||
plist = self.datastore.proxy_list
|
||||
if not request.json.get('proxy') in plist:
|
||||
return "Invalid proxy choice, currently supported proxies are '{}'".format(', '.join(plist)), 400
|
||||
|
||||
watch.update(request.json)
|
||||
|
||||
return "OK", 200
|
||||
|
||||
|
||||
class WatchHistory(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
# Get a list of available history for a watch by UUID
|
||||
# curl http://localhost:5000/api/v1/watch/<string:uuid>/history
|
||||
@auth.check_token
|
||||
def get(self, uuid):
|
||||
"""
|
||||
@api {get} /api/v1/watch/<string:uuid>/history Get a list of all historical snapshots available for a watch
|
||||
@apiDescription Requires `uuid`, returns list
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091/history -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json"
|
||||
{
|
||||
"1676649279": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/cb7e9be8258368262246910e6a2a4c30.txt",
|
||||
"1677092785": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/e20db368d6fc633e34f559ff67bb4044.txt",
|
||||
"1677103794": "/tmp/data/6a4b7d5c-fee4-4616-9f43-4ac97046b595/02efdd37dacdae96554a8cc85dc9c945.txt"
|
||||
}
|
||||
@apiName Get list of available stored snapshots for watch
|
||||
@apiGroup Watch History
|
||||
@apiSuccess (200) {String} OK
|
||||
@apiSuccess (404) {String} ERR Not found
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
return watch.history, 200
|
||||
|
||||
|
||||
class WatchSingleHistory(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
@auth.check_token
|
||||
def get(self, uuid, timestamp):
|
||||
"""
|
||||
@api {get} /api/v1/watch/<string:uuid>/history/<int:timestamp> Get single snapshot from watch
|
||||
@apiDescription Requires watch `uuid` and `timestamp`. `timestamp` of "`latest`" for latest available snapshot, or <a href="#api-Watch_History-Get_list_of_available_stored_snapshots_for_watch">use the list returned here</a>
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch/cc0cfffa-f449-477b-83ea-0caafd1dc091/history/1677092977 -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json"
|
||||
@apiName Get single snapshot content
|
||||
@apiGroup Watch History
|
||||
@apiSuccess (200) {String} OK
|
||||
@apiSuccess (404) {String} ERR Not found
|
||||
"""
|
||||
watch = self.datastore.data['watching'].get(uuid)
|
||||
if not watch:
|
||||
abort(404, message='No watch exists with the UUID of {}'.format(uuid))
|
||||
|
||||
if not len(watch.history):
|
||||
abort(404, message='Watch found but no history exists for the UUID {}'.format(uuid))
|
||||
|
||||
if timestamp == 'latest':
|
||||
timestamp = list(watch.history.keys())[-1]
|
||||
|
||||
content = watch.get_history_snapshot(timestamp)
|
||||
|
||||
response = make_response(content, 200)
|
||||
response.mimetype = "text/plain"
|
||||
return response
|
||||
|
||||
|
||||
class CreateWatch(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
@expects_json(schema_create_watch)
|
||||
def post(self):
|
||||
"""
|
||||
@api {post} /api/v1/watch Create a single watch
|
||||
@apiDescription Requires atleast `url` set, can accept the same structure as <a href="#api-Watch-Watch">get single watch information</a> to create.
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch -H"x-api-key:813031b16330fe25e3780cf0325daa45" -H "Content-Type: application/json" -d '{"url": "https://my-nice.com" , "tag": "nice list"}'
|
||||
@apiName Create
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {String} OK Was created
|
||||
@apiSuccess (500) {String} ERR Some other error
|
||||
"""
|
||||
|
||||
json_data = request.get_json()
|
||||
url = json_data['url'].strip()
|
||||
|
||||
# If hosts that only contain alphanumerics are allowed ("localhost" for example)
|
||||
allow_simplehost = not strtobool(os.getenv('BLOCK_SIMPLEHOSTS', 'False'))
|
||||
if not validators.url(url, simple_host=allow_simplehost):
|
||||
return "Invalid or unsupported URL", 400
|
||||
|
||||
if json_data.get('proxy'):
|
||||
plist = self.datastore.proxy_list
|
||||
if not json_data.get('proxy') in plist:
|
||||
return "Invalid proxy choice, currently supported proxies are '{}'".format(', '.join(plist)), 400
|
||||
|
||||
extras = copy.deepcopy(json_data)
|
||||
|
||||
# Because we renamed 'tag' to 'tags' but don't want to change the API (can do this in v2 of the API)
|
||||
tags = None
|
||||
if extras.get('tag'):
|
||||
tags = extras.get('tag')
|
||||
del extras['tag']
|
||||
|
||||
del extras['url']
|
||||
|
||||
new_uuid = self.datastore.add_watch(url=url, extras=extras, tag=tags)
|
||||
if new_uuid:
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': new_uuid, 'skip_when_checksum_same': True}))
|
||||
return {'uuid': new_uuid}, 201
|
||||
else:
|
||||
return "Invalid or unsupported URL", 400
|
||||
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
"""
|
||||
@api {get} /api/v1/watch List watches
|
||||
@apiDescription Return concise list of available watches and some very basic info
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/watch -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
{
|
||||
"6a4b7d5c-fee4-4616-9f43-4ac97046b595": {
|
||||
"last_changed": 1677103794,
|
||||
"last_checked": 1677103794,
|
||||
"last_error": false,
|
||||
"title": "",
|
||||
"url": "http://www.quotationspage.com/random.php"
|
||||
},
|
||||
"e6f5fd5c-dbfe-468b-b8f3-f9d6ff5ad69b": {
|
||||
"last_changed": 0,
|
||||
"last_checked": 1676662819,
|
||||
"last_error": false,
|
||||
"title": "QuickLook",
|
||||
"url": "https://github.com/QL-Win/QuickLook/tags"
|
||||
}
|
||||
}
|
||||
|
||||
@apiParam {String} [recheck_all] Optional Set to =1 to force recheck of all watches
|
||||
@apiParam {String} [tag] Optional name of tag to limit results
|
||||
@apiName ListWatches
|
||||
@apiGroup Watch Management
|
||||
@apiSuccess (200) {String} OK JSON dict
|
||||
"""
|
||||
list = {}
|
||||
|
||||
tag_limit = request.args.get('tag', '').lower()
|
||||
|
||||
|
||||
for uuid, watch in self.datastore.data['watching'].items():
|
||||
# Watch tags by name (replace the other calls?)
|
||||
tags = self.datastore.get_all_tags_for_watch(uuid=uuid)
|
||||
if tag_limit and not any(v.get('title').lower() == tag_limit for k, v in tags.items()):
|
||||
continue
|
||||
|
||||
list[uuid] = {
|
||||
'last_changed': watch.last_changed,
|
||||
'last_checked': watch['last_checked'],
|
||||
'last_error': watch['last_error'],
|
||||
'title': watch['title'],
|
||||
'url': watch['url'],
|
||||
'viewed': watch.viewed
|
||||
}
|
||||
|
||||
if request.args.get('recheck_all'):
|
||||
for uuid in self.datastore.data['watching'].keys():
|
||||
self.update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': True}))
|
||||
return {'status': "OK"}, 200
|
||||
|
||||
return list, 200
|
||||
|
||||
class Import(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
|
||||
@auth.check_token
|
||||
def post(self):
|
||||
"""
|
||||
@api {post} /api/v1/import Import a list of watched URLs
|
||||
@apiDescription Accepts a line-feed separated list of URLs to import, additionally with ?tag_uuids=(tag id), ?tag=(name), ?proxy={key}, ?dedupe=true (default true) one URL per line.
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/import --data-binary @list-of-sites.txt -H"x-api-key:8a111a21bc2f8f1dd9b9353bbd46049a"
|
||||
@apiName Import
|
||||
@apiGroup Watch
|
||||
@apiSuccess (200) {List} OK List of watch UUIDs added
|
||||
@apiSuccess (500) {String} ERR Some other error
|
||||
"""
|
||||
|
||||
extras = {}
|
||||
|
||||
if request.args.get('proxy'):
|
||||
plist = self.datastore.proxy_list
|
||||
if not request.args.get('proxy') in plist:
|
||||
return "Invalid proxy choice, currently supported proxies are '{}'".format(', '.join(plist)), 400
|
||||
else:
|
||||
extras['proxy'] = request.args.get('proxy')
|
||||
|
||||
dedupe = strtobool(request.args.get('dedupe', 'true'))
|
||||
|
||||
tags = request.args.get('tag')
|
||||
tag_uuids = request.args.get('tag_uuids')
|
||||
|
||||
if tag_uuids:
|
||||
tag_uuids = tag_uuids.split(',')
|
||||
|
||||
urls = request.get_data().decode('utf8').splitlines()
|
||||
added = []
|
||||
allow_simplehost = not strtobool(os.getenv('BLOCK_SIMPLEHOSTS', 'False'))
|
||||
for url in urls:
|
||||
url = url.strip()
|
||||
if not len(url):
|
||||
continue
|
||||
|
||||
# If hosts that only contain alphanumerics are allowed ("localhost" for example)
|
||||
if not validators.url(url, simple_host=allow_simplehost):
|
||||
return f"Invalid or unsupported URL - {url}", 400
|
||||
|
||||
if dedupe and self.datastore.url_exists(url):
|
||||
continue
|
||||
|
||||
new_uuid = self.datastore.add_watch(url=url, extras=extras, tag=tags, tag_uuids=tag_uuids)
|
||||
added.append(new_uuid)
|
||||
|
||||
return added
|
||||
|
||||
class SystemInfo(Resource):
|
||||
def __init__(self, **kwargs):
|
||||
# datastore is a black box dependency
|
||||
self.datastore = kwargs['datastore']
|
||||
self.update_q = kwargs['update_q']
|
||||
|
||||
@auth.check_token
|
||||
def get(self):
|
||||
"""
|
||||
@api {get} /api/v1/systeminfo Return system info
|
||||
@apiDescription Return some info about the current system state
|
||||
@apiExample {curl} Example usage:
|
||||
curl http://localhost:5000/api/v1/systeminfo -H"x-api-key:813031b16330fe25e3780cf0325daa45"
|
||||
HTTP/1.0 200
|
||||
{
|
||||
'queue_size': 10 ,
|
||||
'overdue_watches': ["watch-uuid-list"],
|
||||
'uptime': 38344.55,
|
||||
'watch_count': 800,
|
||||
'version': "0.40.1"
|
||||
}
|
||||
@apiName Get Info
|
||||
@apiGroup System Information
|
||||
"""
|
||||
import time
|
||||
overdue_watches = []
|
||||
|
||||
# Check all watches and report which have not been checked but should have been
|
||||
|
||||
for uuid, watch in self.datastore.data.get('watching', {}).items():
|
||||
# see if now - last_checked is greater than the time that should have been
|
||||
# this is not super accurate (maybe they just edited it) but better than nothing
|
||||
t = watch.threshold_seconds()
|
||||
if not t:
|
||||
# Use the system wide default
|
||||
t = self.datastore.threshold_seconds
|
||||
|
||||
time_since_check = time.time() - watch.get('last_checked')
|
||||
|
||||
# Allow 5 minutes of grace time before we decide it's overdue
|
||||
if time_since_check - (5 * 60) > t:
|
||||
overdue_watches.append(uuid)
|
||||
from changedetectionio import __version__ as main_version
|
||||
return {
|
||||
'queue_size': self.update_q.qsize(),
|
||||
'overdue_watches': overdue_watches,
|
||||
'uptime': round(time.time() - self.datastore.start_time, 2),
|
||||
'watch_count': len(self.datastore.data.get('watching', {})),
|
||||
'version': main_version
|
||||
}, 200
|
||||
@@ -1,33 +0,0 @@
|
||||
from flask import request, make_response, jsonify
|
||||
from functools import wraps
|
||||
|
||||
|
||||
# Simple API auth key comparison
|
||||
# @todo - Maybe short lived token in the future?
|
||||
|
||||
def check_token(f):
|
||||
@wraps(f)
|
||||
def decorated(*args, **kwargs):
|
||||
datastore = args[0].datastore
|
||||
|
||||
config_api_token_enabled = datastore.data['settings']['application'].get('api_access_token_enabled')
|
||||
if not config_api_token_enabled:
|
||||
return
|
||||
|
||||
try:
|
||||
api_key_header = request.headers['x-api-key']
|
||||
except KeyError:
|
||||
return make_response(
|
||||
jsonify("No authorization x-api-key header."), 403
|
||||
)
|
||||
|
||||
config_api_token = datastore.data['settings']['application'].get('api_access_token')
|
||||
|
||||
if api_key_header != config_api_token:
|
||||
return make_response(
|
||||
jsonify("Invalid access - API key invalid."), 403
|
||||
)
|
||||
|
||||
return f(*args, **kwargs)
|
||||
|
||||
return decorated
|
||||
@@ -1,11 +0,0 @@
|
||||
import apprise
|
||||
|
||||
# Create our AppriseAsset and populate it with some of our new values:
|
||||
# https://github.com/caronc/apprise/wiki/Development_API#the-apprise-asset-object
|
||||
asset = apprise.AppriseAsset(
|
||||
image_url_logo='https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
|
||||
)
|
||||
|
||||
asset.app_id = "changedetection.io"
|
||||
asset.app_desc = "ChangeDetection.io best and simplest website monitoring and change detection"
|
||||
asset.app_url = "https://changedetection.io"
|
||||
@@ -1,241 +0,0 @@
|
||||
|
||||
# HORRIBLE HACK BUT WORKS :-) PR anyone?
|
||||
#
|
||||
# Why?
|
||||
# `browsersteps_playwright_browser_interface.chromium.connect_over_cdp()` will only run once without async()
|
||||
# - this flask app is not async()
|
||||
# - browserless has a single timeout/keepalive which applies to the session made at .connect_over_cdp()
|
||||
#
|
||||
# So it means that we must unfortunately for now just keep a single timer since .connect_over_cdp() was run
|
||||
# and know when that reaches timeout/keepalive :( when that time is up, restart the connection and tell the user
|
||||
# that their time is up, insert another coin. (reload)
|
||||
#
|
||||
# Bigger picture
|
||||
# - It's horrible that we have this click+wait deal, some nice socket.io solution using something similar
|
||||
# to what the browserless debug UI already gives us would be smarter..
|
||||
#
|
||||
# OR
|
||||
# - Some API call that should be hacked into browserless or playwright that we can "/api/bump-keepalive/{session_id}/60"
|
||||
# So we can tell it that we need more time (run this on each action)
|
||||
#
|
||||
# OR
|
||||
# - use multiprocessing to bump this over to its own process and add some transport layer (queue/pipes)
|
||||
|
||||
from distutils.util import strtobool
|
||||
from flask import Blueprint, request, make_response
|
||||
import os
|
||||
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
from changedetectionio.flask_app import login_optionally_required
|
||||
from loguru import logger
|
||||
|
||||
browsersteps_sessions = {}
|
||||
io_interface_context = None
|
||||
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore):
|
||||
browser_steps_blueprint = Blueprint('browser_steps', __name__, template_folder="templates")
|
||||
|
||||
def start_browsersteps_session(watch_uuid):
|
||||
from . import nonContext
|
||||
from . import browser_steps
|
||||
import time
|
||||
global browsersteps_sessions
|
||||
global io_interface_context
|
||||
|
||||
|
||||
# We keep the playwright session open for many minutes
|
||||
keepalive_seconds = int(os.getenv('BROWSERSTEPS_MINUTES_KEEPALIVE', 10)) * 60
|
||||
|
||||
browsersteps_start_session = {'start_time': time.time()}
|
||||
|
||||
# You can only have one of these running
|
||||
# This should be very fine to leave running for the life of the application
|
||||
# @idea - Make it global so the pool of watch fetchers can use it also
|
||||
if not io_interface_context:
|
||||
io_interface_context = nonContext.c_sync_playwright()
|
||||
# Start the Playwright context, which is actually a nodejs sub-process and communicates over STDIN/STDOUT pipes
|
||||
io_interface_context = io_interface_context.start()
|
||||
|
||||
keepalive_ms = ((keepalive_seconds + 3) * 1000)
|
||||
base_url = os.getenv('PLAYWRIGHT_DRIVER_URL', '').strip('"')
|
||||
a = "?" if not '?' in base_url else '&'
|
||||
base_url += a + f"timeout={keepalive_ms}"
|
||||
|
||||
try:
|
||||
browsersteps_start_session['browser'] = io_interface_context.chromium.connect_over_cdp(base_url)
|
||||
except Exception as e:
|
||||
if 'ECONNREFUSED' in str(e):
|
||||
return make_response('Unable to start the Playwright Browser session, is it running?', 401)
|
||||
else:
|
||||
# Other errors, bad URL syntax, bad reply etc
|
||||
return make_response(str(e), 401)
|
||||
|
||||
proxy_id = datastore.get_preferred_proxy_for_watch(uuid=watch_uuid)
|
||||
proxy = None
|
||||
if proxy_id:
|
||||
proxy_url = datastore.proxy_list.get(proxy_id).get('url')
|
||||
if proxy_url:
|
||||
|
||||
# Playwright needs separate username and password values
|
||||
from urllib.parse import urlparse
|
||||
parsed = urlparse(proxy_url)
|
||||
proxy = {'server': proxy_url}
|
||||
|
||||
if parsed.username:
|
||||
proxy['username'] = parsed.username
|
||||
|
||||
if parsed.password:
|
||||
proxy['password'] = parsed.password
|
||||
|
||||
logger.debug(f"Browser Steps: UUID {watch_uuid} selected proxy {proxy_url}")
|
||||
|
||||
# Tell Playwright to connect to Chrome and setup a new session via our stepper interface
|
||||
browsersteps_start_session['browserstepper'] = browser_steps.browsersteps_live_ui(
|
||||
playwright_browser=browsersteps_start_session['browser'],
|
||||
proxy=proxy)
|
||||
|
||||
# For test
|
||||
#browsersteps_start_session['browserstepper'].action_goto_url(value="http://example.com?time="+str(time.time()))
|
||||
|
||||
return browsersteps_start_session
|
||||
|
||||
|
||||
@login_optionally_required
|
||||
@browser_steps_blueprint.route("/browsersteps_start_session", methods=['GET'])
|
||||
def browsersteps_start_session():
|
||||
# A new session was requested, return sessionID
|
||||
|
||||
import uuid
|
||||
global browsersteps_sessions
|
||||
|
||||
browsersteps_session_id = str(uuid.uuid4())
|
||||
watch_uuid = request.args.get('uuid')
|
||||
|
||||
if not watch_uuid:
|
||||
return make_response('No Watch UUID specified', 500)
|
||||
|
||||
logger.debug("Starting connection with playwright")
|
||||
logger.debug("browser_steps.py connecting")
|
||||
browsersteps_sessions[browsersteps_session_id] = start_browsersteps_session(watch_uuid)
|
||||
logger.debug("Starting connection with playwright - done")
|
||||
return {'browsersteps_session_id': browsersteps_session_id}
|
||||
|
||||
@login_optionally_required
|
||||
@browser_steps_blueprint.route("/browsersteps_image", methods=['GET'])
|
||||
def browser_steps_fetch_screenshot_image():
|
||||
from flask import (
|
||||
make_response,
|
||||
request,
|
||||
send_from_directory,
|
||||
)
|
||||
uuid = request.args.get('uuid')
|
||||
step_n = int(request.args.get('step_n'))
|
||||
|
||||
watch = datastore.data['watching'].get(uuid)
|
||||
filename = f"step_before-{step_n}.jpeg" if request.args.get('type', '') == 'before' else f"step_{step_n}.jpeg"
|
||||
|
||||
if step_n and watch and os.path.isfile(os.path.join(watch.watch_data_dir, filename)):
|
||||
response = make_response(send_from_directory(directory=watch.watch_data_dir, path=filename))
|
||||
response.headers['Content-type'] = 'image/jpeg'
|
||||
response.headers['Cache-Control'] = 'no-cache, no-store, must-revalidate'
|
||||
response.headers['Pragma'] = 'no-cache'
|
||||
response.headers['Expires'] = 0
|
||||
return response
|
||||
|
||||
else:
|
||||
return make_response('Unable to fetch image, is the URL correct? does the watch exist? does the step_type-n.jpeg exist?', 401)
|
||||
|
||||
# A request for an action was received
|
||||
@login_optionally_required
|
||||
@browser_steps_blueprint.route("/browsersteps_update", methods=['POST'])
|
||||
def browsersteps_ui_update():
|
||||
import base64
|
||||
import playwright._impl._errors
|
||||
global browsersteps_sessions
|
||||
from changedetectionio.blueprint.browser_steps import browser_steps
|
||||
|
||||
remaining =0
|
||||
uuid = request.args.get('uuid')
|
||||
|
||||
browsersteps_session_id = request.args.get('browsersteps_session_id')
|
||||
|
||||
if not browsersteps_session_id:
|
||||
return make_response('No browsersteps_session_id specified', 500)
|
||||
|
||||
if not browsersteps_sessions.get(browsersteps_session_id):
|
||||
return make_response('No session exists under that ID', 500)
|
||||
|
||||
|
||||
# Actions - step/apply/etc, do the thing and return state
|
||||
if request.method == 'POST':
|
||||
# @todo - should always be an existing session
|
||||
step_operation = request.form.get('operation')
|
||||
step_selector = request.form.get('selector')
|
||||
step_optional_value = request.form.get('optional_value')
|
||||
step_n = int(request.form.get('step_n'))
|
||||
is_last_step = strtobool(request.form.get('is_last_step'))
|
||||
|
||||
if step_operation == 'Goto site':
|
||||
step_operation = 'goto_url'
|
||||
step_optional_value = datastore.data['watching'][uuid].get('url')
|
||||
step_selector = None
|
||||
|
||||
# @todo try.. accept.. nice errors not popups..
|
||||
try:
|
||||
|
||||
browsersteps_sessions[browsersteps_session_id]['browserstepper'].call_action(action_name=step_operation,
|
||||
selector=step_selector,
|
||||
optional_value=step_optional_value)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Exception when calling step operation {step_operation} {str(e)}")
|
||||
# Try to find something of value to give back to the user
|
||||
return make_response(str(e).splitlines()[0], 401)
|
||||
|
||||
# Get visual selector ready/update its data (also use the current filter info from the page?)
|
||||
# When the last 'apply' button was pressed
|
||||
# @todo this adds overhead because the xpath selection is happening twice
|
||||
u = browsersteps_sessions[browsersteps_session_id]['browserstepper'].page.url
|
||||
if is_last_step and u:
|
||||
(screenshot, xpath_data) = browsersteps_sessions[browsersteps_session_id]['browserstepper'].request_visualselector_data()
|
||||
datastore.save_screenshot(watch_uuid=uuid, screenshot=screenshot)
|
||||
datastore.save_xpath_data(watch_uuid=uuid, data=xpath_data)
|
||||
|
||||
# if not this_session.page:
|
||||
# cleanup_playwright_session()
|
||||
# return make_response('Browser session ran out of time :( Please reload this page.', 401)
|
||||
|
||||
# Screenshots and other info only needed on requesting a step (POST)
|
||||
try:
|
||||
state = browsersteps_sessions[browsersteps_session_id]['browserstepper'].get_current_state()
|
||||
except playwright._impl._api_types.Error as e:
|
||||
return make_response("Browser session ran out of time :( Please reload this page."+str(e), 401)
|
||||
|
||||
# Use send_file() which is way faster than read/write loop on bytes
|
||||
import json
|
||||
from tempfile import mkstemp
|
||||
from flask import send_file
|
||||
tmp_fd, tmp_file = mkstemp(text=True, suffix=".json", prefix="changedetectionio-")
|
||||
|
||||
output = json.dumps({'screenshot': "data:image/jpeg;base64,{}".format(
|
||||
base64.b64encode(state[0]).decode('ascii')),
|
||||
'xpath_data': state[1],
|
||||
'session_age_start': browsersteps_sessions[browsersteps_session_id]['browserstepper'].age_start,
|
||||
'browser_time_remaining': round(remaining)
|
||||
})
|
||||
|
||||
with os.fdopen(tmp_fd, 'w') as f:
|
||||
f.write(output)
|
||||
|
||||
response = make_response(send_file(path_or_file=tmp_file,
|
||||
mimetype='application/json; charset=UTF-8',
|
||||
etag=True))
|
||||
# No longer needed
|
||||
os.unlink(tmp_file)
|
||||
|
||||
return response
|
||||
|
||||
return browser_steps_blueprint
|
||||
|
||||
|
||||
@@ -1,287 +0,0 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
from random import randint
|
||||
from loguru import logger
|
||||
|
||||
# Two flags, tell the JS which of the "Selector" or "Value" field should be enabled in the front end
|
||||
# 0- off, 1- on
|
||||
browser_step_ui_config = {'Choose one': '0 0',
|
||||
# 'Check checkbox': '1 0',
|
||||
# 'Click button containing text': '0 1',
|
||||
# 'Scroll to bottom': '0 0',
|
||||
# 'Scroll to element': '1 0',
|
||||
# 'Scroll to top': '0 0',
|
||||
# 'Switch to iFrame by index number': '0 1'
|
||||
# 'Uncheck checkbox': '1 0',
|
||||
# @todo
|
||||
'Check checkbox': '1 0',
|
||||
'Click X,Y': '0 1',
|
||||
'Click element if exists': '1 0',
|
||||
'Click element': '1 0',
|
||||
'Click element containing text': '0 1',
|
||||
'Enter text in field': '1 1',
|
||||
'Execute JS': '0 1',
|
||||
# 'Extract text and use as filter': '1 0',
|
||||
'Goto site': '0 0',
|
||||
'Goto URL': '0 1',
|
||||
'Press Enter': '0 0',
|
||||
'Select by label': '1 1',
|
||||
'Scroll down': '0 0',
|
||||
'Uncheck checkbox': '1 0',
|
||||
'Wait for seconds': '0 1',
|
||||
'Wait for text': '0 1',
|
||||
'Wait for text in element': '1 1',
|
||||
# 'Press Page Down': '0 0',
|
||||
# 'Press Page Up': '0 0',
|
||||
# weird bug, come back to it later
|
||||
}
|
||||
|
||||
|
||||
# Good reference - https://playwright.dev/python/docs/input
|
||||
# https://pythonmana.com/2021/12/202112162236307035.html
|
||||
#
|
||||
# ONLY Works in Playwright because we need the fullscreen screenshot
|
||||
class steppable_browser_interface():
|
||||
page = None
|
||||
|
||||
# Convert and perform "Click Button" for example
|
||||
def call_action(self, action_name, selector=None, optional_value=None):
|
||||
now = time.time()
|
||||
call_action_name = re.sub('[^0-9a-zA-Z]+', '_', action_name.lower())
|
||||
if call_action_name == 'choose_one':
|
||||
return
|
||||
|
||||
logger.debug(f"> Action calling '{call_action_name}'")
|
||||
# https://playwright.dev/python/docs/selectors#xpath-selectors
|
||||
if selector and selector.startswith('/') and not selector.startswith('//'):
|
||||
selector = "xpath=" + selector
|
||||
|
||||
action_handler = getattr(self, "action_" + call_action_name)
|
||||
|
||||
# Support for Jinja2 variables in the value and selector
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
if selector and ('{%' in selector or '{{' in selector):
|
||||
selector = str(jinja2_env.from_string(selector).render())
|
||||
|
||||
if optional_value and ('{%' in optional_value or '{{' in optional_value):
|
||||
optional_value = str(jinja2_env.from_string(optional_value).render())
|
||||
|
||||
action_handler(selector, optional_value)
|
||||
self.page.wait_for_timeout(1.5 * 1000)
|
||||
logger.debug(f"Call action done in {time.time()-now:.2f}s")
|
||||
|
||||
def action_goto_url(self, selector=None, value=None):
|
||||
# self.page.set_viewport_size({"width": 1280, "height": 5000})
|
||||
now = time.time()
|
||||
response = self.page.goto(value, timeout=0, wait_until='load')
|
||||
# Should be the same as the puppeteer_fetch.js methods, means, load with no timeout set (skip timeout)
|
||||
#and also wait for seconds ?
|
||||
#await page.waitForTimeout(1000);
|
||||
#await page.waitForTimeout(extra_wait_ms);
|
||||
logger.debug(f"Time to goto URL {time.time()-now:.2f}s")
|
||||
return response
|
||||
|
||||
def action_click_element_containing_text(self, selector=None, value=''):
|
||||
if not len(value.strip()):
|
||||
return
|
||||
elem = self.page.get_by_text(value)
|
||||
if elem.count():
|
||||
elem.first.click(delay=randint(200, 500), timeout=3000)
|
||||
|
||||
def action_enter_text_in_field(self, selector, value):
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
|
||||
self.page.fill(selector, value, timeout=10 * 1000)
|
||||
|
||||
def action_execute_js(self, selector, value):
|
||||
response = self.page.evaluate(value)
|
||||
return response
|
||||
|
||||
def action_click_element(self, selector, value):
|
||||
logger.debug("Clicking element")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
|
||||
self.page.click(selector=selector, timeout=30 * 1000, delay=randint(200, 500))
|
||||
|
||||
def action_click_element_if_exists(self, selector, value):
|
||||
import playwright._impl._errors as _api_types
|
||||
logger.debug("Clicking element if exists")
|
||||
if not len(selector.strip()):
|
||||
return
|
||||
try:
|
||||
self.page.click(selector, timeout=10 * 1000, delay=randint(200, 500))
|
||||
except _api_types.TimeoutError as e:
|
||||
return
|
||||
except _api_types.Error as e:
|
||||
# Element was there, but page redrew and now its long long gone
|
||||
return
|
||||
|
||||
def action_click_x_y(self, selector, value):
|
||||
if not re.match(r'^\s?\d+\s?,\s?\d+\s?$', value):
|
||||
raise Exception("'Click X,Y' step should be in the format of '100 , 90'")
|
||||
|
||||
x, y = value.strip().split(',')
|
||||
x = int(float(x.strip()))
|
||||
y = int(float(y.strip()))
|
||||
self.page.mouse.click(x=x, y=y, delay=randint(200, 500))
|
||||
|
||||
def action_scroll_down(self, selector, value):
|
||||
# Some sites this doesnt work on for some reason
|
||||
self.page.mouse.wheel(0, 600)
|
||||
self.page.wait_for_timeout(1000)
|
||||
|
||||
def action_wait_for_seconds(self, selector, value):
|
||||
self.page.wait_for_timeout(float(value.strip()) * 1000)
|
||||
|
||||
def action_wait_for_text(self, selector, value):
|
||||
import json
|
||||
v = json.dumps(value)
|
||||
self.page.wait_for_function(f'document.querySelector("body").innerText.includes({v});', timeout=30000)
|
||||
|
||||
def action_wait_for_text_in_element(self, selector, value):
|
||||
import json
|
||||
s = json.dumps(selector)
|
||||
v = json.dumps(value)
|
||||
self.page.wait_for_function(f'document.querySelector({s}).innerText.includes({v});', timeout=30000)
|
||||
|
||||
# @todo - in the future make some popout interface to capture what needs to be set
|
||||
# https://playwright.dev/python/docs/api/class-keyboard
|
||||
def action_press_enter(self, selector, value):
|
||||
self.page.keyboard.press("Enter", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_up(self, selector, value):
|
||||
self.page.keyboard.press("PageUp", delay=randint(200, 500))
|
||||
|
||||
def action_press_page_down(self, selector, value):
|
||||
self.page.keyboard.press("PageDown", delay=randint(200, 500))
|
||||
|
||||
def action_check_checkbox(self, selector, value):
|
||||
self.page.locator(selector).check(timeout=1000)
|
||||
|
||||
def action_uncheck_checkbox(self, selector, value):
|
||||
self.page.locator(selector, timeout=1000).uncheck(timeout=1000)
|
||||
|
||||
|
||||
# Responsible for maintaining a live 'context' with browserless
|
||||
# @todo - how long do contexts live for anyway?
|
||||
class browsersteps_live_ui(steppable_browser_interface):
|
||||
context = None
|
||||
page = None
|
||||
render_extra_delay = 1
|
||||
stale = False
|
||||
# bump and kill this if idle after X sec
|
||||
age_start = 0
|
||||
|
||||
# use a special driver, maybe locally etc
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_BROWSERSTEPS_DRIVER_URL"
|
||||
)
|
||||
# if not..
|
||||
if not command_executor:
|
||||
command_executor = os.getenv(
|
||||
"PLAYWRIGHT_DRIVER_URL",
|
||||
'ws://playwright-chrome:3000'
|
||||
).strip('"')
|
||||
|
||||
browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
|
||||
def __init__(self, playwright_browser, proxy=None):
|
||||
self.age_start = time.time()
|
||||
self.playwright_browser = playwright_browser
|
||||
if self.context is None:
|
||||
self.connect(proxy=proxy)
|
||||
|
||||
# Connect and setup a new context
|
||||
def connect(self, proxy=None):
|
||||
# Should only get called once - test that
|
||||
keep_open = 1000 * 60 * 5
|
||||
now = time.time()
|
||||
|
||||
# @todo handle multiple contexts, bind a unique id from the browser on each req?
|
||||
self.context = self.playwright_browser.new_context(
|
||||
# @todo
|
||||
# user_agent=request_headers['User-Agent'] if request_headers.get('User-Agent') else 'Mozilla/5.0',
|
||||
# proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should never be needed
|
||||
accept_downloads=False,
|
||||
proxy=proxy
|
||||
)
|
||||
|
||||
self.page = self.context.new_page()
|
||||
|
||||
# self.page.set_default_navigation_timeout(keep_open)
|
||||
self.page.set_default_timeout(keep_open)
|
||||
# @todo probably this doesnt work
|
||||
self.page.on(
|
||||
"close",
|
||||
self.mark_as_closed,
|
||||
)
|
||||
# Listen for all console events and handle errors
|
||||
self.page.on("console", lambda msg: print(f"Browser steps console - {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
logger.debug(f"Time to browser setup {time.time()-now:.2f}s")
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
def mark_as_closed(self):
|
||||
logger.debug("Page closed, cleaning up..")
|
||||
|
||||
@property
|
||||
def has_expired(self):
|
||||
if not self.page:
|
||||
return True
|
||||
|
||||
|
||||
def get_current_state(self):
|
||||
"""Return the screenshot and interactive elements mapping, generally always called after action_()"""
|
||||
from pkg_resources import resource_string
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
now = time.time()
|
||||
self.page.wait_for_timeout(1 * 1000)
|
||||
|
||||
# The actual screenshot
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=40)
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
# Go find the interactive elements
|
||||
# @todo in the future, something smarter that can scan for elements with .click/focus etc event handlers?
|
||||
elements = 'a,button,input,select,textarea,i,th,td,p,li,h1,h2,h3,h4,div,span'
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', elements)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
# So the JS will find the smallest one first
|
||||
xpath_data['size_pos'] = sorted(xpath_data['size_pos'], key=lambda k: k['width'] * k['height'], reverse=True)
|
||||
logger.debug(f"Time to complete get_current_state of browser {time.time()-now:.2f}s")
|
||||
# except
|
||||
# playwright._impl._api_types.Error: Browser closed.
|
||||
# @todo show some countdown timer?
|
||||
return (screenshot, xpath_data)
|
||||
|
||||
def request_visualselector_data(self):
|
||||
"""
|
||||
Does the same that the playwright operation in content_fetcher does
|
||||
This is used to just bump the VisualSelector data so it' ready to go if they click on the tab
|
||||
@todo refactor and remove duplicate code, add include_filters
|
||||
:param xpath_data:
|
||||
:param screenshot:
|
||||
:param current_include_filters:
|
||||
:return:
|
||||
"""
|
||||
|
||||
self.page.evaluate("var include_filters=''")
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
xpath_element_js = resource_string(__name__, "../../res/xpath_element_scraper.js").decode('utf-8')
|
||||
from changedetectionio.content_fetcher import visualselector_xpath_selectors
|
||||
xpath_element_js = xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
|
||||
xpath_data = self.page.evaluate("async () => {" + xpath_element_js + "}")
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
|
||||
return (screenshot, xpath_data)
|
||||
@@ -1,18 +0,0 @@
|
||||
from playwright.sync_api import PlaywrightContextManager
|
||||
import asyncio
|
||||
|
||||
# So playwright wants to run as a context manager, but we do something horrible and hacky
|
||||
# we are holding the session open for as long as possible, then shutting it down, and opening a new one
|
||||
# So it means we don't get to use PlaywrightContextManager' __enter__ __exit__
|
||||
# To work around this, make goodbye() act the same as the __exit__()
|
||||
#
|
||||
# But actually I think this is because the context is opened correctly with __enter__() but we timeout the connection
|
||||
# then theres some lock condition where we cant destroy it without it hanging
|
||||
|
||||
class c_PlaywrightContextManager(PlaywrightContextManager):
|
||||
|
||||
def goodbye(self) -> None:
|
||||
self.__exit__()
|
||||
|
||||
def c_sync_playwright() -> PlaywrightContextManager:
|
||||
return c_PlaywrightContextManager()
|
||||
@@ -1,118 +0,0 @@
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
from functools import wraps
|
||||
|
||||
from flask import Blueprint
|
||||
from flask_login import login_required
|
||||
|
||||
from changedetectionio.processors import text_json_diff
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
|
||||
|
||||
STATUS_CHECKING = 0
|
||||
STATUS_FAILED = 1
|
||||
STATUS_OK = 2
|
||||
THREADPOOL_MAX_WORKERS = 3
|
||||
_DEFAULT_POOL = ThreadPoolExecutor(max_workers=THREADPOOL_MAX_WORKERS)
|
||||
|
||||
|
||||
# Maybe use fetch-time if its >5 to show some expected load time?
|
||||
def threadpool(f, executor=None):
|
||||
@wraps(f)
|
||||
def wrap(*args, **kwargs):
|
||||
return (executor or _DEFAULT_POOL).submit(f, *args, **kwargs)
|
||||
|
||||
return wrap
|
||||
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore):
|
||||
check_proxies_blueprint = Blueprint('check_proxies', __name__)
|
||||
checks_in_progress = {}
|
||||
|
||||
@threadpool
|
||||
def long_task(uuid, preferred_proxy):
|
||||
import time
|
||||
from changedetectionio import content_fetcher
|
||||
|
||||
status = {'status': '', 'length': 0, 'text': ''}
|
||||
from jinja2 import Environment, BaseLoader
|
||||
|
||||
contents = ''
|
||||
now = time.time()
|
||||
try:
|
||||
update_handler = text_json_diff.perform_site_check(datastore=datastore, watch_uuid=uuid)
|
||||
update_handler.call_browser()
|
||||
# title, size is len contents not len xfer
|
||||
except content_fetcher.Non200ErrorCodeReceived as e:
|
||||
if e.status_code == 404:
|
||||
status.update({'status': 'OK', 'length': len(contents), 'text': f"OK but 404 (page not found)"})
|
||||
elif e.status_code == 403 or e.status_code == 401:
|
||||
status.update({'status': 'ERROR', 'length': len(contents), 'text': f"{e.status_code} - Access denied"})
|
||||
else:
|
||||
status.update({'status': 'ERROR', 'length': len(contents), 'text': f"Status code: {e.status_code}"})
|
||||
except text_json_diff.FilterNotFoundInResponse:
|
||||
status.update({'status': 'OK', 'length': len(contents), 'text': f"OK but CSS/xPath filter not found (page changed layout?)"})
|
||||
except content_fetcher.EmptyReply as e:
|
||||
if e.status_code == 403 or e.status_code == 401:
|
||||
status.update({'status': 'ERROR OTHER', 'length': len(contents), 'text': f"Got empty reply with code {e.status_code} - Access denied"})
|
||||
else:
|
||||
status.update({'status': 'ERROR OTHER', 'length': len(contents) if contents else 0, 'text': f"Empty reply with code {e.status_code}, needs chrome?"})
|
||||
except content_fetcher.ReplyWithContentButNoText as e:
|
||||
txt = f"Got reply but with no content - Status code {e.status_code} - It's possible that the filters were found, but contained no usable text (or contained only an image)."
|
||||
status.update({'status': 'ERROR', 'text': txt})
|
||||
except Exception as e:
|
||||
status.update({'status': 'ERROR OTHER', 'length': len(contents) if contents else 0, 'text': 'Error: '+type(e).__name__+str(e)})
|
||||
else:
|
||||
status.update({'status': 'OK', 'length': len(contents), 'text': ''})
|
||||
|
||||
if status.get('text'):
|
||||
status['text'] = Environment(loader=BaseLoader()).from_string('{{text|e}}').render({'text': status['text']})
|
||||
|
||||
status['time'] = "{:.2f}s".format(time.time() - now)
|
||||
|
||||
return status
|
||||
|
||||
def _recalc_check_status(uuid):
|
||||
|
||||
results = {}
|
||||
for k, v in checks_in_progress.get(uuid, {}).items():
|
||||
try:
|
||||
r_1 = v.result(timeout=0.05)
|
||||
except Exception as e:
|
||||
# If timeout error?
|
||||
results[k] = {'status': 'RUNNING'}
|
||||
|
||||
else:
|
||||
results[k] = r_1
|
||||
|
||||
return results
|
||||
|
||||
@login_required
|
||||
@check_proxies_blueprint.route("/<string:uuid>/status", methods=['GET'])
|
||||
def get_recheck_status(uuid):
|
||||
results = _recalc_check_status(uuid=uuid)
|
||||
return results
|
||||
|
||||
@login_required
|
||||
@check_proxies_blueprint.route("/<string:uuid>/start", methods=['GET'])
|
||||
def start_check(uuid):
|
||||
|
||||
if not datastore.proxy_list:
|
||||
return
|
||||
|
||||
if checks_in_progress.get(uuid):
|
||||
state = _recalc_check_status(uuid=uuid)
|
||||
for proxy_key, v in state.items():
|
||||
if v.get('status') == 'RUNNING':
|
||||
return state
|
||||
else:
|
||||
checks_in_progress[uuid] = {}
|
||||
|
||||
for k, v in datastore.proxy_list.items():
|
||||
if not checks_in_progress[uuid].get(k):
|
||||
checks_in_progress[uuid][k] = long_task(uuid=uuid, preferred_proxy=k)
|
||||
|
||||
results = _recalc_check_status(uuid=uuid)
|
||||
return results
|
||||
|
||||
return check_proxies_blueprint
|
||||
@@ -1,33 +0,0 @@
|
||||
|
||||
from distutils.util import strtobool
|
||||
from flask import Blueprint, flash, redirect, url_for
|
||||
from flask_login import login_required
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
from changedetectionio import queuedWatchMetaData
|
||||
from queue import PriorityQueue
|
||||
|
||||
PRICE_DATA_TRACK_ACCEPT = 'accepted'
|
||||
PRICE_DATA_TRACK_REJECT = 'rejected'
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore, update_q: PriorityQueue):
|
||||
|
||||
price_data_follower_blueprint = Blueprint('price_data_follower', __name__)
|
||||
|
||||
@login_required
|
||||
@price_data_follower_blueprint.route("/<string:uuid>/accept", methods=['GET'])
|
||||
def accept(uuid):
|
||||
datastore.data['watching'][uuid]['track_ldjson_price_data'] = PRICE_DATA_TRACK_ACCEPT
|
||||
update_q.put(queuedWatchMetaData.PrioritizedItem(priority=1, item={'uuid': uuid, 'skip_when_checksum_same': False}))
|
||||
return redirect(url_for("form_watch_checknow", uuid=uuid))
|
||||
|
||||
|
||||
@login_required
|
||||
@price_data_follower_blueprint.route("/<string:uuid>/reject", methods=['GET'])
|
||||
def reject(uuid):
|
||||
datastore.data['watching'][uuid]['track_ldjson_price_data'] = PRICE_DATA_TRACK_REJECT
|
||||
return redirect(url_for("index"))
|
||||
|
||||
|
||||
return price_data_follower_blueprint
|
||||
|
||||
|
||||
@@ -1,9 +0,0 @@
|
||||
# Groups tags
|
||||
|
||||
## How it works
|
||||
|
||||
Watch has a list() of tag UUID's, which relate to a config under application.settings.tags
|
||||
|
||||
The 'tag' is actually a watch, because they basically will eventually share 90% of the same config.
|
||||
|
||||
So a tag is like an abstract of a watch
|
||||
@@ -1,141 +0,0 @@
|
||||
from flask import Blueprint, request, make_response, render_template, flash, url_for, redirect
|
||||
from changedetectionio.store import ChangeDetectionStore
|
||||
from changedetectionio.flask_app import login_optionally_required
|
||||
|
||||
|
||||
def construct_blueprint(datastore: ChangeDetectionStore):
|
||||
tags_blueprint = Blueprint('tags', __name__, template_folder="templates")
|
||||
|
||||
@tags_blueprint.route("/list", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def tags_overview_page():
|
||||
from .form import SingleTag
|
||||
add_form = SingleTag(request.form)
|
||||
output = render_template("groups-overview.html",
|
||||
form=add_form,
|
||||
available_tags=datastore.data['settings']['application'].get('tags', {}),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
@tags_blueprint.route("/add", methods=['POST'])
|
||||
@login_optionally_required
|
||||
def form_tag_add():
|
||||
from .form import SingleTag
|
||||
add_form = SingleTag(request.form)
|
||||
|
||||
if not add_form.validate():
|
||||
for widget, l in add_form.errors.items():
|
||||
flash(','.join(l), 'error')
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
title = request.form.get('name').strip()
|
||||
|
||||
if datastore.tag_exists_by_name(title):
|
||||
flash(f'The tag "{title}" already exists', "error")
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
datastore.add_tag(title)
|
||||
flash("Tag added")
|
||||
|
||||
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
@tags_blueprint.route("/mute/<string:uuid>", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def mute(uuid):
|
||||
if datastore.data['settings']['application']['tags'].get(uuid):
|
||||
datastore.data['settings']['application']['tags'][uuid]['notification_muted'] = not datastore.data['settings']['application']['tags'][uuid]['notification_muted']
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
@tags_blueprint.route("/delete/<string:uuid>", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def delete(uuid):
|
||||
removed = 0
|
||||
# Delete the tag, and any tag reference
|
||||
if datastore.data['settings']['application']['tags'].get(uuid):
|
||||
del datastore.data['settings']['application']['tags'][uuid]
|
||||
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
if watch.get('tags') and uuid in watch['tags']:
|
||||
removed += 1
|
||||
watch['tags'].remove(uuid)
|
||||
|
||||
flash(f"Tag deleted and removed from {removed} watches")
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
@tags_blueprint.route("/unlink/<string:uuid>", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def unlink(uuid):
|
||||
unlinked = 0
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
if watch.get('tags') and uuid in watch['tags']:
|
||||
unlinked += 1
|
||||
watch['tags'].remove(uuid)
|
||||
|
||||
flash(f"Tag unlinked removed from {unlinked} watches")
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
@tags_blueprint.route("/delete_all", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def delete_all():
|
||||
for watch_uuid, watch in datastore.data['watching'].items():
|
||||
watch['tags'] = []
|
||||
datastore.data['settings']['application']['tags'] = {}
|
||||
|
||||
flash(f"All tags deleted")
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
@tags_blueprint.route("/edit/<string:uuid>", methods=['GET'])
|
||||
@login_optionally_required
|
||||
def form_tag_edit(uuid):
|
||||
from changedetectionio import forms
|
||||
|
||||
if uuid == 'first':
|
||||
uuid = list(datastore.data['settings']['application']['tags'].keys()).pop()
|
||||
|
||||
default = datastore.data['settings']['application']['tags'].get(uuid)
|
||||
|
||||
form = forms.watchForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=default,
|
||||
)
|
||||
form.datastore=datastore # needed?
|
||||
|
||||
output = render_template("edit-tag.html",
|
||||
data=default,
|
||||
form=form,
|
||||
settings_application=datastore.data['settings']['application'],
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@tags_blueprint.route("/edit/<string:uuid>", methods=['POST'])
|
||||
@login_optionally_required
|
||||
def form_tag_edit_submit(uuid):
|
||||
from changedetectionio import forms
|
||||
if uuid == 'first':
|
||||
uuid = list(datastore.data['settings']['application']['tags'].keys()).pop()
|
||||
|
||||
default = datastore.data['settings']['application']['tags'].get(uuid)
|
||||
|
||||
form = forms.watchForm(formdata=request.form if request.method == 'POST' else None,
|
||||
data=default,
|
||||
)
|
||||
# @todo subclass form so validation works
|
||||
#if not form.validate():
|
||||
# for widget, l in form.errors.items():
|
||||
# flash(','.join(l), 'error')
|
||||
# return redirect(url_for('tags.form_tag_edit_submit', uuid=uuid))
|
||||
|
||||
datastore.data['settings']['application']['tags'][uuid].update(form.data)
|
||||
datastore.needs_write_urgent = True
|
||||
flash("Updated")
|
||||
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
|
||||
|
||||
@tags_blueprint.route("/delete/<string:uuid>", methods=['GET'])
|
||||
def form_tag_delete(uuid):
|
||||
return redirect(url_for('tags.tags_overview_page'))
|
||||
return tags_blueprint
|
||||
@@ -1,22 +0,0 @@
|
||||
from wtforms import (
|
||||
BooleanField,
|
||||
Form,
|
||||
IntegerField,
|
||||
RadioField,
|
||||
SelectField,
|
||||
StringField,
|
||||
SubmitField,
|
||||
TextAreaField,
|
||||
validators,
|
||||
)
|
||||
|
||||
|
||||
|
||||
class SingleTag(Form):
|
||||
|
||||
name = StringField('Tag name', [validators.InputRequired()], render_kw={"placeholder": "Name"})
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,136 +0,0 @@
|
||||
{% extends 'base.html' %}
|
||||
{% block content %}
|
||||
{% from '_helpers.jinja' import render_field, render_checkbox_field, render_button %}
|
||||
{% from '_common_fields.jinja' import render_common_settings_form %}
|
||||
<script>
|
||||
const notification_base_url="{{url_for('ajax_callback_send_notification_test', watch_uuid=uuid)}}";
|
||||
</script>
|
||||
|
||||
<script src="{{url_for('static_content', group='js', filename='tabs.js')}}" defer></script>
|
||||
<script>
|
||||
|
||||
/*{% if emailprefix %}*/
|
||||
/*const email_notification_prefix=JSON.parse('{{ emailprefix|tojson }}');*/
|
||||
/*{% endif %}*/
|
||||
|
||||
|
||||
</script>
|
||||
|
||||
<script src="{{url_for('static_content', group='js', filename='watch-settings.js')}}" defer></script>
|
||||
<!--<script src="{{url_for('static_content', group='js', filename='limit.js')}}" defer></script>-->
|
||||
<script src="{{url_for('static_content', group='js', filename='notifications.js')}}" defer></script>
|
||||
|
||||
<div class="edit-form monospaced-textarea">
|
||||
|
||||
<div class="tabs collapsable">
|
||||
<ul>
|
||||
<li class="tab" id=""><a href="#general">General</a></li>
|
||||
<li class="tab"><a href="#filters-and-triggers">Filters & Triggers</a></li>
|
||||
<li class="tab"><a href="#notifications">Notifications</a></li>
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<div class="box-wrap inner">
|
||||
<form class="pure-form pure-form-stacked"
|
||||
action="{{ url_for('tags.form_tag_edit', uuid=data.uuid) }}" method="POST">
|
||||
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}">
|
||||
|
||||
<div class="tab-pane-inner" id="general">
|
||||
<fieldset>
|
||||
<div class="pure-control-group">
|
||||
{{ render_field(form.title, placeholder="https://...", required=true, class="m-d") }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="filters-and-triggers">
|
||||
<div class="pure-control-group">
|
||||
{% set field = render_field(form.include_filters,
|
||||
rows=5,
|
||||
placeholder="#example
|
||||
xpath://body/div/span[contains(@class, 'example-class')]",
|
||||
class="m-d")
|
||||
%}
|
||||
{{ field }}
|
||||
{% if '/text()' in field %}
|
||||
<span class="pure-form-message-inline"><strong>Note!: //text() function does not work where the <element> contains <![CDATA[]]></strong></span><br>
|
||||
{% endif %}
|
||||
<span class="pure-form-message-inline">One rule per line, <i>any</i> rules that matches will be used.<br>
|
||||
|
||||
<ul>
|
||||
<li>CSS - Limit text to this CSS rule, only text matching this CSS rule is included.</li>
|
||||
<li>JSON - Limit text to this JSON rule, using either <a href="https://pypi.org/project/jsonpath-ng/" target="new">JSONPath</a> or <a href="https://stedolan.github.io/jq/" target="new">jq</a> (if installed).
|
||||
<ul>
|
||||
<li>JSONPath: Prefix with <code>json:</code>, use <code>json:$</code> to force re-formatting if required, <a href="https://jsonpath.com/" target="new">test your JSONPath here</a>.</li>
|
||||
{% if jq_support %}
|
||||
<li>jq: Prefix with <code>jq:</code> and <a href="https://jqplay.org/" target="new">test your jq here</a>. Using <a href="https://stedolan.github.io/jq/" target="new">jq</a> allows for complex filtering and processing of JSON data with built-in functions, regex, filtering, and more. See examples and documentation <a href="https://stedolan.github.io/jq/manual/" target="new">here</a>.</li>
|
||||
{% else %}
|
||||
<li>jq support not installed</li>
|
||||
{% endif %}
|
||||
</ul>
|
||||
</li>
|
||||
<li>XPath - Limit text to this XPath rule, simply start with a forward-slash. To specify XPath to be used explicitly or the XPath rule starts with an XPath function: Prefix with <code>xpath:</code>
|
||||
<ul>
|
||||
<li>Example: <code>//*[contains(@class, 'sametext')]</code> or <code>xpath:count(//*[contains(@class, 'sametext')])</code>, <a
|
||||
href="http://xpather.com/" target="new">test your XPath here</a></li>
|
||||
<li>Example: Get all titles from an RSS feed <code>//title/text()</code></li>
|
||||
<li>To use XPath1.0: Prefix with <code>xpath1:</code></li>
|
||||
</ul>
|
||||
</li>
|
||||
</ul>
|
||||
Please be sure that you thoroughly understand how to write CSS, JSONPath, XPath{% if jq_support %}, or jq selector{%endif%} rules before filing an issue on GitHub! <a
|
||||
href="https://github.com/dgtlmoon/changedetection.io/wiki/CSS-Selector-help">here for more CSS selector help</a>.<br>
|
||||
</span>
|
||||
</div>
|
||||
<fieldset class="pure-control-group">
|
||||
{{ render_field(form.subtractive_selectors, rows=5, placeholder="header
|
||||
footer
|
||||
nav
|
||||
.stockticker") }}
|
||||
<span class="pure-form-message-inline">
|
||||
<ul>
|
||||
<li> Remove HTML element(s) by CSS selector before text conversion. </li>
|
||||
<li> Add multiple elements or CSS selectors per line to ignore multiple parts of the HTML. </li>
|
||||
</ul>
|
||||
</span>
|
||||
</fieldset>
|
||||
|
||||
</div>
|
||||
|
||||
<div class="tab-pane-inner" id="notifications">
|
||||
<fieldset>
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_checkbox_field(form.notification_muted) }}
|
||||
</div>
|
||||
{% if is_html_webdriver %}
|
||||
<div class="pure-control-group inline-radio">
|
||||
{{ render_checkbox_field(form.notification_screenshot) }}
|
||||
<span class="pure-form-message-inline">
|
||||
<strong>Use with caution!</strong> This will easily fill up your email storage quota or flood other storages.
|
||||
</span>
|
||||
</div>
|
||||
{% endif %}
|
||||
<div class="field-group" id="notification-field-group">
|
||||
{% if has_default_notification_urls %}
|
||||
<div class="inline-warning">
|
||||
<img class="inline-warning-icon" src="{{url_for('static_content', group='images', filename='notice.svg')}}" alt="Look out!" title="Lookout!" >
|
||||
There are <a href="{{ url_for('settings_page')}}#notifications">system-wide notification URLs enabled</a>, this form will override notification settings for this watch only ‐ an empty Notification URL list here will still send notifications.
|
||||
</div>
|
||||
{% endif %}
|
||||
<a href="#notifications" id="notification-setting-reset-to-default" class="pure-button button-xsmall" style="right: 20px; top: 20px; position: absolute; background-color: #5f42dd; border-radius: 4px; font-size: 70%; color: #fff">Use system defaults</a>
|
||||
|
||||
{{ render_common_settings_form(form, emailprefix, settings_application) }}
|
||||
</div>
|
||||
</fieldset>
|
||||
</div>
|
||||
|
||||
<div id="actions">
|
||||
<div class="pure-control-group">
|
||||
{{ render_button(form.save_button) }}
|
||||
</div>
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
{% endblock %}
|
||||
@@ -1,60 +0,0 @@
|
||||
{% extends 'base.html' %}
|
||||
{% block content %}
|
||||
{% from '_helpers.jinja' import render_simple_field, render_field %}
|
||||
<script src="{{url_for('static_content', group='js', filename='jquery-3.6.0.min.js')}}"></script>
|
||||
|
||||
<div class="box">
|
||||
<form class="pure-form" action="{{ url_for('tags.form_tag_add') }}" method="POST" id="new-watch-form">
|
||||
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}" >
|
||||
<fieldset>
|
||||
<legend>Add a new organisational tag</legend>
|
||||
<div id="watch-add-wrapper-zone">
|
||||
<div>
|
||||
{{ render_simple_field(form.name, placeholder="watch label / tag") }}
|
||||
</div>
|
||||
<div>
|
||||
{{ render_simple_field(form.save_button, title="Save" ) }}
|
||||
</div>
|
||||
</div>
|
||||
<br>
|
||||
<div style="color: #fff;">Groups allows you to manage filters and notifications for multiple watches under a single organisational tag.</div>
|
||||
</fieldset>
|
||||
</form>
|
||||
<!-- @todo maybe some overview matrix, 'tick' with which has notification, filter rules etc -->
|
||||
<div id="watch-table-wrapper">
|
||||
|
||||
<table class="pure-table pure-table-striped watch-table group-overview-table">
|
||||
<thead>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>Tag / Label name</th>
|
||||
<th></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<!--
|
||||
@Todo - connect Last checked, Last Changed, Number of Watches etc
|
||||
--->
|
||||
{% if not available_tags|length %}
|
||||
<tr>
|
||||
<td colspan="3">No website organisational tags/groups configured</td>
|
||||
</tr>
|
||||
{% endif %}
|
||||
{% for uuid, tag in available_tags.items() %}
|
||||
<tr id="{{ uuid }}" class="{{ loop.cycle('pure-table-odd', 'pure-table-even') }}">
|
||||
<td class="watch-controls">
|
||||
<a class="link-mute state-{{'on' if tag.notification_muted else 'off'}}" href="{{url_for('tags.mute', uuid=tag.uuid)}}"><img src="{{url_for('static_content', group='images', filename='bell-off.svg')}}" alt="Mute notifications" title="Mute notifications" class="icon icon-mute" ></a>
|
||||
</td>
|
||||
<td class="title-col inline">{{tag.title}}</td>
|
||||
<td>
|
||||
<a class="pure-button pure-button-primary" href="{{ url_for('tags.form_tag_edit', uuid=uuid) }}">Edit</a>
|
||||
<a class="pure-button pure-button-primary" href="{{ url_for('tags.delete', uuid=uuid) }}" title="Deletes and removes tag">Delete</a>
|
||||
<a class="pure-button pure-button-primary" href="{{ url_for('tags.unlink', uuid=uuid) }}" title="Keep the tag but unlink any watches">Unlink</a>
|
||||
</td>
|
||||
</tr>
|
||||
{% endfor %}
|
||||
</tbody>
|
||||
</table>
|
||||
</div>
|
||||
</div>
|
||||
{% endblock %}
|
||||
114
changedetectionio/changedetection.py
Executable file
@@ -0,0 +1,114 @@
|
||||
#!/usr/bin/python3
|
||||
|
||||
# Launch as a eventlet.wsgi server instance.
|
||||
|
||||
import getopt
|
||||
import os
|
||||
import sys
|
||||
|
||||
import eventlet
|
||||
import eventlet.wsgi
|
||||
from . import store, changedetection_app
|
||||
from . import __version__
|
||||
|
||||
def main():
|
||||
ssl_mode = False
|
||||
host = ''
|
||||
port = os.environ.get('PORT') or 5000
|
||||
do_cleanup = False
|
||||
datastore_path = None
|
||||
|
||||
# On Windows, create and use a default path.
|
||||
if os.name == 'nt':
|
||||
datastore_path = os.path.expandvars(r'%APPDATA%\changedetection.io')
|
||||
os.makedirs(datastore_path, exist_ok=True)
|
||||
else:
|
||||
# Must be absolute so that send_from_directory doesnt try to make it relative to backend/
|
||||
datastore_path = os.path.join(os.getcwd(), "../datastore")
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "Ccsd:h:p:", "port")
|
||||
except getopt.GetoptError:
|
||||
print('backend.py -s SSL enable -h [host] -p [port] -d [datastore path]')
|
||||
sys.exit(2)
|
||||
|
||||
create_datastore_dir = False
|
||||
|
||||
for opt, arg in opts:
|
||||
# if opt == '--purge':
|
||||
# Remove history, the actual files you need to delete manually.
|
||||
# for uuid, watch in datastore.data['watching'].items():
|
||||
# watch.update({'history': {}, 'last_checked': 0, 'last_changed': 0, 'previous_md5': None})
|
||||
|
||||
if opt == '-s':
|
||||
ssl_mode = True
|
||||
|
||||
if opt == '-h':
|
||||
host = arg
|
||||
|
||||
if opt == '-p':
|
||||
port = int(arg)
|
||||
|
||||
if opt == '-d':
|
||||
datastore_path = arg
|
||||
|
||||
# Cleanup (remove text files that arent in the index)
|
||||
if opt == '-c':
|
||||
do_cleanup = True
|
||||
|
||||
# Create the datadir if it doesnt exist
|
||||
if opt == '-C':
|
||||
create_datastore_dir = True
|
||||
|
||||
# isnt there some @thingy to attach to each route to tell it, that this route needs a datastore
|
||||
app_config = {'datastore_path': datastore_path}
|
||||
|
||||
if not os.path.isdir(app_config['datastore_path']):
|
||||
if create_datastore_dir:
|
||||
os.mkdir(app_config['datastore_path'])
|
||||
else:
|
||||
print(
|
||||
"ERROR: Directory path for the datastore '{}' does not exist, cannot start, please make sure the directory exists or specify a directory with the -d option.\n"
|
||||
"Or use the -C parameter to create the directory.".format(app_config['datastore_path']), file=sys.stderr)
|
||||
sys.exit(2)
|
||||
|
||||
datastore = store.ChangeDetectionStore(datastore_path=app_config['datastore_path'], version_tag=__version__)
|
||||
app = changedetection_app(app_config, datastore)
|
||||
|
||||
# Go into cleanup mode
|
||||
if do_cleanup:
|
||||
datastore.remove_unused_snapshots()
|
||||
|
||||
app.config['datastore_path'] = datastore_path
|
||||
|
||||
|
||||
@app.context_processor
|
||||
def inject_version():
|
||||
return dict(right_sticky="v{}".format(datastore.data['version_tag']),
|
||||
new_version_available=app.config['NEW_VERSION_AVAILABLE'],
|
||||
has_password=datastore.data['settings']['application']['password'] != False
|
||||
)
|
||||
|
||||
# Proxy sub-directory support
|
||||
# Set environment var USE_X_SETTINGS=1 on this script
|
||||
# And then in your proxy_pass settings
|
||||
#
|
||||
# proxy_set_header Host "localhost";
|
||||
# proxy_set_header X-Forwarded-Prefix /app;
|
||||
|
||||
if os.getenv('USE_X_SETTINGS'):
|
||||
print ("USE_X_SETTINGS is ENABLED\n")
|
||||
from werkzeug.middleware.proxy_fix import ProxyFix
|
||||
app.wsgi_app = ProxyFix(app.wsgi_app, x_prefix=1, x_host=1)
|
||||
|
||||
if ssl_mode:
|
||||
# @todo finalise SSL config, but this should get you in the right direction if you need it.
|
||||
eventlet.wsgi.server(eventlet.wrap_ssl(eventlet.listen((host, port)),
|
||||
certfile='cert.pem',
|
||||
keyfile='privkey.pem',
|
||||
server_side=True), app)
|
||||
|
||||
else:
|
||||
eventlet.wsgi.server(eventlet.listen((host, int(port))), app)
|
||||
|
||||
|
||||
@@ -1,126 +1,31 @@
|
||||
from abc import abstractmethod
|
||||
from distutils.util import strtobool
|
||||
from urllib.parse import urlparse
|
||||
from abc import ABC, abstractmethod
|
||||
import chardet
|
||||
import hashlib
|
||||
import json
|
||||
import os
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
import requests
|
||||
import sys
|
||||
import time
|
||||
import urllib.parse
|
||||
from loguru import logger
|
||||
|
||||
visualselector_xpath_selectors = 'div,span,form,table,tbody,tr,td,a,p,ul,li,h1,h2,h3,h4, header, footer, section, article, aside, details, main, nav, section, summary'
|
||||
|
||||
|
||||
class Non200ErrorCodeReceived(Exception):
|
||||
def __init__(self, status_code, url, screenshot=None, xpath_data=None, page_html=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.xpath_data = xpath_data
|
||||
self.page_text = None
|
||||
|
||||
if page_html:
|
||||
from changedetectionio import html_tools
|
||||
self.page_text = html_tools.html_to_text(page_html)
|
||||
return
|
||||
|
||||
|
||||
class checksumFromPreviousCheckWasTheSame(Exception):
|
||||
def __init__(self):
|
||||
return
|
||||
|
||||
|
||||
class JSActionExceptions(Exception):
|
||||
def __init__(self, status_code, url, screenshot, message=''):
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.message = message
|
||||
return
|
||||
|
||||
|
||||
class BrowserStepsStepException(Exception):
|
||||
def __init__(self, step_n, original_e):
|
||||
self.step_n = step_n
|
||||
self.original_e = original_e
|
||||
logger.debug(f"Browser Steps exception at step {self.step_n} {str(original_e)}")
|
||||
return
|
||||
|
||||
|
||||
class PageUnloadable(Exception):
|
||||
def __init__(self, status_code, url, message, screenshot=False):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.message = message
|
||||
return
|
||||
import urllib3.exceptions
|
||||
|
||||
|
||||
class EmptyReply(Exception):
|
||||
def __init__(self, status_code, url, screenshot=None):
|
||||
def __init__(self, status_code, url):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
return
|
||||
|
||||
|
||||
class ScreenshotUnavailable(Exception):
|
||||
def __init__(self, status_code, url, page_html=None):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
if page_html:
|
||||
from html_tools import html_to_text
|
||||
self.page_text = html_to_text(page_html)
|
||||
return
|
||||
|
||||
|
||||
class ReplyWithContentButNoText(Exception):
|
||||
def __init__(self, status_code, url, screenshot=None, has_filters=False, html_content=''):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
self.url = url
|
||||
self.screenshot = screenshot
|
||||
self.has_filters = has_filters
|
||||
self.html_content = html_content
|
||||
return
|
||||
|
||||
pass
|
||||
|
||||
class Fetcher():
|
||||
browser_connection_is_custom = None
|
||||
browser_connection_url = None
|
||||
browser_steps = None
|
||||
browser_steps_screenshot_path = None
|
||||
content = None
|
||||
error = None
|
||||
fetcher_description = "No description"
|
||||
headers = {}
|
||||
instock_data = None
|
||||
instock_data_js = ""
|
||||
status_code = None
|
||||
webdriver_js_execute_code = None
|
||||
xpath_data = None
|
||||
xpath_element_js = ""
|
||||
content = None
|
||||
headers = None
|
||||
|
||||
# Will be needed in the future by the VisualSelector, always get this where possible.
|
||||
screenshot = False
|
||||
system_http_proxy = os.getenv('HTTP_PROXY')
|
||||
system_https_proxy = os.getenv('HTTPS_PROXY')
|
||||
|
||||
# Time ONTOP of the system defined env minimum time
|
||||
render_extract_delay = 0
|
||||
|
||||
def __init__(self):
|
||||
from pkg_resources import resource_string
|
||||
# The code that scrapes elements and makes a list of elements/size/position to click on in the VisualSelector
|
||||
self.xpath_element_js = resource_string(__name__, "res/xpath_element_scraper.js").decode('utf-8')
|
||||
self.instock_data_js = resource_string(__name__, "res/stock-not-in-stock.js").decode('utf-8')
|
||||
fetcher_description ="No description"
|
||||
|
||||
@abstractmethod
|
||||
def get_error(self):
|
||||
@@ -133,9 +38,7 @@ class Fetcher():
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
ignore_status_codes=False):
|
||||
# Should set self.error, self.status_code and self.content
|
||||
pass
|
||||
|
||||
@@ -144,454 +47,61 @@ class Fetcher():
|
||||
return
|
||||
|
||||
@abstractmethod
|
||||
def get_last_status_code(self):
|
||||
return self.status_code
|
||||
def screenshot(self):
|
||||
return
|
||||
|
||||
@abstractmethod
|
||||
def screenshot_step(self, step_n):
|
||||
return None
|
||||
def get_last_status_code(self):
|
||||
return self.status_code
|
||||
|
||||
@abstractmethod
|
||||
# Return true/false if this checker is ready to run, in the case it needs todo some special config check etc
|
||||
def is_ready(self):
|
||||
return True
|
||||
|
||||
def get_all_headers(self):
|
||||
"""
|
||||
Get all headers but ensure all keys are lowercase
|
||||
:return:
|
||||
"""
|
||||
return {k.lower(): v for k, v in self.headers.items()}
|
||||
|
||||
def browser_steps_get_valid_steps(self):
|
||||
if self.browser_steps is not None and len(self.browser_steps):
|
||||
valid_steps = filter(
|
||||
lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'),
|
||||
self.browser_steps)
|
||||
|
||||
return valid_steps
|
||||
|
||||
return None
|
||||
|
||||
def iterate_browser_steps(self):
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import steppable_browser_interface
|
||||
from playwright._impl._errors import TimeoutError, Error
|
||||
from jinja2 import Environment
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
|
||||
step_n = 0
|
||||
|
||||
if self.browser_steps is not None and len(self.browser_steps):
|
||||
interface = steppable_browser_interface()
|
||||
interface.page = self.page
|
||||
valid_steps = self.browser_steps_get_valid_steps()
|
||||
|
||||
for step in valid_steps:
|
||||
step_n += 1
|
||||
logger.debug(f">> Iterating check - browser Step n {step_n} - {step['operation']}...")
|
||||
self.screenshot_step("before-" + str(step_n))
|
||||
self.save_step_html("before-" + str(step_n))
|
||||
try:
|
||||
optional_value = step['optional_value']
|
||||
selector = step['selector']
|
||||
# Support for jinja2 template in step values, with date module added
|
||||
if '{%' in step['optional_value'] or '{{' in step['optional_value']:
|
||||
optional_value = str(jinja2_env.from_string(step['optional_value']).render())
|
||||
if '{%' in step['selector'] or '{{' in step['selector']:
|
||||
selector = str(jinja2_env.from_string(step['selector']).render())
|
||||
|
||||
getattr(interface, "call_action")(action_name=step['operation'],
|
||||
selector=selector,
|
||||
optional_value=optional_value)
|
||||
self.screenshot_step(step_n)
|
||||
self.save_step_html(step_n)
|
||||
except (Error, TimeoutError) as e:
|
||||
logger.debug(str(e))
|
||||
# Stop processing here
|
||||
raise BrowserStepsStepException(step_n=step_n, original_e=e)
|
||||
|
||||
# It's always good to reset these
|
||||
def delete_browser_steps_screenshots(self):
|
||||
import glob
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
dest = os.path.join(self.browser_steps_screenshot_path, 'step_*.jpeg')
|
||||
files = glob.glob(dest)
|
||||
for f in files:
|
||||
if os.path.isfile(f):
|
||||
os.unlink(f)
|
||||
|
||||
|
||||
# Maybe for the future, each fetcher provides its own diff output, could be used for text, image
|
||||
# the current one would return javascript output (as we use JS to generate the diff)
|
||||
#
|
||||
# Returns tuple(mime_type, stream)
|
||||
# @abstractmethod
|
||||
# def return_diff(self, stream_a, stream_b):
|
||||
# return
|
||||
|
||||
def available_fetchers():
|
||||
# See the if statement at the bottom of this file for how we switch between playwright and webdriver
|
||||
import inspect
|
||||
p = []
|
||||
for name, obj in inspect.getmembers(sys.modules[__name__], inspect.isclass):
|
||||
if inspect.isclass(obj):
|
||||
# @todo html_ is maybe better as fetcher_ or something
|
||||
# In this case, make sure to edit the default one in store.py and fetch_site_status.py
|
||||
if name.startswith('html_'):
|
||||
t = tuple([name, obj.fetcher_description])
|
||||
p.append(t)
|
||||
import inspect
|
||||
from changedetectionio import content_fetcher
|
||||
p=[]
|
||||
for name, obj in inspect.getmembers(content_fetcher):
|
||||
if inspect.isclass(obj):
|
||||
# @todo html_ is maybe better as fetcher_ or something
|
||||
# In this case, make sure to edit the default one in store.py and fetch_site_status.py
|
||||
if "html_" in name:
|
||||
t=tuple([name,obj.fetcher_description])
|
||||
p.append(t)
|
||||
|
||||
return p
|
||||
return p
|
||||
|
||||
|
||||
class base_html_playwright(Fetcher):
|
||||
fetcher_description = "Playwright {}/Javascript".format(
|
||||
os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').capitalize()
|
||||
)
|
||||
if os.getenv("PLAYWRIGHT_DRIVER_URL"):
|
||||
fetcher_description += " via '{}'".format(os.getenv("PLAYWRIGHT_DRIVER_URL"))
|
||||
|
||||
browser_type = ''
|
||||
command_executor = ''
|
||||
|
||||
# Configs for Proxy setup
|
||||
# In the ENV vars, is prefixed with "playwright_proxy_", so it is for example "playwright_proxy_server"
|
||||
playwright_proxy_settings_mappings = ['bypass', 'server', 'username', 'password']
|
||||
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None, custom_browser_connection_url=None):
|
||||
super().__init__()
|
||||
|
||||
self.browser_type = os.getenv("PLAYWRIGHT_BROWSER_TYPE", 'chromium').strip('"')
|
||||
|
||||
if custom_browser_connection_url:
|
||||
self.browser_connection_is_custom = True
|
||||
self.browser_connection_url = custom_browser_connection_url
|
||||
else:
|
||||
# Fallback to fetching from system
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
self.browser_connection_url = os.getenv("PLAYWRIGHT_DRIVER_URL", 'ws://playwright-chrome:3000').strip('"')
|
||||
|
||||
|
||||
# If any proxy settings are enabled, then we should setup the proxy object
|
||||
proxy_args = {}
|
||||
for k in self.playwright_proxy_settings_mappings:
|
||||
v = os.getenv('playwright_proxy_' + k, False)
|
||||
if v:
|
||||
proxy_args[k] = v.strip('"')
|
||||
|
||||
if proxy_args:
|
||||
self.proxy = proxy_args
|
||||
|
||||
# allow per-watch proxy selection override
|
||||
if proxy_override:
|
||||
self.proxy = {'server': proxy_override}
|
||||
|
||||
if self.proxy:
|
||||
# Playwright needs separate username and password values
|
||||
parsed = urlparse(self.proxy.get('server'))
|
||||
if parsed.username:
|
||||
self.proxy['username'] = parsed.username
|
||||
self.proxy['password'] = parsed.password
|
||||
|
||||
def screenshot_step(self, step_n=''):
|
||||
screenshot = self.page.screenshot(type='jpeg', full_page=True, quality=85)
|
||||
|
||||
if self.browser_steps_screenshot_path is not None:
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.jpeg'.format(step_n))
|
||||
logger.debug(f"Saving step screenshot to {destination}")
|
||||
with open(destination, 'wb') as f:
|
||||
f.write(screenshot)
|
||||
|
||||
def save_step_html(self, step_n):
|
||||
content = self.page.content()
|
||||
destination = os.path.join(self.browser_steps_screenshot_path, 'step_{}.html'.format(step_n))
|
||||
logger.debug(f"Saving step HTML to {destination}")
|
||||
with open(destination, 'w') as f:
|
||||
f.write(content)
|
||||
|
||||
def run_fetch_browserless_puppeteer(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
from pkg_resources import resource_string
|
||||
|
||||
extra_wait_ms = (int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay) * 1000
|
||||
|
||||
self.xpath_element_js = self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors)
|
||||
code = resource_string(__name__, "res/puppeteer_fetch.js").decode('utf-8')
|
||||
# In the future inject this is a proper JS package
|
||||
code = code.replace('%xpath_scrape_code%', self.xpath_element_js)
|
||||
code = code.replace('%instock_scrape_code%', self.instock_data_js)
|
||||
|
||||
from requests.exceptions import ConnectTimeout, ReadTimeout
|
||||
wait_browserless_seconds = 240
|
||||
|
||||
browserless_function_url = os.getenv('BROWSERLESS_FUNCTION_URL')
|
||||
from urllib.parse import urlparse
|
||||
if not browserless_function_url:
|
||||
# Convert/try to guess from PLAYWRIGHT_DRIVER_URL
|
||||
o = urlparse(os.getenv('PLAYWRIGHT_DRIVER_URL'))
|
||||
browserless_function_url = o._replace(scheme="http")._replace(path="function").geturl()
|
||||
|
||||
|
||||
# Append proxy connect string
|
||||
if self.proxy:
|
||||
# Remove username/password if it exists in the URL or you will receive "ERR_NO_SUPPORTED_PROXIES" error
|
||||
# Actual authentication handled by Puppeteer/node
|
||||
o = urlparse(self.proxy.get('server'))
|
||||
proxy_url = urllib.parse.quote(o._replace(netloc="{}:{}".format(o.hostname, o.port)).geturl())
|
||||
browserless_function_url = f"{browserless_function_url}&--proxy-server={proxy_url}"
|
||||
|
||||
try:
|
||||
amp = '&' if '?' in browserless_function_url else '?'
|
||||
response = requests.request(
|
||||
method="POST",
|
||||
json={
|
||||
"code": code,
|
||||
"context": {
|
||||
# Very primitive disk cache - USE WITH EXTREME CAUTION
|
||||
# Run browserless container with -e "FUNCTION_BUILT_INS=[\"fs\",\"crypto\"]"
|
||||
'disk_cache_dir': os.getenv("PUPPETEER_DISK_CACHE", False), # or path to disk cache ending in /, ie /tmp/cache/
|
||||
'execute_js': self.webdriver_js_execute_code,
|
||||
'extra_wait_ms': extra_wait_ms,
|
||||
'include_filters': current_include_filters,
|
||||
'req_headers': request_headers,
|
||||
'screenshot_quality': int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)),
|
||||
'url': url,
|
||||
'user_agent': {k.lower(): v for k, v in request_headers.items()}.get('user-agent', None),
|
||||
'proxy_username': self.proxy.get('username', '') if self.proxy else False,
|
||||
'proxy_password': self.proxy.get('password', '') if self.proxy and self.proxy.get('username') else False,
|
||||
'no_cache_list': [
|
||||
'twitter',
|
||||
'.pdf'
|
||||
],
|
||||
# Could use https://github.com/easylist/easylist here, or install a plugin
|
||||
'block_url_list': [
|
||||
'adnxs.com',
|
||||
'analytics.twitter.com',
|
||||
'doubleclick.net',
|
||||
'google-analytics.com',
|
||||
'googletagmanager',
|
||||
'trustpilot.com'
|
||||
]
|
||||
}
|
||||
},
|
||||
# @todo /function needs adding ws:// to http:// rebuild this
|
||||
url=browserless_function_url+f"{amp}--disable-features=AudioServiceOutOfProcess&dumpio=true&--disable-remote-fonts",
|
||||
timeout=wait_browserless_seconds)
|
||||
|
||||
except ReadTimeout:
|
||||
raise PageUnloadable(url=url, status_code=None, message=f"No response from browserless in {wait_browserless_seconds}s")
|
||||
except ConnectTimeout:
|
||||
raise PageUnloadable(url=url, status_code=None, message=f"Timed out connecting to browserless, retrying..")
|
||||
else:
|
||||
# 200 Here means that the communication to browserless worked only, not the page state
|
||||
if response.status_code == 200:
|
||||
import base64
|
||||
|
||||
x = response.json()
|
||||
if not x.get('screenshot'):
|
||||
# https://github.com/puppeteer/puppeteer/blob/v1.0.0/docs/troubleshooting.md#tips
|
||||
# https://github.com/puppeteer/puppeteer/issues/1834
|
||||
# https://github.com/puppeteer/puppeteer/issues/1834#issuecomment-381047051
|
||||
# Check your memory is shared and big enough
|
||||
raise ScreenshotUnavailable(url=url, status_code=None)
|
||||
|
||||
if not x.get('content', '').strip():
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
if x.get('status_code', 200) != 200 and not ignore_status_codes:
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=x.get('status_code', 200), page_html=x['content'])
|
||||
|
||||
self.content = x.get('content')
|
||||
self.headers = x.get('headers')
|
||||
self.instock_data = x.get('instock_data')
|
||||
self.screenshot = base64.b64decode(x.get('screenshot'))
|
||||
self.status_code = x.get('status_code')
|
||||
self.xpath_data = x.get('xpath_data')
|
||||
|
||||
else:
|
||||
# Some other error from browserless
|
||||
raise PageUnloadable(url=url, status_code=None, message=response.content.decode('utf-8'))
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
|
||||
# For now, USE_EXPERIMENTAL_PUPPETEER_FETCH is not supported by watches with BrowserSteps (for now!)
|
||||
# browser_connection_is_custom doesnt work with puppeteer style fetch (use playwright native too in this case)
|
||||
if not self.browser_connection_is_custom and not self.browser_steps and os.getenv('USE_EXPERIMENTAL_PUPPETEER_FETCH'):
|
||||
if strtobool(os.getenv('USE_EXPERIMENTAL_PUPPETEER_FETCH')):
|
||||
# Temporary backup solution until we rewrite the playwright code
|
||||
return self.run_fetch_browserless_puppeteer(
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes,
|
||||
current_include_filters,
|
||||
is_binary)
|
||||
|
||||
from playwright.sync_api import sync_playwright
|
||||
import playwright._impl._errors
|
||||
|
||||
self.delete_browser_steps_screenshots()
|
||||
response = None
|
||||
|
||||
with sync_playwright() as p:
|
||||
browser_type = getattr(p, self.browser_type)
|
||||
|
||||
# Seemed to cause a connection Exception even tho I can see it connect
|
||||
# self.browser = browser_type.connect(self.command_executor, timeout=timeout*1000)
|
||||
# 60,000 connection timeout only
|
||||
browser = browser_type.connect_over_cdp(self.browser_connection_url, timeout=60000)
|
||||
|
||||
# SOCKS5 with authentication is not supported (yet)
|
||||
# https://github.com/microsoft/playwright/issues/10567
|
||||
|
||||
# Set user agent to prevent Cloudflare from blocking the browser
|
||||
# Use the default one configured in the App.py model that's passed from fetch_site_status.py
|
||||
context = browser.new_context(
|
||||
user_agent={k.lower(): v for k, v in request_headers.items()}.get('user-agent', None),
|
||||
proxy=self.proxy,
|
||||
# This is needed to enable JavaScript execution on GitHub and others
|
||||
bypass_csp=True,
|
||||
# Should be `allow` or `block` - sites like YouTube can transmit large amounts of data via Service Workers
|
||||
service_workers=os.getenv('PLAYWRIGHT_SERVICE_WORKERS', 'allow'),
|
||||
# Should never be needed
|
||||
accept_downloads=False
|
||||
)
|
||||
|
||||
self.page = context.new_page()
|
||||
if len(request_headers):
|
||||
context.set_extra_http_headers(request_headers)
|
||||
|
||||
# Listen for all console events and handle errors
|
||||
self.page.on("console", lambda msg: print(f"Playwright console: Watch URL: {url} {msg.type}: {msg.text} {msg.args}"))
|
||||
|
||||
# Re-use as much code from browser steps as possible so its the same
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import steppable_browser_interface
|
||||
browsersteps_interface = steppable_browser_interface()
|
||||
browsersteps_interface.page = self.page
|
||||
|
||||
response = browsersteps_interface.action_goto_url(value=url)
|
||||
self.headers = response.all_headers()
|
||||
|
||||
if response is None:
|
||||
context.close()
|
||||
browser.close()
|
||||
logger.debug("Content Fetcher > Response object was none")
|
||||
raise EmptyReply(url=url, status_code=None)
|
||||
|
||||
try:
|
||||
if self.webdriver_js_execute_code is not None and len(self.webdriver_js_execute_code):
|
||||
browsersteps_interface.action_execute_js(value=self.webdriver_js_execute_code, selector=None)
|
||||
except playwright._impl._errors.TimeoutError as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
# This can be ok, we will try to grab what we could retrieve
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.debug(f"Content Fetcher > Other exception when executing custom JS code {str(e)}")
|
||||
context.close()
|
||||
browser.close()
|
||||
raise PageUnloadable(url=url, status_code=None, message=str(e))
|
||||
|
||||
extra_wait = int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay
|
||||
self.page.wait_for_timeout(extra_wait * 1000)
|
||||
|
||||
try:
|
||||
self.status_code = response.status
|
||||
except Exception as e:
|
||||
# https://github.com/dgtlmoon/changedetection.io/discussions/2122#discussioncomment-8241962
|
||||
logger.critical(f"Response from browserless/playwright did not have a status_code! Response follows.")
|
||||
logger.critical(response)
|
||||
raise PageUnloadable(url=url, status_code=None, message=str(e))
|
||||
|
||||
if self.status_code != 200 and not ignore_status_codes:
|
||||
|
||||
screenshot=self.page.screenshot(type='jpeg', full_page=True,
|
||||
quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=self.status_code, screenshot=screenshot)
|
||||
|
||||
if len(self.page.content().strip()) == 0:
|
||||
context.close()
|
||||
browser.close()
|
||||
logger.debug("Content Fetcher > Content was empty")
|
||||
raise EmptyReply(url=url, status_code=response.status)
|
||||
|
||||
# Run Browser Steps here
|
||||
if self.browser_steps_get_valid_steps():
|
||||
self.iterate_browser_steps()
|
||||
|
||||
self.page.wait_for_timeout(extra_wait * 1000)
|
||||
|
||||
# So we can find an element on the page where its selector was entered manually (maybe not xPath etc)
|
||||
if current_include_filters is not None:
|
||||
self.page.evaluate("var include_filters={}".format(json.dumps(current_include_filters)))
|
||||
else:
|
||||
self.page.evaluate("var include_filters=''")
|
||||
|
||||
self.xpath_data = self.page.evaluate(
|
||||
"async () => {" + self.xpath_element_js.replace('%ELEMENTS%', visualselector_xpath_selectors) + "}")
|
||||
self.instock_data = self.page.evaluate("async () => {" + self.instock_data_js + "}")
|
||||
|
||||
self.content = self.page.content()
|
||||
# Bug 3 in Playwright screenshot handling
|
||||
# Some bug where it gives the wrong screenshot size, but making a request with the clip set first seems to solve it
|
||||
# JPEG is better here because the screenshots can be very very large
|
||||
|
||||
# Screenshots also travel via the ws:// (websocket) meaning that the binary data is base64 encoded
|
||||
# which will significantly increase the IO size between the server and client, it's recommended to use the lowest
|
||||
# acceptable screenshot quality here
|
||||
try:
|
||||
# The actual screenshot
|
||||
self.screenshot = self.page.screenshot(type='jpeg', full_page=True,
|
||||
quality=int(os.getenv("PLAYWRIGHT_SCREENSHOT_QUALITY", 72)))
|
||||
except Exception as e:
|
||||
context.close()
|
||||
browser.close()
|
||||
raise ScreenshotUnavailable(url=url, status_code=response.status_code)
|
||||
|
||||
context.close()
|
||||
browser.close()
|
||||
|
||||
|
||||
class base_html_webdriver(Fetcher):
|
||||
class html_webdriver(Fetcher):
|
||||
if os.getenv("WEBDRIVER_URL"):
|
||||
fetcher_description = "WebDriver Chrome/Javascript via '{}'".format(os.getenv("WEBDRIVER_URL"))
|
||||
else:
|
||||
fetcher_description = "WebDriver Chrome/Javascript"
|
||||
|
||||
command_executor = ''
|
||||
|
||||
# Configs for Proxy setup
|
||||
# In the ENV vars, is prefixed with "webdriver_", so it is for example "webdriver_sslProxy"
|
||||
selenium_proxy_settings_mappings = ['proxyType', 'ftpProxy', 'httpProxy', 'noProxy',
|
||||
'proxyAutoconfigUrl', 'sslProxy', 'autodetect',
|
||||
'socksProxy', 'socksVersion', 'socksUsername', 'socksPassword']
|
||||
proxy = None
|
||||
|
||||
def __init__(self, proxy_override=None, custom_browser_connection_url=None):
|
||||
super().__init__()
|
||||
from selenium.webdriver.common.proxy import Proxy as SeleniumProxy
|
||||
|
||||
|
||||
proxy=None
|
||||
|
||||
def __init__(self):
|
||||
# .strip('"') is going to save someone a lot of time when they accidently wrap the env value
|
||||
if not custom_browser_connection_url:
|
||||
self.browser_connection_url = os.getenv("WEBDRIVER_URL", 'http://browser-chrome:4444/wd/hub').strip('"')
|
||||
else:
|
||||
self.browser_connection_is_custom = True
|
||||
self.browser_connection_url = custom_browser_connection_url
|
||||
self.command_executor = os.getenv("WEBDRIVER_URL", 'http://browser-chrome:4444/wd/hub').strip('"')
|
||||
|
||||
# If any proxy settings are enabled, then we should setup the proxy object
|
||||
proxy_args = {}
|
||||
@@ -600,16 +110,6 @@ class base_html_webdriver(Fetcher):
|
||||
if v:
|
||||
proxy_args[k] = v.strip('"')
|
||||
|
||||
# Map back standard HTTP_ and HTTPS_PROXY to webDriver httpProxy/sslProxy
|
||||
if not proxy_args.get('webdriver_httpProxy') and self.system_http_proxy:
|
||||
proxy_args['httpProxy'] = self.system_http_proxy
|
||||
if not proxy_args.get('webdriver_sslProxy') and self.system_https_proxy:
|
||||
proxy_args['httpsProxy'] = self.system_https_proxy
|
||||
|
||||
# Allows override the proxy on a per-request basis
|
||||
if proxy_override is not None:
|
||||
proxy_args['httpProxy'] = proxy_override
|
||||
|
||||
if proxy_args:
|
||||
self.proxy = SeleniumProxy(raw=proxy_args)
|
||||
|
||||
@@ -619,22 +119,15 @@ class base_html_webdriver(Fetcher):
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
ignore_status_codes=False):
|
||||
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.chrome.options import Options as ChromeOptions
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
# request_body, request_method unused for now, until some magic in the future happens.
|
||||
|
||||
options = ChromeOptions()
|
||||
if self.proxy:
|
||||
options.proxy = self.proxy
|
||||
|
||||
# check env for WEBDRIVER_URL
|
||||
self.driver = webdriver.Remote(
|
||||
command_executor=self.browser_connection_url,
|
||||
options=options)
|
||||
command_executor=self.command_executor,
|
||||
desired_capabilities=DesiredCapabilities.CHROME,
|
||||
proxy=self.proxy)
|
||||
|
||||
try:
|
||||
self.driver.get(url)
|
||||
@@ -643,34 +136,28 @@ class base_html_webdriver(Fetcher):
|
||||
self.quit()
|
||||
raise
|
||||
|
||||
self.driver.set_window_size(1280, 1024)
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
|
||||
if self.webdriver_js_execute_code is not None:
|
||||
self.driver.execute_script(self.webdriver_js_execute_code)
|
||||
# Selenium doesn't automatically wait for actions as good as Playwright, so wait again
|
||||
self.driver.implicitly_wait(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
|
||||
# @todo - how to check this? is it possible?
|
||||
self.status_code = 200
|
||||
# @todo somehow we should try to get this working for WebDriver
|
||||
# raise EmptyReply(url=url, status_code=r.status_code)
|
||||
|
||||
# @todo - dom wait loaded?
|
||||
time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)) + self.render_extract_delay)
|
||||
time.sleep(int(os.getenv("WEBDRIVER_DELAY_BEFORE_CONTENT_READY", 5)))
|
||||
self.content = self.driver.page_source
|
||||
self.headers = {}
|
||||
|
||||
self.screenshot = self.driver.get_screenshot_as_png()
|
||||
def screenshot(self):
|
||||
return self.driver.get_screenshot_as_png()
|
||||
|
||||
# Does the connection to the webdriver work? run a test connection.
|
||||
def is_ready(self):
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.chrome.options import Options as ChromeOptions
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
from selenium.common.exceptions import WebDriverException
|
||||
|
||||
self.driver = webdriver.Remote(
|
||||
command_executor=self.command_executor,
|
||||
options=ChromeOptions())
|
||||
desired_capabilities=DesiredCapabilities.CHROME)
|
||||
|
||||
# driver.quit() seems to cause better exceptions
|
||||
self.quit()
|
||||
@@ -681,91 +168,42 @@ class base_html_webdriver(Fetcher):
|
||||
try:
|
||||
self.driver.quit()
|
||||
except Exception as e:
|
||||
logger.debug(f"Content Fetcher > Exception in chrome shutdown/quit {str(e)}")
|
||||
|
||||
print("Exception in chrome shutdown/quit" + str(e))
|
||||
|
||||
# "html_requests" is listed as the default fetcher in store.py!
|
||||
class html_requests(Fetcher):
|
||||
fetcher_description = "Basic fast Plaintext/HTTP Client"
|
||||
|
||||
def __init__(self, proxy_override=None, custom_browser_connection_url=None):
|
||||
super().__init__()
|
||||
self.proxy_override = proxy_override
|
||||
# browser_connection_url is none because its always 'launched locally'
|
||||
|
||||
def run(self,
|
||||
url,
|
||||
timeout,
|
||||
request_headers,
|
||||
request_body,
|
||||
request_method,
|
||||
ignore_status_codes=False,
|
||||
current_include_filters=None,
|
||||
is_binary=False):
|
||||
|
||||
# Make requests use a more modern looking user-agent
|
||||
if not {k.lower(): v for k, v in request_headers.items()}.get('user-agent', None):
|
||||
request_headers['User-Agent'] = os.getenv("DEFAULT_SETTINGS_HEADERS_USERAGENT",
|
||||
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36')
|
||||
|
||||
proxies = {}
|
||||
|
||||
# Allows override the proxy on a per-request basis
|
||||
|
||||
# https://requests.readthedocs.io/en/latest/user/advanced/#socks
|
||||
# Should also work with `socks5://user:pass@host:port` type syntax.
|
||||
|
||||
if self.proxy_override:
|
||||
proxies = {'http': self.proxy_override, 'https': self.proxy_override, 'ftp': self.proxy_override}
|
||||
else:
|
||||
if self.system_http_proxy:
|
||||
proxies['http'] = self.system_http_proxy
|
||||
if self.system_https_proxy:
|
||||
proxies['https'] = self.system_https_proxy
|
||||
ignore_status_codes=False):
|
||||
|
||||
r = requests.request(method=request_method,
|
||||
data=request_body,
|
||||
url=url,
|
||||
headers=request_headers,
|
||||
timeout=timeout,
|
||||
proxies=proxies,
|
||||
verify=False)
|
||||
data=request_body,
|
||||
url=url,
|
||||
headers=request_headers,
|
||||
timeout=timeout,
|
||||
verify=False)
|
||||
|
||||
# If the response did not tell us what encoding format to expect, Then use chardet to override what `requests` thinks.
|
||||
# For example - some sites don't tell us it's utf-8, but return utf-8 content
|
||||
# This seems to not occur when using webdriver/selenium, it seems to detect the text encoding more reliably.
|
||||
# https://github.com/psf/requests/issues/1604 good info about requests encoding detection
|
||||
if not is_binary:
|
||||
# Don't run this for PDF (and requests identified as binary) takes a _long_ time
|
||||
if not r.headers.get('content-type') or not 'charset=' in r.headers.get('content-type'):
|
||||
encoding = chardet.detect(r.content)['encoding']
|
||||
if encoding:
|
||||
r.encoding = encoding
|
||||
|
||||
if not r.content or not len(r.content):
|
||||
raise EmptyReply(url=url, status_code=r.status_code)
|
||||
if not r.headers.get('content-type') or not 'charset=' in r.headers.get('content-type'):
|
||||
encoding = chardet.detect(r.content)['encoding']
|
||||
if encoding:
|
||||
r.encoding = encoding
|
||||
|
||||
# @todo test this
|
||||
# @todo maybe you really want to test zero-byte return pages?
|
||||
if r.status_code != 200 and not ignore_status_codes:
|
||||
# maybe check with content works?
|
||||
raise Non200ErrorCodeReceived(url=url, status_code=r.status_code, page_html=r.text)
|
||||
if (not ignore_status_codes and not r) or not r.content or not len(r.content):
|
||||
raise EmptyReply(url=url, status_code=r.status_code)
|
||||
|
||||
self.status_code = r.status_code
|
||||
if is_binary:
|
||||
# Binary files just return their checksum until we add something smarter
|
||||
self.content = hashlib.md5(r.content).hexdigest()
|
||||
else:
|
||||
self.content = r.text
|
||||
|
||||
self.content = r.text
|
||||
self.headers = r.headers
|
||||
self.raw_content = r.content
|
||||
|
||||
|
||||
# Decide which is the 'real' HTML webdriver, this is more a system wide config
|
||||
# rather than site-specific.
|
||||
use_playwright_as_chrome_fetcher = os.getenv('PLAYWRIGHT_DRIVER_URL', False)
|
||||
if use_playwright_as_chrome_fetcher:
|
||||
html_webdriver = base_html_playwright
|
||||
else:
|
||||
html_webdriver = base_html_webdriver
|
||||
|
||||
14
changedetectionio/dev-docker/Dockerfile
Normal file
@@ -0,0 +1,14 @@
|
||||
FROM python:3.8-slim
|
||||
|
||||
# https://stackoverflow.com/questions/58701233/docker-logs-erroneously-appears-empty-until-container-stops
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
RUN [ ! -d "/datastore" ] && mkdir /datastore
|
||||
|
||||
COPY sleep.py /
|
||||
CMD [ "python", "/sleep.py" ]
|
||||
|
||||
|
||||
|
||||
7
changedetectionio/dev-docker/sleep.py
Normal file
@@ -0,0 +1,7 @@
|
||||
import time
|
||||
|
||||
print ("Sleep loop, you should run your script from the console")
|
||||
|
||||
while True:
|
||||
# Wait for 5 seconds
|
||||
time.sleep(2)
|
||||
@@ -10,7 +10,7 @@ def same_slicer(l, a, b):
|
||||
return l[a:b]
|
||||
|
||||
# like .compare but a little different output
|
||||
def customSequenceMatcher(before, after, include_equal=False, include_removed=True, include_added=True, include_replaced=True, include_change_type_prefix=True):
|
||||
def customSequenceMatcher(before, after, include_equal=False):
|
||||
cruncher = difflib.SequenceMatcher(isjunk=lambda x: x in " \\t", a=before, b=after)
|
||||
|
||||
# @todo Line-by-line mode instead of buncghed, including `after` that is not in `before` (maybe unset?)
|
||||
@@ -18,45 +18,35 @@ def customSequenceMatcher(before, after, include_equal=False, include_removed=Tr
|
||||
if include_equal and tag == 'equal':
|
||||
g = before[alo:ahi]
|
||||
yield g
|
||||
elif include_removed and tag == 'delete':
|
||||
row_prefix = "(removed) " if include_change_type_prefix else ''
|
||||
g = [ row_prefix + i for i in same_slicer(before, alo, ahi)]
|
||||
elif tag == 'delete':
|
||||
g = ["(removed) " + i for i in same_slicer(before, alo, ahi)]
|
||||
yield g
|
||||
elif include_replaced and tag == 'replace':
|
||||
row_prefix = "(changed) " if include_change_type_prefix else ''
|
||||
g = [row_prefix + i for i in same_slicer(before, alo, ahi)]
|
||||
row_prefix = "(into) " if include_change_type_prefix else ''
|
||||
g += [row_prefix + i for i in same_slicer(after, blo, bhi)]
|
||||
elif tag == 'replace':
|
||||
g = ["(changed) " + i for i in same_slicer(before, alo, ahi)]
|
||||
g += ["(into ) " + i for i in same_slicer(after, blo, bhi)]
|
||||
yield g
|
||||
elif include_added and tag == 'insert':
|
||||
row_prefix = "(added) " if include_change_type_prefix else ''
|
||||
g = [row_prefix + i for i in same_slicer(after, blo, bhi)]
|
||||
elif tag == 'insert':
|
||||
g = ["(added ) " + i for i in same_slicer(after, blo, bhi)]
|
||||
yield g
|
||||
|
||||
# only_differences - only return info about the differences, no context
|
||||
# line_feed_sep could be "<br>" or "<li>" or "\n" etc
|
||||
def render_diff(previous_version_file_contents, newest_version_file_contents, include_equal=False, include_removed=True, include_added=True, include_replaced=True, line_feed_sep="\n", include_change_type_prefix=True, patch_format=False):
|
||||
# line_feed_sep could be "<br/>" or "<li>" or "\n" etc
|
||||
def render_diff(previous_file, newest_file, include_equal=False, line_feed_sep="\n"):
|
||||
with open(newest_file, 'r') as f:
|
||||
newest_version_file_contents = f.read()
|
||||
newest_version_file_contents = [line.rstrip() for line in newest_version_file_contents.splitlines()]
|
||||
|
||||
newest_version_file_contents = [line.rstrip() for line in newest_version_file_contents.splitlines()]
|
||||
|
||||
if previous_version_file_contents:
|
||||
previous_version_file_contents = [line.rstrip() for line in previous_version_file_contents.splitlines()]
|
||||
if previous_file:
|
||||
with open(previous_file, 'r') as f:
|
||||
previous_version_file_contents = f.read()
|
||||
previous_version_file_contents = [line.rstrip() for line in previous_version_file_contents.splitlines()]
|
||||
else:
|
||||
previous_version_file_contents = ""
|
||||
|
||||
if patch_format:
|
||||
patch = difflib.unified_diff(previous_version_file_contents, newest_version_file_contents)
|
||||
return line_feed_sep.join(patch)
|
||||
|
||||
rendered_diff = customSequenceMatcher(before=previous_version_file_contents,
|
||||
after=newest_version_file_contents,
|
||||
include_equal=include_equal,
|
||||
include_removed=include_removed,
|
||||
include_added=include_added,
|
||||
include_replaced=include_replaced,
|
||||
include_change_type_prefix=include_change_type_prefix)
|
||||
rendered_diff = customSequenceMatcher(previous_version_file_contents,
|
||||
newest_version_file_contents,
|
||||
include_equal)
|
||||
|
||||
# Recursively join lists
|
||||
f = lambda L: line_feed_sep.join([f(x) if type(x) is list else x for x in L])
|
||||
p= f(rendered_diff)
|
||||
return p
|
||||
return f(rendered_diff)
|
||||
|
||||
200
changedetectionio/fetch_site_status.py
Normal file
@@ -0,0 +1,200 @@
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import urllib3
|
||||
|
||||
from changedetectionio import content_fetcher, html_tools
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
|
||||
# Some common stuff here that can be moved to a base class
|
||||
class perform_site_check():
|
||||
|
||||
def __init__(self, *args, datastore, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
|
||||
def run(self, uuid):
|
||||
timestamp = int(time.time()) # used for storage etc too
|
||||
|
||||
changed_detected = False
|
||||
screenshot = False # as bytes
|
||||
stripped_text_from_html = ""
|
||||
|
||||
watch = self.datastore.data['watching'][uuid]
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file', watch['url'], re.IGNORECASE) and not os.getenv('ALLOW_FILE_URI', False):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
extra_headers = self.datastore.get_val(uuid, 'headers')
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = self.datastore.data['settings']['headers'].copy()
|
||||
request_headers.update(extra_headers)
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
# Requests doesnt yet support brotli encoding, so don't put 'br' here, be totally sure that the user cannot
|
||||
# do this by accident.
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests']['timeout']
|
||||
url = self.datastore.get_val(uuid, 'url')
|
||||
request_body = self.datastore.get_val(uuid, 'body')
|
||||
request_method = self.datastore.get_val(uuid, 'method')
|
||||
ignore_status_code = self.datastore.get_val(uuid, 'ignore_status_codes')
|
||||
|
||||
# source: support
|
||||
is_source = False
|
||||
if url.startswith('source:'):
|
||||
url = url.replace('source:', '')
|
||||
is_source = True
|
||||
|
||||
# Pluggable content fetcher
|
||||
prefer_backend = watch['fetch_backend']
|
||||
if hasattr(content_fetcher, prefer_backend):
|
||||
klass = getattr(content_fetcher, prefer_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
klass = getattr(content_fetcher, "html_requests")
|
||||
|
||||
fetcher = klass()
|
||||
fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_code)
|
||||
# Fetching complete, now filters
|
||||
# @todo move to class / maybe inside of fetcher abstract base?
|
||||
|
||||
# @note: I feel like the following should be in a more obvious chain system
|
||||
# - Check filter text
|
||||
# - Is the checksum different?
|
||||
# - Do we convert to JSON?
|
||||
# https://stackoverflow.com/questions/41817578/basic-method-chaining ?
|
||||
# return content().textfilter().jsonextract().checksumcompare() ?
|
||||
|
||||
is_json = 'application/json' in fetcher.headers.get('Content-Type', '')
|
||||
is_html = not is_json
|
||||
|
||||
# source: support, basically treat it as plaintext
|
||||
if is_source:
|
||||
is_html = False
|
||||
is_json = False
|
||||
|
||||
css_filter_rule = watch['css_filter']
|
||||
subtractive_selectors = watch.get(
|
||||
"subtractive_selectors", []
|
||||
) + self.datastore.data["settings"]["application"].get(
|
||||
"global_subtractive_selectors", []
|
||||
)
|
||||
|
||||
has_filter_rule = css_filter_rule and len(css_filter_rule.strip())
|
||||
has_subtractive_selectors = subtractive_selectors and len(subtractive_selectors[0].strip())
|
||||
|
||||
if is_json and not has_filter_rule:
|
||||
css_filter_rule = "json:$"
|
||||
has_filter_rule = True
|
||||
|
||||
if has_filter_rule:
|
||||
if 'json:' in css_filter_rule:
|
||||
stripped_text_from_html = html_tools.extract_json_as_string(content=fetcher.content, jsonpath_filter=css_filter_rule)
|
||||
is_html = False
|
||||
|
||||
if is_html or is_source:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = fetcher.content
|
||||
|
||||
# If not JSON, and if it's not text/plain..
|
||||
if 'text/plain' in fetcher.headers.get('Content-Type', '').lower():
|
||||
# Don't run get_text or xpath/css filters on plaintext
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if css_filter_rule[0] == '/':
|
||||
html_content = html_tools.xpath_filter(xpath_filter=css_filter_rule, html_content=fetcher.content)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content = html_tools.css_filter(css_filter=css_filter_rule, html_content=fetcher.content)
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
if not is_source:
|
||||
# extract text
|
||||
stripped_text_from_html = \
|
||||
html_tools.html_to_text(
|
||||
html_content,
|
||||
render_anchor_tag_content=self.datastore.data["settings"][
|
||||
"application"].get(
|
||||
"render_anchor_tag_content", False)
|
||||
)
|
||||
|
||||
elif is_source:
|
||||
stripped_text_from_html = html_content
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# We rely on the actual text in the html output.. many sites have random script vars etc,
|
||||
# in the future we'll implement other mechanisms.
|
||||
|
||||
update_obj["last_check_status"] = fetcher.get_last_status_code()
|
||||
|
||||
# If there's text to skip
|
||||
# @todo we could abstract out the get_text() to handle this cleaner
|
||||
text_to_ignore = watch.get('ignore_text', []) + self.datastore.data['settings']['application'].get('global_ignore_text', [])
|
||||
if len(text_to_ignore):
|
||||
stripped_text_from_html = html_tools.strip_ignore_text(stripped_text_from_html, text_to_ignore)
|
||||
else:
|
||||
stripped_text_from_html = stripped_text_from_html.encode('utf8')
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
else:
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html).hexdigest()
|
||||
|
||||
# On the first run of a site, watch['previous_md5'] will be None, set it the current one.
|
||||
if not watch.get('previous_md5'):
|
||||
watch['previous_md5'] = fetched_md5
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
if len(watch['trigger_text']):
|
||||
# Yeah, lets block first until something matches
|
||||
blocked_by_not_found_trigger_text = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=watch['trigger_text'],
|
||||
mode="line numbers")
|
||||
if result:
|
||||
blocked_by_not_found_trigger_text = False
|
||||
|
||||
if not blocked_by_not_found_trigger_text and watch['previous_md5'] != fetched_md5:
|
||||
changed_detected = True
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
update_obj["last_changed"] = timestamp
|
||||
|
||||
# Extract title as title
|
||||
if is_html:
|
||||
if self.datastore.data['settings']['application']['extract_title_as_title'] or watch['extract_title_as_title']:
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=fetcher.content)
|
||||
|
||||
if self.datastore.data['settings']['application'].get('real_browser_save_screenshot', True):
|
||||
screenshot = fetcher.screenshot()
|
||||
|
||||
fetcher.quit()
|
||||
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter, screenshot
|
||||
@@ -1,11 +1,11 @@
|
||||
import os
|
||||
import re
|
||||
from distutils.util import strtobool
|
||||
|
||||
from wtforms import (
|
||||
BooleanField,
|
||||
Field,
|
||||
Form,
|
||||
IntegerField,
|
||||
PasswordField,
|
||||
RadioField,
|
||||
SelectField,
|
||||
StringField,
|
||||
@@ -13,41 +13,30 @@ from wtforms import (
|
||||
TextAreaField,
|
||||
fields,
|
||||
validators,
|
||||
widgets
|
||||
widgets,
|
||||
)
|
||||
from flask_wtf.file import FileField, FileAllowed
|
||||
from wtforms.fields import FieldList
|
||||
|
||||
from wtforms.validators import ValidationError
|
||||
|
||||
from validators.url import url as url_validator
|
||||
|
||||
|
||||
# default
|
||||
# each select <option data-enabled="enabled-0-0"
|
||||
from changedetectionio.blueprint.browser_steps.browser_steps import browser_step_ui_config
|
||||
|
||||
from changedetectionio import content_fetcher, html_tools
|
||||
|
||||
from changedetectionio import content_fetcher
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
valid_notification_formats,
|
||||
)
|
||||
|
||||
from wtforms.fields import FormField
|
||||
|
||||
dictfilt = lambda x, y: dict([ (i,x[i]) for i in x if i in set(y) ])
|
||||
|
||||
valid_method = {
|
||||
'GET',
|
||||
'POST',
|
||||
'PUT',
|
||||
'PATCH',
|
||||
'DELETE',
|
||||
'OPTIONS',
|
||||
}
|
||||
|
||||
default_method = 'GET'
|
||||
allow_simplehost = not strtobool(os.getenv('BLOCK_SIMPLEHOSTS', 'False'))
|
||||
|
||||
|
||||
class StringListField(StringField):
|
||||
widget = widgets.TextArea()
|
||||
@@ -100,29 +89,6 @@ class SaltyPasswordField(StringField):
|
||||
else:
|
||||
self.data = False
|
||||
|
||||
class StringTagUUID(StringField):
|
||||
|
||||
# process_formdata(self, valuelist) handled manually in POST handler
|
||||
|
||||
# Is what is shown when field <input> is rendered
|
||||
def _value(self):
|
||||
# Tag UUID to name, on submit it will convert it back (in the submit handler of init.py)
|
||||
if self.data and type(self.data) is list:
|
||||
tag_titles = []
|
||||
for i in self.data:
|
||||
tag = self.datastore.data['settings']['application']['tags'].get(i)
|
||||
if tag:
|
||||
tag_title = tag.get('title')
|
||||
if tag_title:
|
||||
tag_titles.append(tag_title)
|
||||
|
||||
return ', '.join(tag_titles)
|
||||
|
||||
if not self.data:
|
||||
return ''
|
||||
|
||||
return 'error'
|
||||
|
||||
class TimeBetweenCheckForm(Form):
|
||||
weeks = IntegerField('Weeks', validators=[validators.Optional(), validators.NumberRange(min=0, message="Should contain zero or more seconds")])
|
||||
days = IntegerField('Days', validators=[validators.Optional(), validators.NumberRange(min=0, message="Should contain zero or more seconds")])
|
||||
@@ -169,11 +135,9 @@ class ValidateContentFetcherIsReady(object):
|
||||
def __call__(self, form, field):
|
||||
import urllib3.exceptions
|
||||
from changedetectionio import content_fetcher
|
||||
return
|
||||
|
||||
# AttributeError: module 'changedetectionio.content_fetcher' has no attribute 'extra_browser_unlocked<>ASDF213r123r'
|
||||
# Better would be a radiohandler that keeps a reference to each class
|
||||
if field.data is not None and field.data != 'system':
|
||||
if field.data is not None:
|
||||
klass = getattr(content_fetcher, field.data)
|
||||
some_object = klass()
|
||||
try:
|
||||
@@ -182,12 +146,12 @@ class ValidateContentFetcherIsReady(object):
|
||||
except urllib3.exceptions.MaxRetryError as e:
|
||||
driver_url = some_object.command_executor
|
||||
message = field.gettext('Content fetcher \'%s\' did not respond.' % (field.data))
|
||||
message += '<br>' + field.gettext(
|
||||
message += '<br/>' + field.gettext(
|
||||
'Be sure that the selenium/webdriver runner is running and accessible via network from this container/host.')
|
||||
message += '<br>' + field.gettext('Did you follow the instructions in the wiki?')
|
||||
message += '<br><br>' + field.gettext('WebDriver Host: %s' % (driver_url))
|
||||
message += '<br><a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">Go here for more information</a>'
|
||||
message += '<br>'+field.gettext('Content fetcher did not respond properly, unable to use it.\n %s' % (str(e)))
|
||||
message += '<br/>' + field.gettext('Did you follow the instructions in the wiki?')
|
||||
message += '<br/><br/>' + field.gettext('WebDriver Host: %s' % (driver_url))
|
||||
message += '<br/><a href="https://github.com/dgtlmoon/changedetection.io/wiki/Fetching-pages-with-WebDriver">Go here for more information</a>'
|
||||
message += '<br/>'+field.gettext('Content fetcher did not respond properly, unable to use it.\n %s' % (str(e)))
|
||||
|
||||
raise ValidationError(message)
|
||||
|
||||
@@ -228,7 +192,7 @@ class ValidateAppRiseServers(object):
|
||||
message = field.gettext('\'%s\' is not a valid AppRise URL.' % (server_url))
|
||||
raise ValidationError(message)
|
||||
|
||||
class ValidateJinja2Template(object):
|
||||
class ValidateTokensList(object):
|
||||
"""
|
||||
Validates that a {token} is from a valid set
|
||||
"""
|
||||
@@ -237,30 +201,14 @@ class ValidateJinja2Template(object):
|
||||
|
||||
def __call__(self, form, field):
|
||||
from changedetectionio import notification
|
||||
|
||||
from jinja2 import Environment, BaseLoader, TemplateSyntaxError, UndefinedError
|
||||
from jinja2.meta import find_undeclared_variables
|
||||
|
||||
|
||||
try:
|
||||
jinja2_env = Environment(loader=BaseLoader)
|
||||
jinja2_env.globals.update(notification.valid_tokens)
|
||||
|
||||
rendered = jinja2_env.from_string(field.data).render()
|
||||
except TemplateSyntaxError as e:
|
||||
raise ValidationError(f"This is not a valid Jinja2 template: {e}") from e
|
||||
except UndefinedError as e:
|
||||
raise ValidationError(f"A variable or function is not defined: {e}") from e
|
||||
|
||||
ast = jinja2_env.parse(field.data)
|
||||
undefined = ", ".join(find_undeclared_variables(ast))
|
||||
if undefined:
|
||||
raise ValidationError(
|
||||
f"The following tokens used in the notification are not valid: {undefined}"
|
||||
)
|
||||
|
||||
regex = re.compile('{.*?}')
|
||||
for p in re.findall(regex, field.data):
|
||||
if not p.strip('{}') in notification.valid_tokens:
|
||||
message = field.gettext('Token \'%s\' is not a valid token.')
|
||||
raise ValidationError(message % (p))
|
||||
|
||||
class validateURL(object):
|
||||
|
||||
|
||||
"""
|
||||
Flask wtform validators wont work with basic auth
|
||||
"""
|
||||
@@ -269,24 +217,13 @@ class validateURL(object):
|
||||
self.message = message
|
||||
|
||||
def __call__(self, form, field):
|
||||
# This should raise a ValidationError() or not
|
||||
validate_url(field.data)
|
||||
|
||||
def validate_url(test_url):
|
||||
# If hosts that only contain alphanumerics are allowed ("localhost" for example)
|
||||
try:
|
||||
url_validator(test_url, simple_host=allow_simplehost)
|
||||
except validators.ValidationError:
|
||||
#@todo check for xss
|
||||
message = f"'{test_url}' is not a valid URL."
|
||||
# This should be wtforms.validators.
|
||||
raise ValidationError(message)
|
||||
|
||||
from .model.Watch import is_safe_url
|
||||
if not is_safe_url(test_url):
|
||||
# This should be wtforms.validators.
|
||||
raise ValidationError('Watch protocol is not permitted by SAFE_PROTOCOL_REGEX or incorrect URL format')
|
||||
|
||||
import validators
|
||||
try:
|
||||
validators.url(field.data.strip())
|
||||
except validators.ValidationFailure:
|
||||
message = field.gettext('\'%s\' is not a valid URL.' % (field.data.strip()))
|
||||
raise ValidationError(message)
|
||||
|
||||
class ValidateListRegex(object):
|
||||
"""
|
||||
Validates that anything that looks like a regex passes as a regex
|
||||
@@ -297,10 +234,11 @@ class ValidateListRegex(object):
|
||||
def __call__(self, form, field):
|
||||
|
||||
for line in field.data:
|
||||
if re.search(html_tools.PERL_STYLE_REGEX, line, re.IGNORECASE):
|
||||
if line[0] == '/' and line[-1] == '/':
|
||||
# Because internally we dont wrap in /
|
||||
line = line.strip('/')
|
||||
try:
|
||||
regex = html_tools.perl_style_slash_enclosed_regex_to_options(line)
|
||||
re.compile(regex)
|
||||
re.compile(line)
|
||||
except re.error:
|
||||
message = field.gettext('RegEx \'%s\' is not a valid regular expression.')
|
||||
raise ValidationError(message % (line))
|
||||
@@ -329,30 +267,11 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
return
|
||||
|
||||
# Does it look like XPath?
|
||||
if line.strip()[0] == '/' or line.strip().startswith('xpath:'):
|
||||
if not self.allow_xpath:
|
||||
raise ValidationError("XPath not permitted in this field!")
|
||||
from lxml import etree, html
|
||||
import elementpath
|
||||
# xpath 2.0-3.1
|
||||
from elementpath.xpath3 import XPath3Parser
|
||||
tree = html.fromstring("<html></html>")
|
||||
line = line.replace('xpath:', '')
|
||||
|
||||
try:
|
||||
elementpath.select(tree, line.strip(), parser=XPath3Parser)
|
||||
except elementpath.ElementPathError as e:
|
||||
message = field.gettext('\'%s\' is not a valid XPath expression. (%s)')
|
||||
raise ValidationError(message % (line, str(e)))
|
||||
except:
|
||||
raise ValidationError("A system-error occurred when validating your XPath expression")
|
||||
|
||||
if line.strip().startswith('xpath1:'):
|
||||
if line.strip()[0] == '/':
|
||||
if not self.allow_xpath:
|
||||
raise ValidationError("XPath not permitted in this field!")
|
||||
from lxml import etree, html
|
||||
tree = html.fromstring("<html></html>")
|
||||
line = re.sub(r'^xpath1:', '', line)
|
||||
|
||||
try:
|
||||
tree.xpath(line.strip())
|
||||
@@ -384,79 +303,32 @@ class ValidateCSSJSONXPATHInput(object):
|
||||
|
||||
# Re #265 - maybe in the future fetch the page and offer a
|
||||
# warning/notice that its possible the rule doesnt yet match anything?
|
||||
if not self.allow_json:
|
||||
raise ValidationError("jq not permitted in this field!")
|
||||
|
||||
if 'jq:' in line:
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise ValidationError("jq not support not found")
|
||||
|
||||
input = line.replace('jq:', '')
|
||||
|
||||
try:
|
||||
jq.compile(input)
|
||||
except (ValueError) as e:
|
||||
message = field.gettext('\'%s\' is not a valid jq expression. (%s)')
|
||||
raise ValidationError(message % (input, str(e)))
|
||||
except:
|
||||
raise ValidationError("A system-error occurred when validating your jq expression")
|
||||
|
||||
class quickWatchForm(Form):
|
||||
from . import processors
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tags = StringTagUUID('Group tag', [validators.Optional()])
|
||||
watch_submit_button = SubmitField('Watch', render_kw={"class": "pure-button pure-button-primary"})
|
||||
processor = RadioField(u'Processor', choices=processors.available_processors(), default="text_json_diff")
|
||||
edit_and_watch_submit_button = SubmitField('Edit > Watch', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)])
|
||||
|
||||
# Common to a single watch and the global settings
|
||||
class commonSettingsForm(Form):
|
||||
|
||||
notification_urls = StringListField('Notification URL List', validators=[validators.Optional(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification Title', default='ChangeDetection.io Notification - {{ watch_url }}', validators=[validators.Optional(), ValidateJinja2Template()])
|
||||
notification_body = TextAreaField('Notification Body', default='{{ watch_url }} had a change.', validators=[validators.Optional(), ValidateJinja2Template()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys())
|
||||
fetch_backend = RadioField(u'Fetch Method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
notification_urls = StringListField('Notification URL list', validators=[validators.Optional(), ValidateNotificationBodyAndTitleWhenURLisSet(), ValidateAppRiseServers()])
|
||||
notification_title = StringField('Notification title', default=default_notification_title, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_body = TextAreaField('Notification body', default=default_notification_body, validators=[validators.Optional(), ValidateTokensList()])
|
||||
notification_format = SelectField('Notification format', choices=valid_notification_formats.keys(), default=default_notification_format)
|
||||
fetch_backend = RadioField(u'Fetch method', choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
extract_title_as_title = BooleanField('Extract <title> from document and use as watch title', default=False)
|
||||
webdriver_delay = IntegerField('Wait seconds before extracting text', validators=[validators.Optional(), validators.NumberRange(min=1,
|
||||
message="Should contain one or more seconds")])
|
||||
class importForm(Form):
|
||||
from . import processors
|
||||
processor = RadioField(u'Processor', choices=processors.available_processors(), default="text_json_diff")
|
||||
urls = TextAreaField('URLs')
|
||||
xlsx_file = FileField('Upload .xlsx file', validators=[FileAllowed(['xlsx'], 'Must be .xlsx file!')])
|
||||
file_mapping = SelectField('File mapping', [validators.DataRequired()], choices={('wachete', 'Wachete mapping'), ('custom','Custom mapping')})
|
||||
|
||||
|
||||
class SingleBrowserStep(Form):
|
||||
|
||||
operation = SelectField('Operation', [validators.Optional()], choices=browser_step_ui_config.keys())
|
||||
|
||||
# maybe better to set some <script>var..
|
||||
selector = StringField('Selector', [validators.Optional()], render_kw={"placeholder": "CSS or xPath selector"})
|
||||
optional_value = StringField('value', [validators.Optional()], render_kw={"placeholder": "Value"})
|
||||
# @todo move to JS? ajax fetch new field?
|
||||
# remove_button = SubmitField('-', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Remove'})
|
||||
# add_button = SubmitField('+', render_kw={"type": "button", "class": "pure-button pure-button-primary", 'title': 'Add new step after'})
|
||||
|
||||
class watchForm(commonSettingsForm):
|
||||
|
||||
url = fields.URLField('URL', validators=[validateURL()])
|
||||
tags = StringTagUUID('Group tag', [validators.Optional()], default='')
|
||||
tag = StringField('Group tag', [validators.Optional(), validators.Length(max=35)], default='')
|
||||
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
|
||||
include_filters = StringListField('CSS/JSONPath/JQ/XPath Filters', [ValidateCSSJSONXPATHInput()], default='')
|
||||
css_filter = StringField('CSS/JSON/XPATH Filter', [ValidateCSSJSONXPATHInput()], default='')
|
||||
|
||||
subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
|
||||
extract_text = StringListField('Extract text', [ValidateListRegex()])
|
||||
|
||||
title = StringField('Title', default='')
|
||||
|
||||
ignore_text = StringListField('Ignore text', [ValidateListRegex()])
|
||||
@@ -464,29 +336,10 @@ class watchForm(commonSettingsForm):
|
||||
body = TextAreaField('Request body', [validators.Optional()])
|
||||
method = SelectField('Request method', choices=valid_method, default=default_method)
|
||||
ignore_status_codes = BooleanField('Ignore status codes (process non-2xx status codes as normal)', default=False)
|
||||
check_unique_lines = BooleanField('Only trigger when unique lines appear', default=False)
|
||||
|
||||
filter_text_added = BooleanField('Added lines', default=True)
|
||||
filter_text_replaced = BooleanField('Replaced/changed lines', default=True)
|
||||
filter_text_removed = BooleanField('Removed lines', default=True)
|
||||
|
||||
# @todo this class could be moved to its own text_json_diff_watchForm and this goes to restock_diff_Watchform perhaps
|
||||
in_stock_only = BooleanField('Only trigger when product goes BACK to in-stock', default=True)
|
||||
|
||||
trigger_text = StringListField('Trigger/wait for text', [validators.Optional(), ValidateListRegex()])
|
||||
if os.getenv("PLAYWRIGHT_DRIVER_URL"):
|
||||
browser_steps = FieldList(FormField(SingleBrowserStep), min_entries=10)
|
||||
text_should_not_be_present = StringListField('Block change-detection while text matches', [validators.Optional(), ValidateListRegex()])
|
||||
webdriver_js_execute_code = TextAreaField('Execute JavaScript before change detection', render_kw={"rows": "5"}, validators=[validators.Optional()])
|
||||
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
proxy = RadioField('Proxy')
|
||||
filter_failure_notification_send = BooleanField(
|
||||
'Send a notification when the filter can no longer be found on the page', default=False)
|
||||
|
||||
notification_muted = BooleanField('Notifications Muted / Off', default=False)
|
||||
notification_screenshot = BooleanField('Attach screenshot to notification (where possible)', default=False)
|
||||
save_and_preview_button = SubmitField('Save & Preview', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
def validate(self, **kwargs):
|
||||
if not super().validate():
|
||||
@@ -499,74 +352,26 @@ class watchForm(commonSettingsForm):
|
||||
self.body.errors.append('Body must be empty when Request Method is set to GET')
|
||||
result = False
|
||||
|
||||
# Attempt to validate jinja2 templates in the URL
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(self.url.data).render())
|
||||
except Exception as e:
|
||||
self.url.errors.append('Invalid template syntax')
|
||||
result = False
|
||||
return result
|
||||
|
||||
|
||||
class SingleExtraProxy(Form):
|
||||
|
||||
# maybe better to set some <script>var..
|
||||
proxy_name = StringField('Name', [validators.Optional()], render_kw={"placeholder": "Name"})
|
||||
proxy_url = StringField('Proxy URL', [validators.Optional()], render_kw={"placeholder": "socks5:// or regular proxy http://user:pass@...:3128", "size":50})
|
||||
# @todo do the validation here instead
|
||||
|
||||
class SingleExtraBrowser(Form):
|
||||
browser_name = StringField('Name', [validators.Optional()], render_kw={"placeholder": "Name"})
|
||||
browser_connection_url = StringField('Browser connection URL', [validators.Optional()], render_kw={"placeholder": "wss://brightdata... wss://oxylabs etc", "size":50})
|
||||
# @todo do the validation here instead
|
||||
|
||||
|
||||
# datastore.data['settings']['requests']..
|
||||
class globalSettingsRequestForm(Form):
|
||||
time_between_check = FormField(TimeBetweenCheckForm)
|
||||
proxy = RadioField('Proxy')
|
||||
jitter_seconds = IntegerField('Random jitter seconds ± check',
|
||||
render_kw={"style": "width: 5em;"},
|
||||
validators=[validators.NumberRange(min=0, message="Should contain zero or more seconds")])
|
||||
extra_proxies = FieldList(FormField(SingleExtraProxy), min_entries=5)
|
||||
extra_browsers = FieldList(FormField(SingleExtraBrowser), min_entries=5)
|
||||
|
||||
def validate_extra_proxies(self, extra_validators=None):
|
||||
for e in self.data['extra_proxies']:
|
||||
if e.get('proxy_name') or e.get('proxy_url'):
|
||||
if not e.get('proxy_name','').strip() or not e.get('proxy_url','').strip():
|
||||
self.extra_proxies.errors.append('Both a name, and a Proxy URL is required.')
|
||||
return False
|
||||
|
||||
|
||||
# datastore.data['settings']['application']..
|
||||
class globalSettingsApplicationForm(commonSettingsForm):
|
||||
|
||||
api_access_token_enabled = BooleanField('API access token security check enabled', default=True, validators=[validators.Optional()])
|
||||
base_url = StringField('Notification base URL override',
|
||||
validators=[validators.Optional()],
|
||||
render_kw={"placeholder": os.getenv('BASE_URL', 'Not set')}
|
||||
)
|
||||
empty_pages_are_a_change = BooleanField('Treat empty pages as a change?', default=False)
|
||||
fetch_backend = RadioField('Fetch Method', default="html_requests", choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
global_ignore_text = StringListField('Ignore Text', [ValidateListRegex()])
|
||||
base_url = StringField('Base URL', validators=[validators.Optional()])
|
||||
global_subtractive_selectors = StringListField('Remove elements', [ValidateCSSJSONXPATHInput(allow_xpath=False, allow_json=False)])
|
||||
global_ignore_text = StringListField('Ignore Text', [ValidateListRegex()])
|
||||
ignore_whitespace = BooleanField('Ignore whitespace')
|
||||
password = SaltyPasswordField()
|
||||
pager_size = IntegerField('Pager size',
|
||||
render_kw={"style": "width: 5em;"},
|
||||
validators=[validators.NumberRange(min=0,
|
||||
message="Should be atleast zero (disabled)")])
|
||||
real_browser_save_screenshot = BooleanField('Save last screenshot when using Chrome?')
|
||||
removepassword_button = SubmitField('Remove password', render_kw={"class": "pure-button pure-button-primary"})
|
||||
render_anchor_tag_content = BooleanField('Render anchor tag content', default=False)
|
||||
shared_diff_access = BooleanField('Allow access to view diff page when password is enabled', default=False, validators=[validators.Optional()])
|
||||
filter_failure_notification_threshold_attempts = IntegerField('Number of times the filter can be missing before sending a notification',
|
||||
render_kw={"style": "width: 5em;"},
|
||||
validators=[validators.NumberRange(min=0,
|
||||
message="Should contain zero or more attempts")])
|
||||
fetch_backend = RadioField('Fetch Method', default="html_requests", choices=content_fetcher.available_fetchers(), validators=[ValidateContentFetcherIsReady()])
|
||||
password = SaltyPasswordField()
|
||||
|
||||
|
||||
class globalSettingsForm(Form):
|
||||
@@ -578,7 +383,3 @@ class globalSettingsForm(Form):
|
||||
application = FormField(globalSettingsApplicationForm)
|
||||
save_button = SubmitField('Save', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
|
||||
class extractDataForm(Form):
|
||||
extract_regex = StringField('RegEx to extract', validators=[validators.Length(min=1, message="Needs a RegEx")])
|
||||
extract_submit_button = SubmitField('Extract as CSV', render_kw={"class": "pure-button pure-button-primary"})
|
||||
|
||||
@@ -1,61 +1,26 @@
|
||||
|
||||
from bs4 import BeautifulSoup
|
||||
from inscriptis import get_text
|
||||
from jsonpath_ng.ext import parse
|
||||
from typing import List
|
||||
from inscriptis.css_profiles import CSS_PROFILES, HtmlElement
|
||||
from inscriptis.html_properties import Display
|
||||
from inscriptis.model.config import ParserConfig
|
||||
from xml.sax.saxutils import escape as xml_escape
|
||||
import json
|
||||
import re
|
||||
from typing import List
|
||||
|
||||
from bs4 import BeautifulSoup
|
||||
from jsonpath_ng.ext import parse
|
||||
import re
|
||||
from inscriptis import get_text
|
||||
from inscriptis.model.config import ParserConfig
|
||||
|
||||
# HTML added to be sure each result matching a filter (.example) gets converted to a new line by Inscriptis
|
||||
TEXT_FILTER_LIST_LINE_SUFFIX = "<br>"
|
||||
|
||||
PERL_STYLE_REGEX = r'^/(.*?)/([a-z]*)?$'
|
||||
# 'price' , 'lowPrice', 'highPrice' are usually under here
|
||||
# All of those may or may not appear on different websites - I didnt find a way todo case-insensitive searching here
|
||||
LD_JSON_PRODUCT_OFFER_SELECTORS = ["json:$..offers", "json:$..Offers"]
|
||||
|
||||
class JSONNotFound(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
# Doesn't look like python supports forward slash auto enclosure in re.findall
|
||||
# So convert it to inline flag "(?i)foobar" type configuration
|
||||
def perl_style_slash_enclosed_regex_to_options(regex):
|
||||
|
||||
res = re.search(PERL_STYLE_REGEX, regex, re.IGNORECASE)
|
||||
|
||||
if res:
|
||||
flags = res.group(2) if res.group(2) else 'i'
|
||||
regex = f"(?{flags}){res.group(1)}"
|
||||
else:
|
||||
# Fall back to just ignorecase as an option
|
||||
regex = f"(?i){regex}"
|
||||
|
||||
return regex
|
||||
|
||||
# Given a CSS Rule, and a blob of HTML, return the blob of HTML that matches
|
||||
def include_filters(include_filters, html_content, append_pretty_line_formatting=False):
|
||||
def css_filter(css_filter, html_content):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
html_block = ""
|
||||
r = soup.select(include_filters, separator="")
|
||||
for item in soup.select(css_filter, separator=""):
|
||||
html_block += str(item)
|
||||
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and not element.name in (['br', 'hr', 'div', 'p']):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
html_block += str(element)
|
||||
|
||||
return html_block
|
||||
return html_block + "\n"
|
||||
|
||||
def subtractive_css_selector(css_selector, html_content):
|
||||
soup = BeautifulSoup(html_content, "html.parser")
|
||||
@@ -69,117 +34,19 @@ def element_removal(selectors: List[str], html_content):
|
||||
selector = ",".join(selectors)
|
||||
return subtractive_css_selector(selector, html_content)
|
||||
|
||||
def elementpath_tostring(obj):
|
||||
"""
|
||||
change elementpath.select results to string type
|
||||
# The MIT License (MIT), Copyright (c), 2018-2021, SISSA (Scuola Internazionale Superiore di Studi Avanzati)
|
||||
# https://github.com/sissaschool/elementpath/blob/dfcc2fd3d6011b16e02bf30459a7924f547b47d0/elementpath/xpath_tokens.py#L1038
|
||||
"""
|
||||
|
||||
import elementpath
|
||||
from decimal import Decimal
|
||||
import math
|
||||
|
||||
if obj is None:
|
||||
return ''
|
||||
# https://elementpath.readthedocs.io/en/latest/xpath_api.html#elementpath.select
|
||||
elif isinstance(obj, elementpath.XPathNode):
|
||||
return obj.string_value
|
||||
elif isinstance(obj, bool):
|
||||
return 'true' if obj else 'false'
|
||||
elif isinstance(obj, Decimal):
|
||||
value = format(obj, 'f')
|
||||
if '.' in value:
|
||||
return value.rstrip('0').rstrip('.')
|
||||
return value
|
||||
|
||||
elif isinstance(obj, float):
|
||||
if math.isnan(obj):
|
||||
return 'NaN'
|
||||
elif math.isinf(obj):
|
||||
return str(obj).upper()
|
||||
|
||||
value = str(obj)
|
||||
if '.' in value:
|
||||
value = value.rstrip('0').rstrip('.')
|
||||
if '+' in value:
|
||||
value = value.replace('+', '')
|
||||
if 'e' in value:
|
||||
return value.upper()
|
||||
return value
|
||||
|
||||
return str(obj)
|
||||
|
||||
# Return str Utf-8 of matched rules
|
||||
def xpath_filter(xpath_filter, html_content, append_pretty_line_formatting=False, is_rss=False):
|
||||
def xpath_filter(xpath_filter, html_content):
|
||||
from lxml import etree, html
|
||||
import elementpath
|
||||
# xpath 2.0-3.1
|
||||
from elementpath.xpath3 import XPath3Parser
|
||||
|
||||
parser = etree.HTMLParser()
|
||||
if is_rss:
|
||||
# So that we can keep CDATA for cdata_in_document_to_text() to process
|
||||
parser = etree.XMLParser(strip_cdata=False)
|
||||
|
||||
tree = html.fromstring(bytes(html_content, encoding='utf-8'), parser=parser)
|
||||
tree = html.fromstring(html_content)
|
||||
html_block = ""
|
||||
|
||||
r = elementpath.select(tree, xpath_filter.strip(), namespaces={'re': 'http://exslt.org/regular-expressions'}, parser=XPath3Parser)
|
||||
#@note: //title/text() wont work where <title>CDATA..
|
||||
|
||||
if type(r) != list:
|
||||
r = [r]
|
||||
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and (not hasattr( element, 'tag' ) or not element.tag in (['br', 'hr', 'div', 'p'])):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
if type(element) == str:
|
||||
html_block += element
|
||||
elif issubclass(type(element), etree._Element) or issubclass(type(element), etree._ElementTree):
|
||||
html_block += etree.tostring(element, pretty_print=True).decode('utf-8')
|
||||
else:
|
||||
html_block += elementpath_tostring(element)
|
||||
for item in tree.xpath(xpath_filter.strip(), namespaces={'re':'http://exslt.org/regular-expressions'}):
|
||||
html_block+= etree.tostring(item, pretty_print=True).decode('utf-8')+"<br/>"
|
||||
|
||||
return html_block
|
||||
|
||||
# Return str Utf-8 of matched rules
|
||||
# 'xpath1:'
|
||||
def xpath1_filter(xpath_filter, html_content, append_pretty_line_formatting=False, is_rss=False):
|
||||
from lxml import etree, html
|
||||
|
||||
parser = None
|
||||
if is_rss:
|
||||
# So that we can keep CDATA for cdata_in_document_to_text() to process
|
||||
parser = etree.XMLParser(strip_cdata=False)
|
||||
|
||||
tree = html.fromstring(bytes(html_content, encoding='utf-8'), parser=parser)
|
||||
html_block = ""
|
||||
|
||||
r = tree.xpath(xpath_filter.strip(), namespaces={'re': 'http://exslt.org/regular-expressions'})
|
||||
#@note: //title/text() wont work where <title>CDATA..
|
||||
|
||||
for element in r:
|
||||
# When there's more than 1 match, then add the suffix to separate each line
|
||||
# And where the matched result doesn't include something that will cause Inscriptis to add a newline
|
||||
# (This way each 'match' reliably has a new-line in the diff)
|
||||
# Divs are converted to 4 whitespaces by inscriptis
|
||||
if append_pretty_line_formatting and len(html_block) and (not hasattr( element, 'tag' ) or not element.tag in (['br', 'hr', 'div', 'p'])):
|
||||
html_block += TEXT_FILTER_LIST_LINE_SUFFIX
|
||||
|
||||
if type(element) == etree._ElementStringResult:
|
||||
html_block += str(element)
|
||||
elif type(element) == etree._ElementUnicodeResult:
|
||||
html_block += str(element)
|
||||
else:
|
||||
html_block += etree.tostring(element, pretty_print=True).decode('utf-8')
|
||||
|
||||
return html_block
|
||||
|
||||
# Extract/find element
|
||||
def extract_element(find='title', html_content=''):
|
||||
@@ -195,35 +62,19 @@ def extract_element(find='title', html_content=''):
|
||||
return element_text
|
||||
|
||||
#
|
||||
def _parse_json(json_data, json_filter):
|
||||
if 'json:' in json_filter:
|
||||
jsonpath_expression = parse(json_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
def _parse_json(json_data, jsonpath_filter):
|
||||
s=[]
|
||||
jsonpath_expression = parse(jsonpath_filter.replace('json:', ''))
|
||||
match = jsonpath_expression.find(json_data)
|
||||
|
||||
if 'jq:' in json_filter:
|
||||
|
||||
try:
|
||||
import jq
|
||||
except ModuleNotFoundError:
|
||||
# `jq` requires full compilation in windows and so isn't generally available
|
||||
raise Exception("jq not support not found")
|
||||
|
||||
jq_expression = jq.compile(json_filter.replace('jq:', ''))
|
||||
match = jq_expression.input(json_data).all()
|
||||
|
||||
return _get_stripped_text_from_json_match(match)
|
||||
|
||||
def _get_stripped_text_from_json_match(match):
|
||||
s = []
|
||||
# More than one result, we will return it as a JSON list.
|
||||
if len(match) > 1:
|
||||
for i in match:
|
||||
s.append(i.value if hasattr(i, 'value') else i)
|
||||
s.append(i.value)
|
||||
|
||||
# Single value, use just the value, as it could be later used in a token in notifications.
|
||||
if len(match) == 1:
|
||||
s = match[0].value if hasattr(match[0], 'value') else match[0]
|
||||
s = match[0].value
|
||||
|
||||
# Re #257 - Better handling where it does not exist, in the case the original 's' value was False..
|
||||
if not match:
|
||||
@@ -235,64 +86,37 @@ def _get_stripped_text_from_json_match(match):
|
||||
|
||||
return stripped_text_from_html
|
||||
|
||||
# content - json
|
||||
# json_filter - ie json:$..price
|
||||
# ensure_is_ldjson_info_type - str "product", optional, "@type == product" (I dont know how to do that as a json selector)
|
||||
def extract_json_as_string(content, json_filter, ensure_is_ldjson_info_type=None):
|
||||
def extract_json_as_string(content, jsonpath_filter):
|
||||
|
||||
stripped_text_from_html = False
|
||||
|
||||
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded within HTML tags
|
||||
# Try to parse/filter out the JSON, if we get some parser error, then maybe it's embedded <script type=ldjson>
|
||||
try:
|
||||
stripped_text_from_html = _parse_json(json.loads(content), json_filter)
|
||||
stripped_text_from_html = _parse_json(json.loads(content), jsonpath_filter)
|
||||
except json.JSONDecodeError:
|
||||
|
||||
# Foreach <script json></script> blob.. just return the first that matches json_filter
|
||||
# As a last resort, try to parse the whole <body>
|
||||
# Foreach <script json></script> blob.. just return the first that matches jsonpath_filter
|
||||
s = []
|
||||
soup = BeautifulSoup(content, 'html.parser')
|
||||
bs_result = soup.findAll('script')
|
||||
|
||||
if ensure_is_ldjson_info_type:
|
||||
bs_result = soup.findAll('script', {"type": "application/ld+json"})
|
||||
else:
|
||||
bs_result = soup.findAll('script')
|
||||
bs_result += soup.findAll('body')
|
||||
if not bs_result:
|
||||
raise JSONNotFound("No parsable JSON found in this document")
|
||||
|
||||
bs_jsons = []
|
||||
for result in bs_result:
|
||||
# Skip empty tags, and things that dont even look like JSON
|
||||
if not result.text or '{' not in result.text:
|
||||
if not result.string or not '{' in result.string:
|
||||
continue
|
||||
|
||||
try:
|
||||
json_data = json.loads(result.text)
|
||||
bs_jsons.append(json_data)
|
||||
json_data = json.loads(result.string)
|
||||
except json.JSONDecodeError:
|
||||
# Skip objects which cannot be parsed
|
||||
# Just skip it
|
||||
continue
|
||||
|
||||
if not bs_jsons:
|
||||
raise JSONNotFound("No parsable JSON found in this document")
|
||||
|
||||
for json_data in bs_jsons:
|
||||
stripped_text_from_html = _parse_json(json_data, json_filter)
|
||||
|
||||
if ensure_is_ldjson_info_type:
|
||||
# Could sometimes be list, string or something else random
|
||||
if isinstance(json_data, dict):
|
||||
# If it has LD JSON 'key' @type, and @type is 'product', and something was found for the search
|
||||
# (Some sites have multiple of the same ld+json @type='product', but some have the review part, some have the 'price' part)
|
||||
# @type could also be a list (Product, SubType)
|
||||
# LD_JSON auto-extract also requires some content PLUS the ldjson to be present
|
||||
# 1833 - could be either str or dict, should not be anything else
|
||||
if json_data.get('@type') and stripped_text_from_html:
|
||||
try:
|
||||
if json_data.get('@type') == str or json_data.get('@type') == dict:
|
||||
types = [json_data.get('@type')] if isinstance(json_data.get('@type'), str) else json_data.get('@type')
|
||||
if ensure_is_ldjson_info_type.lower() in [x.lower().strip() for x in types]:
|
||||
break
|
||||
except:
|
||||
continue
|
||||
|
||||
elif stripped_text_from_html:
|
||||
break
|
||||
else:
|
||||
stripped_text_from_html = _parse_json(json_data, jsonpath_filter)
|
||||
if stripped_text_from_html:
|
||||
break
|
||||
|
||||
if not stripped_text_from_html:
|
||||
# Re 265 - Just return an empty string when filter not found
|
||||
@@ -305,56 +129,50 @@ def extract_json_as_string(content, json_filter, ensure_is_ldjson_info_type=None
|
||||
#
|
||||
# wordlist - list of regex's (str) or words (str)
|
||||
def strip_ignore_text(content, wordlist, mode="content"):
|
||||
ignore = []
|
||||
ignore_regex = []
|
||||
|
||||
# @todo check this runs case insensitive
|
||||
for k in wordlist:
|
||||
|
||||
# Is it a regex?
|
||||
if k[0] == '/':
|
||||
ignore_regex.append(k.strip(" /"))
|
||||
else:
|
||||
ignore.append(k)
|
||||
|
||||
i = 0
|
||||
output = []
|
||||
ignore_text = []
|
||||
ignore_regex = []
|
||||
ignored_line_numbers = []
|
||||
|
||||
for k in wordlist:
|
||||
# Is it a regex?
|
||||
res = re.search(PERL_STYLE_REGEX, k, re.IGNORECASE)
|
||||
if res:
|
||||
ignore_regex.append(re.compile(perl_style_slash_enclosed_regex_to_options(k)))
|
||||
else:
|
||||
ignore_text.append(k.strip())
|
||||
|
||||
for line in content.splitlines():
|
||||
i += 1
|
||||
# Always ignore blank lines in this mode. (when this function gets called)
|
||||
got_match = False
|
||||
if len(line.strip()):
|
||||
for l in ignore_text:
|
||||
if l.lower() in line.lower():
|
||||
got_match = True
|
||||
regex_matches = False
|
||||
|
||||
if not got_match:
|
||||
for r in ignore_regex:
|
||||
if r.search(line):
|
||||
got_match = True
|
||||
# if any of these match, skip
|
||||
for regex in ignore_regex:
|
||||
try:
|
||||
if re.search(regex, line, re.IGNORECASE):
|
||||
regex_matches = True
|
||||
except Exception as e:
|
||||
continue
|
||||
|
||||
if not got_match:
|
||||
# Not ignored
|
||||
if not regex_matches and not any(skip_text.lower() in line.lower() for skip_text in ignore):
|
||||
output.append(line.encode('utf8'))
|
||||
else:
|
||||
ignored_line_numbers.append(i)
|
||||
|
||||
|
||||
|
||||
# Used for finding out what to highlight
|
||||
if mode == "line numbers":
|
||||
return ignored_line_numbers
|
||||
|
||||
return "\n".encode('utf8').join(output)
|
||||
|
||||
def cdata_in_document_to_text(html_content: str, render_anchor_tag_content=False) -> str:
|
||||
pattern = '<!\[CDATA\[(\s*(?:.(?<!\]\]>)\s*)*)\]\]>'
|
||||
def repl(m):
|
||||
text = m.group(1)
|
||||
return xml_escape(html_to_text(html_content=text)).strip()
|
||||
|
||||
return re.sub(pattern, repl, html_content)
|
||||
|
||||
def html_to_text(html_content: str, render_anchor_tag_content=False, is_rss=False) -> str:
|
||||
def html_to_text(html_content: str, render_anchor_tag_content=False) -> str:
|
||||
"""Converts html string to a string with just the text. If ignoring
|
||||
rendering anchor tag content is enable, anchor tag content are also
|
||||
included in the text
|
||||
@@ -370,72 +188,17 @@ def html_to_text(html_content: str, render_anchor_tag_content=False, is_rss=Fals
|
||||
# if anchor tag content flag is set to True define a config for
|
||||
# extracting this content
|
||||
if render_anchor_tag_content:
|
||||
|
||||
parser_config = ParserConfig(
|
||||
annotation_rules={"a": ["hyperlink"]},
|
||||
display_links=True
|
||||
annotation_rules={"a": ["hyperlink"]}, display_links=True
|
||||
)
|
||||
# otherwise set config to None/default
|
||||
|
||||
# otherwise set config to None
|
||||
else:
|
||||
parser_config = None
|
||||
|
||||
# RSS Mode - Inscriptis will treat `title` as something else.
|
||||
# Make it as a regular block display element (//item/title)
|
||||
# This is a bit of a hack - the real way it to use XSLT to convert it to HTML #1874
|
||||
if is_rss:
|
||||
html_content = re.sub(r'<title([\s>])', r'<h1\1', html_content)
|
||||
html_content = re.sub(r'</title>', r'</h1>', html_content)
|
||||
|
||||
# get text and annotations via inscriptis
|
||||
text_content = get_text(html_content, config=parser_config)
|
||||
|
||||
return text_content
|
||||
|
||||
|
||||
# Does LD+JSON exist with a @type=='product' and a .price set anywhere?
|
||||
def has_ldjson_product_info(content):
|
||||
pricing_data = ''
|
||||
|
||||
try:
|
||||
if not 'application/ld+json' in content:
|
||||
return False
|
||||
|
||||
for filter in LD_JSON_PRODUCT_OFFER_SELECTORS:
|
||||
pricing_data += extract_json_as_string(content=content,
|
||||
json_filter=filter,
|
||||
ensure_is_ldjson_info_type="product")
|
||||
|
||||
except Exception as e:
|
||||
# Totally fine
|
||||
return False
|
||||
x=bool(pricing_data)
|
||||
return x
|
||||
|
||||
|
||||
def workarounds_for_obfuscations(content):
|
||||
"""
|
||||
Some sites are using sneaky tactics to make prices and other information un-renderable by Inscriptis
|
||||
This could go into its own Pip package in the future, for faster updates
|
||||
"""
|
||||
|
||||
# HomeDepot.com style <span>$<!-- -->90<!-- -->.<!-- -->74</span>
|
||||
# https://github.com/weblyzard/inscriptis/issues/45
|
||||
if not content:
|
||||
return content
|
||||
|
||||
content = re.sub('<!--\s+-->', '', content)
|
||||
|
||||
return content
|
||||
|
||||
|
||||
def get_triggered_text(content, trigger_text):
|
||||
triggered_text = []
|
||||
result = strip_ignore_text(content=content,
|
||||
wordlist=trigger_text,
|
||||
mode="line numbers")
|
||||
|
||||
i = 1
|
||||
for p in content.splitlines():
|
||||
if i in result:
|
||||
triggered_text.append(p)
|
||||
i += 1
|
||||
|
||||
return triggered_text
|
||||
|
||||
@@ -1,303 +0,0 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import time
|
||||
import validators
|
||||
from wtforms import ValidationError
|
||||
from loguru import logger
|
||||
|
||||
from changedetectionio.forms import validate_url
|
||||
|
||||
|
||||
class Importer():
|
||||
remaining_data = []
|
||||
new_uuids = []
|
||||
good = 0
|
||||
|
||||
def __init__(self):
|
||||
self.new_uuids = []
|
||||
self.good = 0
|
||||
self.remaining_data = []
|
||||
self.import_profile = None
|
||||
|
||||
@abstractmethod
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore):
|
||||
pass
|
||||
|
||||
|
||||
class import_url_list(Importer):
|
||||
"""
|
||||
Imports a list, can be in <code>https://example.com tag1, tag2, last tag</code> format
|
||||
"""
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
processor=None
|
||||
):
|
||||
|
||||
urls = data.split("\n")
|
||||
good = 0
|
||||
now = time.time()
|
||||
|
||||
if (len(urls) > 5000):
|
||||
flash("Importing 5,000 of the first URLs from your list, the rest can be imported again.")
|
||||
|
||||
for url in urls:
|
||||
url = url.strip()
|
||||
if not len(url):
|
||||
continue
|
||||
|
||||
tags = ""
|
||||
|
||||
# 'tags' should be a csv list after the URL
|
||||
if ' ' in url:
|
||||
url, tags = url.split(" ", 1)
|
||||
|
||||
# Flask wtform validators wont work with basic auth, use validators package
|
||||
# Up to 5000 per batch so we dont flood the server
|
||||
# @todo validators.url failed on local hostnames (such as referring to ourself when using browserless)
|
||||
if len(url) and 'http' in url.lower() and good < 5000:
|
||||
extras = None
|
||||
if processor:
|
||||
extras = {'processor': processor}
|
||||
new_uuid = datastore.add_watch(url=url.strip(), tag=tags, write_to_disk_now=False, extras=extras)
|
||||
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
continue
|
||||
|
||||
# Worked past the 'continue' above, append it to the bad list
|
||||
if self.remaining_data is None:
|
||||
self.remaining_data = []
|
||||
self.remaining_data.append(url)
|
||||
|
||||
flash("{} Imported from list in {:.2f}s, {} Skipped.".format(good, time.time() - now, len(self.remaining_data)))
|
||||
|
||||
|
||||
class import_distill_io_json(Importer):
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
):
|
||||
|
||||
import json
|
||||
good = 0
|
||||
now = time.time()
|
||||
self.new_uuids=[]
|
||||
|
||||
# @todo Use JSONSchema like in the API to validate here.
|
||||
|
||||
try:
|
||||
data = json.loads(data.strip())
|
||||
except json.decoder.JSONDecodeError:
|
||||
flash("Unable to read JSON file, was it broken?", 'error')
|
||||
return
|
||||
|
||||
if not data.get('data'):
|
||||
flash("JSON structure looks invalid, was it broken?", 'error')
|
||||
return
|
||||
|
||||
for d in data.get('data'):
|
||||
d_config = json.loads(d['config'])
|
||||
extras = {'title': d.get('name', None)}
|
||||
|
||||
if len(d['uri']) and good < 5000:
|
||||
try:
|
||||
# @todo we only support CSS ones at the moment
|
||||
if d_config['selections'][0]['frames'][0]['excludes'][0]['type'] == 'css':
|
||||
extras['subtractive_selectors'] = d_config['selections'][0]['frames'][0]['excludes'][0]['expr']
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
extras['include_filters'] = []
|
||||
try:
|
||||
if d_config['selections'][0]['frames'][0]['includes'][0]['type'] == 'xpath':
|
||||
extras['include_filters'].append('xpath:' + d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
else:
|
||||
extras['include_filters'].append(d_config['selections'][0]['frames'][0]['includes'][0]['expr'])
|
||||
except KeyError:
|
||||
pass
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
new_uuid = datastore.add_watch(url=d['uri'].strip(),
|
||||
tag=",".join(d.get('tags', [])),
|
||||
extras=extras,
|
||||
write_to_disk_now=False)
|
||||
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
|
||||
flash("{} Imported from Distill.io in {:.2f}s, {} Skipped.".format(len(self.new_uuids), time.time() - now, len(self.remaining_data)))
|
||||
|
||||
|
||||
class import_xlsx_wachete(Importer):
|
||||
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
):
|
||||
|
||||
good = 0
|
||||
now = time.time()
|
||||
self.new_uuids = []
|
||||
|
||||
from openpyxl import load_workbook
|
||||
|
||||
try:
|
||||
wb = load_workbook(data)
|
||||
except Exception as e:
|
||||
# @todo correct except
|
||||
flash("Unable to read export XLSX file, something wrong with the file?", 'error')
|
||||
return
|
||||
|
||||
row_id = 2
|
||||
for row in wb.active.iter_rows(min_row=row_id):
|
||||
try:
|
||||
extras = {}
|
||||
data = {}
|
||||
for cell in row:
|
||||
if not cell.value:
|
||||
continue
|
||||
column_title = wb.active.cell(row=1, column=cell.column).value.strip().lower()
|
||||
data[column_title] = cell.value
|
||||
|
||||
# Forced switch to webdriver/playwright/etc
|
||||
dynamic_wachet = str(data.get('dynamic wachet', '')).strip().lower() # Convert bool to str to cover all cases
|
||||
# libreoffice and others can have it as =FALSE() =TRUE(), or bool(true)
|
||||
if 'true' in dynamic_wachet or dynamic_wachet == '1':
|
||||
extras['fetch_backend'] = 'html_webdriver'
|
||||
elif 'false' in dynamic_wachet or dynamic_wachet == '0':
|
||||
extras['fetch_backend'] = 'html_requests'
|
||||
|
||||
if data.get('xpath'):
|
||||
# @todo split by || ?
|
||||
extras['include_filters'] = [data.get('xpath')]
|
||||
if data.get('name'):
|
||||
extras['title'] = data.get('name').strip()
|
||||
if data.get('interval (min)'):
|
||||
minutes = int(data.get('interval (min)'))
|
||||
hours, minutes = divmod(minutes, 60)
|
||||
days, hours = divmod(hours, 24)
|
||||
weeks, days = divmod(days, 7)
|
||||
extras['time_between_check'] = {'weeks': weeks, 'days': days, 'hours': hours, 'minutes': minutes, 'seconds': 0}
|
||||
|
||||
# At minimum a URL is required.
|
||||
if data.get('url'):
|
||||
try:
|
||||
validate_url(data.get('url'))
|
||||
except ValidationError as e:
|
||||
logger.error(f">> Import URL error {data.get('url')} {str(e)}")
|
||||
flash(f"Error processing row number {row_id}, URL value was incorrect, row was skipped.", 'error')
|
||||
# Don't bother processing anything else on this row
|
||||
continue
|
||||
|
||||
new_uuid = datastore.add_watch(url=data['url'].strip(),
|
||||
extras=extras,
|
||||
tag=data.get('folder'),
|
||||
write_to_disk_now=False)
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
flash(f"Error processing row number {row_id}, check all cell data types are correct, row was skipped.", 'error')
|
||||
else:
|
||||
row_id += 1
|
||||
|
||||
flash(
|
||||
"{} imported from Wachete .xlsx in {:.2f}s".format(len(self.new_uuids), time.time() - now))
|
||||
|
||||
|
||||
class import_xlsx_custom(Importer):
|
||||
|
||||
def run(self,
|
||||
data,
|
||||
flash,
|
||||
datastore,
|
||||
):
|
||||
|
||||
good = 0
|
||||
now = time.time()
|
||||
self.new_uuids = []
|
||||
|
||||
from openpyxl import load_workbook
|
||||
|
||||
try:
|
||||
wb = load_workbook(data)
|
||||
except Exception as e:
|
||||
# @todo correct except
|
||||
flash("Unable to read export XLSX file, something wrong with the file?", 'error')
|
||||
return
|
||||
|
||||
# @todo cehck atleast 2 rows, same in other method
|
||||
from .forms import validate_url
|
||||
row_i = 1
|
||||
|
||||
try:
|
||||
for row in wb.active.iter_rows():
|
||||
url = None
|
||||
tags = None
|
||||
extras = {}
|
||||
|
||||
for cell in row:
|
||||
if not self.import_profile.get(cell.col_idx):
|
||||
continue
|
||||
if not cell.value:
|
||||
continue
|
||||
|
||||
cell_map = self.import_profile.get(cell.col_idx)
|
||||
|
||||
cell_val = str(cell.value).strip() # could be bool
|
||||
|
||||
if cell_map == 'url':
|
||||
url = cell.value.strip()
|
||||
try:
|
||||
validate_url(url)
|
||||
except ValidationError as e:
|
||||
logger.error(f">> Import URL error {url} {str(e)}")
|
||||
flash(f"Error processing row number {row_i}, URL value was incorrect, row was skipped.", 'error')
|
||||
# Don't bother processing anything else on this row
|
||||
url = None
|
||||
break
|
||||
elif cell_map == 'tag':
|
||||
tags = cell.value.strip()
|
||||
elif cell_map == 'include_filters':
|
||||
# @todo validate?
|
||||
extras['include_filters'] = [cell.value.strip()]
|
||||
elif cell_map == 'interval_minutes':
|
||||
hours, minutes = divmod(int(cell_val), 60)
|
||||
days, hours = divmod(hours, 24)
|
||||
weeks, days = divmod(days, 7)
|
||||
extras['time_between_check'] = {'weeks': weeks, 'days': days, 'hours': hours, 'minutes': minutes, 'seconds': 0}
|
||||
else:
|
||||
extras[cell_map] = cell_val
|
||||
|
||||
# At minimum a URL is required.
|
||||
if url:
|
||||
new_uuid = datastore.add_watch(url=url,
|
||||
extras=extras,
|
||||
tag=tags,
|
||||
write_to_disk_now=False)
|
||||
if new_uuid:
|
||||
# Straight into the queue.
|
||||
self.new_uuids.append(new_uuid)
|
||||
good += 1
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
flash(f"Error processing row number {row_i}, check all cell data types are correct, row was skipped.", 'error')
|
||||
else:
|
||||
row_i += 1
|
||||
|
||||
flash(
|
||||
"{} imported from custom .xlsx in {:.2f}s".format(len(self.new_uuids), time.time() - now))
|
||||
@@ -1,50 +1,46 @@
|
||||
from os import getenv
|
||||
import collections
|
||||
import os
|
||||
|
||||
import uuid as uuid_builder
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
)
|
||||
|
||||
_FILTER_FAILURE_THRESHOLD_ATTEMPTS_DEFAULT = 6
|
||||
|
||||
class model(dict):
|
||||
base_config = {
|
||||
'note': "Hello! If you change this file manually, please be sure to restart your changedetection.io instance!",
|
||||
'watching': {},
|
||||
'settings': {
|
||||
'headers': {
|
||||
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',
|
||||
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
|
||||
'Accept-Encoding': 'gzip, deflate', # No support for brolti in python requests yet.
|
||||
'Accept-Language': 'en-GB,en-US;q=0.9,en;'
|
||||
},
|
||||
'requests': {
|
||||
'extra_proxies': [], # Configurable extra proxies via the UI
|
||||
'extra_browsers': [], # Configurable extra proxies via the UI
|
||||
'jitter_seconds': 0,
|
||||
'proxy': None, # Preferred proxy connection
|
||||
'timeout': 15, # Default 15 seconds
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': 3, 'minutes': None, 'seconds': None},
|
||||
'timeout': int(getenv("DEFAULT_SETTINGS_REQUESTS_TIMEOUT", "45")), # Default 45 seconds
|
||||
'workers': int(getenv("DEFAULT_SETTINGS_REQUESTS_WORKERS", "10")), # Number of threads, lower is better for slow connections
|
||||
'workers': 10 # Number of threads, lower is better for slow connections
|
||||
},
|
||||
'application': {
|
||||
# Custom notification content
|
||||
'api_access_token_enabled': True,
|
||||
'password': False,
|
||||
'base_url' : None,
|
||||
'empty_pages_are_a_change': False,
|
||||
'extract_title_as_title': False,
|
||||
'fetch_backend': getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'filter_failure_notification_threshold_attempts': _FILTER_FAILURE_THRESHOLD_ATTEMPTS_DEFAULT,
|
||||
'fetch_backend': os.getenv("DEFAULT_FETCH_BACKEND", "html_requests"),
|
||||
'global_ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'global_subtractive_selectors': [],
|
||||
'ignore_whitespace': True,
|
||||
'ignore_whitespace': False,
|
||||
'render_anchor_tag_content': False,
|
||||
'notification_urls': [], # Apprise URL list
|
||||
# Custom notification content
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'notification_title': default_notification_title,
|
||||
'notification_urls': [], # Apprise URL list
|
||||
'pager_size': 50,
|
||||
'password': False,
|
||||
'render_anchor_tag_content': False,
|
||||
'schema_version' : 0,
|
||||
'shared_diff_access': False,
|
||||
'webdriver_delay': None , # Extra delay in seconds before extracting text
|
||||
'tags': {} #@todo use Tag.model initialisers
|
||||
'real_browser_save_screenshot': True,
|
||||
'schema_version' : 0
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -52,15 +48,3 @@ class model(dict):
|
||||
def __init__(self, *arg, **kw):
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
self.update(self.base_config)
|
||||
|
||||
|
||||
def parse_headers_from_text_file(filepath):
|
||||
headers = {}
|
||||
with open(filepath, 'r') as f:
|
||||
for l in f.readlines():
|
||||
l = l.strip()
|
||||
if not l.startswith('#') and ':' in l:
|
||||
(k, v) = l.split(':')
|
||||
headers[k.strip()] = v.strip()
|
||||
|
||||
return headers
|
||||
@@ -1,19 +0,0 @@
|
||||
from .Watch import base_config
|
||||
import uuid
|
||||
|
||||
class model(dict):
|
||||
|
||||
def __init__(self, *arg, **kw):
|
||||
|
||||
self.update(base_config)
|
||||
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
if kw.get('default'):
|
||||
self.update(kw['default'])
|
||||
del kw['default']
|
||||
|
||||
|
||||
# Goes at the end so we update the default object with the initialiser
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
|
||||
@@ -1,363 +1,55 @@
|
||||
from distutils.util import strtobool
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import uuid
|
||||
from pathlib import Path
|
||||
from loguru import logger
|
||||
|
||||
# Allowable protocols, protects against javascript: etc
|
||||
# file:// is further checked by ALLOW_FILE_URI
|
||||
SAFE_PROTOCOL_REGEX='^(http|https|ftp|file):'
|
||||
import uuid as uuid_builder
|
||||
|
||||
minimum_seconds_recheck_time = int(os.getenv('MINIMUM_SECONDS_RECHECK_TIME', 60))
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
|
||||
from changedetectionio.notification import (
|
||||
default_notification_format_for_watch
|
||||
default_notification_body,
|
||||
default_notification_format,
|
||||
default_notification_title,
|
||||
)
|
||||
|
||||
base_config = {
|
||||
'body': None,
|
||||
'browser_steps': [],
|
||||
'browser_steps_last_error_step': None,
|
||||
'check_unique_lines': False, # On change-detected, compare against all history if its something new
|
||||
'check_count': 0,
|
||||
'date_created': None,
|
||||
'consecutive_filter_failures': 0, # Every time the CSS/xPath filter cannot be located, reset when all is fine.
|
||||
'extract_text': [], # Extract text by regex after filters
|
||||
'extract_title_as_title': False,
|
||||
'fetch_backend': 'system', # plaintext, playwright etc
|
||||
'fetch_time': 0.0,
|
||||
'processor': 'text_json_diff', # could be restock_diff or others from .processors
|
||||
'filter_failure_notification_send': strtobool(os.getenv('FILTER_FAILURE_NOTIFICATION_SEND_DEFAULT', 'True')),
|
||||
'filter_text_added': True,
|
||||
'filter_text_replaced': True,
|
||||
'filter_text_removed': True,
|
||||
'has_ldjson_price_data': None,
|
||||
'track_ldjson_price_data': None,
|
||||
'headers': {}, # Extra headers to send
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
'in_stock' : None,
|
||||
'in_stock_only' : True, # Only trigger change on going to instock from out-of-stock
|
||||
'include_filters': [],
|
||||
'last_checked': 0,
|
||||
'last_error': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'method': 'GET',
|
||||
# Custom notification content
|
||||
'notification_body': None,
|
||||
'notification_format': default_notification_format_for_watch,
|
||||
'notification_muted': False,
|
||||
'notification_title': None,
|
||||
'notification_screenshot': False, # Include the latest screenshot if available and supported by the apprise URL
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'paused': False,
|
||||
'previous_md5': False,
|
||||
'previous_md5_before_filters': False, # Used for skipping changedetection entirely
|
||||
'proxy': None, # Preferred proxy connection
|
||||
'subtractive_selectors': [],
|
||||
'tag': '', # Old system of text name for a tag, to be removed
|
||||
'tags': [], # list of UUIDs to App.Tags
|
||||
'text_should_not_be_present': [], # Text that should not present
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None},
|
||||
'title': None,
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'url': '',
|
||||
'uuid': str(uuid.uuid4()),
|
||||
'webdriver_delay': None,
|
||||
'webdriver_js_execute_code': None, # Run before change-detection
|
||||
}
|
||||
|
||||
|
||||
def is_safe_url(test_url):
|
||||
# See https://github.com/dgtlmoon/changedetection.io/issues/1358
|
||||
|
||||
# Remove 'source:' prefix so we dont get 'source:javascript:' etc
|
||||
# 'source:' is a valid way to tell us to return the source
|
||||
|
||||
r = re.compile(re.escape('source:'), re.IGNORECASE)
|
||||
test_url = r.sub('', test_url)
|
||||
|
||||
pattern = re.compile(os.getenv('SAFE_PROTOCOL_REGEX', SAFE_PROTOCOL_REGEX), re.IGNORECASE)
|
||||
if not pattern.match(test_url.strip()):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
class model(dict):
|
||||
__newest_history_key = None
|
||||
__history_n = 0
|
||||
jitter_seconds = 0
|
||||
base_config = {
|
||||
'url': None,
|
||||
'tag': None,
|
||||
'last_checked': 0,
|
||||
'last_changed': 0,
|
||||
'paused': False,
|
||||
'last_viewed': 0, # history key value of the last viewed via the [diff] link
|
||||
'newest_history_key': 0,
|
||||
'title': None,
|
||||
'previous_md5': False,
|
||||
# UUID not needed, should be generated only as a key
|
||||
# 'uuid':
|
||||
'headers': {}, # Extra headers to send
|
||||
'body': None,
|
||||
'method': 'GET',
|
||||
'history': {}, # Dict of timestamp and output stripped filename
|
||||
'ignore_text': [], # List of text to ignore when calculating the comparison checksum
|
||||
# Custom notification content
|
||||
'notification_urls': [], # List of URLs to add to the notification Queue (Usually AppRise)
|
||||
'notification_title': default_notification_title,
|
||||
'notification_body': default_notification_body,
|
||||
'notification_format': default_notification_format,
|
||||
'css_filter': "",
|
||||
'subtractive_selectors': [],
|
||||
'trigger_text': [], # List of text or regex to wait for until a change is detected
|
||||
'fetch_backend': None,
|
||||
'extract_title_as_title': False,
|
||||
# Re #110, so then if this is set to None, we know to use the default value instead
|
||||
# Requires setting to None on submit if it's the same as the default
|
||||
# Should be all None by default, so we use the system default in this case.
|
||||
'time_between_check': {'weeks': None, 'days': None, 'hours': None, 'minutes': None, 'seconds': None}
|
||||
}
|
||||
|
||||
def __init__(self, *arg, **kw):
|
||||
|
||||
self.update(base_config)
|
||||
self.__datastore_path = kw['datastore_path']
|
||||
|
||||
self['uuid'] = str(uuid.uuid4())
|
||||
|
||||
del kw['datastore_path']
|
||||
|
||||
if kw.get('default'):
|
||||
self.update(kw['default'])
|
||||
del kw['default']
|
||||
|
||||
# Be sure the cached timestamp is ready
|
||||
bump = self.history
|
||||
|
||||
# Goes at the end so we update the default object with the initialiser
|
||||
self.update(self.base_config)
|
||||
# goes at the end so we update the default object with the initialiser
|
||||
super(model, self).__init__(*arg, **kw)
|
||||
|
||||
@property
|
||||
def viewed(self):
|
||||
# Don't return viewed when last_viewed is 0 and newest_key is 0
|
||||
if int(self['last_viewed']) and int(self['last_viewed']) >= int(self.newest_history_key) :
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def ensure_data_dir_exists(self):
|
||||
if not os.path.isdir(self.watch_data_dir):
|
||||
logger.debug(f"> Creating data dir {self.watch_data_dir}")
|
||||
os.mkdir(self.watch_data_dir)
|
||||
|
||||
@property
|
||||
def link(self):
|
||||
|
||||
url = self.get('url', '')
|
||||
if not is_safe_url(url):
|
||||
return 'DISABLED'
|
||||
|
||||
ready_url = url
|
||||
if '{%' in url or '{{' in url:
|
||||
from jinja2 import Environment
|
||||
# Jinja2 available in URLs along with https://pypi.org/project/jinja2-time/
|
||||
jinja2_env = Environment(extensions=['jinja2_time.TimeExtension'])
|
||||
try:
|
||||
ready_url = str(jinja2_env.from_string(url).render())
|
||||
except Exception as e:
|
||||
from flask import (
|
||||
flash, Markup, url_for
|
||||
)
|
||||
message = Markup('<a href="{}#general">The URL {} is invalid and cannot be used, click to edit</a>'.format(
|
||||
url_for('edit_page', uuid=self.get('uuid')), self.get('url', '')))
|
||||
flash(message, 'error')
|
||||
return ''
|
||||
|
||||
if ready_url.startswith('source:'):
|
||||
ready_url=ready_url.replace('source:', '')
|
||||
return ready_url
|
||||
|
||||
@property
|
||||
def is_source_type_url(self):
|
||||
return self.get('url', '').startswith('source:')
|
||||
|
||||
@property
|
||||
def get_fetch_backend(self):
|
||||
"""
|
||||
Like just using the `fetch_backend` key but there could be some logic
|
||||
:return:
|
||||
"""
|
||||
# Maybe also if is_image etc?
|
||||
# This is because chrome/playwright wont render the PDF in the browser and we will just fetch it and use pdf2html to see the text.
|
||||
if self.is_pdf:
|
||||
return 'html_requests'
|
||||
|
||||
return self.get('fetch_backend')
|
||||
|
||||
@property
|
||||
def is_pdf(self):
|
||||
# content_type field is set in the future
|
||||
# https://github.com/dgtlmoon/changedetection.io/issues/1392
|
||||
# Not sure the best logic here
|
||||
return self.get('url', '').lower().endswith('.pdf') or 'pdf' in self.get('content_type', '').lower()
|
||||
|
||||
@property
|
||||
def label(self):
|
||||
# Used for sorting
|
||||
return self.get('title') if self.get('title') else self.get('url')
|
||||
|
||||
@property
|
||||
def last_changed(self):
|
||||
# last_changed will be the newest snapshot, but when we have just one snapshot, it should be 0
|
||||
if self.__history_n <= 1:
|
||||
return 0
|
||||
if self.__newest_history_key:
|
||||
return int(self.__newest_history_key)
|
||||
return 0
|
||||
|
||||
@property
|
||||
def history_n(self):
|
||||
return self.__history_n
|
||||
|
||||
@property
|
||||
def history(self):
|
||||
"""History index is just a text file as a list
|
||||
{watch-uuid}/history.txt
|
||||
|
||||
contains a list like
|
||||
|
||||
{epoch-time},{filename}\n
|
||||
|
||||
We read in this list as the history information
|
||||
|
||||
"""
|
||||
tmp_history = {}
|
||||
|
||||
# Read the history file as a dict
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
if os.path.isfile(fname):
|
||||
logger.debug(f"Reading watch history index for {self.get('uuid')}")
|
||||
with open(fname, "r") as f:
|
||||
for i in f.readlines():
|
||||
if ',' in i:
|
||||
k, v = i.strip().split(',', 2)
|
||||
|
||||
# The index history could contain a relative path, so we need to make the fullpath
|
||||
# so that python can read it
|
||||
if not '/' in v and not '\'' in v:
|
||||
v = os.path.join(self.watch_data_dir, v)
|
||||
else:
|
||||
# It's possible that they moved the datadir on older versions
|
||||
# So the snapshot exists but is in a different path
|
||||
snapshot_fname = v.split('/')[-1]
|
||||
proposed_new_path = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(v) and os.path.exists(proposed_new_path):
|
||||
v = proposed_new_path
|
||||
|
||||
tmp_history[k] = v
|
||||
|
||||
if len(tmp_history):
|
||||
self.__newest_history_key = list(tmp_history.keys())[-1]
|
||||
|
||||
self.__history_n = len(tmp_history)
|
||||
|
||||
return tmp_history
|
||||
|
||||
@property
|
||||
def has_history(self):
|
||||
fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
return os.path.isfile(fname)
|
||||
|
||||
@property
|
||||
def has_browser_steps(self):
|
||||
has_browser_steps = self.get('browser_steps') and list(filter(
|
||||
lambda s: (s['operation'] and len(s['operation']) and s['operation'] != 'Choose one' and s['operation'] != 'Goto site'),
|
||||
self.get('browser_steps')))
|
||||
|
||||
return has_browser_steps
|
||||
|
||||
# Returns the newest key, but if theres only 1 record, then it's counted as not being new, so return 0.
|
||||
@property
|
||||
def newest_history_key(self):
|
||||
if self.__newest_history_key is not None:
|
||||
return self.__newest_history_key
|
||||
|
||||
if len(self.history) <= 1:
|
||||
return 0
|
||||
|
||||
|
||||
bump = self.history
|
||||
return self.__newest_history_key
|
||||
|
||||
# Given an arbitrary timestamp, find the closest next key
|
||||
# For example, last_viewed = 1000 so it should return the next 1001 timestamp
|
||||
#
|
||||
# used for the [diff] button so it can preset a smarter from_version
|
||||
@property
|
||||
def get_next_snapshot_key_to_last_viewed(self):
|
||||
|
||||
"""Unfortunately for now timestamp is stored as string key"""
|
||||
keys = list(self.history.keys())
|
||||
if not keys:
|
||||
return None
|
||||
|
||||
last_viewed = int(self.get('last_viewed'))
|
||||
prev_k = keys[0]
|
||||
sorted_keys = sorted(keys, key=lambda x: int(x))
|
||||
sorted_keys.reverse()
|
||||
|
||||
# When the 'last viewed' timestamp is greater than the newest snapshot, return second last
|
||||
if last_viewed > int(sorted_keys[0]):
|
||||
return sorted_keys[1]
|
||||
|
||||
for k in sorted_keys:
|
||||
if int(k) < last_viewed:
|
||||
if prev_k == sorted_keys[0]:
|
||||
# Return the second last one so we dont recommend the same version compares itself
|
||||
return sorted_keys[1]
|
||||
|
||||
return prev_k
|
||||
prev_k = k
|
||||
|
||||
return keys[0]
|
||||
|
||||
def get_history_snapshot(self, timestamp):
|
||||
import brotli
|
||||
filepath = self.history[timestamp]
|
||||
|
||||
# See if a brotli versions exists and switch to that
|
||||
if not filepath.endswith('.br') and os.path.isfile(f"{filepath}.br"):
|
||||
filepath = f"{filepath}.br"
|
||||
|
||||
# OR in the backup case that the .br does not exist, but the plain one does
|
||||
if filepath.endswith('.br') and not os.path.isfile(filepath):
|
||||
if os.path.isfile(filepath.replace('.br', '')):
|
||||
filepath = filepath.replace('.br', '')
|
||||
|
||||
if filepath.endswith('.br'):
|
||||
# Brotli doesnt have a fileheader to detect it, so we rely on filename
|
||||
# https://www.rfc-editor.org/rfc/rfc7932
|
||||
with open(filepath, 'rb') as f:
|
||||
return(brotli.decompress(f.read()).decode('utf-8'))
|
||||
|
||||
with open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
|
||||
return f.read()
|
||||
|
||||
# Save some text file to the appropriate path and bump the history
|
||||
# result_obj from fetch_site_status.run()
|
||||
def save_history_text(self, contents, timestamp, snapshot_id):
|
||||
import brotli
|
||||
|
||||
self.ensure_data_dir_exists()
|
||||
|
||||
# Small hack so that we sleep just enough to allow 1 second between history snapshots
|
||||
# this is because history.txt indexes/keys snapshots by epoch seconds and we dont want dupe keys
|
||||
if self.__newest_history_key and int(timestamp) == int(self.__newest_history_key):
|
||||
time.sleep(timestamp - self.__newest_history_key)
|
||||
|
||||
threshold = int(os.getenv('SNAPSHOT_BROTLI_COMPRESSION_THRESHOLD', 1024))
|
||||
skip_brotli = strtobool(os.getenv('DISABLE_BROTLI_TEXT_SNAPSHOT', 'False'))
|
||||
|
||||
if not skip_brotli and len(contents) > threshold:
|
||||
snapshot_fname = f"{snapshot_id}.txt.br"
|
||||
dest = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(dest):
|
||||
with open(dest, 'wb') as f:
|
||||
f.write(brotli.compress(contents, mode=brotli.MODE_TEXT))
|
||||
else:
|
||||
snapshot_fname = f"{snapshot_id}.txt"
|
||||
dest = os.path.join(self.watch_data_dir, snapshot_fname)
|
||||
if not os.path.exists(dest):
|
||||
with open(dest, 'wb') as f:
|
||||
f.write(contents)
|
||||
|
||||
# Append to index
|
||||
# @todo check last char was \n
|
||||
index_fname = os.path.join(self.watch_data_dir, "history.txt")
|
||||
with open(index_fname, 'a') as f:
|
||||
f.write("{},{}\n".format(timestamp, snapshot_fname))
|
||||
f.close()
|
||||
|
||||
self.__newest_history_key = timestamp
|
||||
self.__history_n += 1
|
||||
|
||||
# @todo bump static cache of the last timestamp so we dont need to examine the file to set a proper ''viewed'' status
|
||||
return snapshot_fname
|
||||
|
||||
@property
|
||||
def has_empty_checktime(self):
|
||||
@@ -368,186 +60,9 @@ class model(dict):
|
||||
|
||||
def threshold_seconds(self):
|
||||
seconds = 0
|
||||
mtable = {'seconds': 1, 'minutes': 60, 'hours': 3600, 'days': 86400, 'weeks': 86400 * 7}
|
||||
for m, n in mtable.items():
|
||||
x = self.get('time_between_check', {}).get(m, None)
|
||||
if x:
|
||||
seconds += x * n
|
||||
return seconds
|
||||
|
||||
# Iterate over all history texts and see if something new exists
|
||||
def lines_contain_something_unique_compared_to_history(self, lines: list):
|
||||
local_lines = set([l.decode('utf-8').strip().lower() for l in lines])
|
||||
|
||||
# Compare each lines (set) against each history text file (set) looking for something new..
|
||||
existing_history = set({})
|
||||
for k, v in self.history.items():
|
||||
content = self.get_history_snapshot(k)
|
||||
alist = set([line.strip().lower() for line in content.splitlines()])
|
||||
existing_history = existing_history.union(alist)
|
||||
|
||||
# Check that everything in local_lines(new stuff) already exists in existing_history - it should
|
||||
# if not, something new happened
|
||||
return not local_lines.issubset(existing_history)
|
||||
|
||||
def get_screenshot(self):
|
||||
fname = os.path.join(self.watch_data_dir, "last-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
|
||||
# False is not an option for AppRise, must be type None
|
||||
return None
|
||||
|
||||
def __get_file_ctime(self, filename):
|
||||
fname = os.path.join(self.watch_data_dir, filename)
|
||||
if os.path.isfile(fname):
|
||||
return int(os.path.getmtime(fname))
|
||||
return False
|
||||
|
||||
@property
|
||||
def error_text_ctime(self):
|
||||
return self.__get_file_ctime('last-error.txt')
|
||||
|
||||
@property
|
||||
def snapshot_text_ctime(self):
|
||||
if self.history_n==0:
|
||||
return False
|
||||
|
||||
timestamp = list(self.history.keys())[-1]
|
||||
return int(timestamp)
|
||||
|
||||
@property
|
||||
def snapshot_screenshot_ctime(self):
|
||||
return self.__get_file_ctime('last-screenshot.png')
|
||||
|
||||
@property
|
||||
def snapshot_error_screenshot_ctime(self):
|
||||
return self.__get_file_ctime('last-error-screenshot.png')
|
||||
|
||||
@property
|
||||
def watch_data_dir(self):
|
||||
# The base dir of the watch data
|
||||
return os.path.join(self.__datastore_path, self['uuid'])
|
||||
|
||||
def get_error_text(self):
|
||||
"""Return the text saved from a previous request that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.watch_data_dir, "last-error.txt")
|
||||
if os.path.isfile(fname):
|
||||
with open(fname, 'r') as f:
|
||||
return f.read()
|
||||
return False
|
||||
|
||||
def get_error_snapshot(self):
|
||||
"""Return path to the screenshot that resulted in a non-200 error"""
|
||||
fname = os.path.join(self.watch_data_dir, "last-error-screenshot.png")
|
||||
if os.path.isfile(fname):
|
||||
return fname
|
||||
return False
|
||||
|
||||
|
||||
def pause(self):
|
||||
self['paused'] = True
|
||||
|
||||
def unpause(self):
|
||||
self['paused'] = False
|
||||
|
||||
def toggle_pause(self):
|
||||
self['paused'] ^= True
|
||||
|
||||
def mute(self):
|
||||
self['notification_muted'] = True
|
||||
|
||||
def unmute(self):
|
||||
self['notification_muted'] = False
|
||||
|
||||
def toggle_mute(self):
|
||||
self['notification_muted'] ^= True
|
||||
|
||||
def extract_regex_from_all_history(self, regex):
|
||||
import csv
|
||||
import re
|
||||
import datetime
|
||||
csv_output_filename = False
|
||||
csv_writer = False
|
||||
f = None
|
||||
|
||||
# self.history will be keyed with the full path
|
||||
for k, fname in self.history.items():
|
||||
if os.path.isfile(fname):
|
||||
if True:
|
||||
contents = self.get_history_snapshot(k)
|
||||
res = re.findall(regex, contents, re.MULTILINE)
|
||||
if res:
|
||||
if not csv_writer:
|
||||
# A file on the disk can be transferred much faster via flask than a string reply
|
||||
csv_output_filename = 'report.csv'
|
||||
f = open(os.path.join(self.watch_data_dir, csv_output_filename), 'w')
|
||||
# @todo some headers in the future
|
||||
#fieldnames = ['Epoch seconds', 'Date']
|
||||
csv_writer = csv.writer(f,
|
||||
delimiter=',',
|
||||
quotechar='"',
|
||||
quoting=csv.QUOTE_MINIMAL,
|
||||
#fieldnames=fieldnames
|
||||
)
|
||||
csv_writer.writerow(['Epoch seconds', 'Date'])
|
||||
# csv_writer.writeheader()
|
||||
|
||||
date_str = datetime.datetime.fromtimestamp(int(k)).strftime('%Y-%m-%d %H:%M:%S')
|
||||
for r in res:
|
||||
row = [k, date_str]
|
||||
if isinstance(r, str):
|
||||
row.append(r)
|
||||
else:
|
||||
row+=r
|
||||
csv_writer.writerow(row)
|
||||
|
||||
if f:
|
||||
f.close()
|
||||
|
||||
return csv_output_filename
|
||||
|
||||
|
||||
def has_special_diff_filter_options_set(self):
|
||||
|
||||
# All False - nothing would be done, so act like it's not processable
|
||||
if not self.get('filter_text_added', True) and not self.get('filter_text_replaced', True) and not self.get('filter_text_removed', True):
|
||||
return False
|
||||
|
||||
# Or one is set
|
||||
if not self.get('filter_text_added', True) or not self.get('filter_text_replaced', True) or not self.get('filter_text_removed', True):
|
||||
return True
|
||||
|
||||
# None is set
|
||||
return False
|
||||
|
||||
|
||||
def get_last_fetched_before_filters(self):
|
||||
import brotli
|
||||
filepath = os.path.join(self.watch_data_dir, 'last-fetched.br')
|
||||
|
||||
if not os.path.isfile(filepath):
|
||||
# If a previous attempt doesnt yet exist, just snarf the previous snapshot instead
|
||||
dates = list(self.history.keys())
|
||||
if len(dates):
|
||||
return self.get_history_snapshot(dates[-1])
|
||||
else:
|
||||
return ''
|
||||
|
||||
with open(filepath, 'rb') as f:
|
||||
return(brotli.decompress(f.read()).decode('utf-8'))
|
||||
|
||||
def save_last_fetched_before_filters(self, contents):
|
||||
import brotli
|
||||
filepath = os.path.join(self.watch_data_dir, 'last-fetched.br')
|
||||
with open(filepath, 'wb') as f:
|
||||
f.write(brotli.compress(contents, mode=brotli.MODE_TEXT))
|
||||
|
||||
@property
|
||||
def get_browsersteps_available_screenshots(self):
|
||||
"For knowing which screenshots are available to show the user in BrowserSteps UI"
|
||||
available = []
|
||||
for f in Path(self.watch_data_dir).glob('step_before-*.jpeg'):
|
||||
step_n=re.search(r'step_before-(\d+)', f.name)
|
||||
if step_n:
|
||||
available.append(step_n.group(1))
|
||||
return available
|
||||
|
||||
@@ -1,266 +1,126 @@
|
||||
import apprise
|
||||
import time
|
||||
from jinja2 import Environment, BaseLoader
|
||||
from apprise import NotifyFormat
|
||||
import json
|
||||
from loguru import logger
|
||||
|
||||
valid_tokens = {
|
||||
'base_url': '',
|
||||
'current_snapshot': '',
|
||||
'diff': '',
|
||||
'diff_added': '',
|
||||
'diff_full': '',
|
||||
'diff_patch': '',
|
||||
'diff_removed': '',
|
||||
'diff_url': '',
|
||||
'preview_url': '',
|
||||
'triggered_text': '',
|
||||
'watch_tag': '',
|
||||
'watch_title': '',
|
||||
'watch_url': '',
|
||||
'watch_uuid': '',
|
||||
'watch_title': '',
|
||||
'watch_tag': '',
|
||||
'diff': '',
|
||||
'diff_full': '',
|
||||
'diff_url': '',
|
||||
'preview_url': '',
|
||||
'current_snapshot': ''
|
||||
}
|
||||
|
||||
default_notification_format_for_watch = 'System default'
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{{watch_url}} had a change.\n---\n{{diff}}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {{watch_url}}'
|
||||
|
||||
valid_notification_formats = {
|
||||
'Text': NotifyFormat.TEXT,
|
||||
'Markdown': NotifyFormat.MARKDOWN,
|
||||
'HTML': NotifyFormat.HTML,
|
||||
# Used only for editing a watch (not for global)
|
||||
default_notification_format_for_watch: default_notification_format_for_watch
|
||||
}
|
||||
|
||||
# include the decorator
|
||||
from apprise.decorators import notify
|
||||
|
||||
@notify(on="delete")
|
||||
@notify(on="deletes")
|
||||
@notify(on="get")
|
||||
@notify(on="gets")
|
||||
@notify(on="post")
|
||||
@notify(on="posts")
|
||||
@notify(on="put")
|
||||
@notify(on="puts")
|
||||
def apprise_custom_api_call_wrapper(body, title, notify_type, *args, **kwargs):
|
||||
import requests
|
||||
from apprise.utils import parse_url as apprise_parse_url
|
||||
from apprise.URLBase import URLBase
|
||||
|
||||
url = kwargs['meta'].get('url')
|
||||
|
||||
if url.startswith('post'):
|
||||
r = requests.post
|
||||
elif url.startswith('get'):
|
||||
r = requests.get
|
||||
elif url.startswith('put'):
|
||||
r = requests.put
|
||||
elif url.startswith('delete'):
|
||||
r = requests.delete
|
||||
|
||||
url = url.replace('post://', 'http://')
|
||||
url = url.replace('posts://', 'https://')
|
||||
url = url.replace('put://', 'http://')
|
||||
url = url.replace('puts://', 'https://')
|
||||
url = url.replace('get://', 'http://')
|
||||
url = url.replace('gets://', 'https://')
|
||||
url = url.replace('put://', 'http://')
|
||||
url = url.replace('puts://', 'https://')
|
||||
url = url.replace('delete://', 'http://')
|
||||
url = url.replace('deletes://', 'https://')
|
||||
|
||||
headers = {}
|
||||
params = {}
|
||||
auth = None
|
||||
|
||||
# Convert /foobar?+some-header=hello to proper header dictionary
|
||||
results = apprise_parse_url(url)
|
||||
if results:
|
||||
# Add our headers that the user can potentially over-ride if they wish
|
||||
# to to our returned result set and tidy entries by unquoting them
|
||||
headers = {URLBase.unquote(x): URLBase.unquote(y)
|
||||
for x, y in results['qsd+'].items()}
|
||||
|
||||
# https://github.com/caronc/apprise/wiki/Notify_Custom_JSON#get-parameter-manipulation
|
||||
# In Apprise, it relies on prefixing each request arg with "-", because it uses say &method=update as a flag for apprise
|
||||
# but here we are making straight requests, so we need todo convert this against apprise's logic
|
||||
for k, v in results['qsd'].items():
|
||||
if not k.strip('+-') in results['qsd+'].keys():
|
||||
params[URLBase.unquote(k)] = URLBase.unquote(v)
|
||||
|
||||
# Determine Authentication
|
||||
auth = ''
|
||||
if results.get('user') and results.get('password'):
|
||||
auth = (URLBase.unquote(results.get('user')), URLBase.unquote(results.get('user')))
|
||||
elif results.get('user'):
|
||||
auth = (URLBase.unquote(results.get('user')))
|
||||
|
||||
# Try to auto-guess if it's JSON
|
||||
try:
|
||||
json.loads(body)
|
||||
headers['Content-Type'] = 'application/json; charset=utf-8'
|
||||
except ValueError as e:
|
||||
pass
|
||||
|
||||
r(results.get('url'),
|
||||
auth=auth,
|
||||
data=body,
|
||||
headers=headers,
|
||||
params=params
|
||||
)
|
||||
|
||||
default_notification_format = 'Text'
|
||||
default_notification_body = '{watch_url} had a change.\n---\n{diff}\n---\n'
|
||||
default_notification_title = 'ChangeDetection.io Notification - {watch_url}'
|
||||
|
||||
def process_notification(n_object, datastore):
|
||||
|
||||
now = time.time()
|
||||
if n_object.get('notification_timestamp'):
|
||||
logger.trace(f"Time since queued {now-n_object['notification_timestamp']:.3f}s")
|
||||
# Insert variables into the notification content
|
||||
notification_parameters = create_notification_parameters(n_object, datastore)
|
||||
|
||||
# Get the notification body from datastore
|
||||
jinja2_env = Environment(loader=BaseLoader)
|
||||
n_body = jinja2_env.from_string(n_object.get('notification_body', '')).render(**notification_parameters)
|
||||
n_title = jinja2_env.from_string(n_object.get('notification_title', '')).render(**notification_parameters)
|
||||
n_body = n_object.get('notification_body', default_notification_body)
|
||||
n_title = n_object.get('notification_title', default_notification_title)
|
||||
n_format = valid_notification_formats.get(
|
||||
n_object.get('notification_format', default_notification_format),
|
||||
n_object['notification_format'],
|
||||
valid_notification_formats[default_notification_format],
|
||||
)
|
||||
|
||||
# If we arrived with 'System default' then look it up
|
||||
if n_format == default_notification_format_for_watch and datastore.data['settings']['application'].get('notification_format') != default_notification_format_for_watch:
|
||||
# Initially text or whatever
|
||||
n_format = datastore.data['settings']['application'].get('notification_format', valid_notification_formats[default_notification_format])
|
||||
|
||||
logger.trace(f"Complete notification body including Jinja and placeholders calculated in {time.time() - now:.3f}s")
|
||||
# Insert variables into the notification content
|
||||
notification_parameters = create_notification_parameters(n_object, datastore)
|
||||
|
||||
for n_k in notification_parameters:
|
||||
token = '{' + n_k + '}'
|
||||
val = notification_parameters[n_k]
|
||||
n_title = n_title.replace(token, val)
|
||||
n_body = n_body.replace(token, val)
|
||||
|
||||
# https://github.com/caronc/apprise/wiki/Development_LogCapture
|
||||
# Anything higher than or equal to WARNING (which covers things like Connection errors)
|
||||
# raise it as an exception
|
||||
apobjs=[]
|
||||
for url in n_object['notification_urls']:
|
||||
|
||||
sent_objs = []
|
||||
from .apprise_asset import asset
|
||||
apobj = apprise.Apprise(debug=True, asset=asset)
|
||||
apobj = apprise.Apprise(debug=True)
|
||||
url = url.strip()
|
||||
if len(url):
|
||||
print(">> Process Notification: AppRise notifying {}".format(url))
|
||||
with apprise.LogCapture(level=apprise.logging.DEBUG) as logs:
|
||||
# Re 323 - Limit discord length to their 2000 char limit total or it wont send.
|
||||
# Because different notifications may require different pre-processing, run each sequentially :(
|
||||
# 2000 bytes minus -
|
||||
# 200 bytes for the overhead of the _entire_ json payload, 200 bytes for {tts, wait, content} etc headers
|
||||
# Length of URL - Incase they specify a longer custom avatar_url
|
||||
|
||||
if not n_object.get('notification_urls'):
|
||||
return None
|
||||
# So if no avatar_url is specified, add one so it can be correctly calculated into the total payload
|
||||
k = '?' if not '?' in url else '&'
|
||||
if not 'avatar_url' in url:
|
||||
url += k + 'avatar_url=https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
|
||||
|
||||
with apprise.LogCapture(level=apprise.logging.DEBUG) as logs:
|
||||
for url in n_object['notification_urls']:
|
||||
url = url.strip()
|
||||
if not url:
|
||||
logger.warning(f"Process Notification: skipping empty notification URL.")
|
||||
continue
|
||||
if url.startswith('tgram://'):
|
||||
# real limit is 4096, but minus some for extra metadata
|
||||
payload_max_size = 3600
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
|
||||
logger.info(">> Process Notification: AppRise notifying {}".format(url))
|
||||
url = jinja2_env.from_string(url).render(**notification_parameters)
|
||||
elif url.startswith('discord://'):
|
||||
# real limit is 2000, but minus some for extra metadata
|
||||
payload_max_size = 1700
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
|
||||
# Re 323 - Limit discord length to their 2000 char limit total or it wont send.
|
||||
# Because different notifications may require different pre-processing, run each sequentially :(
|
||||
# 2000 bytes minus -
|
||||
# 200 bytes for the overhead of the _entire_ json payload, 200 bytes for {tts, wait, content} etc headers
|
||||
# Length of URL - Incase they specify a longer custom avatar_url
|
||||
apobj.add(url)
|
||||
|
||||
# So if no avatar_url is specified, add one so it can be correctly calculated into the total payload
|
||||
k = '?' if not '?' in url else '&'
|
||||
if not 'avatar_url' in url \
|
||||
and not url.startswith('mail') \
|
||||
and not url.startswith('post') \
|
||||
and not url.startswith('get') \
|
||||
and not url.startswith('delete') \
|
||||
and not url.startswith('put'):
|
||||
url += k + 'avatar_url=https://raw.githubusercontent.com/dgtlmoon/changedetection.io/master/changedetectionio/static/images/avatar-256x256.png'
|
||||
apobj.notify(
|
||||
title=n_title,
|
||||
body=n_body,
|
||||
body_format=n_format)
|
||||
|
||||
if url.startswith('tgram://'):
|
||||
# Telegram only supports a limit subset of HTML, remove the '<br>' we place in.
|
||||
# re https://github.com/dgtlmoon/changedetection.io/issues/555
|
||||
# @todo re-use an existing library we have already imported to strip all non-allowed tags
|
||||
n_body = n_body.replace('<br>', '\n')
|
||||
n_body = n_body.replace('</br>', '\n')
|
||||
# real limit is 4096, but minus some for extra metadata
|
||||
payload_max_size = 3600
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
apobj.clear()
|
||||
|
||||
elif url.startswith('discord://') or url.startswith('https://discordapp.com/api/webhooks') or url.startswith(
|
||||
'https://discord.com/api'):
|
||||
# real limit is 2000, but minus some for extra metadata
|
||||
payload_max_size = 1700
|
||||
body_limit = max(0, payload_max_size - len(n_title))
|
||||
n_title = n_title[0:payload_max_size]
|
||||
n_body = n_body[0:body_limit]
|
||||
|
||||
elif url.startswith('mailto'):
|
||||
# Apprise will default to HTML, so we need to override it
|
||||
# So that whats' generated in n_body is in line with what is going to be sent.
|
||||
# https://github.com/caronc/apprise/issues/633#issuecomment-1191449321
|
||||
if not 'format=' in url and (n_format == 'Text' or n_format == 'Markdown'):
|
||||
prefix = '?' if not '?' in url else '&'
|
||||
# Apprise format is lowercase text https://github.com/caronc/apprise/issues/633
|
||||
n_format = n_format.lower()
|
||||
url = f"{url}{prefix}format={n_format}"
|
||||
# If n_format == HTML, then apprise email should default to text/html and we should be sending HTML only
|
||||
|
||||
apobj.add(url)
|
||||
|
||||
sent_objs.append({'title': n_title,
|
||||
'body': n_body,
|
||||
'url': url,
|
||||
'body_format': n_format})
|
||||
|
||||
# Blast off the notifications tht are set in .add()
|
||||
apobj.notify(
|
||||
title=n_title,
|
||||
body=n_body,
|
||||
body_format=n_format,
|
||||
# False is not an option for AppRise, must be type None
|
||||
attach=n_object.get('screenshot', None)
|
||||
)
|
||||
|
||||
# Give apprise time to register an error
|
||||
time.sleep(3)
|
||||
|
||||
# Returns empty string if nothing found, multi-line string otherwise
|
||||
log_value = logs.getvalue()
|
||||
|
||||
if log_value and 'WARNING' in log_value or 'ERROR' in log_value:
|
||||
raise Exception(log_value)
|
||||
|
||||
# Return what was sent for better logging - after the for loop
|
||||
return sent_objs
|
||||
# Incase it needs to exist in memory for a while after to process(?)
|
||||
apobjs.append(apobj)
|
||||
|
||||
# Returns empty string if nothing found, multi-line string otherwise
|
||||
log_value = logs.getvalue()
|
||||
if log_value and 'WARNING' in log_value or 'ERROR' in log_value:
|
||||
raise Exception(log_value)
|
||||
|
||||
# Notification title + body content parameters get created here.
|
||||
# ( Where we prepare the tokens in the notification to be replaced with actual values )
|
||||
def create_notification_parameters(n_object, datastore):
|
||||
from copy import deepcopy
|
||||
|
||||
# in the case we send a test notification from the main settings, there is no UUID.
|
||||
uuid = n_object['uuid'] if 'uuid' in n_object else ''
|
||||
|
||||
if uuid:
|
||||
watch_title = datastore.data['watching'][uuid].get('title', '')
|
||||
tag_list = []
|
||||
tags = datastore.get_all_tags_for_watch(uuid)
|
||||
if tags:
|
||||
for tag_uuid, tag in tags.items():
|
||||
tag_list.append(tag.get('title'))
|
||||
watch_tag = ', '.join(tag_list)
|
||||
if uuid != '':
|
||||
watch_title = datastore.data['watching'][uuid]['title']
|
||||
watch_tag = datastore.data['watching'][uuid]['tag']
|
||||
else:
|
||||
watch_title = 'Change Detection'
|
||||
watch_tag = ''
|
||||
|
||||
# Create URLs to customise the notification with
|
||||
# active_base_url - set in store.py data property
|
||||
base_url = datastore.data['settings']['application'].get('active_base_url')
|
||||
base_url = datastore.data['settings']['application']['base_url']
|
||||
|
||||
watch_url = n_object['watch_url']
|
||||
|
||||
# Re #148 - Some people have just {base_url} in the body or title, but this may break some notification services
|
||||
# like 'Join', so it's always best to atleast set something obvious so that they are not broken.
|
||||
if base_url == '':
|
||||
base_url = "<base-url-env-var-not-set>"
|
||||
|
||||
diff_url = "{}/diff/{}".format(base_url, uuid)
|
||||
preview_url = "{}/preview/{}".format(base_url, uuid)
|
||||
|
||||
@@ -270,20 +130,16 @@ def create_notification_parameters(n_object, datastore):
|
||||
# Valid_tokens also used as a field validator
|
||||
tokens.update(
|
||||
{
|
||||
'base_url': base_url,
|
||||
'current_snapshot': n_object.get('current_snapshot', ''),
|
||||
'diff': n_object.get('diff', ''), # Null default in the case we use a test
|
||||
'diff_added': n_object.get('diff_added', ''), # Null default in the case we use a test
|
||||
'diff_full': n_object.get('diff_full', ''), # Null default in the case we use a test
|
||||
'diff_patch': n_object.get('diff_patch', ''), # Null default in the case we use a test
|
||||
'diff_removed': n_object.get('diff_removed', ''), # Null default in the case we use a test
|
||||
'diff_url': diff_url,
|
||||
'preview_url': preview_url,
|
||||
'triggered_text': n_object.get('triggered_text', ''),
|
||||
'watch_tag': watch_tag if watch_tag is not None else '',
|
||||
'watch_title': watch_title if watch_title is not None else '',
|
||||
'base_url': base_url if base_url is not None else '',
|
||||
'watch_url': watch_url,
|
||||
'watch_uuid': uuid,
|
||||
'watch_title': watch_title if watch_title is not None else '',
|
||||
'watch_tag': watch_tag if watch_tag is not None else '',
|
||||
'diff_url': diff_url,
|
||||
'diff': n_object.get('diff', ''), # Null default in the case we use a test
|
||||
'diff_full': n_object.get('diff_full', ''), # Null default in the case we use a test
|
||||
'preview_url': preview_url,
|
||||
'current_snapshot': n_object['current_snapshot'] if 'current_snapshot' in n_object else ''
|
||||
})
|
||||
|
||||
return tokens
|
||||
|
||||
@@ -1,11 +0,0 @@
|
||||
# Change detection post-processors
|
||||
|
||||
The concept here is to be able to switch between different domain specific problems to solve.
|
||||
|
||||
- `text_json_diff` The traditional text and JSON comparison handler
|
||||
- `restock_diff` Only cares about detecting if a product looks like it has some text that suggests that it's out of stock, otherwise assumes that it's in stock.
|
||||
|
||||
Some suggestions for the future
|
||||
|
||||
- `graphical`
|
||||
- `restock_and_price` - extract price AND stock text
|
||||
@@ -1,137 +0,0 @@
|
||||
from abc import abstractmethod
|
||||
import os
|
||||
import hashlib
|
||||
import re
|
||||
from changedetectionio import content_fetcher
|
||||
from copy import deepcopy
|
||||
from distutils.util import strtobool
|
||||
from loguru import logger
|
||||
|
||||
class difference_detection_processor():
|
||||
|
||||
browser_steps = None
|
||||
datastore = None
|
||||
fetcher = None
|
||||
screenshot = None
|
||||
watch = None
|
||||
xpath_data = None
|
||||
|
||||
def __init__(self, *args, datastore, watch_uuid, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.datastore = datastore
|
||||
self.watch = deepcopy(self.datastore.data['watching'].get(watch_uuid))
|
||||
|
||||
def call_browser(self):
|
||||
|
||||
# Protect against file:// access
|
||||
if re.search(r'^file://', self.watch.get('url', '').strip(), re.IGNORECASE):
|
||||
if not strtobool(os.getenv('ALLOW_FILE_URI', 'false')):
|
||||
raise Exception(
|
||||
"file:// type access is denied for security reasons."
|
||||
)
|
||||
|
||||
url = self.watch.link
|
||||
|
||||
# Requests, playwright, other browser via wss:// etc, fetch_extra_something
|
||||
prefer_fetch_backend = self.watch.get('fetch_backend', 'system')
|
||||
|
||||
# Proxy ID "key"
|
||||
preferred_proxy_id = self.datastore.get_preferred_proxy_for_watch(uuid=self.watch.get('uuid'))
|
||||
|
||||
# Pluggable content self.fetcher
|
||||
if not prefer_fetch_backend or prefer_fetch_backend == 'system':
|
||||
prefer_fetch_backend = self.datastore.data['settings']['application'].get('fetch_backend')
|
||||
|
||||
# In the case that the preferred fetcher was a browser config with custom connection URL..
|
||||
# @todo - on save watch, if its extra_browser_ then it should be obvious it will use playwright (like if its requests now..)
|
||||
custom_browser_connection_url = None
|
||||
if prefer_fetch_backend.startswith('extra_browser_'):
|
||||
(t, key) = prefer_fetch_backend.split('extra_browser_')
|
||||
connection = list(
|
||||
filter(lambda s: (s['browser_name'] == key), self.datastore.data['settings']['requests'].get('extra_browsers', [])))
|
||||
if connection:
|
||||
prefer_fetch_backend = 'base_html_playwright'
|
||||
custom_browser_connection_url = connection[0].get('browser_connection_url')
|
||||
|
||||
# PDF should be html_requests because playwright will serve it up (so far) in a embedded page
|
||||
# @todo https://github.com/dgtlmoon/changedetection.io/issues/2019
|
||||
# @todo needs test to or a fix
|
||||
if self.watch.is_pdf:
|
||||
prefer_fetch_backend = "html_requests"
|
||||
|
||||
# Grab the right kind of 'fetcher', (playwright, requests, etc)
|
||||
if hasattr(content_fetcher, prefer_fetch_backend):
|
||||
fetcher_obj = getattr(content_fetcher, prefer_fetch_backend)
|
||||
else:
|
||||
# If the klass doesnt exist, just use a default
|
||||
fetcher_obj = getattr(content_fetcher, "html_requests")
|
||||
|
||||
|
||||
proxy_url = None
|
||||
if preferred_proxy_id:
|
||||
proxy_url = self.datastore.proxy_list.get(preferred_proxy_id).get('url')
|
||||
logger.debug(f"Selected proxy key '{preferred_proxy_id}' as proxy URL '{proxy_url}' for {url}")
|
||||
|
||||
# Now call the fetcher (playwright/requests/etc) with arguments that only a fetcher would need.
|
||||
# When browser_connection_url is None, it method should default to working out whats the best defaults (os env vars etc)
|
||||
self.fetcher = fetcher_obj(proxy_override=proxy_url,
|
||||
custom_browser_connection_url=custom_browser_connection_url
|
||||
)
|
||||
|
||||
if self.watch.has_browser_steps:
|
||||
self.fetcher.browser_steps = self.watch.get('browser_steps', [])
|
||||
self.fetcher.browser_steps_screenshot_path = os.path.join(self.datastore.datastore_path, self.watch.get('uuid'))
|
||||
|
||||
# Tweak the base config with the per-watch ones
|
||||
request_headers = self.watch.get('headers', [])
|
||||
request_headers.update(self.datastore.get_all_base_headers())
|
||||
request_headers.update(self.datastore.get_all_headers_in_textfile_for_watch(uuid=self.watch.get('uuid')))
|
||||
|
||||
# https://github.com/psf/requests/issues/4525
|
||||
# Requests doesnt yet support brotli encoding, so don't put 'br' here, be totally sure that the user cannot
|
||||
# do this by accident.
|
||||
if 'Accept-Encoding' in request_headers and "br" in request_headers['Accept-Encoding']:
|
||||
request_headers['Accept-Encoding'] = request_headers['Accept-Encoding'].replace(', br', '')
|
||||
|
||||
timeout = self.datastore.data['settings']['requests'].get('timeout')
|
||||
|
||||
request_body = self.watch.get('body')
|
||||
request_method = self.watch.get('method')
|
||||
ignore_status_codes = self.watch.get('ignore_status_codes', False)
|
||||
|
||||
# Configurable per-watch or global extra delay before extracting text (for webDriver types)
|
||||
system_webdriver_delay = self.datastore.data['settings']['application'].get('webdriver_delay', None)
|
||||
if self.watch.get('webdriver_delay'):
|
||||
self.fetcher.render_extract_delay = self.watch.get('webdriver_delay')
|
||||
elif system_webdriver_delay is not None:
|
||||
self.fetcher.render_extract_delay = system_webdriver_delay
|
||||
|
||||
if self.watch.get('webdriver_js_execute_code') is not None and self.watch.get('webdriver_js_execute_code').strip():
|
||||
self.fetcher.webdriver_js_execute_code = self.watch.get('webdriver_js_execute_code')
|
||||
|
||||
# Requests for PDF's, images etc should be passwd the is_binary flag
|
||||
is_binary = self.watch.is_pdf
|
||||
|
||||
# And here we go! call the right browser with browser-specific settings
|
||||
self.fetcher.run(url, timeout, request_headers, request_body, request_method, ignore_status_codes, self.watch.get('include_filters'),
|
||||
is_binary=is_binary)
|
||||
|
||||
#@todo .quit here could go on close object, so we can run JS if change-detected
|
||||
self.fetcher.quit()
|
||||
|
||||
# After init, call run_changedetection() which will do the actual change-detection
|
||||
|
||||
@abstractmethod
|
||||
def run_changedetection(self, uuid, skip_when_checksum_same=True):
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
some_data = 'xxxxx'
|
||||
update_obj["previous_md5"] = hashlib.md5(some_data.encode('utf-8')).hexdigest()
|
||||
changed_detected = False
|
||||
return changed_detected, update_obj, ''.encode('utf-8')
|
||||
|
||||
|
||||
def available_processors():
|
||||
from . import restock_diff, text_json_diff
|
||||
x=[('text_json_diff', text_json_diff.name), ('restock_diff', restock_diff.name)]
|
||||
# @todo Make this smarter with introspection of sorts.
|
||||
return x
|
||||
@@ -1,66 +0,0 @@
|
||||
|
||||
from . import difference_detection_processor
|
||||
from copy import deepcopy
|
||||
from loguru import logger
|
||||
import hashlib
|
||||
import urllib3
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
name = 'Re-stock detection for single product pages'
|
||||
description = 'Detects if the product goes back to in-stock'
|
||||
|
||||
class UnableToExtractRestockData(Exception):
|
||||
def __init__(self, status_code):
|
||||
# Set this so we can use it in other parts of the app
|
||||
self.status_code = status_code
|
||||
return
|
||||
|
||||
class perform_site_check(difference_detection_processor):
|
||||
screenshot = None
|
||||
xpath_data = None
|
||||
|
||||
def run_changedetection(self, uuid, skip_when_checksum_same=True):
|
||||
|
||||
# DeepCopy so we can be sure we don't accidently change anything by reference
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
|
||||
if not watch:
|
||||
raise Exception("Watch no longer exists.")
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
self.screenshot = self.fetcher.screenshot
|
||||
self.xpath_data = self.fetcher.xpath_data
|
||||
|
||||
# Track the content type
|
||||
update_obj['content_type'] = self.fetcher.headers.get('Content-Type', '')
|
||||
update_obj["last_check_status"] = self.fetcher.get_last_status_code()
|
||||
|
||||
# Main detection method
|
||||
fetched_md5 = None
|
||||
if self.fetcher.instock_data:
|
||||
fetched_md5 = hashlib.md5(self.fetcher.instock_data.encode('utf-8')).hexdigest()
|
||||
# 'Possibly in stock' comes from stock-not-in-stock.js when no string found above the fold.
|
||||
update_obj["in_stock"] = True if self.fetcher.instock_data == 'Possibly in stock' else False
|
||||
logger.debug(f"Watch UUID {uuid} restock check returned '{self.fetcher.instock_data}' from JS scraper.")
|
||||
else:
|
||||
raise UnableToExtractRestockData(status_code=self.fetcher.status_code)
|
||||
|
||||
# The main thing that all this at the moment comes down to :)
|
||||
changed_detected = False
|
||||
logger.debug(f"Watch UUID {uuid} restock check - Previous MD5: {watch.get('previous_md5')}, Fetched MD5 {fetched_md5}")
|
||||
|
||||
if watch.get('previous_md5') and watch.get('previous_md5') != fetched_md5:
|
||||
# Yes if we only care about it going to instock, AND we are in stock
|
||||
if watch.get('in_stock_only') and update_obj["in_stock"]:
|
||||
changed_detected = True
|
||||
|
||||
if not watch.get('in_stock_only'):
|
||||
# All cases
|
||||
changed_detected = True
|
||||
|
||||
# Always record the new checksum
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
return changed_detected, update_obj, self.fetcher.instock_data.encode('utf-8').strip()
|
||||
@@ -1,357 +0,0 @@
|
||||
# HTML to TEXT/JSON DIFFERENCE self.fetcher
|
||||
|
||||
import hashlib
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import urllib3
|
||||
|
||||
from . import difference_detection_processor
|
||||
from ..html_tools import PERL_STYLE_REGEX, cdata_in_document_to_text
|
||||
from changedetectionio import content_fetcher, html_tools
|
||||
from changedetectionio.blueprint.price_data_follower import PRICE_DATA_TRACK_ACCEPT, PRICE_DATA_TRACK_REJECT
|
||||
from copy import deepcopy
|
||||
from loguru import logger
|
||||
|
||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||
|
||||
name = 'Webpage Text/HTML, JSON and PDF changes'
|
||||
description = 'Detects all text changes where possible'
|
||||
json_filter_prefixes = ['json:', 'jq:']
|
||||
|
||||
class FilterNotFoundInResponse(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
class PDFToHTMLToolNotFound(ValueError):
|
||||
def __init__(self, msg):
|
||||
ValueError.__init__(self, msg)
|
||||
|
||||
|
||||
# Some common stuff here that can be moved to a base class
|
||||
# (set_proxy_from_list)
|
||||
class perform_site_check(difference_detection_processor):
|
||||
|
||||
def run_changedetection(self, uuid, skip_when_checksum_same=True):
|
||||
changed_detected = False
|
||||
html_content = ""
|
||||
screenshot = False # as bytes
|
||||
stripped_text_from_html = ""
|
||||
|
||||
# DeepCopy so we can be sure we don't accidently change anything by reference
|
||||
watch = deepcopy(self.datastore.data['watching'].get(uuid))
|
||||
if not watch:
|
||||
raise Exception("Watch no longer exists.")
|
||||
|
||||
# Unset any existing notification error
|
||||
update_obj = {'last_notification_error': False, 'last_error': False}
|
||||
|
||||
url = watch.link
|
||||
|
||||
self.screenshot = self.fetcher.screenshot
|
||||
self.xpath_data = self.fetcher.xpath_data
|
||||
|
||||
# Track the content type
|
||||
update_obj['content_type'] = self.fetcher.get_all_headers().get('content-type', '').lower()
|
||||
|
||||
# Watches added automatically in the queue manager will skip if its the same checksum as the previous run
|
||||
# Saves a lot of CPU
|
||||
update_obj['previous_md5_before_filters'] = hashlib.md5(self.fetcher.content.encode('utf-8')).hexdigest()
|
||||
if skip_when_checksum_same:
|
||||
if update_obj['previous_md5_before_filters'] == watch.get('previous_md5_before_filters'):
|
||||
raise content_fetcher.checksumFromPreviousCheckWasTheSame()
|
||||
|
||||
# Fetching complete, now filters
|
||||
|
||||
# @note: I feel like the following should be in a more obvious chain system
|
||||
# - Check filter text
|
||||
# - Is the checksum different?
|
||||
# - Do we convert to JSON?
|
||||
# https://stackoverflow.com/questions/41817578/basic-method-chaining ?
|
||||
# return content().textfilter().jsonextract().checksumcompare() ?
|
||||
|
||||
is_json = 'application/json' in self.fetcher.get_all_headers().get('content-type', '').lower()
|
||||
is_html = not is_json
|
||||
is_rss = False
|
||||
|
||||
ctype_header = self.fetcher.get_all_headers().get('content-type', '').lower()
|
||||
# Go into RSS preprocess for converting CDATA/comment to usable text
|
||||
if any(substring in ctype_header for substring in ['application/xml', 'application/rss', 'text/xml']):
|
||||
if '<rss' in self.fetcher.content[:100].lower():
|
||||
self.fetcher.content = cdata_in_document_to_text(html_content=self.fetcher.content)
|
||||
is_rss = True
|
||||
|
||||
# source: support, basically treat it as plaintext
|
||||
if watch.is_source_type_url:
|
||||
is_html = False
|
||||
is_json = False
|
||||
|
||||
inline_pdf = self.fetcher.get_all_headers().get('content-disposition', '') and '%PDF-1' in self.fetcher.content[:10]
|
||||
if watch.is_pdf or 'application/pdf' in self.fetcher.get_all_headers().get('content-type', '').lower() or inline_pdf:
|
||||
from shutil import which
|
||||
tool = os.getenv("PDF_TO_HTML_TOOL", "pdftohtml")
|
||||
if not which(tool):
|
||||
raise PDFToHTMLToolNotFound("Command-line `{}` tool was not found in system PATH, was it installed?".format(tool))
|
||||
|
||||
import subprocess
|
||||
proc = subprocess.Popen(
|
||||
[tool, '-stdout', '-', '-s', 'out.pdf', '-i'],
|
||||
stdout=subprocess.PIPE,
|
||||
stdin=subprocess.PIPE)
|
||||
proc.stdin.write(self.fetcher.raw_content)
|
||||
proc.stdin.close()
|
||||
self.fetcher.content = proc.stdout.read().decode('utf-8')
|
||||
proc.wait(timeout=60)
|
||||
|
||||
# Add a little metadata so we know if the file changes (like if an image changes, but the text is the same
|
||||
# @todo may cause problems with non-UTF8?
|
||||
metadata = "<p>Added by changedetection.io: Document checksum - {} Filesize - {} bytes</p>".format(
|
||||
hashlib.md5(self.fetcher.raw_content).hexdigest().upper(),
|
||||
len(self.fetcher.content))
|
||||
|
||||
self.fetcher.content = self.fetcher.content.replace('</body>', metadata + '</body>')
|
||||
|
||||
# Better would be if Watch.model could access the global data also
|
||||
# and then use getattr https://docs.python.org/3/reference/datamodel.html#object.__getitem__
|
||||
# https://realpython.com/inherit-python-dict/ instead of doing it procedurely
|
||||
include_filters_from_tags = self.datastore.get_tag_overrides_for_watch(uuid=uuid, attr='include_filters')
|
||||
include_filters_rule = [*watch.get('include_filters', []), *include_filters_from_tags]
|
||||
|
||||
subtractive_selectors = [*self.datastore.get_tag_overrides_for_watch(uuid=uuid, attr='subtractive_selectors'),
|
||||
*watch.get("subtractive_selectors", []),
|
||||
*self.datastore.data["settings"]["application"].get("global_subtractive_selectors", [])
|
||||
]
|
||||
|
||||
# Inject a virtual LD+JSON price tracker rule
|
||||
if watch.get('track_ldjson_price_data', '') == PRICE_DATA_TRACK_ACCEPT:
|
||||
include_filters_rule += html_tools.LD_JSON_PRODUCT_OFFER_SELECTORS
|
||||
|
||||
has_filter_rule = len(include_filters_rule) and len(include_filters_rule[0].strip())
|
||||
has_subtractive_selectors = len(subtractive_selectors) and len(subtractive_selectors[0].strip())
|
||||
|
||||
if is_json and not has_filter_rule:
|
||||
include_filters_rule.append("json:$")
|
||||
has_filter_rule = True
|
||||
|
||||
if is_json:
|
||||
# Sort the JSON so we dont get false alerts when the content is just re-ordered
|
||||
try:
|
||||
self.fetcher.content = json.dumps(json.loads(self.fetcher.content), sort_keys=True)
|
||||
except Exception as e:
|
||||
# Might have just been a snippet, or otherwise bad JSON, continue
|
||||
pass
|
||||
|
||||
if has_filter_rule:
|
||||
for filter in include_filters_rule:
|
||||
if any(prefix in filter for prefix in json_filter_prefixes):
|
||||
stripped_text_from_html += html_tools.extract_json_as_string(content=self.fetcher.content, json_filter=filter)
|
||||
is_html = False
|
||||
|
||||
if is_html or watch.is_source_type_url:
|
||||
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
self.fetcher.content = html_tools.workarounds_for_obfuscations(self.fetcher.content)
|
||||
html_content = self.fetcher.content
|
||||
|
||||
# If not JSON, and if it's not text/plain..
|
||||
if 'text/plain' in self.fetcher.get_all_headers().get('content-type', '').lower():
|
||||
# Don't run get_text or xpath/css filters on plaintext
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# Does it have some ld+json price data? used for easier monitoring
|
||||
update_obj['has_ldjson_price_data'] = html_tools.has_ldjson_product_info(self.fetcher.content)
|
||||
|
||||
# Then we assume HTML
|
||||
if has_filter_rule:
|
||||
html_content = ""
|
||||
|
||||
for filter_rule in include_filters_rule:
|
||||
# For HTML/XML we offer xpath as an option, just start a regular xPath "/.."
|
||||
if filter_rule[0] == '/' or filter_rule.startswith('xpath:'):
|
||||
html_content += html_tools.xpath_filter(xpath_filter=filter_rule.replace('xpath:', ''),
|
||||
html_content=self.fetcher.content,
|
||||
append_pretty_line_formatting=not watch.is_source_type_url,
|
||||
is_rss=is_rss)
|
||||
elif filter_rule.startswith('xpath1:'):
|
||||
html_content += html_tools.xpath1_filter(xpath_filter=filter_rule.replace('xpath1:', ''),
|
||||
html_content=self.fetcher.content,
|
||||
append_pretty_line_formatting=not watch.is_source_type_url,
|
||||
is_rss=is_rss)
|
||||
else:
|
||||
# CSS Filter, extract the HTML that matches and feed that into the existing inscriptis::get_text
|
||||
html_content += html_tools.include_filters(include_filters=filter_rule,
|
||||
html_content=self.fetcher.content,
|
||||
append_pretty_line_formatting=not watch.is_source_type_url)
|
||||
|
||||
if not html_content.strip():
|
||||
raise FilterNotFoundInResponse(include_filters_rule)
|
||||
|
||||
if has_subtractive_selectors:
|
||||
html_content = html_tools.element_removal(subtractive_selectors, html_content)
|
||||
|
||||
if watch.is_source_type_url:
|
||||
stripped_text_from_html = html_content
|
||||
else:
|
||||
# extract text
|
||||
do_anchor = self.datastore.data["settings"]["application"].get("render_anchor_tag_content", False)
|
||||
stripped_text_from_html = \
|
||||
html_tools.html_to_text(
|
||||
html_content=html_content,
|
||||
render_anchor_tag_content=do_anchor,
|
||||
is_rss=is_rss # #1874 activate the <title workaround hack
|
||||
)
|
||||
|
||||
# Re #340 - return the content before the 'ignore text' was applied
|
||||
text_content_before_ignored_filter = stripped_text_from_html.encode('utf-8')
|
||||
|
||||
# @todo whitespace coming from missing rtrim()?
|
||||
# stripped_text_from_html could be based on their preferences, replace the processed text with only that which they want to know about.
|
||||
# Rewrite's the processing text based on only what diff result they want to see
|
||||
if watch.has_special_diff_filter_options_set() and len(watch.history.keys()):
|
||||
# Now the content comes from the diff-parser and not the returned HTTP traffic, so could be some differences
|
||||
from .. import diff
|
||||
# needs to not include (added) etc or it may get used twice
|
||||
# Replace the processed text with the preferred result
|
||||
rendered_diff = diff.render_diff(previous_version_file_contents=watch.get_last_fetched_before_filters(),
|
||||
newest_version_file_contents=stripped_text_from_html,
|
||||
include_equal=False, # not the same lines
|
||||
include_added=watch.get('filter_text_added', True),
|
||||
include_removed=watch.get('filter_text_removed', True),
|
||||
include_replaced=watch.get('filter_text_replaced', True),
|
||||
line_feed_sep="\n",
|
||||
include_change_type_prefix=False)
|
||||
|
||||
watch.save_last_fetched_before_filters(text_content_before_ignored_filter)
|
||||
|
||||
if not rendered_diff and stripped_text_from_html:
|
||||
# We had some content, but no differences were found
|
||||
# Store our new file as the MD5 so it will trigger in the future
|
||||
c = hashlib.md5(text_content_before_ignored_filter.translate(None, b'\r\n\t ')).hexdigest()
|
||||
return False, {'previous_md5': c}, stripped_text_from_html.encode('utf-8')
|
||||
else:
|
||||
stripped_text_from_html = rendered_diff
|
||||
|
||||
# Treat pages with no renderable text content as a change? No by default
|
||||
empty_pages_are_a_change = self.datastore.data['settings']['application'].get('empty_pages_are_a_change', False)
|
||||
if not is_json and not empty_pages_are_a_change and len(stripped_text_from_html.strip()) == 0:
|
||||
raise content_fetcher.ReplyWithContentButNoText(url=url,
|
||||
status_code=self.fetcher.get_last_status_code(),
|
||||
screenshot=screenshot,
|
||||
has_filters=has_filter_rule,
|
||||
html_content=html_content
|
||||
)
|
||||
|
||||
# We rely on the actual text in the html output.. many sites have random script vars etc,
|
||||
# in the future we'll implement other mechanisms.
|
||||
|
||||
update_obj["last_check_status"] = self.fetcher.get_last_status_code()
|
||||
|
||||
# If there's text to skip
|
||||
# @todo we could abstract out the get_text() to handle this cleaner
|
||||
text_to_ignore = watch.get('ignore_text', []) + self.datastore.data['settings']['application'].get('global_ignore_text', [])
|
||||
if len(text_to_ignore):
|
||||
stripped_text_from_html = html_tools.strip_ignore_text(stripped_text_from_html, text_to_ignore)
|
||||
else:
|
||||
stripped_text_from_html = stripped_text_from_html.encode('utf8')
|
||||
|
||||
# 615 Extract text by regex
|
||||
extract_text = watch.get('extract_text', [])
|
||||
if len(extract_text) > 0:
|
||||
regex_matched_output = []
|
||||
for s_re in extract_text:
|
||||
# incase they specified something in '/.../x'
|
||||
if re.search(PERL_STYLE_REGEX, s_re, re.IGNORECASE):
|
||||
regex = html_tools.perl_style_slash_enclosed_regex_to_options(s_re)
|
||||
result = re.findall(regex.encode('utf-8'), stripped_text_from_html)
|
||||
|
||||
for l in result:
|
||||
if type(l) is tuple:
|
||||
# @todo - some formatter option default (between groups)
|
||||
regex_matched_output += list(l) + [b'\n']
|
||||
else:
|
||||
# @todo - some formatter option default (between each ungrouped result)
|
||||
regex_matched_output += [l] + [b'\n']
|
||||
else:
|
||||
# Doesnt look like regex, just hunt for plaintext and return that which matches
|
||||
# `stripped_text_from_html` will be bytes, so we must encode s_re also to bytes
|
||||
r = re.compile(re.escape(s_re.encode('utf-8')), re.IGNORECASE)
|
||||
res = r.findall(stripped_text_from_html)
|
||||
if res:
|
||||
for match in res:
|
||||
regex_matched_output += [match] + [b'\n']
|
||||
|
||||
# Now we will only show what the regex matched
|
||||
stripped_text_from_html = b''
|
||||
text_content_before_ignored_filter = b''
|
||||
if regex_matched_output:
|
||||
# @todo some formatter for presentation?
|
||||
stripped_text_from_html = b''.join(regex_matched_output)
|
||||
text_content_before_ignored_filter = stripped_text_from_html
|
||||
|
||||
# Re #133 - if we should strip whitespaces from triggering the change detected comparison
|
||||
if self.datastore.data['settings']['application'].get('ignore_whitespace', False):
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html.translate(None, b'\r\n\t ')).hexdigest()
|
||||
else:
|
||||
fetched_md5 = hashlib.md5(stripped_text_from_html).hexdigest()
|
||||
|
||||
############ Blocking rules, after checksum #################
|
||||
blocked = False
|
||||
|
||||
trigger_text = watch.get('trigger_text', [])
|
||||
if len(trigger_text):
|
||||
# Assume blocked
|
||||
blocked = True
|
||||
# Filter and trigger works the same, so reuse it
|
||||
# It should return the line numbers that match
|
||||
# Unblock flow if the trigger was found (some text remained after stripped what didnt match)
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=trigger_text,
|
||||
mode="line numbers")
|
||||
# Unblock if the trigger was found
|
||||
if result:
|
||||
blocked = False
|
||||
|
||||
text_should_not_be_present = watch.get('text_should_not_be_present', [])
|
||||
if len(text_should_not_be_present):
|
||||
# If anything matched, then we should block a change from happening
|
||||
result = html_tools.strip_ignore_text(content=str(stripped_text_from_html),
|
||||
wordlist=text_should_not_be_present,
|
||||
mode="line numbers")
|
||||
if result:
|
||||
blocked = True
|
||||
|
||||
# The main thing that all this at the moment comes down to :)
|
||||
if watch.get('previous_md5') != fetched_md5:
|
||||
changed_detected = True
|
||||
|
||||
# Looks like something changed, but did it match all the rules?
|
||||
if blocked:
|
||||
changed_detected = False
|
||||
|
||||
# Extract title as title
|
||||
if is_html:
|
||||
if self.datastore.data['settings']['application'].get('extract_title_as_title') or watch['extract_title_as_title']:
|
||||
if not watch['title'] or not len(watch['title']):
|
||||
update_obj['title'] = html_tools.extract_element(find='title', html_content=self.fetcher.content)
|
||||
|
||||
logger.debug(f"Watch UUID {uuid} content check - Previous MD5: {watch.get('previous_md5')}, Fetched MD5 {fetched_md5}")
|
||||
|
||||
if changed_detected:
|
||||
if watch.get('check_unique_lines', False):
|
||||
has_unique_lines = watch.lines_contain_something_unique_compared_to_history(lines=stripped_text_from_html.splitlines())
|
||||
# One or more lines? unsure?
|
||||
if not has_unique_lines:
|
||||
logger.debug(f"check_unique_lines: UUID {uuid} didnt have anything new setting change_detected=False")
|
||||
changed_detected = False
|
||||
else:
|
||||
logger.debug(f"check_unique_lines: UUID {uuid} had unique content")
|
||||
|
||||
# Always record the new checksum
|
||||
update_obj["previous_md5"] = fetched_md5
|
||||
|
||||
# On the first run of a site, watch['previous_md5'] will be None, set it the current one.
|
||||
if not watch.get('previous_md5'):
|
||||
watch['previous_md5'] = fetched_md5
|
||||
|
||||
return changed_detected, update_obj, text_content_before_ignored_filter
|
||||
@@ -1,10 +0,0 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any
|
||||
|
||||
# So that we can queue some metadata in `item`
|
||||
# https://docs.python.org/3/library/queue.html#queue.PriorityQueue
|
||||
#
|
||||
@dataclass(order=True)
|
||||
class PrioritizedItem:
|
||||
priority: int
|
||||
item: Any=field(compare=False)
|
||||
@@ -1,190 +0,0 @@
|
||||
module.exports = async ({page, context}) => {
|
||||
|
||||
var {
|
||||
url,
|
||||
execute_js,
|
||||
user_agent,
|
||||
extra_wait_ms,
|
||||
req_headers,
|
||||
include_filters,
|
||||
xpath_element_js,
|
||||
screenshot_quality,
|
||||
proxy_username,
|
||||
proxy_password,
|
||||
disk_cache_dir,
|
||||
no_cache_list,
|
||||
block_url_list,
|
||||
} = context;
|
||||
|
||||
await page.setBypassCSP(true)
|
||||
await page.setExtraHTTPHeaders(req_headers);
|
||||
|
||||
if (user_agent) {
|
||||
await page.setUserAgent(user_agent);
|
||||
}
|
||||
// https://ourcodeworld.com/articles/read/1106/how-to-solve-puppeteer-timeouterror-navigation-timeout-of-30000-ms-exceeded
|
||||
|
||||
await page.setDefaultNavigationTimeout(0);
|
||||
|
||||
if (proxy_username) {
|
||||
// Setting Proxy-Authentication header is deprecated, and doing so can trigger header change errors from Puppeteer
|
||||
// https://github.com/puppeteer/puppeteer/issues/676 ?
|
||||
// https://help.brightdata.com/hc/en-us/articles/12632549957649-Proxy-Manager-How-to-Guides#h_01HAKWR4Q0AFS8RZTNYWRDFJC2
|
||||
// https://cri.dev/posts/2020-03-30-How-to-solve-Puppeteer-Chrome-Error-ERR_INVALID_ARGUMENT/
|
||||
await page.authenticate({
|
||||
username: proxy_username,
|
||||
password: proxy_password
|
||||
});
|
||||
}
|
||||
|
||||
await page.setViewport({
|
||||
width: 1024,
|
||||
height: 768,
|
||||
deviceScaleFactor: 1,
|
||||
});
|
||||
|
||||
await page.setRequestInterception(true);
|
||||
if (disk_cache_dir) {
|
||||
console.log(">>>>>>>>>>>>>>> LOCAL DISK CACHE ENABLED <<<<<<<<<<<<<<<<<<<<<");
|
||||
}
|
||||
const fs = require('fs');
|
||||
const crypto = require('crypto');
|
||||
|
||||
function file_is_expired(file_path) {
|
||||
if (!fs.existsSync(file_path)) {
|
||||
return true;
|
||||
}
|
||||
var stats = fs.statSync(file_path);
|
||||
const now_date = new Date();
|
||||
const expire_seconds = 300;
|
||||
if ((now_date / 1000) - (stats.mtime.getTime() / 1000) > expire_seconds) {
|
||||
console.log("CACHE EXPIRED: " + file_path);
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
|
||||
}
|
||||
|
||||
page.on('request', async (request) => {
|
||||
// General blocking of requests that waste traffic
|
||||
if (block_url_list.some(substring => request.url().toLowerCase().includes(substring))) return request.abort();
|
||||
|
||||
if (disk_cache_dir) {
|
||||
const url = request.url();
|
||||
const key = crypto.createHash('md5').update(url).digest("hex");
|
||||
const dir_path = disk_cache_dir + key.slice(0, 1) + '/' + key.slice(1, 2) + '/' + key.slice(2, 3) + '/';
|
||||
|
||||
// https://stackoverflow.com/questions/4482686/check-synchronously-if-file-directory-exists-in-node-js
|
||||
|
||||
if (fs.existsSync(dir_path + key)) {
|
||||
console.log("* CACHE HIT , using - " + dir_path + key + " - " + url);
|
||||
const cached_data = fs.readFileSync(dir_path + key);
|
||||
// @todo headers can come from dir_path+key+".meta" json file
|
||||
request.respond({
|
||||
status: 200,
|
||||
//contentType: 'text/html', //@todo
|
||||
body: cached_data
|
||||
});
|
||||
return;
|
||||
}
|
||||
}
|
||||
request.continue();
|
||||
});
|
||||
|
||||
|
||||
if (disk_cache_dir) {
|
||||
page.on('response', async (response) => {
|
||||
const url = response.url();
|
||||
// Basic filtering for sane responses
|
||||
if (response.request().method() != 'GET' || response.request().resourceType() == 'xhr' || response.request().resourceType() == 'document' || response.status() != 200) {
|
||||
console.log("Skipping (not useful) - Status:" + response.status() + " Method:" + response.request().method() + " ResourceType:" + response.request().resourceType() + " " + url);
|
||||
return;
|
||||
}
|
||||
if (no_cache_list.some(substring => url.toLowerCase().includes(substring))) {
|
||||
console.log("Skipping (no_cache_list) - " + url);
|
||||
return;
|
||||
}
|
||||
if (url.toLowerCase().includes('data:')) {
|
||||
console.log("Skipping (embedded-data) - " + url);
|
||||
return;
|
||||
}
|
||||
response.buffer().then(buffer => {
|
||||
if (buffer.length > 100) {
|
||||
console.log("Cache - Saving " + response.request().method() + " - " + url + " - " + response.request().resourceType());
|
||||
|
||||
const key = crypto.createHash('md5').update(url).digest("hex");
|
||||
const dir_path = disk_cache_dir + key.slice(0, 1) + '/' + key.slice(1, 2) + '/' + key.slice(2, 3) + '/';
|
||||
|
||||
if (!fs.existsSync(dir_path)) {
|
||||
fs.mkdirSync(dir_path, {recursive: true})
|
||||
}
|
||||
|
||||
if (fs.existsSync(dir_path + key)) {
|
||||
if (file_is_expired(dir_path + key)) {
|
||||
fs.writeFileSync(dir_path + key, buffer);
|
||||
}
|
||||
} else {
|
||||
fs.writeFileSync(dir_path + key, buffer);
|
||||
}
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
const r = await page.goto(url, {
|
||||
waitUntil: 'load'
|
||||
});
|
||||
|
||||
await page.waitForTimeout(1000);
|
||||
await page.waitForTimeout(extra_wait_ms);
|
||||
|
||||
if (execute_js) {
|
||||
await page.evaluate(execute_js);
|
||||
await page.waitForTimeout(200);
|
||||
}
|
||||
|
||||
var xpath_data;
|
||||
var instock_data;
|
||||
try {
|
||||
// Not sure the best way here, in the future this should be a new package added to npm then run in browserless
|
||||
// (Once the old playwright is removed)
|
||||
xpath_data = await page.evaluate((include_filters) => {%xpath_scrape_code%}, include_filters);
|
||||
instock_data = await page.evaluate(() => {%instock_scrape_code%});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// Protocol error (Page.captureScreenshot): Cannot take screenshot with 0 width can come from a proxy auth failure
|
||||
// Wrap it here (for now)
|
||||
|
||||
var b64s = false;
|
||||
try {
|
||||
b64s = await page.screenshot({encoding: "base64", fullPage: true, quality: screenshot_quality, type: 'jpeg'});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// May fail on very large pages with 'WARNING: tile memory limits exceeded, some content may not draw'
|
||||
if (!b64s) {
|
||||
// @todo after text extract, we can place some overlay text with red background to say 'croppped'
|
||||
console.error('ERROR: content-fetcher page was maybe too large for a screenshot, reverting to viewport only screenshot');
|
||||
try {
|
||||
b64s = await page.screenshot({encoding: "base64", quality: screenshot_quality, type: 'jpeg'});
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
}
|
||||
|
||||
var html = await page.content();
|
||||
return {
|
||||
data: {
|
||||
'content': html,
|
||||
'headers': r.headers(),
|
||||
'instock_data': instock_data,
|
||||
'screenshot': b64s,
|
||||
'status_code': r.status(),
|
||||
'xpath_data': xpath_data
|
||||
},
|
||||
type: 'application/json',
|
||||
};
|
||||
};
|
||||
@@ -1,132 +0,0 @@
|
||||
// Restock Detector
|
||||
// (c) Leigh Morresi dgtlmoon@gmail.com
|
||||
//
|
||||
// Assumes the product is in stock to begin with, unless the following appears above the fold ;
|
||||
// - outOfStockTexts appears above the fold (out of stock)
|
||||
// - negateOutOfStockRegex (really is in stock)
|
||||
|
||||
function isItemInStock() {
|
||||
// @todo Pass these in so the same list can be used in non-JS fetchers
|
||||
const outOfStockTexts = [
|
||||
' أخبرني عندما يتوفر',
|
||||
'0 in stock',
|
||||
'agotado',
|
||||
'article épuisé',
|
||||
'artikel zurzeit vergriffen',
|
||||
'as soon as stock is available',
|
||||
'ausverkauft', // sold out
|
||||
'available for back order',
|
||||
'back-order or out of stock',
|
||||
'backordered',
|
||||
'benachrichtigt mich', // notify me
|
||||
'brak na stanie',
|
||||
'brak w magazynie',
|
||||
'coming soon',
|
||||
'currently have any tickets for this',
|
||||
'currently unavailable',
|
||||
'dostępne wkrótce',
|
||||
'en rupture de stock',
|
||||
'ist derzeit nicht auf lager',
|
||||
'item is no longer available',
|
||||
'let me know when it\'s available',
|
||||
'message if back in stock',
|
||||
'nachricht bei',
|
||||
'nicht auf lager',
|
||||
'nicht lieferbar',
|
||||
'nicht zur verfügung',
|
||||
'niet beschikbaar',
|
||||
'niet leverbaar',
|
||||
'no disponible temporalmente',
|
||||
'no longer in stock',
|
||||
'no tickets available',
|
||||
'not available',
|
||||
'not currently available',
|
||||
'not in stock',
|
||||
'notify me when available',
|
||||
'notify when available',
|
||||
'não estamos a aceitar encomendas',
|
||||
'out of stock',
|
||||
'out-of-stock',
|
||||
'produkt niedostępny',
|
||||
'sold out',
|
||||
'sold-out',
|
||||
'temporarily out of stock',
|
||||
'temporarily unavailable',
|
||||
'tickets unavailable',
|
||||
'tijdelijk uitverkocht',
|
||||
'unavailable tickets',
|
||||
'we do not currently have an estimate of when this product will be back in stock.',
|
||||
'we don\'t know when or if this item will be back in stock.',
|
||||
'zur zeit nicht an lager',
|
||||
'品切れ',
|
||||
'已售完',
|
||||
'품절'
|
||||
];
|
||||
|
||||
const vh = Math.max(document.documentElement.clientHeight || 0, window.innerHeight || 0);
|
||||
function getElementBaseText(element) {
|
||||
// .textContent can include text from children which may give the wrong results
|
||||
// scan only immediate TEXT_NODEs, which will be a child of the element
|
||||
var text = "";
|
||||
for (var i = 0; i < element.childNodes.length; ++i)
|
||||
if (element.childNodes[i].nodeType === Node.TEXT_NODE)
|
||||
text += element.childNodes[i].textContent;
|
||||
return text.toLowerCase().trim();
|
||||
}
|
||||
|
||||
const negateOutOfStockRegex = new RegExp('([0-9] in stock|add to cart)', 'ig');
|
||||
|
||||
// The out-of-stock or in-stock-text is generally always above-the-fold
|
||||
// and often below-the-fold is a list of related products that may or may not contain trigger text
|
||||
// so it's good to filter to just the 'above the fold' elements
|
||||
// and it should be atleast 100px from the top to ignore items in the toolbar, sometimes menu items like "Coming soon" exist
|
||||
const elementsToScan = Array.from(document.getElementsByTagName('*')).filter(element => element.getBoundingClientRect().top + window.scrollY <= vh && element.getBoundingClientRect().top + window.scrollY >= 100);
|
||||
|
||||
var elementText = "";
|
||||
|
||||
// REGEXS THAT REALLY MEAN IT'S IN STOCK
|
||||
for (let i = elementsToScan.length - 1; i >= 0; i--) {
|
||||
const element = elementsToScan[i];
|
||||
elementText = "";
|
||||
if (element.tagName.toLowerCase() === "input") {
|
||||
elementText = element.value.toLowerCase();
|
||||
} else {
|
||||
elementText = getElementBaseText(element);
|
||||
}
|
||||
|
||||
if (elementText.length) {
|
||||
// try which ones could mean its in stock
|
||||
if (negateOutOfStockRegex.test(elementText)) {
|
||||
return 'Possibly in stock';
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// OTHER STUFF THAT COULD BE THAT IT'S OUT OF STOCK
|
||||
for (let i = elementsToScan.length - 1; i >= 0; i--) {
|
||||
const element = elementsToScan[i];
|
||||
if (element.offsetWidth > 0 || element.offsetHeight > 0 || element.getClientRects().length > 0) {
|
||||
elementText = "";
|
||||
if (element.tagName.toLowerCase() === "input") {
|
||||
elementText = element.value.toLowerCase();
|
||||
} else {
|
||||
elementText = getElementBaseText(element);
|
||||
}
|
||||
|
||||
if (elementText.length) {
|
||||
// and these mean its out of stock
|
||||
for (const outOfStockText of outOfStockTexts) {
|
||||
if (elementText.includes(outOfStockText)) {
|
||||
return outOfStockText; // item is out of stock
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return 'Possibly in stock'; // possibly in stock, cant decide otherwise.
|
||||
}
|
||||
|
||||
// returns the element text that makes it think it's out of stock
|
||||
return isItemInStock().trim()
|
||||
|
||||
@@ -1,235 +0,0 @@
|
||||
// Copyright (C) 2021 Leigh Morresi (dgtlmoon@gmail.com)
|
||||
// All rights reserved.
|
||||
|
||||
// @file Scrape the page looking for elements of concern (%ELEMENTS%)
|
||||
// http://matatk.agrip.org.uk/tests/position-and-width/
|
||||
// https://stackoverflow.com/questions/26813480/when-is-element-getboundingclientrect-guaranteed-to-be-updated-accurate
|
||||
//
|
||||
// Some pages like https://www.londonstockexchange.com/stock/NCCL/ncondezi-energy-limited/analysis
|
||||
// will automatically force a scroll somewhere, so include the position offset
|
||||
// Lets hope the position doesnt change while we iterate the bbox's, but this is better than nothing
|
||||
var scroll_y = 0;
|
||||
try {
|
||||
scroll_y = +document.documentElement.scrollTop || document.body.scrollTop
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
|
||||
|
||||
// Include the getXpath script directly, easier than fetching
|
||||
function getxpath(e) {
|
||||
var n = e;
|
||||
if (n && n.id) return '//*[@id="' + n.id + '"]';
|
||||
for (var o = []; n && Node.ELEMENT_NODE === n.nodeType;) {
|
||||
for (var i = 0, r = !1, d = n.previousSibling; d;) d.nodeType !== Node.DOCUMENT_TYPE_NODE && d.nodeName === n.nodeName && i++, d = d.previousSibling;
|
||||
for (d = n.nextSibling; d;) {
|
||||
if (d.nodeName === n.nodeName) {
|
||||
r = !0;
|
||||
break
|
||||
}
|
||||
d = d.nextSibling
|
||||
}
|
||||
o.push((n.prefix ? n.prefix + ":" : "") + n.localName + (i || r ? "[" + (i + 1) + "]" : "")), n = n.parentNode
|
||||
}
|
||||
return o.length ? "/" + o.reverse().join("/") : ""
|
||||
}
|
||||
|
||||
const findUpTag = (el) => {
|
||||
let r = el
|
||||
chained_css = [];
|
||||
depth = 0;
|
||||
|
||||
// Strategy 1: If it's an input, with name, and there's only one, prefer that
|
||||
if (el.name !== undefined && el.name.length) {
|
||||
var proposed = el.tagName + "[name=" + el.name + "]";
|
||||
var proposed_element = window.document.querySelectorAll(proposed);
|
||||
if (proposed_element.length) {
|
||||
if (proposed_element.length === 1) {
|
||||
return proposed;
|
||||
} else {
|
||||
// Some sites change ID but name= stays the same, we can hit it if we know the index
|
||||
// Find all the elements that match and work out the input[n]
|
||||
var n = Array.from(proposed_element).indexOf(el);
|
||||
// Return a Playwright selector for nthinput[name=zipcode]
|
||||
return proposed + " >> nth=" + n;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Strategy 2: Keep going up until we hit an ID tag, imagine it's like #list-widget div h4
|
||||
while (r.parentNode) {
|
||||
if (depth == 5) {
|
||||
break;
|
||||
}
|
||||
if ('' !== r.id) {
|
||||
chained_css.unshift("#" + CSS.escape(r.id));
|
||||
final_selector = chained_css.join(' > ');
|
||||
// Be sure theres only one, some sites have multiples of the same ID tag :-(
|
||||
if (window.document.querySelectorAll(final_selector).length == 1) {
|
||||
return final_selector;
|
||||
}
|
||||
return null;
|
||||
} else {
|
||||
chained_css.unshift(r.tagName.toLowerCase());
|
||||
}
|
||||
r = r.parentNode;
|
||||
depth += 1;
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
// @todo - if it's SVG or IMG, go into image diff mode
|
||||
// %ELEMENTS% replaced at injection time because different interfaces use it with different settings
|
||||
var elements = window.document.querySelectorAll("%ELEMENTS%");
|
||||
var size_pos = [];
|
||||
// after page fetch, inject this JS
|
||||
// build a map of all elements and their positions (maybe that only include text?)
|
||||
var bbox;
|
||||
for (var i = 0; i < elements.length; i++) {
|
||||
bbox = elements[i].getBoundingClientRect();
|
||||
|
||||
// Exclude items that are not interactable or visible
|
||||
if(elements[i].style.opacity === "0") {
|
||||
continue
|
||||
}
|
||||
if(elements[i].style.display === "none" || elements[i].style.pointerEvents === "none" ) {
|
||||
continue
|
||||
}
|
||||
|
||||
// Skip really small ones, and where width or height ==0
|
||||
if (bbox['width'] * bbox['height'] < 100) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// Don't include elements that are offset from canvas
|
||||
if (bbox['top']+scroll_y < 0 || bbox['left'] < 0) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo the getXpath kind of sucks, it doesnt know when there is for example just one ID sometimes
|
||||
// it should not traverse when we know we can anchor off just an ID one level up etc..
|
||||
// maybe, get current class or id, keep traversing up looking for only class or id until there is just one match
|
||||
|
||||
// 1st primitive - if it has class, try joining it all and select, if theres only one.. well thats us.
|
||||
xpath_result = false;
|
||||
|
||||
try {
|
||||
var d = findUpTag(elements[i]);
|
||||
if (d) {
|
||||
xpath_result = d;
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
// You could swap it and default to getXpath and then try the smarter one
|
||||
// default back to the less intelligent one
|
||||
if (!xpath_result) {
|
||||
try {
|
||||
// I've seen on FB and eBay that this doesnt work
|
||||
// ReferenceError: getXPath is not defined at eval (eval at evaluate (:152:29), <anonymous>:67:20) at UtilityScript.evaluate (<anonymous>:159:18) at UtilityScript.<anonymous> (<anonymous>:1:44)
|
||||
xpath_result = getxpath(elements[i]);
|
||||
} catch (e) {
|
||||
console.log(e);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
if (window.getComputedStyle(elements[i]).visibility === "hidden") {
|
||||
continue;
|
||||
}
|
||||
|
||||
// @todo Possible to ONLY list where it's clickable to save JSON xfer size
|
||||
size_pos.push({
|
||||
xpath: xpath_result,
|
||||
width: Math.round(bbox['width']),
|
||||
height: Math.round(bbox['height']),
|
||||
left: Math.floor(bbox['left']),
|
||||
top: Math.floor(bbox['top'])+scroll_y,
|
||||
tagName: (elements[i].tagName) ? elements[i].tagName.toLowerCase() : '',
|
||||
tagtype: (elements[i].tagName == 'INPUT' && elements[i].type) ? elements[i].type.toLowerCase() : '',
|
||||
isClickable: (elements[i].onclick) || window.getComputedStyle(elements[i]).cursor == "pointer"
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
// Inject the current one set in the include_filters, which may be a CSS rule
|
||||
// used for displaying the current one in VisualSelector, where its not one we generated.
|
||||
if (include_filters.length) {
|
||||
// Foreach filter, go and find it on the page and add it to the results so we can visualise it again
|
||||
for (const f of include_filters) {
|
||||
bbox = false;
|
||||
q = false;
|
||||
|
||||
if (!f.length) {
|
||||
console.log("xpath_element_scraper: Empty filter, skipping");
|
||||
continue;
|
||||
}
|
||||
|
||||
try {
|
||||
// is it xpath?
|
||||
if (f.startsWith('/') || f.startsWith('xpath')) {
|
||||
var qry_f = f.replace(/xpath(:|\d:)/, '')
|
||||
console.log("[xpath] Scanning for included filter " + qry_f)
|
||||
q = document.evaluate(qry_f, document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
|
||||
} else {
|
||||
console.log("[css] Scanning for included filter " + f)
|
||||
q = document.querySelector(f);
|
||||
}
|
||||
} catch (e) {
|
||||
// Maybe catch DOMException and alert?
|
||||
console.log("xpath_element_scraper: Exception selecting element from filter "+f);
|
||||
console.log(e);
|
||||
}
|
||||
|
||||
if (q) {
|
||||
// Try to resolve //something/text() back to its /something so we can atleast get the bounding box
|
||||
try {
|
||||
if (typeof q.nodeName == 'string' && q.nodeName === '#text') {
|
||||
q = q.parentElement
|
||||
}
|
||||
} catch (e) {
|
||||
console.log(e)
|
||||
console.log("xpath_element_scraper: #text resolver")
|
||||
}
|
||||
|
||||
// #1231 - IN the case XPath attribute filter is applied, we will have to traverse up and find the element.
|
||||
if (typeof q.getBoundingClientRect == 'function') {
|
||||
bbox = q.getBoundingClientRect();
|
||||
console.log("xpath_element_scraper: Got filter element, scroll from top was " + scroll_y)
|
||||
} else {
|
||||
try {
|
||||
// Try and see we can find its ownerElement
|
||||
bbox = q.ownerElement.getBoundingClientRect();
|
||||
console.log("xpath_element_scraper: Got filter by ownerElement element, scroll from top was " + scroll_y)
|
||||
} catch (e) {
|
||||
console.log(e)
|
||||
console.log("xpath_element_scraper: error looking up q.ownerElement")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if(!q) {
|
||||
console.log("xpath_element_scraper: filter element " + f + " was not found");
|
||||
}
|
||||
|
||||
if (bbox && bbox['width'] > 0 && bbox['height'] > 0) {
|
||||
size_pos.push({
|
||||
xpath: f,
|
||||
width: parseInt(bbox['width']),
|
||||
height: parseInt(bbox['height']),
|
||||
left: parseInt(bbox['left']),
|
||||
top: parseInt(bbox['top'])+scroll_y
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Sort the elements so we find the smallest one first, in other words, we find the smallest one matching in that area
|
||||
// so that we dont select the wrapping element by mistake and be unable to select what we want
|
||||
size_pos.sort((a, b) => (a.width*a.height > b.width*b.height) ? 1 : -1)
|
||||
|
||||
// Window.width required for proper scaling in the frontend
|
||||
return {'size_pos': size_pos, 'browser_width': window.innerWidth};
|
||||
@@ -9,8 +9,6 @@
|
||||
# exit when any command fails
|
||||
set -e
|
||||
|
||||
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
||||
|
||||
find tests/test_*py -type f|while read test_name
|
||||
do
|
||||
echo "TEST RUNNING $test_name"
|
||||
@@ -24,15 +22,3 @@ echo "RUNNING WITH BASE_URL SET"
|
||||
export BASE_URL="https://really-unique-domain.io"
|
||||
pytest tests/test_notification.py
|
||||
|
||||
|
||||
# Re-run with HIDE_REFERER set - could affect login
|
||||
export HIDE_REFERER=True
|
||||
pytest tests/test_access_control.py
|
||||
|
||||
# Re-run a few tests that will trigger brotli based storage
|
||||
export SNAPSHOT_BROTLI_COMPRESSION_THRESHOLD=5
|
||||
pytest tests/test_access_control.py
|
||||
pytest tests/test_notification.py
|
||||
pytest tests/test_backend.py
|
||||
pytest tests/test_rss.py
|
||||
pytest tests/test_unique_lines.py
|
||||
@@ -1,44 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
# run some tests and look if the 'custom-browser-search-string=1' connect string appeared in the correct containers
|
||||
|
||||
# enable debug
|
||||
set -x
|
||||
|
||||
# A extra browser is configured, but we never chose to use it, so it should NOT show in the logs
|
||||
docker run --rm -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/custom_browser_url/test_custom_browser_url.py::test_request_not_via_custom_browser_url'
|
||||
docker logs browserless-custom-url &>log.txt
|
||||
grep 'custom-browser-search-string=1' log.txt
|
||||
if [ $? -ne 1 ]
|
||||
then
|
||||
echo "Saw a request in 'browserless-custom-url' container with 'custom-browser-search-string=1' when I should not"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
docker logs browserless &>log.txt
|
||||
grep 'custom-browser-search-string=1' log.txt
|
||||
if [ $? -ne 1 ]
|
||||
then
|
||||
echo "Saw a request in 'browser' container with 'custom-browser-search-string=1' when I should not"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Special connect string should appear in the custom-url container, but not in the 'default' one
|
||||
docker run --rm -e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" --network changedet-network test-changedetectionio bash -c 'cd changedetectionio;pytest tests/custom_browser_url/test_custom_browser_url.py::test_request_via_custom_browser_url'
|
||||
docker logs browserless-custom-url &>log.txt
|
||||
grep 'custom-browser-search-string=1' log.txt
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see request in 'browserless-custom-url' container with 'custom-browser-search-string=1' when I should"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
docker logs browserless &>log.txt
|
||||
grep 'custom-browser-search-string=1' log.txt
|
||||
if [ $? -ne 1 ]
|
||||
then
|
||||
echo "Saw a request in 'browser' container with 'custom-browser-search-string=1' when I should not"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
|
||||
@@ -1,116 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
# exit when any command fails
|
||||
set -e
|
||||
# enable debug
|
||||
set -x
|
||||
|
||||
# Test proxy list handling, starting two squids on different ports
|
||||
# Each squid adds a different header to the response, which is the main thing we test for.
|
||||
docker run --network changedet-network -d --name squid-one --hostname squid-one --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf ubuntu/squid:4.13-21.10_edge
|
||||
docker run --network changedet-network -d --name squid-two --hostname squid-two --rm -v `pwd`/tests/proxy_list/squid.conf:/etc/squid/conf.d/debian.conf ubuntu/squid:4.13-21.10_edge
|
||||
|
||||
# SOCKS5 related - start simple Socks5 proxy server
|
||||
# SOCKSTEST=xyz should show in the logs of this service to confirm it fetched
|
||||
docker run --network changedet-network -d --hostname socks5proxy --name socks5proxy -p 1080:1080 -e PROXY_USER=proxy_user123 -e PROXY_PASSWORD=proxy_pass123 serjs/go-socks5-proxy
|
||||
docker run --network changedet-network -d --hostname socks5proxy-noauth -p 1081:1080 --name socks5proxy-noauth serjs/go-socks5-proxy
|
||||
|
||||
echo "---------------------------------- SOCKS5 -------------------"
|
||||
# SOCKS5 related - test from proxies.json
|
||||
docker run --network changedet-network \
|
||||
-v `pwd`/tests/proxy_socks5/proxies.json-example:/app/changedetectionio/test-datastore/proxies.json \
|
||||
--rm \
|
||||
-e "SOCKSTEST=proxiesjson" \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_socks5/test_socks5_proxy_sources.py'
|
||||
|
||||
# SOCKS5 related - by manually entering in UI
|
||||
docker run --network changedet-network \
|
||||
--rm \
|
||||
-e "SOCKSTEST=manual" \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_socks5/test_socks5_proxy.py'
|
||||
|
||||
# SOCKS5 related - test from proxies.json via playwright - NOTE- PLAYWRIGHT DOESNT SUPPORT AUTHENTICATING PROXY
|
||||
docker run --network changedet-network \
|
||||
-e "SOCKSTEST=manual-playwright" \
|
||||
-v `pwd`/tests/proxy_socks5/proxies.json-example-noauth:/app/changedetectionio/test-datastore/proxies.json \
|
||||
-e "PLAYWRIGHT_DRIVER_URL=ws://browserless:3000" \
|
||||
--rm \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_socks5/test_socks5_proxy_sources.py'
|
||||
|
||||
echo "socks5 server logs"
|
||||
docker logs socks5proxy
|
||||
echo "----------------------------------"
|
||||
|
||||
# Used for configuring a custom proxy URL via the UI
|
||||
docker run --network changedet-network -d \
|
||||
--name squid-custom \
|
||||
--hostname squid-custom \
|
||||
--rm \
|
||||
-v `pwd`/tests/proxy_list/squid-auth.conf:/etc/squid/conf.d/debian.conf \
|
||||
-v `pwd`/tests/proxy_list/squid-passwords.txt:/etc/squid3/passwords \
|
||||
ubuntu/squid:4.13-21.10_edge
|
||||
|
||||
|
||||
## 2nd test actually choose the preferred proxy from proxies.json
|
||||
docker run --network changedet-network \
|
||||
-v `pwd`/tests/proxy_list/proxies.json-example:/app/changedetectionio/test-datastore/proxies.json \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_list/test_multiple_proxy.py'
|
||||
|
||||
|
||||
## Should be a request in the default "first" squid
|
||||
docker logs squid-one 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy - squid one)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# And one in the 'second' squid (user selects this as preferred)
|
||||
docker logs squid-two 2>/dev/null|grep chosen.changedetection.io
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a request to chosen.changedetection.io in the squid logs (while checking preferred proxy - squid two)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
|
||||
# Test the UI configurable proxies
|
||||
docker run --network changedet-network \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_list/test_select_custom_proxy.py'
|
||||
|
||||
|
||||
# Should see a request for one.changedetection.io in there
|
||||
docker logs squid-custom 2>/dev/null|grep "TCP_TUNNEL.200.*changedetection.io"
|
||||
if [ $? -ne 0 ]
|
||||
then
|
||||
echo "Did not see a valid request to changedetection.io in the squid logs (while checking preferred proxy - squid two)"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Test "no-proxy" option
|
||||
docker run --network changedet-network \
|
||||
test-changedetectionio \
|
||||
bash -c 'cd changedetectionio && pytest tests/proxy_list/test_noproxy.py'
|
||||
|
||||
# We need to handle grep returning 1
|
||||
set +e
|
||||
# Check request was never seen in any container
|
||||
for c in $(echo "squid-one squid-two squid-custom"); do
|
||||
echo Checking $c
|
||||
docker logs $c &> $c.txt
|
||||
grep noproxy $c.txt
|
||||
if [ $? -ne 1 ]
|
||||
then
|
||||
echo "Saw request for noproxy in $c container"
|
||||
cat $c.txt
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
|
||||
|
||||
docker kill squid-one squid-two squid-custom
|
||||
{kind=link}
|
Before Width: | Height: | Size: 33 KiB |
{kind=link}
|
Before Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 31 KiB |
@@ -1,9 +0,0 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<browserconfig>
|
||||
<msapplication>
|
||||
<tile>
|
||||
<square150x150logo src="favicons/mstile-150x150.png"/>
|
||||
<TileColor>#da532c</TileColor>
|
||||
</tile>
|
||||
</msapplication>
|
||||
</browserconfig>
|
||||
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
@@ -1,35 +0,0 @@
|
||||
<?xml version="1.0" standalone="no"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20010904//EN"
|
||||
"http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd">
|
||||
<svg version="1.0" xmlns="http://www.w3.org/2000/svg"
|
||||
width="256.000000pt" height="256.000000pt" viewBox="0 0 256.000000 256.000000"
|
||||
preserveAspectRatio="xMidYMid meet">
|
||||
<metadata>
|
||||
Created by potrace 1.14, written by Peter Selinger 2001-2017
|
||||
</metadata>
|
||||
<g transform="translate(0.000000,256.000000) scale(0.100000,-0.100000)"
|
||||
fill="#000000" stroke="none">
|
||||
<path d="M0 1280 l0 -1280 1280 0 1280 0 0 1280 0 1280 -1280 0 -1280 0 0
|
||||
-1280z m1555 936 c387 -112 675 -426 741 -810 24 -138 15 -352 -20 -470 -106
|
||||
-353 -360 -606 -713 -712 -75 -22 -113 -27 -253 -31 -144 -5 -176 -2 -252 16
|
||||
-316 75 -564 271 -707 557 -67 136 -92 237 -98 401 -7 164 5 253 47 378 106
|
||||
315 349 556 665 659 114 37 180 45 350 41 125 -2 165 -7 240 -29z"/>
|
||||
<path d="M1091 2165 c-364 -82 -629 -328 -738 -682 -24 -80 -27 -103 -27 -258
|
||||
-1 -146 2 -182 21 -251 74 -271 259 -497 508 -621 477 -238 1061 -35 1294 450
|
||||
61 126 83 220 88 379 7 194 -15 307 -93 461 -126 251 -340 428 -614 507 -99
|
||||
29 -343 37 -439 15z m829 -473 c55 -54 100 -106 100 -116 0 -21 -184 -213
|
||||
-212 -222 -24 -7 -48 12 -48 38 0 11 26 47 58 80 l57 60 -151 -3 c-145 -4
|
||||
-152 -5 -190 -31 -22 -15 -78 -73 -124 -128 l-85 -99 -32 31 -32 31 30 38 c17
|
||||
22 70 79 117 128 66 67 97 92 127 100 22 6 106 11 188 11 81 0 147 3 147 8 0
|
||||
4 -25 31 -55 61 -55 55 -65 77 -43 99 25 25 50 10 148 -86z m-1002 -101 c46
|
||||
-24 141 -121 312 -321 203 -236 290 -330 322 -346 22 -11 60 -14 169 -12 l141
|
||||
3 -51 58 c-28 32 -51 64 -51 71 0 18 21 36 43 36 24 0 217 -193 217 -217 0
|
||||
-19 -185 -210 -212 -219 -24 -7 -48 12 -48 38 0 10 23 43 50 72 l50 53 -52 7
|
||||
c-29 3 -93 6 -142 6 -104 0 -152 12 -200 52 -19 15 -135 144 -258 286 -274
|
||||
316 -305 347 -354 361 -22 6 -94 11 -161 11 -67 0 -128 3 -137 6 -22 9 -21 61
|
||||
2 67 9 3 86 5 170 6 133 1 158 -2 190 -18z m227 -468 c23 -34 17 -43 -103
|
||||
-172 -119 -128 -131 -133 -343 -129 l-154 3 0 35 c0 34 1 35 50 42 28 3 96 7
|
||||
153 7 64 1 115 6 136 15 20 8 71 56 127 120 52 58 99 106 105 106 7 0 20 -12
|
||||
29 -27z"/>
|
||||
</g>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 2.0 KiB |
@@ -1,19 +0,0 @@
|
||||
{
|
||||
"name": "",
|
||||
"short_name": "",
|
||||
"icons": [
|
||||
{
|
||||
"src": "android-chrome-192x192.png",
|
||||
"sizes": "192x192",
|
||||
"type": "image/png"
|
||||
},
|
||||
{
|
||||
"src": "android-chrome-256x256.png",
|
||||
"sizes": "256x256",
|
||||
"type": "image/png"
|
||||
}
|
||||
],
|
||||
"theme_color": "#ffffff",
|
||||
"background_color": "#ffffff",
|
||||
"display": "standalone"
|
||||
}
|
||||
{kind=link}
|
Before Width: | Height: | Size: 6.2 KiB |
{kind=link}
@@ -1,4 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg width="15" height="16.363636" viewBox="0 0 15 16.363636" xmlns="http://www.w3.org/2000/svg" >
|
||||
<path d="m 14.318182,11.762045 v 1.1925 H 5.4102273 L 11.849318,7.1140909 C 12.234545,9.1561364 12.54,11.181818 14.318182,11.762045 Z m -6.7984093,4.601591 c 1.0759091,0 2.0256823,-0.955909 2.0256823,-2.045454 H 5.4545455 c 0,1.089545 0.9879545,2.045454 2.0652272,2.045454 z M 15,2.8622727 0.9177273,15.636136 0,14.627045 l 1.8443182,-1.6725 h -1.1625 v -1.1925 C 4.0070455,10.677273 2.1784091,4.5388636 5.3611364,2.6897727 5.8009091,2.4347727 6.0709091,1.9609091 6.0702273,1.4488636 v -0.00205 C 6.0702273,0.64772727 6.7104545,0 7.5,0 8.2895455,0 8.9297727,0.64772727 8.9297727,1.4468182 v 0.00205 C 8.9290909,1.9602319 9.199773,2.4354591 9.638864,2.6897773 10.364318,3.111141 10.827273,3.7568228 11.1525,4.5129591 L 14.085682,1.8531818 Z M 6.8181818,1.3636364 C 6.8181818,1.74 7.1236364,2.0454545 7.5,2.0454545 7.8763636,2.0454545 8.1818182,1.74 8.1818182,1.3636364 8.1818182,0.98795455 7.8763636,0.68181818 7.5,0.68181818 c -0.3763636,0 -0.6818182,0.30613637 -0.6818182,0.68181822 z" id="path2" style="fill:#f8321b;stroke-width:0.681818;fill-opacity:1"/>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 1.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
@@ -1,58 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
height="59.553207"
|
||||
viewBox="-0.36 95.21 25.082135 59.553208"
|
||||
width="249.99138"
|
||||
version="1.1"
|
||||
id="svg12"
|
||||
sodipodi:docname="brightdata.svg"
|
||||
inkscape:version="1.1.2 (0a00cf5339, 2022-02-04)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
>
|
||||
<defs
|
||||
id="defs16" />
|
||||
<sodipodi:namedview
|
||||
id="namedview14"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
fit-margin-top="0"
|
||||
fit-margin-left="0"
|
||||
fit-margin-right="0"
|
||||
fit-margin-bottom="0"
|
||||
inkscape:zoom="0.9464"
|
||||
inkscape:cx="22.189349"
|
||||
inkscape:cy="-90.870668"
|
||||
inkscape:window-width="1920"
|
||||
inkscape:window-height="1051"
|
||||
inkscape:window-x="1920"
|
||||
inkscape:window-y="0"
|
||||
inkscape:window-maximized="1"
|
||||
inkscape:current-layer="svg12" />
|
||||
<path
|
||||
d="m -34.416031,129.28 c -3.97,-2.43 -5.1,-6.09 -4.32,-10.35 0.81,-4.4 3.95,-6.75 8.04,-7.75 4.23,-1.04 8.44,-0.86 12.3,1.5 0.63,0.39 0.93,0.03 1.31,-0.29 1.5,-1.26 3.27,-1.72 5.189999,-1.83 0.79,-0.05 1.04,0.24 1.01,1.01 -0.05,1.31 -0.04,2.63 0,3.95 0.02,0.65 -0.19,0.93 -0.87,0.89 -0.889999,-0.04 -1.789999,0.03 -2.669999,-0.02 -0.82,-0.04 -1.08,0.1 -0.88,1.04 0.83,3.9 -0.06,7.37 -3.1,10.06 -2.76,2.44 -6.13,3.15 -9.72,3.04 -0.51,-0.02 -1.03,-0.02 -1.52,-0.13 -1.22,-0.25 -1.96,0.14 -2.19,1.41 -0.28,1.54 0.16,2.62 1.37,3.07 0.84,0.31 1.74,0.35 2.63,0.39 2.97,0.13 5.95,-0.18 8.91,0.21 2.93,0.39 5.69,1.16 6.85,4.25 1.269999,3.38 0.809999,6.62 -1.48,9.47 -2.73,3.39 -6.52,4.78 -10.66,5.33 -3.53,0.48 -7.04,0.27 -10.39,-1.11 -3.89,-1.6 -5.75,-4.95 -4.84,-8.72 0.51,-2.11 1.85,-3.58 3.69,-4.65 0.38,-0.22 0.93,-0.32 0.28,-0.96 -2.91,-2.83 -2.85,-6.16 0.1,-8.95 0.28,-0.26 0.6,-0.53 0.96,-0.86 z m 8.07,21.5 c 0.95,0.04 1.87,-0.13 2.78,-0.33 1.89,-0.42 3.51,-1.3 4.49,-3.06 1.82,-3.25 0.24,-6.2 -3.37,-6.58 -2.88,-0.3 -5.76,0.24 -8.63,-0.13 -0.53,-0.07 -0.75,0.34 -0.95,0.71 -1.16,2.24 -1.08,4.53 0,6.73 1.15,2.34 3.46,2.48 5.68,2.66 z m -5,-30.61 c -0.03,1.67 0.08,3.19 0.74,4.61 0.76,1.62 2.17,2.42 4.03,2.31 1.62,-0.1 2.9,-1.12 3.36,-2.84 0.66,-2.46 0.69,-4.95 0.01,-7.42 -0.49,-1.76 -1.7,-2.64 -3.56,-2.7 -2.08,-0.07 -3.37,0.7 -4.04,2.42 -0.47,1.21 -0.6,2.47 -0.54,3.62 z m 32.9399993,6.56 c 0,2.59 0.05,5.18 -0.02,7.77 -0.03,1.03 0.31,1.46 1.32,1.52 0.65,0.04 1.61,-0.09 1.82,0.57 0.26,0.81 0.11,1.76 0.06,2.65 -0.03,0.48 -0.81,0.39 -0.81,0.39 l -11.47,0.01 c 0,0 -0.95,-0.21 -0.88,-0.88 0.03,-0.29 0.04,-0.6 0,-0.89 -0.19,-1.24 0.21,-1.92 1.58,-1.9 0.99,0.01 1.28,-0.52 1.28,-1.53 -0.05,-8.75 -0.05,-17.49 0,-26.24 0.01,-1.15 -0.36,-1.62 -1.44,-1.67 -0.17,-0.01 -0.34,-0.04 -0.5,-0.07 -1.43,-0.22 -2.12,-1.57 -1.53,-2.91 0.15,-0.35 0.43,-0.36 0.72,-0.4 2.94,-0.41 5.88,-0.81 8.82000002,-1.23 0.81999998,-0.12 0.99999998,0.27 0.98999998,1.01 -0.02,3.35 0,6.71 0.02,10.06 0,0.35 -0.23,0.84 0.18,1.03 0.38,0.17 0.69,-0.25 0.99,-0.45 2.56,-1.74 5.33,-2.73 8.4900007,-2.56 3.51005,0.19 5.65005,1.95 6.35005,5.46 0.42,2.09 0.52,4.21 0.51,6.33 -0.02,3.86 0.05,7.73 -0.04,11.59 -0.02,1.12 0.37,1.5 1.39,1.6 0.61,0.05 1.55,-0.13 1.74,0.47 0.26,0.85 0.12,1.84 0.1,2.77 -0.01,0.41 -0.69,0.37 -0.69,0.37 l -11.4700504,0.01 c 0,0 -0.81,-0.29 -0.8,-0.85 0.01,-0.38 0.04,-0.77 -0.01,-1.15 -0.13,-1.01 0.32,-1.52 1.31,-1.56 1.0600004,-0.05 1.3800004,-0.55 1.3500004,-1.63 -0.14,-4.84 0.16,-9.68 -0.18,-14.51 -0.26,-3.66 -2.1100004,-4.95 -5.6700007,-3.99 -0.25,0.07 -0.49,0.15 -0.73,0.22 -2.57,0.8 -2.79,1.09 -2.79,3.71 0.01,2.3 0.01,4.59 0.01,6.88 z M -109.26603,122.56 c 0,-4.75 -0.02,-9.51 0.02,-14.26 0.01,-0.92 -0.17,-1.47 -1.19,-1.45 -0.16,0 -0.33,-0.07 -0.5,-0.1 -1.56,-0.27 -2.24,-1.47 -1.69,-2.92 0.14,-0.37 0.41,-0.38 0.7,-0.42 2.98,-0.41 5.97,-0.81 8.94,-1.24 0.85,-0.12 0.88,0.33 0.88,0.96 -0.01,3.01 -0.01,6.03 0,9.04 0,0.4 -0.18,0.96 0.27,1.16 0.36,0.16 0.66,-0.3 0.96,-0.52 4.729999,-3.51 12.459999,-2.61 14.889999,4.48 1.89,5.51 1.91,11.06 -0.96,16.28 -2.37,4.31 -6.19,6.49 -11.15,6.59 -3.379999,0.07 -6.679999,-0.3 -9.909999,-1.37 -0.93,-0.31 -1.3,-0.78 -1.28,-1.83 0.05,-4.81 0.02,-9.6 0.02,-14.4 z m 7.15,3.89 c 0,2.76 0.02,5.52 -0.01,8.28 -0.01,0.76 0.18,1.29 0.91,1.64 1.899999,0.9 4.299999,0.5 5.759999,-1.01 0.97,-1 1.56,-2.21 1.96,-3.52 1.03,-3.36 0.97,-6.78 0.61,-10.22 a 9.991,9.991 0 0 0 -0.93,-3.29 c -1.47,-3.06 -4.67,-3.85 -7.439999,-1.86 -0.6,0.43 -0.88,0.93 -0.87,1.7 0.04,2.76 0.01,5.52 0.01,8.28 z"
|
||||
fill="#4280f6"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 68.644019,137.2 c -1.62,1.46 -3.41,2.56 -5.62,2.96 -4.4,0.8 -8.7,-1.39 -10.49,-5.49 -2.31,-5.31 -2.3,-10.67 -0.1,-15.98 2.31,-5.58 8.29,-8.65 14.24,-7.46 1.71,0.34 1.9,0.18 1.9,-1.55 0,-0.68 -0.05,-1.36 0.01,-2.04 0.09,-1.02 -0.25,-1.54 -1.34,-1.43 -0.64,0.06 -1.26,-0.1 -1.88,-0.21 -1.32,-0.24 -1.6,-0.62 -1.37,-1.97 0.07,-0.41 0.25,-0.57 0.65,-0.62 2.63,-0.33 5.27,-0.66 7.9,-1.02 1.04,-0.14 1.17,0.37 1.17,1.25 -0.02,10.23 -0.02,20.45 -0.01,30.68 v 1.02 c 0.02,0.99 0.35,1.6 1.52,1.47 0.52,-0.06 1.35,-0.27 1.25,0.73 -0.08,0.8 0.58,1.93 -0.94,2.18 -1.29,0.22 -2.51,0.69 -3.86,0.65 -2.04,-0.06 -2.3,-0.23 -2.76,-2.19 -0.09,-0.3 0.06,-0.67 -0.27,-0.98 z m -0.07,-12.46 c 0,-2.8 -0.04,-5.6 0.02,-8.39 0.02,-0.9 -0.28,-1.47 -1.05,-1.81 -3.18,-1.4 -7.54,-0.8 -9.3,2.87 -0.83,1.74 -1.31,3.54 -1.49,5.46 -0.28,2.93 -0.38,5.83 0.61,8.65 0.73,2.09 1.81,3.9 4.11,4.67 2.49,0.83 4.55,-0.04 6.5,-1.48 0.54,-0.4 0.62,-0.95 0.61,-1.57 -0.02,-2.8 -0.01,-5.6 -0.01,-8.4 z m 28.79,2.53 c 0,3.24 0.04,5.83 -0.02,8.41 -0.02,1 0.19,1.49 1.309998,1.41 0.55,-0.04 1.460003,-0.46 1.520003,0.73 0.05,1.02 0.1,1.89 -1.330003,2.08 -1.289998,0.17 -2.559998,0.51 -3.889998,0.48 -1.88,-0.05 -2.15,-0.26 -2.42,-2.15 -0.04,-0.27 0.14,-0.65 -0.22,-0.79 -0.34,-0.13 -0.5,0.24 -0.72,0.42 -3.61,3 -8.15,3.4 -11.64,1.08 -1.61,-1.07 -2.49,-2.63 -2.67,-4.43 -0.51,-5.13 0.77,-7.91 6.3,-10.22 2.44,-1.02 5.07,-1.27 7.68,-1.49 0.77,-0.07 1.03,-0.28 1.02,-1.05 -0.03,-1.48 -0.05,-2.94 -0.64,-4.36 -0.59,-1.42 -1.67,-1.92 -3.08,-2.03 -3.04,-0.24 -5.88,0.5 -8.63,1.71 -0.51,0.23 -1.19,0.75 -1.48,-0.13 -0.26,-0.77 -1.35,-1.61 0.05,-2.47 3.27,-2 6.7,-3.44 10.61,-3.42 1.44,0.01 2.88,0.27 4.21,0.81 2.67,1.08 3.44,3.4 3.8,5.99 0.46,3.37 0.1,6.73 0.24,9.42 z m -5.09,2.9 c 0,-1.23 -0.01,-2.46 0,-3.69 0,-0.52 -0.06,-0.98 -0.75,-0.84 -1.45,0.3 -2.93,0.28 -4.37,0.69 -3.71,1.04 -5.46,4.48 -3.97,8.03 0.51,1.22 1.48,1.98 2.79,2.16 2.01,0.28 3.86,-0.29 5.6,-1.28 0.54,-0.31 0.73,-0.76 0.72,-1.37 -0.05,-1.23 -0.02,-2.47 -0.02,-3.7 z m 43.060001,-2.89 c 0,2.72 0.01,5.43 -0.01,8.15 0,0.66 0.02,1.21 0.91,1.12 0.54,-0.06 0.99,0.12 0.86,0.75 -0.15,0.71 0.56,1.7 -0.58,2.09 -1.55,0.52 -3.16,0.59 -4.77,0.4 -0.99,-0.12 -1.12,-1.01 -1.18,-1.73 -0.08,-1.15 -0.16,-1.45 -1.24,-0.54 -3.41,2.87 -8.05,3.17 -11.43,0.88 -1.75,-1.18 -2.49,-2.91 -2.7,-4.94 -0.64,-6.24 3.16,-8.74 7.83,-10.17 2.04,-0.62 4.14,-0.8 6.24,-0.99 0.81,-0.07 1,-0.36 0.98,-1.09 -0.04,-1.31 0.04,-2.62 -0.42,-3.89 -0.57,-1.57 -1.53,-2.34 -3.18,-2.45 -3.03,-0.21 -5.88,0.46 -8.64,1.66 -0.6,0.26 -1.25,0.81 -1.68,-0.2 -0.34,-0.8 -1.08,-1.61 0.16,-2.36 4.12,-2.5 8.44,-4.16 13.36,-3.07 3.21,0.71 4.89,2.91 5.26,6.34 0.18,1.69 0.22,3.37 0.22,5.07 0.01,1.66 0.01,3.32 0.01,4.97 z m -5.09,2.54 c 0,-1.27 -0.03,-2.54 0.01,-3.81 0.02,-0.74 -0.27,-1.02 -0.98,-0.92 -1.21,0.17 -2.43,0.28 -3.62,0.55 -3.72,0.83 -5.47,3.48 -4.82,7.21 0.29,1.66 1.57,2.94 3.21,3.16 2.02,0.27 3.85,-0.34 5.57,-1.34 0.49,-0.29 0.64,-0.73 0.63,-1.29 -0.02,-1.18 0,-2.37 0,-3.56 z"
|
||||
fill="#c8dbfb"
|
||||
id="path4" />
|
||||
<path
|
||||
d="m 26.314019,125.77 c 0,-2.89 -0.05,-5.77 0.02,-8.66 0.03,-1.04 -0.33,-1.39 -1.31,-1.24 a 0.7,0.7 0 0 1 -0.25,0 c -0.57,-0.18 -1.44,0.48 -1.68,-0.58 -0.35,-1.48 -0.02,-2.3 1.21,-2.7 1.3,-0.43 2.16,-1.26 2.76,-2.46 0.78,-1.56 1.44,-3.17 1.91,-4.84 0.18,-0.63 0.47,-0.86 1.15,-0.88 3.28,-0.09 3.27,-0.11 3.32,3.17 0.01,1.06 0.09,2.12 0.09,3.18 -0.01,0.67 0.27,0.89 0.91,0.88 1.61,-0.02 3.23,0.03 4.84,-0.02 0.77,-0.02 1.01,0.23 1.03,1.01 0.08,3.27 0.1,3.27 -3.09,3.27 -0.93,0 -1.87,0.03 -2.8,-0.01 -0.67,-0.02 -0.89,0.26 -0.88,0.91 0.04,5.43 0.04,10.86 0.12,16.29 0.02,1.7 0.75,2.26 2.46,2.1 1.1,-0.1 2.19,-0.26 3.23,-0.65 0.59,-0.22 0.89,-0.09 1.14,0.53 0.93,2.29 0.92,2.37 -1.32,3.52 -2.54,1.3 -5.22,1.99 -8.1,1.79 -2.27,-0.16 -3.68,-1.27 -4.35,-3.45 -0.3,-0.98 -0.41,-1.99 -0.41,-3.01 z m -97.67005,-8.99 c 0.57,-0.84 1.11,-1.74 1.76,-2.55 1.68,-2.09 3.68,-3.62 6.54,-3.66 1.08,-0.01 1.63,0.28 1.57,1.52 -0.1,2.08 -0.05,4.16 -0.02,6.24 0.01,0.74 -0.17,0.96 -0.96,0.76 -2.36,-0.59 -4.71,-0.42 -7.03,0.28 -0.8,0.24 -1.16,0.62 -1.15,1.52 0.05,4.5 0.04,9 0,13.5 -0.01,0.89 0.29,1.16 1.15,1.2 1.23,0.06 2.44,0.32 3.67,0.39 0.75,0.05 0.91,0.38 0.89,1.04 -0.06,2.86 0.29,2.28 -2.25,2.3 -4.2,0.04 -8.41,-0.02 -12.61,0.03 -0.91,0.01 -1.39,-0.18 -1.22,-1.18 0.02,-0.12 0,-0.25 0,-0.38 0.02,-2.1 -0.24,-1.88 1.77,-2.04 1.33,-0.11 1.6,-0.67 1.58,-1.9 -0.07,-5.35 -0.04,-10.7 -0.02,-16.05 0,-0.78 -0.17,-1.2 -1,-1.46 -2.21,-0.68 -2.7,-1.69 -2.22,-3.99 0.11,-0.52 0.45,-0.56 0.82,-0.62 2.22,-0.34 4.44,-0.7 6.67,-0.99 0.99,-0.13 1.82,0.7 1.84,1.76 0.03,1.4 0.03,2.8 0.04,4.2 -0.01,0.02 0.06,0.04 0.18,0.08 z m 25.24,6.59 c 0,3.69 0.04,7.38 -0.03,11.07 -0.02,1.04 0.31,1.48 1.32,1.49 0.29,0 0.59,0.12 0.88,0.13 0.93,0.01 1.18,0.47 1.16,1.37 -0.05,2.19 0,2.19 -2.24,2.19 -3.48,0 -6.96,-0.04 -10.44,0.03 -1.09,0.02 -1.47,-0.33 -1.3,-1.36 0.02,-0.12 0.02,-0.26 0,-0.38 -0.28,-1.39 0.39,-1.96 1.7,-1.9 1.36,0.06 1.76,-0.51 1.74,-1.88 -0.09,-5.17 -0.08,-10.35 0,-15.53 0.02,-1.22 -0.32,-1.87 -1.52,-2.17 -0.57,-0.14 -1.47,-0.11 -1.57,-0.85 -0.15,-1.04 -0.05,-2.11 0.01,-3.17 0.02,-0.34 0.44,-0.35 0.73,-0.39 2.81,-0.39 5.63,-0.77 8.44,-1.18 0.92,-0.14 1.15,0.2 1.14,1.09 -0.04,3.8 -0.02,7.62 -0.02,11.44 z"
|
||||
fill="#4280f6"
|
||||
id="path6" />
|
||||
<path
|
||||
d="m 101.44402,125.64 c 0,-3.18 -0.03,-6.37 0.02,-9.55 0.02,-0.94 -0.26,-1.36 -1.22,-1.22 -0.21,0.03 -0.430003,0.04 -0.630003,0 -0.51,-0.12 -1.35,0.39 -1.44,-0.55 -0.08,-0.85 -0.429998,-1.87 0.93,-2.24 2.080003,-0.57 2.720003,-2.39 3.350003,-4.17 0.31,-0.88 0.62,-1.76 0.87,-2.66 0.18,-0.64 0.52,-0.85 1.19,-0.84 2.46,0.05 2,-0.15 2.04,2.04 0.02,1.1 0.08,2.21 -0.02,3.31 -0.11,1.16 0.46,1.52 1.46,1.53 1.78,0.01 3.57,0.04 5.35,-0.01 0.82,-0.02 1.12,0.23 1.11,1.08 -0.05,2.86 0.19,2.49 -2.42,2.51 -1.53,0.01 -3.06,0.02 -4.59,-0.01 -0.65,-0.01 -0.9,0.22 -0.9,0.89 0.02,5.52 0,11.04 0.03,16.56 0,0.67 0.14,1.34 0.25,2.01 0.17,1.04 1.17,1.62 2.59,1.42 1.29,-0.19 2.57,-0.49 3.86,-0.69 0.43,-0.07 1.05,-0.47 1.19,0.4 0.12,0.75 1.05,1.61 -0.09,2.24 -2.09,1.16 -4.28,2.07 -6.71,2.16 -1.05,0.04 -2.13,0.2 -3.16,-0.14 -1.92,-0.65 -3.03,-2.28 -3.05,-4.51 -0.02,-3.19 -0.01,-6.37 -0.01,-9.56 z"
|
||||
fill="#c8dbfb"
|
||||
id="path8" />
|
||||
<path
|
||||
d="m -50.816031,95.21 c 0.19,2.160002 1.85,3.240002 2.82,4.740002 0.25,0.379998 0.48,0.109998 0.67,-0.16 0.21,-0.31 0.6,-1.21 1.15,-1.28 -0.35,1.38 -0.04,3.149998 0.16,4.449998 0.49,3.05 -1.22,5.64 -4.07,6.18 -3.38,0.65 -6.22,-2.21 -5.6,-5.62 0.23,-1.24 1.37,-2.5 0.77,-3.699998 -0.85,-1.7 0.54,-0.52 0.79,-0.22 1.04,1.199998 1.21,0.09 1.45,-0.55 0.24,-0.63 0.31,-1.31 0.47,-1.97 0.19,-0.770002 0.55,-1.400002 1.39,-1.870002 z"
|
||||
fill="#4280f6"
|
||||
id="path10" />
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
@@ -12,7 +12,7 @@
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
><defs
|
||||
xmlns:svg="http://www.w3.org/2000/svg"><defs
|
||||
id="defs11" /><sodipodi:namedview
|
||||
id="namedview9"
|
||||
pagecolor="#ffffff"
|
||||
|
||||
|
Before Width: | Height: | Size: 2.5 KiB After Width: | Height: | Size: 2.5 KiB |
{kind=link}
@@ -1,37 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Uploaded to: SVG Repo, www.svgrepo.com, Generator: SVG Repo Mixer Tools -->
|
||||
|
||||
<svg
|
||||
fill="#FFFFFF"
|
||||
height="7.5005589"
|
||||
width="11.248507"
|
||||
version="1.1"
|
||||
id="Layer_1"
|
||||
viewBox="0 0 7.1975545 4.7993639"
|
||||
xml:space="preserve"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
><defs
|
||||
id="defs19" />
|
||||
<g
|
||||
id="g14"
|
||||
transform="matrix(-0.01406065,0,0,0.01406065,7.1975543,-1.1990922)">
|
||||
<g
|
||||
id="g12">
|
||||
<g
|
||||
id="g10">
|
||||
<path
|
||||
d="M 468.373,85.28 H 45.333 C 21.227,85.28 0,105.76 0,129.014 V 383.2 c 0,23.147 21.227,43.413 45.333,43.413 h 422.933 c 23.68,0 43.627,-19.84 43.627,-43.413 V 129.014 C 512,105.334 492.053,85.28 468.373,85.28 Z m 0,320 H 45.333 c -12.373,0 -24,-10.773 -24,-22.08 V 129.014 c 0,-11.307 11.84,-22.4 24,-22.4 h 422.933 c 11.733,0 22.293,10.667 22.293,22.4 V 383.2 h 0.107 c 10e-4,11.734 -10.453,22.08 -22.293,22.08 z"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 440.853,153.974 c -3.307,-4.907 -9.92,-6.187 -14.827,-2.987 L 256,264.48 85.973,151.094 c -4.907,-3.2 -11.52,-1.707 -14.72,3.2 -3.093,4.8 -1.813,11.307 2.88,14.507 l 176,117.333 c 3.627,2.347 8.213,2.347 11.84,0 l 176,-117.333 c 4.8,-3.201 6.187,-9.921 2.88,-14.827 z"
|
||||
id="path4" />
|
||||
<path
|
||||
d="m 143.573,257.654 c -0.107,0.107 -0.32,0.213 -0.427,0.32 L 68.48,311.307 c -4.907,3.307 -6.187,9.92 -2.88,14.827 3.307,4.907 9.92,6.187 14.827,2.88 0.107,-0.107 0.32,-0.213 0.427,-0.32 l 74.667,-53.333 c 4.907,-3.307 6.187,-9.92 2.88,-14.827 -3.308,-4.907 -9.921,-6.187 -14.828,-2.88 z"
|
||||
id="path6" />
|
||||
<path
|
||||
d="m 443.947,311.627 c -0.107,-0.107 -0.32,-0.213 -0.427,-0.32 l -74.667,-53.333 c -4.693,-3.52 -11.413,-2.56 -14.933,2.133 -3.52,4.693 -2.56,11.413 2.133,14.933 0.107,0.107 0.32,0.213 0.427,0.32 l 74.667,53.333 c 4.693,3.52 11.413,2.56 14.933,-2.133 3.52,-4.693 2.56,-11.413 -2.133,-14.933 z"
|
||||
id="path8" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 1.9 KiB |
BIN
changedetectionio/static/images/favicon.ico
Normal file
|
After Width: | Height: | Size: 31 KiB |
{kind=link}
@@ -1,3 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
<svg width="61.649mm" height="61.649mm" version="1.1" viewBox="0 0 61.649 61.649" xml:space="preserve" xmlns="http://www.w3.org/2000/svg"><g transform="translate(66.269 -15.463)" fill="#3056d3"><g transform="matrix(1.423 0 0 1.423 101.16 69.23)" fill="#3056d3"><g transform="matrix(.8229 0 0 .8229 -23.378 -2.3935)" fill="#3056d3"><path d="m-88.248-43.007a26.323 26.323 0 0 0-26.323 26.323 26.323 26.323 0 0 0 26.323 26.323 26.323 26.323 0 0 0 26.323-26.323 26.323 26.323 0 0 0-26.323-26.323zm0 2.8417a23.482 23.482 0 0 1 23.482 23.482 23.482 23.482 0 0 1-23.482 23.482 23.482 23.482 0 0 1-23.482-23.482 23.482 23.482 0 0 1 23.482-23.482z"/><g transform="matrix(.26458 0 0 .26458 -115.65 -44.085)"><path d="m33.02 64.43c0.35-0.05 2.04-0.13 2.04-0.13h25.53s3.17 0.32 3.67 0.53c2.5 1.05 3.98 1.89 6.04 3.57 0.72 0.58 4.12 4.01 4.12 4.01l51.67 57.39s1.61 1.65 1.97 1.94c1.2 0.97 2.48 1.96 3.98 2.32 0.5 0.12 2.72 0.21 2.72 0.21h27.32l-8.83-9.04s-1.31-1.65-1.44-1.94c-0.45-0.93-0.59-2.59-0.13-3.51 0.35-0.69 1.46-1.87 2.23-1.98 1.03-0.14 2.12-0.39 3.02 0.14 0.33 0.2 1.64 1.32 1.64 1.32l17.49 17.49s1.35 1.09 1.6 1.6c0.17 0.34 0.29 0.82 0.15 1.18-0.17 0.42-1.42 1.63-1.42 1.63l-0.94 0.98-15.69 16.37s-1.44 1.4-1.79 1.67c-0.76 0.6-1.99 0.89-2.96 0.9-1.03 0-2.62-1.11-3.26-1.91-0.6-0.76-1.1-2.22-0.77-3.13 0.16-0.45 1.28-1.85 1.28-1.85l11.36-11.3-29.47-0.02-1.68 0.09s-4.16-0.66-5.26-1.03c-1.63-0.56-3.44-1.82-4.75-2.93-0.39-0.33-1.8-1.92-1.8-1.92l-51.7-59.28s-2-2.06-2.43-2.43c-1.37-1.17-2-1.62-3.76-2.34-0.44-0.18-3.45-0.55-3.45-0.55l-24.13-0.22s-2.23-0.15-2.61-0.22c-1.08-0.21-2.16-1.07-2.81-1.83-0.79-0.92-0.59-3.06 0.06-4.09 0.57-0.89 2.14-1.52 3.19-1.66z"/><path d="m86.1 109.7-17.13 19.65s-2 2.06-2.43 2.43c-1.37 1.17-2 1.62-3.76 2.34-0.44 0.18-3.45 0.55-3.45 0.55l-24.13 0.22s-2.23 0.15-2.61 0.22c-1.08 0.21-2.16 1.07-2.81 1.83-0.79 0.92-0.59 3.06 0.06 4.09 0.57 0.89 2.14 1.52 3.19 1.66 0.35 0.05 2.04 0.13 2.04 0.13h25.53s3.17-0.32 3.67-0.53c2.5-1.05 3.98-1.89 6.04-3.57 0.72-0.58 4.12-4.01 4.12-4.01l17.38-19.3z"/><path d="m177.81 67.6c-0.17-0.42-1.42-1.63-1.42-1.63l-0.94-0.98-15.69-16.37s-1.44-1.4-1.79-1.67c-0.76-0.6-1.99-0.89-2.96-0.9-1.03 0-2.62 1.11-3.26 1.91-0.6 0.76-1.1 2.22-0.77 3.13 0.16 0.45 1.28 1.85 1.28 1.85l11.36 11.3-29.47 0.02-1.68-0.09s-4.16 0.66-5.26 1.03c-1.63 0.56-3.44 1.82-4.75 2.93-0.39 0.33-1.8 1.92-1.8 1.92l-18.91 21.69 5.98 5.98 18.38-20.41s1.61-1.65 1.97-1.94c1.2-0.97 2.48-1.96 3.98-2.32 0.5-0.12 2.72-0.21 2.72-0.21h27.32l-8.83 9.04s-1.31 1.65-1.44 1.94c-0.45 0.93-0.59 2.59-0.13 3.51 0.35 0.69 1.46 1.87 2.23 1.98 1.03 0.14 2.12 0.39 3.02-0.14 0.33-0.2 1.64-1.32 1.64-1.32l17.49-17.49s1.35-1.09 1.6-1.6c0.17-0.34 0.29-0.82 0.15-1.18z"/></g></g></g></g></svg>
|
||||
|
Before Width: | Height: | Size: 2.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB After Width: | Height: | Size: 43 KiB |
{kind=link}
@@ -1,51 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!-- Created with Inkscape (http://www.inkscape.org/) -->
|
||||
|
||||
<svg
|
||||
width="20.108334mm"
|
||||
height="21.43125mm"
|
||||
viewBox="0 0 20.108334 21.43125"
|
||||
version="1.1"
|
||||
id="svg5"
|
||||
xmlns:xlink="http://www.w3.org/1999/xlink"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
>
|
||||
<defs
|
||||
id="defs2" />
|
||||
<g
|
||||
id="layer1"
|
||||
transform="translate(-141.05873,-76.816635)">
|
||||
<image
|
||||
width="20.108334"
|
||||
height="21.43125"
|
||||
preserveAspectRatio="none"
|
||||
style="image-rendering:optimizeQuality"
|
||||
xlink:href="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEwAAABRCAYAAAB430BuAAAABHNCSVQICAgIfAhkiAAABLxJREFU
|
||||
eJztnN2Z2jgUhl8Z7petIGwF0WMXsFBBoIKwFWS2gmQryKSCJRXsTAUDBTDRVBCmgkAB9tkLexh+
|
||||
bIONLGwP7xU2RjafpaOjoyNBCxHNQAJEfG5sl+3ZLrAWeAyST5/sF91mFH3bRbZbsAq4ClaQq2B7
|
||||
iKYnmg9Z318F20ICRnj8pMOd6E3HscNVsATxmQD/oeghPCnDLO26q2AkYin+TQ7XREyyrn3zgu2J
|
||||
BSEjZTBZ179pwQ7EEv7KaoovvFnBUsV6ZHrsd+0WTHhKPV1SLGivYEsA1KEtEs2grFitRjQ65VxP
|
||||
fH5JgEjAKsvXupKwFfYxaYJeSeHcWqVSCuwD7/HQQD8lRHLWDStBWG3slbAElkTc5/lTZdkIJhpN
|
||||
h6/UUZDyzAgZK8PKVoEKErE8HlD0bBVcI2ZqwdBWYbFgAT+g1UZwrBbcvRyIpofHJ1Sh1rQCZt1k
|
||||
lN5msQAm8CoYoFF8KVHOsFtQ5aayExBUhpnopJl6J/3/FREGWCrxmaH40/4z1oyQ320Yf5dDozXC
|
||||
P4QMCRkCY4S5w/tbMTtd4L2Ngo6wJmSQ4hfdScAU+OjgGazgOXEl8oJyof3Z6Spx0iTzgnLKsMoK
|
||||
w9SRuoR3rHniVVMXwRpDXQR7d+kHOJV6CFZB0khVOBGsTcE6VzWsNVGQizfJptU+N4LlD3AbVfsu
|
||||
XsOahhvB8nrB08IrtcGNYNIct+EYl2+S6mr0D8kLUMrV6BfFRTzOGs4Ey8p1aNrUnssaliaMO/vV
|
||||
sfNi3AmW5j54DgUTO/dyJ1hab9iwHhLcNskP23ZMND0kewFBXek6vZvHg/hMiUPSN00z+OBasFig
|
||||
y8wSRfnZ0adSBz+sUVwFK4jbJhnPP06To1ETczpcCnavHhltHd82LU0AXDbJMGXBU8PSBAA8Jxk0
|
||||
wnNaqlGSJuAyg+dsXIV38iZqXU3iWsmodhetSNlDQgJGriZxbWVSe1hS/gQ+S/C6j4QEfES21vxU
|
||||
icXsoC4vC5mqJvbybyXgduucG/YWaYmmj+IdHvpoxFdt8ltRP5h3iZjRqfBh60C4t1rNY7rxAU95
|
||||
aYnhEp+/u8pgxGfeRCfyJIR5SkLfFOHYXMMzu63PEDF9WQnSo8MUmhduyUWYEzGyvnRmU3683ugG
|
||||
GAG/2bqJU4RnFDNCpsfWb5chswUnwb5Xg+hxiyo9w7MGJoSVpmYulam+A8scS+5nPYtf+s9mpZw7
|
||||
J1nayDnCVuu4Ck+E6DqIBYDHHR1+is/n8kVUhfBExMBFMzm4taafkXcWL9BSfBG/nNN8sutYcE3S
|
||||
d7XI3o6lSpIe/xcAIX/svzDxMVu22BAyLNKL2q9hwrdLiZWwXbP6B99GDLaGSpoOD6JPn4yxK1i8
|
||||
B0StY1zKsCJiQNxzQ0HRbAm2BsZN2TBDGVaE5USzIVjsNix2VrzWHmUwB6J5fD32uyKCzQ7OxG5D
|
||||
vzZuQ0E2osXjRlBMjvWe5WtYPE4b2BynXQJlMEToTUegmEiwM1mzQ1nBvqvH5ov1wlZHcA+AZHdc
|
||||
xQW7vNuQS9kBtzKs1IIRMM7b0q/YvGTzto4qbFutdV5FnLtLk2x3JVWUfXKTbIu9Opc2J6Osj19S
|
||||
HLfJKO64r6rg/wFBX3+2ZapW8wAAAABJRU5ErkJggg==
|
||||
"
|
||||
id="image832"
|
||||
x="141.05873"
|
||||
y="76.816635" />
|
||||
</g>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 2.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.7 KiB |
{kind=link}
@@ -3,6 +3,7 @@
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
version="1.1"
|
||||
id="Capa_1"
|
||||
|
||||
|
Before Width: | Height: | Size: 2.8 KiB After Width: | Height: | Size: 2.9 KiB |
{kind=link}
@@ -1,9 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" width="75.320129mm" height="92.604164mm" viewBox="0 0 75.320129 92.604164">
|
||||
<g transform="translate(53.548057 -183.975276) scale(1.4843)">
|
||||
<path fill="#ff2116" d="M-29.632812 123.94727c-3.551967 0-6.44336 2.89347-6.44336 6.44531v49.49804c0 3.55185 2.891393 6.44532 6.44336 6.44532H8.2167969c3.5519661 0 6.4433591-2.89335 6.4433591-6.44532v-40.70117s.101353-1.19181-.416015-2.35156c-.484969-1.08711-1.275391-1.84375-1.275391-1.84375a1.0584391 1.0584391 0 0 0-.0059-.008l-9.3906254-9.21094a1.0584391 1.0584391 0 0 0-.015625-.0156s-.8017392-.76344-1.9902344-1.27344c-1.39939552-.6005-2.8417968-.53711-2.8417968-.53711l.021484-.002z" color="#000" font-family="sans-serif" overflow="visible" paint-order="markers fill stroke" style="line-height:normal;font-variant-ligatures:normal;font-variant-position:normal;font-variant-caps:normal;font-variant-numeric:normal;font-variant-alternates:normal;font-feature-settings:normal;text-indent:0;text-align:start;text-decoration-line:none;text-decoration-style:solid;text-decoration-color:#000000;text-transform:none;text-orientation:mixed;white-space:normal;shape-padding:0;isolation:auto;mix-blend-mode:normal;solid-color:#000000;solid-opacity:1"/>
|
||||
<path fill="#f5f5f5" d="M-29.632812 126.06445h28.3789058a1.0584391 1.0584391 0 0 0 .021484 0s1.13480448.011 1.96484378.36719c.79889772.34282 1.36536982.86176 1.36914062.86524.0000125.00001.00391.004.00391.004l9.3671868 9.18945s.564354.59582.837891 1.20899c.220779.49491.234375 1.40039.234375 1.40039a1.0584391 1.0584391 0 0 0-.002.0449v40.74609c0 2.41592-1.910258 4.32813-4.3261717 4.32813H-29.632812c-2.415914 0-4.326172-1.91209-4.326172-4.32813v-49.49804c0-2.41603 1.910258-4.32813 4.326172-4.32813z" color="#000" font-family="sans-serif" overflow="visible" paint-order="markers fill stroke" style="line-height:normal;font-variant-ligatures:normal;font-variant-position:normal;font-variant-caps:normal;font-variant-numeric:normal;font-variant-alternates:normal;font-feature-settings:normal;text-indent:0;text-align:start;text-decoration-line:none;text-decoration-style:solid;text-decoration-color:#000000;text-transform:none;text-orientation:mixed;white-space:normal;shape-padding:0;isolation:auto;mix-blend-mode:normal;solid-color:#000000;solid-opacity:1"/>
|
||||
<path fill="#ff2116" d="M-23.40766 161.09299c-1.45669-1.45669.11934-3.45839 4.39648-5.58397l2.69124-1.33743 1.04845-2.29399c.57665-1.26169 1.43729-3.32036 1.91254-4.5748l.8641-2.28082-.59546-1.68793c-.73217-2.07547-.99326-5.19438-.52872-6.31588.62923-1.51909 2.69029-1.36323 3.50626.26515.63727 1.27176.57212 3.57488-.18329 6.47946l-.6193 2.38125.5455.92604c.30003.50932 1.1764 1.71867 1.9475 2.68743l1.44924 1.80272 1.8033728-.23533c5.72900399-.74758 7.6912472.523 7.6912472 2.34476 0 2.29921-4.4984914 2.48899-8.2760865-.16423-.8499666-.59698-1.4336605-1.19001-1.4336605-1.19001s-2.3665326.48178-3.531704.79583c-1.202707.32417-1.80274.52719-3.564509 1.12186 0 0-.61814.89767-1.02094 1.55026-1.49858 2.4279-3.24833 4.43998-4.49793 5.1723-1.3991.81993-2.86584.87582-3.60433.13733zm2.28605-.81668c.81883-.50607 2.47616-2.46625 3.62341-4.28553l.46449-.73658-2.11497 1.06339c-3.26655 1.64239-4.76093 3.19033-3.98386 4.12664.43653.52598.95874.48237 2.01093-.16792zm21.21809-5.95578c.80089-.56097.68463-1.69142-.22082-2.1472-.70466-.35471-1.2726074-.42759-3.1031574-.40057-1.1249.0767-2.9337647.3034-3.2403347.37237 0 0 .993716.68678 1.434896.93922.58731.33544 2.0145161.95811 3.0565161 1.27706 1.02785.31461 1.6224.28144 2.0729-.0409zm-8.53152-3.54594c-.4847-.50952-1.30889-1.57296-1.83152-2.3632-.68353-.89643-1.02629-1.52887-1.02629-1.52887s-.4996 1.60694-.90948 2.57394l-1.27876 3.16076-.37075.71695s1.971043-.64627 2.97389-.90822c1.0621668-.27744 3.21787-.70134 3.21787-.70134zm-2.74938-11.02573c.12363-1.0375.1761-2.07346-.15724-2.59587-.9246-1.01077-2.04057-.16787-1.85154 2.23517.0636.8084.26443 2.19033.53292 3.04209l.48817 1.54863.34358-1.16638c.18897-.64151.47882-2.02015.64411-3.06364z"/>
|
||||
<path fill="#2c2c2c" d="M-20.930423 167.83862h2.364986q1.133514 0 1.840213.2169.706698.20991 1.189489.9446.482795.72769.482795 1.75625 0 .94459-.391832 1.6233-.391833.67871-1.056548.97958-.65772.30087-2.02913.30087h-.818651v3.72941h-1.581322zm1.581322 1.22447v3.33058h.783664q1.049552 0 1.44838-.39184.405826-.39183.405826-1.27345 0-.65772-.265887-1.06355-.265884-.41282-.587747-.50378-.314866-.098-1.000572-.098zm5.50664-1.22447h2.148082q1.560333 0 2.4909318.55276.9375993.55276 1.4133973 1.6443.482791 1.09153.482791 2.42096 0 1.3994-.4338151 2.49793-.4268149 1.09153-1.3154348 1.76324-.8816233.67172-2.5189212.67172h-2.267031zm1.581326 1.26645v7.018h.657715q1.378411 0 2.001144-.9516.6227329-.95858.6227329-2.5539 0-3.5125-2.6238769-3.5125zm6.4722254-1.26645h5.30372941v1.26645H-4.2075842v2.85478h2.9807225v1.26646h-2.9807225v4.16322h-1.5813254z" font-family="Franklin Gothic Medium Cond" letter-spacing="0" style="line-height:125%;-inkscape-font-specification:'Franklin Gothic Medium Cond'" word-spacing="4.26000023"/>
|
||||
</g>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 5.0 KiB |
{kind=link}
@@ -1,121 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
version="1.1"
|
||||
id="Capa_1"
|
||||
x="0px"
|
||||
y="0px"
|
||||
viewBox="0 0 15 14.998326"
|
||||
xml:space="preserve"
|
||||
width="15"
|
||||
height="14.998326"
|
||||
sodipodi:docname="play.svg"
|
||||
inkscape:version="1.1.1 (1:1.1+202109281949+c3084ef5ed)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"><sodipodi:namedview
|
||||
id="namedview21"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
inkscape:zoom="45.47174"
|
||||
inkscape:cx="7.4991632"
|
||||
inkscape:cy="7.4991632"
|
||||
inkscape:window-width="1554"
|
||||
inkscape:window-height="896"
|
||||
inkscape:window-x="3048"
|
||||
inkscape:window-y="227"
|
||||
inkscape:window-maximized="0"
|
||||
inkscape:current-layer="Capa_1" /><metadata
|
||||
id="metadata39"><rdf:RDF><cc:Work
|
||||
rdf:about=""><dc:format>image/svg+xml</dc:format><dc:type
|
||||
rdf:resource="http://purl.org/dc/dcmitype/StillImage" /></cc:Work></rdf:RDF></metadata><defs
|
||||
id="defs37" />
|
||||
<path
|
||||
id="path2"
|
||||
style="fill:#1b98f8;fill-opacity:1;stroke-width:0.0292893"
|
||||
d="M 7.4980469,0 C 4.5496028,-0.04093755 1.7047721,1.8547661 0.58789062,4.5800781 -0.57819305,7.2574082 0.02636631,10.583252 2.0703125,12.671875 4.0368718,14.788335 7.2754393,15.560096 9.9882812,14.572266 12.800219,13.617028 14.874915,10.855516 14.986328,7.8847656 15.172991,4.9968456 13.497714,2.109448 10.910156,0.8203125 9.858961,0.28011352 8.6796569,-0.00179908 7.4980469,0 Z"
|
||||
sodipodi:nodetypes="ccccccc" />
|
||||
<g
|
||||
id="g4"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g6"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g8"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g10"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g12"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g14"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g16"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g18"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g20"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g22"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g24"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g26"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g28"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g30"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<g
|
||||
id="g32"
|
||||
transform="translate(-0.01903604,0.02221043)">
|
||||
</g>
|
||||
<path
|
||||
sodipodi:type="star"
|
||||
style="fill:#ffffff;fill-opacity:1;stroke-width:37.7953;paint-order:stroke fill markers"
|
||||
id="path1203"
|
||||
inkscape:flatsided="false"
|
||||
sodipodi:sides="3"
|
||||
sodipodi:cx="7.2964563"
|
||||
sodipodi:cy="7.3240671"
|
||||
sodipodi:r1="3.805218"
|
||||
sodipodi:r2="1.9026089"
|
||||
sodipodi:arg1="-0.0017436774"
|
||||
sodipodi:arg2="1.0454539"
|
||||
inkscape:rounded="0"
|
||||
inkscape:randomized="0"
|
||||
d="M 11.101669,7.317432 8.2506324,8.9701135 5.3995964,10.622795 5.3938504,7.3273846 5.3881041,4.0319742 8.2448863,5.6747033 Z"
|
||||
inkscape:transform-center-x="-0.94843001"
|
||||
inkscape:transform-center-y="0.0033175346" /></svg>
|
||||
|
Before Width: | Height: | Size: 3.4 KiB |
{kind=link}
@@ -1,2 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<svg width="83.39" height="89.648" enable-background="new 0 0 122.406 122.881" version="1.1" viewBox="0 0 83.39 89.648" xml:space="preserve" xmlns="http://www.w3.org/2000/svg"><g transform="translate(5e-4 -33.234)"><path d="m44.239 42.946-39.111 39.896 34.908 34.91 39.09-39.876-1.149-34.931zm-0.91791 42.273c0.979-0.979 1.507-1.99 1.577-3.027 0.077-1.043-0.248-2.424-0.967-4.135-0.725-1.717-1.348-3.346-1.87-4.885s-0.814-3.014-0.897-4.432c-0.07-1.42 0.134-2.768 0.624-4.045 0.477-1.279 1.348-2.545 2.607-3.804 2.099-2.099 4.535-3.123 7.314-3.065 2.773 0.063 5.457 1.158 8.04 3.294l2.881 3.034c1.946 2.607 2.799 5.33 2.557 8.166-0.235 2.83-1.532 5.426-3.893 7.785l-6.296-6.297c1.291-1.291 2.035-2.531 2.238-3.727 0.191-1.197-0.165-2.252-1.081-3.168-0.821-0.82-1.717-1.195-2.69-1.139-0.967 0.064-1.908 0.547-2.817 1.457-0.922 0.922-1.393 1.914-1.412 2.977s0.306 2.416 0.973 4.064c0.661 1.652 1.24 3.25 1.736 4.801 0.496 1.553 0.782 3.035 0.858 4.445 0.076 1.426-0.127 2.787-0.591 4.104-0.477 1.316-1.336 2.596-2.588 3.848-2.125 2.125-4.522 3.186-7.212 3.18s-5.311-1.063-7.855-3.16l-3.747 3.746-2.964-2.965 3.766-3.764c-2.423-2.996-3.568-5.998-3.447-9.02 0.127-3.014 1.476-5.813 4.045-8.383l6.278 6.277c-1.412 1.412-2.175 2.799-2.277 4.16-0.108 1.367 0.414 2.627 1.571 3.783 0.839 0.84 1.755 1.26 2.741 1.242 0.985-0.017 1.92-0.47 2.798-1.347zm21.127-46.435h17.457c-0.0269 2.2368 0.69936 16.025 0.69936 16.025l0.785 23.858c0.019 0.609-0.221 1.164-0.619 1.564l5e-3 4e-3 -41.236 42.022c-0.82213 0.8378-2.175 0.83-3.004 0l-37.913-37.91c-0.83-0.83-0.83-2.176 0-3.006l41.236-42.021c0.39287-0.42671 1.502-0.53568 1.502-0.53568zm18.011 11.59c-59.392-29.687-29.696-14.843 0 0z"/></g></svg>
|
||||
|
Before Width: | Height: | Size: 1.7 KiB |
{kind=link}
@@ -1,20 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
width="18"
|
||||
height="19.92"
|
||||
viewBox="0 0 18 19.92"
|
||||
version="1.1"
|
||||
id="svg6"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
>
|
||||
<defs
|
||||
id="defs10" />
|
||||
<path
|
||||
d="M -3,-2 H 21 V 22 H -3 Z"
|
||||
fill="none"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z"
|
||||
id="path4"
|
||||
style="fill:#ffffff;fill-opacity:1" />
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 854 B |
{kind=link}
@@ -1,5 +1,46 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg width="18" height="19.92" viewBox="0 0 18 19.92" xmlns="http://www.w3.org/2000/svg" >
|
||||
<path d="M -3,-2 H 21 V 22 H -3 Z" fill="none" id="path2"/>
|
||||
<path d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z" id="path4" style="fill:#0078e7;fill-opacity:1"/>
|
||||
<svg
|
||||
width="18"
|
||||
height="19.92"
|
||||
viewBox="0 0 18 19.92"
|
||||
version="1.1"
|
||||
id="svg6"
|
||||
sodipodi:docname="spread.svg"
|
||||
inkscape:version="1.1.1 (1:1.1+202109281949+c3084ef5ed)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs10" />
|
||||
<sodipodi:namedview
|
||||
id="namedview8"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
fit-margin-top="0"
|
||||
fit-margin-left="0"
|
||||
fit-margin-right="0"
|
||||
fit-margin-bottom="0"
|
||||
inkscape:zoom="28.416667"
|
||||
inkscape:cx="9.0087975"
|
||||
inkscape:cy="9.9941348"
|
||||
inkscape:window-width="1920"
|
||||
inkscape:window-height="1056"
|
||||
inkscape:window-x="1920"
|
||||
inkscape:window-y="0"
|
||||
inkscape:window-maximized="1"
|
||||
inkscape:current-layer="svg6" />
|
||||
<path
|
||||
d="M -3,-2 H 21 V 22 H -3 Z"
|
||||
fill="none"
|
||||
id="path2" />
|
||||
<path
|
||||
d="m 15,14.08 c -0.76,0 -1.44,0.3 -1.96,0.77 L 5.91,10.7 C 5.96,10.47 6,10.24 6,10 6,9.76 5.96,9.53 5.91,9.3 L 12.96,5.19 C 13.5,5.69 14.21,6 15,6 16.66,6 18,4.66 18,3 18,1.34 16.66,0 15,0 c -1.66,0 -3,1.34 -3,3 0,0.24 0.04,0.47 0.09,0.7 L 5.04,7.81 C 4.5,7.31 3.79,7 3,7 1.34,7 0,8.34 0,10 c 0,1.66 1.34,3 3,3 0.79,0 1.5,-0.31 2.04,-0.81 l 7.12,4.16 c -0.05,0.21 -0.08,0.43 -0.08,0.65 0,1.61 1.31,2.92 2.92,2.92 1.61,0 2.92,-1.31 2.92,-2.92 0,-1.61 -1.31,-2.92 -2.92,-2.92 z"
|
||||
id="path4"
|
||||
style="fill:#0078e7;fill-opacity:1" />
|
||||
</svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 749 B After Width: | Height: | Size: 1.7 KiB |
{kind=link}
@@ -1,44 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
aria-hidden="true"
|
||||
viewBox="0 0 19.966091 17.999964"
|
||||
class="css-1oqmxjn"
|
||||
version="1.1"
|
||||
id="svg4"
|
||||
sodipodi:docname="steps.svg"
|
||||
width="19.966091"
|
||||
height="17.999964"
|
||||
inkscape:version="1.1.2 (0a00cf5339, 2022-02-04)"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:svg="http://www.w3.org/2000/svg">
|
||||
<defs
|
||||
id="defs8" />
|
||||
<sodipodi:namedview
|
||||
id="namedview6"
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1.0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:pageopacity="0.0"
|
||||
inkscape:pagecheckerboard="0"
|
||||
showgrid="false"
|
||||
fit-margin-top="0"
|
||||
fit-margin-left="0"
|
||||
fit-margin-right="0"
|
||||
fit-margin-bottom="0"
|
||||
inkscape:zoom="8.6354167"
|
||||
inkscape:cx="-1.3896261"
|
||||
inkscape:cy="6.1375151"
|
||||
inkscape:window-width="1280"
|
||||
inkscape:window-height="667"
|
||||
inkscape:window-x="2419"
|
||||
inkscape:window-y="250"
|
||||
inkscape:window-maximized="0"
|
||||
inkscape:current-layer="svg4" />
|
||||
<path
|
||||
d="m 16.95807,12.000003 c -0.7076,0.0019 -1.3917,0.2538 -1.9316,0.7113 -0.5398,0.4575 -0.9005,1.091 -1.0184,1.7887 H 5.60804 c -0.80847,0.0297 -1.60693,-0.1865 -2.29,-0.62 -0.26632,-0.1847 -0.48375,-0.4315 -0.63356,-0.7189 -0.14982,-0.2874 -0.22753,-0.607 -0.22644,-0.9311 -0.02843,-0.3931 0.03646,-0.7873 0.1894,-1.1505 0.15293,-0.3632 0.38957,-0.6851 0.6906,-0.9395 0.66628,-0.4559004 1.4637,-0.6807004 2.27,-0.6400004 h 8.35003 c 0.8515,-0.0223 1.6727,-0.3206 2.34,-0.85 0.3971,-0.3622 0.7076,-0.8091 0.9084,-1.3077 0.2008,-0.49857 0.2868,-1.03596 0.2516,-1.57229 0.0113,-0.47161 -0.0887,-0.93924 -0.292,-1.36493 -0.2033,-0.4257 -0.5041,-0.79745 -0.878,-1.08507 -0.7801,-0.55815 -1.7212,-0.84609 -2.68,-0.82 H 5.95804 c -0.12537,-0.7417 -0.5248,-1.40924 -1.11913,-1.87032996 -0.59434,-0.46108 -1.3402,-0.68207 -2.08979,-0.61917 -0.74958,0.06291 -1.44818,0.40512 -1.95736,0.95881 C 0.28259,1.5230126 0,2.2477926 0,3.0000126 c 0,0.75222 0.28259,1.47699 0.79176,2.03068 0.50918,0.55369 1.20778,0.8959 1.95736,0.95881 0.74959,0.0629 1.49545,-0.15808 2.08979,-0.61917 0.59433,-0.46109 0.99376,-1.12863 1.11913,-1.87032 h 7.70003 c 0.7353,-0.03061 1.4599,0.18397 2.06,0.61 0.2548,0.19335 0.4595,0.445 0.597,0.73385 0.1375,0.28884 0.2036,0.60644 0.193,0.92615 0.0316,0.38842 -0.0247,0.77898 -0.165,1.14258 -0.1402,0.36361 -0.3607,0.69091 -0.645,0.95741 -0.5713,0.4398 -1.2799,0.663 -2,0.63 H 5.69804 c -1.03259,-0.0462 -2.05065,0.2568 -2.89,0.86 -0.43755,0.3361 -0.78838,0.7720004 -1.02322,1.2712004 -0.23484,0.4993 -0.34688,1.0474 -0.32678,1.5988 -0.00726,0.484 0.10591,0.9622 0.32934,1.3916 0.22344,0.4295 0.55012,0.7966 0.95066,1.0684 0.85039,0.5592 1.85274,0.8421 2.87,0.81 h 8.40003 c 0.0954,0.5643 0.3502,1.0896 0.7343,1.5138 0.3842,0.4242 0.8817,0.7297 1.4338,0.8803 0.5521,0.1507 1.1358,0.1403 1.6822,-0.0299 0.5464,-0.1702 1.0328,-0.4932 1.4016,-0.9308 0.3688,-0.4376 0.6048,-0.9716 0.6801,-1.5389 0.0752,-0.5673 -0.0134,-1.1444 -0.2554,-1.663 -0.242,-0.5186 -0.6273,-0.9572 -1.1104,-1.264 -0.4831,-0.3068 -1.0439,-0.469 -1.6162,-0.4675 z m 0,5 c -0.3956,0 -0.7823,-0.1173 -1.1112,-0.3371 -0.3289,-0.2197 -0.5852,-0.5321 -0.7366,-0.8975 -0.1514,-0.3655 -0.191,-0.7676 -0.1138,-1.1556 0.0772,-0.3879 0.2677,-0.7443 0.5474,-1.024 0.2797,-0.2797 0.636,-0.4702 1.024,-0.5474 0.388,-0.0771 0.7901,-0.0375 1.1555,0.1138 0.3655,0.1514 0.6778,0.4078 0.8976,0.7367 0.2198,0.3289 0.3371,0.7155 0.3371,1.1111 0,0.5304 -0.2107,1.0391 -0.5858,1.4142 -0.3751,0.3751 -0.8838,0.5858 -1.4142,0.5858 z"
|
||||
id="path2"
|
||||
style="fill:#777777;fill-opacity:1" />
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 3.7 KiB |
@@ -1,469 +0,0 @@
|
||||
$(document).ready(function () {
|
||||
|
||||
// duplicate
|
||||
var csrftoken = $('input[name=csrf_token]').val();
|
||||
$.ajaxSetup({
|
||||
beforeSend: function (xhr, settings) {
|
||||
if (!/^(GET|HEAD|OPTIONS|TRACE)$/i.test(settings.type) && !this.crossDomain) {
|
||||
xhr.setRequestHeader("X-CSRFToken", csrftoken)
|
||||
}
|
||||
}
|
||||
})
|
||||
var browsersteps_session_id;
|
||||
var browserless_seconds_remaining = 0;
|
||||
var apply_buttons_disabled = false;
|
||||
var include_text_elements = $("#include_text_elements");
|
||||
var xpath_data = false;
|
||||
var current_selected_i;
|
||||
var state_clicked = false;
|
||||
var c;
|
||||
|
||||
// redline highlight context
|
||||
var ctx;
|
||||
var last_click_xy = {'x': -1, 'y': -1}
|
||||
|
||||
$(window).resize(function () {
|
||||
set_scale();
|
||||
});
|
||||
// Should always be disabled
|
||||
$('#browser_steps >li:first-child select').val('Goto site').attr('disabled', 'disabled');
|
||||
|
||||
$('#browsersteps-click-start').click(function () {
|
||||
$("#browsersteps-click-start").fadeOut();
|
||||
$("#browsersteps-selector-wrapper .spinner").fadeIn();
|
||||
start();
|
||||
});
|
||||
|
||||
$('a#browsersteps-tab').click(function () {
|
||||
reset();
|
||||
});
|
||||
|
||||
window.addEventListener('hashchange', function () {
|
||||
if (window.location.hash == '#browser-steps') {
|
||||
reset();
|
||||
}
|
||||
});
|
||||
|
||||
function reset() {
|
||||
xpath_data = false;
|
||||
$('#browsersteps-img').removeAttr('src');
|
||||
$("#browsersteps-click-start").show();
|
||||
$("#browsersteps-selector-wrapper .spinner").hide();
|
||||
browserless_seconds_remaining = 0;
|
||||
browsersteps_session_id = false;
|
||||
apply_buttons_disabled = false;
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
set_first_gotosite_disabled();
|
||||
}
|
||||
|
||||
function set_first_gotosite_disabled() {
|
||||
$('#browser_steps >li:first-child select').val('Goto site').attr('disabled', 'disabled');
|
||||
$('#browser_steps >li:first-child').css('opacity', '0.5');
|
||||
}
|
||||
|
||||
// Show seconds remaining until playwright/browserless needs to restart the session
|
||||
// (See comment at the top of changedetectionio/blueprint/browser_steps/__init__.py )
|
||||
setInterval(() => {
|
||||
if (browserless_seconds_remaining >= 1) {
|
||||
document.getElementById('browserless-seconds-remaining').innerText = browserless_seconds_remaining + " seconds remaining in session";
|
||||
browserless_seconds_remaining -= 1;
|
||||
}
|
||||
}, "1000")
|
||||
|
||||
|
||||
function set_scale() {
|
||||
|
||||
// some things to check if the scaling doesnt work
|
||||
// - that the widths/sizes really are about the actual screen size cat elements.json |grep -o width......|sort|uniq
|
||||
selector_image = $("img#browsersteps-img")[0];
|
||||
selector_image_rect = selector_image.getBoundingClientRect();
|
||||
|
||||
// make the canvas and input steps the same size as the image
|
||||
$('#browsersteps-selector-canvas').attr('height', selector_image_rect.height).attr('width', selector_image_rect.width);
|
||||
//$('#browsersteps-selector-wrapper').attr('width', selector_image_rect.width);
|
||||
$('#browser-steps-ui').attr('width', selector_image_rect.width);
|
||||
|
||||
x_scale = selector_image_rect.width / xpath_data['browser_width'];
|
||||
y_scale = selector_image_rect.height / selector_image.naturalHeight;
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.lineWidth = 3;
|
||||
console.log("scaling set x: " + x_scale + " by y:" + y_scale);
|
||||
}
|
||||
|
||||
// bootstrap it, this will trigger everything else
|
||||
$('#browsersteps-img').bind('load', function () {
|
||||
$('body').addClass('full-width');
|
||||
console.log("Loaded background...");
|
||||
|
||||
document.getElementById("browsersteps-selector-canvas");
|
||||
c = document.getElementById("browsersteps-selector-canvas");
|
||||
// redline highlight context
|
||||
ctx = c.getContext("2d");
|
||||
// @todo is click better?
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
// Undo disable_browsersteps_ui
|
||||
$("#browser-steps-ui").css('opacity', '1.0');
|
||||
|
||||
// init
|
||||
set_scale();
|
||||
|
||||
// @todo click ? some better library?
|
||||
$('#browsersteps-selector-canvas').bind('click', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
});
|
||||
|
||||
// When the mouse moves we know which element it should be above
|
||||
// mousedown will link that to the UI (select the right action, highlight etc)
|
||||
$('#browsersteps-selector-canvas').bind('mousedown', function (e) {
|
||||
// https://developer.mozilla.org/en-US/docs/Web/API/MouseEvent
|
||||
e.preventDefault()
|
||||
last_click_xy = {'x': parseInt((1 / x_scale) * e.offsetX), 'y': parseInt((1 / y_scale) * e.offsetY)}
|
||||
process_selected(current_selected_i);
|
||||
current_selected_i = false;
|
||||
|
||||
// if process selected returned false, then best we can do is offer a x,y click :(
|
||||
if (!found_something) {
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
$('select', first_available).val('Click X,Y').change();
|
||||
$('input[type=text]', first_available).first().val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
draw_circle_on_canvas(e.offsetX, e.offsetY);
|
||||
}
|
||||
});
|
||||
|
||||
// Debounce and find the current most 'interesting' element we are hovering above
|
||||
$('#browsersteps-selector-canvas').bind('mousemove', function (e) {
|
||||
if (!xpath_data) {
|
||||
return;
|
||||
}
|
||||
|
||||
// checkbox if find elements is enabled
|
||||
ctx.clearRect(0, 0, c.width, c.height);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.1)';
|
||||
ctx.strokeStyle = 'rgba(255,0,0, 0.9)';
|
||||
|
||||
// Add in offset
|
||||
if ((typeof e.offsetX === "undefined" || typeof e.offsetY === "undefined") || (e.offsetX === 0 && e.offsetY === 0)) {
|
||||
var targetOffset = $(e.target).offset();
|
||||
e.offsetX = e.pageX - targetOffset.left;
|
||||
e.offsetY = e.pageY - targetOffset.top;
|
||||
}
|
||||
current_selected_i = false;
|
||||
// Reverse order - the most specific one should be deeper/"laster"
|
||||
// Basically, find the most 'deepest'
|
||||
var possible_elements = [];
|
||||
xpath_data['size_pos'].forEach(function (item, index) {
|
||||
// If we are in a bounding-box
|
||||
if (e.offsetY > item.top * y_scale && e.offsetY < item.top * y_scale + item.height * y_scale
|
||||
&&
|
||||
e.offsetX > item.left * y_scale && e.offsetX < item.left * y_scale + item.width * y_scale
|
||||
|
||||
) {
|
||||
// There could be many elements here, record them all and then we'll find out which is the most 'useful'
|
||||
// (input, textarea, button, A etc)
|
||||
if (item.width < xpath_data['browser_width']) {
|
||||
possible_elements.push(item);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
// Find the best one
|
||||
if (possible_elements.length) {
|
||||
possible_elements.forEach(function (item, index) {
|
||||
if (["a", "input", "textarea", "button"].includes(item['tagName'])) {
|
||||
current_selected_i = item;
|
||||
}
|
||||
});
|
||||
|
||||
if (!current_selected_i) {
|
||||
current_selected_i = possible_elements[0];
|
||||
}
|
||||
|
||||
sel = xpath_data['size_pos'][current_selected_i];
|
||||
ctx.strokeRect(current_selected_i.left * x_scale, current_selected_i.top * y_scale, current_selected_i.width * x_scale, current_selected_i.height * y_scale);
|
||||
ctx.fillRect(current_selected_i.left * x_scale, current_selected_i.top * y_scale, current_selected_i.width * x_scale, current_selected_i.height * y_scale);
|
||||
}
|
||||
|
||||
|
||||
}.debounce(10));
|
||||
});
|
||||
|
||||
// $("#browser-steps-fieldlist").bind('mouseover', function(e) {
|
||||
// console.log(e.xpath_data_index);
|
||||
// });
|
||||
|
||||
|
||||
// callback for clicking on an xpath on the canvas
|
||||
function process_selected(selected_in_xpath_list) {
|
||||
found_something = false;
|
||||
var first_available = $("ul#browser_steps li.empty").first();
|
||||
|
||||
|
||||
if (selected_in_xpath_list !== false) {
|
||||
// Nothing focused, so fill in a new one
|
||||
// if inpt type button or <button>
|
||||
// from the top, find the next not used one and use it
|
||||
var x = selected_in_xpath_list;
|
||||
console.log(x);
|
||||
if (x && first_available.length) {
|
||||
// @todo will it let you click shit that has a layer ontop? probably not.
|
||||
if (x['tagtype'] === 'text' || x['tagtype'] === 'number' || x['tagtype'] === 'email' || x['tagName'] === 'textarea' || x['tagtype'] === 'password' || x['tagtype'] === 'search') {
|
||||
$('select', first_available).val('Enter text in field').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
$('input[placeholder="Value"]', first_available).addClass('ok').click().focus();
|
||||
found_something = true;
|
||||
} else {
|
||||
// There's no good way (that I know) to find if this
|
||||
// see https://stackoverflow.com/questions/446892/how-to-find-event-listeners-on-a-dom-node-in-javascript-or-in-debugging
|
||||
// https://codepen.io/azaslavsky/pen/DEJVWv
|
||||
|
||||
// So we dont know if its really a clickable element or not :-(
|
||||
// Assume it is - then we dont fill the pages with unreliable "Click X,Y" selections
|
||||
// If you switch to "Click X,y" after an element here is setup, it will give the last co-ords anyway
|
||||
//if (x['isClickable'] || x['tagName'].startsWith('h') || x['tagName'] === 'a' || x['tagName'] === 'button' || x['tagtype'] === 'submit' || x['tagtype'] === 'checkbox' || x['tagtype'] === 'radio' || x['tagtype'] === 'li') {
|
||||
$('select', first_available).val('Click element').change();
|
||||
$('input[type=text]', first_available).first().val(x['xpath']);
|
||||
found_something = true;
|
||||
//}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function draw_circle_on_canvas(x, y) {
|
||||
ctx.beginPath();
|
||||
ctx.arc(x, y, 8, 0, 2 * Math.PI, false);
|
||||
ctx.fillStyle = 'rgba(255,0,0, 0.6)';
|
||||
ctx.fill();
|
||||
}
|
||||
|
||||
function start() {
|
||||
console.log("Starting browser-steps UI");
|
||||
browsersteps_session_id = false;
|
||||
// @todo This setting of the first one should be done at the datalayer but wtforms doesnt wanna play nice
|
||||
$('#browser_steps >li:first-child').removeClass('empty');
|
||||
set_first_gotosite_disabled();
|
||||
$('#browser-steps-ui .loader .spinner').show();
|
||||
$('.clear,.remove', $('#browser_steps >li:first-child')).hide();
|
||||
$.ajax({
|
||||
type: "GET",
|
||||
url: browser_steps_start_url,
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
$("#loading-status-text").fadeIn();
|
||||
browsersteps_session_id = data.browsersteps_session_id;
|
||||
// This should trigger 'Goto site'
|
||||
console.log("Got startup response, requesting Goto-Site (first) step fake click");
|
||||
$('#browser_steps >li:first-child .apply').click();
|
||||
browserless_seconds_remaining = 500;
|
||||
set_first_gotosite_disabled();
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
alert('There was an error communicating with the server.');
|
||||
});
|
||||
|
||||
}
|
||||
|
||||
function disable_browsersteps_ui() {
|
||||
set_first_gotosite_disabled();
|
||||
$("#browser-steps-ui").css('opacity', '0.3');
|
||||
$('#browsersteps-selector-canvas').off("mousemove mousedown click");
|
||||
}
|
||||
|
||||
|
||||
////////////////////////// STEPS UI ////////////////////
|
||||
$('ul#browser_steps [type="text"]').keydown(function (e) {
|
||||
if (e.keyCode === 13) {
|
||||
// hitting [enter] in a browser-step input should trigger the 'Apply'
|
||||
e.preventDefault();
|
||||
$(".apply", $(this).closest('li')).click();
|
||||
return false;
|
||||
}
|
||||
});
|
||||
|
||||
// Look up which step was selected, and enable or disable the related extra fields
|
||||
// So that people using it dont' get confused
|
||||
$('ul#browser_steps select').on("change", function () {
|
||||
var config = browser_steps_config[$(this).val()].split(' ');
|
||||
var elem_selector = $('tr:nth-child(2) input', $(this).closest('tbody'));
|
||||
var elem_value = $('tr:nth-child(3) input', $(this).closest('tbody'));
|
||||
|
||||
if (config[0] == 0) {
|
||||
$(elem_selector).fadeOut();
|
||||
} else {
|
||||
$(elem_selector).fadeIn();
|
||||
}
|
||||
if (config[1] == 0) {
|
||||
$(elem_value).fadeOut();
|
||||
} else {
|
||||
$(elem_value).fadeIn();
|
||||
}
|
||||
|
||||
if ($(this).val() === 'Click X,Y' && last_click_xy['x'] > 0 && $(elem_value).val().length === 0) {
|
||||
// @todo handle scale
|
||||
$(elem_value).val(last_click_xy['x'] + ',' + last_click_xy['y']);
|
||||
}
|
||||
}).change();
|
||||
|
||||
function set_greyed_state() {
|
||||
$('ul#browser_steps select').not('option:selected[value="Choose one"]').closest('li').removeClass('empty');
|
||||
$('ul#browser_steps select option:selected[value="Choose one"]').closest('li').addClass('empty');
|
||||
}
|
||||
|
||||
// Add the extra buttons to the steps
|
||||
$('ul#browser_steps li').each(function (i) {
|
||||
var s = '<div class="control">' + '<a data-step-index=' + i + ' class="pure-button button-secondary button-green button-xsmall apply" >Apply</a> ';
|
||||
if (i > 0) {
|
||||
// The first step never gets these (Goto-site)
|
||||
s += `<a data-step-index="${i}" class="pure-button button-secondary button-xsmall clear" >Clear</a> ` +
|
||||
`<a data-step-index="${i}" class="pure-button button-secondary button-red button-xsmall remove" >Remove</a>`;
|
||||
|
||||
// if a screenshot is available
|
||||
if (browser_steps_available_screenshots.includes(i.toString())) {
|
||||
var d = (browser_steps_last_error_step === i+1) ? 'before' : 'after';
|
||||
s += ` <a data-step-index="${i}" class="pure-button button-secondary button-xsmall show-screenshot" title="Show screenshot from last run" data-type="${d}">Pic</a> `;
|
||||
}
|
||||
}
|
||||
s += '</div>';
|
||||
$(this).append(s)
|
||||
}
|
||||
);
|
||||
|
||||
$('ul#browser_steps li .control .clear').click(function (element) {
|
||||
$("select", $(this).closest('li')).val("Choose one").change();
|
||||
$(":text", $(this).closest('li')).val('');
|
||||
});
|
||||
|
||||
|
||||
$('ul#browser_steps li .control .remove').click(function (element) {
|
||||
// so you wanna remove the 2nd (3rd spot 0,1,2,...)
|
||||
var p = $("#browser_steps li").index($(this).closest('li'));
|
||||
|
||||
var elem_to_remove = $("#browser_steps li")[p];
|
||||
$('.clear', elem_to_remove).click();
|
||||
$("#browser_steps li").slice(p, 10).each(function (index) {
|
||||
// get the next one's value from where we clicked
|
||||
var next = $("#browser_steps li")[p + index + 1];
|
||||
if (next) {
|
||||
// and set THIS ones value from the next one
|
||||
var n = $('input', next);
|
||||
$("select", $(this)).val($('select', next).val());
|
||||
$('input', this)[0].value = $(n)[0].value;
|
||||
$('input', this)[1].value = $(n)[1].value;
|
||||
// Triggers reconfiguring the field based on the system config
|
||||
$("select", $(this)).change();
|
||||
}
|
||||
|
||||
});
|
||||
|
||||
// Reset their hidden/empty states
|
||||
set_greyed_state();
|
||||
});
|
||||
|
||||
$('ul#browser_steps li .control .apply').click(function (event) {
|
||||
// sequential requests @todo refactor
|
||||
if (apply_buttons_disabled) {
|
||||
return;
|
||||
}
|
||||
|
||||
var current_data = $(event.currentTarget).closest('li');
|
||||
$('#browser-steps-ui .loader .spinner').fadeIn();
|
||||
apply_buttons_disabled = true;
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 0.5);
|
||||
$("#browsersteps-img").css('opacity', 0.65);
|
||||
|
||||
var is_last_step = 0;
|
||||
var step_n = $(event.currentTarget).data('step-index');
|
||||
|
||||
// On the last step, we should also be getting data ready for the visual selector
|
||||
$('ul#browser_steps li select').each(function (i) {
|
||||
if ($(this).val() !== 'Choose one') {
|
||||
is_last_step += 1;
|
||||
}
|
||||
});
|
||||
|
||||
if (is_last_step == (step_n + 1)) {
|
||||
is_last_step = true;
|
||||
} else {
|
||||
is_last_step = false;
|
||||
}
|
||||
|
||||
console.log("Requesting step via POST " + $("select[id$='operation']", current_data).first().val());
|
||||
// POST the currently clicked step form widget back and await response, redraw
|
||||
$.ajax({
|
||||
method: "POST",
|
||||
url: browser_steps_sync_url + "&browsersteps_session_id=" + browsersteps_session_id,
|
||||
data: {
|
||||
'operation': $("select[id$='operation']", current_data).first().val(),
|
||||
'selector': $("input[id$='selector']", current_data).first().val(),
|
||||
'optional_value': $("input[id$='optional_value']", current_data).first().val(),
|
||||
'step_n': step_n,
|
||||
'is_last_step': is_last_step
|
||||
},
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
$("#loading-status-text").hide();
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
},
|
||||
401: function (data) {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert(data.responseText);
|
||||
$("#loading-status-text").hide();
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
// it should return the new state (selectors available and screenshot)
|
||||
xpath_data = data.xpath_data;
|
||||
$('#browsersteps-img').attr('src', data.screenshot);
|
||||
$('#browser-steps-ui .loader .spinner').fadeOut();
|
||||
apply_buttons_disabled = false;
|
||||
$("#browsersteps-img").css('opacity', 1);
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 1);
|
||||
$("#loading-status-text").hide();
|
||||
set_first_gotosite_disabled();
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
if (data.responseText.includes("Browser session expired")) {
|
||||
disable_browsersteps_ui();
|
||||
}
|
||||
apply_buttons_disabled = false;
|
||||
$("#loading-status-text").hide();
|
||||
$('ul#browser_steps li .control .apply').css('opacity', 1);
|
||||
$("#browsersteps-img").css('opacity', 1);
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
$('ul#browser_steps li .control .show-screenshot').click(function (element) {
|
||||
var step_n = $(event.currentTarget).data('step-index');
|
||||
w = window.open(this.href, "_blank", "width=640,height=480");
|
||||
const t = $(event.currentTarget).data('type');
|
||||
|
||||
const url = browser_steps_fetch_screenshot_image_url + `&step_n=${step_n}&type=${t}`;
|
||||
w.document.body.innerHTML = `<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<body>
|
||||
<img src="${url}" style="width: 100%" alt="Browser Step at step ${step_n} from last run." title="Browser Step at step ${step_n} from last run."/>
|
||||
</body>
|
||||
</html>`;
|
||||
w.document.title = `Browser Step at step ${step_n} from last run.`;
|
||||
});
|
||||
|
||||
if (browser_steps_last_error_step) {
|
||||
$("ul#browser_steps>li:nth-child("+browser_steps_last_error_step+")").addClass("browser-step-with-error");
|
||||
}
|
||||
|
||||
$("ul#browser_steps select").change(function () {
|
||||
set_greyed_state();
|
||||
}).change();
|
||||
|
||||
});
|
||||
@@ -1,94 +0,0 @@
|
||||
$(document).ready(function () {
|
||||
var csrftoken = $('input[name=csrf_token]').val();
|
||||
$.ajaxSetup({
|
||||
beforeSend: function (xhr, settings) {
|
||||
if (!/^(GET|HEAD|OPTIONS|TRACE)$/i.test(settings.type) && !this.crossDomain) {
|
||||
xhr.setRequestHeader("X-CSRFToken", csrftoken)
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
// Load it when the #screenshot tab is in use, so we dont give a slow experience when waiting for the text diff to load
|
||||
window.addEventListener('hashchange', function (e) {
|
||||
toggle(location.hash);
|
||||
}, false);
|
||||
|
||||
toggle(location.hash);
|
||||
|
||||
function toggle(hash_name) {
|
||||
if (hash_name === '#screenshot') {
|
||||
$("img#screenshot-img").attr('src', screenshot_url);
|
||||
$("#settings").hide();
|
||||
} else if (hash_name === '#error-screenshot') {
|
||||
$("img#error-screenshot-img").attr('src', error_screenshot_url);
|
||||
$("#settings").hide();
|
||||
} else if (hash_name === '#extract') {
|
||||
$("#settings").hide();
|
||||
} else {
|
||||
$("#settings").show();
|
||||
}
|
||||
}
|
||||
|
||||
const article = $('.highlightable-filter')[0];
|
||||
|
||||
// We could also add the 'touchend' event for touch devices, but since
|
||||
// most iOS/Android browsers already show a dialog when you select
|
||||
// text (often with a Share option) we'll skip that
|
||||
article.addEventListener('mouseup', dragTextHandler, false);
|
||||
article.addEventListener('mousedown', clean, false);
|
||||
|
||||
function clean(event) {
|
||||
$("#highlightSnippet").remove();
|
||||
}
|
||||
|
||||
|
||||
function dragTextHandler(event) {
|
||||
console.log('mouseupped');
|
||||
|
||||
// Check if any text was selected
|
||||
if (window.getSelection().toString().length > 0) {
|
||||
|
||||
// Find out how much (if any) user has scrolled
|
||||
var scrollTop = (window.pageYOffset !== undefined) ? window.pageYOffset : (document.documentElement || document.body.parentNode || document.body).scrollTop;
|
||||
|
||||
// Get cursor position
|
||||
const posX = event.clientX;
|
||||
const posY = event.clientY + 20 + scrollTop;
|
||||
|
||||
// Append HTML to the body, create the "Tweet Selection" dialog
|
||||
document.body.insertAdjacentHTML('beforeend', '<div id="highlightSnippet" style="position: absolute; top: ' + posY + 'px; left: ' + posX + 'px;"><div class="pure-form-message-inline" style="font-size: 70%">Ignore any change on any line which contains the selected text.</div><br><a data-mode="exact" href="javascript:void(0);" class="pure-button button-secondary button-xsmall">Ignore exact text</a> </div>');
|
||||
|
||||
if (/\d/.test(window.getSelection().toString())) {
|
||||
// Offer regex replacement
|
||||
document.getElementById("highlightSnippet").insertAdjacentHTML('beforeend', '<a data-mode="digit-regex" href="javascript:void(0);" class="pure-button button-secondary button-xsmall">Ignore text including number changes</a>');
|
||||
}
|
||||
|
||||
$('#highlightSnippet a').bind('click', function (e) {
|
||||
if(!window.getSelection().toString().trim().length) {
|
||||
alert('Oops no text selected!');
|
||||
return;
|
||||
}
|
||||
|
||||
$.ajax({
|
||||
type: "POST",
|
||||
url: highlight_submit_ignore_url,
|
||||
data: {'mode': $(this).data('mode'), 'selection': window.getSelection().toString()},
|
||||
statusCode: {
|
||||
400: function () {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
}).done(function (data) {
|
||||
$("#highlightSnippet").html(data)
|
||||
}).fail(function (data) {
|
||||
console.log(data);
|
||||
alert('There was an error communicating with the server.');
|
||||
});
|
||||
});
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
});
|
||||
@@ -1,120 +0,0 @@
|
||||
$(document).ready(function () {
|
||||
var a = document.getElementById("a");
|
||||
var b = document.getElementById("b");
|
||||
var result = document.getElementById("result");
|
||||
var inputs;
|
||||
|
||||
$('#jump-next-diff').click(function () {
|
||||
|
||||
var element = inputs[inputs.current];
|
||||
var headerOffset = 80;
|
||||
var elementPosition = element.getBoundingClientRect().top;
|
||||
var offsetPosition = elementPosition - headerOffset + window.scrollY;
|
||||
|
||||
window.scrollTo({
|
||||
top: offsetPosition,
|
||||
behavior: "smooth",
|
||||
});
|
||||
|
||||
inputs.current++;
|
||||
if (inputs.current >= inputs.length) {
|
||||
inputs.current = 0;
|
||||
}
|
||||
});
|
||||
|
||||
function changed() {
|
||||
// https://github.com/kpdecker/jsdiff/issues/389
|
||||
// I would love to use `{ignoreWhitespace: true}` here but it breaks the formatting
|
||||
options = {
|
||||
ignoreWhitespace: document.getElementById("ignoreWhitespace").checked,
|
||||
};
|
||||
|
||||
var diff = Diff[window.diffType](a.textContent, b.textContent, options);
|
||||
var fragment = document.createDocumentFragment();
|
||||
for (var i = 0; i < diff.length; i++) {
|
||||
if (diff[i].added && diff[i + 1] && diff[i + 1].removed) {
|
||||
var swap = diff[i];
|
||||
diff[i] = diff[i + 1];
|
||||
diff[i + 1] = swap;
|
||||
}
|
||||
|
||||
var node;
|
||||
if (diff[i].removed) {
|
||||
node = document.createElement("del");
|
||||
node.classList.add("change");
|
||||
const wrapper = node.appendChild(document.createElement("span"));
|
||||
wrapper.appendChild(document.createTextNode(diff[i].value));
|
||||
} else if (diff[i].added) {
|
||||
node = document.createElement("ins");
|
||||
node.classList.add("change");
|
||||
const wrapper = node.appendChild(document.createElement("span"));
|
||||
wrapper.appendChild(document.createTextNode(diff[i].value));
|
||||
} else {
|
||||
node = document.createTextNode(diff[i].value);
|
||||
}
|
||||
fragment.appendChild(node);
|
||||
}
|
||||
|
||||
result.textContent = "";
|
||||
result.appendChild(fragment);
|
||||
|
||||
// For nice mouse-over hover/title information
|
||||
const removed_current_option = $('#diff-version option:selected')
|
||||
if (removed_current_option) {
|
||||
$('del').each(function () {
|
||||
$(this).prop('title', 'Removed '+removed_current_option[0].label);
|
||||
});
|
||||
}
|
||||
const inserted_current_option = $('#current-version option:selected')
|
||||
if (removed_current_option) {
|
||||
$('ins').each(function () {
|
||||
$(this).prop('title', 'Inserted '+inserted_current_option[0].label);
|
||||
});
|
||||
}
|
||||
// Set the list of possible differences to jump to
|
||||
inputs = document.querySelectorAll('#diff-ui .change')
|
||||
// Set the "current" diff pointer
|
||||
inputs.current = 0;
|
||||
// Goto diff
|
||||
$('#jump-next-diff').click();
|
||||
}
|
||||
|
||||
$('.needs-localtime').each(function () {
|
||||
for (var option of this.options) {
|
||||
var dateObject = new Date(option.value * 1000);
|
||||
option.label = dateObject.toLocaleString(undefined, {dateStyle: "full", timeStyle: "medium"});
|
||||
}
|
||||
})
|
||||
onDiffTypeChange(
|
||||
document.querySelector('#settings [name="diff_type"]:checked'),
|
||||
);
|
||||
changed();
|
||||
|
||||
a.onpaste = a.onchange = b.onpaste = b.onchange = changed;
|
||||
|
||||
if ("oninput" in a) {
|
||||
a.oninput = b.oninput = changed;
|
||||
} else {
|
||||
a.onkeyup = b.onkeyup = changed;
|
||||
}
|
||||
|
||||
function onDiffTypeChange(radio) {
|
||||
window.diffType = radio.value;
|
||||
// Not necessary
|
||||
// document.title = "Diff " + radio.value.slice(4);
|
||||
}
|
||||
|
||||
var radio = document.getElementsByName("diff_type");
|
||||
for (var i = 0; i < radio.length; i++) {
|
||||
radio[i].onchange = function (e) {
|
||||
onDiffTypeChange(e.target);
|
||||
changed();
|
||||
};
|
||||
}
|
||||
|
||||
document.getElementById("ignoreWhitespace").onchange = function (e) {
|
||||
changed();
|
||||
};
|
||||
|
||||
});
|
||||
|
||||
1055
changedetectionio/static/js/diff.js
Normal file
38
changedetectionio/static/js/diff.min.js
vendored
@@ -1,26 +0,0 @@
|
||||
$(document).ready(function () {
|
||||
$("#api-key").hover(
|
||||
function () {
|
||||
$("#api-key-copy").html('copy').fadeIn();
|
||||
},
|
||||
function () {
|
||||
$("#api-key-copy").hide();
|
||||
}
|
||||
).click(function (e) {
|
||||
$("#api-key-copy").html('copied');
|
||||
var range = document.createRange();
|
||||
var n = $("#api-key")[0];
|
||||
range.selectNode(n);
|
||||
window.getSelection().removeAllRanges();
|
||||
window.getSelection().addRange(range);
|
||||
document.execCommand("copy");
|
||||
window.getSelection().removeAllRanges();
|
||||
|
||||
});
|
||||
|
||||
$("#notification-token-toggle").click(function (e) {
|
||||
e.preventDefault();
|
||||
$('#notification-tokens-info').toggle();
|
||||
});
|
||||
});
|
||||
|
||||
@@ -1,56 +0,0 @@
|
||||
/**
|
||||
* debounce
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait after the last call before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds after the last call before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.debounce = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
timer = null,
|
||||
wait = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments;
|
||||
|
||||
function complete() {
|
||||
baseFunction.apply(self, args);
|
||||
timer = null;
|
||||
}
|
||||
|
||||
if (timer) {
|
||||
clearTimeout(timer);
|
||||
}
|
||||
|
||||
timer = setTimeout(complete, wait);
|
||||
};
|
||||
};
|
||||
|
||||
/**
|
||||
* throttle
|
||||
* @param {integer} milliseconds This param indicates the number of milliseconds
|
||||
* to wait between calls before calling the original function.
|
||||
* @param {object} What "this" refers to in the returned function.
|
||||
* @return {function} This returns a function that when called will wait the
|
||||
* indicated number of milliseconds between calls before
|
||||
* calling the original function.
|
||||
*/
|
||||
Function.prototype.throttle = function (milliseconds, context) {
|
||||
var baseFunction = this,
|
||||
lastEventTimestamp = null,
|
||||
limit = milliseconds;
|
||||
|
||||
return function () {
|
||||
var self = context || this,
|
||||
args = arguments,
|
||||
now = Date.now();
|
||||
|
||||
if (!lastEventTimestamp || now - lastEventTimestamp >= limit) {
|
||||
lastEventTimestamp = now;
|
||||
baseFunction.apply(self, args);
|
||||
}
|
||||
};
|
||||
};
|
||||
@@ -24,35 +24,29 @@ $(document).ready(function() {
|
||||
})
|
||||
|
||||
data = {
|
||||
notification_body: $('#notification_body').val(),
|
||||
notification_format: $('#notification_format').val(),
|
||||
notification_title: $('#notification_title').val(),
|
||||
notification_urls: $('.notification-urls').val(),
|
||||
window_url: window.location.href,
|
||||
window_url : window.location.href,
|
||||
notification_urls : $('.notification-urls').val(),
|
||||
notification_title : $('.notification-title').val(),
|
||||
notification_body : $('.notification-body').val(),
|
||||
notification_format : $('.notification-format').val(),
|
||||
}
|
||||
|
||||
|
||||
if (!data['notification_urls'].length) {
|
||||
alert("Notification URL list is empty, cannot send test.")
|
||||
return;
|
||||
for (key in data) {
|
||||
if (!data[key].length) {
|
||||
alert(key+" is empty, cannot send test.")
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
$.ajax({
|
||||
type: "POST",
|
||||
url: notification_base_url,
|
||||
data : data,
|
||||
statusCode: {
|
||||
400: function() {
|
||||
// More than likely the CSRF token was lost when the server restarted
|
||||
alert("There was a problem processing the request, please reload the page.");
|
||||
}
|
||||
}
|
||||
data : data
|
||||
}).done(function(data){
|
||||
console.log(data);
|
||||
alert('Sent');
|
||||
}).fail(function(data){
|
||||
console.log(data);
|
||||
alert('There was an error communicating with the server.');
|
||||
alert('Error: '+data.responseJSON.error);
|
||||
})
|
||||
});
|
||||
});
|
||||
|
||||